一种二进制数据无损压缩方法、设备及存储介质
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及数据处理技术领域,特别涉及一种二进制数据无损压缩方法、设备及存储介质。
背景技术
随着社会的进步,人们每天会通过不同方式得到各种各样的信息,计算机通过存储存储各种信息数据,虽然存储器容量越来越大,但是然而庞大的数据量还是给数据的存储和传输造成一定的困难,因此数据压缩方法应运而生。数据压缩方法分为有损压缩和无损压缩,有损压损一般应用在不需要特别注重细节的图片和视频上。而有一些数据对细节要求严苛,如医学影响、电子档案、程序数据等,这些较为严谨的数据则采用无损压缩方法进行压缩。
目前的无损压缩方法主要对高清图像、高清视频、大型数据文件等以MB为单位的文件进行压缩。然而像水声通信指令这种几十B~几百B的超小文件,在无损压缩编码领域被视为较难处理的小数据量文件。由于这种超小数据大部分是没有规律的,容易被认为是随机二进制数据序列,根据香农信息论,其信息熵会很大,因此超小二进制文件可压缩空间很小,加上无损解码时所需的附加信息,多出现压缩后文件甚至大于原文件的情况从而导致无法有效压缩。
发明内容
本发明目的是为了解决现有无损数据压缩方法无法有效压缩二进制数据序列的问题,而提出了一种二进制数据无损压缩方法、设备及存储介质。
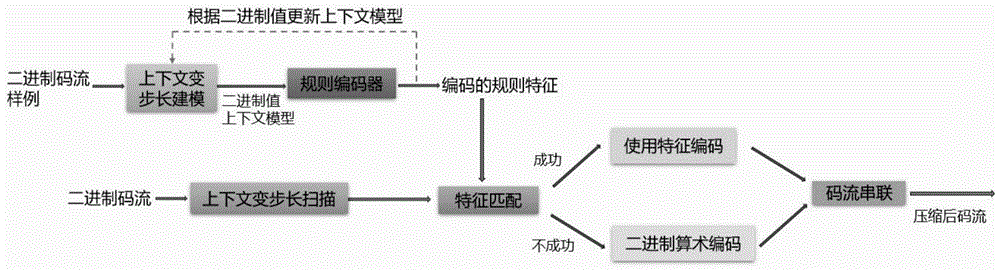
一种二进制数据无损压缩方法具体过程为:
Step1、获取待压缩二进制码流,并按照符号频度对待压缩二进制码流进行分割采用基于上下文的变步长搜索方法在分割后的待压缩二进制码流中提取待匹配的二进制数据序列;
Step2、利用步骤Step1提取的待匹配的二进制数据序列与编码后的规则特征进行匹配,若待匹配的二进制数据序列与编码后的规则特征相同,则将当前编码后的规则特征作为编码后的待压缩二进制码流的一部分β1;若待匹配的二进制数据序列与编码后的规则特征不同,则将当前待匹配的二进制数据序列作为随机序列,采用二进制算数编码方法对随机序列进行编码,将编码后的随机序列作为编码后的待压缩二进制码流的另一部分β2;
Step3、将步骤Step2获得的β1和β2分别解码,并将解码后的β1和β2串联组合,获得解码压缩后的二进制码流
进一步地,所述Step2中的编码后的规则特征,通过以下方式获得:
步骤一、读取二进制码流样例,并按照分隔符对二进制码流样例进行分割,利用分割后的二进制码流样例建立上下文概率模型中,并以前缀树的形式存储上下文概率模型,从而根据上下文概率模型获得每个字符的概率分布,从而获得划分的概率空间;
所述字符为二进制码流样例中的比特或比特块;
步骤二、根据步骤一获得的每个字符的概率分布,获得出现概率较大的字符MPS和出现概率较小的字符LPS,在概率空间中将MPS输入到规则编码器,获得编码后的规则特征,同时更新每个字符的概率分布,并返回步骤一更新上下文概率模型;
其中,出现概率在[0,0,5]中的字符为出现概率较小的字符,出现概率在(0,5,1]的字符为出现概率较大的字符
所述规则编码器采用二进制算数编码方法对MPS编码。
进一步地,所述上下文概率模型为树高为N的存储n-gram的前缀树结构,具体为:
首先,用前缀树的边表示字符,从根节点出发的一系列边构成前缀,每个节点存储特定前缀下不同字符出现的条件概率;
然后,将概率值小于预设阈值Pt的节点合并为字符为$的节点,从而获得存储n-gram的前缀树。
进一步地,所述步骤二中更新每个字符的概率分布,具体为:
(a)根据如下规则绘制LPS和MPS概率变化曲线:
其中,
(b)根据(a)获得的LPS和MPS概率变化曲线更新字符:
若当前字符为MPS,则沿MPS概率变化曲线向MPS概率增大方向更新;若MPS持续出现,则LPS概率最终更新到预设最小概率值,而后保持当前状态不再变化,直出现LPS;
当前字符为LPS,则沿LPS概率曲线向LPS概率增大方向更新,当LPS的概率达到0.5时,若下一个字符依然为LPS,则将LPS与MPS对调后继续更新。
进一步地,所述step2中的采用二进制算数编码方法对随机序列进行编码,具体为:
A1、初始化编码概率区间[0,1],设置寄存器C的值为编码点,并将寄存器C的值初始化为C
A2、当前输入的是LPS时,采用以下方式编码:
C
当前输入的是MPS时,采用以下方式编码:
C
其中,C
A3、判断当前比特编号n是否小于随机序列比特总数N,若n<N则令n=n+1,并返回步骤A2,若n=N,则将第N个比特的编码后获得C
