移动终端设备用的轻量化目标跟踪算法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明属于计算机视觉技术领域,具体涉及移动终端设备用的轻量化跟踪算法。
背景技术
目标跟踪作为计算机视觉图像处理方向热门的研究课题之一,能够广泛的应用在交通、监控、安防、机器人、动画制作等领域。传统的跟踪算法的优势是模型成熟、简单而且便于部署,但是它们普遍在跟踪的精度上表现差、实时性差,不能应对各类跟踪常见的问题与挑战。随着芯片技术的发展,计算设备的算力增强,深度学习的神经网络兴起。深度学习网络在目标跟踪的应用拥有相较于传统算法与相关滤波更优秀的跟踪精度。研究目标跟踪的拥有很高的实用价值和发展前景,因此也有很多研究人员在跟踪算法的深度学习领域进行优化与研究。
应用在跟踪算法的深度学习网络常用的结构是孪生网络,它的具体实现是将第一帧的图片与后续帧图片同时输入到网络中,其中第一帧的图片用作模板持续输入。通过两者之间的对比,在后续帧图片中找出与模板中选定目标相似度最高的区域作为跟踪目标的bounding_box。孪生网络匹配的越准确,跟踪网络的准确性就越高。近些年来,跟踪算法更新曾不出穷。各种算法的更新迭代的目的是将目标跟踪的精度、准确性提高以及更好的应对目标物体被遮挡、光照变化、形变、运动模糊、出视野等问题。然而,准确度的提升往往需要网络结构更加复杂,这样就不便于跟踪算法在算力受到限制的移动边缘设备端的部署。因此,设计一个运算量与参数量小、算力要求小的跟踪网络才能够满足上述需求。另外,为了解决初始化跟踪目标需要人工框选的痛点,设计一个能够自动初始化的目标跟踪系统能够极大的提高跟踪网络的实用性。
发明内容
本发明的目的在于提供一种算法复杂度低、算力需求小的移动终端设备用的轻量化跟踪算法,以解决单目标跟踪算法部署移动设备的难点问题。
本发明提供的移动终端设备用的轻量化跟踪算法,使用预训练好的且复杂度能够适应移动终端设备的检测模型对需要处理的视频中待跟踪的目标进行目标检测,实时且高精度提供一个初始化的框定目标;然后在跟踪网络中,使用经过轻量化处理的孪生网络将初始对象与视频后续帧的图像进行特征提取和特征匹配,找出匹配程度最高的位置作为预测目标的位置;具体步骤为:
步骤1:预先训练好对指定类别的目标进行检测的模型,将该检测模型部署到移动设备端;
步骤2:初始化跟踪目标的检测;使用步骤1训练好的模型检测视频流中的待跟踪目标,将检测到的所有可能的目标中选择置信度最高的目标作为初始化跟踪的目标,完成初始帧框定目标的任务;
步骤3:视频流的目标跟踪;将步骤2在初始帧框定的目标与下一帧的图像置入目标跟踪的孪生网络(也称跟踪网络)中进行特征提取与匹配,选取匹配度最高的位置作为预测的目标位置;重复步骤3完成后续视频流的目标跟踪。
进一步地,步骤1中,所述预训练对指定类别目标进行检测的模型,具体步骤为:
步骤1.1:准备好需要跟踪的目标物体类别的图像数据,整理成为数据集、标注好每张图像数据中感兴趣目标的具体位置和区域,并生成标签文本文件;
