一种基于智能语音问答的跨模态抑郁症检测方法
文献发布时间:2023-06-19 11:49:09
技术领域
本发明涉及心理学、语音处理和自然语言处理技术领域,尤其涉及一种基于智能语音问答的跨模态抑郁症检测方法。
背景技术
根据世界卫生组织的数据表明,全球约有3.5亿抑郁患者,我国的抑郁患者高达9500万人,当前抑郁症已经成为世界第二大疾病,抑郁症对社会的危害性巨大,每年给我国造成的经济损失高达78亿美元。抑郁症的及时治疗对于康复十分重要,而抑郁症的检测是治愈抑郁症的第一步。
现有的抑郁症检测方法主要包括基于问卷量表的方法、基于社交媒体的方法以及基于眼动仪或者脑成像等设备的检测方法,例如,Kohrt等人探究了基于PHQ-9抑郁症诊断标准的问卷量表对于检测抑郁症的效果;Islam等人从用户在社交媒体上发表的文本提取了词典特征,并使用决策树模型进行抑郁症检测;Ay等人提出使用长短期记忆网络(LSTM)和卷积神经网络(CNN)来处理脑电波数据,用于抑郁症检测。然而,基于问卷量表的抑郁症检测方法往往存在反馈信息较少,结果不够客观准确的问题。基于社交媒体的抑郁症检测方法要求用户在社交媒体上需要有足够的发布内容和行为,无法处理新用户和行为稀疏的用户。基于眼动仪和脑电波的方法设备成本高昂,导致检测成本较高。同时,这些方法涉及的模态较为单一,抑郁症检测的准确率不够令人满意。
发明内容
本发明的目的是为了解决现有技术中存在的缺点,而提出的一种基于智能语音问答的跨模态抑郁症检测方法。
为了实现上述目的,本发明采用了如下技术方案:一种基于智能语音问答的跨模态抑郁症检测方法,包括以下步骤:
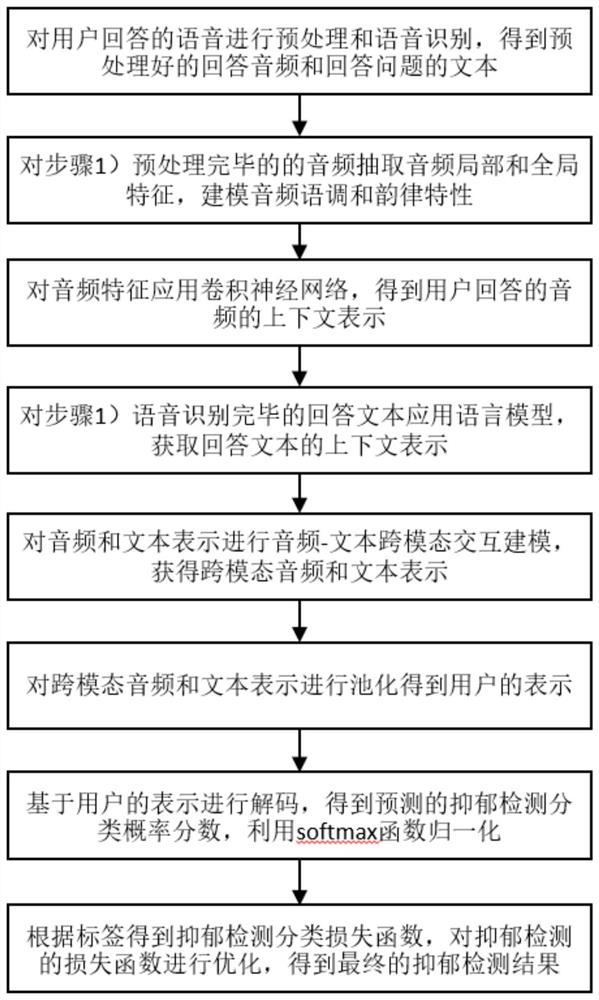
先让用户对语音问题进行语音答复或文本式答复,再对用户回答的语音进行预处理和语音识别,得到预处理好的回答音频和回答问题的文本,在对回答音频和回答问题文本进行整合;
对步骤1)中音频语调和韵律特性进行建模,对音频语调和韵律中含有的独特语调和韵律进行单独整合。
对整合好的音频特征应用到卷积神经网络,得到用户回答音频的上下文表示;
对步骤1)语音识别完毕的回答文本应用语言模型,获取回答文本的上下文表示;
对音频和文本的表示进行跨模态处理,获得跨模态音频和文本表示;
对跨模态音频和文本表示进行池化得到用户的表示;
基于用户的表示进行解码,得到预测的抑郁检测分类概率分数,并利用softmax函数对分类概率归一化;
根据标签得到抑郁检测分类损失函数,得到最终的抑郁检测结果。
优选的,对于步骤1)将预处理完毕的音频抽取音频的局部和全局特征,并对局部音频和全局音频进行分类整合,再导入步骤2)。
优选的,对于步骤5)将音频表示和文本表示进行音频到文本跨模态交互建模再导入步骤6)。
优选的,对于步骤8)对抑郁检测的损失函数进行优化,再得到最终抑郁症检测结果。
与现有技术相比,本发明的优点和积极效果在于,从每帧中提取诸如音调和能量之类的局部特征,和从一句话中提取的所有语音特征的统计结果的全局特征。
正常人与抑郁症患者在语音特性上有明显区别。正常人说话时,情感较为丰富,音调也随着情绪变化起伏,听起来抑扬顿挫的感觉清晰而明显;抑郁症患者说话时,情感比较平淡,以负面情绪居多,语气听起来模糊而平淡,体现出患者的无力感与虚无感。这些语言行为可通过多种语音特征表示,如韵律特征、频谱特征、声音质量特征。
