一种用于乘务资源调度的数据管理方法
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及数据处理技术领域,具体涉及一种用于乘务资源调度的数据管理方法。
背景技术
为确保运输服务的正常运行,运输公司通常会对乘务资源调度数据进行管理后,存储在乘务调度系统中,由于乘务资源调度数据的数据大,且包含运输公司以及员工的隐私信息,因此,需要对乘务资源调度数据进行压缩和加密,降低存储成本的同时保证数据的安全性。
结合混沌系统和DNA编码规则的加密方法是一种常规的加密方法,该加密方法通过密钥和混沌系统产生两个混沌值序列,通过第一个混沌值序列获得的DNA编码规则对明文进行编码,获得碱基,通过第二个混沌值序列获得解码规则对碱基进行解码获得密文,明文和密文的长度相同;因此,常规的加密方法只能实现数据加密,并不能实现数据压缩,导致想要对乘务资源调度数据进行压缩和加密,需要分别进行压缩操作和加密操作,使得乘务资源调度数据的管理效率低。
因此,如何对加密方法进行改进,使得改进后的加密方法能够同时实现对乘务资源调度数据的加密和压缩,进而提高乘务资源调度数据的管理效率成为亟待解决的问题。
发明内容
有鉴于此,本发明实施例提供了一种用于乘务资源调度的数据管理方法,以解决如何使得改进后的加密方法能够同时实现对乘务资源调度数据的加密和压缩,进而提高乘务资源调度数据的管理效率的问题。
本发明实施例中提供了一种用于乘务资源调度的数据管理方法,所述数据管理方法包括:
一种用于乘务资源调度的数据管理方法,其特征在于,所述数据管理方法包括:
对采集的乘务资源调度数据进行编码,获得二进制数据序列;
将二进制数据序列划分为多个明文子序列;
根据一维Logistic映射构建两个密钥,分别根据两个密钥获得第一混沌值序列和第二混沌值序列;
给每个DNA编码规则分配三位二进制数据;
根据所有DNA编码规则对应的三位二进制数据,获得每个明文子序列对应的第一编码规则;
根据第一混沌值序列中的每个第一混沌值对应的两位二进制数据获得每个中间子序列;
根据第二混沌值序列中的每个第二混沌值获得每个第二编码规则;
根据每个第一编码规则和第二编码规则对每个中间子序列进行编码和解码,获得两个二进制数据组成的每个密文子序列;
对所有密文子序列组成的密文序列进行存储。
进一步地,所述将二进制数据序列划分为多个明文子序列,包括:
将二进制数据序列中每三个二进制数据划分为一个明文子序列;
判断每个明文子序列的第一位二进制数据与前一个明文子序列的第三位二进制数据是否相同:若明文子序列的第一位二进制数据与前一个明文子序列的第三位二进制数据相同,则将该明文子序列记为第一明文子序列,若明文子序列的第一位二进制数据与前一个明文子序列的第三位二进制数据不相同,则将该明文子序列记为第二明文子序列;
将第一明文子序列的数量记为第一数量,将第二明文子序列的数量记为第二数量;
判断第一数量与第二数量的大小关系:若第一数量大于或者等于第二数量,则将所有第二明文子序列的第一位二进制数据转换为与该明文子序列的前一个明文子序列的第三位二进制数据相同的二进制数据,若第一数量小于第二数量,则将所有第一明文子序列的第一位二进制数据转换为与该明文子序列的前一个明文子序列的第三位二进制数据不相同的二进制数据。
进一步地,所述分别根据两个密钥获得第一混沌值序列和第二混沌值序列,包括:
根据第一密钥的参数将一维Logistic混沌映射模型迭代
根据第二密钥的参数将一维Logistic混沌映射模型迭代
进一步地,所述给每个DNA编码规则分配三位二进制数据,包括:
将第一个二进制数据为第一码字的所有三位二进制数据分配给DNA编码规则1、DNA编码规则3、DNA编码规则6、DNA编码规则8;
将第一个二进制数据为第二码字的三位二进制数据分配给DNA编码规则2、DNA编码规则4、DNA编码规则5、DNA编码规则7。
进一步地,所述根据第一混沌值序列中的每个第一混沌值对应的两位二进制数据获得每个中间子序列,包括:
将第i个第一混沌值
进一步地,所述根据每个第一编码规则和第二编码规则对每个中间子序列进行编码和解码,获得两个二进制数据组成的每个密文子序列,包括:
根据第i个明文子序列对应的第i个第一编码规则对第i个中间子序列进行编码,获得第i个碱基,根据第i个第二编码规则对第i个碱基进行解码,获得第i个密文子序列。
本发明实施例至少具有如下有益效果:本发明将乘务资源调度数据对应的二进制数据序列划分为多个明文子序列,根据两个密钥获得两个混沌值序列,给每个DNA编码规则分配三位二进制数据,根据所有DNA编码规则对应的三位二进制数据,获得每个明文子序列对应的第一编码规则,根据第一混沌值序列获得每个中间子序列,根据第二混沌值序列获得每个第二编码规则,根据每个第一编码规则和第二编码规则对每个中间子序列进行编码和解码,获得所有密文子序列,密文子序列是两位二进制数据,而明文子序列由三个二进制数据组成,因此,获得的密文子序列相较于明文子序列减少了一位二进制数据,能够实现数据压缩,同时,获得的密文子序列和明文子序列不同,因此能够实现数据加密,改进后的加密方法能够同时实现对乘务资源调度数据的加密和压缩,进而提高乘务资源调度数据的管理效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案和优点,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
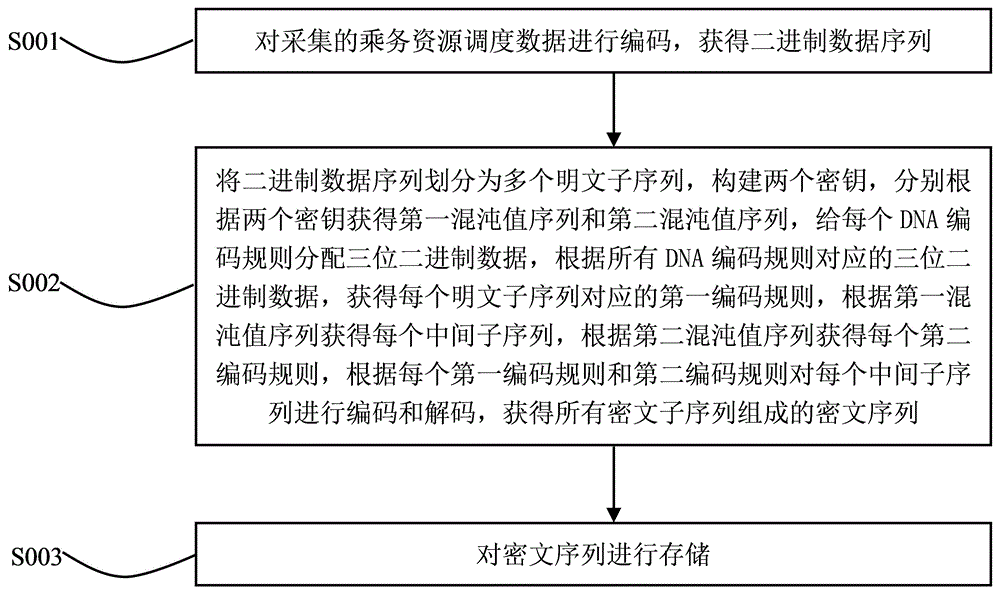
图1为本发明实施例提供的一种用于乘务资源调度的数据管理方法的步骤流程图;
图2为本发明实施例提供的一种DNA编码规则表示意图;
图3为本发明实施例提供的常规的结合混沌系统和DNA编码规则的加密方法的具体过程;
图4为本发明实施例提供的改进后的结合混沌系统和DNA编码规则的加密方法的具体过程。
具体实施方式
为了更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的一种用于乘务资源调度的数据管理方法,其具体实施方式、结构、特征及其功效,详细说明如下。在下述说明中,不同的“一个实施例”或“另一个实施例”指的不一定是同一实施例。此外,一或多个实施例中的特定特征、结构或特点可由任何合适形式组合。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。
下面结合附图具体的说明本发明所提供的一种用于乘务资源调度的数据管理方法的具体方案。
请参阅图1,其示出了本发明一个实施例提供的一种用于乘务资源调度的数据管理方法的步骤流程图,该方法包括以下步骤:
步骤S001,对采集的乘务资源调度数据进行编码,获得二进制数据序列。
在一些实现中,为确保运输服务的正常运行,运输公司通常会对乘务调度系统中的乘务资源调度数据进行管理;乘务资源调度数据通常包含以下内容:员工信息、排班信息、任务分配信息、培训记录、资格信息、工时薪资信息、休息管理信息等乘务员个人信息,以及驾驶日志、紧急事件记录、车辆设备分配信息等运输公司管理信息;因此,乘务资源调度数据涉及到运输公司以及员工的隐私信息,所以需要对乘务资源调度数据进行压缩和加密,降低存储成本的同时保证数据的安全性。
具体的,获得每次运输过程的乘务资源调度数据,对乘务资源调度数据进行编码,获得二进制数据序列,二进制数据序列中的每个二进制数据为0或者1,将0作为第一码字,将1作为第二码字,则二进制数据序列是由多个第一码字和多个第二码字组成的;编码方式包括但不限于:UTF8编码方式、UTF16编码方式、GB2312编码方式、ASCII编码方式,本实施例中使用的文本编码方式为ASCII编码方式。
举例说明:乘务资源调度数据中的排班信息为:MU2101,则采用ASCII编码方式进行编码后获得的二进制数据序列为{0,1,0,0,1,1,0,1,0,1,0,1,0,1,0,1,0,0,1,1,0,0,1,0,0,0,1,1,0,0,0,1,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,1}。
