语言翻译方法及电子设备
文献发布时间:2024-04-18 20:01:23
技术领域
本申请涉及终端技术领域,尤其涉及语言翻译方法及电子设备。
背景技术
随着智能设备的普及,越来越多用户可以在各种场景使用各种智能设备。比如,用户可以使用智能设备观看外语视频、直播等内容。在这些场景中,通常需要获取实时的翻译,比如将外语翻译为相应中文。相应的,这些场景中,智能设备的翻译性能变得越发重要。
上述翻译性能可以体现在诸多方面。比如,翻译的时效性,跳变率和准确率均可以反映智能设备的翻译性能。目前,智能设备使用固化的神经机器翻译(neural machinetranslation,NMT)模型进行跨语种的翻译,翻译性能不佳。
发明内容
本申请提供语言翻译方法及电子设备,可以提升翻译性能。
为了实现上述目的,本申请实施例提供了以下技术方案:
第一方面提供一种语言翻译方法,可以应用于第一终端或能够实现第一终端功能的组件(比如芯片系统)中,所述方法包括:
电子设备获取源语言的第一句子的翻译结果的词分布以及源语言的第二句子,并获取所述第二句子的第一翻译结果的词分布以及所述第二句子的第一翻译结果所包含词语的跳变率,之后,所述电子设备根据所述第一句子的翻译结果的词分布、所述第二句子的第一翻译结果的词分布以及所述跳变率,确定所述第二句子的第二翻译结果的词分布。所述第二句子包括所述第一句子中的词语以及第一词语;所述跳变率与第一相似度有关;所述第一相似度为所述第一句子的翻译结果与所述第二句子的第一翻译结果之间的相似度。
所述第一翻译结果所包含词语至少包括第二词语和第三词语,所述第三词语的跳变率相对于所述第二词语的跳变率发生变化。
其中,该跳变率与相邻两次翻译结果之间的相似度有关,通常,相似度能够反映句子结构、句子所包含词语等的变化信息。相应的,与相似度有关的跳变率也能够反映句子结构、句子所包含词语等的变化信息。在翻译语境、翻译任务发生变化时,句子结构和句子所包含词语可能发生变化,本申请实施例中,能够获取在当前翻译语境中用于表征句子结构和词语等变化的信息,即跳变率,并基于该跳变率确定第二句子的第二翻译结果的词分布,使得确定的最终词分布符合当前的翻译语境(句子结构和词语),进而提升翻译性能。
在一种可能的设计中,所述电子设备获取所述第二句子的第一翻译结果的词分布以及所述第二句子的第一翻译结果所包含词语的跳变率,包括:
所述电子设备将所述第一句子的翻译结果的词分布以及所述第二句子输入第一模型;
所述电子设备通过所述第一模型获取所述第二句子的第一翻译结果的词分布以及所述跳变率。
这就意味着,通过上述方案,可以把跳变率参数化,即,将跳变率视为一个变量,并且,该变量与相似度有关,相似度与语境有关。由于考虑到语境的变化,且根据语境变化能够确定与语境相关的跳变率,即本申请实施例中,电子设备能够自适应语境,并确定语境相关的跳变率(可称为自适应跳变率)。即,跳变率是可变的。因此,语境变化时,电子设备能够实时控制跳变率,进而根据跳变率确定最终的翻译结果对应的词分布,平衡时效性,跳变率、准确率这几个翻译指标,尽可能提升实时翻译的质量,比如能够拥有动态改变前缀的能力,使得本次翻译不再是一味的复制前次翻译的结果,减少因固定前缀造成的翻译质量恶化,再比如,可以使得翻译结果在需要跳变的时候及时发生改变,再无需跳变时降低跳变概率。
在一种可能的设计中,所述第一模型是通过训练样本训练得到的,所述训练样本包括:多个目标语言句子、所述多个目标语言句子中相邻目标语言句子之间的相似度、相邻目标语言句子之间的词语对齐结果、多个源语言句子、所述目标语言句子对应的第一标签、所述源语言句子对应的第二标签,所述第一标签用于表征所述目标语言句子所包含词语的跳变率,所述第二标签用于表征所述源语言句子的翻译结果。
所述第一模型包括第一子模型和第二子模型;
所述电子设备通过所述第一模型获取所述第二句子的第一翻译结果的词分布以及所述跳变率,包括:
所述电子设备通过所述第一子模型获取所述第二句子的第一翻译结果的词分布,通过所述第二子模型获取所述跳变率。
所述第一子模型是通过多个训练样本训练得到的,所述多个训练样本包括:多个源语言句子、所述源语言句子对应的第二标签,所述第二标签用于表征所述源语言句子的翻译结果。
在一种可能的设计中,所述第二子模型是通过多个训练样本训练得到的,所述多个训练样本包括:多个目标语言句子、所述多个目标语言句子中相邻目标语言句子之间的相似度、相邻目标语言句子之间的词语对齐结果、所述目标语言句子对应的第一标签、所述第一标签用于表征所述目标语言句子所包含词语的跳变率。
在一种可能的设计中,所述电子设备根据所述第一句子的翻译结果的词分布、所述第二句子的第一翻译结果的词分布以及所述跳变率,确定所述第二句子的第二翻译结果的词分布,包括:所述电子设备根据如下公式获得所述第二句子的第二翻译结果所包含的第j个词语的词分布,所述第二翻译结果的词分布包括所述第二翻译结果中的每个词语的词分布;
p
其中,p
在一种可能的设计中,可以利用相似度计算跳变率。对于所述第二句子的第一翻译结果中的目标词语:若所述第一句子的翻译结果中不存在与所述目标词语相同的词语,则β
在一种可能的设计中,所述相似度由语义相似度模型得到,所述语义相似度模型的训练样本包括:多个句子、每个句子对应的标签,所述句子对应的标签用于表征所述句子与相邻句子之间的相似度。
第二方面提供一种电子设备,包括:
处理模块,用于获取源语言的第一句子的翻译结果的词分布以及源语言的第二句子,以及获取所述第二句子的第一翻译结果的词分布以及所述第二句子的第一翻译结果所包含词语的跳变率;根据所述第一句子的翻译结果的词分布、所述第二句子的第一翻译结果的词分布以及所述跳变率,确定所述第二句子的第二翻译结果的词分布。所述第二句子包括所述第一句子中的词语以及第一词语;所述跳变率与第一相似度有关;所述第一相似度为所述第一句子的翻译结果与所述第二句子的第一翻译结果之间的相似度。所述第一翻译结果所包含词语至少包括第二词语和第三词语,所述第三词语的跳变率相对于所述第二词语的跳变率发生变化。
在一种可能的设计中,处理模块,用于获取所述第二句子的第一翻译结果的词分布以及所述第二句子的第一翻译结果所包含词语的跳变率,包括:用于所述电子设备将所述第一句子的翻译结果的词分布以及所述第二句子输入第一模型;
所述电子设备通过所述第一模型获取所述第二句子的第一翻译结果的词分布以及所述跳变率。
在一种可能的设计中,所述第一模型是通过训练样本训练得到的,所述训练样本包括:多个目标语言句子、所述多个目标语言句子中相邻目标语言句子之间的相似度、相邻目标语言句子之间的词语对齐结果、多个源语言句子、所述目标语言句子对应的第一标签、所述源语言句子对应的第二标签,所述第一标签用于表征所述目标语言句子所包含词语的跳变率,所述第二标签用于表征所述源语言句子的翻译结果。
所述第一模型包括第一子模型和第二子模型;
所述电子设备通过所述第一模型获取所述第二句子的第一翻译结果的词分布以及所述跳变率,包括:
所述电子设备通过所述第一子模型获取所述第二句子的第一翻译结果的词分布,通过所述第二子模型获取所述跳变率。
所述第一子模型是通过多个训练样本训练得到的,所述多个训练样本包括:多个源语言句子、所述源语言句子对应的第二标签,所述第二标签用于表征所述源语言句子的翻译结果。
在一种可能的设计中,所述第二子模型是通过多个训练样本训练得到的,所述多个训练样本包括:多个目标语言句子、所述多个目标语言句子中相邻目标语言句子之间的相似度、相邻目标语言句子之间的词语对齐结果、所述目标语言句子对应的第一标签、所述第一标签用于表征所述目标语言句子所包含词语的跳变率。
在一种可能的设计中,处理模块,用于根据所述第一句子的翻译结果的词分布、所述第二句子的第一翻译结果的词分布以及所述跳变率,确定所述第二句子的第二翻译结果的词分布,包括:所述电子设备根据如下公式获得所述第二句子的第二翻译结果所包含的第j个词语的词分布,所述第二翻译结果的词分布包括所述第二翻译结果中的每个词语的词分布;
p′(t
其中,p′(t
在一种可能的设计中,对于所述第二句子的第一翻译结果中的目标词语:
若所述第一句子的翻译结果中不存在与所述目标词语相同的词语,则β
若所述第一句子的翻译结果中存在与所述目标词语相同的词语,则β
其中,β
在一种可能的设计中,所述相似度由语义相似度模型得到,所述语义相似度模型的训练样本包括:多个句子、每个句子对应的标签,所述句子对应的标签用于表征所述句子与相邻句子之间的相似度。
第三方面提供一种电子设备,该电子设备具有实现如上述任意方面及其中任一种可能的实现方式中的语言翻译方法的功能。该功能可以通过硬件实现,也可以通过硬件执行相应的软件实现。该硬件或软件包括一个或多个与上述功能相对应的模块。
