用于缓存分布式数据的智能网络接口控制器
文献发布时间:2023-06-19 11:52:33
技术领域
本申请涉及用于缓存分布式数据的智能网络接口控制器。
发明背景
嵌入是由多个条目组成的表格。每个条目可以与多个元素相关联。例如,嵌入表格可以由一百万个条目组成,其中每个条目由64个元素组成。嵌入表格可以用来表示不同的事物,例如电影、人、物品等。嵌入表格可用于推荐目的。例如,可以推荐与彼此相似的条目。嵌入表格可以存储在存储器中。然而,由于嵌入表格的大尺寸,嵌入表格可能使用大量的可用存储器。这可能降低系统性能,因为可以用于其他目的的存储器的一大部分被保留用于存储嵌入表格。
发明内容
本申请提供了以下内容:
1)一种网络接口控制器系统,包括:
网络接口,其被配置为与网络连接并接收对来自分布式表格的数据的请求;
计算机接口,其被配置为向连接到所述网络接口控制器系统的主计算机系统提供数据;
高速缓存,其被配置为缓存所述分布式表格的数据;以及
控制器,其被配置成:
将对来自所述分布式表格的数据的请求识别为要由所述网络接口控制器系统而不是所述主计算机系统的处理器处理的请求;
经由所述计算机接口从所述主计算机系统的存储器请求和接收所请求的数据;以及
使接收到的所请求的数据缓存在所述网络接口控制器系统的所述高速缓存中。
2)根据1)所述的网络接口控制器系统,其中,所述分布式表格是嵌入表格。
3)根据1)所述的网络接口控制器系统,其中,所述网络接口被配置为向第二主计算机系统提供接收到的所请求的数据。
4)根据3)所述的网络接口控制器系统,其中,所述网络接口被配置成从所述第二主计算机系统接收所提供的数据的更新。
5)根据4)所述的网络接口控制器系统,其中,所述控制器被配置为更新来自缓存在所述网络接口控制器系统的高速缓存中的所述分布式表格的数据。
6)根据5)所述的网络接口控制器系统,其中,所述控制器被配置为基于所提供的数据的所述更新来更新所述主计算机系统的所述存储器。
7)根据1)所述的网络接口控制器系统,其中,所述主计算机系统和第二主计算机系统被包括在分布式计算系统中。
8)根据1)所述的网络接口控制器系统,其中,所述主计算机系统的所述存储器被配置成存储所述分布式表格的一部分。
9)根据8)所述的网络接口控制器系统,其中,对来自所述分布式表格的数据的所述请求是针对所述分布式表格的所述一部分的子集。
10)根据8)所述的网络接口控制器系统,其中,对来自所述分布式表格的数据的所述请求是针对所述分布式表格的整个部分。
11)根据1)所述的网络接口控制器系统,其中,所述控制器被配置为基于与所述请求相关联的头部将对来自所述分布式表格的数据的所述请求识别为要由所述网络接口控制器系统处理的请求。
12)根据1)所述的网络接口控制器系统,其中,所述网络接口被配置成接收对来自所述分布式表格的数据的第二请求。
13)根据12)所述的网络接口控制器系统,其中,所述控制器被配置为:
将对来自所述分布式表格的数据的所述第二请求识别为要由所述网络接口控制器系统处理的请求;以及
确定来自与所述第二请求相关联的所述分布式表格的所述数据是否被缓存在所述网络接口控制器系统的高速缓存中。
14)根据13)所述的网络接口控制器系统,其中,响应于确定来自与所述第二请求相关联的所述分布式表格的所述数据被缓存在所述网络接口控制器系统的所述高速缓存中,所述控制器被配置为:
从所述网络接口控制器系统的所述高速缓存检索来自与所述第二请求相关联的所述分布式表格的数据;以及
提供来自与所述第二请求相关联的所述分布式表格的所述数据。
15)根据13)所述的网络接口控制器系统,其中,响应于确定来自与所述第二请求相关联的所述分布式表格的所述数据没有被缓存在所述网络接口控制器系统的所述高速缓存中,所述控制器被配置为经由所述计算机接口向所述主计算机系统提供所述第二请求。
16)一种方法,包括:
在网络接口控制器系统处接收对来自分布式表格的数据的请求;
将对来自所述分布式表格的数据的所述请求识别为要由所述网络接口控制器系统而不是主计算机系统的处理器处理的请求;
经由所述网络接口控制器系统的计算机接口从所述主计算机系统的存储器请求和接收所请求的数据;以及
使接收到的所请求的数据被缓存在所述网络接口控制器系统的高速缓存中。
17)根据16)所述的方法,还包括将接收到的所请求的数据提供到第二主计算机系统。
18)根据16)所述的方法,其中,对来自所述分布式表格的数据的所述请求基于与所述请求相关联的头部被识别为要由所述网络接口控制器系统处理的请求。
19)根据16)所述的方法,还包括:
接收对来自所述分布式表格的数据的第二请求;
将对来自所述分布式表格的数据的所述第二请求识别为要由所述网络接口控制器系统处理的请求;以及
确定来自与所述第二请求相关联的所述分布式表格的所述数据是否被缓存在所述网络接口控制器系统的所述高速缓存中。
20)一种非暂时性计算机可读存储介质,其包括存储在其上的计算机指令,所述计算机指令当由处理器执行时使所述处理器执行以下操作:
在网络接口控制器系统处接收对来自分布式表格的数据的请求;
将对来自所述分布式表格的数据的请求识别为要由所述网络接口控制器系统而不是主计算机系统的处理器处理的请求;
