一种基于多时间尺度解耦的循环神经网络的长序列采样方法及装置
文献发布时间:2023-06-19 18:37:28
技术领域
本发明属于计算机数据处理技术领域,具体涉及一种基于多时间尺度解耦的循环神经网络的长序列采样方法及装置。
背景技术
现实世界中存在大量的无标签序列数据,采用预训练对其加以利用是深度学习中的一种重要方法。预训练能够通过深度神经网络,挖掘大量无标签数据中的自监督信息,获得数据的低维表示,并迁移至下游的有监督任务中,这种方法可以使下游有监督任务需要的数据量减少,降低其训练难度。
在自然语言处理领域中,目前广泛使用的预训练语言模型常以Transformer为模型基础,包括GPT、BERT等,这些模型采用了注意力机制,在捕捉序列的长期依赖和彼此交互方面能力突出,并在文本生成、机器翻译等多项下游任务上取得了巨大的成功。然而,全连接式的自注意力机制的时间复杂度与空间复杂度随输入序列的长度平方级增长,使其难以处理较长的序列,因此,在实际应用中往往在输入模型前将长序列截断或采样。同时,一些研究表明,序列表征在下游任务上的表现,与模型能接收的序列长度息息相关。因此,如何使得模型能够接收更长的序列并进行表征,是当前学术研究的热点和难点。
Transformer是基于注意力机制学习序列之间的依赖关系,产生序列表征的模型。Transformer模型的注意力机制主要用来捕捉序列之间的相关性,该模块接收输入X,通过线性变换得到(Q,K,V)三元组,并以如下公式计算注意力:
其中
针对这一技术难题,存在几个研究方向。其一是从计算复杂度较高的注意力机制入手,采取核函数估算或用一定的手段稀疏化的方式,使其计算复杂度降低到O(NlogN)甚至O(N);其二为采用固定长度的向量作为记忆单元,将长序列中的信息压缩存储到记忆单元中;其三是用池化或卷积的方式压缩长序列,降低其分辨率。这些技术手段都能一定程度上解决问题,但同样也都存在一定缺陷。稀疏化注意力的方案在理论上可以达到高效,但采样过程中需要做一些复杂的运算,且需要特殊的优化器优化;线性注意力的方法无法并行训练,导致这两类方法都很难达到理论上的复杂度;记忆单元和降低分辨率的方法容易导致序列的细节丢失。
此外,目前长序列表征技术较少考虑到序列的阶段性与周期性。Transformer在位置编码中引入类周期性,但这种处理方式难以捕捉具有复杂周期性的序列;Informer提供了一种特殊的时间编码,以期模型捕捉到有关星期、季节等的周期性,然而这种方式同样不够灵活。
发明内容
本发明提供了一种基于多时间尺度解耦的循环神经网络的长序列采样方法,采用该方法能够删减序列中的冗余信息,减少送入表征模型的序列长度,从根本上减少模型的消耗。
一种基于多时间尺度解耦的循环神经网络(TPD-LSTM,multi-timescaleperiodicity disentangled LSTM)的长序列采样方法,包括:
(1)获得下游任务训练样本集,每个训练样本为一条序列,对应一个真实标签,所述序列包括多个样本点,每个样本点对应一个时间戳,每个样本点的特征进行one-hot形式转化或z-score标准化转化,将每个转化后的特征通过嵌入层后拼接得到每个样本点的嵌入表征,多个样本点的嵌入表征构建了表征序列;
