一种基于用电量数据和径向基神经网络的资源配置方法
文献发布时间:2023-06-19 13:46:35
技术领域
本发明涉及电力大数据技术领域,具体涉及一种基于用电量数据和径向基神经网络的资源配置方法。
背景技术
在进行资源配置时,由于地区生产总值数据统计总存在滞后性,并且可能会存在企业误报数据导致统计不准确,只依靠传统的财务统计方法已经无法支持针对产业发展不平衡带来的资源配置采取应对措施。统计在现代环境下将从只依靠已有数据的统计变为需要依靠智能手段及时地做出较为准确的预测并进行调整优化。电力大数据由于其及时性和准确性,可以用来预测各地区各产业发展情况,作为资源配置的基础和依据。
机器学习是现阶段主流的方式之一,其中人工神经网络通过统计学的方法,能够类似人一样具有简单的决断能力,也可以利用其来作为预测和资源配置的手段。一般的神经网络模型具有过多的隐含层,训练速度不够迅速。
发明内容
为解决现有技术中存在的不足,本发明的目的在于,提供一种基于用电量数据和径向基神经网络的资源配置方法,依靠企业电力数据和地区环境数据,模拟预测产业发展趋势,快速准确进行资源的优化配置。
本发明采用如下的技术方案
一种基于用电量数据和径向基神经网络的资源配置方法,该方法包括以下步骤:
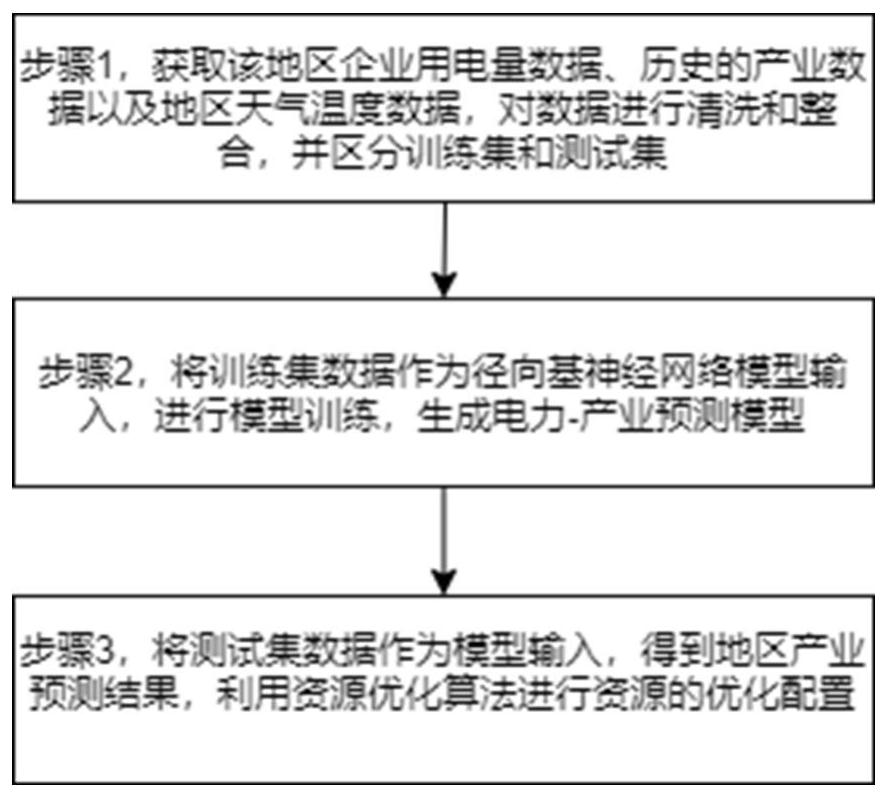
步骤1:获取该地区企业用电量数据、历史的产业数据以及地区天气温度数据,对数据进行清洗和整合,并区分训练集和测试集;
步骤2:将训练集数据作为径向基神经网络模型输入,进行模型训练,生成电力-产业预测模型;
步骤3:将测试集数据作为模型输入,得到地区产业预测结果,利用资源优化算法进行资源的优化配置。
优选的,步骤1包括:
步骤1.1:获取该地区企业用电量数据、历史的产业数据以及地区天气温度数据;
步骤1.2:对该地区企业用电量数据、历史的产业数据以及地区天气温度数据进行清洗;
步骤1.3:对企业用电量数据、产业数据、地区天气温度数据统一进行对数差分处理并整合;
步骤1.4:将处理好的数据划分为训练集和测试集。
优选的,步骤1.2中,数据清洗包括删除严重缺失的企业用电量数据以及产业数据、使用中位数填补缺失的温度数据。
优选的,步骤1.3中,对企业用电量数据、产业数据、地区天气温度数据统一进行对数差分处理,统一为各自的增长率数据;整合转换后的数据。
优选的,步骤2中,将训练集数据作为径向基模型输入,进行模型训练,找到用电量数据、地区温度数据与产业数据之间的关系,生成电力-产业预测模型。
优选的,步骤2中,模型的输入为用电量数据和温度数据各自的增长率,输出为产业发展增长率。7、如权利要求5所述的基于用电量数据和径向基神经网络的资源配置方法,其特征在于,
步骤2包括:
步骤2.1:网络初始化;
步骤2.2:设置激励函数为高斯径向基函数;
步骤2.3:采用最小均方误差算法LMS计算输出层的连接权值;
步骤2.4:若预测结果的均值与实际结果的均值差值大于给定阈值,需要重新调整隐含层神经元个数l,重新进行训练,直到差值小于给定阈值。
优选的,步骤2.1中,根据系统输入输出序列(X,Y),确定网络输入层节点数n、隐含层神经元个数l、输出层节点数q,初始化隐含层和输出层之间的连接权值w
