一种工业设计领域产品知识图谱构建方法及系统
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及工业设计产品信息处理领域以及自然语言处理领域,尤其是设计一种工业设计领域产品知识图谱构建方法与系统。
背景技术
设计师在进行工业产品设计时,需要花费大量时间调研、收集相关产品信息,这会降低设计师的工作效率。知识图谱是设计师开展工作的优秀辅助工具,可以有效缩短产品调研时间,同时帮助设计师从大数据的角度快速、有效和直观地了解行业或者产品信息。
知识图谱构建的核心步骤是知识抽取和知识融合。目前基于深度神经网络的实体识别或关系抽取模型对于关系上下文特征提取效果较差,以至于无法解决样本中关系重叠问题,且模型层数多、复杂度高。现有的多数实体对齐工作将研究核心聚焦于实体结构与实体属性信息,以实体为中心进行嵌入学习,容易忽略关系在实体对齐中的重要性,这导致了现有的实体对齐模型对于存在复杂多关系结构的图谱的对齐效果不佳。
发明内容
本发明要克服现有技术的上述缺点,提供一种工业设计领域产品知识图谱构建方法与系统。
本发明的技术方案为:一种工业设计领域产品知识图谱构建方法,其特征在于:包括以下步骤:
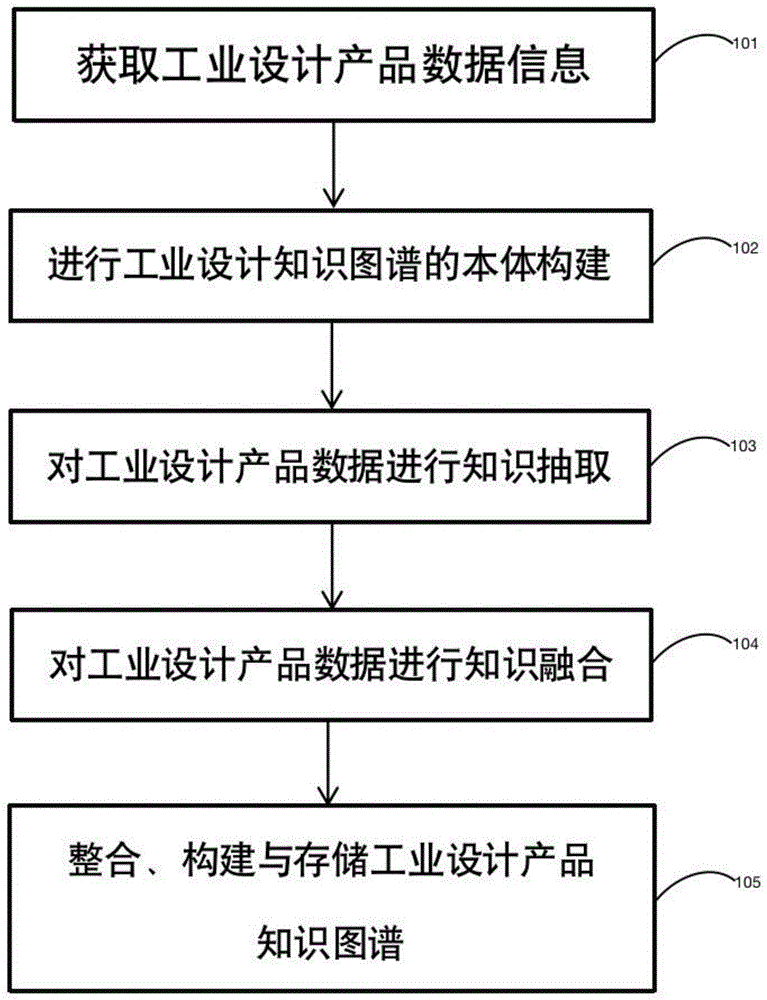
步骤101,获取工业设计产品信息;
步骤102,对知识图谱进行本体构建;
步骤103,对工业设计产品数据进行知识抽取;
步骤104,对工业设计产品数据进行知识融合;
步骤105,整合、构建与存储工业设计产品知识图谱。
进一步的,所述步骤101具体包括:
确定需要获取的产品的基本信息以及字段,所需的产品信息有:产品名称、品牌、价格、重量、材质、颜色、产地、上架时间、简介、适用场所等;
确定数据来源,主要是主流电商网站和产品设计网站,有淘宝、天猫、京东、亚马逊、普象网等;
使用爬虫框架Scrapy开发数据爬取脚本,爬取内容包含上述列出的产品信息,爬取的目标网站包括上述电商网站和产品设计网站。
进一步的,所述步骤102具体包括:
定义本体类别,将本体分为香薰机、人群、地点、设计风格、外观、品牌六个类别,为了便于图谱的扩展和关系的添加,所设计的大类中包含了多个子类,例如“人群”类别下有目标用户、设计师等自类,“地点”类别下游产地、使用场地等子类,“外观”类别下有材质、颜色和形状等子类;
定义本体属性,根据设计需求,将本体的属性定义为品牌、价格、颜色、材质、产地、尺寸、重量、销售量、评论数、口碑分数等,根据数据类型,将价格、尺寸、重量、销售量、评论数、口碑分数、面积、人口设置为数值型,其他属性均为字符串类型;
定义实体语义关系,语义关系时实体与实体之间的重要联系根据所构建的本体间的语义关系,将本体间的关系定义为“属于”、“产自”、“用于”等。
进一步的,所述步骤103具体包括:
实体关系抽取与实体识别,关系抽取的工作是要把句子中的关系一一识别并提取出来,实体识别的目的是从文本中抽取出所需要的名词类实体元素,关系抽取与实体识别对于构建高质量知识图谱起着至关重要的作用;基于Bert模型完成关系抽取任务,依据香薰机产品数据集的格式对数据处理部分进行调整,包括数据读取方式和tokens的处理;由于是使用一个模型对关系抽取和实体识别进行联合处理,实体识别模块的输入即是关系抽取模块中得到的输出,模型的Loss值需要由关系抽取和实体识别两部分任务共同决定,需要为它们分配权重,将关系抽取任务和实体识别任务的权重比设定为4:6。
