车联网中一种面向用户服务体验的内容分级优化缓存方法
文献发布时间:2023-06-19 10:22:47
技术领域
本发明属于车辆网技术领域,具体涉及车联网中一种面向用户服务体验的内容分级优化 缓存。
背景技术
近年来,随着车载应用的快速发展,娱乐内容越来越受到乘坐公共车辆出行的乘客的欢 迎。因此,乘客产生的大量内容请求导致城市公共交通系统中的通信需求迅速增加。此外, 传统云服务器与公共交通车辆之间的距离较远,回程链路容量有限会增加用户获取内容的时 延,从而严重影响用户体验。幸运的是,在车辆边缘节点缓存热门的内容被认为是缓解这一 问题的有效方法。
一些研究学者提出在城市公共交通系统中,为公共车辆(公交车、地铁等)配备服务器, 使其成为具有一定存储和计算资源的MPS(Mobile Public Server,移动公共服务器),从而能 够为车内乘客提供内容服务。然而,MPS的资源有限,无法在高峰时段处理大量的内容请求。 通信链路的拥挤导致通信延迟较长,极大地影响了乘客的体验。此外,由于公共车辆行驶跨 越多个地区,且车内的乘客由于上下车行为不断流动,因此导致车内乘客的内容偏好变化, 这意味着MPS需要不断调整其缓存的内容,以满足更多的乘客需求。
目前,针对边缘设备存储空间有限的问题,一些基于DRL(Deep ReinforcementLearning, 深度强化学习)的内容替换策略被提出。参考文献[1]利用基于学习的方法设计了一种多层缓 存机制,它基于车辆移动性来预测内容请求分布,结合深度学习方法生成RSUs(Road Side Units,路侧单元)中缓存内容的决策,使移动用户在到达RSUs覆盖范围时立即获得到目标 内容,从而减小内容获取时延,减少带宽消耗。参考文献[2]提出仅根据时变的请求和基站缓 存的内容,利用DRL方法来动态更新内容缓存,并且为了提高系统的决策能力对相关方法进 行了改进,使得该方法具有比最少使用、先进先出和基于深度Q网络方法更高的缓存命中率。 参考文献[3]利用DRL方法设计了基于车辆间内容分享的最优内容缓存方案。参考文献[4]提 出了一种协作式的边缘缓存策略,利用深度确定性策略梯度方法联合优化宏蜂窝基站、RSU 和智能车辆之间的内容替换和内容分发。现有的采用移动车辆和RSU/基站联合提供内容服务 的方式,大多考虑如何将完整的内容通过何种服务器传输给用户,较少考虑MPS的存储容量 有限,且较少考虑由MPS和RSU分别提供相同内容的不同内容切片。同时,现有的车辆内 容缓存的研究中,大多仅考虑单个RSU/基站/车辆的内容更新策略,较少同时考虑了车辆的 移动性以及车辆上用户的流动性带来的内容偏好变化。
参考文献:
[1]Z.Zhao,L.Guardalben,M.Karimzadeh,J.Silva,T.Braun and S.Sargento,"Mobility Prediction-Assisted Over-the-Top Edge Prefetching for HierarchicalVANETs,"in IEEE Journal on Selected Areas in Communications,vol.36,no.8,pp.1786-1801,Aug.2018.
[2]P.Wu,J.Li,L.Shi,M.Ding,K.Cai and F.Yang,"Dynamic Content Updatefor Wireless Edge Caching via Deep Reinforcement Learning,"in IEEECommunications Letters,vol.23,no.10, pp.1773-1777,Oct.2019.
[3]Y.Dai,D.Xu,K.Zhang,S.Maharjan and Y.Zhang,"Deep ReinforcementLearning and Permissioned Blockchain for Content Caching in Vehicular EdgeComputing and Networks,"in IEEE Transactions on Vehicular Technology,vol.69,no.4,pp.4312-4324,April 2020.
[4]G.Qiao,S.Leng,S.Maharjan,Y.Zhang and N.Ansari,"Deep ReinforcementLearning for Cooperative Content Caching in Vehicular Edge Computing andNetworks,"in IEEE Internet of Things Journal,vol.7,no.1,pp.247-257,Jan.2020.