经由所述网络接口控制器系统的计算机接口从所述主计算机系统的存储器请求和接收所请求的数据;以及
使接收到的所请求的数据被缓存在所述网络接口控制器系统的高速缓存中。
附图简述
在下面的详细描述和附图中公开了本发明的各种实施例。
图1是示出根据一些实施例的分布式计算系统的框图。
图2是示出网络接口控制器的实施例的框图。
图3是示出分布式表格的实施例的表格。
图4是示出根据一些实施例的机器学习模型的框图。
图5是示出用于机器学习的过程的实施例的流程图。
图6是示出用于检索数据的过程的实施例的流程图。
图7是示出用于检索数据的过程的实施例的流程图。
图8是示出用于更新分布式表格的过程的实施例的流程图。
图9是示出用于更新机器学习模型的过程的实施例的流程图。
详细描述
本发明可以以多种方式实现,包括作为过程;装置;系统;物质的组成;体现在计算机可读存储介质上的计算机程序产品;和/或处理器,例如被配置为执行存储在耦合到处理器的存储器上和/或由该存储器提供的指令的处理器。在本说明书中,这些实现或者本发明可以采取的任何其他形式可以被称为技术。通常,在本发明的范围内,可以改变所公开的过程的步骤顺序。除非另有说明,否则被描述为被配置成执行任务的诸如处理器或存储器的组件可以被实现为在给定时间被临时配置为执行任务的通用组件或者被制造为执行任务的特定组件。如本文所使用的,术语“处理器”指的是被配置成处理数据(例如计算机程序指令)的一个或更多个设备、电路和/或处理核心。
下面连同说明本发明原理的附图一起提供本发明的一个或更多个实施例的详细描述。结合这些实施例描述本发明,但是本发明不限于任何实施例。本发明的范围仅由权利要求限定,并且本发明包括许多替代方案、修改方案和等价方案。为了提供对本发明的全面理解,在以下描述中阐述了许多具体细节。这些细节是出于示例的目的而提供的,并且本发明可以根据权利要求来实施,而不需要这些具体细节中的一些或全部。为了清楚起见,没有详细描述与本发明相关的技术领域中已知的技术材料,以便本发明不被不必要地模糊。
分布式计算系统可以由多个主计算机系统组成。每个主计算机系统可以具有相应的处理器(例如CPU、GPU等)和相应的存储器。每个主计算机系统可以耦合到相应的网络接口控制器(NIC)。在一些实施例中,NIC集成到主计算机系统内(例如扩展卡、可移除设备、集成在主板上等)。在一些实施例中,NIC经由计算机总线(例如PCI、PCI-e、ISA等)连接到主计算机系统。NIC被配置为提供到与它相关联的主计算机系统的网络接入(例如以太网、Wi-Fi、光纤、FDDI、LAN、WAN、SAN等)。
多个主计算机系统中的每一个可以被配置成实现相应的机器学习模型以输出相应的预测。由分布式计算系统实现的机器学习模型的例子包括但不限于神经网络模型、深度学习模型等。机器学习模型可以由多个层组成。每一层可以与相应的权重相关联。输入数据可以应用于机器学习模型的初始层。初始层的输出可以被提供作为机器学习模型的下一层的输入。向前传递可以继续,直到机器学习模型的最后一层接收到来自机器学习模型的倒数第二层的输出作为输入。机器学习模型的最后一层可以输出预测。
分布式计算系统的每个主计算机系统可以被配置成实现不同版本的机器学习模型,即,与机器学习模型的每一层相关联的权重可以不同。例如,第一机器学习模型可以具有与第一层相关联的第一权重,第二机器学习模型可以具有与第一层相关联的第二权重,······,以及第n机器学习模型可以具有与第一层相关联的第n权重。第一机器学习模型可以具有与第二层相关联的第一权重,第二机器学习模型可以具有与第二层相关联的第二权重,······,以及第n机器学习模型可以具有与第二层相关联的第n权重。第一机器学习模型可以具有与第n层相关联的第一权重,第二机器学习模型可以具有与第n层相关联的第二权重,······,以及第n机器学习模型可以具有与第n层相关联的第n权重。
分布式计算系统可以将与嵌入表格相关联的数据应用于主计算机系统的每个相应的机器学习模型。在单个主计算机系统中存储与嵌入表格相关联的数据可能使单个主计算机系统的资源负担过重。例如,存储与嵌入表格相关联的数据可能使用单个主计算机系统的可用存储器的一大部分。这可能降低单个主计算机系统的系统性能,因为可以用于其他目的的存储器的该大部分被保留用于存储嵌入表格。为了减少在单个主计算机系统上的负担,与嵌入表格相关联的数据可以分布在多个主计算机系统中,使得每个主计算机系统存储分布式表格的一部分。
第一主计算机系统可以从分布式计算系统的其他主计算机系统中的每个请求数据,并且接收所请求的数据以执行向前传递。例如,第一主计算机系统可以请求由分布式计算系统的第二主计算机系统存储的分布式表格部分的一些或全部。该请求可以在第二主计算机系统的NIC处被接收。该请求可以从第二主计算机系统的NIC提供到第二主计算机系统的处理器。响应于该请求,第二主计算机系统的处理器可以执行查找,并且从第二主计算机系统的存储器检索所请求的数据,并且经由第二主计算机系统的NIC将所请求的数据提供到第一主计算机系统。
