一种基于时空掩码重建的骨架检测模型的构建方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及图像数据处理技术领域,具体而言,涉及一种基于时空掩码重建的骨架检测模型的构建方法。
背景技术
人体姿态识别是检测图像或者视频中人体关键点的位置、构建人体骨架图的过程。利用人体姿态信息可以进一步进行动作识别、人机信息交互、异常行为检测等任务。然而,人的肢体比较灵活,姿态特征在视觉上变化比较大,容易受到视角和服饰变化的影响,同时,经常会出现用户的身体部分被遮挡的情况,导致在检测识别用户的人体姿态时,用户的骨架信息存在被遮掩和不完整的情况。因此,当前使用的骨架模型HRNet在实际部署中存在着问题,其无法在用户的骨架信息被遮挡或不完整的情况下,准确地还原识别出完整的人体骨架图。
由此可见,相关技术中存在的问题是:相关技术中的技术方案无法在骨架信息被遮挡或不完整的情况下,准确地还原识别出完整的人体骨架图。
发明内容
本发明解决的问题是:相关技术中的技术方案无法在骨架信息被遮挡或不完整的情况下,准确地还原识别出完整的人体骨架图。
为解决上述问题,本发明提供了一种基于时空掩码重建的骨架检测模型的构建方法,构建方法包括:
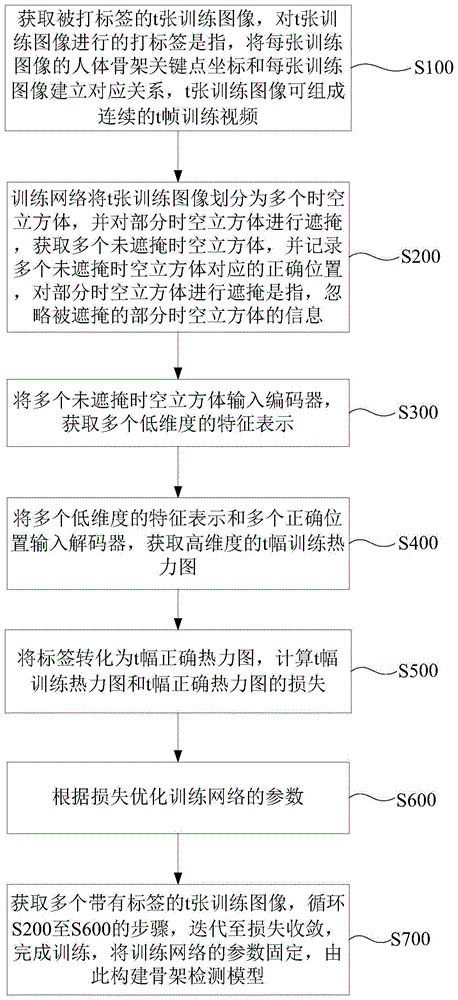
S100:获取被打标签的t张训练图像,对t张训练图像进行的打标签是指,将每张训练图像的人体骨架关键点坐标和每张训练图像建立对应关系,t张训练图像可组成连续的t帧训练视频;
S200:训练网络将t张训练图像划分为多个时空立方体,并对部分时空立方体进行遮掩,获取多个未遮掩时空立方体,并记录多个未遮掩时空立方体对应的正确位置,对部分时空立方体进行遮掩是指,忽略被遮掩的部分时空立方体的信息;
S300:将多个未遮掩时空立方体输入编码器,获取多个低维度的特征表示;
S400:将多个低维度的特征表示和多个正确位置输入解码器,获取高维度的t幅训练热力图;
S500:将标签转化为t幅正确热力图,计算t幅训练热力图和t幅正确热力图的损失;
S600:根据损失优化训练网络的参数;
S700:获取多个带有标签的t张训练图像,循环S200至S600的步骤,迭代至损失收敛,完成训练,将训练网络的参数固定,由此构建骨架检测模型;
其中,t为大于或等于2的整数。
与现有技术相比,采用该技术方案所达到的技术效果:经过时空掩码重建的骨架检测模型对于用户的骨架信息被遮挡或不完整的情况下,能够准确地还原识别出完整的人体骨架图。
在本发明的一个实施例中,在S100之前,还包括:
获取带有标签的训练视频,从训练视频中抽取t张训练图像,对训练视频打标签是指,将训练视频中每帧的人体骨架关键点坐标和训练视频的每帧建立对应关系。
与现有技术相比,采用该技术方案所达到的技术效果:通过本实施例的方法能够快速地获取t张训练图像,以满足本发明的构建方法的训练需要。
在本发明的一个实施例中,训练图像为RGB图像;或,训练图像为深度图像。
与现有技术相比,采用该技术方案所达到的技术效果:在本实施例的方案中,可通过输入不同种类的训练图像,使训练完成的骨架检测模型适用于相应种类的训练图像,有效地提升了其实用性。
在本发明的一个实施例中,t张训练图像包括H×W×t个像素;
其中,H为每张训练图像的高度,W为每张训练图像的宽度,t为训练图像的数量。
在本发明的一个实施例中,编码器和解码器均为Vision Transformer网络结构。
与现有技术相比,采用该技术方案所达到的技术效果:Vision Transformer网络结构能够准确地完成本发明中编码器和解码器的工作,提高了本发明的构建方法的可靠性。
在本发明的一个实施例中,编码器包括编码器全连接层和Transformer blocks,S300包括:
将多个未遮掩时空立方体输入编码器全连接层进行线性映射后,再输入Transformer blocks中,得到多个特征表示。
与现有技术相比,采用该技术方案所达到的技术效果:通过本实施例的方法能够准确地得到多个未遮掩时空立方体内的信息,进而使后续的构建方法更加准确地的进行。