发明内容
本发明为了解决MPS存储容量小的问题,提出了一种面向用户服务体验的内容分级优化 缓存方法,采用MPS和RSU协同传输的缓存策略,利用命中率QoE-CSC(基于QoE的内容 切片缓存)技术来最大化系统QoE(Quality of Experience,体验质量)命中率,已优化内容缓 存策略。
本发明提供的车联网中面向用户服务体验的内容分级优化缓存方法,应用的车联网场景 中,在公共车辆中设置有MPS,在车站处设置有路侧单元RSU;其中,将车联网系统中的需 要缓存的内容文件进行切片,MPS为乘客提供内容的开始部分,RSU提供剩下的内容切片。
为了更准确地评估用户体验,本发明定义QoE命中率,其表示乘客从MPS和RSU成功获取完整内容的概率。由于客流的变化会导致内容偏好的不同,MPS缓存的内容片段需要定期被更换,因此本发明通过最大化QoE命中率来获取MPS的缓存策略。本发明方法设需要 缓存F个内容文件,每个内容文件大小均为D,内容可观看时长为τ,将每个内容文件切成 相等大小的N片;设MPS缓存f的z
步骤1,对公共车辆的移动、乘客的内容请求以及车联网中的无线信道进行建模,然后 建立最大化体验质量QoE命中率以获得内容切片缓存策略的目标函数;
所述的QoE命中率是指乘客从MPS和RSU成功获取完整内容的概率,表示为
其中,K表示车站数量;U
步骤2,利用深度强化学习网络DQN进行内容切片缓存策略优化,包括:
(1)在训练DQN阶段,包括:初始输入的状态为车辆MPS采用均匀缓存策略存储各内容切片;车辆MPS在车站间行驶途中接收乘客的内容请求,当车辆到达下一车站时,MPS选择一个可行动作,动作是指MPS中对各内容文件的切片缓存的数量进行更新;MPS根据 缓存命中情况(即QoE命中率)计算当前动作的即时收益,并将当前的状态、动作以及即时 收益记录存入回放池中;从回放池中抽取一定数量的记录,计算下一状态及未来收益,得到当前状态下的理想Q值,并以理想Q值为基准,按照梯度下降策略对Q网络进行训练,使 得网络收敛。
(2)车辆不断的重复上述过程,经过一定次数后,网络区域稳定,MPS此时可以通过向Q网络输入当前所处的状态,从而获取最佳的缓存替换动作,从而提高站点1~K间的缓存命中率。
相对于现有技术,本发明的优点与积极效果在于:(1)本发明方法基于内容切片缓存策 略最大化系统的QoE命中率,可调整MPS缓存的内容种类和内容片段比例,以适应因客流 变化而导致的内容偏好变化,使更多乘客获得所需的内容开头切片,同时降低了缓存替换成 本,与现有方法相比,本发明方法在具有高QoE命中率的同时具有更小的缓存成本。(2)本 发明方法提高了MPS缓存容量的利用效率,仿真实验结果表明,在MPS具有不同缓存容量 的情况下,本发明方法的缓存命中率均高于现有对比方法,即本发明方法可以较好地利用MPS 的缓存容量。(3)本发明方法提高了MPS的QoE命中率,仿真实验结果表明,与LRU和LFU基准方法相比,本发明方法能更好的学习和预测各地区的内容流行度,从而提前使MPS缓存相应的内容,提高QoE命中率,用户服务体验效果更好。
附图说明
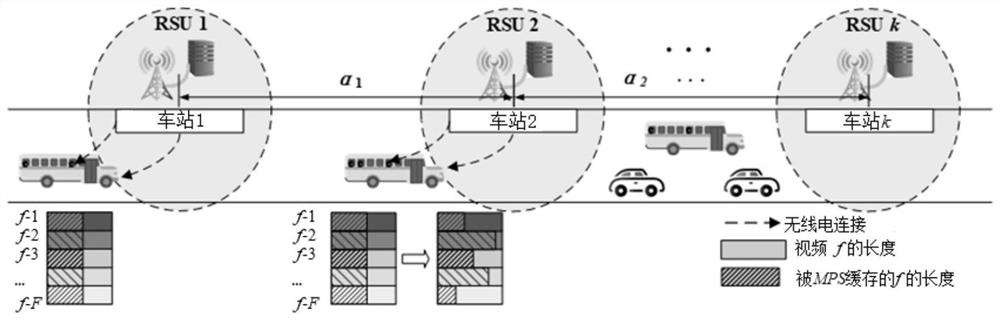
图1是本发明实施例的应用场景示意图;
图2是本发明方法的一个实现流程图;
图3是本发明实施例中MPS存储相同数量内容切片时的QoE命中率示意图;
图4是本发明实施例中MPS存储不同数量内容切片时的平均QoE命中率示意图;
