一种轻量级活体检测方法
文献发布时间:2023-06-19 09:24:30
技术领域
本发明属于计算机视觉领域,具体来说,涉及一种基于机器学习技术的人脸活体检测方法。
背景技术
活体检测是在一些身份验证场景确定对象真实生理特征的方法,在人脸识别应用中,一般先进行活体检测确保用户为真实活体本人,因此需要能有效抵御打印照片、面具、遮挡以及屏幕翻拍等常见的攻击手段,然后再决定是否进行后续的验证工作。常见的交互式活体,需要用户能通过眨眼、张嘴、摇头、点头等组合动作来配合算法,用户体验性不好。静默活体检测则全程无需任何指令动作配合,用户只需对准摄像头即可完成检测。
近些年来,随着人工智能的不断发展,活体检测技术开始越来越多地应用到工业生产、社会安防和生活消费等各个方面,如刷脸支付、远程身份验证、刷脸闸机通行。与传统的“个人主机+固定摄像头”框架相比,嵌入式平台或者移动端的计算性能较弱,存储空间限制,因此除了对模型的识别准确性有要求,还对模型所占内存空间以及运行速度有较高要求。另外虽然多模态数据对于活体检测有更好的帮助,比如结合红外、深度数据,但这需要配套有相应的红外和深度相机,提高了成本。因此有必要研究和提出更加轻量级,且仅依靠RGB数据的活体检测方法。
发明内容
本发明旨在提供一种高精度、高安全性、高效的基于RGB的活体检测方法,该方法可以方便部署在嵌入式或者移动端平台,且不需要额外的红外、深度相机,仅依靠RGB图像数据,即可实现高精度的活体检测。
为实现上述技术目的,本发明采用的技术方案如下:
一种人脸活体检测方法,包括如下步骤:
实时采集视频图像,生成视频序列图像;
对视频序列图像进行人脸检测,获取人脸区域的位置信息;
根据人脸区域的位置信息在视频序列图像中截取矩形人脸区域A,然后在矩形人脸区域A上进行关键点标注;
扣除矩形人脸区域A周围的背景区域,得到新的矩形人脸区域B;
将处理后的矩形区域B缩放到统一尺寸,然后将缩放后的图片的RGB颜色空间转换为HSV颜色空间,并将HSV颜色空间并入到RGB颜色通道形成6通道图像,再进行归一化处理;
对归一化处理后的图像进行特征提取,从而提取出高维特征;
将提取出的高维特征通过度量学习进行分类,从而识别活体。
进一步限定,所述去除矩形人脸区域A周围的背景区域,得到新的矩形人脸区域B具体包括:
构造一个H×W的全零二维数组mask,其中,H、W分别是矩形人脸区域A的长度和宽度,将人脸的轮廓和眉毛处的关键点顺序进行调整,使得关键点坐标在数组mask上按逆时针顺序构成一个闭环,将数组mask上的关键点和闭环内区域的元素设置为1,然后将数组mask与矩形人脸区域A的对应坐标分别相乘得到新的矩形区域B。
进一步限定,所述对归一化处理后的图像进行特征提取,从而提取出高维特征具体包括:
通过深度可分离结构、逆残差结构和线性瓶颈层的轻量级网络结构进行训练,从而提取出高位特征。
进一步限定,所述将提取出的高维特征通过度量学习进行分类为:
定义提取特征的过程:
其中,
在训练过程中,对于
其中,
采用Triplet Loss损失函数来区分出活体和攻击样本:
其中,
Triplet Loss损失函数保证任意两个活体样本之间的特征距离都要尽可能大于其中一个活体样本和任意一个攻击样本之间的特征距离。
本发明相比现有技术,具有如下特点:
1、基于单摄像头完成采集工作,对高清视频翻录、打印照片、面具等攻击情况有很好的适应能力。
2、精度高,拒绝率>99%(代表在N次假体攻击时,会有超过99%的请求被拒绝),误拒率<1%(代表在N次真人活体请求时,仅有低于1%的请求会因为活体分数低于阈值而被拒绝)。
3、速度快,单张图片推理时间小于10毫秒,而人脸检测+关键点标注+预处理+活体检测全流程耗时小于60毫秒。
4、模型占用内存小,模型大小可控制在8MB左右。
附图说明
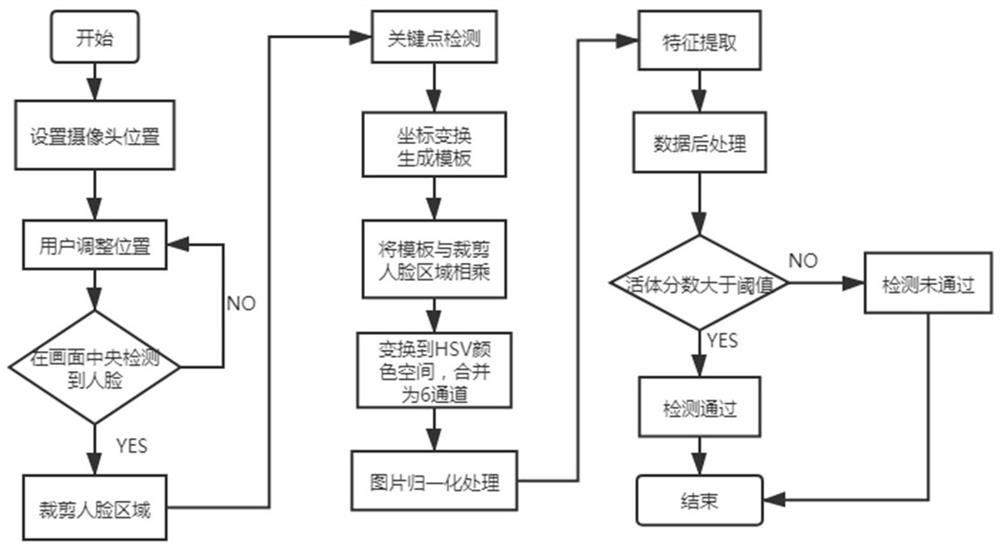
图1为本发明人脸活体检测方法的流程图;
图2为人脸检测、关键点标注的流程图;
图3为将RGB颜色空间生成6通道图像用于训练网络的流程图;
图4为高维特征降维后的特征图。
具体实施方式
为了便于本领域技术人员的理解,下面结合实施例与附图对本发明作进一步的说明,实施方式提及的内容并非对本发明的限定。
如图1所示,一种人脸活体检测方法,包括如下步骤:
S10:通过摄像头实时采集视频图像,生成视频序列图像以待处理。
