一种基于布隆过滤器的NDN路由表建立查找方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及一种基于布隆过滤器的NDN路由表建立查找方法,属于计算机网络的路由领域。
背景技术
相比端到端的IP网络通信模式,命名数据网络(Named Data Networking,NDN)以数据内容为中心,以内容名称为寻址方式,并基于内容名称建立路由表进行通信,解耦了数据内容与位置的关系。NDN转发路由表的建立是通过内容生产者向网络中路由器通告本节点持有数据内容的名称,路由器根据数据内容名称以及接收通告信息的接口,在转发信息库FIB(Forwarding Information Base)中建立内容名称路由条目,为后续的数据内容请求提供转发依据。FIB路由条目的基本结构为NDN名称与网口号之间的映射,代表兴趣包中的NDN名称与兴趣包的转发方向之间的关联。
NDN网络的传输机制是通过用户发送兴趣包驱动内容生产者回复数据包的方式进行数据通信,且兴趣包和数据包中都含有一个内容名称来标识用户需要获取的数据内容。当路由器转发来自用户的兴趣包时,首先查询FIB中对应名称的路由条目,并从该条目下的多个转发接口中选择最合适的接口转发数据请求。NDN将兴趣包流入的接口称为“下游接口”,兴趣包流出的接口称为“上游接口”,NDN节点的待定兴趣表PIT(Pending InterestTable)记录当前节点转发的兴趣包的内容名称及其对应的“下游接口”,保证接收数据包能按原路返回到兴趣包请求的发起位置;
NDN的名称命名方式是将内容名称被分为多个字段,在FIB检索中按照名称字段进行最长前缀匹配:例如,对于一个名称“/ab/cd”的兴趣包,首先检索“/ab/cd”的匹配项,如果不匹配,则继续检索“/ab”。
FPGA(Field Programmable Gate Array)是在PAL(可编程阵列逻辑)、GAL(通用阵列逻辑)等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
布隆过滤器(Bloom Filter)是由Bloom于1970年提出的。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于List、Map、Set等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。布隆过滤器空间占用低、存储器访问次数少,能够让查找速度和空间需求得到充分的优化。
目前FIB表的查询算法主要有以CPU代表的软件和以FPGA为代表硬件实现两种。对于CPU实现的FIB表,大多依靠从IP地址查找算法修改而来的布隆过滤器算法进行查找,而FPGA查找算法则大多为CPU查找算法的移植。以上算法存在的不足之处如下:
(1)在算法设计方面,相比长度确定为32比特或4字节,最长前缀匹配的最小单元为比特的IP地址,NDN的名称长度不定且最长前缀匹配的最小单元为名称段。目前大多数查询算法是由TCP/IP的路由查找算法改进而成,这类算法会存在很多冗余的运算。例如,原本查询的IP地址为4字节,最长前缀匹配在最坏情况下需要查询32个值,而NDN的名称长度与需要查询数量的比例远远大于IP地址,性能的瓶颈会从难以短时间内查询较多的匹配项,变为难以短时间内将较长的名称完成比对。