进一步地,所述Step3中的将步骤Step2获得的β1和β2分别解码,并将解码后的β1和β2串联组合,获得解码压缩后的二进制码流,具体为:
Stpe301、将每个编码后的规则特征作为字典编码码流,对字典编码码流进行解码,获得解码后的字典码流:
①创建空的编码表code_table,从字典编码码流中获取第一个字符,并将字符的值赋值给prefix_character;
②判断字典编码码流是否结束,若字典编码码流没结束,则从字典编码码流中再取一个字符赋给current_character,然后执行③;若字典编码码流结束,则输出prefix_character;
③获取总字符String=prefix_character+current_character,并判断String是否在字典编码码流code_table当中?
若String在code_table当中,则将String赋给prefix_character,并转往②。
若String没在code_table当中,则把String存储到code_table当中去,输出prefix_charracter,同时把current_character赋给prefix_character,再转往②;
Step302、将编码后的随机序列作为非字典码流,对非字典码流进行解码,获得解码后的非字典码流;
Step303、将Step301获得的解码后的字典编码码流和Step302获得的解码后的非字典码流串联组合,获得解码压缩后的二进制码流。。
进一步地,所述Step302中的将编码后的随机序列作为非字典码流,对非字典码流进行解码,获得解码的非字典码流,具体为:
B1、将概率终点值A'
其中,i取0到I-1;
B2、判断编码后的随机序列c'
若编码后的随机序列c'
c'
若编码后的随机序列在Q
C'
B3、判断当前解码出的比特个数i是否小于预设比特个数I,若i<I,则令i=i+1,并返回B2,若i=I,则按顺序输出D
一种二进制数据无损压缩设备包括处理器和存储器,所述存储器中至少存储一条指令,所述至少一条指令由处理器加载并执行以实现一种二进制数据无损方法。
一种存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现一种二进制数据无损压缩方法。
本发明的有益效果为:
本发明在扫描输入的二进制数据文件的同时,根据比特或比特块在局部出现的概率,动态划分了概率空间,同时本发明提取出概率较高的比特或比特块作为特征,并在概率空间内对特征进行编码。本发明采用基于上下文的变步长搜索方法处理未知码流,将获得比特或比特块与已编码的特征进行匹配,从而获得压缩后的未知码流。本发明自适应的提取了二进制数据文件的特征,同时本发明不需要附加信息,实现了对未知规律的超小二进制序列文件的有效无损压缩,提升了二进制数据压缩效率。
附图说明
图1为本发明流程图;
图2为上下文概率模型结构图;
图3为更新字符概率分布的曲线图;
图4为解码过程流程图;
图5为实施例中的解码示意图。
具体实施方式
具体实施方式一:如图1所示,本实施方式一种二进制数据无损压缩方法具体过程为:
Step1、获取待压缩二进制码流,并按照符号频度对待压缩二进制码流进行分割,利用分割后的待压缩二进制码流采用基于上下文的变步长搜索方法提取待匹配的二进制数据序列;
Step2、利用步骤Step1提取的待匹配的二进制数据序列与编码后的规则特征进行匹配,若待匹配的二进制数据序列与编码后的规则特征相同,则将当前编码后的规则特征作为编码后的待压缩二进制码流的一部分β1;若待匹配的二进制数据序列与编码后的规则特征不同,则将当前待匹配的二进制数据序列作为随机序列,采用二进制算数编码方法对随机序列进行编码,将编码后的随机序列作为编码后的待压缩二进制码流的另一部分β2;
所述采用二进制算数编码方法对随机序列进行编码,具体为:
A1、初始化编码概率区间[0,1],设置寄存器C的值为编码点(指针所指处),并将寄存器C的值初始化为C
A2、当前输入的是LPS时,采用以下方式编码:
C
当前输入的是MPS时,采用以下方式编码:
C
其中,C
