一种供水管网独立计量分区系统及方法
文献发布时间:2023-06-19 19:33:46
技术领域
本发明属于水务数据管理技术领域,特别是涉及一种供水管网独立计量分区系统及方法。
背景技术
水表对用水数量的统计方式可以简单分为分区计量和独立计量。前者将整个用水区域的水量进行合并统计,只需要处理一个或少数几个表端上传的数据即可。后者是将每个用水户的水量进行单独统计,面对一个区域内数量极其众多的表端需要逐个统计,尤其是一线城市的表端数量轻松过千万。
物联网水表采集的用水量数据会以数据包的形式发送传递至管理端,为了提高通讯效率避免丢包,数据包中并非是完整记录每个用水量和以及对应的采集时刻,这就需要对新接收的数据包进行解析并结合以往的数据包历史记录或对应表端的用水量历史记录进行分析运算。
在对独立计量的众多表端发送的数据包进行接收和解析的过程中需要消耗大量的算力并且大幅度增加数据库的吞吐压力,很可能会导致管理端的硬件设备宕机。
在公开号为CN111566620A的专利中公开了一种用于提供基于位置的服务的分布式处理系统以及用于定制如有待车辆车载提供的基于位置的服务等服务的系统、方法和计算机程序产品。所述分布式处理系统包含多个计算装置,所述多个计算装置包含至少一个边缘装置和至少一个云计算装置。每个计算装置包含核心组件和一个或多个服务。所述服务可以被配置为流水线或微服务。每个计算装置的所述核心组件被配置成与相应计算装置的所述一个或多个服务并且与其它计算装置中的至少一个计算装置的所述核心组件进行通信,以便共享如具有无冲突复制数据类型的数据等数据并同步所述核心组件。该方案依靠部署大量分布式的计算装置实现数据包的安全稳定传输和解析,但是需要对整个水务数据统计管理系统进行全面升级,成本较高。
发明内容
本发明的目的在于提供一种供水管网独立计量分区系统及方法,通过对表端的用水量历史记录进行分析获取表端发送水务数据包的时间概率并据此对众多表端进行虚拟分区,从而对管理端进行存储资源和算力调度,提高了管理端服务响应的可靠性。
为解决上述技术问题,本发明是通过以下技术方案实现的:
本发明提供一种供水管网独立计量分区方法,包括,
获取每个表端的地理位置以及用水量关于时间的对应关系;
根据每个表端的用水量关于时间的对应关系提取每个表端的用水量周期特征;
根据每个表端的地理位置以及每个表端的用水量周期特征获取若干个位置团组,其中,同一个所述位置团组内的所述表端之间的用水量周期特征差异在设定范围内;
获取每个所述位置团组内所述表端的用水量代表周期特征;
根据每个所述位置团组内所述表端的用水量代表周期特征进行用水量关于时间的对应关系的历史记录的预加载以及管理端的算力资源准备;
接收所述表端发送的水务数据包;
根据预加载的所述表端的用水量关于时间的对应关系的历史记录和所述水务数据包在准备的算力资源下解析得到所述水务数据包记录的所述表端的用水量关于时间的对应关系;
将解析得到的所述表端的用水量关于时间的对应关系写入数据库。
本发明还公开了一种供水管网独立计量分区系统,包括,
表端,用于根据采集的用户的用水量生成水务数据包,其中所述水务数据包的解析复杂性与对应的用水量正相关;
将所述水务数据包对外发送;
管理端,包括数据库、负载均衡单元、网络收发单元以及解析计算单元;其中,
所述数据库用于存储所述表端采集的用水量关于时间的对应关系的历史记录;
所述负载均衡单元用于获取每个表端的地理位置以及用水量关于时间的对应关系;
根据每个表端的用水量关于时间的对应关系提取每个表端的用水量周期特征;
根据每个表端的地理位置以及每个表端的用水量周期特征获取若干个位置团组,其中,同一个所述位置团组内的所述表端之间的用水量周期特征差异在设定范围内;
获取每个所述位置团组内所述表端的用水量代表周期特征;
根据每个所述位置团组内所述表端的用水量代表周期特征进行用水量关于时间的对应关系的历史记录的预加载以及管理端的算力资源准备;
所述网络收发单元用于接收所述表端发送的水务数据包;
所述解析计算单元用于根据预加载的所述表端的用水量关于时间的对应关系的历史记录和所述水务数据包在准备的算力资源下解析得到所述水务数据包记录的所述表端的用水量关于时间的对应关系;