(2)在设备选取上,CPU查找算法一般为步骤较多的串行查找算法,而这些算法向FPGA的移植,对步骤数量的削减效果并不显著,其加速效果也不够强。例如,一般的CPU上实现的布隆过滤器算法需要对存储器做多次访问,在FPGA上会成为制约查找速度提升的性能瓶颈,但在CPU上并不会成为瓶颈,这是由于CPU和FPGA使用的存储器结构存在差异。如果只对CPU算法进行简单的移植,性能并不能达到最优。
上述不足的根源在于现有的查找算法,在设计之初并不是为NDN路由查找和FPGA上查找设计的,而是从IP地址查找的软件算法上改进移植的,较多的步骤数量让算法很难达到很高的查找速度,软件和硬件存储单元的差异也让存储空间需求很难降到足够低。
发明内容
针对命名数据网络NDN(Named Data Networking)的转发信息库FIB(ForwardingInformation Base)表查找算法存在“速度不够快”以及“占用存储空间太多”的技术问题,本发明的主要目的是提供一种基于布隆过滤器的NDN路由表建立查找方法,利用布隆过滤器的数据结构,将较长的NDN名称转化为固定长度的哈希值进行存储,从而减少储存空间的需求;充分利用FPGA在并行计算上的优势,设计适用于并行计算的布隆过滤器结构,由多个哈希函数同时进行计算,并通过数据流输出最长前缀匹配的每一级查找结果,从而增加路由表查找的速度和吞吐量;针对布隆过滤器可能存在的哈希冲突,设计第二层过滤器,对发生哈希冲突的NDN名称进行过滤,从而将冲突的可能降到最低,提升路由表查找的可靠性。
为了达到上述目的,本发明的技术方案如下:
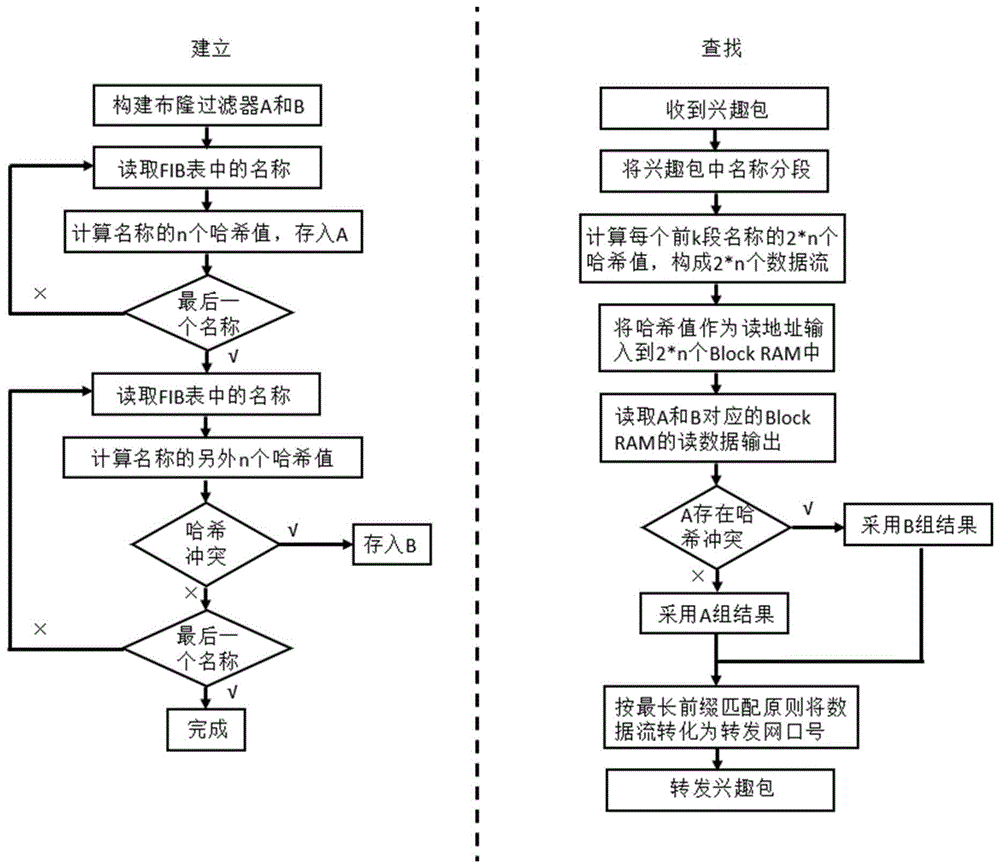
本发明公开的一种基于布隆过滤器的NDN路由表建立查找方法,通过建立两个布隆过滤器的存储格式,每个布隆过滤器包含多个哈希表,第一个布隆过滤器的深度大于第二个布隆过滤器;将NDN名称通过多个哈希函数转化为多个比NDN名称长度更短的固定长度的哈希值,并将所述转化后的多个固定长度的哈希值存储至第一个布隆过滤器中的各个哈希表内;计算布隆过滤器中发生哈希冲突的NDN名称,将第一个布隆过滤器中发生哈希冲突的NDN名称通过其他哈希函数转化为多个其他哈希值,将所述转化后的哈希值存储至第二个布隆过滤器中的各个哈希表内,然后将两个布隆过滤器发送至FPGA,存储到FPGA片上的Block RAM中;收到用户的兴趣包时,计算用户发送兴趣包中NDN名称的哈希值,得到多个满足最长前缀匹配需求的哈希值结果数据流,通过多个哈希函数的并行计算提高查找效率;将哈希值结果数据流作为读地址输入到Block RAM中,得到两组读数据流,分别对应两个布隆过滤器的输出;判断第一组查找结果数据流是否存在哈希冲突,如果不存在哈希冲入则采用第一组查找结果作为匹配结果,如果存在哈希冲突则采用第二组查找结果作为匹配结果,并由所述匹配结果构建匹配结果数据流,通过第二个布隆过滤器对哈希冲突进行过滤,降低哈希冲突概率,提高对兴趣包转发可靠性;根据匹配结果数据流,在最长前缀匹配原则下得到兴趣包的转发网口,并转发兴趣包,通过哈希流水线结构大幅度提高查找效率,提高兴趣包转发效率和吞吐量。
本发明公开的一种基于布隆过滤器的NDN路由表建立查找方法,包括如下步骤:
步骤1、构建两个布隆过滤器存储格式,每个布隆过滤器包含多个哈希表,第一个布隆过滤器的深度大于第二个布隆过滤器。每个哈希表对应不同的哈希函数,在FPGA上可以同时进行查询,以满足并行计算的要求;
步骤1.1:生成第一个二维数组,宽度为n,深度为
其中,n为使用的哈希函数个数,m取决于FPGA上的万兆以太网接口数量;