第四方面提供一种计算机可读存储介质,包括计算机指令,当计算机指令在电子设备上运行时,使得电子设备执行如上述任意方面及其中任一种可能的实现方式中任一项的语言翻译方法。
第五方面提供一种计算机程序产品,当计算机程序产品在电子设备上运行时,使得电子设备执行如任意方面及其中任一种可能的实现方式中任一项的语言翻译方法。
第六方面提供一种电路系统,电路系统包括处理电路,处理电路被配置为执行如上述任意方面及其中任一种可能的实现方式中的语言翻译方法。
第七方面提供一种电子设备,包括:一个或多个处理器;一个或多个存储器;存储器存储有一个或多个程序,当一个或者多个程序被处理器执行时,使得电子设备执行上述任一方面任一的方法。
第八方面提供一种芯片系统,包括至少一个处理器和至少一个接口电路,至少一个接口电路用于执行收发功能,并将指令发送给至少一个处理器,当至少一个处理器执行指令时,至少一个处理器执行如上述任意方面及其中任一种可能的实现方式中的语言翻译方法。
附图说明
图1-图3为语言翻译方法的示意图;
图4、图5为本申请实施例提供的电子设备的结构示意图;
图6为本申请实施例提供的电子设备的软件架构的示意图;
图7A为本申请实施例提供的语言翻译方法的示意图;
图7B为本申请实施例提供的一组界面示意图;
图8为本申请实施例提供的模型的示意图;
图9A为本申请实施例提供的跳变率计算原理的示意图;
图9B、图9C为本申请实施例提供的模型训练方法的示意图;
图10为本申请实施例提供的模型的示意图;
图11-图13为本申请实施例提供的语言翻译方法的示意图;
图14为本申请实施例提供的装置的示意图;
图15为本申请实施例提供的芯片系统的示意图。
具体实施方式
图1示出了一种语言翻译方法。以手机进行翻译为例,手机采集源语言的语音流,并将源语言的语音流输入自动语音识别(automatic speech recognition,ASR)模型,由ASR模型识别源语言的语音流,并将源语言的语音流转化为源语言的文本(或称源语言句子,或称为源语言序列)。之后,ASR模型将源语言的文本输出至NMT模型,由NMT模型将源语言的文本翻译为目标语言。其中,NMT模型包括编码模块(encoder)和解码模块(decoder)。编码模块用于对源语言的文本进行编码,得到源语言的文本对应的编码向量,并将该编码向量输出至解码模块。解码模块用于对来自编码模块的编码向量进行解码,即将该向量转化(或称翻译)为目标语言。示例性的,手机将采集的英文语音流“I am a student”输入ASR模型,ASR模型将该语音流转化为对应的文本,并将该文本输出至编码模块,由编码模块对该文本进行编码,得到源语言的文本对应的编码向量。源语言的文本包括多个词语(或称为词汇,或称为“字”)。源语言的文本对应的编码向量包括该文本中每个词语的编码向量。比如该文本中词语“student”对应的编码向量为[0.5,0.2,-0.1,-0.3,0.4,1.2]。编码模块得到源语言文本中每个词语对应的编码向量后,将每个词语的编码向量输出至解码模块。
解码模块对源语言的每个词语的编码向量进行处理,得到目标语言句子(或称目标语言的文本信息,或称目标语言文本,或称目标语言序列,或称翻译结果)。目标语言句子包含J个词语,其中,每个词语对应一个概率分布。概率分布可以是向量形式。
其中,目标语言句子中的第j个词语的概率分布:p(t
其中,w表示对每个可能的输出词语进行打分,softmax(w)表示对各打分进行归一化处理。
示例性的,解码模块对源语言句子“I am a student”进行处理,输出如下概率分布:[0.04,0.21.0.05,0.70]、[0.04,0.21.0.1,0.65]、[0.04,0.11.0.15,0.70]、[0.14,0.11.0.05,0.70]、[0.04,0.51.0.05,0.40]、[0.04,0.21.0.45,0.30]。
其中,概率分布[0.04,0.21.0.05,0.70]中有4个元素,每个元素表示一个概率,该概率表示目标语言句子中的第j个词语可能为该概率对应的词语的概率。该概率分布所表示的向量中,各元素的值(即各概率)相加的结果为1。0.04表示目标语言中的第一个词语可能为“x1”的概率是0.04,0.21表示目标语言句子中的第一个词语可能为“y1”的概率是0.21,0.05表示目标语言句子的第一个词语可能为“z1”的概率是0.05,0.7表示目标语言句子的第一个词语可能为“我”的概率是0.7。由于词语“我”的概率最高,因此,确定目标语言句子的第一个词语为“我”。
类似的,概率分布[0.04,0.21.0.1,0.65]中,0.04表示目标语言句子中第二个词语可能为词语“x2”的概率是0.04,0.21表示目标语言句子中第二个词语可能为词语“y2”的概率是0.21,0.1表示目标语言句子中第二个词语可能为“z2”的概率是0.1,0.65表示目标语言句子中第二个词语可能为“是”的概率是0.65。由于词语“是”的概率最高,因此,确定目标语言句子中第二个词语“是”。以此类推,可确定目标语言句子包含的各个词语,进而完成将源语言句子翻译为目标语言句子的翻译任务。
对于目标语言中的第j个词语来说,该词语对应的概率分布,也可简称为该词语对应的词分布。
在一些方案中,电子设备采集的语音流中每增加一个语音信息,就将该语音信息输入ASR模型,并由ASR模型、NMT模型处理后,得到该语音信息对应的翻译结果,直至语音流结束。示例性的,以图2为例,手机目前正在播放英文视频,手机实时采集视频中说话者的英文语音流。在时刻A,手机采集的语音流S1为“this one question will yourprofessional success”,手机将英文语音流S1输入ASR模块,由ASR模型、NMT模型处理后,将英文语音流S1翻译成相应中文“这个问题将定义您的职业成功”。在时刻B,手机继续采集说话者的新的语音信息,在采集到英文单词“more”之后,手机将该英文单词(该英文单词与语音流S1构成语音流S2)输入ASR模块,由ASR模块、NMT模型处理后,对英文语音流S2进行翻译。在一个示例中,NMT模型在复制上次翻译结果(S1的翻译结果)的基础上,对新增单词进行翻译。即,在对英文语音流S2进行翻译时,NMT模型复用S1的翻译结果“这个问题将定义您的职业成功”,并获得新输入单词more的翻译结果(更加),然后,对S1的翻译结果和新输入单词more的翻译结果进行拼接,获得英语语音流S2的翻译结果“这个问题将定义您的职业成功,更加”。类似的,NMT模型在对英文语音流S3进行翻译时,对S2的翻译结果以及此次新输入单词“than any other”的翻译结果进行拼接,得到S3的翻译结果“这个问题将定义您的职业成功,更加比其他问题”。该实现方式中,手机可以将一个句子的翻译过程分解为多个翻译任务,对多个翻译任务分别进行处理,无需等待检测到完整的英文语句,就可以提前进行翻译,相比于检测到完整的英文语句才开始进行翻译,图2对应的技术方案能降低翻译用时,提升翻译的时效性。但是,由于每次翻译均是在复制上次翻译结果的基础上拼接新单词的翻译结果,使得最终的翻译结果不易于用户理解,甚至可能存在翻译错误等问题。
在另一些示例中,一个句子的翻译过程分解为多个翻译任务,NMT模型不考虑上次翻译结果,仅对当前翻译任务的语音信息进行翻译。以图3为例,this one question willdefine your professional success more than any other这一英文句子的翻译过程可以分解为多个翻译任务,其中包括S2翻译任务、S3翻译任务。在对英文语音流S2进行翻译时,NMT模型不考虑S1的翻译结果,而是直接对英语语音流S2进行翻译,得到翻译结果“这个问题将更能定义您的职业成功”。类似的,NMT模型在对英文语音流S3进行翻译时,不考虑S2的翻译结果,直接对S3进行翻译,得到S3的翻译结果“这个问题将更能定义您的职业成功,而不是”。该实现方式中,当前的翻译结果会覆盖上次的翻译结果,使得相邻两次翻译结果之间的跳变率较高。翻译结果的反复变化,使得用户需要重新阅读、理解发生变化的翻译结果,给用户带来不便,降低用户体验。
为了解决上述问题,提升翻译性能,本申请实施例提供一种语言翻译方法。本申请实施例的技术方案可应用在各种场景中,比如包括但不限于:视频、直播、音频、视频会议、视频演讲等需要进行语义翻译的场景中。本申请实施例的技术方案可应用在具有翻译功能的电子设备中。示例性的,电子设备可以为手机、平板电脑、个人计算机(personalcomputer,PC)、个人数字助理(personal digital assistant,PDA)、智能手表、上网本、可穿戴电子设备、增强现实技术(augmented reality,AR)设备、虚拟现实(virtual reality,VR)设备、车载设备、智能汽车等设备,本申请对该电子设备的具体形式不做特殊限制。