将解析得到的所述表端的用水量关于时间的对应关系写入数据库。
本发明通过对每个表端的用水量关于时间的历史数据进行分析得到表端的用水特性,也就是用水量周期特征,之后再依据用水量周期特征将用水特性相近的表端分类到同一个位置团组内。对于同一个位置团组内的表端可以视为具有相同的用水量周期特征,因此只需要结合位置团组内的表端数量和用水量代表周期特征即可实现对该位置团组用水量预测。之后只需要依据不同位置团组的用水量比例即可实现对管理端预加载空间以及算力资源的分配,再据此解析计算水务数据包得到每个表端的用水量关于时间的对应关系。在此过程中针对每个表端的用水特性进行预加载空间和算力资源的预先分配,有效避免大量水务数据包同时上传至管理端导致的宕机。
当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
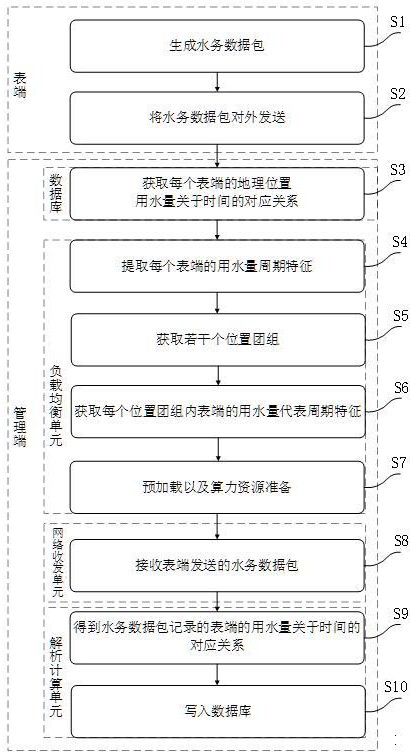
图1为本发明所述一种供水管网独立计量分区方法的流程示意图;
图2为本发明所述一种供水管网独立计量分区系统的功能模块及信息流向示意图;
图3为本发明中表端在一年内采集到用水量关于时间的对应关系的散点示意图;
图4为本发明中表端在一周内用水量日占比及变化系数示意图;
图5为本发明中表端在一天内用水量占比及时变化系数示意图;
图6为本发明所述步骤S5的流程示意图;
图7为本发明所述步骤S51的流程示意图;
图8为本发明所述步骤S511的流程示意图;
图9为本发明所述步骤S54的流程示意图;
图10为本发明所述步骤S6的流程示意图;
图11为本发明所述步骤S7的流程示意图;
图12为本发明所述步骤S72的流程示意图;
附图中,各标号所代表的部件列表如下:
1-管理端,11-数据库,12-负载均衡单元,13-网络收发单元,14-解析计算单元;
2-表端。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
由于水务物联网的性能较弱,为了确保数据传输稳定可靠通常表端发送的水务数据包具有较为复杂的数据纠错校验机制,需要先对其进行解算之后才能得到表端新收集到的用水量数据,而且为了节省电量,物联网表端通常被设计为水流量每达到一吨发送一次水务数据包。但是由于表端的数量实在是过于巨大,例如在上海市民用、商用、政府以及工业用途的表端超过一千万个,当数量庞大的水务数据包同时涌入管理端的时候,如果没有事先的水务数据包解算准备,很有可能导致管理端宕机。为了有效避免此种情况,本发明提供以下方案。
请参阅图1和2所示,本发明提供了一种供水管网独立计量分区系统,从功能模块上划分可以拆分为数据库、负载均衡单元、网络收发单元以及解析计算单元。数据库通常是关系型数据库,例如MySQL或者Oracle,将每个表端收集到的水量关于时间的对应关系存储在一张数据表内,在对网络收发单元新接收的水务数据包进行解析之前需要在数据库中调取对应表端的数据表。换言之,在对水务数据包进行解析之前需要在解析计算单元内准备好用于加载的缓存空间和用于计算的算力。本系统经过初始化调试之后其硬件资源完全可以满足水务数据包的解析计算需要,但是由于内存和计算线程调度问题很可能会导致解析计算出现阻塞,为了避免此种情况,需要结合每个表端的用水量周期特征实现对表端上传的水务数据包的解析计算准备。
从整体上来说,本系统与表端通过网络连接,表端在执行步骤S1根据采集的用户的用水量生成水务数据包之后执行步骤S2将水务数据包对外发送。需要着重说明的是,由于水务数据包内包含用水量关于时间的对应关系,水务数据包内对应的用水量越多,解析出来的用水量关于时间的对应关系也就越复杂,因此水务数据包的解析复杂性与对应的用水量正相关。
接下来我们来讨论管理端在应用过程中的运行逻辑。从功能上划分,管理端可以划分为数据库、负载均衡单元、网络收发单元以及解析计算单元。数据库用来存储水量关于时间的对应关系,网络收发单元用来进行网络通讯,解析计算单元用来解析计算水务数据包,而负载均衡单元是本方案的重点,用来进行内存和计算线程的准备。