步骤1.2:使用标注好标签的数据集训练检测网络,所述检测网络是在YOLO基础上将主干网络改为轻量化的Shuffle Net 的网络;在输入图片后,在主干网络部分采用四层卷积神经网络的Shuffle Net,四层卷积网络的输入通道数分别为24,116,232和464个;在后面三层的卷积网络中加入FPN与PAN联合的特征金字塔网络;在采样过程中采用双线性插值的方式而不是pooling,能够有效的减小特征提取网络的计算量,FPN网络将高层次网络的语义信息上采样不断传递到低层的网络,PAN网络将低层次网络的语义信息下采样传递到高层的网络中,两者互为补充,将不同层次网络间的信息融合起来,增强网络的目标定位信息;因为单阶段的检测网络中,预测的结果box大部分属于负样本,只有少部分属于正样本,且定位的质量与分类的具体得分都会对模型的训练造成影响,为了规避以上问题导致的训练模型精确度低的问题,损失函数部分使用Generalized Focal Loss(GFL),公式在(1)给出;检测网络的输出部分包括:定位框box,回归前背景信息regression以及类别class信息;
其中,
步骤1.3:对检测网络进行性能评估,选取检测精度最优秀的网络作为后续部署的检测算法使用;训练结束的网络能够较好的实现相关目标的检测功能。
进一步,步骤2中,所述初始化跟踪目标的检测,具体过程为:
步骤2.1:将视频流的第一帧图像传入检测网络中;
步骤2.2:检测网络从输入图像中进行特征提取、特征匹配,从而进行目标的检测;
步骤2.3:将第一帧的图像中的待跟踪目标框选出来,返回目标物体的左上角坐标信息(x, y)以及目标物体的框选的宽与高(h, w),传递给步骤3的跟踪网络;
步骤2.4:如果目标检测预测失败,就持续的重复上述步骤2.2,直到有目标出现为止。
进一步,步骤3中,所述视频流的目标跟踪,具体过程为:
步骤3.1:将孪生网络基础上的LightTrack目标跟踪网络进行主干网络的改进实现目标跟踪网络的轻量化(即作为跟踪网络);具体来说,输入尺寸256*256,通道数为3 的图片,在主干网络中使用六层卷积网络,使用逆向残差网络(Inverted Residual Blocks)结构、深度可分离卷积(Depth-wise Separable Convolutions)以及Mobile net V2(简称为MBConv)卷积模块作为核心模块,第一层使用3*3卷积,第二层使用深度可分离卷积,后面四层均使用MBConv卷积模块;在主干网络的后面引入注意力机制模块,这里的注意力机制模块包括通道注意力机制以及空间注意力机制;其中:
通道注意力机制的实现过程是:将每一层的特征分别进行全局平均池化和全局最大池化,使用共享的全连接层处理两个池化的结果并相加,然后取sigmoid获得输入特征层的每个通道的权值(在0~1之间),最后这个权值与原来的输入特征层相乘;
空间注意力机制的实现过程是:将每一个输入特征层的所有特征点的通道上取最大值和平均值,将两个结果堆叠在一起并通过一个1*1的卷积层重新调整通道数,随后取sigmoid获得特征点的权值(在0~1之间),再与原输入特征层相乘,引入注意力机制能够更加突出重要的特征;
在预测头网络中,使用三层卷积网络,第一层和第二层使用深度可分离卷积模块,第三层使用3*3的卷积模块;在分类头网络中,与预测头的网络结构相似,整体的预测头网络进行前背景的预测输出,分类头网络进行目标位置信息的预测输出;
步骤3.2:在上述基础上,在训练阶段,首先使用Image NET预训练一个主干网络;
