一种融合语料模糊匹配和术语精准提取的语言资产管理系统
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及一种融合语料模糊匹配和术语精准提取的语言资产管理系统,属于多语言翻译技术领域。
背景技术
语言资产是指语言服务供应商在进行翻译本地化项目的过程中日益积累的无形资产,包括风格指南、语料库、术语库等。随着语言服务行业技术的不断发展,计算机辅助翻译(Computer-aided Translation,CAT)工具(例如:Trados Studio、memoQ、Wordfast、Phrase、TWS、XTM等)被广泛地使用,产生了大量的语料和术语。语言资产管理系统能够有效地将这些语料和术语进行归类、整合与复用,不仅可以帮助译员提高翻译效率和准确度,还可以为客户节约成本,持续保证客户文件的一致性。
然而,随着经济全球化的不断深入,软件/网站本地化行业迅速发展,与此相呼应,CAT工具的使用也越来越普遍,但是由于不同CAT工具的开发者不同,因此导致文件数据存储格式千差万别,现有技术中,尚未查询到一种可支持多种行业主流CAT工具文件格式的,同时融合语料模糊匹配导出和术语精准匹配提取两项功能的语言资产管理系统。
发明内容
有鉴于此,本发明提供一种融合语料模糊匹配和术语精准提取的语言资产管理系统,其无需手动转换格式,自动导入和导出行业标准格式,实现语言资产的复用,进一步提高过往语言资产的利用率,帮助译员提高翻译效率和准确度,为客户节约成本并保证客户文件的一致性。
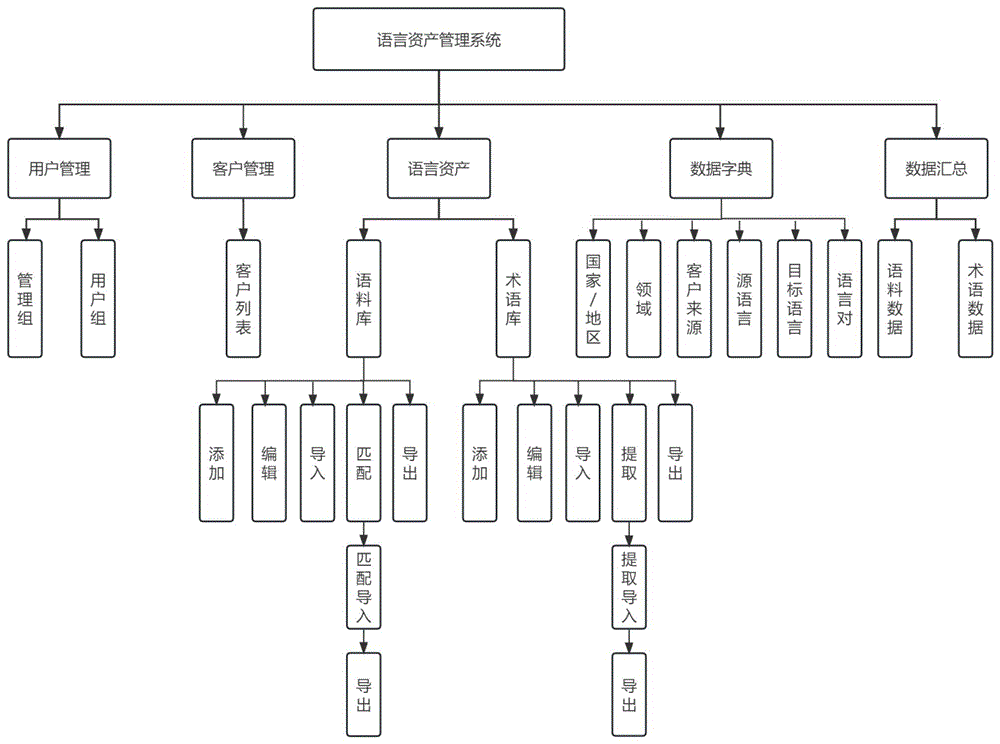
本发明提供一种融合语料模糊匹配和术语精准提取的语言资产管理系统,其包括用户管理模块、客户管理模块、语言资产模块、数据字典模块、数据汇总模块和系统执行模块,所述语言资产模块包括语料库模块和术语库模块;
语言资产管理系统采用RabbitMQ处理高并发场景,运用高并发缓存队列防止溢出,系统分批次执行导入。
优选的,所述语料库模块模糊匹配导出时使用余弦函数进行英文相似度的判断,将文本转换为向量表示,然后计算向量之间的余弦相似度,使用词袋模型来表示文本向量,使用CountVectorizer将文本转换为词袋模型的向量表示,然后使用cosine_similarity计算两个向量的余弦相似度,最后,打印出相似度的结果。
优选的,所述术语库模块通过调整相似度的得分阈值判断字符串的包含关系,根据相似度得分判断包含关系,从而进行术语精准匹配提取。
优选的,所述语料库模块使用向量空间中两向量夹角的余弦值作为衡量两个个体之间差异的大小。
优选的,所述余弦值越接近1,表明两个向量的夹角越接近0度,则两个向量越相似;余弦值越接近0,表明两个向量的夹角越接近180度,则两个向量越不相似。
优选的,所述语料库模块以翻译单元为单位,将相似度达到75%及以上的翻译单元排序并采用翻译记忆库通用的文件格式导出。
优选的,所述术语库模块通过calculateSimilarity()函数接受两个字符串作为参数,使用strpos()函数来判断字符串A是否包含于字符串B,如果包含,则返回相似度为100%;否则,返回相似度为0%。
优选的,如果相似度得分接近1,表示字符串A与字符串B非常相似,可以认为A包含于B;如果相似度得分接近0,表示字符串A与字符串B相似度很低,可以认为A不包含于B。
本发明的有益效果:
本发明提供一种融合语料模糊匹配和术语精准提取的语言资产管理系统,其可帮助客户实现全生命周期管理语言资产,提质增效降本,规避本地化语言风险,确保内容的准确、一致、规范和专业,高效利用反向语言对平行文本;借助庞大的专业术语库可提取更多带释义的高频词和术语,减少手动摘取时间,便于多人协同翻译时结合语境,确保术语译法一致。此外,语料库和术语库作为内部数据库集合,方便客户检索任何在网络查询不到的具体语境下的专业语料,节省查询时间。预计产生“帮助客户提高过往语料利用率,提质增效降本,提升语言资产赋能,打破企业语言资产孤岛”的经济效益以及“提高客户语言资产管理意识,提升社会语言资产管理水平,助推语言服务业专精发展”的社会效益。
