基于预训练语言模型和编码器的消息意图识别方法及系统
文献发布时间:2023-06-19 12:13:22
技术领域
本发明涉及电商技术领域,具体而言,涉及一种基于预训练语言模型和编码器的消息意图识别方法及系统。
背景技术
在对话机器人中,意图识别模型最核心的部分是消息编码器,一般有两类实现方式:基于LSTM、CNN、transformer等神经网络和大量领域数据构建的轻量编码器(参数量少),基于BERT、Roberta、XLNet等预训练语言模型和少量领域数据构建的精调编码器(参数量很多)。虽然预训练语言模型的出现,使得利用少量领域数据对模型做精调便可达到较高意图识别精度成为可能,但是:1)这类模型训练需要更新大量模型参数,导致语言模型的实时更新部署难度过高;2)对语言模型精调时其分词器(基于开放领域文本训练)与领域数据分布并不相符,因此输入处理可能会影响语言模型的性能,导致其意图识别精度无法达到最优。
此外,针对语言模型设计的参数优化方法(领域蒸馏迁移、适配器、模型压缩)等,都会造成模型意图识别精度的下降。专门针对对话设计预训练任务时,虽然模型精度上升,但是计算量相比简单的精调算法大幅度提升,更加不利于在线识别模型的实时更新部署。简而言之,现有方法无法同时兼顾模型识别精度与训练有效性。因此需要提供一种方案以在提高意图识别模型精度的同时提高训练效率。
发明内容
本发明的目的在于提供一种基于预训练语言模型和编码器的消息意图识别方法及系统,用以实现在提高意图识别模型精度的同时提高训练效率的技术效果。
第一方面,本发明提供了一种基于预训练语言模型和编码器的消息意图识别方法,包括:
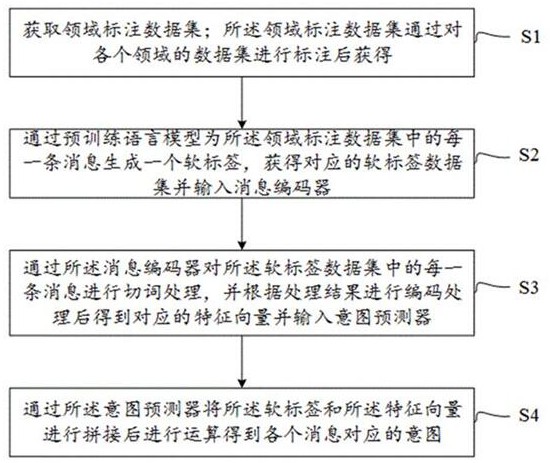
S1.获取领域标注数据集;所述领域标注数据集通过对各个领域的数据集进行标注后获得;
S2.通过预训练语言模型为所述领域标注数据集中的每一条消息生成一个软标签,获得对应的软标签数据集并输入消息编码器;
S3.通过所述消息编码器对所述软标签数据集中的每一条消息进行切词处理,并根据处理结果进行编码处理后得到对应的特征向量并输入意图预测器;
S4.通过所述意图预测器将所述软标签和所述特征向量进行拼接后进行运算得到各个消息对应的意图。
进一步地,所述S2包括:
a.根据预设的采样比例对所述领域标注数据集进行采样,并获得的样本集输入所述预训练语言模型;
b.通过所述预训练语言模型产生所述样本集的特征池化向量,然后将该特征池化向量输入意图预测器中,通过以下公式更新池化变量参数和意图预测器的参数,同时冻结预训练语言模型的参数;
式中,Loss表示损失函数;
c.当所述预训练语言模型收敛后,通过预训练语言模型和意图预测器一起预测所述领域标注数据集中每个消息的softmax输出概率作为该条消息的软标签。
进一步地,所述特征池化向量的计算方式为:
上式中,
进一步地,在执行S3之前所述方法还包括第一训练流程:
从所述软标签数据集中获取一个训练集,通过BPE分词器将所述训练集中的每一条消息进行切词处理后将处理结果输入消息编码器;
所述消息编码器根据所述处理结果进行编码得到每一条信息对应的特征向量并输入意图预测器;
所述意图预测器通过两个全链接隐藏层和一个softmax输出层对该特征向量进行处理得到对应的输出结果;
根据所述输出结果和每一条消息对应的软标签计算交叉熵后作为损失函数对所述消息编码器进行更新。
进一步地,所述第一训练流程之后还包括第二训练流程:通过所述领域标注数据集训练所述消息编码器和意图预测器;使用每一条消息真实标注的语义和所述意图预测器的输出结果计算交叉熵,再次更新所述消息编码器的参数,同时更新所述意图预测器的参数。
进一步地,所述第二训练流程之后还包括第三训练流程:通过所述领域标注数据集对所述预训练语言模型、所述消息编码器和所述意图预测器进行联合训练,对于每一条消息,分别使用预训练语言模型和消息编码器获得对应的特征向量;然后将两个特征向量拼接后输入意图预测器,得到输出结构后与每一条消息真实标注的语义计算交叉熵作为损失函数,更新所述消息编码器和所述意图预测器的参数,冻结预训练语言模型的参数,直到输出结果收敛。
