一种基于日志采集事件的故障告警治理方法
文献发布时间:2024-01-17 01:21:27
技术领域
本发明属于计算机技术领域,具体涉及一种基于日志采集事件的故障告警治理方法。
背景技术
在微服务架构体系中,由于大量的服务分散在各处,当用户操作发生故障时,往往不能及时发现问题,更多的是等待用户投诉,才能着手排查故障点。而排查故障点,往往也需要耗费大量的人力和时间去每个系统准一排查,整个流程排查下来,用户已经失去信心。
针对以上问题,行业中大多基于旁路推送或分析日志异常堆栈的方式,通过采集问题事件进行告警推送。这种方式带来的结果则是,每天都有成千上万个告警消息推送,这种大量的告警消息,既包含了有效告警事件,也包含了大量无效的告警事件,精准降噪粒度不够,开发人员无法及时跟进发现真正的问题事件;告警后无法获取当时请求的上下文参数信息,从而增加解决问题难度;拦截并主动推送事件的方式,会大幅度增加接口调用耗时,剩至可能出现阻塞情况;相同异常事件的识别精准度不高,可能造成相近代码块事件误识别情况。
而本发明则是基于以上日志收集告警的方式,从前期的事件源采样降噪到后期的日志深度分析识别有效事件,都做了全流程的优化,大幅提升了最终推送出有效的告警事件的准确率,并提供快捷辅助功能,实现直接定位所有相关的上下文参数信息,从而提升问题分析的效率。
发明内容
本发明要解决的技术问题是:提供一种基于日志采集事件的故障告警治理方法,解决了现有日志收集告警排查故障点处理噪点高、效率低的技术问题。
为实现上述目的,本发明采用的技术方案如下:
一种基于日志采集事件的故障告警治理方法,所述故障告警治理方法包括以下步骤:
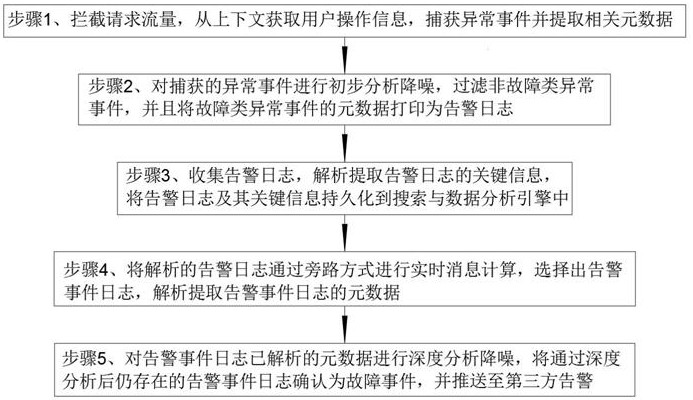
步骤1、拦截请求流量,从上下文获取用户操作信息,捕获异常事件并提取相关元数据;所述异常事件的元数据包括但不限于异常信息的异常类型、错误码、错误描述信息、异常堆栈内容、异常堆栈签名和定义事件类型;
步骤2、对捕获的异常事件进行初步分析降噪,过滤非故障类异常事件,并且将故障类异常事件的元数据打印为告警日志;
步骤3、收集告警日志,解析提取告警日志的关键信息,将告警日志及其关键信息持久化到搜索与数据分析引擎中;
步骤4、将解析的告警日志通过旁路方式进行实时消息计算,选择出告警事件日志,解析提取告警事件日志的元数据;
步骤5、对告警事件日志已解析的元数据进行深度分析降噪,将通过深度分析后仍存在的告警事件日志确认为故障事件,并推送至第三方告警。
进一步地,所述步骤1还包括基于异常事件的元数据,判定多个异常事件是否为相同异常,所述判定通过异常堆栈提取关键行作为异常签名进行判定;
所述判定的方法为:步骤a1、从异常代码提取包含1行异常类型、1行框架或第三方调用位置、以及三行业务堆栈的五行关键行;步骤a2、将五行关键行的异常信息进行字符串拼接,然后进行MD5算法签名计算得出一个32位的字符串,作为异常签名;步骤a3、当两个或多个异常事件的异常签名值相等,则视为相同异常。
进一步地,所述步骤5的深度分析降噪包括基于全链路ID标记进行同一请求的多事件源降噪、基于异常签名在固定时间窗内重复告警降噪、固定发布时间窗口内的抖动告警时间自动降噪、以及基于一段时间窗内告警数量超过指定阈值则视为重大故障风险识别。
进一步地,所述基于全链路ID标记进行同一请求的多事件源降噪的方法为:步骤b1、提取告警事件日志的全链路ID,将全链路ID作为Redis的分布式锁的唯一标识;步骤b2、设置分布式锁的第一过期时间,在第一过期时间内进行加锁;步骤b3、加锁成功,则将该告警事件日志视为同一请求的第一个故障事件,直接推送第三方告警;反之,加锁失败,则视为同一个请求的重复故障事件,直接忽略。
进一步地,所述基于异常签名在固定时间窗内重复告警降噪的方法为:步骤c1、参照步骤a1,计算告警事件日志的异常签名、提取异常签名ID,将异常签名ID作为Redis的分布式锁的唯一标识;步骤c2、设置分布式锁的第二过期时间,在第二过期时间内进行加锁;步骤c3、加锁成功,则将该告警事件日志视为同一个故障问题在固定时间窗内的第一个故障事件,直接推送第三方告警;反之,加锁失败,则视为同一个故障问题在固定时间窗内的重复故障事件,直接忽略。
