一种自动特征生成系统和方法
文献发布时间:2023-06-19 10:05:17
技术领域
本发明涉及机器学习技术领域,更具体地,涉及一种自动特征生成系统和方法。
背景技术
随着大数据人工智能技术的普及,通过机器学习算法进行数据分析处理的方法逐步被各个行业的工程人员所采用。机器学习算法的输入数据被称为特征,是通过一系列工程方法将原始数据加工而成的。目前,针对特征的自动建模方法或本发明的系统已经有了很多成熟的产品,但对于自动处理原始数据生成特征的本发明的系统产品仍然处于研究阶段。现有的包含特征生成的本发明的系统产品有以下几种:
(1)集成人工提取特征功能的数据平台,此类平台支持用户在前端界面编写提取特征的代码,系统运行代码后将特征保存为可供建模的数据表,并支持导入建模平台。此类平台的输入是原始数据,缺点是特征生成逻辑依靠工程人员编写代码完成,需要用户有较高的技术能力,无法实现自动的特征生成过程。
(2)集成特征衍生功能的自动建模平台,此类平台的特征衍生功能的主要目的是为了对已有的特征进行进一步衍生,以增强特征的表达能力,提高建模的效果。此类平台的输入是可以直接建模的特征,缺点是无法对不可建模的原始数据进行特
(3)集成半自动特征生成功能的特征平台,此类平台支持用户在前端界面指定特征生成逻辑,系统自动根据特征生成逻辑在后台生成代码并执行,生成用户指定的特征。此类平台的输入是原始数据,不需要用户编写代码,但缺点是生成的特征数量和效果都依赖于用户的业务理解和生成逻辑,无法实现自动的特征生成过程。
发明内容
针对背景技术中的问题,本发明的明目的是:自动对原始数据进行处理分析,生成正确的有效的特征。对于非专业技术人员,可以通过本发明的系统方便快捷的生成供模型建模使用的特征变量。对于专业技术人员,可以通过本发明的系统快速测试、分析或迭代特征。
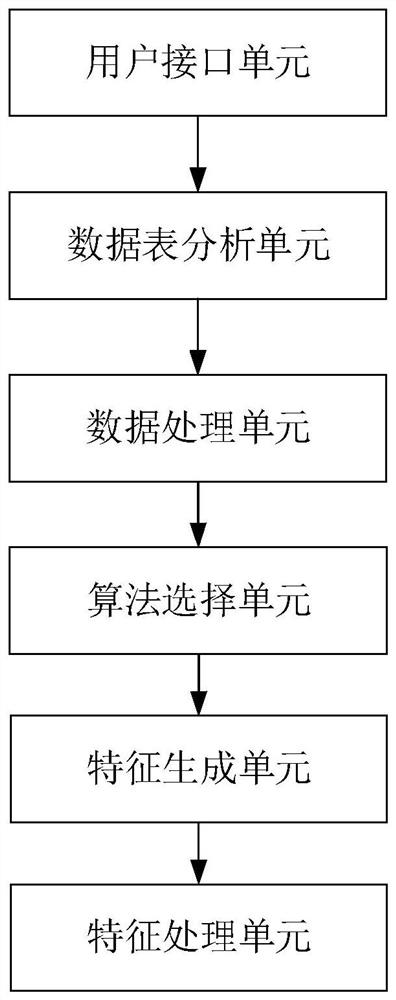
本发明提出一种自动特征生成系统,包括:数据表分析单元,用于对用户输入的数据表进行分析;用户接口单元,用于呈现数据表分析单元的分析结果,并接收用户的选择的使用字段,以及接收用户配置的数据表关联关系;数据处理单元,用于根据数据表关系结构提取样本对应的数据;特征生成单元,根据数据表关系结构,选择合适的特征生成算法进行特征生成;特征处理单元,用于对生成的特征数据进行特征分析。
与现有技术相比,本发明的优点有:
(1)本发明的系统不要求使用人员有任何的技术能力和生成逻辑,仅需要提供少量关于使用哪些原始数据生成特征的信息,系统自动完成特征生成的全流程处理。
(2)本发明的系统集成对原始数据表的分析功能,自动分析原始数据的数据类型、统计指标,并对每个数据字段自动给出是否建议使用的建议。该功能帮助使用者详细了解所选原始数据的基本情况,帮助判断使用该原始数据进行特征生成是否合理。
(3)本发明的系统集成数据提取、清洗加工功能,自动根据用户指定的数据表及其关系,从原始数据表中提取样本对应的数据。可选的,系统可以自动的完成数据清洗、数据回溯、数据分窗等功能。
(4)本发明的系统集成多种特征生成算法,自动根据用户指定的数据表及其关系,选择合适的算法进行特征加工。不同的特征生成算法保证了不同形式的数据表,如关系型数据表、宽表型数据表,都能够被正确的处理并生成效果较好的特征。
(5)本发明的系统集成特征分析功能,自动对生成的特征进行分析和评价,系统会根据样本是否带有标签,选择合适的有监督或无监督指标进行计算,并根据用户的要求保留最优的特征。
(6)本发明的系统支持对大数据的分布式处理,能够自动根据数据量的大小,调整算法中的参数设置。
附图说明