在所请求的数据从其他主计算机系统中的每个被接收到之后,第一主计算机系统可以将接收到的数据与和它的分布式表格部分相关联的数据组合以为第一主计算机系统的机器学习模型生成输入数据集。输入数据集可以应用于与第一主计算机系统相关联的机器学习模型。与第一主计算机系统相关联的机器学习模型可以输出预测。第一主计算机系统可以基于它的预测来接收反馈。例如,第一主计算机系统可以预测与社交媒体平台相关联的用户对特定产品感兴趣,并且第一主计算机系统可以(直接或间接)从用户接收指示用户是否对特定产品感兴趣的反馈。
第一主计算机系统可以使用该反馈来更新它的相应机器学习模型。例如,第一主计算机系统可以使用反馈来更新与机器学习模型的多个层中的每一个相关联的权重。第一主计算机系统也可以使用反馈来更新它的相应分布式表格部分。例如,分布式表格的条目可以表示用户的兴趣。可以基于反馈来调整条目的元素值以提供对用户兴趣的更准确的表示。
当第一主计算机系统正在执行向前传递以输出预测时,分布式系统的其他主计算机系统也可以并行地执行相应的向前传递以输出相应的预测。其他主计算机系统也可以基于它们的相应预测来接收相应的反馈,并使用相应的反馈来更新它们的相应模型和相应分布式表格部分。
更新主计算机系统的相应机器学习模型可以包括主计算机系统执行权重梯度通信并共享与每个机器学习模型层相关联的相应权重以确定每个机器学习模型层的共同权重。例如,第一主计算机系统可以向其他主计算机系统提供与机器学习模型的最后一层相关联的已更新权重。其他主计算机系统可以向第一主计算机系统提供与机器学习模型的最后一层相关联的相应已更新权重。主计算机系统,即第一主计算机系统和其他主计算机系统,可以为机器学习模型的最后一层确定共同权重。每当机器学习模型的一层被更新时,主计算机系统可以执行该过程。主计算机系统可以共同确定分布式表格的已更新值。例如,分布式表格可以是表示实体的嵌入表格。嵌入的元素可以被更新以更准确地表示实体。已更新值可以经由与主计算机系统相关联的NIC提供到与主计算机系统相关联的处理器。响应于接收到已更新值,与主计算机系统相关联的处理器可以查找存储在存储器中的分布式表格部分,从存储器检索分布式表格部分,并用已更新值更新检索到的分布式表格部分。
在上述过程中的一个限制因素是每个处理器具有有限数量的核心。一些核心可用于执行计算操作。一些核心可用于执行通信操作。由处理器执行的每个查找操作具有相关查找时间,并且需要相关数量的通信核心。每当主计算机系统的处理器执行与由主计算机系统的存储器存储的它的分布式表格部分相关联的查找操作时,该处理器使用核心用于通信操作,而不是使用核心用于计算操作。这对于分布式计算系统来说可能产生瓶颈,因为不是使用核心来执行计算操作(例如,执行向前传递预测或确定在向后传播中的共同权重),核心将用于通信操作,因为多个主计算机系统可能正在从一主计算机系统请求与由该主计算机系统存储的分布式表格部分相关联的数据。主计算机系统的处理器可以并行地执行多个预测,进一步加剧了对计算核心的需求。分布式系统的每个主计算机系统都可能遇到这个问题,因为它们单独地执行向前传递预测和向后传播更新。
可以通过使用NIC以卸载由主计算机系统处理器执行的查找操作来减少瓶颈。NIC可以包括控制器和高速缓存存储装置。NIC可以向主计算机系统处理器发送对存储在主计算机系统的存储器中的分布式表格部分的一些或全部的请求。例如,该请求可以针对存储在主计算机系统的存储器中的分布式表格部分的最常见的条目。响应于该请求,主计算机系统处理器可以执行对所请求的分布式表格部分的查找,并且向NIC提供所请求的分布式表格部分。NIC可以将所请求的分布式表格部分存储在NIC的高速缓存存储装置中。例如,存储在主计算机系统的存储器中的分布式表格部分可以存储一百万个条目,以及存储在NIC的高速缓存存储装置中的分布式表格部分可以存储数千个条目。将分布式表格部分的一些条目存储在NIC的高速缓存存储装置中可以减少瓶颈,因为在主计算机系统处理器执行初始查找之后,不是针对通信操作使用一些处理器核心,而是处理器核心可被用于计算操作。
第一主计算机系统的NIC可以从第二主计算机系统接收对数据的请求。NIC控制器可以确定该请求是否与可缓存的数据(例如,与分布式表格相关联的数据)相关联。该请求可以包括该请求是针对与由主计算机系统存储的分布式表格相关联的数据的指示。例如,该指示可以是被包括在该请求的头部中的一系列数据位。NIC控制器可以检查该请求以确定该请求是否包括该指示。在该请求包括该指示的情况下(即,该请求不与可缓存的数据相关联),NIC控制器可以确定所请求的数据是否存储在NIC的高速缓存存储装置中。在所请求的数据存储在NIC的高速缓存存储装置中的情况下,NIC控制器可以向请求主计算机系统提供所请求的数据。在该请求包括该指示但是所请求的数据没有存储在NIC的高速缓存存储装置中(例如,该请求是针对与不常被请求的条目相关联的数据)的情况下,NIC控制器可以将该请求提供到与该NIC相关联的主计算机系统的处理器,并且主计算机系统的处理器可以如上所述执行查找。在该请求不包括该指示(即,该请求不与可缓存的数据相关联)的情况下,NIC控制器可以将该请求提供到与该NIC相关联的主计算机系统的处理器,并且主计算机系统的处理器可以如上所述执行查找。
