一种基于知识图谱规则嵌入的组合商品挖掘方法
文献发布时间:2023-06-19 10:32:14
技术领域
本发明涉及知识图谱规则领域,尤其是涉及一种基于知识图谱规则嵌入的组合商品挖掘方法。
背景技术
在知识图谱中,用三元组(head,relation,tail)来表示知识。我们可以用独热向量来表示这个知识。但实体和关系太多,维度太大。当两个实体或关系很近时,独热向量无法捕捉相似度。受Wrod2Vec模型的启发,学术界提出了很多用分布表示来表示实体和关系的方法(KGE),如TransE,TransH,TransR等等。这些模型的基本思想是通过对图结构的学习,可以用低维稠密向量来表示head、relation和tail。比如TransE,就是让head向量和relation向量的和尽可能靠近tail向量。在TransE中,一个三元组的得分为
对于正确的三元组(h,r,t)∈△,应该有较低的得分,而错误的三元组(h′,r′,t′)∈△′,应该有比较高的得分,最终的损失函数为:
知识图谱就只有正确的三元组(golden triplet),因此可以通过破坏一个正确三元组的头实体或者尾实体来生成负例,即将头实体,尾实体,关系三者之一随机替换成其他实体或关系,从而生成负例集合△′。通过不断优化该损失函数,最终可以学到h,r,t的表示。
在电商领域,同样的,也存在着商品知识图谱。在商品知识图谱中,头实体指的是商品,关系指的是的商品属性,尾实体指的是商品的属性值。因此可以通过KGE的方法学习得到商品,商品属性和商品属性值的embedding,然后将其运用在下游任务当中。
在电商领域,商家有时需要绑定销售几款商品,一方面,几款商品的总价一般会低于所有单品单卖的价格总和,这样让利给用户,用户会更有动力购买;另一方面卖家同时卖几个也比单卖一个赚取更多利润。因此,组合商品销售在实际应用中有很大的需求,这就需要有方法能够自动帮助卖家组合几个能够合在一起卖的商品。
但是,基于KGE的方法存在着的缺点是虽然能够预测两个商品是否属于组合品,但卖家并不知道基于何种原因,这两个商品被组合在一起,因此需要为此提供可解释性。基于此,亟需设计一种方法,使卖家可以直观的知道为什么两个商品可以组合在一起售卖。
发明内容
本发明提供了一种基于知识图谱规则嵌入的组合商品挖掘方法,通过将组合商品规则表示成embedding,然后将学习得到的规则embedding解析成具体的规则,从而能够帮助商家构建可以合在一起售卖的组合商品。
一种基于知识图谱规则嵌入的组合商品挖掘方法,包括:
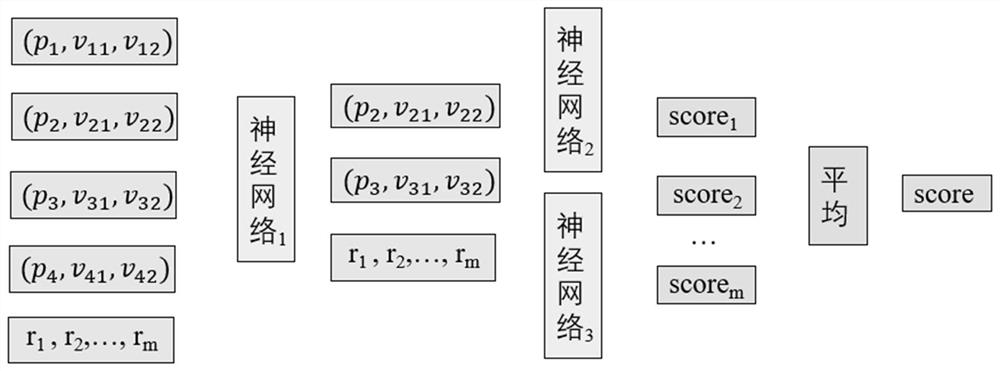
(1)构建商品的知识图谱,对于知识图谱中的每个三元组数据,头实体为商品I,关系为商品属性P,尾实体为商品属性值V;
(2)将商品I、商品属性P、商品属性值V分别表示成embedding,并随机初始化若干个规则的embedding;
(3)将规则的embedding和商品属性的embedding拼接输入到第一个神经网络中,得到商品属性的重要性分数s
(4)将规则的embedding和商品属性的embedding拼接输入到第二个神经网络中,得到该规则在该属性下应该取得的属性值的embedding:V
(5)将规则的embedding和商品属性的embedding拼接输入到第三个神经网络中,计算某条规则在某个属性下的属性值相同的概率分数p;
(6)若两个商品在某个属性下的属性值不同,计算V
其中,V
(7)当某个属性的重要性分数s
(8)汇总一个商品对的m个属性-属性值对的得分score
(9)汇总n条规则下一个商品对的得分score