步骤S002,将二进制数据序列划分为多个明文子序列,构建两个密钥,分别根据两个密钥获得第一混沌值序列和第二混沌值序列,给每个DNA编码规则分配三位二进制数据,根据所有DNA编码规则对应的三位二进制数据,获得每个明文子序列对应的第一编码规则,根据第一混沌值序列获得每个中间子序列,根据第二混沌值序列获得每个第二编码规则,根据每个第一编码规则和第二编码规则对每个中间子序列进行编码和解码,获得所有密文子序列组成的密文序列。
举例说明:参照图2,其为本发明实施例提供的一种DNA编码规则表示意图,DNA编码规则中的编码过程是将两位二进制数据编码为碱基,解码过程是将碱基解码为两位二进制数据;对于常规的结合混沌系统和DNA编码规则的加密方法,通过该加密方法对二进制数据序列{0,1,0,0,1,1,0,1,0,1,0,1,0,1,0,1,0,0,1,1,0,0,1,0,0,0,1,1,0,0,0,1,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,1}进行加密时,该加密方法先通过密钥和混沌系统产生两个混沌值序列,本实施例根据一维Logistic映射生成两个密钥,分别为(3.771266,0.6823,31)和(3.596253,0.1789,45),分别根据两个密钥生成两个混沌值序列,第一个混沌值序列为{8, 2, 6, 8, 4, 8, 3, 7, 5, 8, 2, 5, 8, 3, 7, 4, 8, 2, 6, 7, 5, 8, 2, 6},第二个混沌值序列为{7, 5, 7, 4, 7, 4, 7, 4, 7, 4, 8, 3, 7, 4, 8, 3, 7, 5, 7, 4, 7,4, 7, 4},由于DNA编码规则中将两位二进制数据编码为碱基,因此将二进制数据序列中的每两个二进制数据组成一个明文子序列,结合如图2所示的DNA编码规则表,根据第一个混沌值序列中每个混沌值对应的DNA编码规则对每个明文子序列进行编码,获得所有编码结果组成的碱基序列为{G,A,C,G,A,G,A,C,C,A,A,A,T,G,T,A,T,T,G,T,C,A,A,T},根据第二个混沌值序列中每个混沌值对应的DNA编码规则对碱基序列中每个碱基进行解码,获得每个密文子序列,密文子序列也是两位二进制数据,所有密文子序列组成的密文序列为{1,0,1,0,0,1,0,0,1,1,0,0,1,1,1,1,0,1,0,1,1,1,0,1,0,0,0,0,1,1,0,0,0,1,0,0,0,1,1,0,1,0,0,1,0,1,1,1,1,0},结合混沌系统和DNA编码规则的加密方法的具体过程参照图3,其中,对于第一个子序列“01”,通过第一个混沌值序列中的第一个混沌值8获得DNA编码规则8,通过DNA编码规则8对第一个子序列“01”进行编码,获得第一个碱基为G,通过第二个混沌值序列中的第一个混沌值5获得DNA编码规则5,通过DNA编码规则5对第一个碱基G进行解码,获得第一个密文子序列“11”;通过两个混沌值序列使得明文子序列在编码和解码时的DNA编码规则不同,所以密文序列和二进制数据序列不相同,由于明文子序列和密文子序列都是两位二进制数据,所以密文序列和二进制数据序列的长度相同。综上该加密方法只能实现数据加密,并不能实现数据压缩,导致想要对乘务资源调度数据进行压缩和加密,需要分别进行压缩操作和加密操作,使得乘务资源调度数据的管理效率低。