其中,网口为FPGA上连接的万兆以太网光纤的接口;
其中,d
步骤1.2:生成第二个二维数组,宽度为n,深度为
所述第一个布隆过滤器A的深度大于第二个布隆过滤器B;
为了避免过多的哈希函数消耗过多的FPGA片上计算资源,作为优选,所述哈希函数个数n不大于4;
为了平衡FPGA片上存储空间消耗与查找结果的可靠性,作为优选,d
步骤2、将FIB中NDN名称通过多个哈希函数转化为多个比NDN名称长度更短的固定长度的哈希值,并将所述转化后的多个固定长度的哈希值存储至第一个布隆过滤器A中的各个哈希表内,从而将长度不确定的NDN名称转换为固定大小数组中的一个数值,降低存储空间的需求;
步骤2.1:将FIB表中的NDN名称按照最长前缀匹配的要求进行分段;
其中,最长前缀匹配是指NDN中,如果一个NDN名称匹配多个查询结果,则取其中最明确的查询结果,即NDN名称段落数最多的查询结果作为匹配项;
步骤2.2:通过n个哈希函数,计算经过步骤2.1分段的每一段NDN名称的哈希值;
其中,哈希函数是指从不定长输入到定长输出的映射;
为了在保证哈希值结果分布均匀的同时尽量减少哈希函数消耗的FPGA片上运算资源,作为优选,哈希函数的选取如公式(1)所示:
公式(1)中,name为NDN名称输入,每次向函数输入16比特;^为异或运算符;%为除法求余数运算符;h(x)为32比特的哈希值,H取其中最后的d个比特;V为常数,通过选取多个不同的V得到多个不同的哈希函数;
步骤2.3:通过另一个的哈希函数,将步骤2.2中计算的各段NDN名称的哈希值输入哈希函数,输出为NDN名称的总哈希值,分别记为H
步骤2.4:若当前NDN名称对应的路由表网口号为w,读取步骤1.2中的数组A,将A[k-1][H
其中,路由表网口号为收到对应NDN名称的兴趣包以后,发送兴趣包的目的网口;
其中,A[x][y]代表二维数组A,即第一个布隆过滤器A中的数,该数位于A的第x行、第y列;
步骤2.5:如果FIB表还有其他NDN名称,则跳转到步骤2.1,反之,若FIB表中所有NDN名称都处理完毕,则继续进行步骤3。
步骤3、针对步骤2构建的第一个布隆过滤器,计算发生哈希冲突的NDN名称,将第一个布隆过滤器A中发生哈希冲突的NDN名称通过其他哈希函数转化为多个其他哈希值,将所述转化后的哈希值存储至第二个布隆过滤器B中的各个哈希表内;
其中,哈希冲突为两个或以上的NDN名称拥有同样的哈希值,造成查询结果的不确定;
步骤3.1:按照步骤2.2中的哈希函数,计算NDN名称的哈希值,具体包含如下子步骤:
步骤3.1A:通过步骤2.2中的哈希函数,分别计算每一段NDN名称的哈希值;
步骤3.1B:通过步骤2.3中的哈希函数,将步骤4.3A中计算的各段NDN名称的哈希值输入哈希函数,输出为NDN名称的总哈希值,记为H
步骤3.2:对于第一个布隆过滤器A,对所有A[k-1][H
其中,按位与运算为一种逻辑运算,用符号“&”表示,对输入的每一个比特分别进行运算,若所有输入的第x个比特均为1,则输出第x个比特为1,反之则第x个比特为0;
所述步骤3.2用来确定发生哈希冲突的NDN名称范围;
布隆过滤器A中,每个FIB表中的NDN名称发生哈希冲突,需要该NDN名称的n个哈希值均存储了另一个网口号,即存在n个其他NDN名称,拥有共同的、与当前NDN名称网口号不同的网口号,发生哈希冲突的概率p
公式(2)中,len为FIB表中的NDN名称数量;
