虚拟对象的识别方法、装置、设备、介质及程序产品
文献发布时间:2024-04-18 19:58:30
技术领域
本申请实施例涉及虚拟环境领域,特别涉及一种虚拟对象的识别方法、装置、设备、介质及程序产品。
背景技术
在游戏领域,经常需要对游戏内的虚拟对象进行识别。
相关技术中,采用帧差法检测游戏内的虚拟对象。在相邻两帧图像中,图像的背景部分移动缓慢,虚拟对象的移动速度较快,通过将后一帧图像与前一帧图像做差值,即可检测出虚拟对象。
然而,当相邻两帧图像中同时存在多个虚拟对象时,相关技术仅能检测出存在多个虚拟对象,无法对多个虚拟对象进行区分,即无法将后一帧图像的多个虚拟对象与前一帧图像的多个虚拟对象进行一一对应。
发明内容
本申请提供了一种虚拟对象的识别方法、装置、设备、介质及程序产品,不仅支持识别同一虚拟对象,还可确定出同一虚拟对象的移动轨迹。所述技术方案如下:
根据本申请的一方面,提供了一种虚拟对象的识别方法,所述方法包括:
在基于虚拟环境的视频流中获取第一图像;基于第一图像的频域信息,在第一图像内标记出第一区域,第一区域对应有第一虚拟对象;
在基于虚拟环境的视频流中获取第二图像;基于第二图像的频域信息,在第二图像内标记出第二区域,第二区域对应有第二虚拟对象;
基于第一区域和第二区域的图像特征,确定第一虚拟对象和第二虚拟对象为同一虚拟对象。
根据本申请的另一方面,提供了一种虚拟对象的识别装置,所述装置包括:
获取模块,用于在基于虚拟环境的视频流中获取第一图像;
标记模块,用于基于第一图像的频域信息,在第一图像内标记出第一区域,第一区域对应有第一虚拟对象;
获取模块,还用于在基于虚拟环境的视频流中获取第二图像;
标记模块,还用于基于第二图像的频域信息,在第二图像内标记出第二区域,第二区域对应有第二虚拟对象;
确定模块,用于基于第一区域和第二区域的图像特征,确定第一虚拟对象和第二虚拟对象为同一虚拟对象。
根据本申请的一个方面,提供了一种计算机设备,所述计算机设备包括:处理器和存储器,所述存储器存储有计算机程序,所述计算机程序由所述处理器加载并执行以实现如上所述的虚拟对象的识别方法。
根据本申请的另一方面,提供了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序由处理器加载并执行以实现如上所述的虚拟对象的识别方法。
根据本申请的另一方面,提供了一种计算机程序产品,所述计算机程序产品包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述方面提供的虚拟对象的识别方法。
本申请实施例提供的技术方案带来的有益效果至少包括:
根据第一图像的频域信息标记出对应有第一虚拟对象的第一区域,以及根据第二图像的频域信息标记出对应有第二虚拟对象的第二区域,之后根据第一区域和第二区域的图像特征,确定第一虚拟对象和第二虚拟对象为同一虚拟对象,提供了一种虚拟对象的识别方法,该方法不仅支持在图像帧中识别出虚拟对象,还支持将两帧图像中的虚拟对象进行一一对应,得到虚拟对象的移动轨迹。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1示出了一个示例性实施例提供的计算机系统的结构框图;
图2示出了一个示例性实施例提供的虚拟对象的识别方法的流程图;
图3示出了一个示例性实施例提供的虚拟对象的识别方法的示意图;
图4示出了一个示例性实施例提供的压缩器的示意图;
图5示出了一个示例性实施例提供的解压器的示意图;
图6示出了另一个示例性实施例提供的虚拟对象的识别方法的流程图;
图7示出了另一个示例性实施例提供的虚拟对象的识别方法的示意图;
图8示出了一个示例性实施例提供的虚拟对象的识别装置的结构框图;
图9示出了一个示例性实施例提供的计算机设备的结构框图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本申请相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本申请的一些方面相一致的装置和方法的例子。
应当理解的是,在本文中提及的“若干个”是指一个或者多个,“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。
首先,对本申请实施例中涉及的名词进行简单介绍:
虚拟环境:是客户端在终端上运行时显示(或提供)的虚拟环境。该虚拟环境可以是对真实世界的仿真环境,也可以是半仿真半虚构的环境,还可以是纯虚构的环境。虚拟环境可以是二维虚拟环境、2.5维虚拟环境和三维虚拟环境中的任意一种,本申请对此不加以限定。下述实施例以虚拟环境是三维虚拟环境来举例说明。
可选的,该虚拟环境可以提供虚拟对象的对战环境。示例性的,在MOBA(Multiplayer Online Battle Arena,多人在线战术竞技游戏)类型游戏中,两个敌对阵营在虚拟环境中进行对战,摧毁敌方阵营的防御型虚拟机关的一方获取最终胜利。示例性的,在大逃杀类型游戏中,至少一个虚拟对象在虚拟环境中进行单局对战,虚拟对象通过躲避敌方单位发起的攻击和虚拟环境中存在的危险(比如,毒气圈、沼泽地等)来达到在虚拟环境中存活的目的,当虚拟对象在虚拟环境中的生命值为零时,虚拟对象在虚拟环境中的生命结束,最后存活的虚拟对象是获胜方。
虚拟对象:是指虚拟环境中的可活动对象。该可活动对象可以是虚拟人物、虚拟动物、动漫人物等,比如:在三维虚拟环境中显示的人物、动物。可选地,虚拟对象是基于动画骨骼技术创建的三维立体模型。每个虚拟对象在三维虚拟环境中具有自身的形状和体积,占据三维虚拟环境中的一部分空间。
图1示出了本申请一个示例性实施例提供的计算机系统的结构框图。该计算机系统100包括:终端120和服务器140。
终端120安装和运行有支持虚拟环境的客户端。客户端可以是三维地图程序、横版射击、横版冒险、横版过关、横版策略、虚拟现实(Virtual Reality,VR)应用程序、增强现实(Augmented Reality,AR)程序中的任意一种。