分布式系统的每个NIC可以请求由它们的相应主计算机系统存储的相应分布式表格部分的一部分,并将所请求的数据存储在与每个NIC相关联的相应高速缓冲存储装置中。分布式计算系统可以使用分布式表格来做出多个预测。不是每个主计算机系统必须在存储器中为每个预测执行查找,而是数据可以从NIC的高速缓存存储装置被检索。这减少了完成请求所需的时间的数量,因为该请求可以由NIC控制器快速完成,而不是等待主计算机系统的处理器获得执行查找操作的核心、执行查找操作以及将与查找操作相关联的数据提供到请求主计算机系统。这也释放主计算机系统的处理器核心以用于计算操作而不是通信操作。
每个主计算机系统可以输出相应的预测,接收相应的反馈,并更新它们的相应机器学习模型。在对相应机器学习模型的更新被执行之后,存储在高速缓存存储装置中的相应分布式表格部分可以由它们的相应NIC控制器更新。相应分布式表格部分可以被更新以提供与分布式表格的条目相关联的实体的更准确的表示。NIC控制器然后可以直接更新与NIC控制器相关联的主计算机系统的相应存储器。这释放主计算机系统处理器的资源,因为不是主计算机系统处理器执行分布式表格的查找、从存储器检索数据以及更新所检索的数据,而是NIC控制器可以直接更新存储在主计算机系统的存储器中的分布式表格。
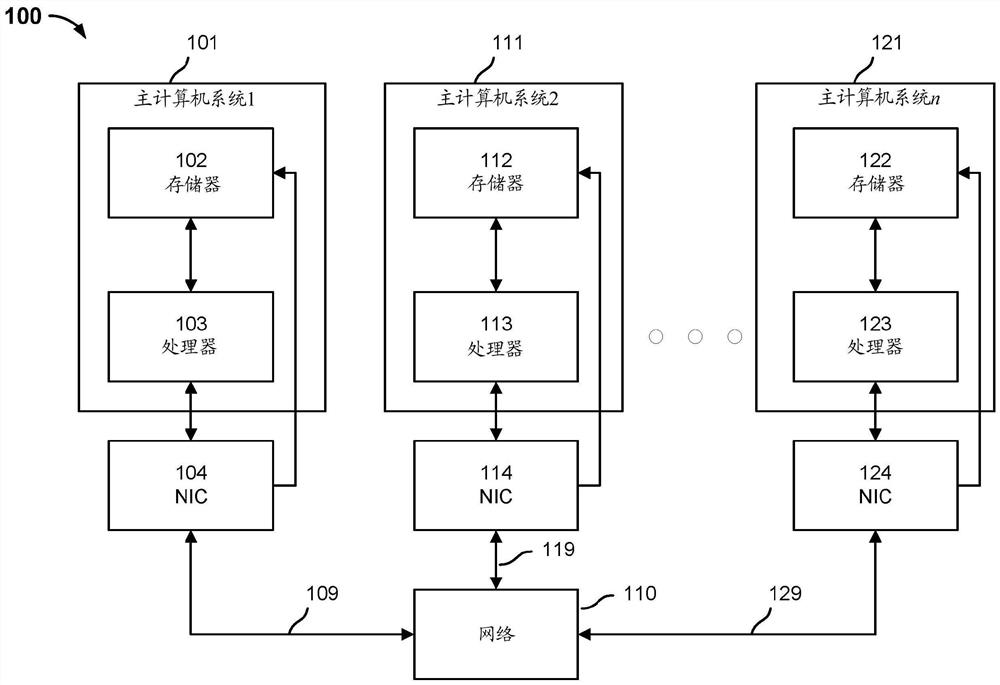
图1是示出根据一些实施例的分布式计算系统的框图。在所示的例子中,分布式计算系统100由主计算机系统101、主计算机系统111和主计算机系统112组成。尽管描绘了三个主计算机系统,但是分布式计算系统100可以由n个主计算机系统组成。主计算机系统101、111、112经由网络110连接到彼此。网络110可以是LAN、WAN、内联网、互联网和/或其组合。连接109、119、129可以是有线连接或无线连接。
主计算机系统101由存储器102和处理器103组成。主计算机系统101耦合到NIC104。主计算机系统111由存储器112和处理器113组成。主计算机系统111耦合到NIC 114。主计算机系统121由存储器122和处理器123组成。主计算机系统121耦合到NIC 124。在一些实施例中,NIC 104、114、124分别集成到主计算机系统101、111、121中(例如,扩展卡、可移除设备、集成在主板上等)。在一些实施例中,NIC 104、114、124分别经由计算机总线(例如PCI、PCI-e、ISA等)连接到主计算机系统101、111、121。NIC 104、114、124被配置为提供到与它相关联的主计算机系统的网络接入(例如以太网、Wi-Fi、光纤、FDDI、LAN、WAN、SAN等)。
表格(例如嵌入表格)由多个条目组成。每个条目可以与多个元素相关联。例如,表格可以由数百万个条目组成,其中每个条目由64个元素组成。不是将该表格存储在单个主计算机系统的存储器中,而是该表格可以分布在分布式计算系统100中。例如,存储器102可以存储第一分布式表格部分,存储器112可以存储第二分布式表格部分,······,以及存储器122可以存储第n分布式表格部分。这减少了分布式计算系统100对用于执行预测的单个计算节点及其相应存储器的依赖性。存储器102、112、122可以存储与不同分布式表格相关联的多个分布式表格部分。例如,存储器102可以存储与用户相关联的第一分布式表格部分和与项目(例如电影、产品、服务、商品等)相关联的第一分布式表格部分。存储器112可以存储与用户相关联的第二分布式表格部分和与项目相关联的第二分布式表格部分。存储器122可以存储与用户相关联的第n分布式表格部分和与项目相关联的第n分布式表格部分。
处理器103、113、123可以是计算机处理单元(CPU)、图形处理单元(GPU)或任何其他类型的处理单元。处理器103、113、123可以被配置成实现相应的机器学习模型。由分布式计算系统100实现的机器学习模型的例子包括但不限于神经网络模型、深度学习模型等。机器学习模型可以由多个层组成。每一层可以与相应的权重相关联。
由每个处理器103、113、123实现的机器学习模型可以不同。例如,基于机器学习模型在上面被执行的处理器,与机器学习模型的每一层相关联的权重可以不同。由处理器103执行的机器学习模型可以具有与第一层相关联的第一权重,由处理器113执行的机器学习模型可以具有与第一层相关联的第二权重,······,以及由处理器123执行的机器学习模型可以具有与第一层相关联的第n权重。由处理器103执行的机器学习模型可以具有与第二层相关联的第一权重,由处理器113执行的机器学习模型可以具有与第二层相关联的第二权重,······,以及由处理器123执行的机器学习模型可以具有与第二层相关联的第n权重。由处理器103执行的机器学习模型可以具有与第n层相关联的第一权重,由处理器113执行的机器学习模型可以具有与第n层相关联的第二权重,······,以及由处理器123执行的机器学习模型可以具有与第n层相关联的第n权重。
主计算机系统101、111、121可以一起工作来解决问题。例如,主计算机系统101、111、121可以确定特定用户是否对特定项目感兴趣。主计算机系统101、111、121可以实现相应的机器学习模型以预测特定用户是否对特定项目感兴趣。
