一种基于不可逆变换的联合训练隐私保护方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于深度学习算法中训练数据隐私保护技术领域,具体涉及一种由多方参与联合训练的场景。该方法对各方提供的训练数据提供隐私保护。
背景技术
深度学习为代表的人工智能技术已开始渗透到工作与生活的各个层面,如人脸识别、语音输入、基因探测等。在实际应用中,深度学习算法经常需要将多个合作方的数据联合起来集中训练以取得更好的训练效果。集中式联合训练即将所有合作方的训练数据集中起来共同进行模型训练可以解决因训练数据不足造成的模型性能低下的问题。但集中式的联合训练主要面临各合作方数据交叉泄露的问题,同时,这种方式不符合隐私保护规范。因为在许多应用中,数据信息所有权属于个人,公司收集的个人信息无权透露给第三方。另外,由于合作方的多样性,各合作方提供的训练数据质量参差不齐,当有个别或部分合作方提供了低质量数据时,这将对模型的训练效果造成较大的影响。需要一种既可保护各方数据隐私同时又可避免低质量数据对训练结果造成负面影响的深度学习隐私保护方法。
目前在针对训练数据的隐私保护方面,目前主流的方法有同态加密(HE)、结合同态加密的安全多方计算(SMC)及差分隐私(DP))等。基于同态加密的方案能很好的保护训练数据隐私,但是其加密速度慢且通信成本高,这在数据集较大时是不实用的。而基于差分隐私的方案不适于集中式的合作训练。在多方合作的深度学习训练中,如何弱化低质量数据的参与对训练结果的影响也是一个重要课题。有学者在物联网领域中提出通过过滤掉质量较差的参数来弱化低质量数据参与者对模型的影响。同时Xu等人提出通过提高高质量数据的权重并降低低质量数据权重的方式解决低质量数据参与训练的问题。另外Zhao等人首次提出在低质量训练数据参与者存在时的联合训练保护方法。该方案能够有效的降低低质量数据参与者对合作训练的模型性能的影响。然而以上方案针对的是参与者训练数据整体的数据质量,当参与者只有少量数据时以上无法判定数据的质量并有效的防止参与者对于模型性能的影响。
综上目前多方协作训练的隐私保护方案存在以下问题:
(1)计算开销以及通信开销较大;
(2)没有考虑到数据集中的低质量数据对于整体模型精度的破坏;
由此可见,目前的深度学习隐私保护方法存在着计算开销大且没有考虑到低质量训练数据对于整体模型预测精度的影响。为此本发明提出一种基于不可逆变换的深度学习数据集的隐私保护方法,基于随机节点的方式对原始数据集进行不可逆的变换,并且通过计算各参与者数据集的可信度过滤掉低质量的数据集防止低质量数据集对整体模型预测精度的影响。该方法能在保护数据集隐私安全的同时避免低质量数据对整体模型的影响。
发明内容
本发明的发明目的在于:针对上述存在的问题,提供一种通用、有效、低成本的深度学习方法。该方法联合多方参与训练并保护各方数据集隐私安全。
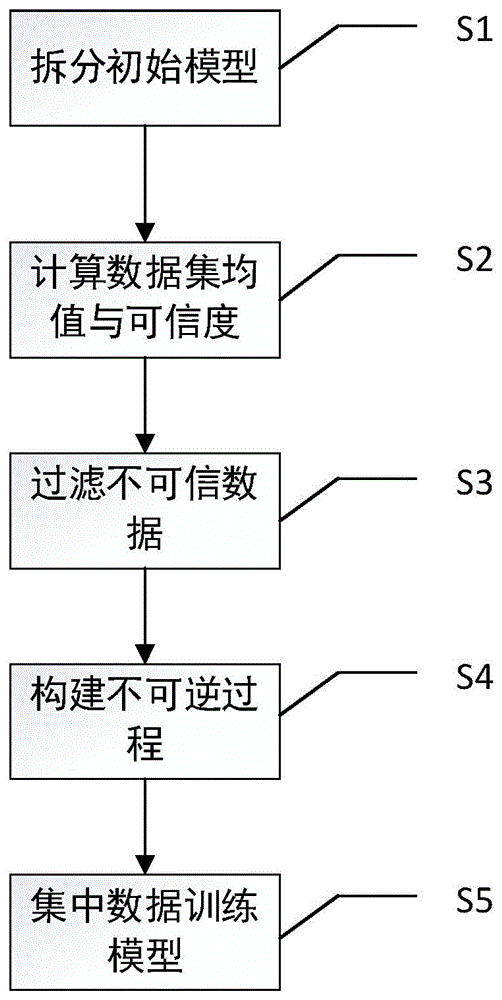
本发明的在联合深度学习下支持训练集成员隐私保护的方法,包括以下步骤:
S1:将初始模型拆分为本地模型以及中心服务器模型,收集并获取各方原始数据集用于训练。
S2:计算各参与者原始数据集的均值以及计算各参与者数据集的可信度。
S3:过滤掉低质量数据集中可信度较低的数据,并使用过滤后数据参与本地的不可逆变换
S4:对本地模型网络添加随机干扰节点构建不可逆的训练过程;各方在本地使用各自的原始训练数据经过单层不可逆训练得到本地训练结果;其中构建不可逆的训练过程具体为:在本地网络输入层中添加d个随机节点,将原始数据集作为输入层数据进行训练且各初始变换参数矩阵为w,得到变换后的数据集D’,其中变换参数w的维度为(n+d)*n,随机节点在每组数据时都是随机的。