第二方面,本发明提供了一种基于预训练语言模型和编码器的消息意图识别系统,包括数据获取模块、预训练语言模型、消息编码器和意图识别器;
所述数据获取模块用于获取领域标注数据集;
所述预训练语言模型用于为所述领域标注数据集中的每一条消息生成一个软标签,获得对应的软标签数据集并输入消息编码器;
所述消息编码器用于对所述软标签数据集中的每一条消息进行切词处理,并根据处理结果进行编码处理后得到对应的特征向量并输入意图预测器;
所述意图预测器用于将所述软标签和所述特征向量进行拼接后进行运算得到各个消息对应的意图。
进一步地,所述消息编码器包括BPE分词器、Glove词嵌入层和LSTM-CNN网络;所述BPE分词器对输入消息文本进行切词并转化成数字序列,然后将该数字序列送入所述Glove词嵌入层得到对应的词嵌入向量,最后该词嵌入向量通过LSTM-CNN网络进行处理得到对应的特征向量。
进一步地,所述意图识别器为feed-forward神经网络,包括两层全连接隐藏层和一个输出层,使用gelu激活函数,输出层使用softmax函数做多分类处理将消息映射到对应的意图。
本发明能够实现的有益效果是:本发明提供的消息意图识别方法通过预训练语言模型、消息编码器和意图识别器联合对输入消息的意图进识别,既提高了消息识别的精度,同时也提高了训练的效率。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1为本发明实施例提供的一种基于预训练语言模型和编码器的消息意图识别方法的流程示意图;
图2为本发明实施例提供的一种基于预训练语言模型和编码器的消息意图识别系统的拓扑结构示意图。
图标:10-消息意图识别系统;100-数据获取模块;200-预训练语言模型;300-消息编码器;400-意图识别器。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行描述。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。同时,在本发明的描述中,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
请参看图1,图1为本发明实施例提供的一种基于预训练语言模型和编码器的消息意图识别方法的流程示意图。
在一种实施方式中,本发明实施例提供的基于预训练语言模型和编码器的消息意图识别方法,包括:
S1.获取领域标注数据集;所述领域标注数据集通过对各个领域的数据集进行标注后获得;
S2.通过预训练语言模型为所述领域标注数据集中的每一条消息生成一个软标签,获得对应的软标签数据集并输入消息编码器;
S3.通过所述消息编码器对所述软标签数据集中的每一条消息进行切词处理,并根据处理结果进行编码处理后得到对应的特征向量并输入意图预测器;
S4.通过所述意图预测器将所述软标签和所述特征向量进行拼接后进行运算得到各个消息对应的意图。
在上述实现过程中,意图预测器根据预训练语言模型和消息编码器的输出进行拼接后计算得到各个消息对应的意图,既提高了消息示意图识别的精度,同时也提高了训练效率。
在一种实施方式中,预训练语言模型可以采用目前任意一种,例如BERT、Roberta、XLNet等,在实际使用时也可以根据具体领域需求,构建一个专属的预训练语言模型。
在一种实施方式中,S2具体包括:
a.根据预设的采样比例对所述领域标注数据集进行采样,并获得的样本集输入所述预训练语言模型;
b.通过所述预训练语言模型产生所述样本集的特征池化向量,然后将该特征池化向量输入意图预测器中,通过以下公式更新池化变量参数和意图预测器的参数,同时冻结预训练语言模型的参数;
式中,Loss表示损失函数;
c.当所述预训练语言模型收敛后,通过预训练语言模型和意图预测器一起预测领域标注数据集中每个消息的softmax输出概率作为该条消息的软标签。
其中,特征池化向量的计算方式为:
上式中,
在一种实施方式中,上述方法还包括以下几个训练流程。
在执行S3之前先执行第一训练流程:
从所述软标签数据集中获取一个训练集,通过BPE分词器将所述训练集中的每一条消息进行切词处理后将处理结果输入消息编码器;