在本发明的一个实施例中,解码器包括解码器全连接层和reshape,S400包括:
将多个低维度的特征表示和多个正确位置输入解码器全连接层进行线性映射后,再输入reshape中,得到t幅训练热力图。
与现有技术相比,采用该技术方案所达到的技术效果:通过本实施例的方法能够根据编码器输出的信息还原得到完整的训练热力图,进而使后续的构建方法更加准确地的进行。
附图说明
图1为本发明一些实施例的基于时空掩码重建的骨架检测模型的构建方法的步骤流程图。
具体实施方式
为使本发明的上述目的、特征和优点能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
参见图1,本实施例提供一种基于时空掩码重建的骨架检测模型的构建方法,构建方法包括:
S100:获取被打标签的t张训练图像,对t张训练图像进行的打标签是指,将每张训练图像的人体骨架关键点坐标和每张训练图像建立对应关系,t张训练图像可组成连续的t帧训练视频;
S200:训练网络将t张训练图像划分为多个时空立方体,并对部分时空立方体进行遮掩,获取多个未遮掩时空立方体,并记录多个未遮掩时空立方体对应的正确位置,对部分时空立方体进行遮掩是指,忽略被遮掩的部分时空立方体的信息;
S300:将多个未遮掩时空立方体输入编码器,获取多个低维度的特征表示;
S400:将多个低维度的特征表示和多个正确位置输入解码器,获取高维度的t幅训练热力图;
S500:将标签转化为t幅正确热力图,计算t幅训练热力图和t幅正确热力图的损失;
S600:根据损失优化训练网络的参数;
S700:获取多个带有标签的t张训练图像,循环S200至S600的步骤,迭代至损失收敛,完成训练,将训练网络的参数固定,由此构建骨架检测模型;
其中,t为大于或等于2的整数。
在本实施例中,提供了一种基于时空掩码重建的骨架检测模型的构建方法,通过本发明的构建方法构建的骨架检测模型,能够应用于人体工学智能设备,使人体工学智能设备能够在骨架信息被遮挡或不完整的情况下,准确地还原识别出完整的人体骨架图。
需要说明的是,人体工学智能设备包括但不限于升降桌、升降讲台等,用户往往需要将双手放于人体工学智能设备上进行办公或学习,人体工学智能设备可通过电机进行高度调节。
现有技术中的识别模型采用HRNet,HRNet是针对2D人体姿态估计任务提出的,并且该网络主要是针对单一个体的姿态评估,即输入网络的图像中只有一个人体目标。HRNet平行地连接从高到低分辨率的子网络,使用重复的多尺度融合,利用相同深度和相似级别的低分辨率表示来提高高分辨率表示。模型的最终输出包括人体的多个骨架关键点。
HRNet网络是使用MSE损失对骨架热力图进行回归和复原,进而得到16个关键点的粗定位后,再进行修正和定位。为了实现在部分关键点被遮挡情况下,模型还能识别出用户在使用人体工学智能设备时的使用姿态,我们希望能对模型进行了优化。目的在于模型能够实现在部分关键点被遮挡时,模型能够重构出关键骨骼点,帮助HRNet进行姿态的识别,提供合理的智能操作。
优选地,本实施例中的训练网络为Transformer训练网络。
进一步地,在S100中,获取被打标签的t张训练图像,对t张训练图像进行的打标签是指,将每张训练图像的人体骨架关键点坐标和每张训练图像建立对应关系,t张训练图像可组成连续的t帧训练视频。需要说明的是,在本实施例的构建方法中,标签可为工作人员根据训练视频片段输入,标签包含了人体骨架的多个关键点坐标;在确定标签后,可将标签转化为正确关键点坐标的正确热力图。同时,本实施例中的t张训练图像可组成连续的t帧训练视频,即t张训练图像可为t帧训练视频拆分而来。
进一步地,在S200中,训练网络将t张训练图像划分为多个时空立方体,并对部分时空立方体进行遮掩,获取多个未遮掩时空立方体,并记录多个未遮掩时空立方体对应的正确位置,对部分时空立方体进行遮掩是指,忽略被遮掩的部分时空立方体的信息。即在训练骨架检测模型时,通过主动遮挡部分时空立方体来模拟用户的骨架信息被遮挡或不完整的情况。需要说明的是,若基于时空立方体建立xyz三维坐标系,则x轴、y轴分别代表该时空立方体每帧图像的长和宽,z轴代表时间,当将t张训练图像视为t帧训练视频时,时空立方体z轴的长度即为t个连续帧的时间大小。示例性地,若将训练视频片段划分为10*10一共100个时空立方体,其中一个未遮掩时空立方体的位置为第1排第3个,则该未遮掩时空立方体的正确位置为第1排第3个。