本申请的说明书以及附图中的术语“第一”和“第二”等是用于区别不同的对象,或者用于区别对同一对象的不同处理。“第一”、“第二”等字样可以对功能和作用基本相同的相同项或相似项进行区分。例如,第一设备和第二设备仅仅是为了区分不同的设备,并不对其先后顺序进行限定。本领域技术人员可以理解“第一”、“第二”等字样并不对数量和执行次序进行限定,并且“第一”、“第二”等字样也并不限定一定不同。“至少一个”是指一个或者多个,“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B的情况,其中A,B可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。“以下至少一项(个)”或其类似表达,是指的这些项中的任意组合,包括单项(个)或复数项(个)的任意组合。例如,a,b,或c中的至少一项(个),可以表示:a,b,c,a-b,a-c,b-c,或a-b-c,其中a,b,c可以是单个,也可以是多个。
此外,本申请的描述中所提到的术语“包括”和“具有”以及它们的任何变形,操作信息在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括其他没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。
需要说明的是,本申请实施例中,“示例性的”或者“例如”等词用于表示作例子、例证或说明。本申请实施例中被描述为“示例性的”或者“例如”的任何实施例或设计方案不应被解释为比其它实施例或设计方案更优选或更具优势。确切而言,使用“示例性的”或者“例如”等词旨在以具体方式呈现相关概念。
以电子设备为手机为例,图4示出了电子设备的结构示意图。
电子设备可以包括处理器110,外部存储器接口120,内部存储器121,通用串行总线(universal serial bus,USB)接口130,充电管理模块140,电源管理模块141,电池142,天线1,天线2,移动通信模块150,无线通信模块160,音频模块170,扬声器170A,受话器170B,麦克风170C,耳机接口170D,传感器模块180,按键190,马达191,指示器192,摄像头193,显示屏194,以及用户标识模块(subscriber identification module,SIM)卡接口195等。其中传感器模块180可以包括压力传感器180A,陀螺仪传感器180B,气压传感器180C,磁传感器180D,加速度传感器180E,距离传感器180F,接近光传感器180G,指纹传感器180H,温度传感器180J,触摸传感器180K,环境光传感器180L,骨传导传感器180M等。
可以理解的是,本发明实施例示意的结构并不构成对电子设备的具体限定。在本申请另一些实施例中,电子设备可以包括比图示更多或更少的部件,或者组合某些部件,或者拆分某些部件,或者不同的部件布置。图示的部件可以以硬件,软件或软件和硬件的组合实现。
处理器110可以包括一个或多个处理单元,例如:处理器110可以包括应用处理器(application processor,AP),调制解调处理器,图形处理器(graphics processingunit,GPU),图像信号处理器(image signal processor,ISP),控制器,视频编解码器,数字信号处理器(digital signal processor,DSP),基带处理器,和/或神经网络处理器(neural-network processing unit,NPU)等。其中,不同的处理单元可以是独立的器件,也可以集成在一个或多个处理器中。
控制器可以根据指令操作码和时序信号,产生操作控制信号,完成取指令和执行指令的控制。
处理器110中还可以设置存储器,用于存储指令和数据。
在一些实施例中,处理器110可以包括一个或多个接口。
可以理解的是,本发明实施例示意的各模块间的接口连接关系,只是示意性说明,并不构成对电子设备的结构限定。在本申请另一些实施例中,电子设备也可以采用上述实施例中不同的接口连接方式,或多种接口连接方式的组合。
充电管理模块140用于从充电器接收充电输入。其中,充电器可以是无线充电器,也可以是有线充电器。
电源管理模块141用于连接电池142,充电管理模块140与处理器110。电源管理模块141接收电池142和/或充电管理模块140的输入,为处理器110,内部存储器121,显示屏194,摄像头193,和无线通信模块160等供电。
电子设备的无线通信功能可以通过天线1,天线2,移动通信模块150,无线通信模块160,调制解调处理器以及基带处理器等实现。
天线1和天线2用于发射和接收电磁波信号。电子设备中的每个天线可用于覆盖单个或多个通信频带。不同的天线还可以复用,以提高天线的利用率。例如:可以将天线1复用为无线局域网的分集天线。在另外一些实施例中,天线可以和调谐开关结合使用。
移动通信模块150可以提供应用在电子设备上的包括2G/3G/4G/5G/6G等无线通信的解决方案。移动通信模块150可以包括至少一个滤波器,开关,功率放大器,低噪声放大器(low noise amplifier,LNA)等。移动通信模块150可以由天线1接收电磁波,并对接收的电磁波进行滤波,放大等处理,传送至调制解调处理器进行解调。移动通信模块150还可以对经调制解调处理器调制后的信号放大,经天线1转为电磁波辐射出去。在一些实施例中,移动通信模块150的至少部分功能模块可以被设置于处理器110中。在一些实施例中,移动通信模块150的至少部分功能模块可以与处理器110的至少部分模块被设置在同一个器件中。
调制解调处理器可以包括调制器和解调器。其中,调制器用于将待发送的低频基带信号调制成中高频信号。解调器用于将接收的电磁波信号解调为低频基带信号。随后解调器将解调得到的低频基带信号传送至基带处理器处理。低频基带信号经基带处理器处理后,被传递给应用处理器。应用处理器通过音频设备(不限于扬声器170A,受话器170B等)输出声音信号,或通过显示屏194显示图像或视频。在一些实施例中,调制解调处理器可以是独立的器件。在另一些实施例中,调制解调处理器可以独立于处理器110,与移动通信模块150或其他功能模块设置在同一个器件中。
无线通信模块160可以提供应用在电子设备上的包括无线局域网(wirelesslocal area networks,WLAN)(如无线保真(wireless fidelity,Wi-Fi)网络),蓝牙(bluetooth,BT),全球导航卫星系统(global navigation satellite system,GNSS),调频(frequency modulation,FM),近距离无线通信技术(near field communication,NFC),红外技术(infrared,IR)等无线通信的解决方案。无线通信模块160可以是集成至少一个通信处理模块的一个或多个器件。无线通信模块160经由天线2接收电磁波,将电磁波信号调频以及滤波处理,将处理后的信号发送到处理器110。无线通信模块160还可以从处理器110接收待发送的信号,对其进行调频,放大,经天线2转为电磁波辐射出去。
在一些实施例中,电子设备的天线1和移动通信模块150耦合,天线2和无线通信模块160耦合,使得电子设备可以通过无线通信技术与网络以及其他设备通信。
电子设备通过GPU,显示屏194,以及应用处理器等实现显示功能。GPU为图像处理的微处理器,连接显示屏194和应用处理器。GPU用于执行数学和几何计算,用于图形渲染。处理器110可包括一个或多个GPU,其执行程序指令以生成或改变显示信息。
显示屏194用于显示图像,视频等。显示屏194包括显示面板。在一些实施例中,电子设备可以包括1个或N个显示屏194,N为大于1的正整数。
电子设备可以通过ISP,摄像头193,视频编解码器,GPU,显示屏194以及应用处理器等实现拍摄功能。
ISP用于处理摄像头193反馈的数据。例如,拍照时,打开快门,光线通过镜头被传递到摄像头感光元件上,光信号转换为电信号,摄像头感光元件将所述电信号传递给ISP处理,转化为肉眼可见的图像。ISP还可以对图像的噪点,亮度,肤色进行算法优化。ISP还可以对拍摄场景的曝光,色温等参数优化。在一些实施例中,ISP可以设置在摄像头193中。