(10)将得到的一个商品对的score与两个是否属于组合品的标签0或者1比较得到交叉熵损失;基于梯度下降的优化算法迭代求解直至损失值收敛,三个神经网络的参数训练完毕,同时得到学习完规则的embedding;
(11)对于学习完规则的embedding,利用上述训练完毕的神经网络进行解析,得到商品组合的规则。
步骤(1)中,商品知识图谱中每个三元组的的构成为(I,P,V),表示商品I在属性P下面的属性值为V。不同的商品通过相同的属性或者属性值关联在一起,从而构成了图的结构。
步骤(2)中,将商品I、商品属性P、商品属性值V以及若干个规则都分别编号成一个id,然后每个id再构成一个onehot向量,之后将这个onehot向量映射成一个embedding,该embeding会随着模型训练过程不断优化。
步骤(3)~(5)中,三个神经网络中,每层神经元的激活函数的计算公式为:
RELU(x)=max(0,x)
RELU函数会依次判断这个矩阵中每个元素的值,如果该元素的值大于0,那么就保留该值,否则就将该值设为0。
三个神经网络中,每个神经网络各个层的计算公式为:
l
l
l
…
l
其中,W
步骤(6)中,相似度分数s
步骤(10)中,交叉熵损失函数为:
其中,prob(i)和y(i)都是概率分布函数,0≤i<K且i为整数,y(i)∈{0,1}是真实的概率分布,0≤prob(i)≤1是模型预测出来的概率分布,∑
优选地,梯度下降的优化算法为SGD或Adam。
步骤(11)的具体过程为:
对于学习到的规则embeding和每个商品对,将规则embeding和商品对每个属性的embedding拼接输入到第一个网络中得到每个属性的重要性分数;
若该属性的得分s
若该属性包含在该规则下,且两个商品在该属性下的属性值相同,则计算在该属性下取“相同”的概率p,若p大于阈值thres
若该属性包含在该规则下,且两个商品在该属性下的属性值不相同,那么计算相似度分数s
与现有技术相比,本发明具有以下有益效果:
本发明将规则的学习融入到模型的训练过程中,最终将学习到的规则embeding,解析成一条条规则,基于规则,卖家就可以知道为什么两个商品可以组合在一起售卖,这样可以为电商销售商品带来非常大的收益。
附图说明
图1为本发明基于知识图谱规则嵌入的组合商品挖掘方法的流程示意图。
具体实施方式
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
如图1所示,一种基于知识图谱规则嵌入的组合商品挖掘方法,包括以下步骤:
S01,构建商品知识图谱,对于每个三元组,头实体为商品,关系为商品属性,尾实体为商品属性值。组合商品的任务定义为:给定商品知识图谱中的两个商品,以及每个商品各自的若干个属性和属性值,需要判断两个商品是否为组合商品。本发明的创新之处在于将规则学习融入到模型训练过程中,从而能够通过学习得到的规则,为卖家提供可解释性。
S02,将商品、商品属性、商品属性值,以及规则先表示成id,然后每个id索引到一个embedding。对于每条样本而言,输入的两个商品会有n个属性和属性值,加上输入的n条规则,本发明基于此预测两个商品是否为组合品。
S03,首先是计算每个属性的得分。我们首先将规则的embedding和商品属性的embedding拼接输入到第一个神经网络中,得到属性重要性分数s
l
l
l
…
s
具体的,通过将规则的embedding和商品属性的embedding拼接不断送入全连接层中,从而得到越来越高阶的语义,最终基于高阶语义可以预测出来该属性在该规则下的重要性分数s