优选的,输入层节点数为输入向量维数,输入包括电力数据和温度数据,则n=2;输出层节点数为输出向量维数,输出包括地区产业发展增长率,q=1。
优选的,步骤2.2中,高斯径向基函数为:
其中,r表示样本数据点和训练数据点之间的距离,距离等于0时,径向基函数等于1;常数σ为到达率或者函数跌落到零的速度。
优选的,径向基函数的常数σ根据数据中心的散布确定,将径向基函数的常数σ设为:
其中,d
优选的,步骤2.3中,最小均方误差算LMS算法包括以下步骤:
步骤2.3.1:设置变量和参量,X(n)为输入向量,称为训练样本;W(n)为权值向量;e(n)为偏差;d(n)为期望输出;y(n)为实际输出;η为学习速率;n为迭代次数;
步骤2.3.2:初始化,令n=0,赋给W(0)一个较小的随机非零值;
步骤2.3.3:对于一组输入样本X(n)和对应的期望输出d,计算:
e(n)=d(n)-X
W(n+1)=W(n)+ηX(n)e(n)
步骤2.3.4:判断期望输出与实际输出的差是否小于隐含层阈值,如小于第一则结束;如否,则n增加1,转入步骤2.3.3继续执行。
优选的,步骤3包括:
步骤3.1:将共m个产业发展趋势预测结果r
步骤3.2:根据优化后的资源配置的比例,进行资源的优化配置。
优选的,步骤3.1中,第n产业优化后的资源配置的比例R
其中,
优选的,步骤3.2中,根据优化后的资源配置的比例,增减该产业当期的有限资源投入量,有限资源包括原材料供应量、以及电力供应量。
本发明的有益效果在于,与现有技术相比:
本发明利用用电数据的及时性,可以快速预测地区产业发展趋势,进行资源的优化配置;本发明的径向基神经网络使用高斯基函数作为激励函数,对输入信息进行空间映射的变换,由于高斯基函数可以将向量映射到更高的维度,对隐含层和输出层之间的可调权重来说,原本线性不可分的问题就可以直接变为线性可分,所以只需要有一层隐含层,大大加快了运算速度,能够快速进行资源的优化配置;本发明利用用电数据的可靠性以及径向基模型的准确性,可以核查数据的真实度;本发明利用资源优化算法,将预测出的地区产业发展趋势映射到具体的资源优化配置方案,能够更为合理、快速地增减有限资源的供给量。
附图说明
图1是本发明的基于用电量数据和径向基神经网络的资源优化配置方法的步骤流程示意图;
图2是本发明的电力-产业径向基模型的结构示意图;
图3是本发明的具体实例中2015-2020年南京和盐城市每月医药行业用电量、行业发展趋势和温度数据;
图4是本发明的具体实例中预测出的2021年南京市医药行业发展趋势示意图;
图5是本发明的具体实例中预测出的2021年盐城市医药行业发展趋势示意图。
具体实施方式
下面结合附图对本申请作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本申请的保护范围。
如图1所示,本发明的基于用电量数据和径向基神经网络的资源优化配置方法包括以下步骤:
步骤1:获取该地区企业用电量数据、历史的产业数据以及地区天气温度数据,对数据进行清洗和整合,并区分训练集和测试集。
进一步地,步骤1包含以下步骤:
步骤1.1:获取该地区企业用电量数据、历史的产业数据以及地区天气温度数据。
其中,企业用电量数据来源于电力系统数据库,从中导出;产业数据可由统计局发布的统计年鉴中获取,为该产业的产值总量;天气数据使用的是气象局发布的一段时间内的平均温度数据。