终端120通过无线网络或有线网络与服务器140相连。
服务器140包括一台服务器、多台服务器、云计算平台和虚拟化中心中的至少一种。示例性的,服务器140包括处理器144和存储器142,存储器142又包括接收模块1421、控制模块1422和发送模块1423,接收模块1421用于接收客户端发送的请求,如控制虚拟对象移动的请求;控制模块1422用于控制虚拟环境画面的渲染;发送模块1423用于向客户端发送响应,如向客户端发送虚拟对象的位置已变更。服务器140用于为支持虚拟环境的应用程序提供后台服务。可选地,服务器140承担主要计算工作,终端120承担次要计算工作;或者,服务器140承担次要计算工作,终端120承担主要计算工作;或者,服务器140和终端120通过协同的方式承担计算工作。
可选地,上述客户端可以运行在不同操作系统平台(安卓或IOS)上。可选的,终端的设备类型包括:智能手机、智能手表、车载终端、可穿戴设备、智能电视、平板电脑、电子书阅读器、MP3播放器、MP4播放器、膝上型便携计算机和台式计算机中的至少一种。
本领域技术人员可以知晓,上述终端的数量可以更多或更少。比如上述终端可以仅为一个,或者上述终端为几十个或几百个,或者更多数量。本申请实施例对终端的数量和设备类型不加以限定。
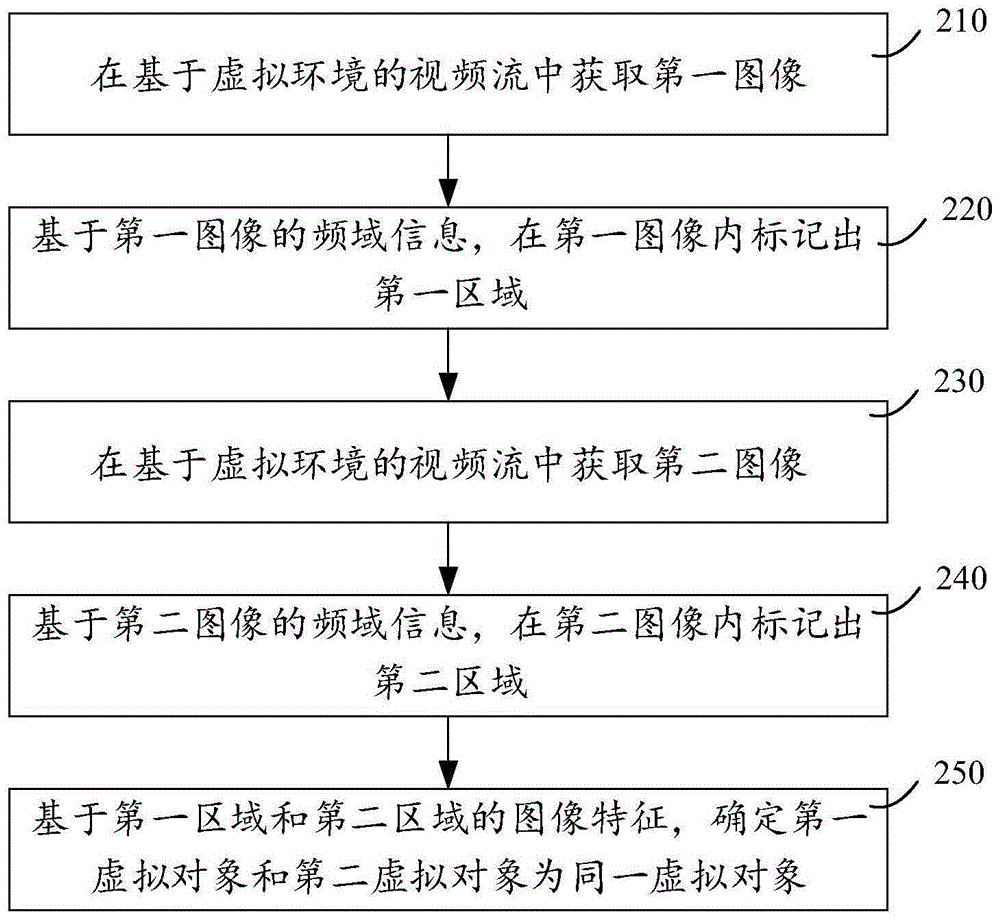
图2示出了本申请一个示例性实施例提供的虚拟对象的识别方法的流程图。以该方法由图1所示的终端或服务器执行进行举例说明,该方法包括:
步骤210,在基于虚拟环境的视频流中获取第一图像;
第一图像,指虚拟环境的视频流中的任意一张图像。在一个实施例中,虚拟环境的视频流可以是用户终端的屏幕上显示的视频,用户终端通过调用摄像机模型获取虚拟环境画面,并将该虚拟环境画面显示在屏幕上。可选的,虚拟环境的视频流也可以是服务器通过虚拟环境中的摄像机模型获取的虚拟环境画面。可选的,虚拟环境中的视频流内的相邻图像帧之间的间隔为预设间隔。比如,将每隔2s通过摄像机模型获取的虚拟环境画面作为视频流。
结合参考图3,其示出了基于虚拟环境的视频流获取的第一图像311。由图3可看出,第一图像311内包含了两个虚拟对象“炮车”和“小兵”。
步骤220,基于第一图像的频域信息,在第一图像内标记出第一区域;
在一个实施例中,第一图像的频域信息可以理解为将第一图像通过傅里叶变换后得到的频谱。图像的傅里叶变换用于将图像的灰度分布变换为图像的频率分布,频谱信息中的高频分量对应图像的细节信息,低频分量对应图像的轮廓信息。并且,高频分量代表的是信号的突变部分(即灰度值梯度大),而低频分量决定信号的整体形象(即梯度小)。
在一个实施例中,终端或服务器将第一图像通过DCT(Discrete Cosine Transform,离散余弦变换)得到第一图像的频域信息;将第一图像的频域信息输入用于识别虚拟对象的高通滤波器,得到第一DCT矩阵,第一DCT矩阵存储有第一虚拟对象的信息;根据第一DCT矩阵,在第一图像内标记出第一区域。
可选的,步骤220可以由下述步骤执行。
首先,通过下述公式(1),将第一图像进行DCT变换;
其中,f(x、y)为第一图像的像素,F(u,v)为经过DCT变换后的第一图像的频域信息,N为像素点个数。
然后,将通过公式(1)得到的第一图像的频域信息,经过下述公式(2)的高通滤波器,得到第一DCT矩阵。
其中,P、Q为预设的频段。可选的,通过离线从大量的图像中截取虚拟对象所在的区域,并提取该区域的频率信息,通过统计大量的区域的频域信息,得到综合频段,综合频段的临界点即为P和Q。
接着,通过高通滤波器得到第一DCT矩阵之后,还采用注意力机制为第一DCT矩阵中指示第一区域的矩阵块赋予第一注意力权重,得到加权后的第一DCT矩阵;
注意力机制从本质上讲与人类的选择性视觉注意力机制类似,用于从众多信息中选择出与当前任务目标相关的核心信息,即注意力机制用于调节核心信息的权重,加大核心信息的权重。
在一个实施例中,第一DCT矩阵与第一图像的像素矩阵相对应,第一DCT矩阵包括多个矩阵块,通过注意力机制为指示第一区域的矩阵块赋予第一注意力权重,得到加权后的第一DCT矩阵。其中,为指示第一区域的矩阵块赋予第一注意力权重,可以理解为:降低指示其它区域的矩阵块的注意力权重,和/或,增高指示第一区域的矩阵块的注意力权重。
最后,根据加权后的第一DCT矩阵和第一图像的像素矩阵,在第一图像内标记出第一区域。
在一个实施例中,将加权后的第一DCT矩阵与第一图像的像素矩阵相结合,即可以放大第一图像中第一区域内的像素点与其他区域的像素点的像素值的差异,因此,即区分出第一区域与其他区域。
在一个实施例中,通过预设的程序标记出第一区域。可选的,通过为第一区域添加矩形框标记出第一区域。示例性的,在区分第一区域与其他区域时,程序在第一区域的边界处打上直线标记,全部直线均标记完成之后,程序再找出由边界处的直线构成的方框,并裁剪掉较长的直线,因此即在第一区域的边界处添加矩形框。可选的,程序在添加直线时,直线需尽可能多的经过第一区域的边缘处的像素点,使得标记出的矩形框尽可能与第一区域的边缘处贴合。
可选的,通过为第一区域添加无规则框标记出第一区域。示例性的,在区分第一区域与其他区域时,程序直接串联第一区域的边缘处的像素点,最终为第一区域添加无规则框。
综上,可结合参考图3,步骤220即为图3中的左半部分。第一图像311经过DCT变换和滤波之后,得到第一DCT矩阵,将第一DCT矩阵输入压缩器和解压器,即可标记出第一区域。图3中的矩形框312即为第一区域添加的标记。在第一区域内存在第一虚拟对象(小兵)。
图3的左半部分还示出了记录器313,记录器313用于记录第一图像内虚拟对象的类型和位置。示意性的,记录性313中有填充内容的两个圆表示第一图像内的两个虚拟对象(炮车和小兵)。不同填充内容的圆表示不同的虚拟对象。并且,有填充内容的两个圆在记录器313的位置与两个虚拟对象在第一图像的位置相对应,有填充内容的两个圆中位置较左的圆表示第一图像中位置较左的虚拟对象,有填充内容的两个圆中位置较右的圆表示第一图像中位置较右的虚拟对象。以此类推,可得到第一图像存在不止两个虚拟对象时,记录器313按序记录虚拟对象。因此,通过记录器313即可记录第一图像内的虚拟对象,并且,结合相邻图像的记录器,即可获得任意一个虚拟对象的移动轨迹。