图5是本发明实施例中MPS存储不同数量内容切片时的平均缓存成本示意图;
图6是本发明方法的收敛性能示意图。
具体实施方式
下面将结合附图和实施例对本发明作进一步的详细说明。
本发明针对MPS存储容量有限,乘客流动性强等问题,提供了车辆网中一种面向用户服 务体验的内容分级优化缓存方法,采用MPS和RSU协同传输的缓存策略,MPS为乘客提供内 容的开始部分,RSU提供剩下的内容切片;然后考虑到乘客从MPS和RSU分别获取内容切片, 定义了QoE命中率,它表示MPS和RSUs共同成功向乘客提供相应内容片段的概率,进而实现 一种基于QoE的内容切片缓存(Content Segments Caching,内容切片缓存)策略,可以准确地 评估用户体验。本发明利用深度强化学习网络DQN对车辆MPS的内容切片缓存策略进行优 化,在训练DQN网络收敛后,每次车辆从当前车站出发向下一车站行驶过程中,收集车内乘 客的内容请求,在到达下一车站后,将当前MPS的内容切片缓存状态输入DQN网络中,计算 输出QoE命中率最大的动作,更新MPS的内容切片缓存策略。
本发明的应用场景中所包含的装置如下:
公共车辆:包括公交车、有轨电车和地铁等公共交通工具;车内部署具有存储、计算和 通信能力的服务器,被称为MPS。MPS缓存各种内容的开头内容切片,为车内乘客提供内容 服务。
车站:公共车辆行驶一段时间后停靠的站点,乘客在此处上下车。车站一般依据交通部 门的设定设置在城市各区域。
RSU:部署在车站处,缓存系统中所有种类的内容以及其全部切片,在公共车辆停靠车 站时,可以为车内的乘客提供内容服务,可以和MPS之间进行通信。
如图1所示,是本发明研究的一个由公共车辆和RSUs构成的典型公共交通网络场景,K 个站点以间距L均匀分布在城市公路主干道上,站点标号k={1,2,...,K},每个站点处均部署 一个RSU。公交车站i即第i个公交车站。车联网系统中存在F类内容文件,设每个内容文 件大小均为D,内容可观看时长为τ。任意内容文件f∈F,均可以被切割为长度相等的N个 切片,设文件f被切分为f
首先,建立公共车辆移动模型,以公交车为例,设公交车在相邻两公交车站之间做匀速 直线运动,速度为v,那么在两站间的移动时间T
T
设公交车停靠公交车站的时间为T
然后依据齐夫定律建立内容请求模型。通常,同一地区的用户对于不同内容的请求概率 p
其中,p
在现有文献中,往往设定用户对内容的请求概率服从单一参数的ZipF分布。然而,在本 发明中,由于公共车辆处于不断行驶—靠站—行驶的过程中,跨越了不同的地区,其中乘客 也因为上下车行为不断流动。因此,设相邻两公交车站之间的内容请求分布遵循不同参数α的 齐夫分布,如图1所示,即在不同公交站之间,公交车接收到乘客的内容请求服从不同参数α 的齐夫分布。
考虑到乘客在公交车停靠公交车站时的上、下车行为,因此单位时间内MPS接收到的 乘客内容请求的总次数会发生变化。设MPS在第i个公交站与第i+1个公交站之间接收到的用户请求总次数为U
其中,λ为泊松分布参数,
车联网中的无线信道服从瑞利分布,所以本发明将乘客与RSU之间的信道建模为瑞利衰 落信道。当公交车停靠公交车站时,设公交车与公交车站间的距离为d,路径损耗用d
其中,B表示传输带宽,P表示公交车站处RSU的发送功率,N
同样,MPS与RSU之间的无线传输信道服从瑞利分布,二者之间的距离与用户和RSU之间的距离相同,为d,那么,在公交站处MPS与RSU之间的传输速率r