具体地,摄像头在采集用户人像时,需要确保用户是正对摄像头,同时要求周围有较为均匀的光照,避免人脸区域有过多范围的阴影,同时要求用户根据画面引导,调整距离摄像头距离,使得人脸位于画面指定区域,这些都是为了过滤掉因外界条件导致采集的低质量人脸,可以更好的起到安全保护的作用。
S20:对视频序列图像进行人脸检测,获取人脸区域的位置信息。
S30:根据人脸区域的位置信息在视频序列图像中截取出矩形人脸区域A,然后在矩形人脸区域A上进行关键点标注。
人脸检测和面部关键点标注是实现活体检测的前提和基础。当前人脸检测技术日趋成熟,OpenCV、dlib等机器视觉库都提供了高效的人脸检测算法,同时也提供了高效的人脸面部关键点标注算法;iOS和Android移动平台自身也集成了人脸检测和面部关键点标注算法。
本申请在步骤S20和S30实施过程中采用了dilb机器视觉库中的算法,具体地,人脸检测采用了人脸检测模块来对每张图片上的人脸进行定位,获得人脸区域的位置信息。
人脸检测(Face Detector)是检测出图片中包含的正面人脸,在dilb机器视觉库中有如下人脸检测模块,比如基于HOG(Histogram of Oriented Gradients) 特征结合线性分类器、图像金字塔(image pyramid)及滑窗检测机制(sliding window detectionscheme)实现的人脸检测器,基于预训练的CNN 模型的人脸检测器。
基于CNN 模型比基于 HOG 特征模型的人脸检测准确度更高。但是需要更多的计算资源,即在GPU上运行才可有较好的运行速率。
关键点标注则采用了人脸关键点检测模块,通过该模块能够在矩形人脸区域A上估计人脸的关键点姿态(pose),分别是人脸各部位的点,如嘴角(corners of the mouth),眼睛边(corners of the mouth)等,共68对关键点。
S40:构造一个H×W的全零二维数组mask,其中,H、W分别是矩形人脸区域A的长度和宽度,将人脸的轮廓和眉毛处的27对关键点顺序进行调整,使得关键点坐标在数组mask上按逆时针顺序构成一个闭环,对于数组mask上的27对关键点和闭环内区域的元素,将填充值设置为1,然后将数组mask与矩形人脸区域A的对应坐标分别相乘得到新的矩形区域B,通过上述手段,矩形区域B能够去除人脸周围的细微背景区域。
S50:人脸预处理
如图2所示,将步骤S40中处理后的矩形区域B缩放到统一尺寸,再将缩放后的图片的RGB颜色空间转换为HSV颜色空间,并将HSV颜色空间并入到RGB颜色通道形成6通道图像,再进行归一化处理。
上述转换可以提取某些在RGB颜色空间不够显示的特征,能够明显提高最终的识别精度。
6通道图像作为步骤S60特征提取的输入,用于训练。为了适应实际场景下各种可能的非活体攻击方式,如手机高清视频翻录、打印照片、面具等情况,同时收集了不同光照、不同分辨率下的非活体样本,另外针对存在明显反光、模糊、人脸偏转角度过大的活体样本,在训练时将其视为非活体样本进行训练,这样做可以更好的提供安全。
S60:对归一化处理后的6通道图像进行特征提取,从而提取出1280维的高维特征。
S70:针对步骤S60中的高维特征,基于度量学习的思想,将高维特征进行分类,从而识别活体。
在步骤S60中,特征提取采用设计新颖的轻量级网络结构,其结合了深度可分离结构、逆残差结构和线性瓶颈层,通过深度可分离结构减少了参数量,提高了训练和推理速度,通过逆残差结构和线性瓶颈层则减少了训练过程中的信息丢失,缓解了特征退化情况,提高了特征提取能力。
度量学习具体步骤为:
首先定义提取特征的过程:
(1)式中,
在训练过程中,对于
(2)式中,
同时为了使活体样本和攻击样本在特征空间中具有更好的区分性,我们采用损失函数Triplet Loss来辅助目标函数(2)式,使得学习到的特征能明显区分出活体和攻击样本。其中损失函数为:
(3)式中,
具体地,
Triplet Loss损失函数保证任意两个活体样本之间的特征距离都要尽可能大于其中一个活体样本和任意一个攻击样本之间的特征距离。
如图4所示,本申请通过对于高维特征进行PCA(主成分分析)降维操作,将1280维的高维特征降到2维,从而明显区分出活体样本和攻击样本的特征。
本发明通过正对用户的单目摄像头采集用户的照片,而后运用深度学习技术从图片中检测到人脸区域,再通过本发明提供的方案判别照片中的人脸是否为真实活体。该方法充分考虑了应用场景中可能存在的面具、手机视频翻录、手机照片、打印高清照片等情况,实现了一种高性能的RGB活体检测方法。
- 一种轻量级活体检测方法
- 一种具有活体检测功能的穿戴设备及其活体检测方法