情感分析模型训练方法、情感分析方法、设备及存储介质
文献发布时间:2023-06-19 18:37:28
技术领域
本申请涉及自然语言处理技术领域,特别是情感分析模型训练方法、情感分析方法、设备及存储介质。
背景技术
目前,常见的用于情感分析的模型往往只能对文本的词性进行分析,对于文本是情感极性是积极、消极还是中性,需要依赖人工定义的规则来确定。但这种依赖规则确定情感极性的方式需要设计大量的规则来覆盖所有情况,非常耗时。
发明内容
本申请提供一种情感分析模型训练方法、情感分析方法、设备及存储介质,通过依赖关系预测和掩码词预测同时进行的方式去训练第一情感分析模型,使第一情感分析模型达到领域不变性表示学习的目的。
为了解决上述技术问题,本申请采用的一个技术方案是:提供一种情感分析模型训练方法,该方法包括:获取用于情感分析的第一标注文本;对第一标注文本进行词性分析,得到名词集合;以及对第一标注文本进行情感词分析,得到情感词集合;基于名词集合和情感词集合,对第一标注文本进行掩码处理,得到目标文本序列;利用第一情感分析模型对目标文本序列进行依赖关系预测和掩码词预测,得到预测掩码词和预测依赖关系;利用真实掩码词和预测掩码词、真实依赖关系和预测依赖关系对第一情感分析模型进行网络参数调整,以使第一情感分析模型达到领域不变性表示学习的目的。
其中,基于名词集合和情感词集合,对第一标注文本进行掩码处理,得到目标文本序列,包括:获取相关词集合,其中相关词集合由名词集合和情感词集合组成;按照预设比例从相关词集合中确定目标掩码词,对第一标注文本中的目标掩码词进行掩码处理,得到目标文本序列。
其中,目标文本序列包含掩码词组和非掩码词组。
其中,利用第一情感分析模型对目标文本序列进行依赖关系预测和掩码词预测,得到预测掩码词和预测依赖关系,包括:利用第一情感分析模型对目标文本序列进行上下文转换,得到目标文本序列对应的隐藏状态;对隐藏状态进行掩码词预测,得到预测掩码词;按照预设比例从目标文本序列中选择至少两个相邻的非掩码词组;利用第一情感分析模型对至少两个相邻的非掩码词组进行依赖关系预测,得到相邻非掩码词组之间的预测依赖关系。
其中,按照预设比例从目标文本序列中选择至少两个相邻的非掩码词组,包括:获取与目标文本序列对应的解析依赖树,其中解析依赖树上的节点由掩码词组和非掩码词组构成;按照预设比例从解析依赖树中选择至少两个相邻的非掩码词组。
其中,利用真实掩码词和预测掩码词、真实依赖关系和预测依赖关系对情感分析模型进行网络参数调整,以使第一情感分析模型达到领域不变性表示学习的目的之后,包括:利用第一情感分析模型的网络参数初始化第二情感分析模型;利用第一标注文本对第二情感分析模型进行训练;利用训练后的第二情感分析模型对待标注文本进行预测,得到情感预测结果,其中待标注文本和第一标注文本为不同领域文本;利用情感预测结果对待标注文本进行标注,得到第二标注文本;利用第一标注文本和第二标注文本对第二情感分析模型进行训练。
其中,利用第一标注文本和第二标注文本对第二情感分析模型进行训练,包括:利用第一标注文本对第二情感分析模型进行训练,并调整第二情感分析模型的网络参数;利用第二标注文本对第二情感分析模型进行训练,并调整第二情感分析模型的网络参数。
其中,利用第一标注文本和第二标注文本对第二情感分析模型进行训练之前,包括:对第二标注文本进行过滤;利用第一标注文本和第二标注文本对第二情感分析模型进行训练,包括:利用第一标注文本和过滤后的第二标注文本对第二情感分析模型进行训练。
为了解决上述技术问题,本申请采用的另一技术方案是:提供一种情感分析方法,该方法包括:获取评论文本;将评论文本输入至情感分析模型,得到评论文本对应的情感结果。其中,情感分析模型是采用上述的情感分析模型训练方法训练得到。