摄像头193用于捕获静态图像或视频。物体通过镜头生成光学图像投射到感光元件。感光元件把光信号转换成电信号,之后将电信号传递给ISP转换成数字图像信号。ISP将数字图像信号输出到DSP加工处理。DSP将数字图像信号转换成标准的RGB,YUV等格式的图像信号。在一些实施例中,电子设备可以包括1个或N个摄像头193,N为大于1的正整数。
数字信号处理器用于处理数字信号,除了可以处理数字图像信号,还可以处理其他数字信号。例如,当电子设备在频点选择时,数字信号处理器用于对频点能量进行傅里叶变换等。
视频编解码器用于对数字视频压缩或解压缩。电子设备可以支持一种或多种视频编解码器。这样,电子设备可以播放或录制多种编码格式的视频,例如:动态图像专家组(moving picture experts group,MPEG)1,MPEG2,MPEG3,MPEG4等。
NPU为神经网络(neural-network,NN)计算处理器,通过借鉴生物神经网络结构,例如借鉴人脑神经元之间传递模式,对输入信息快速处理,还可以不断的自学习。通过NPU可以实现电子设备的智能认知等应用,例如:图像识别,人脸识别,语音识别,文本理解等。
外部存储器接口120可以用于连接外部存储卡,例如Micro SD卡,实现扩展电子设备的存储能力。外部存储卡通过外部存储器接口120与处理器110通信,实现数据存储功能。
内部存储器121可以用于存储计算机可执行程序代码,所述可执行程序代码包括指令。内部存储器121可以包括存储程序区和存储数据区。其中,存储程序区可存储操作系统,至少一个功能所需的应用程序(比如声音播放功能,图像播放功能等)等。存储数据区可存储电子设备使用过程中所创建的数据(比如音频数据,电话本等)等。此外,内部存储器121可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件,闪存器件,通用闪存存储器(universal flash storage,UFS)等。处理器110通过运行存储在内部存储器121的指令,和/或存储在设置于处理器中的存储器的指令,执行电子设备的各种功能应用以及数据处理。
在本申请的一些实施例中,电子设备的存储器中存储有机器翻译模型,该机器翻译模型包括ASR模块、编码模块、解码模块、输出模块以及修正模块。其中,各模块的技术实现和用途可以参见后文。该机器翻译模型用于将源语言的语音信息翻译为目标语言的翻译结果。可选的,电子设备还可以将翻译结果处理为字幕,并在显示屏上显示目标语言的字幕。
电子设备可以通过音频模块170,扬声器170A,受话器170B,麦克风170C,耳机接口170D,以及应用处理器等实现音频功能。例如音乐播放,录音等。
音频模块170用于将数字音频信息转换成模拟音频信号输出,也用于将模拟音频输入转换为数字音频信号。音频模块170还可以用于对音频信号编码和解码。在一些实施例中,音频模块170可以设置于处理器110中,或将音频模块170的部分功能模块设置于处理器110中。
扬声器170A,也称“喇叭”,用于将音频电信号转换为声音信号。电子设备可以通过扬声器170A收听音乐,或收听免提通话。
受话器170B,也称“听筒”,用于将音频电信号转换成声音信号。当电子设备接听电话或语音信息时,可以通过将受话器170B靠近人耳接听语音。
麦克风170C,也称“话筒”,“传声器”,用于将声音信号转换为电信号。当拨打电话或发送语音信息时,用户可以通过人嘴靠近麦克风170C发声,将声音信号输入到麦克风170C。电子设备可以设置至少一个麦克风170C。在另一些实施例中,电子设备可以设置两个麦克风170C,除了采集声音信号,还可以实现降噪功能。在另一些实施例中,电子设备还可以设置三个,四个或更多麦克风170C,实现采集声音信号,降噪,还可以识别声音来源,实现定向录音功能等。
耳机接口170D用于连接有线耳机。耳机接口170D可以是USB接口130,也可以是3.5mm的开放移动电子设备平台(open mobile terminal platform,OMTP)标准接口,美国蜂窝电信工业协会(cellular telecommunications industry association of the USA,CTIA)标准接口。
按键190包括开机键,音量键等。按键190可以是机械按键。也可以是触摸式按键。电子设备可以接收按键输入,产生与电子设备的用户设置以及功能控制有关的键信号输入。
马达191可以产生振动提示。
指示器192可以是指示灯,可以用于指示充电状态,电量变化,也可以用于指示消息,未接来电,通知等。
SIM卡接口195用于连接SIM卡。
示例性的,上述仅以电子设备举例说明本申请实施例中电子设备的结构,但并不构成对电子设备结构、形态的限制。本申请实施例对电子设备的结构、形态不做限制。示例性的,图5示出了电子设备的另一种示例性结构。如图5所示,电子设备包括:处理器501、存储器502、收发器503。处理器501、存储器502的实现可参见电子设备的处理器、存储器的实现。收发器503,用于电子设备与其他设备(比如电子设备)交互。收发器503可以是基于诸如Wi-Fi、蓝牙或其他通信协议的器件。
在本申请另一些实施例中,电子设备可以包括比图示更多或更少的部件,或者组合某些部件,或者拆分某些部件,或者替换某些部件,或者不同的部件布置。图示的部件可以以硬件,软件或软件和硬件的组合实现。
电子设备的软件系统可以采用分层架构、事件驱动架构、微核架构,微服务架构、或云架构。本发明实施例以分层架构的
图6是本发明实施例的电子设备的软件结构框图。
分层架构将软件分成若干个层,每一层都有清晰的角色和分工。层与层之间通过软件接口通信。在一些实施例中,将Android系统分为四层,从上至下分别为应用程序层,应用程序框架层,安卓运行时(Android runtime)和系统库,以及内核层。
应用程序层可以包括一系列应用程序包。
如图6所示,应用程序包可以包括日历,地图,WLAN,短信息,图库,导航,第一应用等应用程序。
其中,本申请的一些实施例中,第一应用程序包括语音相关的应用程序。语音相关的应用程序指的是通过该应用程序可以输出语音(比如通过电子设备播放语音)或向电子设备输入语音(比如在录像场景中,相机应用程序可通过相应驱动调用麦克风采集用户的语音信息)。第一应用程序比如可以但不限于是视频、相机、音乐、通话。
第一应用程序可以是预装应用或通过第三方应用商店下载的应用程序。本申请实施例不限制第一应用程序的具体实现。
在本申请的一些实施例中,可以通过这些应用程序中的某些应用程序输出音频或输入音频,当电子设备检测到音频时,可以利用ASR技术将音频中的部分内容(比如音频中的人物说话声音(简称人声))进行翻译。可选的,电子设备还可以将翻译结果转化为字幕,并在显示屏上显示字幕。
以用户观看网络视频为例,用户观看网络视频可以是通过浏览器观看,或通过视频播放器(比如
应用程序框架层为应用程序层的应用程序提供应用编程接口(applicationprogramming interface,API)和编程框架。应用程序框架层包括一些预先定义的函数。
如图6所示,应用程序框架层可以包括窗口管理器,内容提供器,视图系统,电话管理器,资源管理器,通知管理器等。
在本申请的一些实施例中,框架层还包括声音接口(或称声音模块),用于检测输入电子设备或电子设备输出的声音。
可选的,框架层还可以包括其他用于实现本申请实施例技术方案所需的接口或模块。
窗口管理器用于管理窗口程序。窗口管理器可以获取显示屏大小,判断是否有状态栏,锁定屏幕,截取屏幕等。
内容提供器用来存放和获取数据,并使这些数据可以被应用程序访问。所述数据可以包括视频,图像,音频,拨打和接听的电话,浏览历史和书签,电话簿等。
视图系统包括可视控件,例如显示文字的控件,显示图片的控件等。视图系统可用于构建应用程序。显示界面可以由一个或多个视图组成的。例如,包括短信通知图标的显示界面,可以包括显示文字的视图以及显示图片的视图。
电话管理器用于提供电子设备的通信功能。例如通话状态的管理(包括接通,挂断等)。
资源管理器为应用程序提供各种资源,比如本地化字符串,图标,图片,布局文件,视频文件等等。
通知管理器使应用程序可以在状态栏中显示通知信息,可以用于传达告知类型的消息,可以短暂停留后自动消失,无需用户交互。比如通知管理器被用于告知下载完成,消息提醒等。通知管理器还可以是以图表或者滚动条文本形式出现在系统顶部状态栏的通知,例如后台运行的应用程序的通知,还可以是以对话窗口形式出现在屏幕上的通知。例如在状态栏提示文本信息,发出提示音,指示灯闪烁等。
Android Runtime包括核心库和虚拟机。Android runtime负责安卓系统的调度和管理。
核心库包含两部分:一部分是java语言需要调用的功能函数,另一部分是安卓的核心库。
