基于交并比估计的空间注意力强化学习跟踪方法
文献发布时间:2023-06-19 12:05:39
技术领域
本发明属于本发明属于计算机视觉技术领域,具体涉及数字图像的目标跟踪技术领域中的基于交并比估计的空间注意力强化学习跟踪方法。
背景技术
近年来,深度学习和强化学习被广泛应用在计算机视觉任务中,其中深度学习所提供的强大的特征表达能力为数字图像处理及模式识别任务奠定了重要基础,在此基础之上,研究者们提出了多种不同的深度网络架构来适应不同的计算机视觉任务。D.Danelljan等人[1]研究了卷积网络特征对目标跟踪任务的影响,他们发现第一层的激活具有比其他更深层更好的跟踪性能。B.Luca等人[2]提出了孪生网络的跟踪方法,作者将目标跟踪理解为一种在线匹配问题,跟踪的实质即为将目标模板图像在搜索图像中进行滑动匹配,具有最高相似度的图像块即为当前帧中的目标,为实现这样的思想,作者提出利用两个具有相同结构、相同参数的深度卷积网络分别对目标模板图像和搜索图像提取特征,然后采用互相关(Cross-correlation)实现高效的滑动窗口匹配.H.Nam等人[3]提出了一种多域训练的深度网络(Multi-domain convolutional neural networks,MDNet)模型,作者通过多域网络来解决面向跟踪任务的网络训练时所遇到的目标物体和背景物体的类别混淆问题,相比孪生网络,作者采用更新的VGG[4]深度网络作为特征提取的骨干网络并取得了良好的效果。为了在深度网络训练的过程更好地调整网络初始参数,E.Park等人[5]利用元学习(Meta-learning)[6]思想,通过两次梯度计算加快模型收敛速度。J.Choi等人[7]从另一个角度来应用元学习思想,在提出的跟踪算法中,作者通过元学习快速捕获目标物体的外观特信息以实现特征融合,将最具有判别性的特征保留下来,从而提升跟踪质量.Z.Zhu等人[8]受到深度光流网络(FlowNet)[9]的启发,提出利用深度光流捕获目标物体的运动特征。S.Pu等人[10]提出了一种基于互学习思想的跟踪算法,该算法通过网络反向传播的偏导数来计算图像特征的注意力图,并将其作为正则项来迭代训练深度网络.。S.Dong等人[11]提出了一种三元损失(Triple loss)的跟踪算法,作者在所提出的跟踪算法中通过三元损失以实现更多样本的训练,从而提供更优质的图像表示。为解决多域网络跟踪算法的实时性较弱的问题,Y.Li等人[12]提出了一种对图像进行相似变换以进行匹配的方法以解决物体的角度变化问题,所提出的跟踪算法可以更好地估计物体的矩形边框。为了进一步深度学习跟踪器的判别能力,G.Bhat等人[13]提出了一种模型预测方法来估计更加准确的目标物体外观模型,从而提升跟踪器的判别性能.Y.Wang等人[14]提出了一种基于数据增强的方法来补充训练数据,并且利用散列矩阵(Hash matrix)来降低深度图像特征的维度。N.Wang等人[15]利用跟踪场景下的前后一致性,并采用多帧综合验证,提出了一种无监督的深度学习跟踪算法。
早期基于深度学习的跟踪算法中,网络参数主要通过图像分类任务训练后得到,这样会导致跟踪算法难以发挥其最大潜力,为解决这一问题,Z.Zhu等人[16]提出了一种联合卷积跟踪器(Unified convolutional tracker,UCT),在提出的算法中,该框架可以在跟踪的过程中同时学习物体的特征表示。在基于深度学习的跟踪算法中,一个突出问题是训练的目标图像数量与背景图像数量存在极大的不平衡,这容易导致模型退化,为解决该问题,X.Lu等人[17]提出了一种收缩损失(Shrinkage loss),通过该损失方法降低简单样本(Easy samples)的重要性,维持困难样本(Hard samples)的重要性.紧接着,为了解决基于区域建议网络跟踪算法在干扰场景下性能退化的问题,Z.Zhu等人[18]提出了一种对干扰敏感的跟踪算法,在提出的算法中,作者对滑动窗口匹配产生的响应图(Response map)进行干预,抑制目标物体周围干扰因素的部分,所提出的算法被称为DaSiamRPN跟踪算法。