为了解决上述技术问题,本申请采用的另一技术方案是:提供一种电子设备,该电子设备包括存储器和处理器,其中,存储器用于存储计算机程序,处理器用于执行计算机程序以实现上述的情感分析模型训练方法或情感分析方法。
为了解决上述技术问题,本申请采用的另一技术方案是:提供一种计算机可读储存介质,该计算机可读储存介质用于存储计算机程序,计算机程序在被处理器执行时用于实现上述的情感分析模型训练方法或情感分析方法。
本申请的有益效果是:区别于现有技术,本申请提供的情感分析模型训练方法通过对用于情感分析的第一标注文本分别进行词性分析和情感词分析,得到名词集合和情感词集合,进而,基于名词集合和情感词集合,对第一标注文本进行掩码处理,得到目标文本序列,再利用第一情感分析模型对目标文本序列进行依赖关系预测和掩码词预测,得到预测掩码词和预测依赖关系,最后,利用真实掩码词和预测掩码词、真实依赖关系和预测依赖关系对第一情感分析模型进行网络参数调整,即通过对文本进行词性分析和情感词分析弱化文本对应的领域信息,进而采用依赖关系预测和掩码词预测同时进行的方式,使第一情感分析模型达到领域不变性表示学习的目的。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。其中:
图1是本申请提供的情感分析模型训练方法第一实施例的流程示意图;
图2是本申请提供的步骤15一实施例的流程示意图;
图3是本申请提供的解析依赖语法树一实施例的示意图;
图4是本申请提供的情感分析模型训练方法第二实施例的流程示意图;
图5是本申请提供的情感分析模型训练方法第三实施例的流程示意图;
图6是本申请提供的情感分析方法第一实施例的流程示意图;
图7是本申请提供的电子设备一实施例的结构示意图;
图8是本申请提供的计算机可读储存介质一实施例的结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请的一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
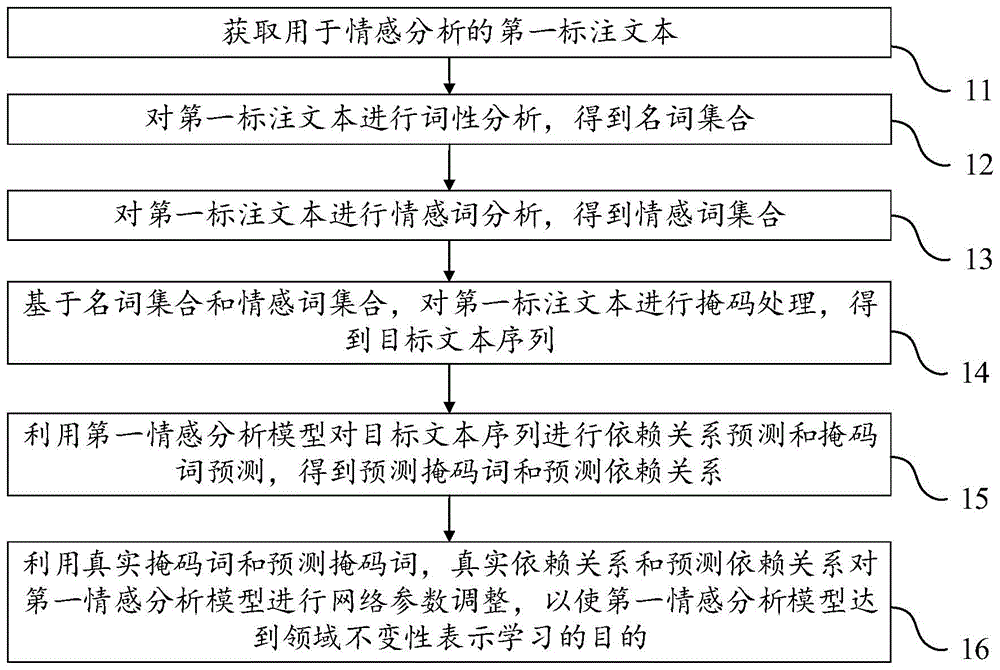
参阅图1,图1是本申请提供的情感分析模型训练方法第一实施例的流程示意图,该方法包括:
步骤11:获取用于情感分析的第一标注文本。
第一标注文本是某一个领域的文本,如餐饮业的评论文本、电器商品的评论文本,且第一标注文本具备与情感相关的标注,这些标注又称为情感极性,情感极性在本申请中表示用户的情感类别,即积极、消极或中性。如“××电脑笔记本竟然没有摄像头,真是让人无语”,该文本对应的标注(即情感极性)是消极;又如,“北京烤鸭很好吃”,该文本对应的标注(即情感极性)是积极。
在一些实施例中,第一标注文本需要包含方面词,在本申请中,方面词特指评论文本中的商品、属性等名词,如北京烤鸭、价格、屏幕。
在一些实施例中,对文本进行标注可以使用联合标注模式对文本中每个词都赋予一个标签。联合标注模式为BIO(B-begin,I-inside,O-outside)标注,即“{B-POS,I-POS,B-NEG,I-NEG,B-NUE,I-NEU,O}”,其中,B指的是名词的开始位置,I指的是名词的中间位置,O指不是名词的位置,POS为position(积极),NEU为neutral(中性),NEG为negative(消极)。联合标注模式可以从待标注文本中抽取方面词,并预测对应方面词的情感极性,如,待标注文本“北京烤鸭很好吃”对应的BIO标注序列(第一标注文本)为“北/B-POS,京/I-POS,烤/I-POS,鸭/I-POS,很/O,好/O,吃/O”,抽取方面词“北京烤鸭”,可知“北京烤鸭”的情感是积极的,文本“北京烤鸭很好吃”的标注是“积极”。
可以理解地,用于情感分析的文本在字数和结构上没有具体要求,但是需要具备相应能表达情感的描述,即需要具备能进行情感极性分析的词组等。
