一种基于数字信号处理的径流预测方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明属于径流预测领域,具体涉及一种基于数字信号处理的径流预测方法。
背景技术
在水文学研究中,高精度的月径流预报一直是与这一领域各方面密切相关且实现困难的研究内容。精确且可靠的径流预测对于防洪减灾、优化水资源调控与分配可以起到重要的指导参考作用。径流过程在气象变化、河床特性和自然地理条件等因素的综合影响下,展现出高度的非线性、非平稳性和随机特性。因此,确保精确性与稳定性的预测方法就成为了相关领域的核心研究问题。
径流信号因为包含复杂的周期性和趋势性特征而难以直接对整体进行准确的预测。选取合适的数字信号处理技术可以将径流信号分解为时序特征更加显著的信号分量,使得模型可以更加高效且准确地对径流信号进行预测。本发明使用了VMD分解技术以提高预测的效率与精度。
经过信号分解得到的分量数量过多可能导致计算量过大,降低模型预测效率,因此需要从分解结果中筛选出与径流过程相关性最高的子信号,以此来减小多余信息对于模型的干扰和不必要的计算量。本发明使用了PCA分析技术以筛选与径流量相关度更高的子信号。
近年来,人工神经网络被广泛应用于径流预测中。LSTM长短期记忆网络,具有非线性预测以及捕捉时间序列的长期关联性的能力,并且能够深入挖掘多种元素特征之间潜在的联系,并整合多维数据对系统的影响进行预测。本发明结合SSA算法优化和改进了LSTM模型以进一步提升预测精度和稳定性。
发明内容
针对现有技术中的上述不足,本发明提供的一种基于数字信号处理的径流预测方法,解决了径流信号难以直接对整体进行准确的预测且预测效率和精度不高的问题。
为了达到上述发明目的,本发明采用的技术方案为:一种基于数字信号处理的径流预测方法,包括以下步骤:
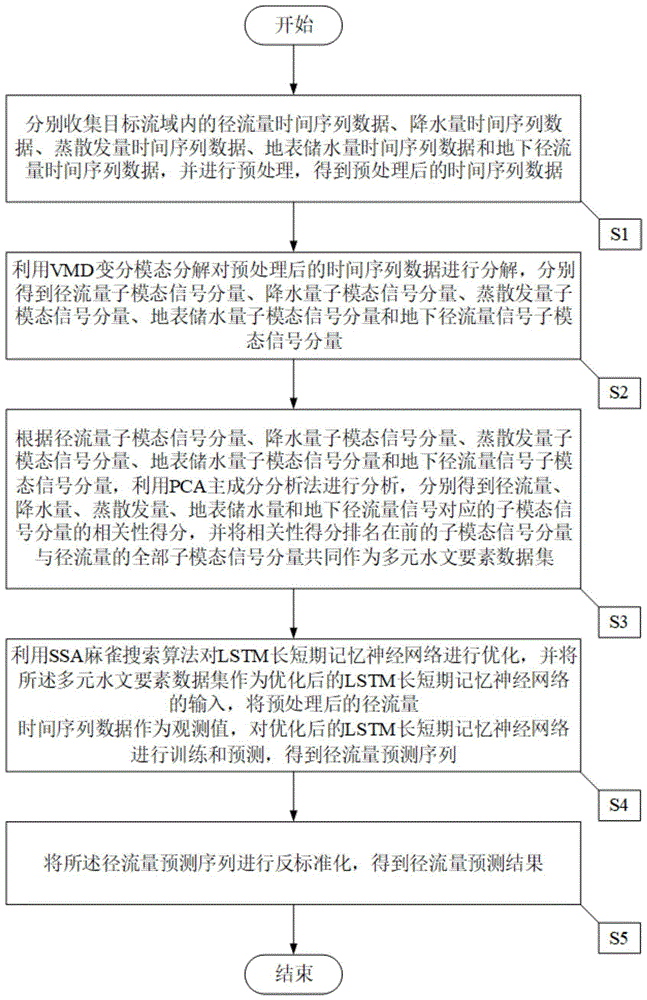
S1:分别收集目标流域内的径流量时间序列数据、降水量时间序列数据、蒸散发量时间序列数据、地表储水量时间序列数据和地下径流量时间序列数据,并进行预处理,得到预处理后的时间序列数据,所述预处理后的时间序列数据包括径预处理后的流量时间序列数据、预处理后的降水量时间序列数据、预处理后的蒸散发时间序列数据、预处理后的地表储水量时间序列数据和预处理后的地下径流量时间序列数据;
S2:利用VMD变分模态分解对预处理后的时间序列数据进行分解,分别得到径流量子模态信号分量、降水量子模态信号分量、蒸散发量子模态信号分量、地表储水量子模态信号分量和地下径流量信号子模态信号分量;
S3:根据径流量子模态信号分量、降水量子模态信号分量、蒸散发量子模态信号分量、地表储水量子模态信号分量和地下径流量信号子模态信号分量,利用PCA主成分分析法进行分析,分别得到径流量、降水量、蒸散发量、地表储水量和地下径流量信号对应的子模态信号分量的相关性得分,并将相关性得分排名在前的子模态信号分量与径流量的全部子模态信号分量共同作为多元水文要素数据集;
S4:利用SSA麻雀搜索算法对LSTM长短期记忆神经网络进行优化,并将所述多元水文要素数据集作为优化后的LSTM长短期记忆神经网络的输入,将预处理后的径流量时间序列数据作为观测值,对优化后的LSTM长短期记忆神经网络进行训练和预测,得到径流量预测序列;
S5:将所述径流量预测序列进行反标准化,得到径流量预测结果。