主计算机系统101、111、121可以共享它们的相应分布式表格部分以执行预测。例如,主计算机系统101可以经由NIC 104与主计算机系统111、121共享存储在存储器102中的分布式表格部分。类似地,主计算机系统111可以经由NIC 114与主计算机系统101、121共享存储在存储器112中的分布式表格部分,以及主计算机系统121可以经由NIC 124与主计算机系统101、111共享存储在存储器122中的分布式表格部分。为了共享分布式表格部分,诸如处理器103、113、123的处理器可以执行分布式表格部分的查找,并从诸如存储器102、112、122的相应存储器检索与分布式表格部分相关联的数据。每当在分布式计算系统100中进行预测时,处理器103、111、123可能必须执行此查找和检索步骤。
处理器由有限数量的核心组成。核心可以执行计算操作例如恢复计算或者可以执行通信操作例如查找。处理器需要使用一个或更多个核心来执行查找。用于执行通信操作的核心减少了执行计算操作的可用核心的总数。这可能在主计算机系统101、111、121试图解决问题时产生瓶颈,因为当与存储在存储器中的分布式表格部分相关联的数据需要与其他主计算机系统共享时可能没有足够的核心来执行通信操作,或者当与分布式表格部分相关联的数据需要应用于机器学习模型时可能没有足够的核心来执行计算操作。
主计算机系统101、111、121可以在一个时间段内执行数个预测(例如数百、数千、数百万)。每当处理器执行查找时,可用于计算操作的核心的数量减少,这可以减少分布式计算系统100的预测时间。可以通过将与分布式表格部分相关联的一些数据存储在NIC的高速缓存存储装置中来增加可用于计算操作的核心的数量。例如,存储在主计算机系统的存储器中的分布式表格部分可以由一百万个条目组成。分布式表格部分的子集(例如几千个条目)可以存储在NIC的高速缓存存储装置中。当NIC 104接收到对与存储在存储器102中的分布式表格部分相关联的数据的请求时,NIC 104可以确定所请求的部分的一些或全部是否存储在NIC 104的高速缓存存储装置中。在所请求的数据存储在NIC 104的高速缓存存储装置中的情况下,NIC 104可以向请求主计算机系统提供所请求的数据。这可以减少由处理器103执行的查找操作的数量。在所请求的数据没有存储在NIC 104的高速缓存存储装置中的情况下,NIC 104可以向处理器103提供该请求,处理器103作为响应可以执行查找并从存储器102检索所请求的数据,并经由NIC 104向请求主计算机系统提供所检索的数据。NIC114、124也可以分别将与存储在存储器112、122中的分布式表格部分相关联的一些数据存储在NIC 114、124的相应高速缓存存储装置中。将与分布式表格部分相关联的一些数据存储在NIC的高速缓存存储装置中可以减少整体预测时间,因为由处理器103、113、123执行的查找操作的数量可以减少。
处理器103、113、123可以在与多个分布式表格部分相关联的数据被输入到它们的相应机器学习模型之后输出预测。机器学习模型可以由多个层组成。与多个分布式表格部分相关联的数据可以被输入到机器学习模型的初始层。机器学习模型的初始层的输出可以被提供到机器学习模型的第二层。机器学习模型的前一层的输出可以被输入到机器学习模型的后一层。这个过程可以重复,直到机器学习模型的倒数第二层的输出被提供到机器学习模型的最后一层为止。机器学习模型的最后一层可以输出值。在一些实施例中,该值对应于预测。
在机器学习模型输出值之后,处理器103、113、123可以基于它们的预测来接收反馈,并确定它们的相应机器学习模型需要被更新。例如,第一主计算机系统可以预测与社交媒体平台相关联的用户对特定产品感兴趣,以及第一主计算机系统可以从用户(直接或间接)接收指示用户是否对特定产品感兴趣的反馈。第一主计算机系统可以使用该反馈来更新它的相应机器学习模型。
处理器103、113、123可以从它们的相应最后层开始,并确定与它们的相应最后层相关联的已更新权重。处理器103、113、123可以共享与它们的相应最后层相关联的它们的所确定的已更新权重。处理器103、113、123可以为相应的最后层确定共同的已更新权重,并基于共同的已更新权重来更新它们的相应机器学习模型。处理器103、113、123可以继续进行到倒数第二层以为倒数第二层确定共同的已更新权重。处理器103、113、123可以共享与它们的相应倒数第二层相关联的它们的所确定的已更新权重。处理器103、113、123可以为相应的倒数第二层确定共同的已更新权重,并基于共同的已更新权重来更新它们的相应机器学习模型。处理器103、113、123可以继续进行到下一层,并如上所述继续更新下一层。更新过程持续,直到初始层被到达并被更新为止。