步骤1.2:对该地区企业用电量数据、历史的产业数据以及地区天气温度数据进行清洗。
数据清洗包括删除严重缺失的企业用电量数据以及产业数据、使用中位数填补缺失的温度数据。
步骤1.3:对企业用电量数据、产业数据、地区天气温度数据统一进行对数差分处理并整合。
对企业用电量数据、产业数据、地区天气温度数据统一进行对数差分处理,以将不同维度的数据统一为各自的增长率数据,方便处理。
以企业用电量数据E为例,对数差分处理后的企业用电量增长率为e
将转换后的数据整合到一张数据表中,便于模型训练。
步骤1.4:将处理好的数据划分为训练集和测试集。
将处理好的数据划分为训练集和测试集。在本发明的一个实施例中,训练集和测试集的比例为4:1。
步骤2:将训练集数据作为径向基神经网络模型输入,进行模型训练,生成电力-产业预测模型。
将训练集数据作为径向基模型输入,进行模型训练,以期找到用电量数据、地区温度数据与产业数据之间的关系,该关系即为生成的电力-产业预测模型。该模型如图3所示,其中X代表了模型的输入,为用电量数据和温度数据,具体为对数差分处理后的增长率数据,f代表了高斯径向基函数,Y代表了模型输出,为产业数据,具体为地区产业发展增长率预测结果。
进一步地,步骤2包含以下步骤:
步骤2.1:网络初始化。
根据系统输入输出序列(X,Y),确定网络输入层节点数n、隐含层神经元个数l、输出层节点数q,初始化隐含层和输出层之间的连接权值w
步骤2.2:设置激励函数为高斯径向基函数:
其中,r表示样本数据点和训练数据点之间的距离,距离等于0时,径向基函数等于1;常数σ在支持向量机中被称为到达率或者函数跌落到零的速度。径向基函数的常数σ可根据数据中心的散布而确定,为了避免每个径向基函数太尖或太平,选择方法是将径向基函数的常数σ设为:
其中,d
步骤2.3:采用最小均方误差算法LMS计算输出层的连接权值w
最小均方误差算LMS算法具体包括以下步骤:
步骤2.3.1:设置变量和参量,X(n)为输入向量,或称为训练样本;W(n)为权值向量;e(n)为偏差;d(n)为期望输出;y(n)为实际输出;η为学习速率;n为迭代次数。
步骤2.3.2:初始化,令n=0,赋给W(0)一个较小的随机非零值。
步骤2.3.3:对于一组输入样本X(n)和对应的期望输出d(n),计算:
e(n)=d(n)-X
W(n+1)=W(n)+ηX(n)e(n)
步骤2.3.4:判断期望输出与实际输出的差是否小于隐含层阈值,如小于则结束;如否,则n增加1,转入步骤2.3.3继续执行。
在本发明的一个实施例中,隐含层阈值设置为为0.015
步骤2.4:若预测的产业发展增长率均值与实际结果的均值差值大于给定阈值,需要重新调整隐含层神经元个数l,重新进行训练,直到差值小于给定阈值。
给定阈值大于隐含层阈值。在本发明的一个实施例中,给定阈值设置为0.02。
步骤3:将测试集数据作为模型输入,得到地区产业预测结果,利用资源优化算法进行资源的优化配置。
其中,地处产业的预测结果主要表示为地区各产业的生产总值增长率,以此结果结合资源优化算法,得出优化产业资源的配置比例。
进一步地,步骤3包含以下步骤:
步骤3.1:将共m个产业发展趋势预测结果r
第n产业优化后的资源配置的比例R
其中,
步骤3.2:根据优化后的资源配置的比例,进行资源的优化配置。