在一些实施例中,从文本中抽取方面词并预测方面词的情感又称为细粒度情感分析,如,文本是“北京烤鸭很好吃,但是价格贵的难以接受”,进行细粒度情感分析可以先抽取方面词“北京烤鸭”和“价格”,接着分别预测其情感,可知“北京烤鸭”对应的情感是积极,而“价格”对应的情感是消极。
步骤12:对第一标注文本进行词性分析,得到名词集合。
具体地,可以利用词性工具对第一标注文本进行词性分析,以得到名词集合。词性工具指的是可以对文本中的字段进行词性分析的工具,如SpaCy工具、TextBlob。
其中,SpaCy工具是一种自然语言处理工具,可以用来对文本进行断词、词干化、标注词性、命名实体识别、名词短语提取、基于词向量计算词间相似度等处理;TextBlob是一种开源的文本处理库,可以用来执行词性标注、名词性成分提取、情感分析、文本翻译等自然语言处理的任务。
词性是一种词的语法分类,如动词、名词、形容词;词性分析指的是以字段为划分依据,对文本中不同的字段进行词性确定,得到文本对应的词性序列。
如,对文本“北京烤鸭很好吃”进行词性分析,可以将其划分成“北京、烤鸭、很、好吃”,对应的词性序列为“NR、NN、AD、VA”,其中,NR指专有名词(如城市名、国家名称),NN指除专有名词之外的其他名词,AD指副词(如情态副词、频率副词、连接副词),VA指谓词性形容词。
获取词性序列之后,可以将词性是名词的字段进行提取,以得到名词集合,且名词集合包含的字段是方面词。
步骤13:对第一标注文本进行情感词分析,得到情感词集合。
具体地,可以利用情感词典或情感资源等情感词分析工具对第一标注文本进行情感词分析,以得到情感词集合。情感词分析工具指的是可以对文本中的情感词进行识别的工具,如SenticNet、SentiWordNet、General Inquirer、HowNet。
情感词指的是能表达用户情感的字段,如好吃、难看。
另外,步骤12和步骤13可以不区分先后顺序。
步骤14:基于名词集合和情感词集合,对第一标注文本进行掩码处理,得到目标文本序列。
在一些实施例中,可以通过获取由名词集合和情感词集合组成的相关词集合,再按照预设比例从相关词集合中确定目标掩码词,对第一标注文本中的目标掩码词进行掩码处理,得到目标文本序列。其中,掩码指屏蔽第一标注文本中部分字段,且可以用[MASK]表示被屏蔽的字段,即可以用[MASK]表示掩码词。其中,预设比例可以为20%、30%、40%或50%。按照预设比例从相关词集合中确定目标掩码词,可以使得第一情感分析模型更好进行领域不变性学习。
如,第一标注文本是“北京烤鸭很好吃,但是价格贵的难以接受”,相关词集合是{北京烤鸭,好吃,价格,难以,接受},目标掩码词是{好吃,价格,接受},对第一标注文本中的目标掩码词进行掩码处理,得到的目标文本序列是“北京烤鸭很[MASK],但是[MASK]贵的难以[MASK]”。
在一些实施例中,可以在进行细粒度情感分析任务时,由方面词抽取子任务和方面词情感分类子任务组成相关词集合。相关词集合可以由文本中能够成为潜在方面词的名词和具有情感极性的形容词组成。
步骤15:利用第一情感分析模型对目标文本序列进行依赖关系预测和掩码词预测,得到预测掩码词和预测依赖关系。
其中,第一情感分析模型是一种基于Transformer架构的模型,如BERT模型、T5模型、XLNet模型,这里不做限制。
在一些实施例中,目标文本序列按照上述方式进行掩码处理得到,则目标文本序列包含掩码词组和非掩码词组,参阅图2,步骤15可以包括以下流程:
步骤21:利用第一情感分析模型对目标文本序列进行上下文转换,得到目标文本序列对应的隐藏状态。
在一些实施例中,第一情感分析模型中的编码器可以对目标文本序列进行处理,以得到与目标文本序列对应的隐藏状态。