步骤230,在基于虚拟环境的视频流中获取第二图像;
第二图像,指虚拟环境的视频流中位于第一图像之后的图像。结合参考图3,其示出了基于虚拟环境的视频流获取的第二图像321。由图3可看出,第二图像321内包含了两个虚拟对象“炮车”和“小兵”。
步骤240,基于第二图像的频域信息,在第二图像内标记出第二区域;
在一个实施例中,终端或服务器将第二图像通过DCT变换得到第二图像的频域信息;将第二图像的频域信息输入用于识别虚拟对象的高通滤波器,得到第二DCT矩阵,第二DCT矩阵存储有第二虚拟对象的信息;根据第二DCT矩阵,在第二图像内标记出第二区域。
可选的,步骤240可以由下述步骤执行。
首先,通过下述公式(3),将第二图像进行DCT变换;
其中,f(x、y)为第二图像的像素,F(u,v)为经过DCT变换后的第二图像的频域信息,N为像素点个数。
然后,将通过公式(3)得到的第二图像的频域信息,经过下述公式(4)所示的高通滤波器,得到第二DCT矩阵。
其中,P、Q为预设的频段边界。可选的,通过离线从大量的图像中截取虚拟对象所在的区域,并提取该区域的频率信息,通过统计大量的区域的频域信息,得到综合频段,综合频段的临界点即为P和Q。
接着,通过高通滤波器得到第二DCT矩阵之后,还采用注意力机制为第二DCT矩阵中指示第二区域的矩阵块赋予第二注意力权重,得到加权后的第二DCT矩阵。
在一个实施例中,第二DCT矩阵与第二图像的像素矩阵相对应,第二DCT矩阵包括多个矩阵块,通过注意力机制为指示第二区域的矩阵块赋予第二注意力权重,得到加权后的第二DCT矩阵。其中,为指示第二区域的矩阵块赋予第二注意力权重,可以理解为:降低指示其它区域的矩阵块的注意力权重,和/或,增高指示第二区域的矩阵块的注意力权重。
最后,根据加权后的第二DCT矩阵和第二图像的像素矩阵,在第二图像内标记出第二区域。
在一个实施例中,将加权后的第二DCT矩阵与第二图像的像素矩阵相结合,即可以放大第二图像中第二区域内的像素点与其他区域的像素点的像素值的差异,因此,即区分出第二区域与其他区域。
在一个实施例中,通过预设的程序标记出第二区域。可选的,通过为第二区域添加矩形框标记出第二区域。示例性的,在区分第二区域与其他区域时,程序在第二区域的边界处打上直线标记,全部直线均标记完成之后,程序再找出由边界处的直线构成的方框,并裁剪掉较长的直线,因此即在第二区域的边界处添加矩形框。可选的,程序在添加直线时,直线需尽可能多的经过第二区域的边缘处的像素点,使得标记出的矩形框尽可能与第二区域的边缘处贴合。
可选的,通过为第二区域添加无规则框标记出第二区域。示例性的,在区分第二区域与其他区域时,程序直接串联第二区域的边缘处的像素点,最终为第二区域添加无规则框。
综上,可结合参考图3,步骤240即为图3中的右半部分。第二图像321经过DCT变换和滤波之后,得到第二DCT矩阵,将第二DCT矩阵输入压缩器和解压器,即可标记出第二区域。图3中的矩形框322即为第二区域添加的标记。在第二区域内存在第二虚拟对象(小兵)。
图3的右半部分还示出了记录器323,记录器323用于记录第二图像内虚拟对象的类型和位置。示意性的,记录性323中有填充内容的三个圆表示第二图像内的三个虚拟对象“炮车和两个小兵”。不同填充内容的圆表示不同的虚拟对象。并且,有填充内容的三个圆在记录器323的位置与三个虚拟对象在第二图像的位置相对应,有填充内容的三个圆中位置较左的圆表示第二图像中位置较左的虚拟对象,有填充内容的三个圆中位置较右的圆表示第二图像中位置较右的虚拟对象。以此类推,可得到第二图像存在多个虚拟对象时,记录器323内按序记录虚拟对象。因此,通过记录器323即可记录第二图像内的虚拟对象,并且,结合相邻图像的记录器,即可获得任意一个虚拟对象的移动轨迹。
步骤250,基于第一区域和第二区域的图像特征,确定第一虚拟对象和第二虚拟对象为同一虚拟对象。
由上可知,第一图像的第一区域内对应有第一虚拟对象,第二图像的第二区域内对应有第二虚拟对象。根据第一区域和第二区域的图像特征,即可确定第一虚拟对象和第二虚拟对象为同一虚拟对象。
在一个实施例中,通过下述两种方式中的至少一种,确定第一虚拟对象和第二虚拟对象为同一虚拟对象。
第一种可能的确定方式:根据第一位置信息与第二位置信息之间的对应关系,确定第一虚拟对象和第二虚拟对象为同一虚拟对象;其中,第一位置信息为第一区域在第一图像的位置信息,第二位置信息是第二区域在第二图像的位置信息。
在一个实施例中,第一区域在第一图像的坐标与第二区域在第二图像的坐标之间的差距小于阈值,则认为第一虚拟对象和第二虚拟对象为同一虚拟对象。
在另一个实施例中,在第二图像中检测出多个区域,每个区域分别对应一个虚拟对象,将多个区域中位置信息与第一区域最为接近的第二区域,认为其对应的虚拟对象与第一区域对应的虚拟对象为同一虚拟对象。
比如,检测出第一区域在第一图像的坐标为(20,25),还检测出第一图像的另一区域的坐标为(60,60),检测出第二区域在第二图像的坐标为(22,26),还检测出第二图像的另一区域的坐标为(61,62),则显然第一区域在第一图像的坐标与第二区域在第二图像的坐标较为接近,则认为第一虚拟对象和第二虚拟对象为同一虚拟对象。
第二种可能的确定方式:基于第一区域与第二区域之间的相似性,确定第一虚拟对象和第二虚拟对象为同一虚拟对象。
在一个实施例中,计算第一区域与第二区域的相似度,基于第一区域与第二区域的相似度小于阈值,则确定第一虚拟对象和第二虚拟对象为同一虚拟对象。
可选的,根据分辨率、区域大小、颜色、色调、饱和度和亮度中的至少一种,计算第一区域与第二区域的相似度。比如,基于第一区域与第二区域的大小一致,则确定第一虚拟对象和第二虚拟对象为同一虚拟对象。又比如,基于第一区域与第二区域的颜色种类和颜色数量一致,则确定第一虚拟对象和第二虚拟对象为同一虚拟对象。