所述消息编码器根据所述处理结果进行编码得到每一条信息对应的特征向量并输入意图预测器;
所述意图预测器通过两个全链接隐藏层和一个softmax输出层对该特征向量进行处理得到对应的输出结果;
根据所述输出结果和每一条消息对应的软标签计算交叉熵后作为损失函数对所述消息编码器进行更新。
在上述训练过程中,更新消息编码器时,冻结意图预测器,直到意图预测器的输出收敛。
在执行完第一训练流程之后就可以继续执行第二训练流程:
通过所述领域标注数据集训练所述消息编码器和意图预测器;使用每一条消息真实标注的语义和所述意图预测器的输出结果计算交叉熵,再次更新所述消息编码器的参数,同时更新所述意图预测器的参数。
在执行完第二训练流程之后就可以继续执行第三训练流程:
通过领域标注数据集对预训练语言训练模型、消息编码器和意图预测器进行联合训练,对于每一条消息,分别使用预训练语言训练模型和消息编码器获得对应的特征向量;然后将两个特征向量拼接后输入意图预测器,得到输出结构后与每一条消息真实标注的语义计算交叉熵作为损失函数,更新消息编码器和意图预测器的参数,冻结预训练语言模型的参数,直到输出结果收敛。
根据输入的消息进行意图识别之前,通过上述几个训练过程依次更新预训练语言训练模型、消息编码器和意图预测器的参数,既可以提高意图识别的精度,也提高了意图识别模型训练的效率。
请参看图2,图2为本发明实施例提供的一种基于预训练语言模型和编码器的消息意图识别系统的拓扑结构示意图。
在一种实施方式中,本发明实施例还提供了一种基于预训练语言模型和编码器的消息意图识别系统10,包括数据获取模块100、预训练语言模型200、消息编码器300和意图识别器400;
数据获取模块100用于获取领域标注数据集;
预训练语言模型200用于为领域标注数据集中的每一条消息生成一个软标签,获得对应的软标签数据集并输入消息编码器;
消息编码器300用于对软标签数据集中的每一条消息进行切词处理,并根据处理结果进行编码处理后得到对应的特征向量并输入意图预测器;
意图预测器400用于将软标签和特征向量进行拼接后进行运算得到各个消息对应的意图。
通过上述消息意图识别系统,既降低了消息意图识别模型的复杂度,也提高了消息意图识别的精度和训练的效率。
在一种实施方式中,消息编码器包括BPE分词器、Glove词嵌入层和LSTM-CNN网络;BPE分词器对输入消息文本进行切词并转化成数字序列,然后将该数字序列送入Glove词嵌入层得到对应的词嵌入向量,最后该词嵌入向量通过LSTM-CNN网络进行处理得到对应的特征向量。其中,BPE分词器可以采用sentencepiece基于无标签对话消息进行训练实现。
需要说明的是,消息编码器所包含的分词器可以采用任意现有分词算法实现;其词嵌入模块也可以用Word2Vec等代替,不局限于Glove;其所用LSTM-CNN网络也可以替换为Transformer、Bi-LSTM等等其他类型的神经网络结构。
在一种实施方式中,意图识别器为feed-forward神经网络,包括两层全连接隐藏层和一个输出层,使用gelu激活函数,输出层使用softmax函数做多分类处理将消息映射到对应的意图。
综上所述,本发明实施例提供一种基于预训练语言模型和编码器的消息意图识别方法及系统,S1.获取领域标注数据集;所述领域标注数据集通过对各个领域的数据集进行标注后获得;S2.通过预训练语言模型为所述领域标注数据集中的每一条消息生成一个软标签,获得对应的软标签数据集并输入消息编码器;S3.通过所述消息编码器对所述软标签数据集中的每一条消息进行切词处理,并根据处理结果进行编码处理后得到对应的特征向量并输入意图预测器;S4.通过所述意图预测器将所述软标签和所述特征向量进行拼接后进行运算得到各个消息对应的意图。通过预训练语言模型、消息编码器和意图识别器进行协同处理,既提高了消息识别的精度,同时也提高了训练的效率。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 基于预训练语言模型和编码器的消息意图识别方法及系统
- 基于预训练语言模型和编码器的消息意图识别方法及系统