步骤3.3:选取与步骤2.2不同的另外n个哈希函数,若当前NDN名称在步骤3.2中判定发生哈希冲突,则计算发生的NDN名称的哈希值,反之则不计算,具体包含如下子步骤:
步骤3.3A:通过新哈希函数,分别计算每一段NDN名称的哈希值;
步骤3.3B:通过步骤2.3中的哈希函数,将步骤4.3A中计算的各段NDN名称的哈希值输入哈希函数,输出为NDN名称的总哈希值,记为H
步骤3.4:若当前NDN名称对应的路由表网口号为w,对于第二个布隆过滤器B,将B[k-1][H
步骤3.5:如果FIB表还有其他NDN名称,则跳转到步骤3.1,反之,若FIB表中所有条目都处理完毕,则继续进行步骤4;
布隆过滤器B中,每个FIB表中的NDN名称发生哈希冲突,需要该NDN名称的n个哈希值均存储了另一个网口号,即存在n个其他NDN名称,拥有共同的、与当前NDN名称网口号不同的网口号,发生哈希冲突的概率p
步骤4、将步骤2构建的第一个布隆过滤器A和步骤3构建的第二个布隆过滤器B发送至FPGA并存储到FPGA片上的Block RAM;
步骤4.1:生成两组Block RAM,每组n个,第一组深度为
其中,Block RAM为FPGA片上的随机存储器,是FPGA片上的主要存储单元;BlockRAM的深度代表内部存储数据的个数,位宽代表每一个数据包含多少个比特;Block RAM有3个输入和1个输出,输入为写地址、写数据、读地址,输出为读数据;
步骤4.2:将CPU产生的数据传输给FPGA,将A[0]、A[1]…A[n-1]存储至第一组Block RAM,对第一组的第k个Block RAM,写地址为j时,写数据为A[k-1][j],k遍历1~n的所有整数,j遍历
步骤5、用户发送兴趣包,计算用户发送兴趣包中NDN名称的哈希值,得到多个满足最长前缀匹配需求的哈希值结果数据流,通过多个哈希函数的并行计算提高查找效率;
步骤5.1:提取用户中兴趣包的NDN名称部分;
步骤5.2:将兴趣包的NDN名称按照最长前缀匹配的要求进行分段,然后转化为数据流,每个时钟周期输出NDN名称的一段;
其中,时钟为数字电路中,按照固定频率在0和1之间不断跳转的信号,用于驱动数字电路模块的运转;
步骤5.3:通过步骤2.2和步骤3.3中选取的2*n个哈希函数,计算每一段NDN名称的2*n个哈希值,每个时钟周期向哈希值计算模块输入16比特,在全部NDN名称输入完毕后,可以得到单段NDN名称的哈希值;
其中,哈希计算模块为电路的一个部分,用于将16比特位宽、多个时钟周期的数据输入转化为哈希值输出;
步骤5.4:通过步骤2.3中选取的哈希函数,将步骤5.3中计算的单段NDN名称哈希值的数据流送入另一个哈希计算模块,对于p段的NDN名称,在第k个时钟周期,输出第1~k段的哈希值,k遍历1~p中所有整数,从而得到满足最长前缀匹配需求的总哈希值数据流。
步骤6、将步骤5中的哈希值结果数据流作为读地址输入到Block RAM中,输出为两组、每组n个的输入读地址对应的m比特的读数据,分别对应布隆过滤器A和B的输出,由所述Block RAM读数据构建查找结果数据流;
步骤6.1:将总哈希值数据流作为读地址输入到两组Block RAM中;
其中,读地址为Block RAM的输入之一,输入读地址后,Block RAM会输出对应地址中储存的数据;
步骤6.2:获得Block RAM的读数据输出,哈希值数据流中的每一个数据都会得到一个对应的查找结果,得到2组,每组n个的m位宽的查找结果数据流,分别对应布隆过滤器A和B;