在对负载均衡单元的运行逻辑进行深入探讨之前,需要对表端采集的用水量关于时间的关系进行分析,也就是如何对表端的用水量的周期特征进行提取。本方案采用的是根据水量关于时间的对应关系的历史记录获取对应表端的周期特征。本方案中的周期特征可以是一年内的用水量特性,也可以是分月、分周以及每天的分时特性。
在现实生活中,用水量和气温、日照时间以及节假日制度密切相关,而这些又是以年为周期,也就是说满一年的水务数据包历史记录具有充分的代表性,能够有效避免后续提取的表端的用水量的周期特征的准确性,具体而言,首先获取每个表端用水量在过去的一年期间内每个工作日和休息日的用水量以及用水量的分布比例作为表端的用水量的周期特征。接下来获取每个表端用水量在过去的一年期间的每个工作日和休息日的分时用水量以及每个小时用水量的分布比例作为表端的用水量的周期特征。由于大部分的表端是居民和消费商业用水表端,因此在其每天的用水量以及当天的分时用水量和当天是工作日还是休息日息息相关,因此需要分别按照工作日和休息日分别提取表端的用水量的周期特征,并且提取对应的分时周期特征。具体的表端的用水量的周期特征提取可以参加如图3至5。
请参阅图3所示,在对某一企业在近一年时间内的用水量,之后在图4中显示将工作日和节假日进行分类周期特征提取,在图5中显示出某一天内表端的分时用水量周期特征提取。
接下来继续探讨管理端的运行流程,由于表端的数量众多,如果让负载均衡单元针对每一个具体的表端进行水量预判可能会导致计算量过于巨大,反而更容易导致管理端宕机,因此本方案将用水量周期特征相同或相近的表端划入同一个位置团组内,以方便后续的计算。在具体的实施过程中,首先可以执行步骤S3负载均衡单元用于获取每个表端的地理位置以及用水量关于时间的对应关系。接下来可以执行步骤S4根据每个表端的用水量关于时间的对应关系提取每个表端的用水量周期特征。接下来可以执行步骤S5根据每个表端的地理位置以及每个表端的用水量周期特征获取若干个位置团组,需要说明的是,同一个位置团组内的表端之间的用水量周期特征差异在设定范围内。
由于每个位置团组内含有数量极多的表端,不能按照每个表端的用水量周期特征进行后续的处理运算,因此接下来可以执行步骤S6获取每个位置团组内表端的用水量代表周期特征。最后可以执行步骤S7根据每个位置团组内表端的用水量代表周期特征进行用水量关于时间的对应关系的历史记录的预加载以及管理端的算力资源准备。从而实现对管理端内存和算力的预先分配,避免后续的解析运算过程中由于性能发挥不充分导致的宕机。
在完成管理端的内存和算力分配之后,网络收发单元用于执行步骤S8接收表端发送的水务数据包并缓存在管理端的内存中,以便于后续的解析运算。之后解析计算单元用于执行步骤S9根据预加载的表端的用水量关于时间的对应关系的历史记录和水务数据包在准备的算力资源下解析得到水务数据包记录的表端的用水量关于时间的对应关系。最后可以执行步骤S10将解析得到的表端的用水量关于时间的对应关系写入数据库,完成对表端采集水量和采集时间的完整准确记录。
请参阅图6所示,饶是如此,如果采用传统的聚类算法寻找用水量周期特征相同或相近的表端依旧工作量繁重,这就需要我们根据生活常识得到一个日常规律,那就是距离相近的用户,他们的用水习惯具有相似性,例如处于同一片商业区的商户,他们开业关门的时间相仿,所以用水习惯相似,基于此特性可以辅助快速得到准确的位置团组。在具体执行的过程中,首先可以执行步骤S51根据每个表端的地理位置对全部表端进行预分类得到若干个位置初始团组。接下来可以执行步骤S52根据每个位置初始团组内表端的用水量周期特征得到初始团组内每个表端在指定周期内的总用水量和用水量的方差值,当然也可以使用均方差值,指定周期可以是一年或一周,当然也可以是一天。接下来可以执行步骤S53在每个位置初始团组内根据每个表端在指定周期内的总用水量和方差值对表端进行量化标记,得到表端的二维量化标记结果。接下来可以执行步骤S54在位置初始团组内根据每个表端的二维量化标记结果以及用水量周期特征差异的设定范围筛选出异常的表端。最后可以执行步骤S55将异常的表端转移至符合用水量周期特征差异的设定范围的位置初始团组内,得到若干个位置团组。通过将表端的用水量周期特征转化为二维量化标记结果,从而实现对表端的用水量周期特征的聚类分析,能够准确实现对位置团组的分类。