本发明的有益效果为:本发明利用VMD变分模态分解对目标流域内各水文要素的时间序列信号进行分解,并利用PCA主成分分析法计算各个水文要素的信号分量对于径流量的相关度,选取相关度高的子模态信号分量与径流量的全部子模态信号分量共同作为模型的输入数据集,利用LSTM长短期记忆神经网络和SSA麻雀搜索算法基于目标流域内径流量数据的周期特征与趋势特征进行训练,本发明能够显著提高径流量预测的精度,得到较为准确的结果,为相关水文研究与调控工作提供理论支撑和技术支持。
进一步地:所述S2的具体步骤如下:
S21:将预处理后的时间序列数据,利用VMD变分模态进行分解,得到若干个时间子序列信号,并构建约束变分问题;
S22:引入惩罚因子α和拉格朗日算子λ,将约束变分问题转变为非约束变分问题,构建得到增广拉格朗日表达式;
S23:设置迭代过程参数
S24:设定判定参数,判断第m次迭代后的时间子序列信号是否满足判定参数,若是,停止迭代,得到迭代后的时间子序列信号,并进入S25,否则,继续下一次迭代,并返回步骤S23;
S25:将迭代后的时间子序列信号作为子模态信号分量,其中,所述子模态信号分量包括径流量子模态信号分量、降水量子模态信号分量、蒸散发量子模态信号分量、地表储水量子模态信号分量和地下径流量信号子模态信号分量。
上述进一步方案的有益效果为:本发明利用VMD变分模态分解对目标流域的各个水文要素的时间序列信号进行分解处理,将各个水文要素的时间序列信号分解为时序特征更加显著的子模态信号分量,能够有效提高预测的效率和精度。
进一步地:所述S23中迭代过程参数
其中,
上述进一步方案地有益效果为:根据迭代过程参数进行迭代,加快迭代速度。
进一步地:所述S24中判断第m次迭代后的时间子序列信号是否满足判定参数的表达式如下:
其中,
上述进一步方案的有益效果为:设置判定参数,使得到地时间子序列信号具有更高的精度。
进一步地:所述S3的具体步骤如下:
S31:将径流量子模态信号分量、降水量子模态信号分量、蒸散发量子模态信号分量、地表储水量子模态信号分量和地下径流量信号子模态信号分量进行标准化处理,并构建相关系数矩阵;
S32:计算所述相关系数矩阵的特征值和特征向量,并选取特征值大于1且方差累计贡献率超过预设阈值的最小成分作为主成分;
S33:根据特征值和特征向量计算得到各个主成分的相关性得分;
S34:根据各个主成分的相关性得分,进行径流过程相关性得分评价,并选取相关性得分排名前的子模态信号分量与径流量的全部子模态信号分量共同作为多元水文要素数据集。
上述进一步方案的有益效果为:本发明利用PCA主成分分析法对各个水文元素的子模态信号分量进行分析,并筛选与径流量相关度更高的子模态信号分量,能够减少多余信息对预测的干扰和不必要的计算量,提高预测效率。
进一步地:所述相关性得分的表达式如下:
其中,Fs
上述进一步方案的有益效果为:通过计算各个主成分的相关性得分,便于提取与径流量预测的相关性强的数据,减少多余信息对预测的影响,提高预测的效率。
进一步地:所述S4的具体步骤如下:
S41:初始化SAA麻雀搜索算法种群,设置优化代数Ti、初始迭代次数iter的值为1和优化变量的维度d为3;
S42:通过计算所有麻雀的适应度更新当前种群位置,所述种群包括发现者、搜寻者和警戒者;
S43:设置警戒者数量占总种群的20%,通过计算更新发现者的位置、搜寻者的位置和警戒者的位置;
S44:根据更新后的种群位置对LSTM长短期记忆神经网络进行优化,得到优化后的LSTM长短期记忆神经网络;