综上所述,根据第一图像的频域信息标记出对应有第一虚拟对象的第一区域,以及根据第二图像的频域信息标记出对应有第二虚拟对象的第二区域,之后根据第一区域和第二区域的图像特征,确定第一虚拟对象和第二虚拟对象为同一虚拟对象,提供了一种虚拟对象的识别方法,该方法不仅支持在图像帧中识别出虚拟对象,还支持将两帧图像中的虚拟对象进行一一对应,并得到虚拟对象的移动轨迹。
并且,通过离散余弦变换和滤波操作,得到存储有第一虚拟对象的信息的第一DCT矩阵,并根据第一DCT矩阵标记虚拟对象,提取出第一图像中的第一虚拟对象的图像特征,并根据第一虚拟对象的图像特征通过注意力机制为第一图像赋予注意力权重,即区分出第一区域和其他区域,最后为第一区域添加标记,提供了具体的实现方式,提高了标记第一虚拟对象的准确率和效率。
并且,通过离散余弦变换和滤波操作,得到存储有第二虚拟对象的信息的第二DCT矩阵,并根据第二DCT矩阵标记虚拟对象,提取出第二图像中的第二虚拟对象的图像特征,并根据第二虚拟对象的图像特征通过注意力机制为第二图像赋予注意力权重,即区分出第二区域和其他区域,最后为第二区域添加标记,提高了标记第二虚拟对象的准确率和效率。
基于图2所示的可选实施例中,步骤220可能涉及到:采用注意力机制为第一DCT矩阵中指示第一区域的矩阵块赋予第一注意力权重,得到加权后的第一DCT矩阵。步骤240可能涉及到:采用注意力机制为第二DCT矩阵中指示第二区域的矩阵块赋予第二注意力权重,得到加权后的第二DCT矩阵。
在一个实施例中,采用压缩器为DCT矩阵赋予注意力权重。
结合参考图4,压缩器400包括M个压缩层。在每个压缩层内存在注意力网络和全连接网络。注意力网络用于将DCT矩阵拆分为多个矩阵块,并为指示对应有虚拟对象的区域的矩阵块赋予注意力权重。全连接网络用于按照图像的像素矩阵的位置关系,将赋予权重后的多个矩阵块进行连接。
可选的,每一个压缩层用于为一个对应有虚拟对象的区域赋予注意力权重,M个压缩层总共可赋予M个区域的注意力权重。可选的,每一个压缩层用于为对应有虚拟对象的全部区域赋予注意力权重,M个压缩层用于重复赋予注意力权重。
示例性的,下述公式(5)示出了压缩层的压缩函数。
f=exp(x+sublayer(x)); (5)
其中,x为输入的DCT矩阵,sublayer(x)为上一压缩层的输出矩阵,对于第一压缩层而言,sublayer(x)为0。
针对第一图像的压缩处理:
1-1,将第一DCT矩阵输入第1压缩层,得到第1压缩层的输出矩阵;
1-2,将第一DCT矩阵和第m-1压缩层的输出矩阵输入第m压缩层,得到第m压缩层的输出矩阵;m的初始值为2;
1-3,在m小于M的情况下,将m更新为m+1,重新执行将第一DCT矩阵和第m-1压缩层的输出矩阵输入第m压缩层,得到第m压缩层的输出矩阵的步骤(即步骤1-2);M为预设的压缩层的数量;
1-4,在m等于M的情况下,将第M压缩层的输出矩阵确定为加权后的第一DCT矩阵。
针对第二图像的压缩处理:
2-1,将第二DCT矩阵输入第1压缩层,得到第1压缩层的输出矩阵;
2-2,将第二DCT矩阵和第m-1压缩层的输出矩阵输入第m压缩层,得到第m压缩层的输出矩阵;m的初始值为2;
2-3,在m小于M的情况下,将m更新为m+1,重新执行将第二DCT矩阵和第m-1压缩层的输出矩阵输入第m压缩层,得到第m压缩层的输出矩阵的步骤(即步骤2-2);M为预设的压缩层的数量;
2-4,在m等于M的情况下,将第M压缩层的输出矩阵确定为加权后的第二DCT矩阵。
综上所述,上述方法给出了压缩器的具体结构,进一步提供了根据第一虚拟对象的图像特征通过注意力机制为第一图像赋予注意力权重的方法,提高了标记第一虚拟对象的准确率和效率。
并且,上述方法给出了压缩器的具体结构,进一步提供了根据第二虚拟对象的图像特征通过注意力机制为第二图像赋予注意力权重的方法,提高了标记第二虚拟对象的准确率和效率。
基于图2所示的可选实施例中,步骤220可能涉及到:根据加权后的第一DCT矩阵和第一图像的像素矩阵,在第一图像内标记出第一区域。步骤240可能涉及到:根据加权后的第二DCT矩阵和第二图像的像素矩阵,在第二图像内标记出第二区域。
在一个实施例中,采用解压器根据加权后的DCT矩阵为图像添加标记。
结合参考图5,解压器包括N个解压层。在每个解压层内存在注意力网络和插值网络。注意力网络用于将加权后的DCT矩阵进行归一化,将归一化的结果与图像的像素矩阵相乘。插值网络用于放大图像,可选的,插值网络为线性插值和/或均值插值。
可选的,每一个解压层用于为一个对应有虚拟对象的区域的矩阵块归一化,并将归一化结果与图像的像素矩阵中该区域的像素块相乘,N个解压层总共可叠加N个区域的归一化结果。可选的,每一个解压层用于为对应有虚拟对象的全部区域的矩阵块归一化,并将归一化结果与图像的像素矩阵中该全部区域的像素块相乘,N个解压层用于重复叠加归一化结果。
示例性的,下述公式(6)示出了解压层的解压函数。
f=softmax(F/exp)V; (6)
其中,F为加权后的DCT矩阵或上一解压层的输出矩阵,exp为指数e,V为图像的像素矩阵。
针对第一图像的解压处理:
1-1’,将加权后的第一DCT矩阵和第一图像的像素矩阵输入第1解压层,得到第1解压层的输出矩阵;
1-2’,将第一图像的像素矩阵和第n-1解压层的输出矩阵输入第n解压层,得到第n解压层的输出矩阵;n的初始值为2;
1-3’,在n小于N的情况下,将n更新为n+1,重新执行将第一图像的像素矩阵和第n-1解压层的输出矩阵输入第n解压层,得到第n解压层的输出矩阵的步骤(即步骤1-2’);N为预设的解压层的数量;
1-4’,在n等于N的情况下,基于第N解压层的输出矩阵,在第一图像上标记出第二区域;
针对第二图像的解压处理:
2-1’,将加权后的第二DCT矩阵和第i帧图像的像素矩阵输入第1解压层,得到第1解压层的输出矩阵;
2-2’,将第二图像的像素矩阵和第n-1解压层的输出矩阵输入第n解压层,得到第n解压层的输出矩阵;n的初始值为2;
2-3’,在n小于N的情况下,将n更新为n+1,重新执行将第二图像的像素矩阵和第n-1解压层的输出矩阵输入第n解压层,得到第n解压层的输出矩阵的步骤;N为预设的解压层的数量;