(2)构建训练模型,所述训练模型包括LSTM神经网络和门控函数,其中:将当前时刻样本点的嵌入表征输入至LSTM神经网络中得到当前时刻的初始记忆单元和初始隐藏状态,将所述初始记忆单元和初始隐藏状态分别输入至门控函数得到当前时刻的最终隐藏状态,所述门控函数是通过当前时间戳和阶段时间点构建的重要度评分函数,用于对当前时刻初始隐藏状态所处阶段的重要度进行评分以确定保留当前时刻初始隐藏状态的比例进而得到当前时刻的最终隐藏状态;将最终隐藏状态输入至带有softmax激活函数的全连接层得到类别概率向量,从类别概率向量中得到下游任务的预测标签;
(3)基于训练样本集通过下游任务的真实标签和预测标签采用损失函数更新训练模型的参数,提取门控函数的更新参数得到采样算子;
(4)应用时,将原始长序列样本输入至采样算子中得到每个样本点重要度评分,将每个样本点重要度评分作为二项分布的概率值生成随机数结果,提取达到阈值的随机数结果对应的样本点作为序列样本数据。
本发明提供的序列样本中的每个样本点包括离散特征或连续特征,对离散特征进行one-hot形式转化,对连续特征进行z-score标准化转化。
本发明提供的将所述表征序列输入至LSTM神经网络中得到当前时刻的初始记忆单元和初始隐藏状态,所述LSTM神经网络中包括遗忘门控、输入门控和输出门控,其中:
将当前时刻样本点的嵌入表征输入至LSTM神经网络,将前一时刻的隐藏状态与当前时刻样本点的嵌入表征进行拼接,将拼接结果通过线性变换分别得到遗忘门控、输入门控和输出门控,将拼接结果通过激活函数得到临时记忆单元,通过遗忘门控控制前一个时刻记忆单元的保留程度,通过输入门控控制临时记忆单元的保留程度,通过遗忘门控和输入门控的控制得到当前时刻的时刻记忆单元,对当前时刻记忆单元通过tanh函数后与输出门控相乘控制当前时刻记忆单元的信息输出至当前时刻隐藏状态的程度。
所述门控函数是通过当前时间戳和阶段时间点构建的重要度评分函数,通过所述门控函数得到的第t时间戳的重要度评分s
其中,j表示当前时刻样本点的时间戳所处的阶段的索引,Ω
所述门控函数中的第j-1个阶段和第j个阶段的时间点均来自时间阶段向量Ω,所述时间向量Ω=(Ω
通过所述重要度评分函数对当前时刻初始记忆单元所处阶段的重要度进行评分以确定保留当前时刻初始记忆单元的比例进而得到当前时刻的最终记忆单元,所述当前时刻t的最终记忆单元c
其中,
通过所述重要度评分函数对当前时刻初始隐藏状态所处阶段的重要度进行评分以确定保留当前时刻初始隐藏状态的比例进而得到当前时刻的最终隐藏状态,所述当前时刻t的最终隐藏状态h
其中,
所述基于训练样本集通过下游任务的真实标签和预测标签采用损失函数更新训练模型的参数,所述门控函数的所更新的参数包括ω
一种基于多时间尺度解耦的循环神经网络的长序列采样装置,包括计算机存储器、计算机处理器以及存储在所述计算机存储器中并可在所述计算机处理器上执行的计算机程序,所述计算机存储器中采用基于自适应和周期性的长序列采样方法构建的采样算子;
所述计算机处理器执行所述计算机程序时实现以下步骤:
将原始长序列样本输入至采样算子中得到每个样本点重要度评分,将每个样本点重要度评分作为二项分布的概率值生成随机数结果,提取达到阈值的随机数结果对应的样本点作为序列样本数据。
与现有技术相比,本发明的有益效果为:
(1)本发明通过时间戳和阶段时间点构建门控函数,通过门控函数对当前时刻,即当前时间戳的隐藏状态进行重要度评分,该重要度评分考虑到了长序列的在不同阶段存在较大的差异,以及周期性变化,从而在训练后得到的采样算子能够去除长序列中的冗余信息,过滤掉长序列中不重要的部分,一方面减少了序列的噪音;另一方面将输入序列长度与模型计算的复杂度解耦,使得模型可以处理更长的序列;此外,使用的采样算子独立于预训练表征模型,使得其容易迁移至其他预训练模型中。