S45:将所述多元水文要素数据集作为优化后的LSTM长短期记忆神经网络的输入,将预处理后的径流量时间序列数据作为观测值对优化后的LSTM长短期记忆神经网络进行训练,得到径流量预测序列;
S46:判断迭代次数iter是否达到优化代数Ti,若是,停止训练,输出径流量预测序列,并进入S5,否则,初始迭代次数iter的值为iter+1,并返回S42。
上述进一步方案的有益效果为:本发明利用SAA麻雀搜索算法对LSTM长短期记忆神经网络进行优化,能够提高预测的精度和效率。
进一步地:所述S45中对优化后的LSTM长短期记忆神经网络进行训练的具体步骤如下:
S451:将预处理后的径流量时间序列数据划分为优化后的LSTM长短期记忆神经网络的训练集和验证集,将多元水文要素数据作为优化后的LSTM长短期记忆神经网络的输入集;
S452:更新优化后的LSTM长短期记忆神经网络的遗忘门状态f
S453:根据LSTM长短期记忆神经网络得到的径流量预测序列,与训练集对照计算得到误差,判断所述误差在若干轮训练后是否降低,若是,则停止训练,并输出径流量预测序列,否则,进入S454;
S454:判断训练周期数是否大于预设的训练周期数,若是,停止训练,并输出径流量预测序列,否则,返回S452。
上述进一步方案的有益效果为:本发明利用已知数据对LSTM长短期记忆神经网络进行训练,能够提高输出的径流量预测序列的精度。
进一步地:所述径流量预测序列的表达式如下:
h
其中,o
上述进一步方案的有益效果为:通过优化后的LSTM长短期记忆神经网络得到径流量预测序列,预测结果精确,预测效率高。
附图说明
图1为一种基于数字信号处理的径流预测方法的流程图;
图2为本发明实施例中对径流量序列进行VMD变分模态分解得到的子序列;
图3为本发明实施例中对降水量序列进行VMD变分模态分解得到的子序列;
图4为本发明实施例中对蒸散发量序列进行VMD变分模态分解得到的子序列;
图5为本发明实施例中对地表储水量序列进行VMD变分模态分解得到的子序列;
图6为本发明实施例中对地下径流量序列进行VMD变分模态分解得到的子序列;
图7为本发明实施例中径流序列实测值和预测值的对比图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
在本发明的一个实施例中,如图1所示,本发明提供了一种基于数字信号处理的径流预测方法,包括以下步骤:
S1:分别收集目标流域内的径流量时间序列数据R O、降水量时间序列数据T P、蒸散发量时间序列数据T E、地表储水量时间序列数据S R C和地下径流量时间序列数据SSRO,并进行预处理,得到预处理后的时间序列数据,所述预处理后的时间序列数据包括预处理后的流量时间序列数据、预处理后的降水量时间序列数据、预处理后的蒸散发时间序列数据、预处理后的地表储水量时间序列数据和预处理后的地下径流量时间序列数据;
S2:利用VMD变分模态分解对预处理后的时间序列数据进行分解,分别得到径流量子模态信号分量、降水量子模态信号分量、蒸散发量子模态信号分量、地表储水量子模态信号分量和地下径流量信号子模态信号分量;
S3:根据径流量子模态信号分量、降水量子模态信号分量、蒸散发量子模态信号分量、地表储水量子模态信号分量和地下径流量信号子模态信号分量,利用PCA主成分分析法进行分析,分别得到径流量、降水量、蒸散发量、地表储水量和地下径流量信号对应的子模态信号分量的相关性得分,并将相关性得分排名在前的子模态信号分量与径流量的全部子模态信号分量共同作为多元水文要素数据集;