A3、判断当前比特编号n是否小于随机序列比特总数N,若n Step3、如图4所示,将步骤Step2获得的β1和β2分别解码,并将解码后的β1和β2串联组合,获得解码压缩后的二进制码流: Step301、将每个编码后的规则特征作为字典编码码流,对字典编码码流进行解码: ①设置初始状态,创建空的编码表code_table,从字典编码码流中获取第一个字符把它的值赋给prefix_character; ②判断字典编码码流是否结束,若字典编码码流没结束,则从字典编码码流中再取一个字符赋给current_character,然后执行③;若字符结束输出prefix_character; ③总字符String=prefix_character+current_character是否在code_table当中? 若String在code_table当中,则把String赋给prefix_character,转往②步进行。 若String没在code_table当中,就把String存储到code_table当中去,输出prefix_charracter,并且把current_character赋给prefix_character,再转往②执行。 所有的prefix_character构成解码后的解码后的字典编码码流。 Step302、将编码后的随机序列作为非字典码流,对非字典码流进行解码: 二进制算术编码的解码过程与编码过程非常相似,唯一的区别在于,编码过程是通过字符映射到相应的概率区间,而还原过程则是通过码字落入的区间确定原始字符的取值,二进制算术编码进行解码时输入编码后的随机序列,整个过程相当于编码时的逆运算,具体为: B1、将概率终点值A' B2、判断编码后的随机序列c' 若编码后的随机序列c' c' 若编码后的随机序列在Q C' B3、判断当前解码出的比特个数i是否小于预设比特个数I,若i<I,则令i=i+1,并返回B2,若i=I,则按顺序输出D Step303、将Step301获得的解码后的字典编码码流和Step302获得的解码后的非字典码流串联,获得解码压缩后的二进制码流。 具体实施方式二:所述编码后的规则特征,通过以下方式获得: 步骤一、读取二进制码流样例,并按照分隔符对二进制码流样例进行分割获得单个比特,利用分割二进制码流样例获得的单个比特建立上下文概率模型中,并以前缀树的形式存储上下文概率模型,从而根据上下文概率模型获得每个字符的概率分布,从而动态划分概率空间; 条件熵理论下,作为条件的已编码符号信息称为上下文;待编码数据具有上下文相关性,利用已编码数据提供的上下文信息,为待编码的数据选择合适的概率模型,这就是上下文建模; 所述二进制码流数据指的是水声通信比特流指令数据;所述二进制序列数据文件小于300比特;所述字符为比特或比特块; 所述上下文概率模型为树高为N的近似存储n-gram的前缀树结构,具体为:用前缀树的边表示字符,从根节点出发的一系列边构成前缀,每个节点存储特定前缀下不同字符出现的条件概率。并将小于预设阈值的概率值小于预设阈值Pt的子节点合并为一个特殊字符$; 设前缀树的树高为N(即存储的前缀长度),单个节点的包含的可能出现的字符数,即节点的扇出(fanout)的集合为F(每个节点的扇出不一定相同)。如图2所示,本步骤建立了树高N=3(即存储3-gram),字符表为{a,b,c,d}时的前缀树结构,图2中第1层节点(根节点为第0层)1阶的n-gram值,即统计直接字符频率得出的概率。对每一个特定的节点,它的下一个字符的概率自然不是均匀的,概率较高的字符单独构成一条边,对应的孩子节也被保留下来点,存放其概率值,而那些概率较小的字符则被合并成一个特殊字符,如图2中的“$”,其对应的孩子节点中存储了这些符号出现概率的总和(在图中层号为1的$节点概率值为0.2)。处于节省空间的考虑,$指向的节点没有子节点。同时,其中包含的所有符号的概率被视作相等的,同时其中记录了剩余可能出现的字符总数以便计算平均概率值。 如何确定合适的N和F是上下文概率模型效果的关键,在实际实现中,通过在取二进制码流样例中的少量指令样例上进行采样实验,确定N变化时上下文概率模型效果的变化趋势,从何选取合适的N值。N值的确定一般是经验法则:常用的N值包括1、2、3和4,即Unigram、Bigram、Trigram和Quadrigram模型。这些N值已经被广泛使用,具有经验性的支持,通常会在大多数任务中取得良好的效果,N一般为1、2、3或4。在确定N的取值后,对于F,本发明对前缀树采用一种自上而下的剪枝策略,针对单个节点,将概率值小于预设阈值Pt的子节点合并成$节点。同样,本发明首先在少量指令样例组成的采样数据集上按照Pt的不同取值,构建对应的前缀树,使用二进制算术编码方法对前缀树中每个节点进行编码,分析每个取值对应的压缩率,选取合适的Pt值。当选定Pt后,本发明在采样数据集上执行该剪枝策略,构建前缀树,完成该概率模型的近似。