进一步的,所述步骤104具体包括:
实体对齐模型设计,目前大多数基于嵌入的实体对齐模型聚焦于实体结构和属性信息的融合表示,对于实体关系,仅仅是学习一个简单的嵌入,这样学习到的实体嵌入对于实体关系这一重要的特征信息利用率不高,设计了一个以实体关系为中心进行嵌入的实体对齐模型RelationTransH,以弥补现有模型在实体关系特征学习上的缺失问题。
进一步的,所述步骤105,具体包括:
依据步骤102中所构建出的知识图谱本体结构和属性信息,对已完成知识抽取与知识融合操作的工业设计产品数据进行符合本体结构要求的相应整理与合并,将数据导入到图数据库Neo4j中,形成可视化的工业设计领域产品知识图谱。
本发明还提出了一种工业设计领域产品知识图谱构建系统,包括工业设计产品数据采集模块、知识抽取模块、知识融合模块和知识图谱整合存储模块;
所述工业设计产品数据采集模块用于采集工业设计产品的基本信息,利用爬虫框架从电商网站和设计网站等公开网络平台爬取产品信息;
所述知识抽取模块用于对采集到的产品数据进行关系抽取与实体识别,识别并提取出产品数据中的语义关系和实体,用于后续知识图谱的构建;
所述知识融合模块用于识别出不同数据来源中指代为同一个对象的实体,去除重复的实体,以此优化知识图谱的存储空间和拓扑结构,为构建高质量的工业设计领域产品知识图谱提供保障;
所述知识图谱整合存储模块用于将产品数据导入到图数据库中,在图数据库中构建出可视化的图谱。
进一步的,所述工业设计产品数据采集模块使用的爬虫框架主要为Scrapy,前端界面采用Vue.js、Element UI组件进行开发,可定时、定量在各大电商网站和设计网站爬取产品信息。
进一步的,所述识抽取模块以基于Bert的关系抽取—实体识别联合处理模型为核心,先进行关系抽取,使用关系抽取的输出结果作为实体识别的输入,完成知识抽取任务。
进一步的,所述知识融合模块的主要功能是实现实体的对齐,以实体关系的特征聚合的中心,聚合实体的上下文信息,得到特征信息丰富的实体表示向量,用以计算实体之间的相似度,得到对齐实体。
本发明提供的一种工业设计领域产品知识图谱构建方法及系统,可构建出高质量的工业设计领域产品知识图谱,为设计师进行设计工作或者用户了解产品提供帮助。
本发明的优点是:
本发明有针对工业设计产品的特征,详细设计产品信息的各条字段,在知识图谱构建的两个核心步骤,即知识抽取和知识融合步骤中,改进了Bert模型和现有的实体对齐模型,使得其有更加优秀的关系抽取、实体识别和实体对齐效果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例1的方法流程图;
图2为本发明实施例1中的知识抽取流程图;
图3为本发明实施例1中的实体对齐上下文嵌入计算方法图;
图4为本发明实施例2的系统示意图;
图5为所构建的工业设计领域产品知识图谱部分展示图。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
实施例1
本发明实施例1提出了一种工业设计领域产品知识图谱构建方法,为了辅助产品设计师的设计工作,提升设计效率,现将工业设计领域的产品信息进行有效整合,构建出一个高质量的工业设计领域知识图谱,如图1为本发明实施例提供的一种工业设计领域产品知识图谱构建方法流程图。