H.Fan等人[19]为了解决基于区域建议网络在干扰物和物体显著尺度变化下的退化问题,提出了一种将区域建议网络进行级联的思想,通过更加合理的时序来应对困难样本。Z.Zhang等人[20]在孪生深度网络跟踪的基础上,通过研究网络卷积结构对跟踪性能的影响,提出了一种更深和更宽(Deeper and wider)的目标跟踪网络结构。自2017年开始,在基于深度学习的跟踪方法中,研究者们也开始将目光投向深度强化学习(Deepreinforcement learning)[21],通过强化学习使跟踪器学会捕捉目标物体的运动信息,这样可以在复杂环境下更好地应对物体受到干扰的现象。S.Yun等人[22]提出了一种动作驱动的强化学习跟踪方法,作者在提出的跟踪算法中将强化学习用于对物体的定位,在这个过程中,作者利用策略梯度方法对网络进行训练使跟踪器学习对目标物体进行定位.J.Supancic等人[23]等人利用策略学习思想,将目跟踪看作一个可观察的动态决策过程,在跟踪过程中动态决定模型更新,而不再使用传统跟踪算法中普遍采用的启发式更新方法。B.Zhong等人[24]采用由粗到细的思想利用深度强化学习对目标物体进行跟踪,作者将运动搜索作为强化学习中的动作决策问题来理解,所提出的跟踪算法利用基于递归卷积神经网络(Recurrent convolutional neural network,RCNN)[25]的深度Q网络来有效对目标的搜索策略.为进一步提升滑动窗口匹配的实时性,Z.Teng等人[26]将跟踪问题看作为一个三步决策过程,作者使用Q-learning来学习跟踪器的定位动作,并且以合作的方式来训练模型。
现有的目标跟踪技术主要存在以下几个问题:
1.在当前大多数基于深度强化学习的跟踪方法中,研究者们普遍将重点放在了确定目标的中心位置上,对目标在每一帧中的边框如何精确界定这一问题尚未展开足够的研究。而在目标跟踪任务中,确定目标物体在每一帧中的矩形边框是一项非常重要的任务,它关系到如何表达目标物体的所占据的空间尺度,仅仅利用固定宽高比缩放的方式难以适应复杂情况下的物体形变。
2.在复杂环境下,被跟踪物体的空间上下文往往充斥着大量的噪声信号,特别是纹理丰富的高频信号,它们会对跟踪器产生诸如相似纹理、相似形态方面的干扰,其提供的图像表征往往与目标物体近似。而当前研究界对这类问题的研究尚不够深入,算法容易发生错误判断,将背景的噪声当作待跟踪的目标物体,影响跟踪器对目标位置的估计,造成跟踪发生偏移甚至是目标丢失。
3.当前的目标跟踪算法中,大多数算法仅仅输出目标的坐标及对应估计的矩形边框,然而在实际应用中,作为计算机视觉中的重要任务,目标跟踪和物体分割的联系非常紧密。目标跟踪可以为视频中的物体输出估计的坐标及矩形框,而物体分割则可以基于此输出更加精确的、属于目标物体的像素级区域。如何能够利用物体分割的结果来提升跟踪任务的性能,亦是一个对研究界非常有帮助的课题。
[文献1]M.Danelljan,G.
[文献2]Luca Bertinetto,Jack Valmadre,
[文献3]H.Nam and B.Han.Learning multi-domain convolutional neuralnetworks for visual tracking.In2016 IEEE Conference on Computer Vision andPattern Recognition(CVPR),pages 4293–4302,June 2016.
[文献4]Karen Simonyan and Andrew Zisserman.Very deep convolutionalnetworks for large-scale image recognition.In International Conference onLearning Representations,2015.