进一步地,在S300中,将多个未遮掩时空立方体输入编码器,获取多个低维度的特征表示。将多个未遮掩时空立方体输入编码器的过程为提取多个未遮掩时空立方体的信息的过程。
进一步地,在S400中,将多个低维度的特征表示和多个正确位置输入解码器,获取高维度的t幅训练热力图。
进一步地,在S500中,将标签转化为t幅正确热力图,计算t幅训练热力图和t幅正确热力图的损失。
进一步地,在S600中,根据损失优化训练网络的参数。需要说明的是,此处训练网络的参数指的是编码器和解码器的参数。
进一步地,在S700中,获取多个带有标签的t张训练图像,循环S200至S600的步骤,迭代至损失收敛,完成训练,将训练网络的参数固定,由此构建骨架检测模型。需要说明的是,每进行一次S200至S600的的步骤,骨架检测模型的参数都会进一步地优化,当多次循环S200至S600的的步骤直至损失收敛时,说明此时训练完成,此时训练图像被遮掩时,训练网络可以将被遮掩的训练图像进行较高准确度地重建,输出完整的人体骨架图。
可以理解地,经过时空掩码重建的骨架检测模型对于用户的骨架信息被遮挡或不完整的情况下,能够准确地还原识别出完整的人体骨架图。
进一步地,在S100之前,还包括:
获取带有标签的训练视频,从训练视频中抽取t张训练图像,对训练视频打标签是指,将训练视频中每帧的人体骨架关键点坐标和训练视频的每帧建立对应关系。
在本实施例中,训练过程中需要多个t张训练图像,而获取多个t张训练图像的途径,优选地,可以是从1个训练视频中抽取由多个由t个连续帧组成的训练视频片段,拆分为t张训练图像;可选地,在S200中,改变对多个时空立方体的遮掩方案;可选地,从多个训练视频中,分别抽取由t个连续帧组成的训练视频片段,并拆分为t张训练图像。
需要说明的是,训练视频均包含标签。
可以理解地,通过本实施例的方法能够快速地获取t张训练图像,以满足本发明的构建方法的训练需要。
进一步地,训练图像为RGB图像;或,训练图像为深度图像。
在本实施例中,训练图像可为RGB图像,也可为深度图像,也可包括RGB图像和深度图像。若训练图像为RGB图像,则构建出的骨架检测模型可适用于RGB图像;若训练图像为深度图像,则构建出的骨架检测模型可适用于深度图像。
可以理解地,在本实施例的方案中,可通过输入不同种类的训练图像,使训练完成的骨架检测模型适用于相应种类的训练图像,有效地提升了其实用性。
进一步地,t张训练图像包括H×W×t个像素;
其中,其中,H为每张训练图像的高度,W为每张训练图像的宽度,t为训练图像的数量。
进一步地,编码器和解码器均为Vision Transformer网络结构。
可以理解地,Vision Transformer网络结构能够准确地完成本发明中编码器和解码器的工作,提高了本发明的构建方法的可靠性。
进一步地,编码器包括编码器全连接层和Transformer blocks,S300包括:
将多个未遮掩时空立方体输入编码器全连接层进行线性映射后,再输入Transformer blocks中,得到多个特征表示。
在本实施例中,S300的整个过程为提取多个未遮掩时空立方体的信息的过程。
可以理解地,通过本实施例的方法能够准确地得到多个未遮掩时空立方体内的信息,进而使后续的构建方法更加准确地的进行。
进一步地,解码器包括解码器全连接层和reshape,S400包括:
将多个低维度的特征表示和多个正确位置输入解码器全连接层进行线性映射后,再输入reshape中,得到t幅训练热力图。
可以理解地,通过本实施例的方法能够根据编码器输出的信息还原得到完整的训练热力图,进而使后续的构建方法更加准确地的进行。
虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。