一种基于视觉转换器的深度强化学习方法及装置
文献发布时间:2023-06-19 11:39:06
技术领域
本发明属于人工智能技术领域,具体而言,涉及一种基于视觉转换器的深度强化学习方法及装置。
背景技术
近年来,强化学习逐渐成为机器学习领域的研究热点。智能体通过在与环境的交互过程中学习策略来实现回报的最大化或实现某种目标。通过与深度学习方法的结合,深度强化学习方法在许多人工智能任务中取得了突破,例如博弈游戏、机器人控制、群体决策、自动驾驶等。
目前,深度强化学习方法主要包括基于值函数的方法、基于策略梯度的方法和基于Actor-Critic框架的方法。在现有的强化学习网络框架中,所采用的网络结构主要是卷积神经网络和长短时记忆网路。卷积神经网络侧重于局部观测信息的提取,全局观测信息的捕捉能力弱。长短时记忆网络处理序列数据更具有优势,可以学习并长期保存信息,但长短时记忆网络作为一种循环网络结构,无法进行并行训练。
转换器(Transformer)在自然语言处理任务中得到了广泛应用,转换器架构可以避免递归,实现并行计算,通过自注意力机制对输入输出的全局依赖关系进行建模。然而,转换器在强化学习领域中还没有相应的研究。因此,需要提供一种改进的基于视觉转换器的深度强化学习方法。
发明内容
本发明旨在至少解决现有技术中存在的技术问题之一,提供一种基于视觉转换器的深度强化学习方法及装置。
本发明的一个方面,提供一种基于视觉转换器的深度强化学习方法,所述方法包括:
构建基于视觉转换器的深度强化学习网络结构,其中,所述视觉转换器包括多层感知器和转换编码器,所述转换编码器包括多头注意力层和前馈网络;
初始化所述深度强化学习网络的权重,根据存储器的容量大小构建经验回放池;
通过贪婪策略与运行环境进行交互,产生经验数据并将其放入所述经验回放池;
当所述经验回放池中的样本数量满足预设的训练样本数量时,从所述经验回放池中随机抽取一批训练样本图像,对所述训练样本图像进行预处理;
将所述预处理后的训练样本图像输入所述深度强化学习网络进行训练;
在所述深度强化学习网络满足收敛条件时,获取强化学习模型。
在一些实施方式中,所述通过贪婪策略与运行环境进行交互,产生经验数据并将其放入所述经验回放池,包括:
通过ε-greedy策略与运行环境进行交互,获取经验数据(s,a,r,s′)并将其放入所述经验回放池,其中,s为当前时刻的观测量,a为当前时刻动作,r为环境返回的回报,s'为下一时刻的观测量。
在一些实施方式中,所述当所述经验回放池中的样本数量满足预设的训练样本数量时,从所述经验回放池中随机抽取一批训练样本图像,对所述训练样本图像进行预处理,包括:
当所述经验回放池中的样本数量满足预设的训练样本数量m时,从所述经验回放池中随机抽取数量为batch大小的训练样本图像,对尺寸大小为H*W的训练样本图像进行预处理,根据所述训练样本图像的大小将其分成N个色块,每个色块的尺寸大小为P*P,其中,H为所述训练样本图像的高度,W为所述训练样本图像的宽度,N=H*W/P
使用线性投影矩阵将输入的t-2时刻、t-1时刻、t时刻图像中的每个色块X进行平化,得到映射后的D维向量X
将状态动作价值占位符QvalueToken通过学习参数的方式与所述色块向量X
X
X
X
其中,MLP为多层感知器,X
在一些实施方式中,所述将所述预处理后的训练样本图像输入所述深度强化学习网络进行训练,包括:
依据均方误差损失函数L对所述深度强化学习网络进行训练,其中,L=E[r+γmax
其中,E为数学期望,a为当前时刻动作,a′为下一时刻动作,α为学习率,γ为折扣系数,Q(s,a;θ)为当前值神经网络的Q值,Q(s′,a′;θ