[文献5]Eunbyung Park and Alexander C.Berg.Meta-tracker:Fast androbust online adaptation for visual object trackers.In Vittorio Ferrari,Martial Hebert,Cristian Sminchisescu,and Yair Weiss,editors,Computer Vision–ECCV 2018,pages 587–604,Cham,2018.Springer International Publishing.
[文献6]Bruno Almeida Pimentel and AndréC.P.L.F.de Carvalho.Ameta-learning approach for recommending the number of clusters for clusteringalgorithms.Knowledge-Based Systems,page 105682,2020.
[文献7]J.Choi,J.Kwon,and K.M.Lee.Deep meta learning for real-timetarget-aware visual tracking.In 2019IEEE/CVF International Conference onComputer Vision(ICCV),pages 911–920,Oct 2019.
[文献8]Z.Zhu,W.Wu,W.Zou,and J.Yan.End-to-end flow correlationtracking with spatialtemporal attention.In 2018IEEE/CVF Conference onComputer Vision and Pattern Recognition,pages 548–557,June 2018.
[文献9]A.Dosovitskiy,P.Fischer,E.Ilg,P.
[文献10]Shi Pu,Yibing Song,Chao Ma,Honggang Zhang,and Ming-HsuanYang.Deep attentive tracking via reciprocative learning.In S.Bengio,H.Wallach,H.Larochelle,K.Grauman,N.Cesa-Bianchi,and R.Garnett,editors,Advances in Neural Information Processing Systems 31,pages 1931–1941.CurranAssociates,Inc.,2018.
[文献11]Xingping Dong and Jianbing Shen.Triplet loss in siamesenetwork for object tracking.In Vittorio Ferrari,Martial Hebert,CristianSminchisescu,and Yair Weiss,editors,Computer Vision–ECCV 2018,pages 472–488,Cham,2018.Springer International Publishing.
[文献12]Yang Li,Jianke Zhu,Steven Hoi,Wenjie Song,Zhefeng Wang,andHantang Liu.Robust estimation of similarity transformation for visual objecttracking.AAAI 2019:Thirty-Third AAAI Conference on Artificial Intelligence,33(1):8666–8673,2019.
[文献13]G.Bhat,M.Danelljan,L.Van Gool,and R.Timofte.Learningdiscriminative model prediction for tracking.In 2019IEEE/CVF InternationalConference on Computer Vision(ICCV),pages 6181–6190,Oct 2019.
[文献14]Yong Wang,Xian Wei,Xuan Tang,Hao Shen,and Lu Ding.Cnntracking based on data augmentation.Knowledge-Based Systems,page 105594,2020.
[文献15]N.Wang,Y.Song,C.Ma,W.Zhou,W.Liu,and H.Li.Unsupervised deeptracking.In 2019IEEE/CVF Conference on Computer Vision and PatternRecognition(CVPR),pages 1308–1317,June 2019.
[文献16]Z.Zhu,G.Huang,W.Zou,D.Du,and C.Huang.Uct:Learning unifiedconvolutional networksforreal-timevisualtracking.In2017 IEEE InternationalConference on Computer Vision Workshops(ICCVW),pages 1973–1982,Oct 2017.
[文献17]Xiankai Lu,Chao Ma,Bingbing Ni,Xiaokang Yang,Ian Reid,andMing-Hsuan Yang.Deep regression tracking with shrinkage loss.In VittorioFerrari,Martial Hebert,Cristian Sminchisescu,and Yair Weiss,editors,ComputerVision–ECCV 2018,pages 369–386,Cham,2018.Springer International Publishing.
[文献18]Zheng Zhu,Qiang Wang,Bo Li,Wei Wu,Junjie Yan,and WeimingHu.Distractor-aware siamese networks for visual object tracking.In VittorioFerrari,Martial Hebert,Cristian Sminchisescu,and Yair Weiss,editors,ComputerVision–ECCV 2018,pages 103–119,Cham,2018.Springer International Publishing.
