一种统一数据访问模型的实现方法
文献发布时间:2023-06-19 18:27:32
技术领域
本发明涉及计算机技术领域,更具体地说,本发明涉及一种统一数据访问模型的实现方法。
背景技术
大数据类应用通常需要涉及多源数据存储,关系型数据库、文件数据、文档数据库、图数据库、键值(Key-Value)数据库、列簇数据库、时序数据库等,另外还可能需要访问消息队列、程序集合类对象等。
结构化查询语言(Structured Query Language,简称SQL)是操作关系型数据库的标准语言,它使用相同的结构化查询语言作为数据输入与管理的接口,无需关心不同数据源的底层结构。SQL在实践中被广泛使用,但非关系型数据存储通常不支持SQL。
对象关系映射框架(Object Relational Mapping,简称ORM)描述对象和关系型数据库之间映射的元数据,主要实现程序对象到关系数据库数据的映射,解决关系型数据库的统一访问问题,但不支持非关系型数据库的访问。
专利号为CN111143449A的专利文献公开了统一模型的数据服务方法,主要解决领域业务融合的解决方案,并没有解决不同数据存储统一访问实现。专利号为CN104142980A的专利文献公开了抽取关系型数据和NoSQL(泛指非关系型数据库)的元数据的流程,并把元数据统一存储为JSON(JavaScript Object Notation,JavaScript对象表示法)格式。但并没有从数据访问维度进行抽象,也没有基于抽象模型提供统一数据访问实现机制。
发明内容
为了克服现有技术的上述缺陷,本发明的实施例提供一种统一数据访问模型的实现方法,通过采用分层架构实现不同数据存储统一访问,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
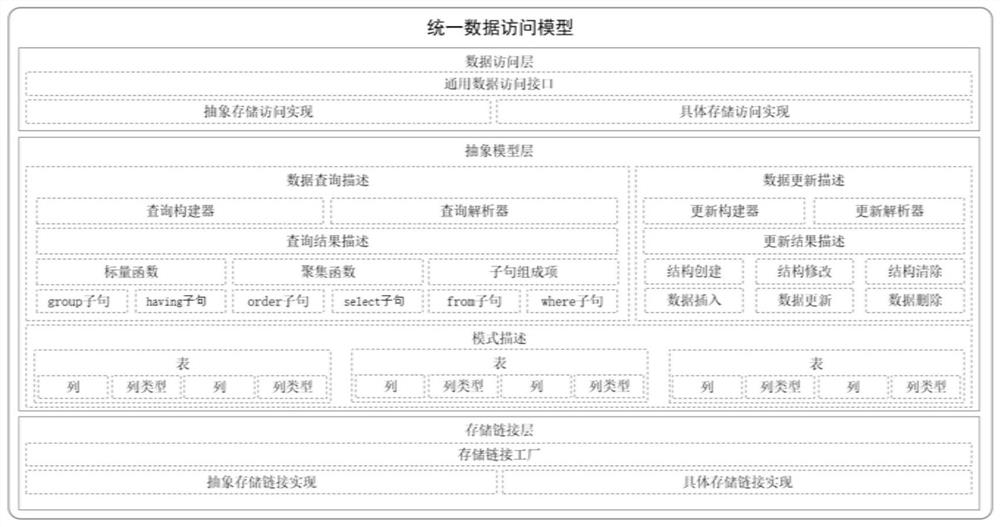
一种统一数据访问模型的实现方法,所述统一数据访问模型采用分层架构,依次包括:数据访问层、抽象模型层与存储链接层;
所述数据访问层,用于提供数据上下文,实现统一的数据访问,并提供抽象实现和具体存储扩展实现的数据访问方式;
所述抽象模型层,用于描述数据存储模式、数据查询及数据更新,提供统一的元数据模型;
所述存储链接层,用于抽象多元数据存储,提供多元异构数据存储的统一连接访问,屏蔽了底层数据存储的差异;
包括如下步骤:
步骤S1、数据访问层为上层应用提供统一数据访问接口接收不同类型的数据,并将其发送至抽象模型层;
步骤S2、抽象模型层对数据访问层接收的数据进行查询与更新,并将其发送至存储链接层;
步骤S3、存储链接层将从抽象模型层处接收的数据进行存储保存。
在一个优选的实施方式中,所述数据访问层包括抽象存储访问单元和具体存储访问单元;
所述抽象存储访问单元,用于实现基础公共方法与开关作用;
所述具体存储访问单元,用于实现与存储相关的功能。
在一个优选的实施方式中,所述数据上下文包括标准上下文与扩展上下文;
所述标准上下文,用于实现关系型数据库的访问;
所述扩展上下文,用于实现非关系型数据的标准SQL访问。
在一个优选的实施方式中,所述抽象模型层包括数据查询描述单元与数据更新描述单元;
所述数据查询描述单元,用于表示返回数据结果的查询描述;
所述数据更新描述单元,用于定义数据、存储结构以及更新结果的描述。
在一个优选的实施方式中,所述数据查询描述单元包括:查询构建器、查询解析器以及查询结果描述单元;
所述查询构建器,用于实现一组链接构建器,包括初始构建器、select构建器、from构建器、where构建器、group构建器、having构建器,并生成表构建器,进而获得数据查询对象;
所述查询解析器,用于实现查询构建器的逆过程,解析数据访问层传入的SQL查询语句,由解析器构成,
所述解析器包括:select项解析器、from项解析器、where项解析器、group项解析器、having项解析器以及order项解析器;