本发明的另一个方面,提供一种基于视觉转换器的深度强化学习装置,所述装置包括构建模块、数据采集模块、输入模块、训练模块和获取模块:
所述构建模块,用于构建基于视觉转换器的深度强化学习网络结构,其中,所述视觉转换器包括多层感知器和转换编码器,所述转换编码器包括多头注意力层和前馈网络,初始化所述深度强化学习网络的权重,根据存储器的容量大小构建经验回放池;
所述数据采集模块,用于通过贪婪策略与运行环境进行交互,产生经验数据并将其放入所述经验回放池;
所述输入模块,用于当所述经验回放池中的样本数量满足预设的训练样本数量时,从所述经验回放池中随机抽取一批训练样本图像,对所述训练样本图像进行预处理,并将所述预处理后的训练样本图像输入所述训练模块;
所述训练模块,用于利用所述预处理后的训练样本图像对所述深度强化学习网络进行训练;
所述获取模块,用于在所述深度强化学习网络满足收敛条件时,获取强化学习模型。
在一些实施方式中,所述数据采集模块具体用于:
通过ε-greedy策略与运行环境进行交互,获取经验数据(s,a,r,s′)并将其放入所述经验回放池,其中,s为当前时刻的观测量,a为当前时刻动作,r为环境返回的回报,s'为下一时刻的观测量。
在一些实施方式中,所述输入模块具体用于:
当所述经验回放池中的样本数量满足预设的训练样本数量m时,从所述经验回放池中随机抽取数量为batch大小的训练样本图像,对尺寸大小为H*W的训练样本图像进行预处理,根据所述训练样本图像的大小将其分成N个色块,每个色块的尺寸大小为P*P,其中,H为所述训练样本图像的高度,W为所述训练样本图像的宽度,N=H*W/P
使用线性投影矩阵将输入的t-2时刻、t-1时刻、t时刻图像中的每个色块X进行平化,得到映射后的D维向量X
将状态动作价值占位符QvalueToken通过学习参数的方式与所述色块向量X
X
X
X
其中,MLP为多层感知器,X
在一些实施方式中,所述训练模块具体用于:
依据均方误差损失函数L对所述深度强化学习网络进行训练,其中,L=E[r+γmax
其中,E为数学期望,a为当前时刻动作,a′为下一时刻动作,α为学习率,γ为折扣系数,Q(s,a;θ)为当前值神经网络的Q值,Q(s′,a′;θ
本发明的另一个方面,提供一种电子设备,所述电子设备包括:
一个或多个处理器;
存储单元,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行时,能使得所述一个或多个处理器实现前文记载的所述的方法。
本发明的另一个方面,提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时能实现根据前文记载的所述的方法。
本发明的基于视觉转换器的深度强化学习方法及装置,通过将视觉转换器引入深度强化学习网络,填补了视觉转换器在强化学习领域应用的空白,提高了强化学习方法的可解释性,能够更有效地进行学习训练,可应用于使用强化学习算法的场景,如游戏、机器人控制等。
附图说明
图1为本发明一实施例的电子设备的组成示意框图;
图2为本发明另一实施例的基于视觉转换器的深度强化学习方法的流程图;
图3为本发明另一实施例的基于视觉转换器的深度强化学习网络的结构示意图;
图4为本发明另一实施例的转换编码器的结构示意图;
图5为本发明另一实施例的基于视觉转换器的深度强化学习装置的结构示意图。
具体实施方式
为使本领域技术人员更好地理解本发明的技术方案,下面结合附图和具体实施方式对本发明作进一步详细描述。
首先,参照图1来描述用于实现本发明实施例的装置及方法的示例电子设备。