2-4’,在n等于N的情况下,基于第N解压层的输出矩阵,在第二图像上标记出第二区域。
综上所述,上述方法给出了解压器的具体结构,根据赋予注意力权重后的第一虚拟对象的图像特征,区分出第一区域和其他区域,最后为第一区域添加标记,提高了标记第一虚拟对象的准确率和效率。
并且,根据赋予注意力权重后的第二虚拟对象的图像特征,区分出第二区域和其他区域,最后为第二区域添加标记,提高了标记第二虚拟对象的准确率和效率。
在上述图2所示的方法实施例中,提供了一种虚拟对象的识别方法,该方法支持将两帧图像之间的虚拟对象进行一一对应。接下来,还将进一步提供识别每个虚拟对象的产生和消失的方法。
基于图2所示的可选实施例中,图6示出了本申请一个示例性实施例提供的虚拟对象的识别方法的流程图,该方法将图2所示的方法中的第一图像重新定义为关键帧图像,以及将第二图像重新定义为第i-1帧图像。以该方法由图1所示的终端或服务器执行进行举例说明,图6所示的方法包括:
步骤610,基于第i-1帧图像的频域信息,在第i-1帧图像内标记出第三区域和第四区域;
在上述图2的步骤240中,给出了基于第二图像的频域信息,在第二图像内标记出第二区域的方法,采用类似的方法,即可在第i-1帧图像(第二图像)内标记出场第三区域和第四区域,第三区域和第四区域内均对应虚拟对象。
结合参考图7,其示出了第i-1帧图像内的第三区域701和第四区域702。
可选的,步骤610在图2所示的方法实施例的步骤240之前或之后执行,或者,步骤610与步骤240同时执行。
步骤620,基于关键帧图像和第i-1帧图像的图像特征,确定第三区域内的虚拟对象为第i-1帧图像新增的虚拟对象;
关键帧图像,指在基于虚拟环境的视频流中,用于确定新增了虚拟对象的图像。可选的,基于关键帧图像和第i-1帧图像的图像特征,确定第三区域内的虚拟对象为第i-1帧图像新增的虚拟对象,可以包括以下方法中的至少之一:
第一、基于关键帧图像和第i-1帧图像标记出的区域的位置信息,确定新增的虚拟对象。
比如,关键帧图像内对应有虚拟对象的所有区域的坐标,与第i-1帧中第三区域的坐标差距达到阈值,则确定关键帧图像内没有与第三区域对应的区域,即确定第三区域内的虚拟对象为新增的虚拟对象;
第二、基于关键帧图像和第i-1帧图像标记出的区域的相似性,确定新增的虚拟对象。
可选的,根据分辨率、区域大小、颜色、色调、饱和度和亮度中的至少一种,计算关键帧图像内对应有虚拟对象的所有区域与第三区域的相似度。
比如,关键帧图像内对应有虚拟对象的所有区域与第三区域的大小不一致,则确定第三区域内的虚拟对象为新增的虚拟对象。又比如,关键帧图像内对应有虚拟对象的所有区域与第三区域的颜色种类和颜色数量不一致,则确定第三区域内的虚拟对象为新增的虚拟对象。
可选的,步骤620在图2所示的方法实施例的步骤250之前或之后执行,或者,步骤620与步骤250同时执行。
步骤630,在基于虚拟环境的视频流中获取第i帧图像;基于第i-1帧图像和第i帧图像的图像特征,确定第四区域内的虚拟对象为第i帧图像减少的虚拟对象。
第i帧图像,指在基于虚拟环境的视频流中第i-1帧图像的下一帧图像。可选的,基于第i-1帧图像和第i帧图像的图像特征,确定第四区域内的虚拟对象为第i帧图像减少的虚拟对象,可以包括以下方法中的至少之一:
第一、基于第i-1帧图像和第i帧图像标记出的区域的位置信息,确定减少的虚拟对象。
比如,第i帧图像内对应有虚拟对象的所有区域的坐标,与第i-1帧中第四区域的坐标差距达到阈值,则确定第i帧图像内没有与第四区域对应的区域,即确定第四区域内的虚拟对象为减少的虚拟对象;
第二、基于第i-1帧图像和第i帧图像标记出的区域的相似性,确定减少的虚拟对象。
可选的,根据分辨率、区域大小、颜色、色调、饱和度和亮度中的至少一种,计算第i帧图像内对应有虚拟对象的所有区域与第四区域的相似度。
比如,第i帧图像内对应有虚拟对象的所有区域与第四区域的大小不一致,则确定第四区域内的虚拟对象为减少的虚拟对象。又比如,第i帧图像内对应有虚拟对象的所有区域与第四区域的颜色种类和颜色数量不一致,则确定第四区域内的虚拟对象为减少的虚拟对象。
可选的,步骤630在图2所示的方法实施例的步骤250之后执行。
综上所述,根据第i-1帧图像和关键帧图像的图像特征,确定出新增的虚拟对象,以及,根据第i帧图像和第i-1帧图像的图像特征,确定出减少的虚拟对象,提供了确定虚拟对象的产生和消失的方法,进一步确定出虚拟对象的移动轨迹。
基于图2或图6所示的可选实施例中,还可能存在选择关键帧图像的相关步骤S1,在基于图2所示的可选实施例中,步骤S1位于步骤250之后;在基于图2所示的可选实施例中,步骤S1位于步骤610、步骤620和步骤630中的任一步骤之前或之后。
S1:在关键帧图像的第一区域的面积与第i-1帧图像的第二区域的面积之间的差值满足阈值的情况下,将第i-1帧图像确认为新的关键帧图像。
可选的,在关键帧图像中检测出的第一区域的第一虚拟对象与在第i-1帧图像中检测出的第二区域的第二虚拟对象为同一虚拟对象的情况下,若第一区域的面积与第二区域的面积(即第一虚拟对象的面积与第二虚拟对象的面积)之间的差值达到阈值的情况下,则认为关键帧图像与第i-1帧图像之间变化较大,将第i-1帧图像确认为新的关键帧图像。
可选的,若第一虚拟对象为完整的虚拟对象,第二虚拟对象与第一虚拟对象为同一虚拟对象,并且第二虚拟对象相比较于完整的虚拟对象的缺失比例达到阈值的情况下,将第i-1帧图像确认为新的关键帧图像。
综上所述,当第i-1帧图像的第二虚拟对象相比于关键帧图像的第一虚拟对象的消失程度达到阈值时,将第i-1帧图像确定为新的关键帧图像,其中,第二虚拟对象和第一虚拟对象为同一虚拟对象,提供了一种关键帧的确定方式。
在一个可选的实施例中,虚拟对象的识别方法主要分为三个阶段:目标初始化发现、目标增量识别和目标消融识别。