请参阅图7所示,由于步骤S5中并非是步骤完整的聚类分析方式,为了提高位置团组的分类速度,本方案预先根据表端距离相近则用水量周期特征也相近的生活常识先进行初步聚类,在具体实施的过程中首先可以执行步骤S511根据每个表端的地理位置获取任意两个最近邻的两个表端之间距离的平均值。接下来可以执行步骤S512将任意两个最近邻的两个表端之间距离的平均值作为分界距离,将相互之间距离小于分界距离的表端划入同一个位置初始团组内。接下来可以执行步骤S513将未被分配至任一位置初始团组的表端标记为未分配表端,将已经分配至任一位置初始团组的表端标记为已分配表端。接下来可以执行步骤S514获取与未分配表端距离最近的已分配表端对应的初始团组作为目标位置初始团组。接下来可以执行步骤S515将未分配表端纳入对应的目标位置初始团组,最后可以执行步骤S516将全部的表端分配至位置初始团组后得到若干个位置初始团组。通过先进行位置聚类的方式,得到若干个位置初始团组,加快了后续位置团组的分类速度。
请参阅图8所示,由于每个位置初始团组内的表端数量极多,按照全部表端距离两两计算求均值的方式计算量巨大,可以借用空间统计的方法进行求取,具体而言首先可以执行步骤S5111根据每个表端的地理位置获取全部表端所在区域的面积以及全部表端的数量。接下来可以执行步骤S5112根据全部表端的数量与全部表端所在区域的面积的比值得到全部表端的平均密度,接下来可以执行步骤S5113根据全部表端的平均密度求取每个表端的平均所占面积。最后可以执行步骤S5114根据每个表端的平均所占面积得到任意两个最近邻的两个表端之间距离的平均值。通过简单的密度计算,极大节省了计算量,也间接提高了位置团组的分类速度。
请参阅图9所示,在采用表端距离相近则用水量周期特征也相近的生活常识时也需要注意到这种方式容易误判,因此还需要将位置初始团组中错误分类的表端挑选出来,具体而言首先可以执行步骤S541根据用水量周期特征差异的设定范围得到指定周期内的总用水量设定范围和用水量的方差值设定范围,即设定二维量化标记结果。接下来可以执行步骤S542在每个位置初始团组内,获取全部表端的平均二维量化标记结果,接下来可以执行步骤S543在该位置初始团组内选取与平均二维量化标记结果最接近的表端作为核心表端。接下来可以执行步骤S544获取每个表端与核心表端的二维量化标记结果差值,接下来可以执行步骤S545将每个表端分配至二维量化标记结果差值最小的核心表端得到更新后的位置初始团组。接下来可以执行步骤S546在每个位置初始团组内,获取二维量化标记结果差值最大的两个表端的二维量化标记结果差值。接下来可以执行步骤S547判断二维量化标记结果差值最大的两个表端的二维量化标记结果差值是否大于设定二维量化标记结果,若是则接下来可以执行步骤S548将该两个表端标记为异常的表端。持续更新位置初始团组并筛选出异常的表端,并执行步骤S548判断每个位置初始团组内二维量化标记结果差值最大的两个表端的二维量化标记结果差值是否均小于设定二维量化标记结果,直至完成对异常的表端的筛查。通过迭代执行聚类算法的方式准确挑选出位置初始团组中的异常表端。
请参阅图10所示,由于位置团组内的表端的数量依旧极多,无法将其中每个表端的用水量周期特征都参与后续的计算,为了简化计算,需要在每个位置团组内挑选出一个具有代表性的表端,在实施的过程中首先可以执行步骤S61在位置团组内,随机抽取出若干个表端。接下来可以执行步骤S62获取随机抽取的若干个表端的二维量化标记结果,接下来可以执行步骤S63在位置团组内,计算出随机抽取的每个表端的二维量化标记结果的均值。接下来可以执行步骤S64在位置团组内获取与随机抽取的每个表端的二维量化标记结果的均值差值最接近的表端,作为位置团组内代表表端。最后可以执行步骤S65将代表表端的用水量代表周期特征作为位置团组内表端的用水量代表周期特征。通过在位置团组中选取出最具代表性的表端在不影响后续内存和算力分配准确性的前提下降低了实施运算的复杂度。