所述查询结果描述单元,用于描述行、列二维表数据集;包括行信息、文档信息、描述行或文档的头信息以及数据集相关的行为。
在一个优选的实施方式中,所述数据更新描述单元包括更新构建器与更新解析器;
所述更新构建器,用于对于数据和结构实现不同,包括插入、修改、删除行更新构建器;
所述更新解析器,用于实现更新构建器的逆过程,解析数据访问层传入的SQL更新语句,更新构建器对应。
在一个优选的实施方式中,所述存储链接层包括存储链接工厂,通过存储链接工厂适配不同数据存储的连接;
所述存储链接工厂包括抽象存储链接实现和具体存储链接实现,
所述抽象存储链接实现,用于校验连接属性的类型;
所述具体存储链接实现,用于根据数据存储分为文件链接工厂、关系型数据库链接工厂、非关系型数据库链接工厂。
本发明的技术效果和优点:
本发明一种统一数据访问模型的实现方法,通过统一数据访问模型,泛化SQL理念,抽象实现以统一标准SQL方式访问多元数据存储;解决了不同数据存储访问的复杂适配问题,降低访问数据存储的难度,提升程序编码工作效率。
附图说明
图1为本发明一种统一数据访问模型的实现方法结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
本发明一种统一数据访问模型的实现方法,其采用分层架构实现,如图1所示,底层为存储链接层,中间层为抽象模型层,上层为数据访问层。
存储链接层用于抽象多元数据存储,提供一致的存储链接工厂接口及抽象实现,屏蔽了底层数据存储的差异;
抽象模型层主要用于描述数据存储模式、数据查询及数据更新,提供统一的元数据模型。
数据访问层用于提供数据上下文,实现统一的数据访问,并提供抽象实现和具体存储扩展实现的数据访问方式。数据上下文表示与数据存储交互的中心入口,包括数据结构和数据交互的描述。数据上下文分为标准上下文和扩展上下文,实现统一标准SQL方式访问。
具体的,所述存储链接层提供了多元异构数据存储的统一连接访问,其包括存储链接工厂,通过存储链接工厂适配不同数据存储的连接。
所述存储链接工厂接收数据存储的连接属性和资源工厂创建存储数据上下文实例。
数据存储的连接属性提供数据存储的连接信息,包括数据存储的网络地址、访问存储方式、访问驱动、字符集等信息。
资源工厂使用简单工厂模式创建数据存储的资源,根据特定类型的数据存储,实现相应的文件资源工厂、网络资源工厂、内存资源工厂。
所述存储链接工厂包括抽象存储链接实现和具体存储链接实现。其中,抽象存储链接实现用于校验连接属性的类型,具体存储链接实现用于根据数据存储分为文件链接工厂、关系型数据库链接工厂、非关系型数据库链接工厂等。
例如,所述存储链接工厂以CSV文件为例。CSV文件链接工厂通过连接属性获取文件存储位置、文件字符集、分隔符、文件最大行数等信息。通过文件资源工厂创建CSV文件资源,基于CSV文件资源创建出CSV文件数据上下文。
关系型数据库链接工厂根据连接属性提供的数据库访问地址、用户名、密码、数据库驱动等信息,创建数据库的连接,并通过连接生成数据库的数据上下文。
非关系型链接工厂以HBASE为例,HBASE链接工厂通过连接属性获取zookeeper配置、连接超时等信息,并封装成HBASE的连接适配器,基于适配器生成HBASE访问的数据上下文。
对于支持模式的关系型数据库返回相应的模式信息,对于不支持模式的关系型或非关系型数据存储,根据配置信息返回默认的模式。
所述抽象模型层包括数据查询描述单元、数据更新描述单元以及模式描述单元;由于不是所有关系型数据库都支持模式(Schema),如PostgreSQL支持,MySQL不支持,大多数NoSQL数据库也不支持。因此,本发明统一数据访问模型以模式组织数据,对于不支持的数据存储,提供默认模式。
即所述模式描述单元包括多个表(table),表包括多个列、表与表关系集合以及索引信息。关系与索引不支持非关系型数据。