(2)本发明对特定的下游任务,使用少量该下游任务的有监督数据集,训练带有门控函数的长短时记忆网络(Long Short Term Memory,简称LSTM),使其学习一个自适应下游任务的,适用于多阶段周期性序列数据的采样函数;然后将学习到的采样函数作为表征模型外一个独立的采样算子,序列数据输入表征模型之前,都需经过采样算子的采样处理以去除冗余的数据。
附图说明
图1为本发明实施例提供的基于多时间尺度解耦的循环神经网络的长序列采样方法流程图。
图2为本发明实施例提供的预训练与迁移学习框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
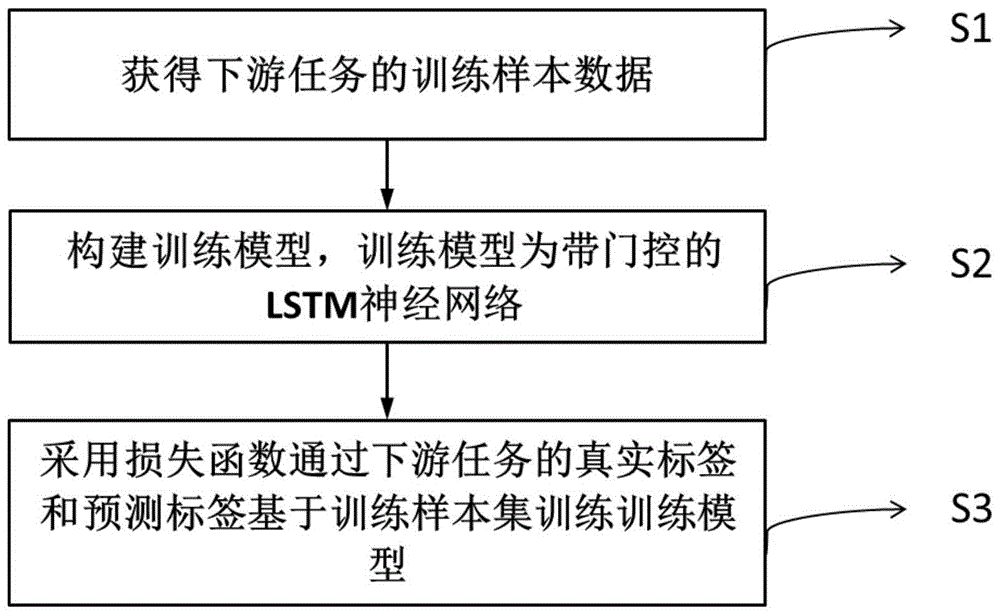
本发明提供一种基于多时间尺度解耦的循环神经网络的长序列采样,如图1所示,包括:
S1:获得训练样本数据:本发明采用少量的下游任务有监督数据集,并获得该监督数据集的真实标签,该监督数据集中的每个样本为一条时间序列,所述时间序列为医疗,金融,电力和天气场景下的时间序列,对应一个真实标签,每一条序列包括多个样本点,每个样本点对应一个时间戳,每个样本点包括多个离散或连续的特征,将连续的特征进行z-score标准化,将离散的特征转化为one-hot形式的特征,将转化后的特征输入对应的嵌入层后拼接起来,作为该样本点的嵌入表征,所有样本点的嵌入表征构建了表征序列;
S2:构建训练模型:训练模型为带门控的LSTM神经网络(TPD-LSTM),如图2所示,带门控的LSTM神经网络包括LSTM神经网络和门控函数,其中:
LSTM神经网络以RNN模型为基础,增加了输入门、遗忘门、输出门三个门控单元,各自连接到一个乘法元件上,其权值控制信息流的输入、输出以及记忆单元的状态。
在t时刻,LSTM神经网络公式如下:
f
i
o
h
其中,x
在上述的LSTM神经网络中,假设序列的时间依赖模式不随时间的改变而改变,而事实上序列具有阶段性,不同阶段的模式存在较大差异,因此TPD-LSTM神经网络提出了自适应的阶段检测机制,该阶段检测机制通过学习一个时间向量Ω=(Ω
本发明设计了一个基于时间戳的门控函数来控制输入信号的流入,以解决RNN类模型面临的长序列的记忆衰减问题,具体来说,通过上述LSTM神经网络,在第个时刻,获得该时刻的初始记忆单元
其中,
其中,j表示当前时刻样本点的时间戳所处的阶段的索引,Ω
样本经过TPD-LSTM前向传播,最后一个时刻输出的隐藏状态h
S3:基于训练样本集训练训练模型:计算得到的标签与真实标签计算损失,该损失可以根据下游任务灵活设计,在序列分类任务中,通常使用交叉熵损失。通过梯度传播调整模型参数;提取门控函数的更新参数得到采样算子;所述门控函数的所更新的参数包括ω
应用时,将原始长序列样本输入至采样算子中得到每个样本点重要度评分,可以理解向采样算子输入原始长序列样本的时间戳得出评分以判断该样本点的重要性进而确定是否采样,将每个样本点重要度评分作为二项分布的概率值生成随机数结果,提取随机数结果为1所对应的样本点作为序列样本数据。
一种基于多时间尺度解耦的循环神经网络的长序列采样装置,包括计算机存储器、计算机处理器以及存储在所述计算机存储器中并可在所述计算机处理器上执行的计算机程序,所述计算机存储器中采用基于自适应和周期性的长序列采样方法构建的采样算子;
所述计算机处理器执行所述计算机程序时实现以下步骤:
将原始长序列样本输入至采样算子中得到每个样本点重要度评分,将每个样本点重要度评分作为二项分布的概率值生成随机数结果,提取随机数结果为1所对应的样本点作为序列样本数据。
本发明采用基于带有门控函数的LSTM的长序列采样方法得到的采样算子用于预训练和迁移学习,如图2所示,包括:
S1:采用大量无监督序列数据集训练预训练模型,包括;
S1.1:获得数据集中的序列样本,通过采样算子得出该序列样本中每个样本点的重要性评分,对于每一个样本点,用该评分作为二项分布的概率值,生成随机数结果,选择结果为1的部分作为被采样的数据;
S1.2:经采样的数据集在预训练模型上训练,以Bert模型为例,包括:
S1.2.1:样本经过嵌入层,转化为表征序列,并在序列最前端加上CLS向量,该CLS向量将作为序列整体的表征,用于计算Loss及应用在下游任务中;
S1.2.2:用随机Mask覆盖15%的表征序列,将其输入Bert模型中;该Bert模型由8个Self-Attention子模块组成,每个子模块包含一个Self-Attention层,一个Linear层,一个Layer-Norm层;经过模型后,我们用CLS向量预测被覆盖的部分的表征,和真实的表征计算MSE Loss作为自监督学习的Loss;
S1.2.3:使用Adam优化算法,对模型进行优化;
S1.2.4:模型训练完毕后,每一个序列样本输入模型后得到的CLS向量作为该序列的总体表征(此时不需要再Mask序列);
S1.3:表征迁移至下游任务:
利用S1.2步骤中得到的序列的整体表征来得到下游任务的结果。以序列分类任务为例,以样本的表征作为输入,经过一个带Softmax激活函数的全连接层映射为一个
实施例1
本发明适用于对各种具有周期性和阶段性的时间序列进行采样,包括医疗、金融、天气、电力等方面的时间序列,可以适用于多样的下游任务,如医疗序列分类,电力数据预测,天气预测,股票预测等等。
以下以ETT电力时间序列公开数据集中的ETTm2数据集为例进行本发明的实例说明。
该数据集包含来自中国两个独立县的2年电力数据。每一个数据点包括目标值“油温”及6个功率负载特征,以15分钟为间隔记录一次。我们用一定窗口内的序列数据预测下一个数据点的目标值“油温”,即这是一个序列预测任务。训练集/验证集/测试集分别是12/4/4个月的数据。这里我们将窗口大小设定为1440个数据点。
S1.一个batch输入数据的维度为:[64,1440,1],其中64代表batch的大小,1440代表序列长度,1代表每个序列点的特征个数。
S2:训练TPD-LSTM模型,具体如下:
S2-1:输入的预处理,在输入最后一维上做z-score标准化,将其数值范围变为均值为0,方差为1;将输入矩阵维度重塑为[64,1,1440],经过一个嵌入层,该嵌入层为一个一维的卷积层,输入通道为1,输出通道为512,卷积核为3;输出维度为[64,512,1440],将其重塑为[64,1440,512]。
S2-2:将经过预处理的数据输入TPD-LSTM模型中。在第t个时刻,按照公式(3-8)计算得到临时记忆单元
S2-3:重复上述步骤,完成该batch数据的输入,获得一个维度为[64,512]的表征,其中512为循环神经网络隐藏层的维度。
S2-6:经全连接层(Linear),获得对下一个时刻“油温”值的预测值,维度变化为:[64,512]->[64,1]
S2-7:与真实值对比,计算MSE损失,训练TPD-LSTM模型;