[文献19]H.FanandH.Ling.Siamese cascade dregion proposal networks forreal-time visual tracking.In 2019IEEE/CVF Conference on Computer Vision andPattern Recognition(CVPR),pages 7944–7953,June 2019.
[文献20]Z.Zhang and H.Peng.Deeper and wider siamese networks forreal-time visual tracking.In 2019IEEE/CVF Conference on Computer Vision andPattern Recognition(CVPR),pages 4586–4595,June 2019.
[文献21]Y.Keneshloo,T.Shi,N.Ramakrishnan,and C.K.Reddy.Deepreinforcement learning for sequence-to-sequence models.IEEE Transactions onNeural Networks and Learning Systems,pages 1–21,2019.
[文献22]S.Yun,J.Choi,Y.Yoo,K.Yun,and J.Y.Choi.Action-driven visualobject tracking with deepreinforcementlearning.IEEE Transactions on NeuralNetworks and Learning Systems,29(6):2239–2252,June 2018.
[文献23]J.Supancic and D.Ramanan.Tracking as online decision-making:Learning a policy from streaming videos with reinforcement learning.In2017IEEE International Conference on Computer Vision(ICCV),pages 322–331,Oct2017.
[文献24]B.Zhong,B.Bai,J.Li,Y.Zhang,and Y.Fu.Hierarchical tracking byreinforcement learning-based searching and coarse-to-fine verifying.IEEETransactions on Image Processing,28(5):2331–2341,May 2019.
[文献25]L.Mou,L.Bruzzone,and X.X.Zhu.Learning spectral-spatial-temporal features via a recurrent convolutional neural network for changedetection in multispectral imagery.IEEE Transactions on Geoscience and RemoteSensing,57(2):924–935,Feb 2019.
[文献26]Zhu Teng,Baopeng Zhang,and Jianping Fan.Three-step actionsearch networks with deep Q-learning for real-time object tracking.PatternRecognition,101:107188,2020.
发明内容
为了解决上述技术问题,本发明提出了基于交并比估计的空间注意力强化学习跟踪算法。