进一步地,所述固定发布时间窗口内的抖动告警时间自动降噪的方法为:步骤d1、在后端应用服务发布时间窗内,根据应用ID和告警事件日志元数据的事件类型,检查该应用是否存在于发布时间窗内;步骤d2、存在则直接忽略该告警事件,反之则视为正常的故障事件,直接推送第三方告警。
进一步地,所述基于一段时间窗内告警数量超过指定阈值则视为重大故障风险识别的方法为:步骤e1、使用Redis客服端中的分布式限流器,设置限流时间内的可用令牌数位;步骤e2、获取可用令牌,获取成功,直接忽略该告警事件日志;反之,获取失败,则将该告警事件日志视为故障事件,并推送至第三方告警。
进一步地,在所述步骤2中,采用错误码号段的方式进行异常事件的初步降噪,过滤错误码号段内的非故障类异常事件。
进一步地,所述步骤3包括:采用ELK方式收集告警日志,并存入搜索与数据分析引擎中用于后续日志快速检索;部署日志托运工具进行告警日志采集并发往Kafka,使用服务端数据处理管道进行告警日志解析,提取出关键信息同时存入搜索与数据分析引擎中用于后续日志的快捷搜索。
进一步地,所述步骤4包括:将解析的告警日志消息发送至Kafka中,使用Flink进行实时消息计算,通过关键词匹配过滤出告警消息并提取出告警元数据;基于告警消息过滤选择出告警事件日志;将告警事件日志的元数据进行反序列化为告警元数据模型。
与现有技术相比,本发明具有以下有益效果:
本发明基于日志收集告警的方式,从前期事件源采样到后期日志深度分析识别有效事件,进行了全流程优化,以此实现推送有效告警事件,并提供快捷辅助功能,帮助值班人员直接定位所有相关的上下文参数信息,从而提升问题分析的效率。
附图说明
图1为本发明的方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进一步详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
术语解释:
MD5:是指信息摘要算法;
全链路ID:是在分布式系统中,跨越多个服务节点的一次请求所对应的唯一标识符;
Redis:是一种高性能的NoSQL数据库;
FELK:是一种日志收集存储与检索的解决方案;
Kafka:是一种分布式的消息发布/订阅中间件;
Flink:是一种开源实时计算的处理框架。
如图1所示,本发明提供的一种基于日志采集事件的故障告警治理方法,包括以下步骤:
步骤1、拦截请求流量,从上下文获取用户操作信息,捕获异常事件并提取相关元数据;所述异常事件的元数据包括但不限于异常信息的异常类型、错误码、错误描述信息、异常堆栈内容、异常堆栈签名和定义事件类型;
步骤2、对捕获的异常事件进行初步分析降噪,过滤非故障类异常事件,并且将故障类异常事件的元数据打印为告警日志;
步骤3、收集告警日志,解析提取告警日志的关键信息,将告警日志及其关键信息持久化到搜索与数据分析引擎中;
步骤4、将解析的告警日志通过旁路方式进行实时消息计算,选择出告警事件日志,解析提取告警事件日志的元数据;
步骤5、对告警事件日志已解析的元数据进行深度分析降噪,将通过深度分析后仍存在的告警事件日志确认为故障事件,并推送至第三方告警。
后端常使用的框架、中间件和公共组件等框架,大部分都会留有扩展接口。因此在步骤1中,本发明基于其扩展接口,拦截对应的请求流量;然后针对拦截的流量进行异常捕获,捕获后根据异常信息进行提取相关元数据信息,如:异常类型、错误码、错误描述信息、异常堆栈内容、异常堆栈签名(提取关键业务信息作为异常签名)和定义事件类型等等。同时针对当前请求,获取用户操作信息,如:操作接口地址(URL或Dubbo接口)、接口描述信息、操作用户ID、操作用户名、所属公司ID、所属公司名称等信息,可根据实际情况按需提取。所述用户操作信息用于后续告警故障的快速定位。
在部分实施例中,所述步骤1还包括基于异常事件的元数据,判定多个异常事件是否为相同异常,所述判定通过异常堆栈提取关键行作为异常签名进行判定。
在程序运行的过程中,当代码出现异常时,系统会自动生成一份异常信息,其异常信息主要包括调用栈中的每个调用方法名称、所属类名和行号等信息,同时抛异常的代码位置也会抛出对应的异常类型和描述信息等。在抛出的大量异常堆栈行中(少则几十行,多则几百行),如果直接将整个堆栈进行MD5算法签名,则无法识别出异常问题是否相同,如:同一行代码抛出空指针,但上游调用的位置不同,则抛出的调用栈也有差异,所以进行MD5计算后的签名值也不一致。