如图1所示,电子设备200包括一个或多个处理器210、一个或多个存储装置220、一个或多个输入装置230、一个或多个输出装置240等,这些组件通过总线系统250和/或其他形式的连接机构互连。应当注意,图1所示的电子设备的组件和结构只是示例性的,而非限制性的,根据需要,电子设备也可以具有其他组件和结构。
处理器210可以是由多(众)核架构的芯片组成的神经网络处理器,也可以是单独的中央处理单元(CPU),或者,也可以是中央处理单元+多核神经网络处理器阵列或者具有数据处理能力和/或指令执行能力的其他形式的处理单元,并且可以控制电子设备200中的其他组件以执行期望的功能。
存储装置220可以包括一个或多个计算机程序产品,所述计算机程序产品可以包括各种形式的计算机可读存储介质,例如易失性存储器和/或非易失性存储器。所述易失性存储器例如可以包括随机存取存储器(RAM)和/或高速缓冲存储器(cache)等。所述非易失性存储器例如可以包括只读存储器(ROM)、硬盘、闪存等。在所述计算机可读存储介质上可以存储一个或多个计算机程序指令,处理器可以运行所述程序指令,以实现下文所述的本发明实施例中(由处理器实现)的客户端功能以及/或者其他期望的功能。在所述计算机可读存储介质中还可以存储各种应用程序和各种数据,例如,所述应用程序使用和/或产生的各种数据等。
输入装置230可以是用户用来输入指令的装置,并且可以包括键盘、鼠标、麦克风和触摸屏等中的一个或多个。
输出装置240可以向外部(例如用户)输出各种信息(例如图像或声音),并且可以包括显示器、扬声器等中的一个或多个。
下面,将参考图2描述根据本发明一实施例的基于视觉转换器的深度强化学习方法。
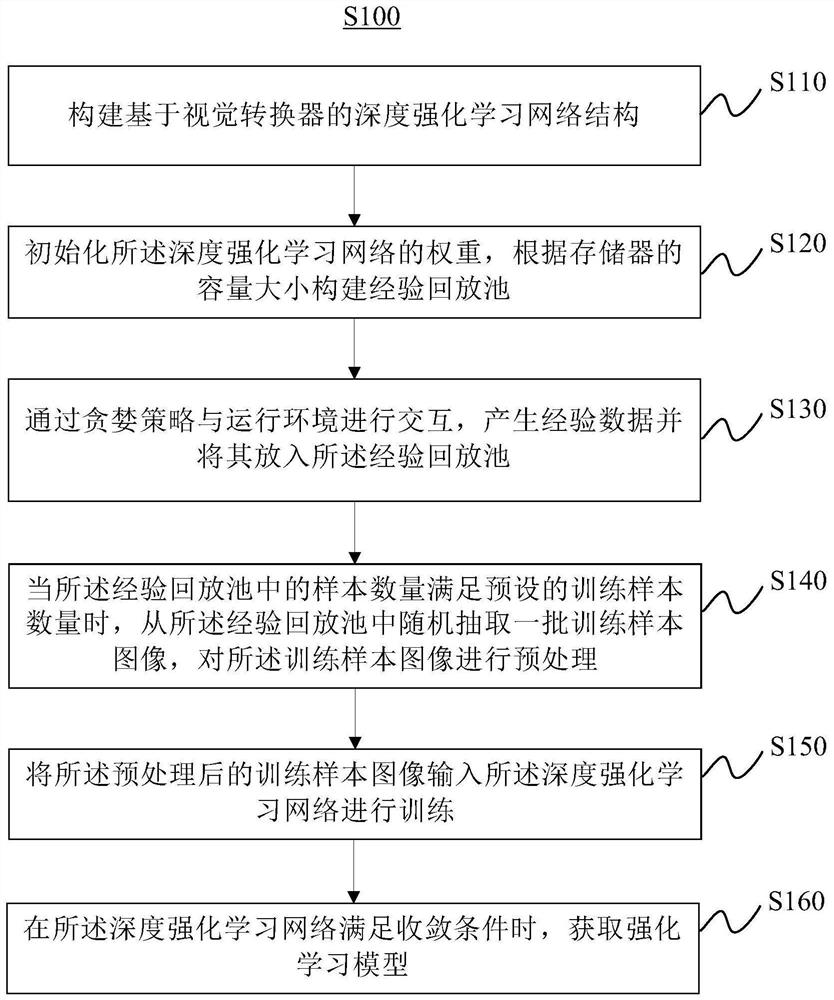
示例性的,如图2所示,本实施例提供一种基于视觉转换器的深度强化学习方法S100,方法S100包括:
S110、构建基于视觉转换器的深度强化学习网络结构,其中,所述视觉转换器包括多层感知器和转换编码器,所述转换编码器包括多头注意力层和前馈网络。
具体地,可以基于强化学习运行环境,定义状态空间、动作空间及奖励函数,构建基于视觉转换器的深度强化学习网络结构。其中,如图3所示,视觉转换器包括一个多层感知器和一个转换编码器。如图4所示,转换编码器包括多头注意力层和前馈网络。
S120、初始化所述深度强化学习网络的权重,根据存储器的容量大小构建经验回放池。
具体地,可以将深度强化学习网络的各个权重进行初始化,根据存储器的容量大小建立经验回放池。
S130、通过贪婪策略与运行环境进行交互,产生经验数据并将其放入所述经验回放池。
具体地,可以通过贪婪策略与强化学习运行环境进行交互,在交互过程中产生经验数据,并将该经验数据放入经验回放池。
S140、当所述经验回放池中的样本数量满足预设的训练样本数量时,从所述经验回放池中随机抽取一批训练样本图像,对所述训练样本图像进行预处理。
具体地,当经验回放池中的样本数量满足预设的训练样本数量时,可以从经验回放池中随机抽取一批训练样本图像,然后根据实际需要,对这些训练样本图像进行预处理。
需要说明的是,预设的训练样本数量可以是对深度强化学习网络进行一次训练所需的最小训练样本数量,也可以是根据实际需要设定的任一训练样本数量,本领域技术人员可以按需进行选择,本实施例对此并不限制。
S150、将所述预处理后的训练样本图像输入所述深度强化学习网络进行训练。
具体地,可以将预处理后的训练样本图像作为输入,对深度强化学习网络进行训练。
S160、在所述深度强化学习网络满足收敛条件时,获取强化学习模型。
具体地,在对深度强化学习网络进行训练的过程中,当深度强化学习网络满足收敛条件时,获取当前的强化学习模型,以作为最终的强化学习模型。