应用程序层和应用程序框架层运行在虚拟机中。虚拟机将应用程序层和应用程序框架层的java文件执行为二进制文件。虚拟机用于执行对象生命周期的管理,堆栈管理,线程管理,安全和异常的管理,以及垃圾回收等功能。
系统库可以包括多个功能模块。例如:表面管理器(surface manager),媒体库(Media Libraries),三维图形处理库(例如:OpenGL ES),2D图形引擎(例如:SGL)等。
表面管理器用于对显示子系统进行管理,并且为多个应用程序提供了2D和3D图层的融合。
媒体库支持多种常用的音频,视频格式回放和录制,以及静态图像文件等。媒体库可以支持多种音视频编码格式,例如:MPEG4,H.264,MP3,AAC,AMR,JPG,PNG等。
三维图形处理库用于实现三维图形绘图,图像渲染,合成,和图层处理等。
2D图形引擎是2D绘图的绘图引擎。
内核层是硬件和软件之间的层。内核层至少包含显示驱动,摄像头驱动,音频驱动,传感器驱动。
以下实施例中所涉及的技术方案均可以在具有如图4、图5所示结构的装置中实现。
本申请实施例提供一种语言翻译方法。以手机开启人工智能(artificialintelligence,AI)字幕功能,且正在播放英文视频为例,手机实时采集英文视频中说话者的英文语音流并将英文语音流转换为中文字幕,并在显示屏上显示中文字幕。
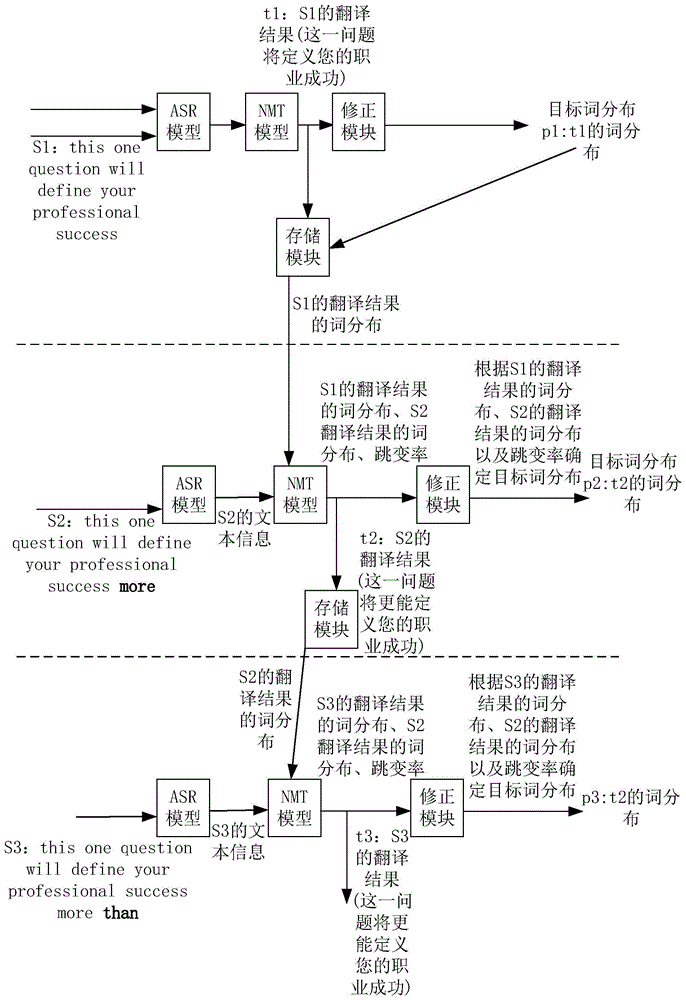
如图7A所示,假设手机已采集并完成对英文语音流S1的翻译(假设S1的翻译结果为“这个问题将定义您的职业成功”)以及获得S1的翻译结果的词分布,且已将将S1的翻译结果以及S1的翻译结果的词分布存储在存储模块(比如存储器、缓存)中。手机继续实时采集英文视频中说话者的新的语音信息,比如,如图7A所示,在某个时刻,手机采集到说话者所说的英文单词“more”,那么,手机可以将英文语音流S2(由英文语音流S1与新增单词more构成)以及上次翻译结果(即英文语音流S1的翻译结果)输入ASR模型,ASR模型将英文语音流S2转化为S2对应的文本信息,并将S2对应的文本信息传递给NMT模型。ASR模型还可以将S1的翻译结果传递给NMT模型。
相应的,NMT模型从ASR模型接收S2的文本信息以及S1的翻译结果之后,对S2的文本信息进行处理,获得S2的翻译结果(比如中文的翻译结果),并获得S2的翻译结果的词分布。此外,NMT模型可以对S1的翻译结果进行处理,获得S1的翻译结果的词分布。NMT模型还可以获得S1的翻译结果所包含词语的跳变率。之后,NMT模型可以将S2的翻译结果的词分布、S1的翻译结果的词分布以及S1的翻译结果与S2的翻译结果之间的跳变率传递给修正模块。
相应的,修正模块可以根据S2的翻译结果的词分布、S1的翻译结果的词分布以及S1的翻译结果所包含词语的跳变率,确定S2的最终翻译结果的词分布(可称为目标词分布)。
由于机器翻译过程是动态进行的,因此翻译语境(或称翻译任务)发生变化时,相邻两次翻译结果之间的跳变率也随之相应发生改变,使得基于跳变率确定的目标词分布也相应发生改变,也就是说,能够根据当前的翻译语境,获得当前翻译语境中本次翻译结果所包含词语的跳变率,并基于该跳变率自适应生成符合语境的目标词分布。
示例性的,仍以图7A为例,在对英文语音流S2进行翻译时,电子设备获得S1的翻译结果所包含词语的跳变率,并根据该跳变率确定目标词分布为S2的翻译结果的词分布(本次翻译结果的词分布),即“这一问题将更能定义您的职业成功”对应的词分布。在对英文语音流S3进行翻译时,电子设备获得S3的翻译结果所包含词语的跳变率,并根据该跳变率确定目标词分布为S2的翻译结果的词分布(上次翻译结果的词分布),即“这一问题将更能定义您的职业成功”对应的词分布。
示例性的,如图7B的(1)所示,用户当前使用手机观看英文视频,手机检测到英文视频中说话者的语音信息之后,可以在视频播放窗口301中显示弹窗302,用于提示用户开启AI字幕功能。检测到用户点击弹窗302中的“开启”选项后,手机可以开启AI字幕功能,以便对英文视频中说话者的英文语音信息进行翻译。在三次翻译任务中,手机生成的中文字幕分别如图7B的(2)、图7B的(3)、图7B的(4)所示。其中,用于生成图7B的(2)所示中文字幕的词分布比如可以是图7A所示的目标词分布p1,用于生成图7B的(3)所示中文字幕的词分布比如可以是图7A所示的目标词分布p2,用于生成图7B的(4)所示中文字幕的词分布比如可以是图7A所示的目标词分布p3。
可见,目标词分布(比如用于生成中文字幕的词分布)不再为固化的词分布,比如不再固化为采用上次翻译结果的词分布,或固定采用本次翻译结果的词分布,而是可以随翻译语境变化(跳变率相应变化),得到非固化的目标词分布。
在一些实施例中,上述英文语音流S2的文本信息可以称为第二句子。英文语音流S1的文本信息可以称为第一句子。如下,结合附图说明本申请实施例提供的机器翻译模型的功能、实现以及具体应用。
可选的,如图8示出了本申请实施例提供的NMT模型、修正模块的框架。
其中,NMT模型包括编码模块、解码模块。
编码模块,用于获取源语言的第二句子以及源语言的第一句子的翻译结果的词分布,并对第一句子进行处理,得到该第一句子对应的编码向量。还用于将该编码向量以及第一句子的翻译结果的词分布输出至解码模块。
解码模块,与编码模块的输出端连接,用于接收来自编码模块的编码向量,并用于对编码向量进行处理,得到上述第二句子的第一翻译结果的词分布。还用于根据第一句子的翻译结果的词分布以及第二句子的编码向量,确定第一翻译结果所包含词语的跳变率。
作为一种可能的实现方式,NMT模型可以称为第一模型。
本申请涉及的功能模块还包括修正模块,其中,修正模块用于获取第一句子的翻译结果的词分布、第二句子的第一翻译结果对应的词分布以及跳变率,并根据第一句子的翻译结果对应的词分布、第二句子的第一翻译结果对应的词分布以及该跳变率,确定修正后的词分布,即第二句子的第二翻译结果的词分布。第二句子的第二翻译结果的词分布作为本次翻译任务最终获得的词分布,即第二句子的最终翻译结果的词分布。
可选的,本申请实施例中,第二句子的第一翻译结果所包含词语的跳变率,第一句子的翻译结果与第二句子的第一翻译结果之间的相似度(可称为第一相似度)之间具有相关关系。示例性的,相似度越高,跳变率越小。
首先,介绍语句之间的相似度这一概念。相似度,可以用于表征语句之间的差异程度。语句之间的相似度越高,差异程度越低,语句之间的相似度越低,差异程度越高。
作为一种可能的实现方式,电子设备在计算语句之间的相似度时,先获得上一句翻译结果和本句翻译结果,搜索上一句翻译结果中的最大连续字符串,以及搜索本句翻译结果的最大连续字符串,并对相应的最大连续字符串进行对齐。之后,将上一句翻译结果中的最大连续字符串以及本句翻译结果中的最大连续字符串输入语义相似度模型进行相似度计算。所述语义相似度模型的训练样本包括:多个翻译任务中的相应翻译结果、翻译结果对应的标签,所述翻译结果的标签用于表征所述翻译结果与上次翻译结果之间的相似度。
本申请实施例中,将使用标签训练模型的方式称为监督学习方式。
示例性的,如图9A所示,在某次翻译任务中,本次翻译任务中的翻译结果为“这一问题将更能定义您的职业成功”,上次翻译任务中的翻译结果为“这个问题将定义您的职业成功”。电子设备分别搜索出两次翻译结果中的最大连续字符串,并对最大连续字符进行对齐。其中,对齐的词语(或称token)已用椭圆框圈出。电子设备调用语义相似度模型,经语义相似度模型计算,确定本次翻译任务的翻译结果与上次翻译任务的翻译结果之间的相似度为0.75。
再示例性的,如图9A所示,在某次翻译任务中,本次翻译任务中的翻译结果为“这一问题将比任何问题都更能定义您的职业成功”,上次翻译任务中的翻译结果为“这个问题将更能定义您的职业成功”。电子设备分别搜索出两次翻译结果中的最大连续字符串,经语义相似度模型计算,本次翻译任务的翻译结果与上次翻译任务的翻译结果之间的相似度为0.2。
图9B给出了相似度模型的一种训练方法。其中,相似度模型的训练样本是多个句子以及句子对应的标签,标签用于表征句子之间的相似度。示例性的,训练样本包括图9A所示的句子1-句子3。可选的,训练样本还可以包括句子1与句子2之间的相似度、句子2与句子3之间的相似度。经过训练,将两个句子输入相似度模型,相似度模型可以输出这两个句子之间的相似度。
本申请实施例中,可以基于上述语义相似度模型,训练跳变率模型,用于计算并输出与语句相似度有关的跳变率。
如下,先给出跳变率的计算原理。作为一种可能的实现方式,对于所述第二句子的第一翻译结果中的目标词语:若所述第一句子的翻译结果中不存在与所述目标词语相同的词语,则β