在目标初始化发现阶段,主要融合DCT和解压缩技术发现动态目标,并且标记不同的颜色。在目标增量识别阶段,通过上一帧(第i-1帧)的多目标位置和特征信息,同样利用DCT和解压缩技术去发现新的增量目标,这个过程中,新发现的目标会标记为不同的颜色。在目标消融识别阶段,通过下一帧(第i帧)的多目标位置和特征信息,同样利用DCT和解压缩技术去发现减少的目标,并且丢弃该目标。
DCT:通过离散余弦变化,将整个图像进行频域转换,然后通过自定义的高频滤波器过滤出高频特征,这部分特征的图像主要包含丰富的游戏角色的信息。
解压缩技术:在压缩过程中,通过加入注意力机制,把整个图像的DCT矩阵打散成独立的压缩块,并同时加入注意力机制。在解压过程中,使用图像技术将压缩后的数据恢复成图像,对应各个图像目标,即支持自动标记对应的目标。
在压缩过程,通过压缩器进行压缩。压缩器给出的是一个固定维数的向量,注意力机制用于调节或加大核心信息的权重。压缩器6个相同的压缩层堆叠而成,每个压缩层有两个子层。第一个子层是多头自我注意力机制,第二子层是简单的位置的全连接前馈网络。在两个子层中会使用一个残差连接,接着进行层标准化,也就是说每一个压缩层的压缩函数都是exp(x+sublayer(x))。并且,每个子层的输出和输入都是相同的维度。因此,将DCT和滤波得到的结果通过压缩器网络,完成了注意力信息的压缩变换,得到的是一个压缩的向量矩阵。
在解压过程,就是要恢复图像信息,由于低频和超高频信息已经被过滤了,留下了带有注意力的信息,因此解压器仅需要恢复注意力信息。
解压器也是由6个完全相同的解压层组成,解压器中的解压层由压缩器的压缩层中插入一个多目标注意力机制和加权均值过滤器组成。压缩器输出的数据与原始图像的像素矩阵做为解压器的输入,经过一个多目标注意力机制和加均值层,MA-1(多目标注意力机制第一层)层的输出作为下一MA-2的输入、MA-2层的Key和Value。MA-2层的输出输入到一个前馈层(FF),经过多次操作后,经过一个线性变换后最终得到带标记的角色标记,这个标记是自动根据恢复的图像注意力添加的自适应的方框。多目标注意力机制函数为MA=softmax(F/exp)V,其中,MA为多目标注意力矩阵,F为从压缩器的输出,V为原始图像,exp为指数e,softmax为softmax函数。
图8示出了本申请一个示例性实施例提供的虚拟对象的识别装置的结构框图,该装置包括:
获取模块801,用于在基于虚拟环境的视频流中获取第一图像;
标记模块802,用于基于第一图像的频域信息,在第一图像内标记出第一区域,第一区域对应有第一虚拟对象;
获取模块801,还用于在基于虚拟环境的视频流中获取第二图像;
标记模块802,还用于基于第二图像的频域信息,在第二图像内标记出第二区域,第二区域对应有第二虚拟对象;
确定模块803,用于基于第一区域和第二区域的图像特征,确定第一虚拟对象和第二虚拟对象为同一虚拟对象。
在一个可选的实施例中,标记模块802还用于将第一图像通过离散余弦变换DCT得到第一图像的频域信息;将第一图像的频域信息输入用于识别虚拟对象的滤波器,得到第一DCT矩阵,第一DCT矩阵存储有第一虚拟对象的信息;根据第一DCT矩阵,在第一图像内标记出第一区域;
在一个可选的实施例中,标记模块802还用于将第二图像通过DCT得到第二图像的频域信息;将第二图像的频域信息输入用于识别虚拟对象的滤波器,得到第二DCT矩阵,第二DCT矩阵存储有第二虚拟对象的信息;根据第二DCT矩阵,在第二图像内标记出第二区域。
在一个可选的实施例中,标记模块802还用于采用注意力机制为第一DCT矩阵中指示第一区域的矩阵块赋予第一注意力权重,得到加权后的第一DCT矩阵;根据加权后的第一DCT矩阵和第一图像的像素矩阵,在第一图像内标记出第一区域。
在一个可选的实施例中,标记模块802还用于采用注意力机制为第二DCT矩阵中指示第二区域的矩阵块赋予第二注意力权重,得到加权后的第二DCT矩阵;根据加权后的第二DCT矩阵和第二图像的像素矩阵,在第二图像内标记出第二区域。
在一个可选的实施例中,标记模块802还用于将第一DCT矩阵输入第1压缩层,得到第1压缩层的输出矩阵;将第一DCT矩阵和第m-1压缩层的输出矩阵输入第m压缩层,得到第m压缩层的输出矩阵;m的初始值为2;在m小于M的情况下,将m更新为m+1,重新执行将第一DCT矩阵和第m-1压缩层的输出矩阵输入第m压缩层,得到第m压缩层的输出矩阵的步骤;M为预设的压缩层的数量;在m等于M的情况下,将第M压缩层的输出矩阵确定为加权后的第一DCT矩阵;其中,压缩层包括注意力网络和全连接网络。
在一个可选的实施例中,标记模块802还用于将第二DCT矩阵输入第1压缩层,得到第1压缩层的输出矩阵;将第二DCT矩阵和第m-1压缩层的输出矩阵输入第m压缩层,得到第m压缩层的输出矩阵;m的初始值为2;在m小于M的情况下,将m更新为m+1,重新执行将第二DCT矩阵和第m-1压缩层的输出矩阵输入第m压缩层,得到第m压缩层的输出矩阵的步骤;M为预设的压缩层的数量;在m等于M的情况下,将第M压缩层的输出矩阵确定为加权后的第二DCT矩阵;其中,压缩层包括注意力网络和全连接网络。
在一个可选的实施例中,标记模块802还用于将加权后的第一DCT矩阵和第一图像的像素矩阵输入第1解压层,得到第1解压层的输出矩阵;将第一图像的像素矩阵和第n-1解压层的输出矩阵输入第n解压层,得到第n解压层的输出矩阵;n的初始值为2;在n小于N的情况下,将n更新为n+1,重新执行将第一图像的像素矩阵和第n-1解压层的输出矩阵输入第n解压层,得到第n解压层的输出矩阵的步骤;N为预设的解压层的数量;在n等于N的情况下,基于第N解压层的输出矩阵,在第一图像上标记出第二区域;其中,解压层包括注意力网络和插值网络。
在一个可选的实施例中,标记模块802还用于将加权后的第二DCT矩阵和第i帧图像的像素矩阵输入第1解压层,得到第1解压层的输出矩阵;将第二图像的像素矩阵和第n-1解压层的输出矩阵输入第n解压层,得到第n解压层的输出矩阵;n的初始值为2;在n小于N的情况下,将n更新为n+1,重新执行将第二图像的像素矩阵和第n-1解压层的输出矩阵输入第n解压层,得到第n解压层的输出矩阵的步骤;N为预设的解压层的数量;在n等于N的情况下,基于第N解压层的输出矩阵,在第二图像上标记出第二区域;其中,解压层包括注意力网络和插值网络。