r
采用本发明方法时,乘客首先从MPS处获取内容开头的切片,在公交车从第i个公交车 站行驶至第i+1个公交车站的过程中,乘客对内容f的请求在
因此,MPS应该为该乘客提供的内容切片数量
其中,
考虑到此时MPS缓存的内容f的切片数为z
因此,乘客向RSU请求的内容切片数量
结合传输速率和停车时间,可以得到乘客从公交车站处的RSU获得的最大传输容量
上式中,P
当车辆停靠第i个公交车站时,车辆上MPS检查自身存储的内容并进行更新,由MPS与RSU之间的传输速率可知,在
那么如果MPS在第i个公交站替换
同时,替换的切片数量不得超过MPS的最大存储空间:
在本发明应用场景中,由于乘客分别从MPS和RSU请求相同内容的不同切片。因此,缓存命中失败有以下两种情况:1)当MPS缓存的内容切片数量不足以支撑乘客播放时,缓存命中失败;2)当乘客无法在停车时间内从RSU获取剩下的内容切片时,缓存命中失败。 基于此,本发明提出一种符合当前内容切片场景的用户体验QoE的缓存命中率。本发明定义QoE命中率为:乘客在特定的时间内从MPS和RSU成功获取完整内容的概率。
首先,将MPS命中乘客请求的概率定义为初次命中率
其中,
即,当乘客请求的内容f前
其次,在公交车停靠第i个公交站时,乘客需要在有限停车时间
即,若乘客能够在有限的停车时间
那么,只有满足以上两个条件时,即
进一步地,本发明将QoE命中率与MPS缓存的各内容切片数量紧密相关。由于MPS存储空间有限,所以需要定期更新自身的缓存内容,以更好地为乘客提供服务。在公交车到达公交车站进行内容更新的过程中,忽略乘客与RSU以及公交车与RSU建立通信连接的时间,将目标函数定义为每次MPS更新切片内容后的QoE命中率,如下:
上面目标函数表示,对两个车站间行驶的公共车辆,求取最大化QoE命中率时的MPS 的缓存策略。
为了最大化系统的QoE命中率,本发明利用深度Q学习网络(Deep Q-learningNetwork, DQN)方法探求公交车内容切片的最佳缓存策略。DQN是一种融合了神经网络和Q-learning 的方法,它利用神经网络预测Q值,并通过不断更新神经网络从而学习到最优的策略。DQN 的基础是马尔科夫过程,马尔科夫决策过程一般由四元组<S,A,P,R>描述,其中代理agent 是MPS,S表示状态空间,A是动作空间,P是转移概率,R是奖励函数,表示当前状态下 执行动作后的奖励。由于乘客的流动性较大,难以使用确定性的转移概率P来描述状态之间 的变化,因此,本发明利用基于值的DQN中的状态-动作价值函数来间接描述转移概率的大 小。
状态空间S的说明。状态是代理当前所处现实环境的一种客观描述。本发明中,状态代 表MPS中各类内容切片的缓存比例。公交车到达第i+1个公交车站前的MPS缓存状态用s
s
其中0≤z
在系统初始阶段,由于公交车位于起始公交车站,服务器未收到乘客的任何内容请求信 息,因此服务器采用均匀缓存策略,即,对每一种内容f均缓存前N
动作空间A的说明。在公交车行驶过程中,由于各个公交站点之间乘客的分布及数量不 同,因此对于内容的需求也不相同。为了最大化系统的QoE命中率,在每一次靠站时,MPS 需要对当前缓存的内容切片进行调整,增加或者删除一部分内容切片。因此,代理中的动作 空间被定义为a
a
其中,0≤h
奖励函数R的说明。r
基于状态空间、动作空间和奖励,DQN由当前Q网络、目标Q网络和经验回放三个模块组成。当前Q网络和目标Q网络的网络结构相同但是参数不相同,当前Q网络负责根据 当前的状态s