附图说明
图1为本发明一种融合语料模糊匹配和术语精准提取的语言资产管理系统的组成结构示意图。
图2为本发明一种融合语料模糊匹配和术语精准提取的语言资产管理系统的语料库模块示意图。
图3为本发明一种融合语料模糊匹配和术语精准提取的语言资产管理系统的术语库模块示意图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
本发明提供一种融合语料模糊匹配和术语精准提取的语言资产管理系统,其包括用户管理模块、客户管理模块、语言资产模块、数据字典模块、数据汇总模块和系统执行模块,所述语言资产模块包括语料库模块和术语库模块;
语言资产管理系统采用RabbitMQ处理高并发场景,运用高并发缓存队列防止溢出,系统分批次执行导入。
语料库模块采用余弦相似度算法将某一专属语料库中的原文与待翻译文件中的原文进行相似度匹配,使用向量空间中两向量夹角的余弦值作为衡量两个个体之间差异的大小。余弦值越接近1,表明两个向量的夹角越接近0度,则两个向量越相似。余弦值越接近0,表明两个向量的夹角越接近180度,则两个向量越不相似,以翻译单元(TranslationUnit,TU)为单位,将相似度达到75%及以上的翻译单元排序并采用翻译记忆库(Translation Memory,TM)通用的文件格式.tmx格式或者Excel格式导出,导出的.tmx格式文件采用国际标准化模板,可兼容Trados Studio、memoQ、Wordfast、Phrase等多款CAT工具。
术语库模块通过字符串匹配方式实现术语之间的包含关系,通过calculateSimilarity()函数接受两个字符串作为参数,使用strpos()函数来判断字符串A是否包含于字符串B。如果包含,则返回相似度为100%;否则,返回相似度为0%
具体的,语料库模块通过创建专属语料库,形成某一具体领域和特定语言对的语料系统大库及其对应的反向语言对语料系统大库,构建语料查询体系,实现语料的快速检索,对待翻译文件与特定语料库进行模糊匹配,实现语料的复用;所述术语库模块,通过创建专属术语库,形成某一具体领域和特定语言对的术语系统大库及其对应的反向语言对术语系统大库,构建术语查询体系,实现术语的快速检索,对待翻译文件与特定术语库进行精准匹配提取,实现术语的有效整理和利用。
针对具体客户创建指定领域、语言对的语料库,并导入已有语料,形成一个专属语料库,其次,上传.mqxliff、.txlf、.mxliff或Excel格式的待翻译文件,通过使用支持XML解析的程序语言PHP进行解析,并使用xml.etree.ElementTree模块来对所述待翻译文件进行解析,最终获取
针对具体客户创建指定领域、语言对的术语库,并导入已有术语,形成一个专属术语库,其次,上传.mqxliff、.txlf、.mxliff或Excel格式的待翻译文件,通过字符串匹配方式实现术语之间的包含关系,获取相似度为100%的术语,实现术语的精准匹配,再次,系统完成匹配后,可将相似度为100%的术语以Excel文件或者兼容多种CAT工具的.tmx文件导出,最后,将导出的Excel文件格式术语针对不同CAT工具转换为相应的格式,实现术语利用;也可以将导出的.tmx文件格式术语做成离线翻译记忆库,供翻译过程中参考利用。
以上对本发明及其实施方式进行了描述,这种描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。总而言之,如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性地设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
- 一种基于多语言平行语料库的医学术语提取方法及系统
- 基于术语提取的跨语言信息匹配方法