S4:利用SSA麻雀搜索算法对LSTM长短期记忆神经网络进行优化,并将所述多元水文要素数据集作为优化后的LSTM长短期记忆神经网络的输入,将径流量的时间序列数据作为观测值,对优化后的LSTM长短期记忆神经网络进行训练和预测,得到径流量预测序列;
S5:将所述径流量预测序列进行反标准化,得到径流量预测结果。
其中,S1中对所述时间序列数据进行预处理的具体方式为错误值剔除和缺失值插值填补。
在本发明的一个实施例中,S2的具体步骤如下:
S21:将预处理后的时间序列数据中的径流量时间序列数据,利用VMD变分模态进行分解,得到径流量时间序列数据的N个时间子序列信号
其中,
S22:引入惩罚因子α和拉格朗日算子λ,将约束变分问题转变为非约束变分问题,构建得到增广拉格朗日表达式,所述增广拉格朗日表达式如下:
其中,L为拉格朗日函数,α为惩罚因子,λ为拉格朗日算子,λ(t)为t时刻的拉格朗日演算函数;
S23:设置迭代过程参数
其中,
S24:设定判定参数ε,判断第m次迭代后的时间子序列信号是否满足判定参数,若是,停止迭代,得到迭代后的时间子序列信号,并进入S25,否则,继续下一次迭代,并返回步骤S23,所述判断第m次迭代后的时间子序列信号是否满足判定参数的表达式如下:
其中,
S25:将迭代后径流量时间序列的时间子序列信号
其中,预处理后的时间序列数据包括径流量时间序列数据RO、降水量时间序列数据TP、蒸散发时间序列数据TE、地表储水量时间序列数据SRC和地下径流量时间序列数据SSRO,均采用所述S21-S25进行分解,得到径流量子模态信号分量RO′、降水量子模态信号分量TP′、蒸散发量子模态信号分量TE′、地表储水量子模态信号分量SRC′和地下径流量信号子模态信号分量SSRO′。
S3的具体步骤如下:
S31:将S2得到的子模态信号分量RO′、TP′、TE′、SRC′和SSRO′进行标准化处理,以一组子模态信号分量对象为一行,同一时刻的不同子模态信号分量的样本值为列,计算第i行的第j列子模态信号分量样本值的标准化数值,将标准化数值作为相关系数矩阵I
其中,I
S32:计算所述相关系数矩阵的特征值和特征向量,并选取特征值大于1且方差累计贡献率超过预设阈值的最小成分作为主成分,所述预设阈值可设置为80%,方差贡献率的表达式如下:
其中,Var为方差累计贡献率,p为主成分个数,Var
S33:根据特征值Ev
其中,Fs
S34:根据各个主成分的相关性得分,进行径流过程相关性得分评价,并选取相关性得分排名前的子模态信号分量与径流量的全部子模态信号分量共同作为多元水文要素数据集,本发明可选取相关性得分排名前80%的子模态信号分量,所述相关性得分的表达式如下:
其中,Fs
S4的具体步骤如下:
S41:初始化SAA麻雀搜索算法种群,设置优化代数Ti、初始迭代次数iter的值为1和优化变量的维度d为3;
S42:通过计算所有麻雀的适应度更新当前种群的位置,并划分发现者、搜寻者和警戒者;
S43:设置警戒者数量占总种群的20%,通过计算更新发现者的位置、搜寻者的位置和警戒者的位置;
S44:根据当前种群位置对LSTM长短期记忆神经网络进行优化,得到优化后的LSTM长短期记忆神经网络;
S45:将所述多元水文要素数据集作为优化后的LSTM长短期记忆神经网络的输入,将预处理后的径流量时间序列数据作为观测值对优化后的LSTM长短期记忆神经网络进行训练,得到径流量预测序列;
S46:判断迭代次数iter是否达到优化代数Ti,若是,停止训练,输出径流量预测序列,并进入S5,否则,初始迭代次数iter的值为iter+1,并返回S42。