在一些实现中,通过对常规的结合混沌系统和DNA编码规则的加密方法进行改进,改进后的加密方法为:将二进制数据序列中每三个二进制数据组成明文子序列,获得明文子序列对应的DNA编码规则Z1,根据DNA编码规则Z1对自定义的中间子序列进行编码,获得碱基,所述自定义的中间子序列是两位二进制数据,通过自定义的DNA编码规则Z2对碱基进行解码,获得密文子序列,密文子序列是两位二进制数据,而明文子序列由三个二进制数据组成,因此,获得的密文子序列相较于明文子序列减少了一位二进制数据,能够实现数据压缩,同时,获得的密文子序列和明文子序列不同,且自定义的两位二进制数据和自定义的DNA编码规则Z2可以通过密钥和混沌系统产生,因此能够实现数据加密。综上改进后的加密方法能够同时实现对乘务资源调度数据的加密和压缩,进而提高乘务资源调度数据的管理效率。
在一些实现中,改进后的加密方法的解密过程为:将密文序列中每两个二进制数据组成密文子序列,通过自定义的DNA编码规则Z2对密文子序列进行编码,获得碱基,通过碱基和自定义的两位二进制数据,在如图2所示的DNA编码规则表中确定对应的DNA编码规则;但是通过碱基和自定义的两位二进制数据确定的DNA编码规则有两个,导致无法获得正确的DNA编码规则Z1,进而无法根据正确的DNA编码规则Z1获得正确的明文子序列。因此,本实施例通过给碱基和两位二进制数据之间对应的两种DNA编码规则,分配第一个二进制数据不同的三位二进制数据,同时,保证每个明文子序列的第一位二进制数据与前一个明文子序列的第三位二进制数据的关系,即每个明文子序列的第一位二进制数据与前一个明文子序列的第三位二进制数据均相同,或者每个明文子序列的第一位二进制数据与前一个明文子序列的第三位二进制数据均不相同;这样在通过碱基和自定义的两位二进制数据确定的DNA编码规则时,先根据前一个解密出的明文子序列的第三位二进制数据确定每个明文子序列的第一位二进制数据,在进一步确定正确的DNA编码规则Z1。
举例说明:对于碱基A和两位二进制数据11,对应的DNA编码规则由DNA编码规则7和DNA编码规则8,通过给DNA编码规则7分配第一个二进制数据为0的三位二进制数据,给DNA编码规则8分配第一个二进制数据为1的三位二进制数据,当前一个明文子序列的第三位二进制数据为0时,碱基A和两位二进制数据11对应的DNA编码规则为DNA编码规则7,当前一个明文子序列的第三位二进制数据为1时,碱基A和两位二进制数据11对应的DNA编码规则为DNA编码规则8。
1、将二进制数据序列划分为多个明文子序列。
在一些实现中,参照图2,共由8种不同的DNA编码规则,可以用
可选的,将二进制数据序列中每三个二进制数据划分为一个明文子序列,判断每个明文子序列的第一位二进制数据与前一个明文子序列的第三位二进制数据是否相同:若明文子序列的第一位二进制数据与前一个明文子序列的第三位二进制数据相同,则将该明文子序列记为第一明文子序列,若明文子序列的第一位二进制数据与前一个明文子序列的第三位二进制数据不相同,则将该明文子序列记为第二明文子序列;将第一明文子序列的数量记为第一数量,将第二明文子序列的数量记为第二数量,判断第一数量与第二数量的大小关系:若第一数量大于或者等于第二数量,则将所有第二明文子序列的第一位二进制数据转换为与该明文子序列的前一个明文子序列的第三位二进制数据相同的二进制数据,若第一数量小于第二数量,则将所有第一明文子序列的第一位二进制数据转换为与该明文子序列的前一个明文子序列的第三位二进制数据不相同的二进制数据。
需要将第一数量与第二数量的大小关系作为第一辅助信息进行记录:若第一数量大于或者等于第二数量,则第一辅助信息为第一码字,若第一数量小于第二数量,则第一辅助信息为第二码字;需要将所有进行转换的明文子序列的序号作为第二辅助信息进行记录。