步骤3.3:使用常用的跟踪数据集,包括COCO、GOT-10K、Image NET DET等,训练头网络与主干网络,使用神经网络结构搜索方式找到最优秀的跟踪网络结构;
步骤3.4:将步骤2检测到的待跟踪目标作为跟踪网络的初始化的跟踪对象,它与视频流后续帧的图片一同作为跟踪网络的输入,进行特征提取;
步骤3.5:完成两个输入部分的特征匹配,取得分最高的预测结果作为后续帧图像中跟踪目标的位置预测。
本发明利用优化的轻量级目标检测网络提供初始帧图像目标的检测与识别功能,实现了目标跟踪网络初始帧自动化提供的功能,使用优化的一种孪生跟踪网络,提供了一个能够应用在移动终端设备的轻量化目标跟踪算法。该轻量化的跟踪算法相较于其他算法,在精度上有比较好的表现,能够应对目标跟踪常见的一些挑战:形变、反转、角度变化、遮挡等,在长时跟踪的表现也比较优秀,最重要的是降低了网络模型的参数量与计算力,从而实现了跟踪模型的轻量化,更有利于部署在计算力受限制的移动边缘设备端。在本发明与其他一些性能优秀的跟踪算法在Got10k数据集的对比中,得到相近的甚至更高的跟踪精度(本发明精度约为0.613),但是参数量约为2M,计算量FLOPs越为530M,远小于其他跟踪算法;因此本发明在算力紧张的移动边缘设备上更易部署并且跟踪精度可以得到保障。
附图说明
图1为本发明提供的目标跟踪算法整体的流程示意图。
图2为本发明提供的检测算法的流程示意图。
图3为本发明提供的跟踪算法的流程示意图。
具体实施方式
下面将结合实施例和附图,对本发明技术方案作进一步描述。
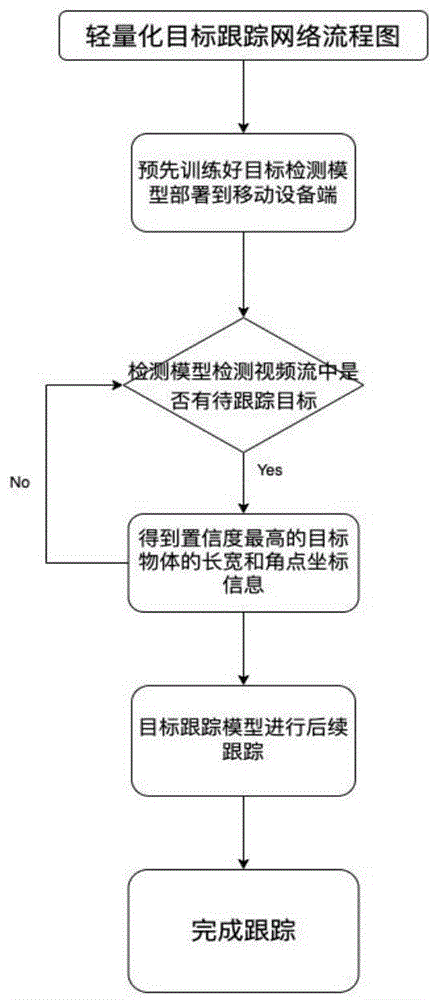
图1为本发明提供的目标跟踪算法整体的流程示意图。如图1所示,本提供了一种应用在移动终端设备上的轻量化目标跟踪算法,具体步骤为:
步骤1:预先训练好的对指定类别的目标进行分类和检测的模型部署到移动设备端。
具体操作步骤:准备好需要跟踪的目标物体类别的图像数据,整理成为数据集、使用图像标注工具labelme标注好每张图像数据中感兴趣目标的具体位置和区域并生成标签文本文件,生成每个图像数据的类别,左上角坐标点(x, y)和长宽信息(w, h); 再使用标注好标签的数据集训练目标检测网络,使用的目标检测网络是在YOLO基础上将主干网络改为轻量化的Shuffle Net 的网络,使用Shuffle Net作为主干网络的目的是减小检测网络模型的复杂度,更有利于部署在移动设备端;对检测网络进行性能评估选取检测精度最优秀的网络作为后续部署的检测算法使用。训练结束的网络能够较好的实现相关目标的检测功能。
步骤2:使用步骤1训练好的检测模型检测视频流中的待跟踪目标,将检测到的所有可能的目标中选择置信度最高的目标作为初始化跟踪的目标,置信度越高代表网络模型检测到的目标是待跟踪目标的准确性越高,通过置信度的筛选完成初始帧框定目标的任务;具体操作步骤:
将视频流的第一帧图像传入检测网络中,在图像中检测是否有感兴趣的目标;预训练好的检测模型学习了需要跟踪目标的特征,因此能够从输入图像中进行特征提取,特征匹配从而进行目标的检测;将第一帧的图像中检测模型预测的待跟踪目标框选出来,按照置信度排名最高的目标,返回该目标物体的左上角坐标信息(x, y)以及目标物体的框选的宽与高(h, w)传递给步骤3的跟踪网络;如果在第一帧目标检测失败,也就是没有预测出待跟踪目标或者检测出的目标置信度过低,则持续性重复上述检测部分直到有符合需求的目标被检测出为止。