列(column)隶属于表,用于描述列元数据并作为表关系的键。列元数据包括名称、别名、列抽象类型、类本地类型(数据存储对应类型)、是否为空、长度、精度、是否为索引、是否为主键等。
列抽象类型按分类定义通用类型,用于转换上层语言对应数据类型,同时能够对应底层数据存储数据类型。包括字符串类型集、数值类型集、时间类型集、布尔类型集、二进制类型集、其他类型集(包括数组类型、IP地址类型、JSON数据类型等一些数据存储支持的特定数据类型)。
对于模式、表、列,还定义了命名规则及构建策略,支持不同数据存储的命名规范。
所述数据更新描述单元用于定义数据、存储结构以及更新结果的描述,以及更新构建器和解析器。
其针对数据的更新包括数据插入(insert)、数据更新(update)、数据删除(delete)。数据插入定义往表中插入行数据描述,数据更新定义更新行数据以及更新条件,数据删除定义删除行数据以及删除条件。
针对存储结构的更新包括结构创建(create)、结构修改(modify)、结构清除(drop)。结构创建定义创建表结构描述、结构修改定义修改表结构描述、结构清除定义清除表结构描述。
每个数据更新、结构更新都提供生成SQL方法(toSQL),实现日志记录和程序调试。
更新构建器对于数据和结构实现不同。数据更新主要实现基于行数据更新构建器,包括插入、修改、删除行更新构建器。结构创建实现列构建器和创建表构建器,结构修改实现增加列、重命名列以及修改表构建器,结构清除实现删除表构建器。
更新解析器实现更新构建器的逆过程,解析数据访问层传入的SQL更新语句,由一组解析器构成,与上述构建器对应。
针对数据更新结果定义了返回插入行数量、更新行数量、删除行数量以及生成键集合。
所述数据查询描述单元用于表示返回数据结果的查询描述,由对应SQL标准的六个子句、分页信息,查询结果数据集描述以及查询构建器、解析器。
select子句定义结果数据集想要返回的列,支持是否对数据结果去重设置。select子句包括几种形式:列、函数列(标量函数、聚合函数)、表达式以及子查询。表达式主要支持关系型数据库常用表达式,提供自定义转换函数和聚合函数增强查询能力。
from子句定义从哪里获取数据。包括查询from项,from项包括别名以及生成对应引用,使得select子句中的select项通过引用前缀进行区别表示。查询from项包括几种形式:表、关联表(通过on子句和关联类型描述)、子查询。
where子句定义对获取数据的过滤条件。where子句由过滤项组成,过滤项描述逻辑操作及组合过滤条件。
group子句定义数据分组实现,由分组项组成,分组项引用select项集。
having子句定义对分组后数据集的过滤条件。与where子句一致,由过滤项描述逻辑操作及组合过滤条件。
order子句结果集的排序信息。由order项组成,order项定义查询结果的排序字段和方向。
分页信息包括偏移量和页大小。
每个子句都提供生成SQL方法(toSQL),数据查询调用子句toSQL方法产生完整SQL查询语句,实现日志记录和程序调试。
另外针对常用的查询方法提供了默认实现。如:查询所有(selectAll),查询数量(selectCount)等。
查询构建器实现一组链接构建器,包括初始构建器、select构建器(包括列和函数构建器)、from构建器、where构建器、group构建器、having构建器,通过上述构建器生成表构建器,进而获得数据查询对象。
查询解析器实现查询构建器的逆过程,解析数据访问层传入的SQL查询语句,由一组解析器构成。包括select项解析器、from项解析器、where项解析器、group项解析器、having项解析器以及order项解析器。
查询结果描述单元用于描述行、列二维表数据集。包括行信息、文档信息、描述行或文档的头信息等。同时包括数据集相关的行为,下一行、迭代行、所有行、取某列、所有列等方法。
所述数据访问层用于为上层应用提供了统一数据访问接口。接口接收标准SQL语言,通过构建器与解析器适配不同数据存储的访问操作,屏蔽了不同数据存储的访问的差异。