在相应的机器学习模型的初始层被更新之后,与分布式表格部分相关联的数据可以被更新。分布式表格部分的条目可以被更新以提供分布式表格部分所关联到的实体(例如人、商品、服务、电影、项目等)的更好表示。在一些实施例中,待更新的分布式表格部分的条目存储在NIC的高速缓存存储装置中。存储在高速缓存存储装置中的分布式表格部分的条目可以被更新,而不是向主计算机系统的处理器发送更新请求。如果有更新请求将被发送到主计算机系统的处理器,主计算机系统的处理器将需要使用一个或更多个核心来查找与更新相关联的分布式表格部分的条目,更新该条目,并将已更新的条目存储在主计算机系统的存储器中。更新存储在NIC的高速缓存存储装置中的分布式表格部分可以释放处理器核心以执行计算过程。在一些实施例中,使用最近最少使用的策略从高速缓存存储装置排出数据。在NIC的高速缓存存储装置被更新之后,NIC可以用存储在高速缓存存储装置中的已更新部分直接更新存储在主计算机系统的存储器中的分布式表格部分。在一些实施例中,在NIC的高速缓存存储装置被更新之后,当处理器具有可用于执行更新的充足数量的核心(例如,多于阈值数量)时,NIC通过将存储在高速缓存存储装置中的已更新部分提供到主计算机系统的处理器来用存储在高速缓存存储装置中的已更新部分间接地更新存储在主计算机系统的存储器中的分布式表格部分。
图2是示出网络接口控制器的实施例的框图。NIC 200可以被实现为NIC,例如NIC104、114、124。
NIC 200由计算机接口202、控制器204、高速缓存存储装置206和网络接口208组成。NIC 200可以与主计算机系统相关联。主计算机系统可以存储分布式表格的一部分。控制器204可以经由计算机接口202向主计算机系统发送对在分布式表格部分中包括的数据的子集的请求。响应于该请求,主计算机系统可以查找所请求的数据,并经由计算机接口202向控制器204提供所请求的数据。响应于接收到所请求的数据,控制器204可以将所请求的数据存储在高速缓存存储装置206中。在分布式表格部分中包括的数据的子集可以对应于分布式表格部分的最常被访问的子集(例如,在指定的持续时间内被访问多于阈值次数)。
NIC 200可以在网络接口208处接收对由主计算机系统存储的数据的请求。NIC200可以确定该请求是否与可缓存的数据(例如,与分布式表格相关联的数据)相关联。对由主计算机系统存储的数据的请求可以由多个数据包组成。控制器204可以检查与多个数据包相关联的头部。与多个数据包相关联的头部可以包括所请求的数据与由与NIC 200相关联的主计算机系统存储的分布式表格部分相关联的指示。在与多个数据包相关联的头部不包括所请求的数据与由与NIC 200相关联的主计算机系统存储的分布式表格部分相关联的指示(即,该请求不与可缓存的数据相关联)的情况下,控制器204可以经由计算机接口202向主计算机系统提供该请求。在与多个数据包相关联的头部确实包括所请求的数据与由与NIC 200相关联的主计算机系统存储的分布式表格部分相关联的指示(即,该请求与可缓存的数据相关联)的情况下,控制器204可以检查高速缓存存储装置206以确定所请求的数据是否存储在高速缓存存储装置206中。在所请求的数据存储在高速缓存存储装置206中的情况下,控制器204可以从高速缓存存储装置206检索所请求的数据,并且经由网络接口208向请求主计算机系统提供所请求的数据。在所请求的数据没有存储在高速缓存存储装置206中的情况下,控制器204可以经由计算机接口202向主计算机系统发送请求。计算机节点可以查找所请求的数据,并将所请求的数据提供到控制器204。响应于接收到所请求的数据,控制器204可以将所请求的数据存储在高速缓存存储装置206中,并且经由网络接口208向请求主计算机系统提供所请求的数据。所请求的数据可以盖写存储在高速缓存存储装置206中的数据。在一些实施例中,最近最少使用的策略被实现,并且所请求的数据盖写存储在高速缓存存储装置206中的最近最少使用的数据。
控制器204可以经由网络接口208接收更新与分布式表格部分相关联的数据的请求。控制器204可以确定更新请求是否与存储在高速缓存存储装置206中的数据相关联。在更新请求与存储在高速缓存存储装置206中的数据相关联的情况下,控制器204可以更新存储在高速缓存存储装置206中的数据。在一些实施例中,NIC 200被配置为直接与NIC 200所关联到的计算设备的存储器通信。NIC 200可以用已更新数据直接更新存储在计算设备的存储器中的分布式表格部分。在一些实施例中,NIC 200被配置成间接地与NIC 200所关联到的计算设备的存储器通信。当主计算机系统具有可用核心来执行更新时,NIC 200可以向主计算机系统的处理器提供已更新数据。在更新请求与存储在高速缓存存储装置206中的数据不相关联的情况下,控制器204可以经由计算机接口202向主计算机系统提供更新请求。
图3是示出分布式表格的实施例的表格。在所示的例子中,分布式表格300由多个部分302、304、306组成。主计算机系统的存储器可以存储多个部分302、304、306中的一个。虽然该例子描绘了分布式表格300由三个部分组成,但是分布式表格300可以由N个部分组成。在一些实施例中,分布式表格300对应于嵌入表格。
分布式表格300由m个元素组成。在一些实施例中,元素的数量是64。在一些实施例中,元素的数量m=2
第一分布式表格部分302由条目I