步骤7、判断步骤6中的第一组查找结果数据流是否存在哈希冲突,如果不存在哈希冲入则采用第一组查找结果作为匹配结果,如果存在哈希冲突则采用第二组查找结果作为匹配结果,并由所述匹配结果构建匹配结果数据流,通过第二个布隆过滤器对哈希冲突进行过滤,降低哈希冲突概率,提高对兴趣包转发可靠性;
步骤7.1:将步骤6得到的两组查找结果数据流分别进行按位与运算,得到布隆过滤器A和B对应的两个位宽为m的运算结果;
步骤7.2:判断布隆过滤器A的运算结果是否有2个或以上的比特为1,如果有,代表存在哈希冲突,则选取布隆过滤器B的运算结果作为输出,反之,如果没有,代表未发生冲突,选取布隆过滤器A的运算结果作为输出,由所述输出构建查询结果数据流。
步骤8、根据步骤7中的匹配结果数据流,在最长前缀匹配原则下得到兴趣包的转发网口,并转发兴趣包,通过哈希流水线结构大幅度提高查找效率,提高兴趣包转发效率和吞吐量。
步骤8.1:设置匹配结果初始值为0,按照最长前缀匹配原则,若步骤7.2中的查询结果数据流的输出不为0,代表匹配,则将匹配结果替换为当前查询结果,表示有更准确的匹配出现,反之,则不修改匹配结果,在全部NDN名称段落的查询完成后,输出m比特位宽兴趣包的转发网口信息;
步骤8.2:如果步骤8.1中得到的兴趣包转发网口信息中,第k个比特为1,则将兴趣包向第k个网口进行发送,k遍历1~m中所有整数,如果有多个比特为1则同时向多个网口转发。
有益效果:
1.相对于目前基于CPU的布隆过滤器方法通过串行操作进行查找,本发明公开的一种基于布隆过滤器的NDN路由表建立查找方法,充分利用FPGA的并行计算能力,将多个CPU上需要依次进行的步骤在同一个时钟周期下同时完成,从而达到更大的查找吞吐量。
2.相对于目前基于CPU的布隆过滤器方法以计算机内存作为主要存储单元,需要多次读取内存数据进行操作,本发明公开的一种基于布隆过滤器的NDN路由表建立查找方法,并行对FPGA片上的Block RAM进行读取,只需要一个时钟周期的存储器读取就能得到一个查询结果,能够在更短的时间获取查找结果,降低路由查找延时。
3.相对于目前布隆过滤器方法中的哈希冲突问题,本发明公开的一种基于布隆过滤器的NDN路由表建立查找方法,通过第二层查找对冲突的情况进行过滤,以较小的存储空间代价,换取比现有方法更低的冲突率,提升查找结果的可靠性;
4.与目前基于CPU的布隆过滤器方法相比,本发明公开的一种基于布隆过滤器的NDN路由表建立查找方法,通过构建适用于并行计算的布隆过滤器架构,并对哈希冲突的情况进行过滤,进一步优化路由查找速度、提高查找吞吐量、降低哈希冲突的发生概率,实现高效、快速、可靠的路由表查找。
附图说明
图1为本发明基于布隆过滤器的NDN路由表建立查找方法中,建立和查找操作的流程图。
图2为本发明基于布隆过滤器的NDN路由表建立查找方法中,公式(1)对应的哈希函数的热图,表示哈希函数在所有取值上的分布情况。
图3为本发明基于布隆过滤器的NDN路由表建立查找方法中,接收兴趣包后进行查找的时序图。
具体实施方式
下面将结合附图和实施例对本发明加以详细说明,同时论述本发明的技术方案解决的技术问题及有益效果。需要指出的是,所描述的实施例旨在便于对本发明的理解,对本发明不起任何限定作用。
实施例1
本实施例基于NDN网络,用户发送兴趣包请求计算任务,路由器根据FIB表查询兴趣包的转发位置,并对兴趣包进行转发。如图1所示,应用本发明基于布隆过滤器的NDN路由表建立查找方法,具体实现方法如下:
步骤I、构建两个布隆过滤器存储格式,每个布隆过滤器包含多个哈希表,第一个布隆过滤器的深度大于第二个布隆过滤器。每个哈希表对应不同的哈希函数,在FPGA上能够同时进行查询,以满足并行计算的要求,具体包括如下子步骤:
步骤I.1生成第一个二维数组,宽度为2,深度为
步骤I.2生成第一个二维数组,宽度为n,深度为
步骤II、将FIB中NDN名称通过多个哈希函数转化为多个比NDN名称长度更短的固定长度的哈希值,并将所述转化后的多个固定长度的哈希值存储至第一个布隆过滤器A中的各个哈希表内,具体包括如下子步骤:
步骤II.1将FIB表中的NDN名称按照最长前缀匹配的要求进行分段,第一条得到ab,第二条得到ab、cde、fghi,第三条得到jk、lmn;
步骤II.2通过2个哈希函数,计算经过步骤2.1分段的每一段NDN名称的哈希值;
其中,使用的哈希函数为:
其中,name为名称输入,每次向函数输入16比特,h(x)为32比特的哈希值,H取其中最后的d个比特,步骤II.2中d为19,步骤III.3中d为17;
其中,通过选取不同的初始值V,即可得到不同的哈希函数。
步骤II.3通过另一个哈希函数(选取另一个V值),将步骤II.2中计算的各段名称的哈希值输入哈希函数,输出为名称的总哈希值,假设计算结果如表1所示;
表1实例中的FIB表
步骤II.4当前名称为/ab时,H
当前名称为/ab/cde/fghi时,H
当前名称为/jk/lmn时,H
步骤II.5如果FIB表还有其他名称,则跳转到步骤II.1,反之,若FIB表中所有条目都处理完毕,则继续进行步骤III;
步骤III、针对步骤2构建的第一个布隆过滤器,计算发生哈希冲突的NDN名称,将第一个布隆过滤器A中发生哈希冲突的NDN名称通过其他哈希函数转化为多个其他哈希值,将所述转化后的哈希值存储至第二个布隆过滤器B中的各个哈希表内,具体包括如下子步骤:
步骤III.1按照步骤II.2中的哈希函数,计算名称的哈希值,仍然得到H
步骤III.2当前名称为/ab时,对A[0][123]、A[1][234]进行按位与运算,得到结果为0110&0100=0100,只有一个比特为1,无哈希冲突;
当前名称为/ab/cde/fghi时,对A[0][123]、A[1][345]进行按位与运算,得到结果为0110&0110=0110,超过一个比特为1,有哈希冲突;
当前名称为/jk时,对A[0][234]、A[1][345]进行按位与运算,得到结果为0100&0110=0100,只有一个比特为1,无哈希冲突;
步骤III.3选取与步骤2.2不同的另外n个哈希函数,对发生哈希冲突的/ab/cde/fghi计算H
步骤III.4当前名称为/ab/cde/fghi时,H
步骤III.5如果FIB表还有其他名称,则跳转到步骤III.1,反之,若FIB表中所有条目都处理完毕,则继续进行步骤IV;
步骤IV、将步骤II构建的第一个布隆过滤器A和步骤III构建的第二个布隆过滤器B发送至FPGA并存储到FPGA片上的Block RAM,具体包括如下子步骤:
步骤IV.1生成两组Block RAM,每组2个,第一组深度为2
步骤IV.2用AXI-DMA或PCI-E等方式将软件产生的数据发送至FPGA,将A[0]、A[1]发送至第一组Block RAM,将B[0]、B[1]发送至第二组Block RAM;
至此,路由表的建立完成,以上工作由CPU完成,步骤5及以后的工作由FPGA完成;