统一数据访问接口提供抽象存储访问单元和具体存储访问单元。
抽象存储访问单元实现了一些公共方法,如获取模式列表、根据名称获取列、创建查询构建器、更新构建器等;由于不同数据存储支持的更新操作不同,抽象存储访问还提供了更新功能的开关,如创建索引开关、修改表结构开关、删除表开关、修改数据内容开关等方法。
具体数据存储访问单元实现与存储相关的功能,主要包括文件存储访问、关系型数据库访问、非关系型数据访问和程序集合类对象访问等。
关系型数据库通过标准上下文进行访问,对于非关系型数据存储,通过扩展上下文实现标准SQL的访问。
扩展上下文通过查询解析器解析6个子语句:select、from、where、group、having、order,创建查询所需的所有字段项列表,物化处理from子句查询的表,通过内存操作取出所有查询字段项目的数据,再根据分组、聚合、过滤、排序、分页等操作,返回查询结果数据集。
实施例2
上述实施例1主要介绍了本发明整体统一数据访问模型的架构,下面从三类典型的具体存储实现来说明,文件存储访问以CSV文件为例,非关系型存储以HBASE为例。
CSV文件通过数据访问层中扩展上下文访问,包括处理查询参数、执行查询操作、返回查询结果数据集。当创建CSV文件数据上下文后,会将文件中的数据加载到内存中。CSV文件访问操作支持分页、分组、聚合、连接、过滤等查询条件。
CSV文件数据更新支持创建CSV文件、插入数据、删除数据和修改数据。执行插入操作通过行插入构建器实现,首先获取CSV文件写入器,并将待插入数据构建成CSV文件行数据,然后在尾部插入数据。其他更新操作实现流程类似,不再重复说明。
关系型数据库支持SQL语言的查询和更新操作。接收SQL字符串通过解析器生成SQL语言,或基于构建器构建SQL语言。依据不同数据库类型生成相应的执行SQL语句。如MySQL和Oracle分页语法不同,需要重写分页参数。
非关系型数据库以HBASE为例说明,HBASE的查询操作通过扩展上下文实现分页、分组、聚合、过滤等操作。HBASE更新操作支持创建表、删除表、插入数据和删除数据;HBASE不支持修改数据,通过设置修改数据开关,禁用数据修改功能。其他非关系型数据对于不支持的数据更新方法,也是通过功能开关进行控制。
最后应说明的几点是:首先,本申请各实施例中的装置及终端中的模块和单元可以根据实际需要进行合并、划分和删减。
本申请所提供的几个实施例中,应该理解到,所揭露的终端,装置和方法,可以通过其他的方式实现。例如,以上所描述的终端实施例仅仅是示意性的,例如,模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或模块可以结合或者可以集成到另一个模块,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或模块的间接耦合或通信连接,可以是电性,机械或其他的形式。
作为分离部件说明的模块或单元可以是或者也可以不是物理上分开的,作为模块或单元的部件可以是或者也可以不是物理模块或单元,即可以位于一个地方,或者也可以分布到多个网络模块或单元上。可以根据实际的需要选择其中的部分或者全部模块或单元来实现本实施例方案的目的。
另外,在本申请各个实施例中的各功能模块或单元可以集成在一个处理模块中,也可以是各个模块或单元单独物理存在,也可以两个或两个以上模块或单元集成在一个模块中。上述集成的模块或单元既可以采用硬件的形式实现,也可以采用软件功能模块或单元的形式实现。
其次:本发明公开实施例附图中,只涉及到与本公开实施例涉及到的结构,其他结构可参考通常设计,在不冲突情况下,本发明同一实施例及不同实施例可以相互组合;
最后:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 通过Fitler模型及注解扩展实现ECP平台数据访问的查询方法
- 一种基于UQPSK统一信号模型下的测控通信实现方法