本发明实现的面向用户服务体验的内容分级优化缓存方法,通过QoE-CSC技术更新MPS 的缓存内容,如图3所示,整体流程包括以下步骤,。
步骤1,在DQN网络训练阶段,初始化公共车辆MPS的缓存内容;设需要缓存F个内容文 件,MPS中采用均匀缓存策略缓存F个内容文件的开头切片,同时对深度强化学习网络的各项 参数进行初始化。
步骤2,初始化公交车站编号及位置,本发明实施例中有K个公交车站。
步骤3,公共车辆从当前车站向下一车站行驶,收集车内乘客的内容请求信息,计算相应 的QoE命中率。在训练阶段,本发明中对乘客的内容请求,使用Zipf分布和Poisson分布来描 述。在实际使用训练稳定的DQN网络的执行阶段,本发明可根据实际情况统计内容请求信息。
步骤4,到达下一车站后,根据上述内容请求及QoE命中率更新深度强化学习网络,并根 据深度强化学习网络对MPS的缓存内容进行替换。在训练阶段,Q网络将当前的时刻的状态、 动作以及即时收益存入回放池中。
步骤5,在训练阶段,Q网络随机从中抽取一定数量的记录,根据状态s以及动作a计算 下一状态,并计算未来收益,从而得到理想的Q值。计算完毕后,将上述抽取的状态记录送 入Q网络中,并以理想Q值为基准,采用梯度下降方式对网络进行训练。
步骤6,在训练阶段,驶离当前车站,继续重复步骤3和4,直到到达终点站。
步骤7,在训练阶段,继续重复上述步骤2~6,直到达到设置的循环次数,或者判断网络 稳定了就停止训练过程,获得稳定的DQN网络。
本发明利用深度强化学习网络DQN进行内容切片缓存策略优化的一个伪代码算法实现 如下所示:
初始化F,N,N
初始化经验回放池
初始化当前状态
随机初始化当前Q网络的参数ω;
初始化目标Q网络的参数ω′=ω;
For 1,2,…,M:
预处理序列φ
for i=1,2,…,K-1:
将φ(s
根据式
从A
根据动作a
使用Zipf分布和Poisson分布生成内容请求,获得即时回报r
更新状态s
从经验回放池
设置
对于(y
End for
End for
上述伪代码算法中:M代表设置的最大循环次数;φ(s
对本发明方法进行仿真实验。系统仿真参数设置如表1所示。相邻的两个公交站点之间 的内容受欢迎度遵循不同参数α的Zipf分布,α=[1.1,2.5,1.6,1.7,1.3,2.7,1.6,2.1,1.9,1.1]。公交 车从第一个公交车站行驶到第十个公交车站后立马返回第一个公交车站。此外,为了降低计 算复杂性,控制MPS每次替换的内容类型不超过三种。另外,根据表1设置的相关数据,计 算出每次替换的内容切片数不超过5个。
表1系统仿真参数设置
为了进行比较,使用最不频繁使用的(Least Frequently Used,LFU)和最近最少使用的(Least Recently Used,LRU)缓存策略作为本发明的对比方法。LFU方法缓存请求次数最多的内容, 每次替换掉最不常用的内容。LRU方法缓存最近请求次数最多的内容,每次替换掉最近最少 用到的内容。为了比较各种缓存方法的命中性能,LRU和LFU也被设置为每次替换不超过5 个切片。仿真结果如图3~图6所示。