具体地,第一情感分析模型是BERT模型,目标文本序列是X={x1,x2,…,xn},BERT模型的编码器可以利用嵌入映射函数(即Embedding函数)对目标文本序列进行处理,得到Emb(X)={e1,e2,…,en},接着利用上下文转换函数(即Enc函数)做进一步处理,得到目标文本序列的隐藏状态,即Enc(Emb(X))={h1,h2,…,hn}。
步骤22:对隐藏状态进行掩码词预测,得到预测掩码词。
在一些实施例中,可以预测隐藏状态与相应的掩码词的概率,得到该隐藏状态对应每一掩码词的概率,将概率最大值对应的掩码词作为所述隐藏状态对应的掩码词。
如,掩码词是“北京烤鸭”,则可以预测P(北京烤鸭|h3),即预测隐藏状态h3是北京烤鸭的概率,或预测P(北京烤鸭|h4),即预测隐藏状态h4是北京烤鸭的概率,在进行多次预测之后,可以确定最大概率值所对应的隐藏状态对应该掩码词。如,在P(北京烤鸭|h4)=0.89和P(北京烤鸭|h3)=0.11之间,可以确定隐藏状态h4对应的掩码词是北京烤鸭。
步骤23:按照预设比例从目标文本序列中选择至少两个相邻的非掩码词组。
在一些实施例中,可以通过获取与目标文本序列对应的解析依赖树,其中解析依赖树上的节点由掩码词组和非掩码词组构成,进而,按照预设比例从解析依赖树中选择至少两个相邻的非掩码词组。其中,预设比例可以为20%、30%、40%或50%。
其中,解析依赖树包含若干个节点,这些节点由掩码词组和非掩码词组构成。
步骤24:利用第一情感分析模型对至少两个相邻的非掩码词组进行依赖关系预测,得到相邻非掩码词组之间的预测依赖关系。
在一些实施例中,依赖关系指的是评论文本经过依存句法分析工具处理后,依存句法树上任意两个词组之间的依赖关系。其中,依存句法分析工具可以是DDParser(BaiduDependency Parser)、LTP(Language Technology Platform)等,这里不作限制。依存句法树可以是解析依赖树。
另外,解析依赖树除了可以将目标文本序列以节点的形式进行展示之外,还可以将节点与节点之间的依赖关系进行展示,可以将节点的词性进行展示。解析依赖树不仅可以预测任意两个相邻的非掩码词组之间的依赖关系,还可以预测掩码词组与相邻的非掩码词组之间的依赖关系。
参阅图3,目标文本序列是“北京[MASK]很好吃,但是价格贵的难以接受”,掩码词组用[MASK]表示,非掩码词组有{“北京”,“很”,“好吃”,“,”,“但是”,“价格”,“贵”,“的”,“难以”,“接受”}。在图3中,节点中括号里的内容即为节点的词性,节点与节点之间连接处的内容即为节点与节点之间的依赖关系。如北京的词性是“NR”,[MASK]的词性是“NN”,北京和[MASK]之间的依赖关系是“nmod”,nmod(modifier of nominal)表示名词性修饰语。
常见的依赖关系还有nsubj(nominal subject,名词主语)、conj(conjunct,连接两个并列的词)、punct(punctuation,标点符号)、advmod(adverbial modifier,状语)、dep(dependent,依赖关系)等,这里不再详述。
值得注意的是,所谓的相邻并不一定指的是在目标文本序列上是相邻的字段,但是在解析依赖树上一定是处于相邻的两个字段。如,选择词组“价格”,寻找依赖关系只能确定另一个词组是“接受”,而不能是“贵”“的”等词组。
另外,在获取相邻非掩码词组之间的预测依赖关系之后,可以获取相应的概率值,如预测“接受”和“价格”之间的依赖关系是nsubj的概率,即P(“接受”&“价格”|nsubj)。若确定“接受”和“价格”之间的真实依赖关系是“nusbj”,此时可以调整相应参数,以使P(“接受”&“价格”|nsubj)的值最大。
步骤16:利用真实掩码词和预测掩码词,真实依赖关系和预测依赖关系对第一情感分析模型进行网络参数调整,以使第一情感分析模型达到领域不变性表示学习的目的。
可以理解地,可以基于第一标注文本确定真实掩码词和真实依赖关系。