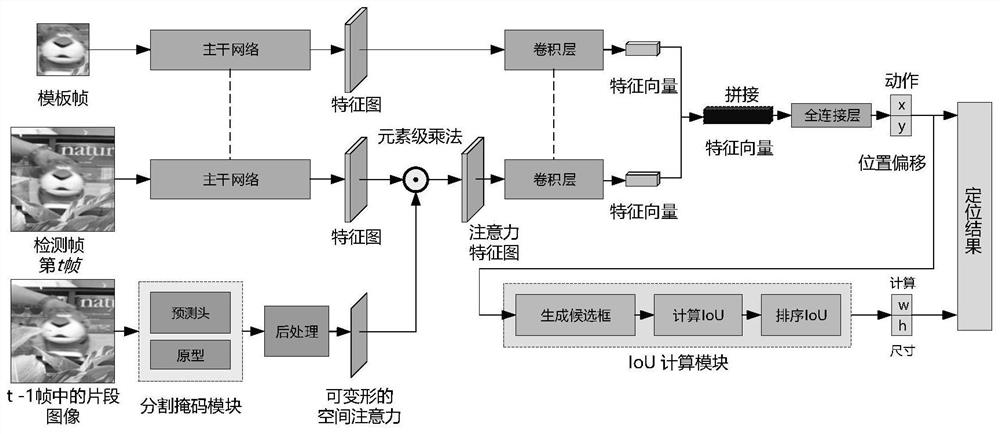
本发明所采用的技术方案是:一种基于交并比估计的空间注意力强化学习跟踪算法,包含强化学习预定位模块、交并比估计模块和空间注意力模块三个部分。这三个部分的网络分别独立进行端到端训练,从而可以更加灵活地适应它们各自的任务。本发明将基于强化学习的视频目标跟踪理解为一个二阶段问题,首先利用强化学习预定位模块对目标运动信息的捕捉能力来确定目标物体的中心点坐标,然后利用交并比估计模块进一步确定物体的边框,并且,在该过程中,本发明提出利用基于物体分割的方法来实现可变形空间注意力以抑制背景噪声,这既是本发明提出算法与相关工作不同的地方,也是本发明的创新之处。本发明提出利用基于物体分割网络的方法来学习目标物体的空间注意力,在分割区域的基础上融合先验图像分布来适应物体运动过程中的形变,从而更好地抑制背景噪声.在多个数据集上进行的大量实验表明,所提出的跟踪算法与当前领先的跟踪算法相比取得了富有竞争力的结果。在跟踪任务中,本发明主要包括如下几个步骤:
步骤1,初始化网络模型,包括强化学习预定位模块、交并比估计模块和空间注意力模块;
所述强化学习预定位模块包括两组并行的主干网络和卷积模块,然后将经过卷积模块处理后得到的特征向量进行拼接,输入到全连接层中,实现目标物体的预定位;
步骤2,将模板帧和检测帧第t帧分别输入到主干网络中,得到模板帧特征图和检测帧特征图,将模板帧特征图输入到卷积模块,得到模板帧特征向量;
步骤3,将检测帧第t-1帧输入到空间注意力模块得到可变形空间注意图;
步骤4,将可变形空间注意图与检测帧特征图进行逐像素相乘,然后输入到卷积模块中得到检测帧特征向量;
步骤5,将模板帧特征向量与检测帧特征向量进行拼接,然后经过一个全连接层中,实现目标物体的预定位,求出目标物体的中心点的位置偏移;
步骤6,将目标物体的中心点的位置偏移输入到交并比估计模块,利用随机方法在目标物体中心点位置生成多个具有不同宽高比例的矩形框,这些矩形框均属于候选框,然后计算得出这些候选框的IOU得分,并根据IOU得分进行排序,得到IOU得分最高的矩形框,获得目标物体的宽和高。
进一步的,所述主干网络结构包括两个结构相同的卷积池化模块,卷积池化模块包括一个卷积层、一个ReLU层、一个局部响应归一化层和一个池化层。
进一步的,采用基于演员Actor-评论家Critic模式的DDPG算法对强化学习预定位模块进行训练,Actor是跟踪定位动作的执行者,Critic是对动作执行效果的评价者,首先定义奖励函数为:
其中,p表示模块定位到的目标位置,G表示训练数据中对应的groundtruth;函数IoU(·)表示对Actor标定的矩形框和ground-truth计算交并比数值,在具备ground-truth的情况下,计算模块预测矩形边框与真实标记边框之间的重叠率,以作为对Actor奖励的依据,若重叠率大于某个阈值,Critic就认为Actor跟踪到了目标,此时的奖励为+1;否则,Critic认为Actor丢失了目标,此时给予的奖励为-1;
根据DDPG算法,用L2 Loss为Critic建立损失函数:
其中,N表示训练样本数目,
进一步的,所述空间注意力模块包括掩码系数网络模块与可变形空间注意力模块,所述掩码系数网络模块通过FPN网络作为图像的特征提取骨干网络,得到的特征金字塔分别用于原型掩码和掩码系数的生成,具体实现过程如下:
首先根据融合强化学习预定位模块与交并比估计模块的定位结果进行采样,其公式为:
m'=Samp(p,pad)
其中,p表示目标物体标定的位置,pad表示采样图像范围相对于目标物体的扩展参数,Samp(·,·)表示采样过程,m′表示采样得到的图像块;
利用FPN进行特征提取的数学公式为:
m'
其中函数ψ
将特征金字塔m′
其中,函数ψ
得出的原型掩码m′
其中符号
最后,对融合后的掩码m′
其中,函数ψ