第一分布式表格部分302可以存储在第一主计算机系统的存储器例如主计算机系统101的存储器102中。第二分布式表格部分304可以存储在第二主计算机系统的存储器例如主计算机系统111的存储器112中。第三分布式表格部分306可以存储在第三主计算机系统的存储器例如主计算机系统121的存储器122中。
第一分布式表格部分302的子集可以存储在与主计算机系统相关联的NIC的高速缓存存储装置中。例如,第一分布式表格部分302的子集可以存储在NIC 104的高速缓存存储装置中。第二分布式表格部分304的子集可以存储在与主计算机系统相关联的NIC的高速缓存存储装置中。例如,第二分布式表格部分304的子集可以存储在NIC 114的高速缓存存储装置中。第三分布式表格部分306的子集可以存储在与主计算机系统相关联的NIC的高速缓存存储装置中。例如,第三分布式表格部分306的子集可以存储在NIC 124的高速缓存存储装置中。在一些实施例中,存储在与主计算机系统相关联的NIC的高速缓存存储装置中的分布式表格部分的子集可以对应于与分布式表格部分子集相关联的最常被访问的条目。
在一些实施例中,分布式表格部分的一个或更多个条目被请求,并且不存储在与主计算机系统相关联的NIC的高速缓存存储装置中。主计算机系统可以向与主计算机系统相关联的NIC提供与一个或更多个所请求的条目相关联的数据。与一个或更多个所请求的条目相关联的数据可以存储在与主计算机系统相关联的NIC的高速缓存存储装置中。NIC的高速缓存存储装置可以实现最近最少使用的驱逐策略。与一个或更多个所请求的条目相关联的数据可以盖写存储在NIC的高速缓存存储装置中的分布式表格部分子集的最近最少使用的条目。
图4是示出根据一些实施例的机器学习模型的框图。在所示的例子中,机器学习模型400由层402、412、422组成。尽管该例子将机器学习模型400示为具有三层,但是机器学习模型400可以由n层组成。
每个层与相应的权重相关联。层402与权重404相关联,层412与权重414相关联,以及层422与权重424相关联。在向前传递中,输入数据可以应用于层402。输入数据可以对应于与分布式表格相关联的数据(例如,分布式表格的一个或更多个条目)。层402可以将权重404(例如加权函数)应用于输入数据,并输出值。层402的输出可以被提供作为层412的输入。层412可以将权重414应用于由层402输出的数据,并输出值。层412的输出可以被提供作为层422的输入。层422可以将权重424应用于由层412输出的数据,并输出值。由层422输出的值可以对应于预测。
主计算机系统可以基于它的预测来接收反馈,并确定它的相应机器学习模型需要被更新以在未来提供更准确的预测。可以确定层422的已更新权重。在一些实施例中,已更新权重与一个或更多个其他主计算机系统共享。一个或更多个其他主计算机系统可以共享层422的它们的相应已更新权重。可以为层422确定共同权重426。可以确定层412的已更新权重。在一些实施例中,已更新权重与一个或更多个其他主计算机系统共享。一个或更多个其他主计算机系统可以共享层412的它们的相应已更新权重。可以为层412确定共同权重416。可以确定层402的已更新权重。在一些实施例中,已更新权重与一个或更多个其他主计算机系统共享。一个或更多个其他主计算机系统可以共享层402的它们的相应已更新权重。可以为层402确定共同权重406。
图5是示出用于机器学习的过程的实施例的流程图。在所示的例子中,过程500可以由主计算机系统例如主计算机系统101、111、121实现。
在502,执行向前传递。输入数据可以应用于主计算机系统的机器学习模型,并且由主计算机系统输出预测。在一些实施例中,输入数据是与分布式表格例如嵌入表格相关联的数据。
在504,执行向后传播。机器学习模型可以被更新。机器学习模型可以由多个层组成,其中每个层与相应的权重相关联。可以更新与机器学习模型的每一层相关联的相应权重。在一些实施例中,与机器学习模型的每一层相关联的相应权重与一个或更多个其他主计算机系统共享,以及针对机器学习模型的每一层确定共同权重。
图6是示出用于检索数据的过程的实施例的流程图。在所示的例子中,过程600可以由NIC例如NIC 104、NIC 114或NIC 124实现。
在602,接收对来自分布式表格的数据的请求。分布式表格可以被分成多个部分。分布式系统可以由多个主计算机系统组成。可以从分布式系统的其他主计算机系统中的任一个接收请求。
每个主计算机系统具有相应的存储器。每个主计算机系统可以存储分布式表格的相应部分。在一些实施例中,对来自分布式表格的数据的请求对应于在存储在主计算机系统的存储器中的分布式表格部分中包括的数据的子集。在一些实施例中,对来自分布式表格的数据的请求对应于在存储在主计算机系统的存储器中的分布式表格部分中包括的所有数据。
在604,对来自分布式表格的数据的请求被识别为要由网络接口控制器系统处理的请求。对来自分布式表格的数据的请求可以由多个包组成。多个包可以具有相关头部。在与请求相关联的头部包括指示该请求是针对来自分布式表格的数据的指示的情况下,该请求可以被识别为对来自分布式表格的数据的请求。
在606,经由计算机接口来请求并接收来自计算机系统的存储器的所请求的数据。该请求可以被提供到接收该请求的NIC所关联到的主计算机系统。响应于接收到该请求,主计算机系统的处理器可以从主计算机系统的存储器检索所请求的数据,并将所检索的数据提供到NIC。
