基于超声波感知与知识蒸馏的唇语识别系统及方法
文献发布时间:2023-06-19 11:32:36
技术领域
本发明属于智能感知技术和人工智能技术领域,具体指代一种基于超声波感知与知识蒸馏的唇语识别系统及方法。
背景技术
随着智能移动设备的快速发展,人们的交流方式正在发生变化,人们开始随时随地使用智能设备进行语音通信,语音识别等服务正被广泛的使用。但这种服务在很多场合下,却会给使用者带来诸多不便。首先,在某些要求安静的公共场合如图书馆,会议室中,使用语音识别服务会打扰到其他人。另外,在嘈杂的环境下,语音质量还会受到周围噪音的干扰而显著下降。
使用唇语识别技术可以弥补语音识别的不足。现有的唇语识别一般是利用计算机视觉技术来实现的。但是基于视觉的唇语识别容易受到周围光照条件的影响,而且使用这种方法进行唇语识别的模型规模较大,难以应用到移动设备上。所以研究人员开始探索使用超声波的方式在智能移动设备上进行唇语识别。
现有的超声波唇语识别系统可以做到在智能手机上进行识别的功能。但是该系统与仅使用视觉模态的唇语识别系统相比,识别准确率有所下降。
发明内容
针对于上述现有技术的不足,本发明的目的在于提供一种基于超声波感知与知识蒸馏的唇语识别系统及方法,以解决现有的超声波唇语识别模型识别准确率不高的问题。
为达到上述目的,本发明采用的技术方案如下:
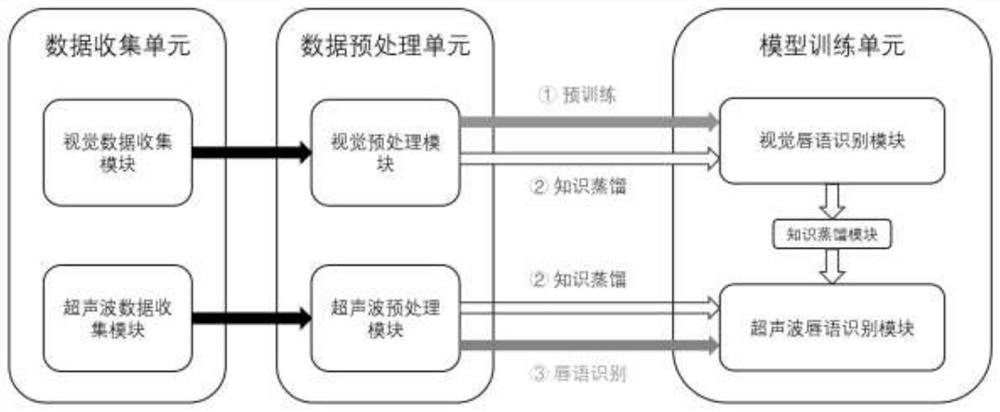
本发明的一种基于超声波感知与知识蒸馏的唇语识别系统,包括:数据收集单元,数据预处理单元,模型训练单元;其中,
数据收集单元包括:超声波数据收集模块,视觉数据收集模块;
所述超声波数据收集模块,用于采集用户无声说话时唇部反射的超声波数据;
所述视觉数据收集模块,用于采集模型训练阶段用户无声说话时人脸正面的视频数据;
数据预处理单元包括:超声波预处理模块,视觉预处理模块;
所述超声波预处理模块,用于从上述唇部超声波数据中提取信号梯度特征;
所述视觉预处理模块,用于从上述人脸正面的视频数据中逐帧提取唇部区域特征;
模型训练单元包括:超声波唇语识别模块,视觉唇语识别模块,知识蒸馏模块;
所述超声波唇语识别模块,在训练阶段利用信号梯度特征训练超声波唇语识别模型,在识别阶段将信号梯度特征翻译成为文本;
所述视觉唇语识别模块,利用唇部区域特征训练视觉唇语识别模型;
所述知识蒸馏模块,用于将视觉唇语识别模块训练得到的视觉唇语识别模型的参数信息蒸馏到超声波唇语识别模型中,以指导超声波唇语识别模型的训练。
进一步地,所述超声波预处理模块包括:信号滤波模块、时频变换模块、信号梯度特征提取模块以及超声波数据归一化模块;
信号滤波模块:由唇部运动导致的多普勒频移在[-20,40]Hz的区间内,使用巴特沃斯带通滤波器过滤原始超声波信号得到频率范围在[20000-20,20000+40]Hz区间的信号;n阶巴特沃斯滤波器的频率响应和增益的公式如下:
式中,G(ω)表示滤波器的增益,H(jω)表示信号的频响,G
时频变换模块:将超声波信号进行短时傅里叶变换操作,得到时频特征,傅里叶变换时每一帧窗口的大小为100ms,帧移10ms,加窗函数选择汉宁窗;短时傅里叶变换的公式如下:
式中,x(m)为输入信号,w(m)为窗函数,在时间上反转并且有n个样本的偏移量,X(n,ω)是时间n和频率ω的二维函数,e是自然对数底数,j为虚数单位;通过上述公式计算得到一个经过短时傅里叶变换后的时频矩阵S;
信号梯度特征提取模块:在得到的时频矩阵S上,使用后一时间帧的特征减去前一时间帧的特征得到信号梯度特征;信号梯度特征计算公式如下:
S=[s(0),s(1),s(2),…,s(T)]
G=[g(1),g(2),…,g(T)]