举例说明,对于二进制数据序列{0,1,0,0,1,1,0,1,0,1,0,1,0,1,0,1,0,0,1,1,0,0,1,0,0,0,1,1,0,0,0,1,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,1},划分后的所有明文子序列分别为:010,011,010,101,010,100,110,010,001,100,010,011,000,000,110,001,其中,第一明文子序列有8个,第一明文子序列有7个,第一数量大于或者等于第二数量,因此,将所有第二明文子序列的第一位二进制数据转换为与该明文子序列的前一个明文子序列的第三位二进制数据相同的二进制数据,即将第3、4、5、6、7、13、15个明文子序列的第一位二进制数据转换为与该明文子序列的前一个明文子序列的第三位二进制数据相同的二进制数据,转换后的所有明文子序列分别为:010,011,110,001,110,000,010,010,001,100,010,011,100,000,010,001。
2、构建两个密钥,分别根据两个密钥获得第一混沌值序列和第二混沌值序列。
一维Logistic映射是一种典型的混沌映射,模型为
可选的,在
可选的,根据第一密钥的参数将一维Logistic混沌映射模型迭代
可选的,根据第二密钥的参数将一维Logistic混沌映射模型迭代
举例说明,根据一维Logistic映射生成两个密钥,分别为(3.910203,0.8111,35)和(3.777344,0.3283,40),分别根据两个密钥生成两个混沌值序列,第一混沌值序列为{2,4,1,3,4,3,4,1,2,4,2,4,3,4,2,4},第二混沌值序列为{7,5,8,2,5,8,3,7,4,8,2,5,8,4,8,4}。
3、给每个DNA编码规则分配三位二进制数据。
在本实施例中,将第一个二进制数据为第一码字的所有三位二进制数据分配给DNA编码规则1、DNA编码规则3、DNA编码规则6、DNA编码规则8,将第一个二进制数据为第二码字的三位二进制数据分配给DNA编码规则2、DNA编码规则4、DNA编码规则5、DNA编码规则7。
在其他实施例中,也可以将第一个二进制数据为第二码字的三位二进制数据分配给DNA编码规则1、DNA编码规则3、DNA编码规则6、DNA编码规则8,将第一个二进制数据为第一码字的三位二进制数据分配给DNA编码规则2、DNA编码规则4、DNA编码规则5、DNA编码规则7。
需要将每个DNA编码规则及其对应的三位二进制数据作为第三辅助信息进行记录。
举例说明:将第一个二进制数据为第一码字的所有三位二进制数据分配给DNA编码规则1、DNA编码规则3、DNA编码规则6、DNA编码规则8,将第一个二进制数据为第二码字的三位二进制数据分配给DNA编码规则2、DNA编码规则4、DNA编码规则5、DNA编码规则7,则DNA编码规则1对应的三位二进制数据为000、DNA编码规则3对应的三位二进制数据为001、DNA编码规则6对应的三位二进制数据为010、DNA编码规则8对应的三位二进制数据为011,DNA编码规则2对应的三位二进制数据为100、DNA编码规则4对应的三位二进制数据为101、DNA编码规则5对应的三位二进制数据为110、DNA编码规则7对应的三位二进制数据为111。
4、根据所有DNA编码规则对应的三位二进制数据,获得每个明文子序列对应的第一编码规则,根据第一混沌值序列获得每个中间子序列,根据第二混沌值序列获得每个第二编码规则,根据每个第一编码规则和第二编码规则对每个中间子序列进行编码和解码,获得所有密文子序列组成的密文序列。
可选的,根据所有DNA编码规则对应的三位二进制数据,获得第i个明文子序列对应的DNA编码规则,记为第i个第一编码规则;根据第一混沌值序列获得中间子序列,具体为:将第i个第一混沌值
举例说明:对于二进制数据序列{0,1,0,0,1,1,0,1,0,1,0,1,0,1,0,1,0,0,1,1,0,0,1,0,0,0,1,1,0,0,0,1,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,1}进行加密时,根据所有DNA编码规则对应的三位二进制数据,获得所有明文子序列:010,011,110,001,110,000,010,010,001,100,010,011,100,000,010,001对应的第一编码规则为:DNA编码规则6, DNA编码规则8, DNA