步骤V、用户发送名称为/ab/cde/fghi的兴趣包,计算用户发送兴趣包中NDN名称的哈希值,得到多个满足最长前缀匹配需求的哈希值结果数据流,具体包含如下子步骤:
步骤V.1将名称分段为ab、cde、fghi,然后转化为数据流,每个时钟周期输出一段名称,为图1中的name信号;
步骤V.2将每一段名称拆分为16比特的数据流,得到name1、name2、name3,将其输入到哈希计算模块中,在全部名称输入完毕后,可以得到单段名称的哈希值数据流,为图1中的h1(namex)和h2(namex)两个信号;
步骤V.3将h1(namex)和h2(namex)作为输入计算总哈希值,为图1中h1(name)和h2(name)两个信号,信号中黄色为/ab的查找结果,橙色为/ab/cde的查找结果,蓝色为/ab/cde/fghi的查找结果;
步骤VI、将步骤V中的哈希值结果数据流作为读地址输入到Block RAM中,输出为两组、每组2个的输入读地址对应的4比特的读数据,分别对应布隆过滤器A和B的输出,由所述Block RAM读数据构建查找结果数据流,具体包含如下子步骤:
步骤VI.1将总哈希值数据流h1(name)和h2(name)作为读地址输入到两组BlockRAM中;
步骤VI.2读取Block RAM的输出,为图1中ram_dout11、ram_dout12、ram_dout21、ram_dout22四个信号;
步骤VII、判断步骤VI中的第一组查找结果数据流是否存在哈希冲突,如果不存在哈希冲入则采用第一组查找结果作为匹配结果,如果存在哈希冲突则采用第二组查找结果作为匹配结果,并由所述匹配结果构建匹配结果数据流,具体包含如下子步骤:
步骤VII.1对ram_dout11和ram_dout12按位与,若结果为0,或1个比特为1,则认为无哈希冲突,输出按位与结果,否则输出ram_dout21、ram_dout22按位与的结果,输出结果为图1中total_dout信号;
名称为/ab(图1中黄色)时,0110&0100=0100,无哈希冲突,输出total_dout为0100;
名称为/ab/cde(图1中橙色)时,0&0=0,无哈希冲突,输出total_dout为0;
名称为/ab/cde/fghi(图1中蓝色)时,0110&0110=0110,有哈希冲突,输出total_dout为0010&0010=0010;
步骤VII.2设置匹配结果初始值为0,若total_dout信号为0,则不修改输出,若total_dout信号不为0,则覆盖上一个结果,代表有更精确的最长前缀匹配结果出现,输出信号为图1中的wan信号;
步骤VIII、按照匹配结果wan信号转发兴趣包,实例中实际匹配结果为0010,第二个比特为1而其他为0,即需要将兴趣包发送至2号网口;
至此,基于布隆过滤器的NDN路由表建立查找方法结束。
本实施例公开的基于布隆过滤器的NDN路由表建立查找方法在路由查找方面的应用,能够显著提高查找速度、降低存储空间需求并减少冲突的发生。
本实施例通过计算路由表,然后用FPGA并行计算多个哈希函数,将很多计算步骤在同一时间完成,从而得到最长前缀匹配结果的方法,能够以很高的吞吐量进行兴趣包的查找和转发。利用第二层布隆过滤器专门存储哈希冲突的名称,在存储空间的需求没有显著提升的情况下,大幅度降低哈希冲突的发生概率,从而使本实施例查找结果的可靠性大幅度提升,对查找速度要求很高的场景尤为适用。
以上所述的具体描述,对发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。