压缩率为编码后的总位数与原始节点存储的N-gram序列的总位数; 步骤二、根据步骤一获得的每个字符的概率分布,获得出现概率较大的比特或比特块MPS(More Probable Symbol)和出现概率较小的比特或比特块LPS(Less ProbableSymbol),在概率空间中将MPS输入到规则编码器,获得编码后的规则特征,同时利用比特或比特块更新每个字符的概率分布: 其中,LPS的取值范围是[0,0.5],MPS的取值范围是(0.5,1]; 根据概率空间的动态划分,系统将自动提取出现概率较高的比特或比特块组合规律作为特征。这些特征是在压缩编码中用于表示和编码数据的重要元素。 所述规则编码器采用二进制算数编码方法对MPS进行编码; 所述利用比特或比特块更新上下文概率模型具体为: (a)对于二进制算术编码中,根据先验知识为LPS的概率设定了64个代表概率,认为LPS的概率值只在这64个代表概率之间变化,而不会取为其他值,LPS的概率取值区间为[0.01875,0.5]。二进制算术编码的状态机中共有64个状态,pStateIdx=0,1,2,…,63,分别代表64个不同的概率,这样,由σ就构成了概率模式的64个概率状态,P0=0.5,P1=0.95*P0,…,P63=0.01875.其中状态转移参数α约为0.95,由于σ与(LPS)的概率是一一对应的关系,LPS的概率的自适应更新就表现为σ值的变化。所以,用σ的更新就代表LPS的概率的更新。由于二进制算术编码只有LPS和MPS两个符号,LPS的概率确定了,MPS的概率也就确定了,这样,LPS的概率值的确定和更新就代表了整个概率模型的概率分配的确定和更新。如此一来,概率的自适应估计问题就转化为概率状态σ值的自适应更新问题,接下来看σ值的确定和更新。在二进制算术编码中所有的概率模型都是自适应模型在每个符号被编码后,概率估计会被更新。编码完一个比特位后,都要进行概率更新。从而得到新的概率状态,实现自适应编码。概率状态的自适应更新发生在对每一个二进制符号编码之后。概率状态σ值自适应更新的法则是:若MPS出现,σ增加;可以看出,σ增加则意味着(LPS)的概率值得减少,从而就是表示下一次的MPS的概率增大,而出现LPS的概率减小。由于LPS是小概率符号,因此它的概率肯定是小于0.5的,如果某个小概率符号在状态转换的过程中超出了0.5,此时我们就需要把MPS与LPS进行交换。 如图3所示,状态机转换的规则由HOWARD与VITTER的"exponential aging"模型借鉴而来,转换规则如下: 其中, (b)根据(a)获得的状态转移规则绘制LPS和MPS概率变化曲线,进行比特更新: 若当前字符为MPS,沿MPS曲线(图3实线部分)向右更新;此时LPS的概率趋向于越来越小,如果MPS持续出现,则LPS概率最终会更新到预设最小概率值(此时LPS的概率达到预定义的最小值),而后保持在该状态不再变化,直到一个LPS出现; 若当前字符为LPS,则LPS曲线(图3的虚线部分)向左更新,此时LPS的概率趋向于越来越大,当索引值降为0时,LPS的概率达到最大的0.5;如果下一个字符依然为LPS,则认为LPS的实际概率已经超过0.5,LPS与MPS对调,继续按当前规则更新。 具体实施方式三、一种存储介质,其特征在于:所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现如权利要求1至7之一所述的一种二进制数据无损压缩方法。 具体实施方式四:一种存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现一种二进制数据无损压缩方法。 实施例: 本发明中的解码步骤,具体如下: 假设需要从记号流0 1 3 2 3 7 2解码出a b ab c ab aba c。解码开始:首先读取第一个记号cW=0,解码为a,输出,赋值pW=cW=0。然后开始循环,依此读取后面的记号,步骤如下: 这样已经解出了前5个字符a b ab c。可以看出解码的思想。首先直接解码最前面的a和b,然后生成了3->ab这一映射,即解码器利用前面已经解出的字符,如实还原了编码过程中字典的生成。而第二个以及以后的ab就可以用记号3破译出来,因为此时我们已经建立了3->ab的关系。P=Str(pW),C=Str(cW)的第一个字符,如图5所示: 注意P+C构成的方式,取前一个符号pW,加上当前最新符号cW的第一个字符。将P编码为pW输出,并更新P=C,P从单字符C开始重新增长。
- 一种阻燃耐磨轴承用浆料的制备方法
- 一种NTC芯片电极浆料及使用该浆料的NTC芯片的制备方法
- 一种无机固体电解质复合浆料的制备方法及无机固体电解质复合浆料
- 阻燃浆料在制备阻燃耐磨轴承材料中的应用
- 一种金属-有机框架材料基耐热阻燃膜的浆料及其制备方法和应用