一种XML文档的数字化方法和系统
文献发布时间:2023-06-19 09:52:39
技术领域
本发明涉及XML文档数字化处理技术领域,具体而言涉及一种XML文档的数字化方法和系统。
背景技术
随着网络的迅速发展,互联网上产生了大量以XML形式存储的半结构化数据,这些在不同领域积累下来的数据宝藏,具有无限潜能,孕育着巨大的价值。XML文档作为半结构数据的代表,由于其平台无关性、便捷的数据处理和灵活的Web应用等特征为越来越多的企事业单位所使用。因此,面对庞大的XML数据,其文档的数字化表示是进行数据分析、归类及各种数据处理的基础,其好坏直接影响着后续的各种操作。例如专利号为CN108984713A的发明中公开了一种XML文件处理方法及装置,通过将XML文件依据结构树进行拆分保存至若干个数据库表中,可以解决单张表过大,造成查询或者其他操作的耗时较长的问题。
但是,随着互联网上以指数级速度逐年增长的XML文档的出现,为半结构化数据的分类处理带来了负担。因此,面对海量XML文档,寻找一种快捷高效的XML文档的数字化方法,方便后续对XML信息的处理已经成为一种必然趋势。XML文档的数字化表示能极大地提高XML文档的分类速度,能够为XML文档的进一步应用处理带来了保障。但是在目前的XML文档数字化方法中,存在以下问题:第一,数字化结果简单粗糙,不能准确地反映出XML文档信息,第二,表示方法复杂,转化效率低下,第三,重视XML结构特征,而忽略了其语义特征。
发明内容
本发明针对现有技术中的不足,提供一种XML文档的数字化方法和系统,通过提取主干结构树、统一结构树型和元组串转换三个步骤,结合XML文档的结构特征和语义特征,实现了对XML文档的数字化处理,处理过程高效快捷,数字化结果具有相似度检测灵敏性高等特点,可以在复杂网络环境下对海量XML文档进行数字化表示,不仅简化了XML文档本身,而且方便后续的文档分类及应用处理。
为实现上述目的,本发明采用以下技术方案:
一种XML文档的数字化方法,适于XML文档之间相似度比较,所述数字化方法包括以下步骤:
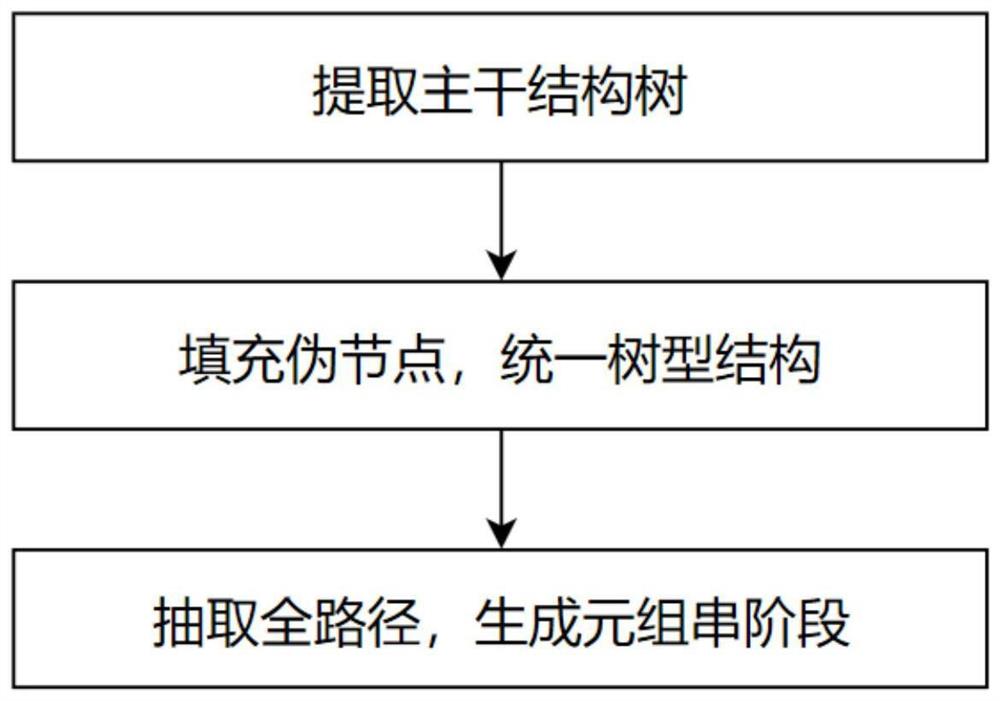
S1,提取主干结构树:
对导入的XML文档进行预处理,找出主干结构树,去除冗余的节点,实现在主干结构树中,相同的路径出现且仅出现一次;
S2,填充伪节点,统一树型结构:
对预处理阶段提取出来的XML文档的主干结构树进行伪节点填充,使用于分类的多个XML文档对应的多个主干结构树具有相同的层数和树深,同时树中同一层的每个节点孩子个数相同;
S3,抽取全路径,生成元组串阶段:
针对填充了伪节点的主干结构树,分别抽取每个XML文档包含的所有不同的全路径,从根节点到叶子节点,依次按元素名称组合成不同的元组串,使每个XML文档对应一组元组串集合,完成XML文档的结构转化。
为优化上述技术方案,采取的具体措施还包括:
进一步地,所述数字化方法还包括以下步骤:
S4,数字化结果的应用验证:
采用下述公式对任意两个XML文档间的相似度进行比较:
式中:P(T
进一步地,步骤S3中,所述元组串中每部分的节点名称,用于反映所属XML文档对应部分的语义。
进一步地,步骤S2中,所述对预处理阶段提取出来的XML文档的主干结构树进行伪节点填充的过程包括以下步骤:
寻找主干结构树的每一层中节点的最大孩子数,把这个最大孩子数作为本层所有节点的孩子数,对孩子数不足的节点进行填充补全。
进一步地,步骤S3中,所述分别抽取每个XML文档包含的所有不同的全路径的过程包括以下步骤:
采用从上到下、从左往右的顺序从根节点到叶子节点,遍历所有主干结构路径,形成全路径集合。