如图3所示,是MPS存储100个内容切片的情况下,其在十个公交车站点间的QoE命中率。图3的横坐标代表各公交车站,纵坐标代表QoE命中率。可以发现,本发明的QoE-CSC策略在第1—5公交站的QoE命中率略低于LFU和LRU缓存策略,但在第6—10公交站点 的QoE命中率明显高于LFU和LRU方法。此外,根据仿真结果数据计算得到,本发明的 QoE-CSC缓存方法的十站总QoE命中率为6.955,而LFU和LRU缓存方法的十站总QoE命 中率分别为5.49104和4.64264,远低于本发明方法。具体原因是本发明方法的目标是使十个 公交车站间的总QoE命中率达到最大,所以在开始阶段,本发明方法选择尽可能多缓存在整 个行驶过程中会被请求的内容切片内容。相比之下,LRU和LFU方法的目标是在当前站点获 得最大的QoE命中率,因此在开始时命中性能较好,但在后期,因为每次能够替换的内容切 片数量有限,所以LFU和LRU方法的QoE命中率迅速下降。
图4展示了MPS分别缓存40、60、80、100和120个内容切片的情况下,十个公交车站间的平均QoE命中率。图4的横坐标代表车辆MPS的缓存数据量,纵坐标代表公交车站的 平均QoE命中率。很明显地可以看出,本发明的QoE-CSC缓存方法的平均QoE命中率处于 0.6-0.7之间,并且随着缓存容量的增加先增加后趋于稳定,先增加是因为随着缓存容量增大,MPS能够缓存更多的内容切片,因此可以满足更多乘客的内容需求。后趋于稳定是因为MPS每次只能替换5个内容切片,所以其性能逐渐稳定。然而,LFU和LRU缓存方法的平均QoE 命中率并没有随着MPS缓存容量的增大而增加,这是因为LFU和LRU缓存方法主要依赖于 乘客的内容请求规律来执行相应的切片替换策略,具有一定的随机性,这也说明LFU和LRU 方法的性能不佳,缓存效果不稳定。另外,本发明的QoE-CSC缓存方法的平均QoE命中率 一直高于两种对比方法的平均QoE命中率,其中LFU方法的平均QoE命中率最高不及0.6, 最低甚至低于0.3,LRU方法的平均QoE命中率最高达到0.648,但是多数情况下低于本发明 缓存方法。造成这一现象的主要原因是本发明缓存方法能够不断地学习各个地区的内容流行 度,从而选择最优的内容切片替换策略,因此,本发明缓存方法比LFU和LRU缓存方法能 更好地利用缓存容量。
在MPS分别缓存40、60、80、100和120个内容切片的情况下,图5展示了MPS采用 三种不同方法在不同公交车站进行内容替换的平均缓存成本。图5的横坐标代表公交车站,纵坐标代表平均缓存成本,缓存成本即每站替换的切片数。可以发现,LFU和LRU方法在每一站都选择替换5个切片数,这是因为这两种方法的优化目标都是提高当前状态下的命中率, 所以需要尽可能多的替换内容切片。然而,本发明的QoE-CSC缓存方法的平均缓存代价比较 低,平均在3.6个切片,原因是通过对历史请求数据的训练,本发明方法会选择缓存在整个 过程中最受欢迎的一些内容切片,所以它不需要经常调整已缓存的内容。因此可知,本发明 方法能利用更低的通信资源获得了更好的命中性能。
图6表示的是本发明的QoE-CSC缓存方法在训练次数方面的性能。图6中,横坐标表示 训练次数,左侧纵坐标表示损失,右侧纵坐标表示奖励。训练损失是指神经网络在DQN中的损失,它随着训练次数的增加而减小,说明神经网络的准确性越来越高。奖励反映了状态- 行动奖励的积累,随着训练时间的增加,奖励也在增加,说明方法的性能更好。由图6可以 看出,本发明缓存方法随着训练次数的增加损失会减小,奖励会增加,并在训练测试达到一 定程度后,二者趋于稳定。
- 车联网中一种面向用户服务体验的内容分级优化缓存方法
- 车联网中一种面向用户服务体验的内容分级优化缓存方法