在一个可选的实施例中,确定模块803还用于基于第一位置信息与第二位置信息之间的关系,确定第一虚拟对象和第二虚拟对象为同一虚拟对象;第一位置信息为第一区域在第一图像的位置信息,第二位置信息是第二区域在第二图像的位置信息。
在一个可选的实施例中,确定模块803基于第一区域与第二区域之间的相似性,确定第一虚拟对象和第二虚拟对象为同一虚拟对象。
在一个可选的实施例中,第一图像为关键帧图像,第二图像为第i-1帧图像;标记模块802还用于,基于第i-1帧图像的频域信息,在第i-1帧图像内标记出第三区域;确定模块803,用于在关键帧图像未被标记出与第三区域对应的区域的情况下,确定第三虚拟对象为第i-1帧图像新增的虚拟对象。
在一个可选的实施例中,确定模块803还用于,在关键帧图像的第一区域的面积与第i-1帧图像的第二区域的面积之间的差值满足阈值的情况下,将第i-1帧图像确认为新的关键帧图像。
在一个可选的实施例中,标记模块802还用于,基于第i-1帧图像的频域信息,在第i-1帧图像内标记出第四区域;获取模块801还用于,在基于虚拟环境的视频流中获取第i帧图像;确定模块803,还用于在第i帧图像未被标记出与第四区域对应的区域的情况下,确定第四虚拟对象为第i帧图像减少的虚拟对象。
综上所述,根据第一图像的频域信息标记出对应有第一虚拟对象的第一区域,以及根据第二图像的频域信息标记出对应有第二虚拟对象的第二区域,之后根据第一区域和第二区域的图像特征,确定第一虚拟对象和第二虚拟对象为同一虚拟对象,提供了一种虚拟对象的识别装置,该装置不仅支持在图像帧中识别出虚拟对象,还支持将两帧图像中的虚拟对象进行一一对应,并得到虚拟对象的移动轨迹。
图9示出了本申请一个示例性实施例提供的计算机设备900的结构框图。该计算机设备900可以是便携式移动终端,比如:智能手机、平板电脑、MP3播放器(Moving PictureExperts Group Audio Layer III,动态影像专家压缩标准音频层面3)、MP4(MovingPicture Experts Group Audio Layer IV,动态影像专家压缩标准音频层面4)播放器、笔记本电脑或台式电脑。计算机设备900还可能被称为用户设备、便携式终端、膝上型终端、台式终端等其他名称。
通常,计算机设备900包括有:处理器901和存储器902。
处理器901可以包括一个或多个处理核心,比如4核心处理器、8核心处理器等。处理器901可以采用DSP(Digital Signal Processing,数字信号处理)、FPGA(Field-Programmable Gate Array,现场可编程门阵列)、PLA(Programmable Logic Array,可编程逻辑阵列)中的至少一种硬件形式来实现。处理器901也可以包括主处理器和协处理器,主处理器是用于对在唤醒状态下的数据进行处理的处理器,也称CPU(Central ProcessingUnit,中央处理器);协处理器是用于对在待机状态下的数据进行处理的低功耗处理器。在一些实施例中,处理器901可以集成有GPU(Graphics Processing Unit,图像处理器),GPU用于负责显示屏所需要显示的内容的渲染和绘制。一些实施例中,处理器901还可以包括AI(Artificial Intelligence,人工智能)处理器,该AI处理器用于处理有关机器学习的计算操作。
存储器902可以包括一个或多个计算机可读存储介质,该计算机可读存储介质可以是非暂态的。存储器902还可包括高速随机存取存储器,以及非易失性存储器,比如一个或多个磁盘存储设备、闪存存储设备。在一些实施例中,存储器902中的非暂态的计算机可读存储介质用于存储至少一个指令,该至少一个指令用于被处理器901所执行以实现本申请中方法实施例提供的虚拟对象的识别方法。
在一些实施例中,计算机设备900还可选包括有:外围设备接口903和至少一个外围设备。处理器901、存储器902和外围设备接口903之间可以通过总线或信号线相连。各个外围设备可以通过总线、信号线或电路板与外围设备接口903相连。示例地,外围设备可以包括:射频电路904、显示屏905、摄像头组件906、音频电路907和电源908中的至少一种。
外围设备接口903可被用于将I/O(Input/Output,输入/输出)相关的至少一个外围设备连接到处理器901和存储器902。在一些实施例中,处理器901、存储器902和外围设备接口903被集成在同一芯片或电路板上;在一些其他实施例中,处理器901、存储器902和外围设备接口903中的任意一个或两个可以在单独的芯片或电路板上实现,本实施例对此不加以限定。
射频电路904用于接收和发射RF(Radio Frequency,射频)信号,也称电磁信号。射频电路904通过电磁信号与通信网络以及其他通信设备进行通信。射频电路904将电信号转换为电磁信号进行发送,或者,将接收到的电磁信号转换为电信号。可选地,射频电路904包括:天线系统、RF收发器、一个或多个放大器、调谐器、振荡器、数字信号处理器、编解码芯片组、用户身份模块卡等等。射频电路904可以通过至少一种无线通信协议来与其它终端进行通信。该无线通信协议包括但不限于:万维网、城域网、内联网、各代移动通信网络(2G、3G、4G及9G)、无线局域网和/或WiFi(Wireless Fidelity,无线保真)网络。在一些实施例中,射频电路904还可以包括NFC(Near Field Communication,近距离无线通信)有关的电路,本申请对此不加以限定。