进一步地,步骤S3中,所述元组串集合是指按照全路径的轨迹,所有从根到叶节点的节点名称连接集合,每个元组串中的每部分用逗号进行间隔;在一个元组串集合中,相同的元组串只保留一个。
基于前述数字化方法,本发明还提及一种XML文档的数字化系统,所述数字化系统包括:
(1)用于提取主干结构树的模块:
对导入的XML文档进行预处理,找出主干结构树,去除冗余的节点,实现在主干结构树中,相同的路径出现且仅出现一次;
(2)用于填充伪节点,统一树型结构的模块:
对预处理阶段提取出来的XML文档的主干结构树进行伪节点填充,使用于分类的多个XML文档对应的多个主干结构树具有相同的层数和树深,同时树中同一层的每个节点孩子个数相同。
(3)用于抽取全路径,生成元组串阶段的模块:
针对填充了伪节点的主干结构树,分别抽取每个XML文档包含的所有不同的全路径,从根节点到叶子节点,依次按元素名称组合成不同的元组串,使每个XML文档对应一组元组串集合,完成XML文档的结构转化。
本发明的有益效果是:
同时结合XML文档的结构特征和语义特征,以结构特征为主,语义特征为辅,实现了对XML文档的数字化处理,处理过程高效快捷,数字化结果具有相似度检测灵敏性高等特点,可以在复杂网络环境下对海量XML文档进行精准的数字化表示,不仅简化了XML文档本身,而且方便后续的文档分类及应用处理。
附图说明
图1是本发明的XML文档的数字化方法的流程图。
图2是本发明的其中一个XML文档实例示意图。
图3是图2对应的主干结构树及添加了伪节点的主干结构树示意图。
图4是图3对应的主干结构树的全路径抽取及其对应的元组串集合示意图。
图5是两个XML文档相似度比较的运行流程图。
具体实施方式
现在结合附图对本发明作进一步详细的说明。
需要注意的是,发明中所引用的如“上”、“下”、“左”、“右”、“前”、“后”等的用语,亦仅为便于叙述的明了,而非用以限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容下,当亦视为本发明可实施的范畴。
结合图1,本发明提及一种XML文档的数字化方法,适于XML文档之间相似度比较,所述数字化方法包括以下步骤:
S1,提取主干结构树:
对导入的XML文档进行预处理,找出主干结构树,去除冗余的节点,实现在主干结构树中,相同的路径出现且仅出现一次。
S2,填充伪节点,统一树型结构:
对预处理阶段提取出来的XML文档的主干结构树进行伪节点填充,使用于分类的多个XML文档对应的多个主干结构树具有相同的层数和树深,同时树中同一层的每个节点孩子个数相同。
S3,抽取全路径,生成元组串阶段:
针对填充了伪节点的主干结构树,分别抽取每个XML文档包含的所有不同的全路径,从根节点到叶子节点,依次按元素名称组合成不同的元组串,使每个XML文档对应一组元组串集合,完成XML文档的结构转化。
优选的,步骤S3中,所述元组串中每部分的节点名称,用于反映所属XML文档对应部分的语义。本发明的XML文档数字化表示尤其适用于XML文档的相似度检测,便于文档分类。在前述分类场景下,处理过程会更加重视XML文档结构,而减少对其内容的关注。例如,对于采用XML格式存储医疗数据的文档,其结构反映出这是一种存储医疗数据的XML文档,而叶子结点的内容反映的是患者的具体信息,在XML文档分类过程中,人们更关心的是结构,也就是说文档存储的是哪类信息,而忽略其具体内容,所以结构是此类问题的核心,此时节点名称只需简单反映该节点部分的内容含义或类型即可。但在其他场景下,如果在关注结构的同时也对内容进行关注,则需要对节点名称进行更加复杂的区分处理,例如结合语义内容对节点做进一步的细分等。