进一步的,在得到目标物体的分割掩码后,利用可变形空间注意力模块对该分割掩码进行后处理生成最终的空间注意力图,具体流程如下;
首先为了适应目标物体在帧间可能存在的像素尺度放大现象,将分割掩码m′进行尺度变化,其公式为:
m'
其中m′表示分割掩码,mag表示放大倍率参数,m′
接下来,为适应目标物体在帧间可能产生的形变,对分割掩码进行边缘模糊操作,其数学公式为:
m'
其中函数Blur(·,·)表示模糊操作,参数rad表示配置的模糊半径,m′
为了使分割掩码能够适应物体形变,引入叶帕涅齐尼科夫核,利用该核所包含的物体像素区域所包含的先验信息与分割掩码进行融合,最终得到更加具有适应性的空间注意力图m,其数学公式为:
m=m'
在上式中,m表示最终的空间注意力矩阵,符号⊙表示矩阵元素级乘法,q表示叶帕涅齐尼科夫核,在一维数据下,其计算公式为:
其中,核函数的平滑程度是由参数σ表征的,r指核函数的输入,为一维数据;在图像领域,将其推广到二维表达式,其计算公式为:
其中,x,y代表图像中像素点坐标。
进一步的,所述交并比估计模块采用了孪生网络的基础结构,它包含有两个网络分支:目标模板图像分支和测试分支;对目标物体的中心点的位置偏移进行交并比估计采样作为测试分支输入,在目标模板图像分支,首先对模板图像和测试图像分别进行特征提取,并且进行池化操作得到测试图像特征图后,网络进一步将数据进行前向计算,通过全连接网络层对测试图像特征图进行处理,得到调制向量,该调制向量的作用是为目标物体与待估计的图像建立起关联,形成调制特征,最后交并比估计模块对该特征数据进行最后一组前向计算,通过全连接层计算出最终的IoU估计值。
本发明对所提出基于交并比估计的空间注意力强化学习跟踪方法进行了实现,并且在OTB2013、OTB50、OTB100、UAV123和VOT2019这五个数据集上进行了验证。在这五个数据集上大量的实验表明,在跟踪精度上,本发明所提出的算法达到了先进水平。
附图说明
图1是本发明实施例总体网络结构示意图。
图2是本发明实施例强化学习预定位模块的骨干网络结构示意图。
图3是本发明实施例交并比的估计模块结构图。
图4是本发明实施例掩码系数的网络结构图。
图5是本发明实施例的空间注意力生成示意图。
图6是本发明实施例在多个视频序列中与其他多种先进的目标跟踪算法的跟踪效果对比。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明做进一步详细说明应当理解,此处描述的具体实施例仅用以解释本发明,并不用于限定本发明。
基于交并比估计的空间注意力强化学习跟踪算法,其主要思想是:将基于强化学习的视频目标跟踪理解为一个二阶段问题(Twostage problem),首先利用深度强化学习对目标运动信息的捕捉能力来确定目标物体的中心点坐标,然后利用交并比估计网络进一步确定物体的边框,并且,在该过程中,提出利用基于物体分割的方法来实现可变形空间注意力以抑制背景噪声。从而使得跟踪器在跟踪过程中有优秀的性能表现。总体网络结构图请见图1。
步骤1,初始化网络模型,包括强化学习预定位模块、交并比估计模块和空间注意力模块;
所述强化学习预定位模块包括两组并行的主干网络和卷积模块,然后将经过卷积模块处理后得到的特征向量进行拼接,输入到全连接层中,实现目标物体的预定位;
如图2所示,所述主干网络结构包括两个结构相同的卷积池化模块,卷积池化模块包括一个卷积层、一个ReLU层、一个局部响应归一化层和一个池化层。
步骤2,将模板帧和检测帧第t帧分别输入到主干网络中,得到模板帧特征图和检测帧特征图,将模板帧特征图输入到卷积模块,得到模板帧特征向量;
步骤3,将检测帧第t-1帧输入到空间注意力模块得到可变形空间注意图;
步骤4,将可变形空间注意图与检测帧特征图进行逐像素相乘,然后输入到卷积模块中得到检测帧特征向量;