g(t)=s(t)-s(t-1)
式中,S表示时频矩阵,s(t)表示时频矩阵t时刻的向量,G表示信号梯度矩阵,g(t)表示信号梯度矩阵t时刻的向量;
超声波数据归一化模块:求所有信号梯度数据的最大值max和最小值min,使用如下公式将信号梯度特征归一化到0-1:
式中,Y是输出的信号梯度特征,X是原始的信号梯度特征。
进一步地,所述视觉预处理模块包括:唇部提取模块,视觉数据归一化模块;
唇部提取模块:使用开源的人脸识别库(dlib) 从视频中逐帧检测人脸对应的68个特征点,取最后20个特征点所包含的区域即为嘴唇区域;
视觉数据归一化模块:通过对唇部提取模块提取到的唇部区域图片的像素值除以255将所有数据归一化到0-1。
进一步地,所述超声波唇语识别模块在训练阶段利用信号梯度特征训练超声波唇语识别模型,在识别阶段将信号梯度特征输入到超声波唇语识别模型中翻译成为文本。
上述的超声波唇语识别模型采用resnet2d_18网络作为模型的架构,包含:2D模型深度卷积模块,2D模型残差模块,2D模型池化模块,2D模型全连接模块;其中,
2D模型深度卷积模块:采用一个深度2d卷积F
y
式中,x
2D模型残差模块:采用一个深度2d卷积F
y
式中,x
2D模型池化模块:使用2d平均池化进行计算,即每次对输入数据的一个固定形状窗口(又称池化窗口)中的元素计算平均输出;
2D模型全连接模块:用于输出最后的特征向量,其公式表达如下:
Y
式中,X
进一步地,所述视觉唇语识别模块将唇部区域特征输入到视觉唇语识别模型中,对视觉唇语识别模型进行预训练,之后在知识蒸馏时指导超声波唇语识别模型进行训练。
上述视觉唇语识别模型采用resnet3d_18网络作为模型的架构,包含3D模型深度卷积模块,3D模型残差模块,3D模型池化模块,3D模型全连接模块:其中,
3D模型深度卷积模块:采用一个深度3d卷积G
y
式中,x
3D模型残差模块:采用一个深度3d卷积G
y
式中,x
3D模型池化模块:使用3d平均池化进行计算,即每次对输入数据的一个固定形状窗口(又称池化窗口)中的元素计算平均输出。
3D模型全连接模块:用于输出最后的特征向量,其公式表达如下:
Y
式中,X
进一步地,所述知识蒸馏模块将一系列2D模型残差模块最后输出的一维向量x
L=g(f(x
式中,f表示一种线性映射,g表示均方误差函数,L表示计算的均方误差,使用反向传播的方式仅更新超声波唇语识别模块的参数。
本发明的一种基于超声波感知和知识蒸馏的唇语识别方法,包括步骤如下:
1)在模型训练阶段,采集用户无声说话时唇部反射的超声波信号,及人脸正面的视频数据;
2)对采集到的超声波信号进行滤波,时频变换,并通过后一帧减前一帧的方式以及归一化计算信号梯度特征;
3)对采集到的视频数据逐帧进行人脸检测,在检测到人脸的基础上切割出唇部区域,并对得到的每一帧唇部数据进行归一化,得到唇部区域特征;
4)将唇部区域特征输入到视觉唇语识别模型中,对视觉唇语识别模型进行预训练;
5)在使用信号梯度特征训练超声波唇语识别模型的同时,还需将唇部区域特征输入到视觉唇语识别模型中,在此过程中将视觉唇语识别模型预训练得到的模型信息蒸馏到超声波唇语识别模型中;
6)在唇语识别阶段,采集唇部的超声波数据并进行数据预处理得到信号梯度特征;
7)将得到的信号梯度特征输入到超声波唇语识别模型中进行识别,输出结果。
进一步地,所述步骤1)具体步骤如下:
11)使用智能移动设备的扬声器发出20kHz的超声波,智能移动设备的麦克风接收用户无声说话时唇部反射的超声波信号;
12)使用其他智能移动设备的前置摄像头收集人脸正面的视频数据。
进一步地,所述步骤2)具体步骤如下:
21)对采集到的超声波信号使用巴特沃斯带通滤波器过滤得到频率范围在[20000-20,20000+40]Hz区间的信号;
22)对过滤后的信号进行短时傅里叶变换操作,得到时频矩阵;
23)对时频矩阵采用后一帧减前一帧的方式得到原始的信号梯度特征;
24)得到原始的信号梯度特征后,计算信号梯度特征中的最大值和最小值,以最大值最小值为界限,将信号梯度特征归一化,得到最终的信号梯度特征。
进一步地,所述步骤3)具体步骤如下:
31)使用现有的人脸识别库(dlib)从采集到的视频数据中逐帧检测人脸对应的68个特征点,取最后20个特征点所包含的区域即为嘴唇区域;
32)通过对提取到的唇部区域图片的像素值除以255将所有数据归一化到0-1,得到唇部区域特征。
进一步地,所述步骤4)具体步骤如下:
41)将唇部区域特征输入到视觉唇语识别模型中,得到预测的输出;
42)使用交叉熵的方式计算真实标签和预测输出之间的损失,再通过反向传播的方式更新视觉唇语识别模型的参数。
进一步地,所述步骤5)具体步骤如下:
51)将信号梯度特征输入到超声波唇语识别模型中,得到一系列2D模型残差模块最后输出的一维向量,及最终的预测输出;
52)将唇部区域特征输入到视觉唇语识别模型中,得到一系列3D模型残差模块最后输出的一维向量;
53)使用交叉熵的方式计算真实标签和预测输出之间的损失,再通过反向传播的方式更新超声波唇语识别模型的参数;
54)在知识蒸馏模块中将超声波唇语识别模型和视觉唇语识别模型中间输出的一维向量先映射到同一个向量空间中,再计算两者的均方误差损失,利用反向传播的方式更新超声波唇语识别模型的参数。
进一步地,所述步骤6)中超声波数据采集的方式与步骤1)的方式相同,信号梯度特征的计算方式与步2)的方式相同。
本发明在模型训练阶段,使用智能移动设备内置的扬声器和麦克风收集用户无声说话时唇部反射的超声波数据,并同时使用另一台智能移动设备前置摄像头采集用户无声说话时唇部的视频数据;之后,对采集的超声波数据进行去噪,时频转换等预处理得到信号梯度特征,对视频数据进行逐帧唇部区域提取等预处理操作得到唇部区域特征。之后,先用唇部区域特征预训练视觉唇语识别模型,之后将视觉唇语识别模型和超声波唇语识别模型一起训练,把视觉唇语识别模型的模型信息蒸馏到超声波唇语识别模型中。而在唇语识别阶段,只需要利用智能移动设备收集用户无声说话时唇部反射的超声波数据,经过数据预处理得到信号梯度特征,再将信号梯度特征输入到超声波唇语识别模型进行识别,即可得到输出的目标语句。
本发明的有益效果:
(1)本发明可以利用智能手机来实现唇语识别的功能,为智能手机增加了一种新的人机交互方式;满足了用户在语音识别不能应用的场景如安静的图书馆或者会议室中进行文字输入的需求。
(2)本发明通过使用知识蒸馏的方法,弥补了仅使用超声波信息进行唇语识别的局限性,增强了超声波唇语识别的能力。
附图说明
图1为本发明系统的模块设计图。
图2为视觉唇语识别模块和超声波唇语识别模块的模型图以及知识蒸馏的原理图。
图3为整个系统的流程图。
具体实施方式
为了便于本领域技术人员的理解,下面结合实例与附图对本发明作进一步的说明,实施方式提及的内容并非对本发明的限定。
参照图1所示,本发明的一种基于超声波感知与知识蒸馏的唇语识别系统,包括:数据收集单元,数据预处理单元,模型训练单元;其中,
数据收集单元包括:超声波数据收集模块,视觉数据收集模块;
所述超声波数据收集模块,用于采集用户无声说话时唇部反射的超声波数据;所述超声波数据收集模块采用智能移动设备的扬声器发出20kHz的连续波,智能移动设备的麦克风接收反射波,采样率44100Hz。
所述视觉数据收集模块,用于采集模型训练阶段用户无声说话时人脸正面的视频数据;