S04,之后是计算属性值的得分。将规则的embedding和商品属性的embedding拼接输入到第二个神经网络中,可以得到预测出来的属性值embeding。第二个神经网络的各个层公式为:
l
l
l
…
V
具体的,可以通过将规则和属性送入到多层神经网络中,最后得到预测出来,在该属性下应该取的属性值的embedding。接下来分两种情况,若输入的两个商品该属性下的属性值是相同的,那么可以计算这个属性值和预测出来的属性值的相似程度,相似程度越高意味着这个属性值的得分越高。所述的计算属性值相似程度的方法如下:
同时,存在一种可能,在该规则下,该属性下的取值是“相同”即可以。此时我们可以将规则的embedding和商品属性的embedding拼接输入到第三个神经网络,从而得到,在该属性下的取值是“相同”的概率,第三个神经网的公式为:
l
l
l
…
p=sigmoid(W
如果输入的两个商品该属性下的属性值是不同的,那么,就可分别计算这两个属性值和预测出来的属性值的相似性程度,然后综合两个相似度分数最终得到这两个属性值的得分。所述的属性值相似程度的计算方法如下:
s
S05,紧接着,我们可以求解一个属性属性值对的分数。可以分成三种情况:该属性的得分s
s
若该属性的得分s
0.5*p*(s
S06,得到一个属性属性对的得分之后,可以计算得到一个商品对在某一条规则下的分数,所述的计算公式为:
S07,得到一个商品对在某一条规则下的分数之后,可以该汇总该商品对在所有规则下的得分,从而得到该商品对最终的得分,所述的计算公式为:
S08,将得到的一个商品对的score与两个是否属于组合品的标签0或者1比较得到交叉熵损失:
H(p,q)=-∑
然后用Adam优化器优化该损失函数。
S09,当规则学习完之后需要解析规则,解析规则的方式同训练时候大同小异。首先需要把该规则embeding与每个可能的属性的embedding拼接输入到第一个网络中得到每个属性的重要性分数,若该属性的得分s
通过上述这种方式,可以得到组合商品规则。最终在具体应用时,主要有两种方式:
第一种方式为:
给定一个商品对,以及每个商品各自的属性属性值,将这些信息输入到模型中,可以得到这个商品对中两个商品可以组成组合商品的概率score,若score大于0.5,则认为这两个商品属于组合商品。
第二种方式为:
给定一个商品对,以及每个商品各自的属性属性值。对于本发明生成的所有规则,逐一检查,每个属性属性值对是否符合当前的规则,所有属性属性值对都符合当前规则,那么基于当前规则,可以判定两个商品属性组合商品。若所有规则均不能判断这两个商品属于组合商品,则这两个商品不构成组合商品。
接下来,以一个具体的实例来说明本发明的构建过程。
首先,如表1所示是模型输入的一个样本,它包含两个商品,每个商品包含着若干个属性和属性值,在每个属性下,两个商品的属性值可能相同也可能不相同。
表1
首先将这两个商品的所有属性和属性值都表示成embedding。然后将每个属性先经过第一个神经网络可以得到该属性的重要性得分;之后属性值输入到第二个神经网络可以得到属性值的得分。之后汇总属性和属性值的分数可以得到该属性-属性值对的得分。然后,汇总所有属性-属性值对的得分得到这两个商品在该规则下属于同款商品的得分。最后,汇总所有规则对这两个商品的打分,最终得到这两个商品属于同款商品的得分。
在测试阶段,需要解析规则。如表2所示,是一条模型基于表1所示的样本解析出来的规则。
表2
解析规则的方式同训练过程是类似的,也是先确定该规则包含哪些属性,然后,再确定每个属性下应该包含哪个属性值,最后就可以解析出来规则了。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。