S3:用S2中训练好的采样函数计算出其中每一个样本点的重要性评分,对于每一个样本点,用该评分作为二项分布的概率值,生成随机数结果,选择结果为1的部分作为被采样的数据;采样后的长度为L,即:[64,2709,1]->[64,L,1]。
采样后的数据集可以使用在任何表征模型上,以下分别以LSTM与Bert模型作为实施例进行说明。
表征模型为LSTM:
S3:将S2中得到的采样后的数据集送入表征模型中进行学习。具体如下:
S3-1:输入为[64,L,1]经过嵌入层,维度转换为[64,L,1]->[64,L,512],其中512为模型隐藏层维度。
S3-2:序列依次输入LSTM单元,输入完毕后最后一个单元的隐藏状态作为序列表征,维度[64,512]。
S3-3:表征输入下游任务网络,该网络是一个全连接(MLP)层,输出各个类别的预测概率,维度[64,512]->[64,2]。
S4-1:和真实标签比较,计算交叉熵损失。
S4-2:使用Adam优化算法,对模型进行优化。
表征模型为Bert:
S3:将S2中得到的采样后的数据集送入表征模型中进行学习。具体如下:S3-1:输入为[64,L,1]经过嵌入层,维度转换为[64,L,1]->[64,L,512],其中512为模型隐藏层维度。
S3-2:在序列最前端加上CLS向量,维度[64,L,512]->[64,L+1,512]。
S3-3:依次经过8个Bert子模块,模块内部具体说明如下:
S3-3-1:经过Self-Attention层,维度[64,L,512]->[64,L,512]。
S3-3-2:经过Linear层,维度[64,L,512]->[64,L,512]。
S3-3-3:经过Layer-Norm层,维度[64,L,512]->[64,L,512]。
S3-4经过经过前向传播得到的CLS向量作为序列的表征;用随机Mask覆盖15%的序列,用学习到的表征预测被覆盖的部分的Embedding,和真实的Embedding计算MSE Loss作为自监督学习的Loss;
S3-5使用Adam优化算法,对模型进行优化。训练得到的CLS向量作为最终表征,维度[64,512]。
S4:将S3中得到的表征输入下游任务,训练下游任务模型。具体如下:S4-1表征输入下游任务网络,该网络是一个MLP层,输出各个类别的预测概率,维度[64,512]->[64,2];
S4-2和真实标签比较,计算交叉熵损失;
S4-3使用Adam优化算法,对模型进行优化。得到下游任务模型。
实施例2
以下以Weather数据集为例进行本发明的实例说明。该数据集包含美国近1,600个地点的当地气候数据。每个数据点由目标值“湿球”和11个气候特征组成。同样是一个序列预测任务。从2010年到2013年4年,每1小时收集一次数据点。训练/验证/测试是28/10/10个月。在这里,我们将时间窗口设定为1440。
S1.一个batch输入数据的维度为:[64,1440,1],其中64代表batch的大小,1440代表序列长度,1代表每个序列点的特征个数。
S2:训练TPD-LSTM模型,具体如下:
S2-1:输入的预处理,在输入最后一维上做z-score标准化,将其数值范围变为均值为0,方差为1;将输入矩阵维度重塑为[64,1,1440],经过一个嵌入层,该嵌入层为一个一维的卷积层,输入通道为1,输出通道为512,卷积核为3;输出维度为[64,512,1440],将其重塑为[64,1440,512]。
S2-2:将经过预处理的数据输入TPD-LSTM模型中。在第t个时刻,按照公式(3-8)计算得到临时记忆单元