所述S43中,更新发现者的位置的计算表达式如下:
其中,
所述S43中,更新搜寻者的位置的计算表达式如下:
其中,
所述S43中,更新警戒者的位置,计算公式如下所述:
其中,
所述S45中对优化后的LSTM长短期记忆神经网络进行训练的具体步骤如下:
S451:将预处理后的径流量时间序列数据划分为优化后的LSTM长短期记忆神经网络的训练集和验证集,将多元水文要素数据作为优化后的LSTM长短期记忆神经网络的输入集;
S452:更新优化后的LSTM长短期记忆神经网络的遗忘门状态f
S453:根据LSTM长短期记忆神经网络得到的径流量预测序列,与训练集对照计算得到误差,判断所述误差在若干轮训练后是否降低,若是,则停止训练,并输出径流量预测序列,否则,进入S454;
S454:判断训练周期数是否大于预设的训练周期数,若是,停止训练,并输出径流量预测序列,否则,返回S452,所述预设的训练周期数可设置为1000。
所述S452中更新LSTM长短期记忆神经网络的遗忘门状态f
其中,f
所述S452中更新LSTM长短期记忆神经网络的输入门状态i
其中,i
所述S452中更新在当前输入神经元
/>
其中,C
所述S452中更新LSTM长短期记忆神经网络的输出的径流量预测序列o
h
其中,o
在S5中,将径流量预测序列进行反标准化,得到径流量预测结果,,并利用误差指标对所述径流量预测结果进行评价,根据径流量预测结果选取均方根误差RMSE、回归系数R和纳什效率系数NSE对预测的性能进行评价:
均方根误差RMSE、回归系数R和纳什效率系数NSE的表达式分别如下:
其中,RMSE为均方根误差,R为回归系数,NSE为纳什效率系数,N为样本数量,y
在本发明的一个实施例中,收集来自唐乃亥水文站1960年到2020年的月度径流量、降水量、蒸散发量、地表储水量和地下径流量时间序列数据,共732个月,并对收集到的数据进行错误值提出和缺失值插值填补。
如图2所示,为对唐乃亥站的径流量序列进行VMD变分模态分解得到的子序列,图中横坐标为时间序列的序号,纵坐标为径流量(m
如图7所示,为径流量实测值和预测值的对比图。对来自唐乃亥1950年到2020年的月径流数据,采用三个对照组和本发明VMD-SSA-LSTM进行分析,三个对照组分别为LSTM长短期记忆神经网络、SSA-LSTM麻雀搜索算法优化长短期神经记忆网络和EMD-SSA-LSTM经验模态分解结合麻雀搜索算法优化长短期记忆神经网络,如表1本发明的预测结果和对照组模型预测结果的误差分析表所示:
表1
由表1可知,本发明预测结果的均方根误差RMSE比其余对照组模型的值小,回归系数R和纳什效率系数NSE均比其余对照组模型的值大,且接近1,说明本发明相比于其余预测,具有更好的预测效果,具有更高的预测精度。
本发明的有益效果为:本发明利用VMD变分模态分解对目标流域内各水文信号进行分解,并利用PCA主成分分析法计算各个水文要素的信号分量对于径流量的相关度,选取相关度高的信号分量与径流量信号分量共同作为模型的输入数据集,利用LSTM长短期记忆神经网络和SSA麻雀搜索算法基于目标流域内径流量数据的周期特征与趋势特征进行训练,本发明能够显著提高径流量预测的精度,得到较为准确的结果,为相关水文研究与调控工作提供理论支撑和技术支持。
- 一种通用化的FPGA配置系统及方法与重配置系统及方法
- 一种通用质量特性要求不达风险分析方法与系统
- 一种基于SysML的设备通用质量特性和功能特性试验流程一体化建模方法