S5:集中各方参与者训练后的结果在中心服务器上进行进一步训练,得到训练好的网络模型。
与现有深度学习隐私保护方法相比,本发明的基于不可逆变换技术的协作神学学习隐私保护方法有以下优点:
(1)隐私保护的计算开销与通信开销较小;
(2)能有效弱化低质量训练数据对于整体训练模型的预测精确度的影响;
附图说明
图1为本发明具体实施方式中,本发明处理流程图;
图2为本发明实施例中本地模型与中心服务器模型的结构图;
图3为本发明中整体流程示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。
本发明基于不可逆变换的处理机制,使得模型中第一层至第二层之间的训练过程不可逆,保护了数据集的隐私。并且本发明通过计算各数据集的可信度过滤掉可信度低的数据集中的低质量数据,使得低质量数据对于模型的预测精度影响极大的降低,能够有效避免低质量参与者对于模型的破坏。参见图1,本发明的在协作深度学习下的保护训练集成员的隐私,隐私保护的方法的具体实现过程如下:
步骤1:拆分初始模型。对于待进行训练的模型M(用户选择的已有或自行设置的神经网络模型),将该模型拆分成两部分,用户模型部分以及中心服务器模型部分。具体包括以下步骤:
步骤1.1:在用户端以及中心服务器端安装网络所需环境,并将该环境部署于安全环境下。
步骤1.2:在用户端部署网络模型其结构为初始模型M的第一层至第二层。在中心服务器端部署网络模型其结构为初始模型去除第一层模型的结构。
步骤1.3:初始化用户端模型,并约定各用户初始变换参数为w。
步骤2:计算各参与者原始数据集的均值以及计算各参与者数据集的可信度。对于各方的数据集需要分别计算各方数据集的各类别数据各特征属性的均值信息以及通过均值信息计算出各参与者数据集的可信度。具体包括以下步骤:
步骤2.1:计算出各参与者各类别数据各特征属性的均值。假设k个参与者参加训练,第i个参与者用户n
步骤2.2:计算出各参与者数据集的可信度,假设有k个参与者参加训练,第i个参与者用户拥有n
步骤2.3:将每个数据集的可信度传输至中心服务器,中心服务器可根据各方参与者的数据可信度调整各参与者的权重占比,提高高质量数据的权重占比,降低低参与者的权重占比。
步骤3:过滤掉低质量数据集中可信度较低的数据,并使用过滤后数据参与本地的不可逆变换。对于各数据集中可信度较低的数据集,对低质量数据集进行筛选,剔除掉可信度较低的数据记录。具体包括以下步骤:
步骤3.1:针对低质量的参与者的数据集筛选,其中单组数据的质量计算过程可描述为:
步骤3.2:使用筛选后的数据参与不可逆变换。
步骤4:对本地模型网络添加随机干扰节点构建不可逆的训练过程。在用户端模型中构建一个不可逆的训练过程来保证训练数据的隐私。具体包括以下步骤:
步骤4.1:在步骤1中的用户端模型中输入层添加d个随机节点,单个随机节点的生成如下:
n
其中rand(0,1)表示符合均值为0方差为1的高斯分布的随机数,d表示随机节点的个数。
步骤4.2:将原始数据输入用户端模型中并经过训练后得到变换后数据。
步骤4.3:将变换后数据传输至中心服务器端。
步骤5:集中各参与者处理后数据并在中心服务器上进行训练,并在进行更新网络参数是使用各参与者的可信度作为更新参数的权重,训练后得到网络模型。
综上,本发明的不可逆转换采用将原始模型拆分为本地模型与中心服务器模型的方式保护了原始训练书记的隐私。同时,本发明通过计算各数据集可信度极大降低了低质量数据集对于整体模型训练结果的影响。另外,该方法只需极少的计算开销以及通信开销就能实现数据集的隐私保护。
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。