在一些实施例中,可以基于真实掩码词和预测掩码词,获取第一损失值,还可以基于真实依赖关系和预测依赖关系,获取第二损失值,基于第一损失值和第二损失值,可以确定总的损失值。其中,总的损失值=第一损失值+第二损失值。
在一些实施例中,总的损失值是L=1/n*Σ
区别于现有技术,本申请提供的情感分析模型训练方法通过对用于情感分析的第一标注文本分别进行词性分析和情感词分析,得到名词集合和情感词集合,进而,基于名词集合和情感词集合,对第一标注文本进行掩码处理,得到目标文本序列,再利用第一情感分析模型对目标文本序列进行依赖关系预测和掩码词预测,得到预测掩码词和预测依赖关系,最后,利用真实掩码词和预测掩码词、真实依赖关系和预测依赖关系对第一情感分析模型进行网络参数调整,即通过对文本进行词性分析和情感词分析弱化文本对应的领域信息,进而采用依赖关系预测和掩码词预测同时进行的方式,使第一情感分析模型达到领域不变性表示学习的目的。
参阅图4,图4是本申请提供的情感分析模型训练方法第二实施例的流程示意图,该方法包括:
步骤401:获取用于情感分析的第一标注文本。
步骤402:对第一标注文本进行词性分析,得到名词集合。
步骤403:对第一标注文本进行情感词分析,得到情感词集合。
步骤402和步骤403可以不区分先后顺序。
步骤404:基于名词集合和情感词集合,对第一标注文本进行掩码处理,得到目标文本序列。
步骤405:利用第一情感分析模型对目标文本序列进行依赖关系预测和掩码词预测,得到预测掩码词和预测依赖关系。
步骤406:利用真实掩码词和预测掩码词、真实依赖关系和预测依赖关系对第一情感分析模型进行网络参数调整,以使第一情感分析模型达到领域不变性表示学习的目的。
步骤401至步骤406可以与上述任一实施例具备相同或相似的技术特征,这里不再赘述。
步骤407:利用第一情感分析模型的网络参数初始化第二情感分析模型。
在一些实施例中,对第一情感分析模型进行领域不变性学习之后,可以获得一个能产生领域不变性表示的第一情感分析模型,则可以利用这个第一情感分析模型对其余情感分析模型进行训练。
具体地,利用第一情感分析模型的网络参数对第二情感分析模型进行初始化处理,以训练第二情感分析模型中的编码器。
其中,第二情感分析模型可以在模型结构和参数等内容上,与完成领域不变性学习之后的第一情感分析模型相同,即第二情感分析模型可以根据第一情感分析模型的网络参数进行初始化。
步骤408:利用第一标注文本对第二情感分析模型进行训练。
可以理解地,第二情感分析模型的网络参数与第一情感分析模型相同,也就意味着,第二情感分析模型与第一情感分析模型相比,同样具备领域不变性学习的功能。
为了进一步训练第二情感分析模型中的编码器和分类器等,需要再次利用第一标注文本,以减少利用第一标注文本训练第二情感分析模型产生的损失值。
步骤409:利用训练后的第二情感分析模型对待标注文本进行预测,得到情感预测结果;其中,待标注文本和第一标注文本为不同领域文本。
利用第一标注文本对第一情感分析模型,经过上述流程步骤,可以实现第一情感分析模型的领域不变性学习,接着利用第一情感分析模型的网络参数初始化第二情感分析模型,以实现第二情感分析模型同样具备领域不变性学习的功能,利用第一标注文本对第二情感分析模型进行训练之后,为了防止第一标注文本主导第二情感分析模型的网络参数更新,需要进一步对第二情感分析模型进行训练,即利用训练后的第二情感分析模型对与第一标注文本为不同领域文本的待标注文本进行预测,并利用预测结果对待标注文本标注的方式,形成新的训练样本,在利用新的训练样本对第二情感分析模型进行训练,使得第二情感分析模型能够防止源领域标注数据(即第一标注文本)主导参数更新。第二情感分析模型对不同领域的文本进行预测,可以实现跨领域分析的目的,且可以避免模型被某一领域的文本影响,以提高模型的预测性能。