本发明实施中提取的局部特征包括帧长、响度、能量、过零率等韵律特征,基频、LPC、LSP、MFCC等频谱特征,频率微扰、振幅微扰、共振峰及其频带等声音质量特征。其中,短时特征以帧长20ms,帧移10ms对音频信号分帧,再通过汉明窗,接着通过FFT变换得到频域值,然后通过自相关函数(ACF)得到基音周期等30维短时特征。由于每个人针对每个问题的回答时长不同,因此每句话的帧数不同,所有话的帧数在300帧到1400帧之间。MFCC的提取是将音频文件分帧后,对语音高频部分进行预加重,增加语音的高频分辨率,再依次进行加窗、FFT变换和梅尔倒谱分析,即可得到13个梅尔倒谱系数。LPC的提取需要经过线性预测编码得到,同时从每帧中提取出LSP。对短时特征MFCC、LPC和LSP进行平滑处理和一阶导数运算,得到29个短时Delta特征。对MFCC进行二次求导运算,得到13个短时特征。因此,关于MFCC、LPC和LSP,共有71维短时特征。从音频模态,共提取了101维短时特征。
将提取出的局部特征值经过7个统计函数可得到全局特征,即通过最大值函数、最小值函数、平均值函数、峰度函数、偏度函数、中位数函数、标准差函数。此时,可从每个音频文件中提取出707维全局特征。
在本发明的一个实施例中,步骤3)包括:使用一个二维多层卷积神经网络,学习音频特征的隐含表示。
具体而言,如图2所示,在这一步骤中,一个二维多层的卷积神经网络(CNN)用于从原始语音特征中提取抽象的隐含语音规律。该CNN的架构从下而上,包括2层具有16个3*3的卷积核,每个卷积核步长为1的卷积层;2个具有3*3区域的最大池化层;2个批归一化层。最终输出的隐含表示矩阵记为
具体而言,如图2所示,在这一步骤中,本发明的一个实施例使用一个预训练的语言模型BERT将用于从原始文本中学习隐含的文本表示,输出一个隐含文本表示矩阵,记为
具体而言,如图2所示,在这一步骤中,本发明的一个实施例使用一个音频-文本跨模态注意力网络,对音频特征和文本特征的关联进行建模。首先,音频特征作为输入的查询,文本特征作为键和值,输出基于音频增强的文本表示。在每一个注意力头中,输出的表示
其中
其中
进一步地,在本发明的一个实施例中,步骤6)包括:对音频表示进行池化,对文本表示进行池化,对模态表示进行池化。
具体而言,如图2所示,在这一步骤中,本发明实施例首先使用一个注意力网络对音频模态进行池化,得到音频模态表示r
r
其中q
r
其中q
α=σ(w
r=αr
其中w是参数。
具体而言,如图2所示,在这一步骤中,分类的概率计算如下:
其中W和b是参数。
具体而言,如图2所示,在这一步骤中,损失函数计算为:
其中y
附图说明
图1为本发明提出一种基于智能语音问答的跨模态抑郁症检测方法的整体流程图;
图2为本发明提出一种基于智能语音问答的跨模态抑郁症检测方法的工作原理图;
图3为本发明提出一种基于智能语音问答的跨模态抑郁症检测方法图2的部分翻译示意图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和实施例对本发明做进一步说明。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用不同于在此描述的其他方式来实施,因此,本发明并不限于下面公开说明书的具体实施例的限制。
实施例1,如图1-2所示,本发明提供了一种基于智能语音问答的跨模态抑郁症检测方法,
1)用户通过语音作答与兴趣、情绪、自杀倾向等抑郁症相关的18个问题。对用户回答的语音进行预处理包括编码和降噪和语音识别,得到预处理好的回答音频和回答问题的文本;
2)对步骤1)预处理完毕的音频抽取音频局部和全局特征,建模音频语调和韵律特性;
进一步地,在本发明的一个实施例中,步骤2)包括:从每帧中提取诸如音调和能量之类的局部特征,和从一句话中提取的所有语音特征的统计结果的全局特征。
正常人与抑郁症患者在语音特性上有明显区别。正常人说话时,情感较为丰富,音调也随着情绪变化起伏,听起来抑扬顿挫的感觉清晰而明显;抑郁症患者说话时,情感比较平淡,以负面情绪居多,语气听起来模糊而平淡,体现出患者的无力感与虚无感。这些语言行为可通过多种语音特征表示,如韵律特征、频谱特征、声音质量特征。