图2为一个XML文档实例,圆形节点是XML文档的结构节点,反映XML文档存储的框架信息,而矩形框里存储的是叶子节点的内容信息。对于XML文档而言,不同的场景下,需要了解不同的信息,区分不同的焦点。如果用户想了解文档存储的框架信息,那么只需了解和掌握反映结构的圆形节点即可,即了解结构节点之间反映的位置关系和反映其语义的节点名称;如果用户想了解XML文档中存储的具体内容,那么需要结合XML文档结构,来取得存储叶子节点的内容,叶子节点的内容是信息存储的核心点。为了便于说明,本发明仅对分类处理应用下的XML文档的数字化过程进行阐述,在此前提下,我们更关注文档的结构,即所有的圆形节点,即结构节点。
由于XML这种半结构化文档,含有大量的冗余结构信息,文档间语义相似,结构类似,因此需要先去除XML文档的冗余信息,提取主干结构树,从而简化XML文档的结构。图3(a)为图2中XML文档对应的主干结构树。抽取主干结构树,是去除了XML文档中存在的大量冗余结构节点及全部叶子节点内容,确保相同路径只在主干结构树中出现且仅出现一次。
为了实现XML文档的分类,需要对提取的主干结构树添加伪节点,添加伪节点的目的是为了解决参与分类的多个XML主干结构树中节点个数不同的问题,实现结构的标准化,使多个XML文档具备统一的结构框架,统一和标准化结构框架,才能进一步进行相似度比较,此集合和文档一一对应,进而实现了XML文档的数字化转换。添加伪节点的方法包括:寻找主干结构树的每一层中节点的最大孩子数,把这个最大孩子数作为本层所有节点的孩子数,不足的填充补全。图3(b)为图3(a)添加了伪节点的扩充主干结构树。
图4是针对图3(b)进行的全路径抽取及其对应的元组串集合。在本发明中,全路径和元组串集合的含义如下:
全路径:在XML主干结构树中,树的全路径被定义为从根到全部叶子节点的所有路径集合。节点v
元组串集合:按照全路径的轨迹,连接所有从根到叶节点的节点名称,元组中每部分用逗号进行间隔。在元组串集合中,对于相同的重复元组串,在集合中只保留一个。
图4(a)是图3对应的全路径,图4(b)为图3对应的元组串,如此实现了对XML文档的数字化表示,一个复杂庞大的XML文档,目前就可以用一组元组集合来代替。对XML文档结构的后续研究,可以从元组串入手,它能代表XML文档进行各种分类处理。集合代表全路径的信息,即结构信息,而元组串中每部分的节点名称,反映了XML文档的语义,这种表示方法即反映了文档结构,又代表一定的语义。例如可以直接采用下述公式对任意两个XML文档间的相似度进行比较:
式中:P(T
基于前述数字化方法,本发明还提及一种XML文档的数字化系统,所述数字化系统包括:
(1)用于提取主干结构树的模块:
对导入的XML文档进行预处理,找出主干结构树,去除冗余的节点,实现在主干结构树中,相同的路径出现且仅出现一次;
(2)用于填充伪节点,统一树型结构的模块:
对预处理阶段提取出来的XML文档的主干结构树进行伪节点填充,使用于分类的多个XML文档对应的多个主干结构树具有相同的层数和树深,同时树中同一层的每个节点孩子个数相同;
(3)用于抽取全路径,生成元组串阶段的模块:
针对填充了伪节点的主干结构树,分别抽取每个XML文档包含的所有不同的全路径,从根节点到叶子节点,依次按元素名称组合成不同的元组串,使每个XML文档对应一组元组串集合,完成XML文档的结构转化。
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
- 一种XML文档的数字化方法和系统
- 一种XML文档解析方法、系统及电子设备和存储介质