根据优化后的资源配置的比例,增减该产业当期的有限资源投入量,有限资源包括原材料供应量、电力供应量等。
为了更好地说明本发明,下面给出本发明的具体实例。本实例模拟了利用南京市和盐城市所有医药企业的产业用电量之和、医药产业发展增长率和天气温度数据,预测南京市和盐城市医药产业发展趋势进行资源的优化配置。
本示例的具体方法包括以下步骤:
步骤1:由统计局以及电力部门数据得到南京市以及盐城市医药行业用电量(E)、行业生产总值数据(GDP)和天气温度数据(T)。其中,天气数据是对各市当月平均温度,对其进行对数差分处理;行业用电量增长率e
步骤2:将训练集数据作为径向基模型输入,进行模型训练,经过多轮训练后生成电力-产业预测模型。初始化神经网络,将图2中电量增长率和温度增长率作为输出序列X,医药产业发展增长率作为输出序列Y,经过多轮测试,确定网络输入层节点数为2,隐含层神经元个数为7、输出节点数为1。本次实验输入层、隐含层的权连接值默认为1,隐含层、输出层之间的连接权值分别为-0.06312462,-0.07661353,0.1909057,0.14380734,0.06198154,-0.17863224,0.11221673,设置激励函数为高斯径向基函数:
步骤3:将测试集数据放入模型中计算结果,南京地区医药产业发展趋势增长率结果如图4所示。其中,2021年上半年增长趋势值为:-0.03462553,-0.06826449,0.12450217,0.0342885,0.0600885,0.05811469;盐城地区医药产业发展趋势增长率结果如图5所示,2021年上半年增长趋势值为:-0.01405698,-0.01245377,-0.00357341,0.00627117,-0.0081563,-0.01255616。若希望计算近半年资源调整的比例,则对6个月的增长趋势值求平均值,南京地区未来半年医药产业发展趋势增长率为0.29,盐城为-0.0074。代入资源优化算法公式
通过本实例可以验证,本发明的资源配置优化方法建立的电力-产业模型可以较为准确地预测两市医药产业发展趋势,能够更为快速准确地进行资源的优化配置。
本发明的有益效果在于,与现有技术相比,本发明利用用电数据的及时性,可以快速预测地区产业发展趋势,进行资源的优化配置;本发明的径向基神经网络使用高斯基函数作为激励函数,对输入信息进行空间映射的变换,由于高斯基函数可以将向量映射到更高的维度,对隐含层和输出层之间的可调权重来说,原本线性不可分的问题就可以直接变为线性可分,所以只需要有一层隐含层,大大加快了运算速度,能够快速进行资源的优化配置;本发明利用用电数据的可靠性以及径向基模型的准确性,可以核查数据的真实度;本发明利用资源优化算法,将预测出的地区产业发展趋势映射到具体的资源优化配置方案,能够更为合理、快速地增减有限资源的供给量。
本发明申请人结合说明书附图对本发明的实施示例做了详细的说明与描述,但是本领域技术人员应该理解,以上实施示例仅为本发明的优选实施方案,详尽的说明只是为了帮助读者更好地理解本发明精神,而并非对本发明保护范围的限制,相反,任何基于本发明的发明精神所作的任何改进或修饰都应当落在本发明的保护范围之内。
- 一种基于用电量数据和径向基神经网络的资源配置方法
- 一种基于大数据的医疗资源配置方法及系统