基于国产化多NUMA节点CPU结温均衡策略的任务调度方法
文献发布时间:2023-06-19 11:35:49
技术领域
本发明属于操作系统任务调度技术领域,具体涉及一种基于国产化多NUMA节点CPU结温均衡策略的任务调度方法。
背景技术
随着信息产业的蓬勃发展,数据的产生以近乎几何级数的速度高速增长,对计算能力提出了巨大需求。但受限于半导体摩尔定律,单CPU核心的主频和计算能力不会有跨越式提升。近年来,在服务器等计算密集型领域,CPU经历了单核、多核到多NUMA节点的发展历程。目前,高性能计算服务器具有数十个NUMA节点,数百个计算核心。
在航空航天、国防军工等领域,计算设备的稳定运行和数据安全关系着重大国家利益、社会稳定。因此,在这些关系着国计民生的领域中,计算设备中CPU等核心硬件有明确的国产化自主可控需求。近年来,国产化CPU研发技术有了迅猛发展,计算性能比肩世界先进水平。但另一方面,国产化CPU,受限于制程工艺等原因,功耗高,发热量大。目前应用的一块集成8个NUMA节点64核心的国产化CPU,芯片面积达到3600mm
由于NUMA节点对临近内存访问效率高,操作系统默认对NUMA节点的任务调度表现出亲和性的特点。若某个任务task在t周期在0号NUMA节点上运行,那么在t+1,t+2,t+3周期,操作系统都优先将task在0号NUMA节点上运行。在国产化CPU平台上,这种默认的任务调度方式,会导致0号NUMA节点结温远超过其他节点,当长时间超过CPU最大工作结温时,CPU运行可靠性大大降低。
发明内容
(一)要解决的技术问题
本发明要解决的技术问题是:国产化多NUMA节点CPU发热量大,不同NUMA节点间结温差异大,无法长时间运行高负载任务的问题。
(二)技术方案
为了解决上述技术问题,本发明提供了一种基于国产化多NUMA节点CPU结温均衡策略的任务调度方法,包括以下步骤:
步骤1、确定NUMA节点体质系数;
步骤2、根据CPU芯片手册中规定的最高工作结温,确定任务调度方法启动结温阈值T
步骤3、轮询检测N个NUMA节点结温,当结温超过结温阈值,启动任务调度;
步骤4、计算NUMA结温差值数;
步骤5、基于步骤4计算NUMA节点迁移值;
步骤6、若N-1个迁移值均小于0,将负载任务挂起指定时间;
步骤7、将负载任务调度至迁移值最大的NUMA继续运行。
优选地,步骤1中,首先确定HPL测试矩阵规模,使用MPI工具控制HPL多进程并行运行,用numactl工具将HPL分别绑定HPL在N个NUMA节点运行,记录下每个NUMA节点的测试结温,第i个NUMA节点测试结温表示为M
优选地,检测时间间隔Time
优选地,步骤4中,第i个NUMA节点的结温值记为T
优选地,步骤5中,第i个NUMA节点负载应用向第j个NUMA节点的迁移系数记为V
优选地,步骤6中,当全部NUMA节点结温均超过上限阈值时,任务调度方法已无法通过均衡方式保障CPU稳定运行,将全部负载任务挂起指定时间Time
优选地,步骤6中,Time
优选地,HPL是计算机性能测试工具,通过对线性代数方程组进行测试,评估计算机系统的性能。
优选地,numactl是在NUMA架构计算机系统中,用于控制任务在指定NUMA节点运行的工具。
优选地,MPI用于控制任务多核心并行运行。
(三)有益效果
本发明提出一种基于国产化多NUMA节点CPU结温均衡策略的任务调度方法,当NUMA接电脑结温超过阈值时,将高负载计算任务调度至结温较低的核心,保证CPU的稳定运行。该任务调度方法能有效降低CPU最高工作结温,且对计算负载任务性能损失小,避免CPU长时间超结温阈值工作,提升CPU工作的稳定性。