显示屏905用于显示UI(User Interface,用户界面)。该UI可以包括图形、文本、图标、视频及其它们的任意组合。当显示屏905是触摸显示屏时,显示屏905还具有采集在显示屏905的表面或表面上方的触摸信号的能力。该触摸信号可以作为控制信号输入至处理器901进行处理。此时,显示屏905还可以用于提供虚拟按钮和/或虚拟键盘,也称软按钮和/或软键盘。在一些实施例中,显示屏905可以为一个,设置在计算机设备900的前面板;在另一些实施例中,显示屏905可以为至少两个,分别设置在计算机设备900的不同表面或呈折叠设计;在另一些实施例中,显示屏905可以是柔性显示屏,设置在计算机设备900的弯曲表面上或折叠面上。甚至,显示屏905还可以设置成非矩形的不规则图形,也即异形屏。显示屏905可以采用LCD(Liquid Crystal Display,液晶显示屏)、OLED(Organic Light-EmittingDiode,有机发光二极管)等材质制备。
摄像头组件906用于采集图像或视频。可选地,摄像头组件906包括前置摄像头和后置摄像头。通常,前置摄像头设置在终端的前面板,后置摄像头设置在终端的背面。在一些实施例中,后置摄像头为至少两个,分别为主摄像头、景深摄像头、广角摄像头、长焦摄像头中的任意一种,以实现主摄像头和景深摄像头融合实现背景虚化功能、主摄像头和广角摄像头融合实现全景拍摄以及VR(Virtual Reality,虚拟现实)拍摄功能或者其它融合拍摄功能。在一些实施例中,摄像头组件906还可以包括闪光灯。闪光灯可以是单色温闪光灯,也可以是双色温闪光灯。双色温闪光灯是指暖光闪光灯和冷光闪光灯的组合,可以用于不同色温下的光线补偿。
音频电路907可以包括麦克风和扬声器。麦克风用于采集用户及环境的声波,并将声波转换为电信号输入至处理器901进行处理,或者输入至射频电路904以实现语音通信。出于立体声采集或降噪的目的,麦克风可以为多个,分别设置在计算机设备900的不同部位。麦克风还可以是阵列麦克风或全向采集型麦克风。扬声器则用于将来自处理器901或射频电路904的电信号转换为声波。扬声器可以是传统的薄膜扬声器,也可以是压电陶瓷扬声器。当扬声器是压电陶瓷扬声器时,不仅可以将电信号转换为人类可听见的声波,也可以将电信号转换为人类听不见的声波以进行测距等用途。在一些实施例中,音频电路907还可以包括耳机插孔。
电源908用于为计算机设备900中的各个组件进行供电。电源908可以是交流电、直流电、一次性电池或可充电电池。当电源908包括可充电电池时,该可充电电池可以是有线充电电池或无线充电电池。有线充电电池是通过有线线路充电的电池,无线充电电池是通过无线线圈充电的电池。该可充电电池还可以用于支持快充技术。
在一些实施例中,计算机设备900还包括有一个或多个传感器909。该一个或多个传感器909包括但不限于:加速度传感器910、陀螺仪传感器911、压力传感器912、光学传感器913以及接近传感器914。
加速度传感器910可以检测以计算机设备900建立的坐标系的三个坐标轴上的加速度大小。比如,加速度传感器910可以用于检测重力加速度在三个坐标轴上的分量。处理器901可以根据加速度传感器910采集的重力加速度信号,控制显示屏905以横向视图或纵向视图进行用户界面的显示。加速度传感器910还可以用于游戏或者用户的运动数据的采集。
陀螺仪传感器911可以检测计算机设备900的机体方向及转动角度,陀螺仪传感器911可以与加速度传感器910协同采集用户对计算机设备900的3D动作。处理器901根据陀螺仪传感器911采集的数据,可以实现如下功能:动作感应(比如根据用户的倾斜操作来改变UI)、拍摄时的图像稳定、游戏控制以及惯性导航。
压力传感器912可以设置在计算机设备900的侧边框和/或显示屏905的下层。当压力传感器912设置在计算机设备900的侧边框时,可以检测用户对计算机设备900的握持信号,由处理器901根据压力传感器912采集的握持信号进行左右手识别或快捷操作。当压力传感器912设置在显示屏905的下层时,由处理器901根据用户对显示屏905的压力操作,实现对UI界面上的可操作性控件进行控制。可操作性控件包括按钮控件、滚动条控件、图标控件、菜单控件中的至少一种。
光学传感器913用于采集环境光强度。在一个实施例中,处理器901可以根据光学传感器913采集的环境光强度,控制显示屏905的显示亮度。示例地,当环境光强度较高时,调高显示屏905的显示亮度;当环境光强度较低时,调低显示屏905的显示亮度。在另一个实施例中,处理器901还可以根据光学传感器913采集的环境光强度,动态调整摄像头组件906的拍摄参数。
接近传感器914,也称距离传感器,通常设置在计算机设备900的前面板。接近传感器914用于采集用户与计算机设备900的正面之间的距离。在一个实施例中,当接近传感器914检测到用户与计算机设备900的正面之间的距离逐渐变小时,由处理器901控制显示屏905从亮屏状态切换为息屏状态;当接近传感器914检测到用户与计算机设备900的正面之间的距离逐渐变大时,由处理器901控制显示屏905从息屏状态切换为亮屏状态。
本领域技术人员可以理解,图9中示出的结构并不构成对计算机设备900的限定,可以包括比图示更多或更少的组件,或者组合某些组件,或者采用不同的组件布置。
本申请还提供一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现上述方法实施例提供的虚拟对象的识别方法。
本申请提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述方法实施例提供的虚拟对象的识别方法。
上述本申请实施例序号仅仅为了描述,不代表实施例的优劣。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
以上所述仅为本申请的可选实施例,并不用以限制本申请,凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 行人再识别方法和装置、电子设备、存储介质、程序产品
- 虚拟对象的操作控制方法、装置、电子设备及存储介质
- 虚拟对象控制方法、装置、电子设备及存储介质
- 虚拟对象控制方法及装置、电子设备、存储介质
- 虚拟机应用程序管理方法、装置、设备及可读存储介质
- 虚拟对象的毛发处理方法、装置、设备、介质及程序产品
- 虚拟对象的控制方法、装置、设备、存储介质及程序产品