本实施例的基于视觉转换器的深度强化学习方法,通过将视觉转换器引入深度强化学习网络,填补了视觉转换器在强化学习领域应用的空白,提高了强化学习方法的可解释性,能够更有效地进行学习训练,可应用于使用强化学习算法的场景,如游戏、机器人控制等。
示例性的,所述通过贪婪策略与运行环境进行交互,产生经验数据并将其放入所述经验回放池,包括:
通过ε-greedy策略与运行环境进行交互,在进行交互时,输出动作会以ε的概率从所有动作中随机抽取一个动作,以1-ε的概率抽取价值最大的动作,获取经验数据(s,a,r,s′)并将其放入经验回放池,其中,s为当前时刻的观测量,a为当前时刻动作,r为环境返回的回报,s'为下一时刻的观测量。
示例性的,所述当所述经验回放池中的样本数量满足预设的训练样本数量时,从所述经验回放池中随机抽取一批训练样本图像,对所述训练样本图像进行预处理,包括:
当经验回放池中的样本数量满足预设的训练样本数量m时,从经验回放池中随机抽取数量为batch大小的训练样本图像,对尺寸大小为H*W的训练样本图像进行预处理。根据训练样本图像的大小将其分成N个色块,每个色块的尺寸大小为P*P,其中,H为训练样本图像的高度,W为训练样本图像的宽度,N=H*W/P
使用线性投影矩阵将输入的t-2时刻、t-1时刻、t时刻图像中的每个色块X进行平化,得到映射后的D维向量X
将状态动作价值占位符QvalueToken通过学习参数的方式与色块向量X
X
X
X
其中,MLP为多层感知器,X
本实施例的基于视觉转换器的深度强化学习方法,通过视觉转换器的注意力机制,能够进一步提高强化学习方法的可解释性,并在提取局部观测信息的同时,进一步学习有用的全局观测信息,从而更好地捕捉全局信息。另外,本实施例通过利用视觉转换器的时序编码,使得深度强化学习网络可以利用过去时刻的观测信息,从而能够更有效地进行学习训练。
示例性的,所述将所述预处理后的训练样本图像输入所述深度强化学习网络进行训练,包括:
依据均方误差损失函数L对深度强化学习网络进行训练,其中,L=E[r+γmax
其中,E为数学期望,a为当前时刻动作,a′为下一时刻动作,α为学习率,γ为折扣系数,Q(s,a;θ)为当前值神经网络的Q值,Q(s′,a′;θ
本实施例的基于视觉转换器的深度强化学习方法,可以通过并行的方式对深度强化学习网络进行训练,从而加快深度强化学习网络的收敛速度。
本发明的另一个方面,提供一种基于视觉转换器的深度强化学习装置。
示例性的,如图5所示,本实施例提供一种基于视觉转换器的深度强化学习装置100,装置100包括构建模块110、数据采集模块120、输入模块130、训练模块140和获取模块150。该装置100可以应用于前文记载的方法,下述装置中未提及的具体内容可以参考前文相关记载,在此不作赘述。
构建模块110用于构建基于视觉转换器的深度强化学习网络结构,定义状态空间、动作空间及奖励函数,其中,所述视觉转换器包括多层感知器和转换编码器,所述转换编码器包括多头注意力层和前馈网络,初始化所述深度强化学习网络的权重,根据存储器的容量大小构建经验回放池;
数据采集模块120用于通过贪婪策略与运行环境进行交互,产生经验数据并将其放入所述经验回放池;
输入模块130用于当所述经验回放池中的样本数量满足预设的训练样本数量时,从所述经验回放池中随机抽取一批训练样本图像,对所述训练样本图像进行预处理,并将所述预处理后的训练样本图像输入所述训练模块140;
训练模块140用于利用所述预处理后的训练样本图像对所述深度强化学习网络进行训练;
获取模块150用于在所述深度强化学习网络满足收敛条件时,获取强化学习模型。