在步骤101中,对网络开放平台的工业设计产品(以香薰机为例)数据进行爬取和处理,在京东、淘宝、亚马逊等电商网站上以及各类百科和设计网站上,根据“香薰”、“香薰机”、“香薰灯”和“加湿器”等关键词,爬取到约5000条香薰机产品数据,以此建立出香薰机产品数据集。
在步骤102中,需要进行知识图谱本体构建操作,确定图谱中所需的本体的类别、属性和语义关系,本体构建方式包括自动化构建、半自动化构建和人工构建三类方法;
本体类别定义时将本体分为香薰机、人群、地点、设计风格、外观、品牌六个类别,为了便于图谱的扩展和关系的添加,所设计的大类中包含了多个子类,例如“人群”类别下有目标用户、设计师等自类,“地点”类别下游产地、使用场地等子类,“外观”类别下有材质、颜色和形状等子类;
本体属性定义时根据设计需求,定义品牌、价格、颜色、材质、产地、尺寸、重量、销售量、评论数、口碑分数等属性,根据数据类型,将价格、尺寸、重量、销售量、评论数、口碑分数、面积、人口设置为数值型,其他属性均为字符串类型;
本体语义关系定义时,将本体间的关系定义为“属于”、“产自”、“用于”等;
本体构建方式包括自动化构建、半自动化构建和人工构建三类方法;其中自动化和半自动化构建本体的效率高,但本体质量难以得到保证;人工构建方式的本体构建效率较低,但构建出的本体质量高;为保证知识图谱的质量,采用自顶向下和自底向上结合的方式人工构建香薰机产品本体。
在步骤103中,知识抽取包括关系抽取和实体识别,知识抽取的流程如图2所示;
使用基于Bert的关系抽取—实体识别联合处理模型完成知识抽取处理,由于是使用一个模型对关系抽取和实体识别进行联合处理,实体识别模块的输入即是关系抽取模块中得到的输出,模型的Loss值需要由关系抽取和实体识别两部分任务共同决定,需要为它们分配权重,将关系抽取任务和实体识别任务的权重比设定为4:6;
关系抽取的工作是要把句子中的关系一一识别并提取出来,例如句子“美的香薰机净化空气”中含有“品牌”和“功能”关系,经过实体关系抽取可得到关系和实体相对应的三元组,完成领域知识图谱中的知识抽取;关系抽取模块参数设置为:输入向量维度为128,最大字符数为256,优化器、激活函数和损失函数分别为Adam优化器、Sigmoid和交叉熵损失函数,学习率设置为0.002;最终可完成实体关系的抽取任务,例如输入句子:“text”:“美的香薰机净化空气”,输出三元组:“triple_list”:[{“predicate”:“品牌”,“object”:“香薰机”,“subject”:“美的”},{“predicate”:“功能”,“object”:“净化空气”:“subject”:“美的香薰机”}]};
实体识别的目的是从文本中抽取出所需要的名词类实体元素,命名实体识别是构建知识图谱最基本的任务之一,实体识别模型参数设置为:输入向量维度为128,最大字符数为128,优化器、激活函数和损失函数分别为Adam优化器、Softmax激活函数和交叉熵损失函数,学习率设置为0.005。
在步骤104中,知识融合主要方法为实体对齐,在构建知识图谱时,知识往往来源于多个不同的数据源,由于数据源之间存在结构、内容上的差异,因此在对获取到的知识进行整合时也会存在一词多义、指代不明的问题。需要进行知识融合处理,消除实体、属性在指代上的歧义,将多源异构数据进行规范上的统一;
实体对齐模型的设计以翻译模型TransH为基础,将实体的上下文描述信息添加到实体的嵌入表示中,对原模型进行改进;
TransH模型将实体嵌入到一个d维的向量空间中,将关系嵌入到一个关系超平面中,TransH的评分函数如下:
其中h表示头实体向量,t表示尾实体向量,r表示关系向量,W
一般嵌入和上下文语义嵌入相结合得到最终的实体嵌入,对于关系嵌入,本实施例中学习一个简单的关系嵌入,将简单关系嵌入与其头尾实体对的嵌入作为输入,计算出最终的包含实体对上下文特征信息的上下文关系嵌入;对于上下文关系嵌入的计算,设计了基于多层感知机(Multilayer Perceptron,MLP)的计算方法,整体由多个MLP堆叠而成,如图3所示;
各层的计算公式如下:
v
v
其中σ是激活函数,W为权重矩阵,b为偏置项。对于一个三元组(h,r,t),将头实体向量h
ψ(h
模型损失函数定义见公式(5)。其中[x]
模型使用Xavier进行参数初始化,使用随机梯度下降算法AdaGrad作为优化器;对于香薰机产品数据集,划分训练集和测试集比例为7:3,参数设置为γ
在步骤105中,对进行了知识抽取与知识融合之后的香薰机产品数据进行整理、合并,将数据导入到图数据库Neo4j中,形成可视化的工业设计领域产品知识图谱。
本发明实施例1提出的一种工业设计领域产品知识图谱构建方法,以香薰机产品为例证对象,首先构建出香薰机知识本体;然后,使用基于Bert的关系抽取-实体识别联合处理模型进行知识抽取,提取出非结构化数据中的实体、属性以及关系知识;还提出了一种以实体关系为嵌入中心的实体对齐模型,以解决多源异构数据源中实体一词多义、指代不明和跨语言等问题,完成知识融合,并最终构建出香薰机产品知识图谱。
实施例2
基于本发明实施例1提出的一种工业设计领域产品知识图谱构建方法,本发明实施例2还提出了一种工业设计领域产品知识图谱构建系统,如图3为本发明实施例2一种工业设计领域产品知识图谱构建系统示意图,该系统包括工业设计产品数据采集模块、知识抽取模块、知识融合模块和知识图谱整合存储模块;
工业设计产品数据采集模块用于采集工业设计产品的基本信息,利用爬虫框架从电商网站和设计网站等公开网络平台爬取产品信息,使用的爬虫框架主要为Scrapy,前端界面采用Vue.js、Element UI组件进行开发,爬取到的数据可存储进MySql数据库中;
知识抽取模块用于对采集到的产品数据进行关系抽取与实体识别,识别并提取出产品数据中的语义关系和实体,用于后续知识图谱的构,主要由基于Bert的关系抽取—实体识别联合处理模型构成;
知识融合模块用于识别出不同数据来源中指代为同一个对象的实体,去除重复的实体,以此优化知识图谱的存储空间和拓扑结构,为构建高质量的工业设计领域产品知识图谱提供保障,主要由实体对齐模型RelationTransH构成;
知识图谱整合存储模块用于将产品数据导入到图数据库中,在图数据库中构建出可视化的图谱。
本发明实施例2提出的一种工业设计领域产品知识图谱构建系统,拥有对数据的采集功能,再通过对工业设计产品数据进行抽取和融合等操作,获得高质量的产品知识,进而将数据导入到图数据库中,整合形成完整的工业设计领域产品知识图谱。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其它实施例的不同之处,各个实施例之间相同或相似部分互相参见即可。对于实施例公开的装置、设备及计算机可读存储介质而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的技术方案及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。