在608,使接收到的所请求的数据缓存在网络接口控制器系统的高速缓存中。NIC的控制器可以使所检索的数据存储在NIC的高速缓存存储装置中。
在610,所请求的数据被提供到分布式系统的请求节点。
图7是示出用于检索数据的过程的实施例的流程图。在所示的例子中,过程700可以由NIC例如NIC 104、NIC 114或NIC 124实现。
在702,分析对来自分布式表格的数据的请求。分布式表格可以被分成多个部分。分布式系统可以由多个主计算机系统组成。可以在主计算机系统处从分布式系统的其他主计算机系统中的任一个接收该请求。
每个主计算机系统具有相应的存储器,并将分布式表格的相应部分存储在相应的存储器中。在一些实施例中,对来自分布式表格的数据的请求对应于在存储在主计算机系统的存储器中的分布式表格部分中包括的数据的子集。在一些实施例中,对来自分布式表格的数据的请求对应于在存储在主计算机系统的存储器中的分布式表格部分中包括的所有数据。对来自分布式表格的数据的请求可以由多个包组成。多个包可以具有相关头部。可以分析多个包的相关头部。
在704,确定该请求是否与可缓存的数据相关联。可缓存的数据可以对应于来自分布式表格的数据。NIC的控制器可以确定与该请求相关联的头部是否包括指示该请求是针对来自分布式表格的数据的指示。在该请求包括指示该请求是针对来自分布式表格的数据的指示(即,该请求与可缓存的数据相关联)的情况下,过程700继续进行到706。在该请求不包括指示该请求是针对来自分布式表格的数据的指示(即,该请求不与可缓存的数据相关联)的情况下,过程700继续进行到712。
在706,确定来自分布式表格的所请求的数据是否存储在NIC的高速缓存存储装置中。NIC的高速缓存存储装置可以存储在NIC所关联到的主计算机系统的存储器中存储的分布式表格部分的子集。该请求可以针对在存储在高速缓存存储装置中的分布式表格部分的子集中包括的数据。该请求可以针对不存储在高速缓存存储装置中而是存储在NIC所关联到的主计算机系统的存储器中的分布式表格部分的数据。
在请求是针对来自存储在NIC的高速缓存存储装置中的分布式表格的数据的情况下,过程700继续进行到708。在请求是针对来自未存储在NIC的高速缓存存储装置中的分布式表格的数据而是针对来自存储在主计算机系统的存储器中的分布式表格的数据的情况下,过程700继续进行到712。
在708,从NIC的高速缓存存储装置检索所请求的数据。在710,所检索的数据被提供到请求主计算机系统。
图8是示出用于更新分布式表格的过程的实施例的流程图。在所示的例子中,过程800可以由NIC例如NIC 104、NIC 114和NIC 124实现。
在802,接收与分布式表格相关联的更新。分布式表格可以被分成多个部分。分布式系统可以由多个主计算机系统组成。每个主计算机系统具有相应的存储器。每个主计算机系统可以存储分布式表格的相应部分。与主计算机系统相关联的NIC可以存储由NIC所关联到的主计算机系统存储的分布式表格部分的子集。与分布式表格相关联的更新可以对应于存储在NIC的高速缓存存储装置中的分布式表格部分的子集。
在804,更新分布式表格。NIC的控制器可以接收与分布式表格相关联的更新,并更新存储在NIC的高速缓存存储装置中的分布式表格部分的子集。例如,分布式表格部分的子集可以由多个条目组成。每个条目与多个元素相关联。可以更新与条目的一个或更多个相应元素相关联的一个或更多个值。
在806,更新被提供到计算机系统。在一些实施例中,NIC可以直接与NIC所关联到的主计算机系统的存储器通信。NIC的控制器可以更新存储在主计算机系统的存储器中的分布式表格部分。在一些实施例中,NIC可以通过向NIC所关联到的主计算机系统的处理器提供与分布式表格相关联的更新来间接地与NIC所关联到的主计算机系统的存储器通信。响应于接收到与分布式表格相关联的更新,主计算机系统的处理器可以更新存储在主计算机系统的存储器中的分布式表格部分。
图9是示出用于更新机器学习模型的过程的实施例的流程图。在所示的例子中,过程900可以由处理器例如处理器103、处理器113和处理器123实现。
在902,执行基于与分布式表格相关联的数据的预测。主计算机系统的处理器可以确定它的相关机器学习模型需要被更新以执行更准确的预测。
在904,确定与机器学习模型层相关联的新权重。机器学习模型可以由多个层组成。每层可以有相应的权重。主计算机系统的处理器可以确定层的已更新权重。
在906,所确定的权重被提供到分布式计算系统的其他节点。分布式计算系统的其他节点可能已经执行相应的预测并已经确定对它们的相应机器学习模型的相应调整。在908,接收来自分布式计算系统的其他节点的所确定的权重。
在910,确定机器学习模型层的共同权重。共同权重基于由主计算机系统确定的权重和由分布式计算系统的其他节点确定的权重。
尽管为了清楚理解的目的已经详细描述了前述实施例,但是本发明不限于所提供的细节。有许多实现本发明的替代方式。所公开的实施例是说明性的,而不是限制性的。
- 用于缓存分布式数据的智能网络接口控制器
- 用于虚拟分布式业务的网络接口控制器