步骤3:将步骤2在初始帧框定的目标与下一帧的图像置入目标跟踪的孪生网络中进行特征提取与匹配,选取匹配度最高的位置作为预测的目标位置,重复步骤3完成后续视频流的跟踪。具体操作步骤:
首先将孪生网络基础上的LightTrack目标跟踪网络进行主干网络的改进,实现目标跟踪网络的轻量化。具体来说,主干网络的具体结构共有六层卷积网络,使用逆向残差网络(Inverted Residual Blocks)结构、深度可分离卷积(Depth-wise SeparableConvolutions)以及Mobile net V2(简称为MBConv)卷积模块作为核心模块,第一层使用3*3卷积,第二层使用深度可分离卷积,后面四层均使用MBConv卷积模块;
在主干网络的后面引入注意力机制模块,这里的注意力机制模块包括通道注意力机制以及空间注意力机制;其中:
通道注意力机制的实现过程是:将每一层的特征分别进行全局平均池化和全局最大池化,使用共享的全连接层处理两个池化的结果并相加,然后取sigmoid获得输入特征层的每个通道的权值(在0~1之间),最后这个权值与原来的输入特征层相乘;
空间注意力机制的实现过程是:将每一个输入特征层的所有特征点的通道上取最大值和平均值,将两个结果堆叠在一起并通过一个1*1的卷积层重新调整通道数,随后取sigmoid获得特征点的权值(在0~1之间),再与原输入特征层相乘,引入注意力机制能够更加突出重要的特征;
在预测头网络中,使用三层卷积网络,第一层和第二层使用深度可分离卷积模块,第三层使用3*3的卷积模块;在分类头网络中,与预测头的网络结构相似,整体的预测头网络进行前背景的预测输出,分类头网络进行目标位置信息的预测输出,将上述的跟踪模型整体进一步压缩使其参数量和运算量更小。
在上述网络结构上,训练阶段首先使用Image NET预训练一个主干网络,具体参数包括图像尺寸选择3*256*256,图像类别1000类,图像crop比例为0.875,特征个数1280个等;再使用了常用的跟踪数据集,包括COCO、GOT-10K、Image NET DET等训练头网络与主干网络,使用神经网络结构搜索方式找到最优秀的跟踪网络结构,跟踪网络的具体参数包括搜索区域尺寸256,模板尺寸为128,步长16,最大搜索网络模型计算量FLOPs控制在470M,参数量在2M以内;将步骤2检测到的待跟踪目标作为跟踪网络的初始化的跟踪对象,它与视频流后续帧的图片一同作为跟踪网络的输入,进行特征提取;在孪生网络的跟踪模型中完成两个输入部分的特征匹配,取得分最高的预测结果作为后续帧图像中跟踪目标的位置预测。在后续帧图像中重复与模板进行网络预测,作后续的跟踪预测。
实际部署在移动设备端时:使用android studio作为手机端APP的开发工具,使用ncnn作为移动端算法部署的工具将网络模型转化成移动端模型,使用该工具的原因是NCNN框架,不仅是一个为手机端极致优化的高性能神经网络前向计算框架,而且无第三方依赖,跨平台,手机端cpu处理算法的速度快于目前所有已知的开源框架。实际部署的移动端APP拥有较好的跟踪精度和稳定性。