示例性的,仍如图9A所示,某次翻译结果为“这一问题更能定义您的职业成功”,该翻译结果的上次翻译结果是“这一问题将定义您的职业成功”。其中,两句翻译结果之间的相似度为0.75,那么,对于本句翻译结果中没有与上句翻译结果对齐的词语(“更能”)这两个词语的跳变率为1-0.75=0.25。对于本句翻译结果中与上句翻译结果对齐的词语(“这一问题将定义您的职业成功”),这些词语的跳变率记为0。
本申请实施例中提及的“本次翻译结果所包含词语的跳变率”,可以指本次翻译结果中的词语与上次翻译结果中对应的词语之间的跳变率。
再示例性的,仍如图9A所示,某次翻译结果为“这一问题比任何问题都更能定义您的职业成功”,该翻译结果的上次翻译结果是“这一问题将更能定义您的职业成功”。其中,两句翻译结果之间的相似度为0.2,那么,对于本句翻译结果中没有与上句翻译结果对齐的词语(“比任何问题都”)这六个词语的跳变率为1-0.2=0.8。对于本句翻译结果中与上句翻译结果对齐的词语(“这一问题更能定义您的职业成功”),这些词语的跳变率记为0。
其中,对于某个词语来说,跳变率越接近0,代表该词语在本句翻译结果中的语义与在上句翻译结果中的语义越相近。特别的,在跳变率为0时,代表该词语出现本句翻译结果中,也出现在上句翻译结果中。词语的跳变率接近1,代表该词语在本句翻译结果中的语义与在上句翻译结果中的语义差异越大。
可选的,上述跳变率满足如下公式1:
β
其中,β
可选的,上述目标词分布p′(t
p′(t
其中,p′(t
示例性的,如图9A,句子1为第一句子S1(this one question will define yourprofessional success)的翻译结果,句子2为第二句子S2(this one question willdefine your professional success more)的初步翻译结果(即第一翻译结果),s
上述介绍了计算跳变率的原理。接下来,介绍基于上述跳变率计算原理的跳变率模型的训练方法。其中,跳变率模型用于计算、输出跳变率。
图9B还示出了跳变率模型的训练方法。跳变率模型的训练样本包括目标语言句子、目标语言句子之间的相似度、相邻的目标语言句子之间的对齐结果以及标签。其中,标签用于表征目标语言句子所包含词语的跳变率。作为一种可能的实现方式,相似度模型和跳变率模型可以同时训练,将多个目标语言句子输入相似度模型和跳变率模型,并将相似度模型输出的目标语言句子之间的相似度、目标语言句子之间的对齐结果输入跳变率模型,相似度和对齐结果作为跳变率模型的另一部分训练样本。
示例性的,跳变率模型的训练样本包括:目标语言句子1(这一问题将定义您的职业成功)、句子2(这一问题将更能定义您的职业成功)、句子3(这一问题将比其他任何问题都更能定义您的职业成功)、句子1与句子2之间的相似度、句子2与句子3之间的相似度、句子1与句子2之间的对齐结果(如图9A的椭圆框所示)、句子2与句子3之间的对齐结果(如图9A的椭圆框所示)以及句子1、句子2、句子3中每个词语对应的跳变率(即标签)。如此,经训练,使得跳变率模型能够基于输入的两个句子,输出其中一个句子所包含词语(相对于另一句子)的跳变率。
在另一些实施例中,可以采用迁移学习的训练方法,训练多个模型,分别用于不同的机器学习任务。不同任务之间可以有关联关系。可选的,一些任务的输出结果能够被其他任务使用。比如,分别训练跳变率模型以及NMT模型。
在一些实施例中,可以采用多任务学习的训练方法,训练一个模型,用于执行多个机器学习任务。比如,训练一个NMT模型(比如图8所示NMT模型)用于计算、输出跳变率以及计算第一翻译结果对应的词分布。该方法中,可视为将跳变率模型集成在NMT模型中,NMT模型同时具有计算跳变率以及计算翻译结果的词分布的能力。
如下分别介绍这两种训练模型的方法。
多任务学习的训练方法:如图9C所示,训练NMT模型,使得该模型能够输出跳变率以及目标词分布。作为一种可能的实现方式,NMT模型所需的训练样本包括:目标语言句子、目标语言句子之间的相似度、相邻的目标语言句子之间的对齐结果、源语言句子。可选的,训练样本还包括用于表征跳变率的标签。其中,目标语言句子、目标语言句子之间的相似度、相邻的目标语言句子之间的对齐结果,用于训练NMT模型,使得NMT模型具有输出跳变率的能力。源语言句子,作为训练样本,用于训练NMT模型,使得NMT模型具有输出翻译结果的能力。
以图7A中的翻译任务为例,本次翻译任务为翻译S2,上次翻译任务为翻译S1,上次翻译任务的翻译结果即S1的翻译结果。训练NMT模型时,将S2的文本信息、S2的文本信息的标签(即S2的最终翻译结果的词分布)以及S1的翻译结果作为训练样本输入NMT模型。类似的,将S3的文本信息、S3的文本信息的标签(即S3的最终翻译结果的词分布)以及S2的翻译结果作为训练样本输入NMT模型。每次翻译任务中待翻译语音信息的文本信息、该文本信息对应的标签以及该次翻译任务之前已得到的翻译结果,可称为一组训练样本。通过多组上述训练样本,迭代、更新NMT模型的权重等参数,使得NMT模型能够输出相应翻译任务中待翻译语音的翻译结果的词分布,以及输出该翻译任务中翻译结果所包含词语的跳变率
迁移学习的训练方法:该训练方式中,训练该模型所需的训练样本包括:本次翻译任务中待翻译语音信息的文本信息、该文本信息对应的标签以及上次翻译任务的翻译结果。迁移学习所使用的训练样本与多任务学习所使用的训练样本的类型相同。所不同的是,多任务学习与迁移学习应用的场景不同。比如,在训练数据较多时,可以利用多任务学习方法,训练规模较大的模型,该模型可以用来输出跳变率以及翻译结果的词分布。在训练数据较少时,这些训练数据可能不足以训练一个规模较大的模型,因此,可以利用较少的训练数据训练轻量级的跳变率模型,用来输出跳变率,利用较少的训练数据训练轻量级的NMT模型,用来输出翻译结果的词分布。
图10示出了使用迁移学习得到的跳变率模型以及NMT模型执行机器翻译的过程。与图8对应的技术方案中使用NMT模型同时输出跳变率以及翻译结果的词分布不同,图10对应的技术方案中,使用单独的跳变率模型输出跳变率,使用NMT模型输出翻译结果的词分布。
具体的,图10对应的技术方案中,编码模块,获取源语言的第二句子,并对第二句子进行处理,得到该第二句子对应的编码向量。还用于将该编码向量输出至解码模块。
解码模块,与编码模块的输出端连接,用于接收来自编码模块的编码向量,并用于对编码向量进行处理,得到上述第二句子的第一翻译结果的词分布。
跳变率模型,用于获取源语言的第二句子以及源语言的第一句子的翻译结果的词分布,并根据第二句子以及第一句子的翻译结果的词分布,确定跳变率。
作为一种可能的实现方式,图10的技术方案中,NMT模型和跳变率模型可以构成第一模型。其中,NMT模型可以称第一子模型,跳变率模型可称第二子模型。该训练方式中,第一子模型与第二子模型的参数是解耦的。
修正模块,与NMT模型的输出端、跳变率模型的输出端连接。用于获取源语言的第一句子的翻译结果的词分布,从NMT模型接收第二句子的第一翻译结果的词分布,从跳变率模型接收跳变率,并根据第一句子的翻译结果对应的词分布、第二句子的第一翻译结果对应的词分布以及该跳变率,确定第二句子的第二翻译结果的词分布。
作为一种可能的实现方式,图10所示通过迁移学习方法训练的NMT模型的损失函数记为Loss_NMT。图8所示通过多任务学习方法训练的NMT模型的损失函数为Loss=Loss_NMT+NLLLoss(β’,β)。其中,NLLLoss(β’,β)是负对数似然函数。
图11示出了本申请实施例的语言翻译方法中各模块之间的交互。如图11所示,该语言翻译方法包括:
S101、AI字幕应用检测到用于指示机器翻译的指令。
AI字幕应用为可以使用AI字幕功能的应用,包括但不限于视频、音乐等应用。示例性的,该实施例中,以图7B所示视频应用为例。
S102、AI字幕应用检测到源语言的语音流1,并向服务器发送语音流1。
S103、服务器中的ASR模型将语音流1转化为文本信息1。
S104、ASR模型向第一模块发送源语言的文本信息1。
可选的,第一模块中集成有修正模块的功能。
S105、第一模块根据文本信息1,解析并向NMT模型分发翻译任务1。
S106、NMT模型根据翻译任务1,获得语音流1的目标语言的翻译结果1以及翻译结果1中词语的跳变率1。
S107、NMT模型向第一模块反馈翻译结果1、跳变率1。
S108、第一模块获得翻译结果1对应的目标语言的字幕1。
S109、第一模块向AI字幕应用反馈字幕1。
S110、AI字幕应用通过显示驱动调用显示屏显示字幕1。
示例性的,若视频应用采集到的语音流为英文this one question will defineyour professional success,则开启AI字幕功能后,手机可以在显示屏显示如图7B的(2)所示字幕。