编码规则5, DNA编码规则3, DNA编码规则5, DNA编码规则1, DNA编码规则6, DNA编码规则6, DNA编码规则3, DNA编码规则2, DNA编码规则6, DNA编码规则8,DNA编码规则2, DNA编码规则1, DNA编码规则6, DNA编码规则3;根据第一混沌值序列{2,4,1,3,4,3,4,1,2,4,2,4,3,4,2,4}获得的所有中间子序列为:01,11,00,10,11,10,11,00,01,11,01,11,10,11,01,11;根据第二混沌值序列{7,5,8,2,5,8,3,7,4,8,2,5,8,4,8,4}获得的所有第二编码规则分别为:DNA编码规则7, DNA编码规则5, DNA编码规则8, DNA编码规则2, DNA编码规则5, DNA编码规则8, DNA编码规则3, DNA编码规则7, DNA编码规则4,DNA编码规则8, DNA编码规则2, DNA编码规则5, DNA编码规则8, DNA编码规则4, DNA编码规则8, DNA编码规则4;根据所有明文子序列对应的第一编码规则对所有中间子序列进行编码,获得所有碱基为:T,A,C,T,G,G,C,G,A,T,T,A,C,T,T,G,根据所有第二编码规则对所有碱基进行解码,获得所有密文子序列为:00,10,10,11,11,01,00,10, 01,00,11,10,10,10,00,11;改进后的加密方法的具体过程参照图4,获得的密文子序列是两位二进制数据,而明文子序列由三个二进制数据组成,因此,获得的密文子序列相较于明文子序列减少了一位二进制数据,能够实现数据压缩,同时,获得的密文子序列和明文子序列不同,因此能够实现数据加密。综上改进后的加密方法能够同时实现对乘务资源调度数据的加密和压缩,进而提高乘务资源调度数据的管理效率。
步骤S003、对密文序列进行存储。
对获得的密文序列进行存储,同时对第一辅助信息、第二辅助信息和第三辅助信息进行存储。
当需要查看存储的乘务资源调度数据时,先对密文序列进行解密,获得二进制数据序列,在对二进制数据序列进行解码,获得乘务资源调度数据。
其中,改进后的加密方法的解密过程为:将密文序列中每两个二进制数据组成密文子序列,通过第二密钥获得第二混沌值序列,通过第二混沌值序列获得所有第二编码规则,根据第二编码规则Z2对密文子序列进行编码,获得碱基,通过第一密钥获得第一混沌值序列,通过第一混沌值序列获得所有中间子序列,通过碱基和中间子序列,在如图2所示的DNA编码规则表中确定对应的DNA编码规则,获得的DNA编码规则对应的三位二进制数据的第一位二进制数据与前一个明文子序列的第三位二进制数据的关系满足第一辅助信息中的关系,所述DNA编码规则对应的三位二进制数据记录在第三辅助信息中,根据第二辅助信息对三位二进制数据进行转换,获得的所有DNA编码规则对应的三位二进制数据组成二进制数据序列。
综上所述,本发明实施例将乘务资源调度数据对应的二进制数据序列划分为多个明文子序列,根据两个密钥获得两个混沌值序列,给每个DNA编码规则分配三位二进制数据,根据所有DNA编码规则对应的三位二进制数据,获得每个明文子序列对应的第一编码规则,根据第一混沌值序列获得每个中间子序列,根据第二混沌值序列获得每个第二编码规则,根据每个第一编码规则和第二编码规则对每个中间子序列进行编码和解码,获得所有密文子序列,密文子序列是两位二进制数据,而明文子序列由三个二进制数据组成,因此,获得的密文子序列相较于明文子序列减少了一位二进制数据,能够实现数据压缩,同时,获得的密文子序列和明文子序列不同,因此能够实现数据加密,改进后的加密方法能够同时实现对乘务资源调度数据的加密和压缩,进而提高乘务资源调度数据的管理效率。
需要说明的是:上述本发明实施例先后顺序仅仅为了描述,不代表实施例的优劣。且上述对本说明书特定实施例进行了描述。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。