附图说明
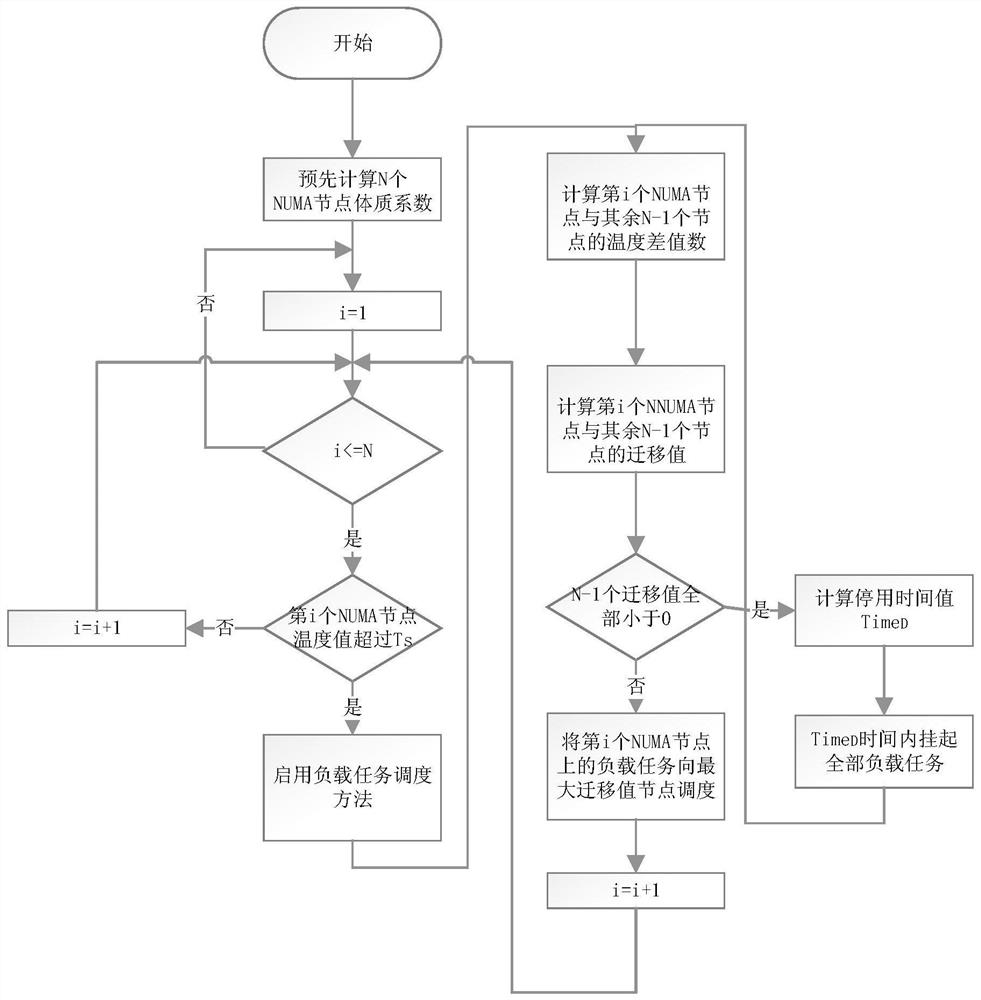
图1为本发明的任务调度方法流程图。
具体实施方式
为使本发明的目的、内容、和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
本发明提出一种基于国产化多NUMA节点CPU结温均衡策略的任务调度方法,首先,确定N个NUMA节点体质系数、最高结温阈值、检测间隔时间等参数。第一步,按照检测间隔时间轮询N个NUMA节点结温,当结温超过最高结温阈值,启动任务调度。第二步,计算N-1个NUMA节点间结温差值数,计算迁移值。第三步,若N-1个迁移值均小于0,将负载任务挂起指定时间。第四步,将负载任务调度至迁移值最大的NUMA继续运行。最后,用发明方法,与默认操作系统默认任务调度方法对比,以结果数据证明本发明方法的有效性。
具体地,如图1所示,本发明的方法包括以下步骤:
步骤1、确定NUMA节点体质系数。由于芯片制程工艺的限制,CPU各NUMA节点的体质会有差异,运行同样负载计算量的最大结温不同。首先确定HPL测试矩阵规模,使用MPI工具控制HPL多进程并行运行,用numactl工具将HPL分别绑定HPL在N个NUMA节点运行,记录下每个NUMA节点的测试结温,第i个NUMA节点测试结温表示为M
其中,HPL:是计算机性能测试工具,通过对线性代数方程组进行测试,评估计算机系统的性能,对CPU有很大负载压力,可调整计算矩阵规模,控制测试计算量;numactl是在NUMA架构计算机系统中,用于控制任务在指定NUMA节点运行的工具;MPI:用于控制任务多核心并行运行。
步骤2、根据CPU芯片手册中规定的最高工作结温,确定任务调度方法启动结温阈值T
步骤3、轮询检测N个NUMA节点结温,当结温超过结温阈值,启动任务调度;
步骤4、计算NUMA结温差值数。第i个NUMA节点的结温值记为T
步骤5、基于步骤4计算NUMA节点迁移值。第i个NUMA节点负载应用向第j个NUMA节点的迁移系数记为V
步骤6、若N-1个迁移值均小于0,将负载任务挂起指定时间。由于国产化CPU不具备动态降低频率功能,因此当全部NUMA节点结温均超过上限阈值时,任务调度方法已无法通过均衡方式保障CPU稳定运行,将全部负载任务挂起指定时间Time
步骤7、将负载任务调度至迁移值最大的NUMA继续运行。
下面给出本发明方法测试结果:
测试机器使用的国产化CPU共有8个NUMA节点,每个节点16个计算核心。CPU芯片手册中规定最高工作结温90度。HPL测试矩阵规模为80000,MPI工具控制HPL任务64进程运行,HPL任务共使用4个NUMA节点。
测试方式1:使用操作系统默认任务调度方法,测试过程中CPU最高结温108度,测试时间共7349秒,通过对CPU使用率的统计,HPL任务超过95%的时间运行在NUMA 0-3节点,测试分数179.5GFlops。
测试方式2:启用本发明方法,检测间隔时间Time
对测试结果数据进行分析,运行同样计算量负载任务,采用本发明方法对比操作系统默认任务调度方法,CPU最高工作结温下降15度,任务运行时间增加了3.6%,测试分数下降了2.6%。
以上测试结果表明,负载任务调度方法能有效降低CPU最高工作结温,且对计算负载任务性能损失小,避免CPU长时间超结温阈值工作,提升CPU工作的稳定性。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 基于国产化多NUMA节点CPU结温均衡策略的任务调度方法
- 基于转码任务调度实现CPU负载均衡的方法和装置