S111、AI字幕应用采集并向ASR模型发送源语言的语音流2。
S112、ASR模型将语音流2转化为源语言的文本信息2。
S113、ASR模型向第一模块发送源语言的文本信息2。
S114、第一模块根据文本信息2,解析并向NMT模型分发翻译任务2。
S115、NMT模型根据翻译任务2,获得目标语言的翻译结果2以及翻译结果2中词语的跳变率2。
S116、NMT模型向第一模块反馈翻译结果2、跳变率2。
S117、第一模块根据翻译结果1、翻译结果2、跳变率2,获得对应的目前语言的字幕2。
可选的,第一模块中集成有上述修正模块,用于根据上次翻译结果1、本次翻译结果2、跳变率2,生成翻译结果2的目标词分布,并根据目标词分布获得对应的字幕2。
S118、第一模块向AI字幕应用发送字幕2。
S119、AI字幕应用通过显示驱动调用显示屏显示字幕2。
示例性的,若语音流2为英文this one question will define yourprofessional success more,那么,视频应用采集该语音流2,可以将语音流2输入ASR模型,由ASR模型、NMT模型、第一模块处理后,得到相应的字幕。比如,得到如图7B的(2)所示字幕,并在显示屏上显示该字幕。
本申请实施例提供的语言翻译方法,能够根据当前的翻译语境,获得当前翻译语境中本次翻译结果所包含词语的跳变率,并基于该跳变率自动识别出需要改变的翻译结果,自适应生成最终的目标词分布。其中,目标词分布(比如用于生成中文字幕的词分布)不再为固化的词分布,比如不再固化为采用上次翻译结果的词分布,或固定采用本次翻译结果的词分布,而是可以随翻译语境变化(跳变率相应变化)得到非固化的目标词分布,因此,生成的目标词分布更加契合翻译语境,能够提升电子设备的翻译性能。比如,模型生成的翻译结果跳变率更低,保证已经翻译的内容不再发生变化,可以更好的保持用户对源视频/音频内容的专注度。
本申请实施例还提供一种字幕生成方法,可以应用在重翻译的技术架构下。在生成翻译结果后,可以增加新的功能模块用于控制字幕呈现,形成自适应的后缀遮盖方案。可选的,可以将待翻译的句子输入模型,由模型输出待翻译的句子对应的呈现字幕。
首先,对训练模型的方法进行介绍。示例性的,可以利用强化学习方式,训练模型。训练模型的流程可参见图12。该流程包括如下步骤S201至S206:
S201、获取初始的观测状态(state)。
其中,初始的观测状态包括本次翻译结果和上次翻译结果。
S202、从动作空间中选择动作(action)。
作为一种可能的实现方式,根据贪心算法(还可以为其他算法),从动作空间中选择动作。可选的,动作,可以是电子设备在显示屏的相应区域或位置呈现字符(词语)。参见表1,为一种示例性的动作空间:
表1
上述表1所示的动作空间包括5个动作,每一动作对应显示规则和一个动作分布值。其中,显示规则表示显示当前位置历史上的第n(n为正整数)个字符或显示遮盖标识(Mask,简称M)或显示本次翻译结果。动作分布值用于表示与显示规则对应的概率分布。动作分布值中各概率的相加结果为1。其中,显示遮盖标识,可以理解为在相应位置不显示词语。
其中,在贪心算法中,每一次从动作空间中选取电子设备所执行的动作时,有ε(取值范围小于或等于1,且大于或等于0)的概率做随机探索,且有1-ε的概率选取Q值最大的动作,也就是说,在每一次选取动作时,有ε的概率从动作空间中随机选取一个动作,有1-ε的概率从动作空间中选择Q值最大的动作。
这里,动作空间为电子设备所执行的一系列动作的集合,比如,包括电子设备在显示屏上相应位置显示词语。
上述仅以贪心算法为例对选择所执行动作的方法进行说明,在实际应用中,可以采用其他算法选择动作,这里不再一一列举。
以表2为例,说明选取动作的步骤。
表2
表2给出了翻译this one question will define your professional successmore than any other这一英文句子的过程中,每次翻译任务对应的源语言句子以及目标语言句子。示例性的,在翻译英文句子this one question will define yourprofessional时,选取动作2,在显示屏的p0位置,显示历史上出现在该位置的第一个字符(即“这”),选取动作3,在显示屏的p1位置,显示历史上出现在该位置的第二个字符(即“一”),以此类推,选取动作1,在显示屏的p10、p11位置,显示遮盖标识,或者在p10、p11位置不显示新增词语的翻译结果(即不在p10、p11位置显示professional的翻译结果)。
再示例性的,在翻译英文句子this one question will define yourprofessional more时,对于p5、p6位置的显示规则,选取动作5,在p5、p6位置显示相应词语的本次翻译结果,即显示more这一词语的本次翻译结果“更能”。
S203、执行动作,并获得来自环境的反馈,以及获得执行动作后的新的观测状态。
比如,初始的观测状态包括当前的翻译结果,根据翻译结果,以及一定算法,比如贪心算法,从动作空间中选取动作5(假设动作5是显示如图7B的(3)所示字幕)。之后,执行动作5。此时,获取环境针对动作的一个反馈,该反馈用于对执行动作5进行奖励或惩罚,进而将观测状态更新为新的观测状态,新的观测状态包括执行动作5后,电子设备新的翻译结果。
可以理解的是,在执行动作5后,若该电子设备的翻译性能满足第一条件,则获取的反馈r为奖励,该奖励表征执行动作5可保证电子设备的翻译性能,在执行动作5后,若电子设备的翻译性能不满足第一条件,则获取的反馈r为惩罚,该惩罚表征执行动作5时,电子设备的翻译性能不佳。
可以理解的是当执行某一动作后,得到的奖励较多,说明该动作对应的Q值较大。
作为一种可能的实现方式,反馈r可以定义为如下的函数形式:
r=a*DELAY+b*CHANGE+c*QUALITY。
其中,a是DELAY这一参数的权重、b是CHANGE这一参数的权重、c是QUALITY参数的权重,a、b、c可依据使用场景灵活设定。比如,可以随业务偏好变化,当用户更偏好要求语言翻译的低时延,可以将a的数值增加。
DELAY表征上次翻译结果与本次翻译结果之间的时延,可以用来衡量翻译性能中的时效性。可选的,
CHANGE表征本次翻译结果与上次翻译结果之间的变化,或者用于表征本次翻译结果所包含词语的跳变率,或者用于表征本次翻译结果与上次翻译结果之间的相似度。
可选的,
QUALITY用于表征翻译性能的好坏或表征翻译质量。
可选的,QUALITY=BLEU。句子没结束QUALITY为0。
可以看出,每次执行相应动作,即在显示屏的相应区域或位置显示字幕,都能通过反馈函数计算出当前的奖励或惩罚。
S204、更新字幕呈现模型(也可以称为第二模型)。
作为一种可能的实现方式,通过随机梯度下降(Stochastic Gradient Descent,SGD)或者小批量梯度下降(Mini-Batch Gradient Descent,MBGD)对字幕呈现模型进行更新。
更新字幕呈现模型包括但不限于更新字幕呈现模型的动作网络的参数和评价网络的参数。
其中,动作网络用于通过观察环境状态,预测并输出当前应该执行的策略(policy),评价网络用于评估并输出当前策略的优劣。策略用于确定在显示屏的显示位置或区域的显示方式。包括显示历史的翻译结果、或显示本次翻译、或不显示。可选的,随着对字幕呈现模型进行更新,可以得到一个字幕呈现模型,该字幕呈现模型能够预测并输出目标策略,目标策略能够使得奖励最大,即翻译性能最好。
这里,更新字幕呈现模型的具体流程可参见现有技术,本申请实施例不再赘述。
S205、判断更新的第二模型是否收敛,若是,则执行S206,若否,则继续执行S201至S204,并判断更新后的第二模型是否收敛,直至更新后的第二模型收敛。
其中,模型收敛指的是当到达给定的迭代次数后,模型输出的变化较小。或者,在相邻几次迭代之间,模型输出的变化很小,比如第一次迭代后,模型输出结果为结果1,第二次迭代后,模型输出结果为结果2,结果1和结果2的差值是一个很小的数。
S206、存储该更新的第二模型。
可选的,将更新的字幕呈现模型存储至存储器中。
将收敛的字幕呈现模型作为训练好的字幕呈现模型,并使用该字幕呈现模型。
通过该方法,能够在实时翻译的同时,对翻译结果进行自适应的后缀遮盖,从而达到减少字幕跳变的目的。减少字幕跳变可以是减少字幕的前缀跳变或后缀跳变。
图13示出了本申请实施例提供的语言翻译方法的另一流程。该方法包括:
S301、电子设备获取源语言的第一句子的翻译结果的词分布以及源语言的第二句子。
其中,所述第二句子包括所述第一句子中的词语以及第一词语;