针对当前系统中的业务代码,为了识别出相同故障异常,本发明通过从异常堆栈字符串中提取业务代码抛错位置相关的代码信息,进行MD5加密后作为异常签名,进行多个异常事件相同异常的判定。具体为:采用从抛异常的代码位置(可能是业务代码、第三方包中的内部代码或自定义框架包中的代码)从上到下逐一遍历异常堆栈,并按可配置化的方式逐一匹配每一行堆栈行字符串。如果发现本行是指定包名路径前缀(一般采用每个系统业务代码的包路径作为规则进行匹配,需要排除公司的框架包路径,防止出现干扰;亦可自定义配置用于满足个性化场景的适配使用)的堆栈行,则视为待计算签名因子。按照所述方式识别提取出包含业务系统包路径的3行堆栈行;然后再从这三行的第一行向上提取出一行不包含业务代码包路径的堆栈行,用于作为框架或第三方包的调用代码位置;并结合抛出的异常类型(一般是整个堆栈的第一行)。将以上提取的五行关键行(包含一行异常类型、一行框架或第三方调用位置、以及三行业务堆栈)的异常信息进行字符串拼接,然后进行MD5算法签名计算得出一个32位的字符串,作为异常签名;当两个或多个异常事件的异常签名值相等,则视为相同异常。
针对后端JAVA项目,当遇到业务中断场景时,开发人员常用抛异常的方式来结束请求。场景的业务中断类异常如:账号不存在、密码错误、消费券已过期等,这类异常主要用于提醒用户:你的操作方式、状态未达到或输入信息不正确等。因此开发人员常采用抛异常的方式来中断业务场景,这类异常事件即为噪点事件,也叫做非故障类异常事件,并不是真正的故障信息。所以可以采用定义错误码号段的方式进行区分,例如错误码号段为1000~1999:表示框架系统错误码号段,错误码号段为2000~2999:表示业务提醒类错误码号段,错误码号段为3000~3999:表示业务异常类错误码号段。每个业务系统定义或自定义的错误码规范不同,但只要能识别出哪些错误码是不需要告警的即可,如请求参数不合理导致抛异常和业务状态未满足导致抛异常等情况。为此,本发明所述步骤2中,采用错误码号段的方式进行异常事件的初步降噪,过滤错误码号段内的非故障类异常事件,得到故障类异常事件(有效故障类异常事件)。以错误码号段的分析规则进行初步降噪,将未命中规则视为需要告警,直接将上述收集到的元数据信息使用JSON格式打印一行告警日志即可。
在部分实施例中,所述步骤3包括:采用ELK方式收集告警日志,并存入搜索与数据分析引擎(Elasticsearch)中用于后续日志快速检索;部署日志托运工具(Filebeat)进行告警日志采集并发往Kafka,使用服务端数据处理管道(Logstash)进行告警日志解析,提取出关键信息(包括日志时间、日志级别、所属应用ID、操作用户ID、全链路ID、线程ID、日志所属类及方法、告警元数据信息等)同时存入搜索与数据分析引擎中(Elasticsearch)用于后续日志的快捷搜索。
在部分实施例中,所述步骤4包括:将解析的告警日志消息发送至Kafka中,使用Flink进行实时消息计算,通过关键词匹配过滤出告警消息并提取出告警元数据;基于告警消息过滤选择出告警事件日志;将告警事件日志的元数据进行反序列化为告警元数据模型。在步骤3的服务端数据处理管道(Logstash)层后,再次架设一层Kafka,用于把Logstash初步解析后的日志行消息发送至Kafka中,然后使用Flink进行实时消息计算,选择告警事件日志,其余日志抛弃,达到一个日志过滤的作用,同时将告警事件日志中的元数据信息进行解析,提取出错误码、事件类型、事件级别、事件名称、事件KEY、描述信息、扩展参数、业务签名KEY、业务签名ID、请求IP、请求URI、用户ID、用户姓名、登录账号和业务错误堆栈等,并传入告警中心进行深度分析降噪。其中,事件KEY指的是事件名称对应的英文标记值,用于关键词匹配;业务签名KEY指的是故障告警事件的关键摘要信息对应的签名值(如MD5加密后的值)。