步骤5,将模板帧特征向量与检测帧特征向量进行拼接,然后经过一个全连接层中,实现目标物体的预定位,求出目标物体的中心点的位置偏移;
步骤6,将目标物体的中心点的位置偏移输入到交并比估计模块,利用随机方法在目标物体中心点位置生成多个具有不同宽高比例的矩形框,这些矩形框均属于候选框,然后计算得出这些候选框的IOU得分,并根据IOU得分进行排序,得到IOU得分最高的矩形框,获得目标物体的宽和高。
而且,采用基于演员Actor-评论家Critic模式的DDPG算法对强化学习预定位模块进行训练,Actor是跟踪定位动作的执行者,Critic是对动作执行效果的评价者,首先定义奖励函数为:
其中,p表示模块定位到的目标位置,G表示训练数据中对应的groundtruth;函数IoU(·)表示对Actor标定的矩形框和ground-truth计算交并比数值,在具备ground-truth的情况下,计算模块预测矩形边框与真实标记边框之间的重叠率,以作为对Actor奖励的依据,若重叠率大于某个阈值,Critic就认为Actor跟踪到了目标,此时的奖励为+1;否则,Critic认为Actor丢失了目标,此时给予的奖励为-1;
根据DDPG算法,用L2 Loss为Critic建立损失函数:
其中,N表示训练样本数目,
如图4所示,所述空间注意力模块包括掩码系数网络模块与可变形空间注意力模块,所述掩码系数网络模块通过FPN网络作为图像的特征提取骨干网络,得到的特征金字塔分别用于原型掩码和掩码系数的生成,具体实现过程如下:
首先根据融合强化学习预定位模块与交并比估计模块的定位结果进行采样,其公式为:
m'=Samp(p,pad)
其中,p表示目标物体标定的位置,pad表示采样图像范围相对于目标物体的扩展参数,Samp(·,·)表示采样过程,m′表示采样得到的图像块;
利用FPN进行特征提取的数学公式为:
m'
其中函数ψ
将特征金字塔m′
其中,函数ψ
得出的原型掩码m′
其中符号
最后,对融合后的掩码m′
其中,函数ψ
如图5所示,,在得到目标物体的分割掩码后,利用可变形空间注意力模块对该分割掩码进行后处理生成最终的空间注意力图,具体流程如下;
首先为了适应目标物体在帧间可能存在的像素尺度放大现象,将分割掩码m′进行尺度变化,其公式为:
m'
其中m′表示分割掩码,mag表示放大倍率参数,m′
接下来,为适应目标物体在帧间可能产生的形变,对分割掩码进行边缘模糊操作,其数学公式为:
m'
其中函数Blur(·,·)表示模糊操作,参数rad表示配置的模糊半径,m′
为了使分割掩码能够适应物体形变,引入叶帕涅齐尼科夫核,利用该核所包含的物体像素区域所包含的先验信息与分割掩码进行融合,最终得到更加具有适应性的空间注意力图m,其数学公式为:
m=m'
在上式中,m表示最终的空间注意力矩阵,符号⊙表示矩阵元素级乘法,q表示叶帕涅齐尼科夫核,在一维数据下,其计算公式为:
其中,核函数的平滑程度是由参数σ表征的,r指核函数的输入,为一维数据;在图像领域,将其推广到二维表达式,其计算公式为:
其中,x,y代表图像中像素点坐标。
如图3所示,所述交并比估计模块采用了孪生网络的基础结构,它包含有两个网络分支:目标模板图像分支和测试分支;对目标物体的中心点的位置偏移进行交并比估计采样作为测试分支输入,在目标模板图像分支,首先对模板图像和测试图像分别进行特征提取,并且进行池化操作得到测试图像特征图后,网络进一步将数据进行前向计算,通过全连接网络层对测试图像特征图进行处理,得到调制向量,该调制向量的作用是为目标物体与待估计的图像建立起关联,形成调制特征,最后交并比估计模块对该特征数据进行最后一组前向计算,通过全连接层计算出最终的IoU估计值。
应理解,上述实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围中。
- 基于交并比估计的空间注意力强化学习跟踪方法
- 基于视线估计的在线学习注意力跟踪方法及其应用