S302、所述电子设备获取所述第二句子的第一翻译结果的词分布以及所述第二句子的第一翻译结果所包含词语的跳变率。
其中,所述跳变率与第一相似度有关;所述第一相似度为所述第一句子的翻译结果与所述第二句子的第一翻译结果之间的相似度。
作为一种可能的实现方式,所述电子设备将所述第一句子的翻译结果的词分布以及所述第二句子输入第一模型,并通过所述第一模型获取所述第二句子的第一翻译结果的词分布以及所述跳变率。
在一些实施例中,若第一模型为图8所示所示NMT模型,则电子设备将第一句子的翻译结果的词分布以及所述第二句子输入NMT模型,并通过NMT模型确定并输出第二句子的第一翻译结果的词分布以及所述跳变率。
其中,所述NMT模型是通过训练样本训练得到的,所述训练样本包括:多个目标语言句子、所述多个目标语言句子中相邻目标语言句子之间的相似度、相邻目标语言句子之间的词语对齐结果、多个源语言句子、所述目标语言句子对应的第一标签、所述源语言句子对应的第二标签,所述第一标签用于表征所述目标语言句子所包含词语的跳变率,所述第二标签用于表征所述源语言句子的翻译结果。NMT模型的训练过程可参见图9C以及相应描述,这里不再赘述。
在另一些实施例中,若第一模型包括图10所示的NMT模型(第一子模型)和跳变率模型(第二子模型),则所述电子设备将所述第一句子的翻译结果的词分布以及所述第二句子输入跳变率模型,以及将第二句子输入NMT模型,并通过所述NMT模型获取所述第二句子的第一翻译结果的词分布,通过所述跳变率模型获取所述跳变率。
其中,所述NMT模型是通过多个训练样本训练得到的,所述多个训练样本包括:多个源语言句子、所述源语言句子对应的第二标签,所述第二标签用于表征所述源语言句子的翻译结果。
所述跳变率模型是通过多个训练样本训练得到的,所述多个训练样本包括:多个目标语言句子、所述多个目标语言句子中相邻目标语言句子之间的相似度、相邻目标语言句子之间的词语对齐结果、所述目标语言句子对应的第一标签、所述第一标签用于表征所述目标语言句子所包含词语的跳变率。示例性的,跳变率模型的训练过程可参见图9B以及相应描述,这里不再赘述。
S303、所述电子设备根据所述第一句子的翻译结果的词分布、所述第二句子的第一翻译结果的词分布以及所述跳变率,确定所述第二句子的第二翻译结果的词分布。
需要说明的是,本申请实施例提及的各功能模块的名称仅是示例,并不构成对模块具有功能的限定。
需要说明的是,上述方法流程中的步骤仅是示例性的。其中某些步骤还可以替换为其他步骤,或者增加或减少部分步骤。
上述各方法实施例的流程中的一些操作任选地被组合,并且/或者一些操作的顺序任选地被改变。
并且,各流程的步骤之间的执行顺序仅是示例性的,并不构成对步骤之间执行顺序的限制,各步骤之间还可以是其他执行顺序。并非旨在表明执行次序是可以执行这些操作的唯一次序。本领域的普通技术人员会想到多种方式来对本文的操作进行重新排序。另外,应当指出的是,对于某个方法来说,本文结合本文的其他方法的其他过程的细节同样以类似的方式适用于上文结合该方法。
示例性的,图13是以服务器进行翻译为例对技术方案进行说明,在另一些实施例中,也可以是终端自己进行翻译,即ASR模型、NMT模型、修正模块位于终端中。
本申请另一些实施例提供了一种装置,该装置可以是上述电子设备(比如折叠屏手机)。该装置可以包括:显示屏、存储器和一个或多个处理器。该显示屏、存储器和处理器耦合。该存储器用于存储计算机程序代码,该计算机程序代码包括计算机指令。当处理器执行计算机指令时,电子设备可执行上述方法实施例中手机执行的各个功能或者步骤。该电子设备的结构可以参考图5或图4所示的电子设备。
其中,该电子设备的核心结构可以表示为图14所示的结构,该核心结构可包括:处理模块1301、输入模块1302、存储模块1303、显示模块1304。
处理模块1301,可包括中央处理器(CPU)、应用处理器(Application Processor,AP)或通信处理器(Communication Processor,CP)中的至少一个。处理模块1301可执行与用户电子设备的其他元件中的至少一个的控制和/或通信相关的操作或数据处理。具体地,处理模块1301可用于根据一定的触发条件,控制主屏上显示的内容。或者根据预设规则确定屏幕上显示的内容。处理模块1301还用于将输入的指令或数据进行处理,并根据处理后的数据确定显示样式。
输入模块1302,用于获取用户输入的指令或数据,并将获取到的指令或数据传输到电子设备的其他模块。具体地说,输入模块1302的输入方式可以包括触摸、手势、接近屏幕等,也可以是语音输入。例如,输入模块可以是电子设备的屏幕,获取用户的输入操作并根据获取到的输入操作生成输入信号,将输入信号传输至处理模块1301。
存储模块1303,可包括易失性存储器和/或非易失性存储器。存储模块用于存储用户终端设备的其他模块中的至少一个相关的指令或数据,具体地说,存储模块可记录终端界面元素UI所在界面的位置。
显示模块1304,可包括例如液晶显示器(LCD)、发光二极管(LED)显示器、有机发光二极管(OLED)显示器、微机电系统(MEMS)显示器或电子纸显示器。用于显示用户可观看的内容(例如,文本、图像、视频、图标、符号等)。
可选的,图14所示结构还可通信模块1305,用于支持电子设备与其他电子设备通信。例如,通信模块可经由无线通信或有线通信连接到网络,以与其他个人终端或网络服务器进行通信。无线通信可采用蜂窝通信协议中的至少一个,诸如,长期演进(LTE)、高级长期演进(LTE-A)、码分多址(CDMA)、宽带码分多址(WCDMA)、通用移动通信系统(UMTS)、无线宽带(WiBro)或全球移动通信系统(GSM)。无线通信可包括例如短距通信。短距通信可包括无线保真(Wi-Fi)、蓝牙、近场通信(NFC)、磁条传输(MST)或GNSS中的至少一个。
需要说明的是,本申请方法实施例中的各步骤的描述均可援引到装置对应的模块,这里不再赘述。
本申请实施例还提供一种芯片系统,如图15所示,该芯片系统包括至少一个处理器1401和至少一个接口电路1402。处理器1401和接口电路1402可通过线路互联。例如,接口电路1402可用于从其它装置(例如电子设备的存储器)接收信号。又例如,接口电路1402可用于向其它装置(例如处理器1401)发送信号。示例性的,接口电路1402可读取存储器中存储的指令,并将该指令发送给处理器1401。当指令被处理器1401执行时,可使得电子设备执行上述实施例中的各个步骤。当然,该芯片系统还可以包含其他分立器件,本申请实施例对此不作具体限定。
本申请实施例还提供一种计算机存储介质,该计算机存储介质包括计算机指令,当计算机指令在上述电子设备上运行时,使得该电子设备执行上述方法实施例中手机执行的各个功能或者步骤。
本申请实施例还提供一种计算机程序产品,当计算机程序产品在计算机上运行时,使得计算机执行上述方法实施例中手机执行的各个功能或者步骤。
通过以上实施方式的描述,所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。
在本申请所提供的几个实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅是示意性的,例如,模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个装置,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是一个物理单元或多个物理单元,即可以位于一个地方,或者也可以分布到多个不同地方。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个可读取存储介质中。基于这样的理解,本申请实施例的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该软件产品存储在一个存储介质中,包括若干指令用以使得一个设备(可以是单片机,芯片等)或处理器(processor)执行本申请各个实施例方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(read only memory,ROM)、随机存取存储器(random access memory,RAM)、磁碟或者光盘等各种可以存储程序代码的介质。
以上内容,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何在本申请揭露的技术范围内的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。