在部分实施例中,所述步骤5的深度分析降噪包括基于全链路ID标记进行同一请求的多事件源降噪、基于异常签名在固定时间窗内重复告警降噪、固定发布时间窗口内的抖动告警时间自动降噪、以及基于一段时间窗内告警数量超过指定阈值则视为重大故障风险识别。本发明采用上述不同降噪规则,对不同场景下的故障进行选择性分析。
场景1,一个请求抛异常可能触发N个事件源(HTTP拦截抛异常、Dubbo调用抛异常、MQ发送抛异常和数据库SQL执行抛异常等等)。在微服务系统中,一般会采用全链路追踪系统对单次请求的所有日志进行统一打标记,然后可用该标记识别出某一次请求的所有日志内容,而TID则是Skywalking中的全链路ID标记。作为优选,所述基于全链路ID标记(TID)进行同一请求的多事件源降噪的方法为:步骤b1、提取告警事件日志的全链路ID(TID),将全链路ID(TID)作为Redis的分布式锁的唯一标识;步骤b2、设置分布式锁的第一过期时间(例如设定为20秒),在第一过期时间内进行加锁;步骤b3、加锁成功,则将该告警事件日志视为同一请求的第一个故障事件,直接推送第三方告警;反之,加锁失败,则视为同一个请求的重复故障事件,直接忽略。
场景2,针对同一个代码问题(相同代码位置抛出相同的异常信息),当出现故障时,用户往往会反复点击尝试,又或者是一部分用户都在该节点同时遇到该问题,则会导致短时间内同一个问题,会出现大量的反复告警,这部分告警如果不进行治理降噪处理,则会严重干扰开发人员识别故障风险,同时也会增加开发人员问题排查的难度。因此,在推送故障告警之前,进行统一拦截,根据异常签名ID在固定时间窗内重复告警降噪。作为优选,所述基于异常签名在固定时间窗内重复告警降噪的方法为:步骤c1、参照上述多个异常事件相同异常的判定方法中异常签名的计算,得到告警事件日志的异常签名、提取异常签名ID,将异常签名ID作为Redis的分布式锁Key;步骤c2、设置分布式锁的第二过期时间,在第二过期时间内进行加锁;步骤c3、加锁成功,则将该告警事件日志视为同一个故障问题在固定时间窗内的第一个故障事件,直接推送第三方告警;反之,加锁失败,则视为同一个故障问题在固定时间窗内的重复故障事件,直接忽略。
场景3,针对有固定的服务发布时间窗情况下,后端服务发布上线,往往会有停机发版,或者发布服务在注册中心有一个过期摘除的时间(一般为几秒至一分钟),该时间内如果有流量持续进入,流量较大时,则会出现大量的调用超时或异常等告警信息推送。针对后端应用服务发版时,通过Hook挂钩回调触发通知深度降噪服务,会自动将挂钩传输过来的应用告警进行一段时间内屏蔽。使用Hook挂钩通知传输的应用ID作为缓存KEY进行缓存1个小时。其中,缓存KEY指在使用分布式缓存时的唯一标识。作为优选,所述固定发布时间窗口内的抖动告警时间自动降噪的方法为:步骤d1、在后端应用服务发布时间窗内,根据应用ID和告警事件日志元数据的事件类型,检查该应用是否存在于发布时间窗内;步骤d2、存在则直接忽略该告警事件,反之则视为正常的故障事件,直接推送第三方告警。
场景4,当一段时间内告警速率过快,极大概率是整个系统发生了较大的故障问题,需要重点关注。作为优选,所述基于一段时间窗内告警数量超过指定阈值则视为重大故障风险识别的方法为:步骤e1、使用Redis客服端(Redisson)中的RRateLimiter作为分布式限流器,设置限流时间内的可用令牌数(例如设置5分钟内可用令牌数为200个);步骤e2、告警消息到达深度降噪服务时,获取可用令牌,获取成功,则视为告警速速率未超过指定阈值,直接忽略该告警事件日志;反之,获取失败,则将该告警事件日志视为故障事件,并推送至第三方告警。当识别为重大故障风险时,即时通过发送短信、发送个人钉钉消息等方式来及时告诉值班人员,从而提前解决或规避故障问题。
最后应说明的是:以上各实施例仅仅为本发明的较优实施例用以说明本发明的技术方案,而非对其限制,当然更不是限制本发明的专利范围;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围;也就是说,但凡在本发明的主体设计思想和精神上作出的毫无实质意义的改动或润色,其所解决的技术问题仍然与本发明一致的,均应当包含在本发明的保护范围之内;另外,将本发明的技术方案直接或间接的运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。