步骤410:利用情感预测结果对待标注文本进行标注,得到第二标注文本。
情感预测结果包括积极、消极和中性。
通过第二情感分析模型对待标注文本进行预测,得到对应的情感预测结果,此时可以根据情感预测结果对待标注文本打上相应标签,以得到第二标注文本。
步骤411:利用第一标注文本和第二标注文本对第二情感分析模型进行训练。
可以理解地,为了避免某一个领域的文本主导第二情感分析模型的网络参数更新,可以使用不同领域的文本对第二情感模型进行训练。
在一些实施例中,可以先利用第一标注文本对第二情感分析模型进行训练,并调整第二情感分析模型的网络参数,再利用第二标注文本对第二情感分析模型进行训练,并调整第二情感分析模型的网络参数。
具体地,对于不同领域的第一标注文本和第二标注文本,可以先使用第一标注文本对第二情感分析模型进行训练,实现第二情感分析模型的领域不变性学习,接着利用第二标注文本对第二情感分析模型进行训练,实现跨领域学习。
在一些实施例中,可以对第一标注文本和第二标注文本随机排序,再利用随机排序后的第一标注文本和第二标注文本对第二情感分析模型进行训练,并调整第二情感分析模型的网络参数。
具体地,对于不同领域的第一标注文本和第二标注文本,可以不区分第一标注文本和第二标注文本的先后顺序,利用随机排序后的第一标注文本和第二标注文本对第二情感分析模型进行训练。此时,第一标注文本和第二标注文本的顺序排列包括“第一标注文本先第二标注文本后”和“第二标注文本先第一标注文本后”两种情况。
区别于现有技术,本申请提供的情感分析模型训练方法可以实现第一情感分析模型达到领域不变性表示学习的目的,且利用完成领域不变性学习的第一情感分析模型的网络参数初始化第二情感分析模型,接着对第二情感分析模型进行跨领域训练,得到一个具备领域不变性学习和可跨领域进行情感分析的第二情感分析模型。
另外,同时从语义和语法的角度出发,设计语义辅助任务(即掩码词预测)和语法辅助任务(即依赖关系预测)进行领域不变性学习,可以同时利用语义辅助任务和语法辅助任务优化情感分析模型中的编码器,弱化文本的领域信息对情感分析模型的主导,使情感分析模型可以进行领域不变性学习。
参阅图5,图5是本申请提供的情感分析模型训练方法第三实施例的流程示意图,该方法包括:
步骤501:获取用于情感分析的第一标注文本。
步骤502:对第一标注文本进行词性分析,得到名词集合。
步骤503:对第一标注文本进行情感词分析,得到情感词集合。
步骤502和步骤503可以不区分先后顺序。
步骤504:基于名词集合和情感词集合,对第一标注文本进行掩码处理,得到目标文本序列。
步骤505:利用第一情感分析模型对目标文本序列进行依赖关系预测和掩码词预测,得到预测掩码词和预测依赖关系。
步骤506:利用真实掩码词和预测掩码词、真实依赖关系和预测依赖关系对第一情感分析模型进行网络参数调整,以使第一情感分析模型达到领域不变性表示学习的目的。
步骤507:利用第一情感分析模型的网络参数初始化第二情感分析模型。
步骤508:利用第一标注文本对第二情感分析模型进行训练。
步骤509:利用训练后的第二情感分析模型对待标注文本进行预测,得到情感预测结果;其中,待标注文本和第一标注文本为不同领域文本。
步骤510:利用情感预测结果对待标注文本进行标注,得到第二标注文本。
步骤501至步骤510可以与上述任一实施例具备相同或相似的技术特征,这里不再赘述。
步骤511:对第二标注文本进行过滤。
在一些实施例中,为了减少第二标注文本的噪声对第二情感分析模型的影响,需要对第二标注文本进行过滤,以将低质量的数据过滤掉。
具体地,利用信息熵对第二标注文本中包含噪声的数据进行过滤,相应公式为
在一些实施例中,可以基于预测的第二标注文本的可信度,过滤低质量的第二标注数据。
步骤512:利用第一标注文本和过滤后的第二标注文本对第二情感分析模型进行训练。