本实施例的基于视觉转换器的深度强化学习装置,通过将视觉转换器引入深度强化学习网络,填补了视觉转换器在强化学习领域应用的空白,提高了强化学习方法的可解释性,能够更有效地进行学习训练,可应用于使用强化学习算法的场景,如游戏、机器人控制等。
示例性的,数据采集模块120具体用于:
通过ε-greedy策略与运行环境进行交互,获取经验数据(s,a,r,s′)并将其放入所述经验回放池,其中,s为当前时刻的观测量,a为当前时刻动作,r为环境返回的回报,s'为下一时刻的观测量。
示例性的,输入模块130具体用于:
当所述经验回放池中的样本数量满足预设的训练样本数量m时,从所述经验回放池中随机抽取数量为batch大小的训练样本图像,对尺寸大小为H*W的训练样本图像进行预处理,根据所述训练样本图像的大小将其分成N个色块,每个色块的尺寸大小为P*P,其中,H为所述训练样本图像的高度,W为所述训练样本图像的宽度,N=H*W/P
使用线性投影矩阵将输入的t-2时刻、t-1时刻、t时刻图像中的每个色块X进行平化,得到映射后的D维向量X
将状态动作价值占位符QvalueToken通过学习参数的方式与所述色块向量X
X
X
X
其中,MLP为多层感知器,X
本实施例的基于视觉转换器的深度强化学习装置,通过视觉转换器的注意力机制,能够进一步提高强化学习方法的可解释性,并在提取局部观测信息的同时,进一步学习有用的全局观测信息,从而更好地捕捉全局信息。另外,本实施例通过利用视觉转换器的时序编码,使得深度强化学习网络可以利用过去时刻的观测信息,从而能够更有效地进行学习训练。
示例性的,训练模块140具体用于:
依据均方误差损失函数L对所述深度强化学习网络进行训练,其中,L=E[r+γmax
其中,E为数学期望,a为当前时刻动作,a′为下一时刻动作,α为学习率,γ为折扣系数,Q(s,a;θ)为当前值神经网络的Q值,Q(s′,a′;θ
本实施例的基于视觉转换器的深度强化学习装置,可以通过并行的方式对深度强化学习网络进行训练,从而加快深度强化学习网络的收敛速度。
本发明的另一个方面,提供一种电子设备,包括:
一个或多个处理器;
存储单元,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行时,能使得所述一个或多个处理器实现根据前文记载的所述的方法。
本发明的另一个方面,提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时能实现根据前文记载的所述的方法。
其中,计算机可读存储介质可以是本发明的装置、设备中所包含的,也可以是单独存在。
其中,计算机可读存储介质可以是任何包含或存储程序的有形介质,其可以是电、磁、光、电磁、红外线、半导体的系统、装置、设备,更具体的例子包括但不限于:具有一个或多个导线的相连、便携式计算机磁盘、硬盘、光纤、随机访问存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、便携式紧凑磁盘只读存储器(CD-ROM)、光存储器件、磁存储器件,或它们任意合适的组合。
其中,计算机可读存储介质也可以包括在基带中或作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码,其具体的例子包括但不限于电磁信号、光信号,或它们任意合适的组合。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 一种基于视觉转换器的深度强化学习方法及装置
- 深度强化学习指导下基于连续移动的视觉跟踪方法及装置