S2-3:重复上述步骤,完成该batch数据的输入,获得一个维度为[64,512]的表征,其中512为循环神经网络隐藏层的维度;
S2-4:经全连接层(Linear),获得对下一个时刻“湿球”值的预测值,维度变化为:[64,512]->[64,1]
S2-5:与真实值对比,计算MSE损失,训练TPD-LSTM模型。
S3:用S2中训练好的采样函数计算出其中每一个样本点的重要性评分,对于每一个样本点,用该评分作为二项分布的概率值,生成随机数结果,选择结果为1的部分作为被采样的数据;采样后的长度为L,即:[64,2709,1]->[64,L,1];
采样后的数据集可以使用在任何表征模型上,以下分别以LSTM与Bert模型作为实施例进行说明。
表征模型为LSTM:
S3:将S2中得到的采样后的数据集送入表征模型中进行学习。具体如下:S3-1:输入为[64,L,1]经过嵌入层,维度转换为[64,L,1]->[64,L,512],其中512为模型隐藏层维度。
S3-2:序列依次输入LSTM单元,输入完毕后最后一个单元的隐藏状态作为序列表征,维度[64,512]。
S3-3:表征输入下游任务网络,该网络是一个全连接(MLP)层,输出各个类别的预测概率,维度[64,512]->[64,2]。
S4-1:和真实标签比较,计算交叉熵损失。
S4-2:使用Adam优化算法,对模型进行优化。
表征模型为Bert:
S3:将S2中得到的采样后的数据集送入表征模型中进行学习。具体如下:S3-1:输入为[64,L,1]经过嵌入层,维度转换为[64,L,1]->[64,L,512],其中512为模型隐藏层维度。
S3-2:在序列最前端加上CLS向量,维度[64,L,512]->[64,L+1,512]。
S3-3:依次经过8个Bert子模块,模块内部具体说明如下:
S3-3-1:经过Self-Attention层,维度[64,L,512]->[64,L,512]。
S3-3-2:经过Linear层,维度[64,L,512]->[64,L,512]。
S3-3-3:经过Layer-Norm层,维度[64,L,512]->[64,L,512]。
S3-4经过经过前向传播得到的CLS向量作为序列的表征;用随机Mask覆盖15%的序列,用学习到的表征预测被覆盖的部分的Embedding,和真实的Embedding计算MSE Loss作为自监督学习的Loss;
S3-5使用Adam优化算法,对模型进行优化。训练得到的CLS向量作为最终表征,维度[64,512]。
S4:将S3中得到的表征输入下游任务,训练下游任务模型。具体如下:
S4-1表征输入下游任务网络,该网络是一个MLP层,输出各个类别的预测概率,维度[64,512]->[64,2];
S4-2和真实标签比较,计算交叉熵损失;
S4-3使用Adam优化算法,对模型进行优化。得到下游任务模型。
本发明在淘宝商家用户行为序列数据集上进行了测试,用PyTorch作为网络模型构建工具,数据随机打乱后按批次大小依次输入模型内,基于本申请的方法依次进行TPD-LSTM模型的训练,预训练模型的训练,下游任务模型的训练。
通过以上设置及足够长时间的训练(直到模型在下游任务上的准确率不再大幅度变化),可以得到评估结果。
由于该下游任务数据集是一个类不均衡的数据集,我们主要关注其F1分数的提升。结果显示该方法在该数据集上达到了95.27%的准确率,F1score相较baseline提高了一个点,如表1所示。
表1在淘宝商家行为序列数据集上的结果对比