为了更容易理解本发明,将通过参照附图中示出的具体实施方式更详细地描述本发明。这些附图只描绘了本发明的典型实施方式,不应认为对本发明保护范围的限制。
图1为本发明的系统的一个实施例的结构原理图。
图2为本发明的系统的另一个实施例的流程图。
图3为本发明的系统的一个实施例的数据表。
图4为本发明的系统的另一个实施例的数据表。
图5为本发明的方法的另一个实施例的流程图。
具体实施方式
下面参照附图描述本发明的实施方式,其中相同的部件用相同的附图标记表示。在不冲突的情况下,下述的实施例及实施例中的技术特征可以相互组合。
图1显示了本发明的方法的流程图。图2显示了本发明的方法的一个实施例的流程图。下面参照图1-2来描述本发明。如图1所示,本发明的系统包括用户接口单元、算法选择单元、数据表分析单元、数据处理单元、特征生成单元、特征处理单元。
用户接口单元接受用户输入(例如通过用户界面上传或选择)的样本文件,样本文件为包含任务目标主体的数据,如姓名、手机号。
用户接口单元还用于接受用户输入(例如通过用户界面上传或选择)的数据表,数据表包含了样本目标主体的各种数据,如年龄、性别、资产等。此处用户可以选择多张数据表。
数据表分析单元,用于对用户输入的数据表进行分析,包括:
1)当数据表太大时,对数据表进行随机抽样。
2)对抽样的数据每一列进行字段类型判断,得到每一列字段最可能的数据类型,包括的数据类型有:数值型、离散型、分类型、时间型、ID型、字符型等。
3)对每一列字段,根据判断出的数据类型,计算对应的统计指标,如:数值型字段计算最大值、均值、方差、峰度等,字符型字段计算字符串最大长度、字符串是否包含中文等。
4)对每一列字段,根据判断的数据类型以及对应的统计指标,判断是否建议使用该字段,如:离散型字段的众数占比超过90%则不建议使用该字段、数值型字段的空值率超过90%则不建议使用该字段等。
5)对以上内容生成数据表报告,展示字段、数据类型、是否建议使用、统计指标。
数据表分析单元将分析结果传输给用户接口单元,用户根据数据表分析结果选择使用字段,如不做修改则可按报告给出的建议进行下一步。
用户接口单元接收用户配置的数据表关联关系,从而确定各个表之间是如何进行关联的,如样本表.phone=数据表1.mobile,即用户告知系统样本表的phone字段与数据表1的mobile字段关联,该两列是标识同样的信息。当用户选择多张数据表时,存在数据表和数据表关联的情况,如数据表1.product_id=数据表2.product_id,即数据表1的product_id字段与数据表2的product_id字段标识相同的信息,此时用户配置完成后,会生成较深的纵向连接关系,如图3所示,此时该任务的数据表为关系型数据表。当用户选择一张数据表时,此时仅产生一层的纵向连接关系,如图4所示,此时该任务的数据表为宽表型数据表。
可选的,用户接口单元接收用户配置的其它参数,如:缺失值填充、生成特征数量等,如不配置则按照默认值进行处理。
用户配置的数据表关系和参数由用户接口单元传输给数据处理单元。数据处理单元根据数据表关系结构提取样本对应的数据。具体地,数据处理单元从样本表开始,通过关联关系从上至下,顺序地把每张数据表中包含的上一张表中的关联字段的数据抽取出来。
可选的,若样本中包括了回溯时间字段,且数据表指定了更新时间字段,则数据处理单元对抽取出的数据进行回溯。回溯是指从数据表中仅提取更新时间小于其归属于的样本的回溯时间。
可选的,若用户配置了数据清洗规则,如:缺失值填充、数据值范围归一化等,数据处理单元对抽取出的数据应用对应的处理算法进行处理。
可选的,若用户配置了时间窗,如:10天、30天、180天,用户可一次配置多个时间窗,则数据处理单元自动对抽取出的数据用最大的时间窗进行过滤。