为了进一步提高第二情感分析模型的预测性能,可以再次利用第一标注文本和过滤后的第二标注文本对第二情感分析模型进行训练。
区别于现有技术,本申请提供的情感分析模型训练方法可以实现第一情感分析模型达到领域不变性表示学习的目的,且利用完成领域不变性学习的第一情感分析模型的网络参数初始化第二情感分析模型,接着对用于训练的数据进行优化,以利用优化后的数据对第二情感分析模型进行跨领域训练,得到一个预测性能更好、且具备领域不变性学习和可跨领域进行情感分析的第二情感分析模型,提高第二情感分析模型的预测性能。
另外,在进行跨领域的细粒度情感分析时,使用源领域标注数据(即第一标注文本)和目标领域伪标注数据(即第二标注文本)一起训练第二情感分析模型中的编码器和分类器等,可以防止源领域标注数据(即第一标注文本)主导第二情感分析模型的参数更新。
经过上述任一实施例描述的情感分析模型训练方法获得的情感分析模型,可以用于对文本进行情感分析,参阅图6,图6是本申请提供的情感分析方法第一实施例的流程示意图,该方法包括:
步骤61:获取评论文本。
在一些实施例中,用户情感分析的文本是评论文本,如餐饮店的就餐评价、电器产品的产品评价。
步骤62:将评论文本输入至情感分析模型,得到评论文本对应的情感结果。
其中,情感分析模型是采用上述任一实施例的情感分析模型训练方法训练得到。
在一些实施例中,响应于用户在目标产品/商品的显示界面上的输入指令,调用与所述输入指令对应的评价文本,利用情感分析模型对评价文本进行情感分析,确定用户对目标产品/商品的评价是积极、消极还是中性。
在一些实施例中,可以利用argmax函数对评论文本进行情感预测,以得到与评论文本对应的情感结果。
在确定目标产品/商品的情感结果之后,可以生成相应的提示信息,以提示目标产品/商品的提供者对目标产品/商品进行改进等。
区别于现有技术,本申请提供的情感分析方法可以利用情感分析模型对评价文本进行情感分析,以得到对应的情感结果,且可以再情感结果是消极的时候,生成相应的警示信息以提示目标产品/商品的提供者对目标产品/商品进行改进。
参阅图7,图7是本申请提供的电子设备一实施例的结构示意图,该电子设备70包括存储器701和处理器702,存储器701用于存储计算机程序,处理器702用于执行计算机程序以实现如上述任一实施例的情感分析模型训练方法或情感分析方法,这里不再赘述。
参阅图8,图8是本申请提供的计算机可读储存介质一实施例的结构示意图,该计算机可读储存介质80用于存储计算机程序801,计算机程序801在被处理器执行时用于实现上述任一实施例的情感分析模型训练方法或情感分析方法,这里不再赘述。
综上所述,本申请提供的情感分析模型训练方法可以实现同时从依赖关系预测和掩码词预测出发,设计相应的依赖关系预测和掩码词预测,以利用真实掩码词和预测掩码词、真实依赖关系和预测依赖关系对情感分析模型进行网络参数调整,以使情感分析模型达到领域不变性表示学习的目的;还可以利用不同领域的文本训练情感分析模型,使得情感分析模型可以避免单一领域文本主导模型参数更新等问题,可以提高情感分析模型的预测性能。
本申请涉及的处理器可以称为CPU(Central Processing Unit,中央处理单元),可能是一种集成电路芯片,还可以是通用处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。
本申请使用的存储介质包括U盘、移动硬盘、只读存储器(ROM,Read-OnlyMemory)、随机存取存储器(RAM,Random Access Memory)或者光盘等各种可以存储程序代码的介质。
以上所述仅为本申请的实施方式,并非因此限制本申请的专利范围,凡是利用本申请说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本申请的专利保护范围内。