请参阅图11所示,需要重申的是,本系统的硬件资源是足够的,只是可能由于调度失衡导致无响应,因此需要对管理端的内存和算力进行分配调度。基于水务数据包的解析复杂性与对应的用水量正相关,可以按照位置团组之间预估用水量对算力和内存空间进行分配,具体而言首先可以执行步骤S71根据每个位置团组内表端的用水量代表周期特征以及每个位置团组内包含的表端,获取未来时段内每个位置团组内表端的累计用水量。接下来可以执行步骤S72根据每个位置团组的用水量代表周期特征得到管理端的预加载空间以及算力资源分配规则。接下来可以执行步骤S73根据未来时段内每个位置团组内表端的累计用水量之间的比值关于时间的对应关系以及管理端的预加载空间分配规则对表端的用水量关于时间的对应关系的历史记录进行预加载。最后可以执行步骤S74根据未来时段内每个位置团组内表端的累计用水量之间的比值关于时间的对应关系以及管理端的算力资源分配规则对管理端的算力资源进行分配。通过计算位置团组之间用水量的比例得到管理端内存和算力在位置团组之间的分配,避免调度不及时导致的系统无响应。
请参阅图12所示,管理端的预加载空间以及算力资源分配规则简而言之是按照位置团组之间的用水量进行分配,具体实施过程中首先可以执行步骤S721根据每个位置团组的用水量代表周期特征获取位置团组内表端的预估用水时段和用水量分布。接下来可以执行步骤S722根据位置团组内表端的预估用水时段和用水量分布获取未来时段每个位置团组内表端的预估用水量分布。接下来可以执行步骤S723根据未来时段每个位置团组内表端的预估用水量分布获取未来时段内每个位置团组内表端的累计用水量之间的比值关于时间的对应关系。最后可以执行步骤S724按照任一时刻获取每个位置团组内表端的累计用水量之间的比值对管理端的预加载空间以及算力资源进行分配,得到管理端的预加载空间以及算力资源分配规则。还需要说明的是,通过预估每个表端在未来时段的用水量分布得到每个位置团组在未来时段的累计用水量比例需要结合每个表端的用水量关于时间的对应关系的历史记录,而且还需要充分考虑工作日和节假日的影响,由于此部分不是本方案的重点因此不再赘述。
综上所述,本方案在实施的过程中根据表端采集的用水量实现对表端的分类和用水量预估,再基于表端分类后的位置团组的预估用水量对管理端中的内存和算力进行预先分配调度,避免管理端接收到的水务数据由于解析处理不及时导致的宕机。
本发明所示实施例的上述描述(包括在说明书摘要中的内容)并非意在详尽列举或将本发明限制到本文所公开的精确形式。尽管在本文仅为说明的目的而描述了本发明的具体实施例和本发明的实例,但是正如本领域技术人员将认识和理解的,各种等效修改是可以在本发明的精神和范围内的。如所指出的,可以按照本发明实施例的上述描述来对本发明进行这些修改,并且这些修改将在本发明的精神和范围内。
本文已经在总体上将系统和方法描述为有助于理解本发明的细节。此外,已经给出了各种具体细节以提供本发明实施例的总体理解。然而,相关领域的技术人员将会认识到,本发明的实施例可以在没有一个或多个具体细节的情况下进行实践,或者利用其它装置、系统、配件、方法、组件、材料、部分等进行实践。在其它情况下,并未特别示出或详细描述公知结构、材料和/或操作以避免对本发明实施例的各方面造成混淆。
因而,尽管本发明在本文已参照其具体实施例进行描述,但是修改自由、各种改变和替换意在上述公开内,并且应当理解,在某些情况下,在未背离所提出发明的范围和精神的前提下,在没有对应使用其他特征的情况下将采用本发明的一些特征。因此,可以进行许多修改,以使特定环境或材料适应本发明的实质范围和精神。本发明并非意在限制到在下面权利要求书中使用的特定术语和/或作为设想用以执行本发明的最佳方式公开的具体实施例,但是本发明将包括落入所附权利要求书范围内的任何和所有实施例及等同物。因而,本发明的范围将只由所附的权利要求书进行确定。