本发明实施中提取的局部特征包括帧长、响度、能量、过零率等韵律特征,基频、LPC、LSP、MFCC等频谱特征,频率微扰、振幅微扰、共振峰及其频带等声音质量特征。其中,短时特征以帧长20ms,帧移10ms对音频信号分帧,再通过汉明窗,接着通过FFT变换得到频域值,然后通过自相关函数(ACF)得到基音周期等30维短时特征。由于每个人针对每个问题的回答时长不同,因此每句话的帧数不同,所有话的帧数在300帧到1400帧之间。MFCC的提取是将音频文件分帧后,对语音高频部分进行预加重,增加语音的高频分辨率,再依次进行加窗、FFT变换和梅尔倒谱分析,即可得到13个梅尔倒谱系数。LPC的提取需要经过线性预测编码得到,同时从每帧中提取出LSP。对短时特征MFCC、LPC和LSP进行平滑处理和一阶导数运算,得到29个短时Delta特征。对MFCC进行二次求导运算,得到13个短时特征。因此,关于MFCC、LPC和LSP,共有71维短时特征。从音频模态,共提取了101维短时特征。
将提取出的局部特征值经过7个统计函数可得到全局特征,即通过最大值函数、最小值函数、平均值函数、峰度函数、偏度函数、中位数函数、标准差函数。此时,可从每个音频文件中提取出707维全局特征。
3)对音频特征应用卷积神经网络,得到用户回答的音频的上下文表示;
进一步地,在本发明的一个实施例中,步骤3)包括:使用一个二维多层卷积神经网络,学习音频特征的隐含表示。
具体而言,如图2所示,在这一步骤中,一个二维多层的卷积神经网络(CNN)用于从原始语音特征中提取抽象的隐含语音规律。该CNN的架构从下而上,包括2层具有16个3*3的卷积核,每个卷积核步长为1的卷积层;2个具有3*3区域的最大池化层;2个批归一化层。最终输出的隐含表示矩阵记为
4)对步骤1)语音识别完毕的回答文本应用语言模型,获取回答文本的上下文表示;
具体而言,如图2所示,在这一步骤中,本发明的一个实施例使用一个预训练的语言模型BERT将用于从原始文本中学习隐含的文本表示,输出一个隐含文本表示矩阵,记为
5)对音频和文本表示进行音频-文本跨模态交互建模,获得跨模态音频和文本表示;
具体而言,如图2所示,在这一步骤中,本发明的一个实施例使用一个音频-文本跨模态注意力网络,对音频特征和文本特征的关联进行建模。首先,音频特征作为输入的查询,文本特征作为键和值,输出基于音频增强的文本表示。在每一个注意力头中,输出的表示
其中
其中
6)对跨模态音频和文本表示进行池化得到用户的表示;
进一步地,在本发明的一个实施例中,步骤6)包括:对音频表示进行池化,对文本表示进行池化,对模态表示进行池化。
具体而言,如图2所示,在这一步骤中,本发明实施例首先使用一个注意力网络对音频模态进行池化,得到音频模态表示r
r
其中q
r
其中q
α=σ(w
r=αr
其中w是参数。
7)基于用户的表示进行解码,得到预测的抑郁检测分类概率分数,并利用softmax函数对分类概率归一化;
具体而言,如图2所示,在这一步骤中,分类的概率计算如下:
其中W和b是参数。
8)根据标签得到抑郁检测分类损失函数,对抑郁检测的损失函数进行优化,得到最终的抑郁检测结果。
具体而言,如图2所示,在这一步骤中,损失函数计算为:
其中y
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例应用于其它领域,但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
- 一种基于智能语音问答的跨模态抑郁症检测方法
- 一种基于开放性问答文本的抑郁症辅助检测方法