数据处理单元处理后的数据被传输给算法选择单元。算法选择单元用于当用户选择多张数据表时,根据表的数量和关系再选择合适的特征生成算法。所有的算法的输入都为数据处理单元抽取并处理后的数据、用户配置参数、程序配置参数等,输出都为生成的特征数据、程序运行参数、程序运行日志等。
对于算法的选择方法,可以根据需要来设定,在一个实例中,可以通过如下判定方法来选择算法:当数据表为宽表型数据时,选择宽表型数据的特征生成算法;当数据表为关系型数据时,若关联关系较深时(如大于3层)则采用关联关系较深的特征生成算法,若关联关系较浅是则采用关联关系较浅的特征生成算法。
特征生成单元用于运行算法选择单元选择的算法,生成特征数据、程序运行参数、程序运行日志等。
特征生成单元处理后的数据传输到特征处理单元,特征处理单元对生成的特征数据进行特征分析,分析包括覆盖率、零值率等统计指标,若样本中包括了标签字段,则还会分析包括特征KS、IV、卡方值等效果指标。
可选的,若用户配置了生成特征数量时,或生成特征的数量大于默认数量时,则特征处理单元将数据对生成的特征进行筛选。根据样本中是否包括了标签字段,若包括则根据特征的效果指标进行排序,选择效果较优的特征保留;若不包括则根据统计指标进行排序,选择统计指标较优的特征保留。筛选后保留的特征会进行保存。
特征处理单元处理后的结果传输给用户接口单元,在用户界面进行显示,并且最终生成特征的保存地址。
本发明的系统可以对接底层数据库系统,从原始数据中生成特征,对数据的要求更低。本发明的系统从数据抽取到最终的生成特征全部流程都进行了自动化处理,无需人工干预,可生成满足数量要求的,有较优效果的特征数据。本发明的系统大幅降低了使用用户的技术要求,非专业人员也可以方便快捷的使用本发明的系统进行特征生成,本发明的系统更加人性化、易操作化、高效化。本发明的系统全部基于分布式本发明的系统开发,可处理大规模数据,保证了处理的高效。
而且,本发明的系统经过开发、测试,处于商业化过程中,测试使用结果表明本发明的系统达到了预期目的,能够大幅提高特征开发的效率,并大幅降低了特征开发的难度,本发明的系统运行稳定可靠,能够满足大数据运算需要。
相对应的,如图5所示,本发明提出一种自动特征生成方法,包括:S1,对用户输入的数据表进行分析;S2,呈现数据表分析单元的分析结果,并接收用户的选择的使用字段,以及接收用户配置的数据表关联关系;S3,根据数据表关系结构提取样本对应的数据;S4,根据数据表关系结构,选择合适的特征生成算法进行特征生成;S5,对生成的特征数据进行特征分析。
进一步,本发明的方法还包括当用户选择多张数据表时,根据表的数量和关系选择不同的特征生成算法。
进一步,在步骤S1中,当数据表太大时,对数据表进行随机抽样。对抽样的数据每一列进行字段类型判断,得到每一列字段最可能的数据类型。对每一列字段,根据判断出的数据类型,计算对应的统计指标。对每一列字段,根据判断的数据类型以及对应的统计指标,判断是否建议使用该字段。
其中,所述数据类型包括:数值型、离散型、分类型、时间型、ID型和字符型。所述统计指标包括:数值型字段计算最大值、均值、方差、峰度等,字符型字段计算字符串最大长度、以及字符串是否包含中文;
当离散型字段的众数占比超过90%则不使用该字段、数值型字段的空值率超过90%则不使用该字段。
以上所述的实施例,只是本发明较优选的具体实施方式,本领域的技术人员在本发明技术方案范围内进行的通常变化和替换都应包含在本发明的保护范围内。
- 一种自动特征生成系统和方法
- 一种基于铭牌图像特征的秘钥生成系统及方法