数据预处理单元包括:超声波预处理模块,视觉预处理模块;
所述超声波预处理模块,用于从上述唇部超声波数据中提取信号梯度特征;
所述超声波预处理模块包括:信号滤波模块、时频变换模块、信号梯度特征提取模块以及超声波数据归一化模块;
信号滤波模块:由唇部运动导致的多普勒频移在[-20,40]Hz的区间内,使用巴特沃斯带通滤波器过滤原始超声波信号得到频率范围在[20000-20,20000+40]Hz区间的信号;n阶巴特沃斯滤波器的频率响应和增益的公式如下:
式中,G(ω)表示滤波器的增益,H(jω)表示信号的频响,G
时频变换模块:将超声波信号进行短时傅里叶变换操作,得到时频特征,傅里叶变换时每一帧窗口的大小为100ms,帧移10ms,加窗函数选择汉宁窗;短时傅里叶变换的公式如下:
式中,x(m)为输入信号,w(m)为窗函数,在时间上反转并且有n个样本的偏移量,X(n,ω)是时间n和频率ω的二维函数,e是自然对数底数,j为虚数单位;对超声波信号进行如上公式的计算得到一个经过短时傅里叶变换后的时频矩阵S;
信号梯度特征提取模块:在得到的时频矩阵上,使用后一时间帧的特征减去前一时间帧的特征得到信号梯度特征;信号梯度特征计算公式如下:
S=[s(0),s(1),s(2),…,s(T)]
G=[g(1),g(2),…,g(T)]
g(t)=s(t)-s(t-1)
式中,S表示时频矩阵,s(t)表示时频矩阵t时刻的向量,G表示信号梯度矩阵,g(t)表示信号梯度矩阵t时刻的向量;
超声波数据归一化模块:求所有信号梯度数据的最大值max和最小值min,使用如下公式将信号梯度特征归一化到0-1:
式中,Y是输出的信号梯度特征,X是原始的信号梯度特征。
所述视觉预处理模块,用于从上述人脸正面的视频数据中逐帧提取唇部区域特征;
所述视觉预处理模块包括:唇部提取模块,视觉数据归一化模块;
唇部提取模块:使用开源的人脸识别库(dlib)从视频中逐帧检测人脸对应的68个特征点,取最后20个特征点所包含的区域即为嘴唇区域;
视觉数据归一化模块:通过对唇部提取模块提取到的唇部区域图片的像素值除以255将所有数据归一化到0-1。
模型训练单元包括:超声波唇语识别模块,视觉唇语识别模块,知识蒸馏模块;
在训练过程中,首先需要对视觉唇语识别模块进行预训练,即将处理好的唇部数据输入到视觉唇语识别模块中,通过计算真实输出与预测输出之间的交叉熵,再利用反向传播的方式更新视觉唇语识别模块的参数。此过程对应于图中的①过程。
在预训练好视觉唇语识别模块之后,要使用知识蒸馏的方式,联合视觉唇语识别模块来训练超声波唇语识别模块,即同时将唇部数据和信号梯度数据分别输入到视觉唇语识别模块和超声波唇语识别模块中,通过比较两个模块中间数据的差异来指导超声波唇语识别模块参数的训练。与此同时,超声波唇语识别模块也要计算该模块预测输出与真实输出之间的交叉熵,再利用反向传播的方式更新参数。此过程对应于图中的②过程。
在唇语识别阶段,即图中的③过程,仅需要将超声波信号经过预处理得到的信号梯度特征输入到超声波唇语识别模块中即可得到最终的预测结果。
所述超声波唇语识别模块,在训练阶段利用信号梯度特征训练超声波唇语识别模型,在识别阶段将信号梯度特征输入到超声波唇语识别模型中翻译成为文本;
参照图2所示,所述超声波唇语识别模块使用resnet2d_18网络作为模型的架构,包含:2D模型深度卷积模块,2D模型残差模块,2D模型池化模块,2D模型全连接模块;其中,
2D模型深度卷积模块:采用一个深度2d卷积F
y
式中,x
2D模型残差模块:采用一个深度2d卷积F
y
式中,x
2D模型池化模块:使用2d平均池化进行计算,即每次对输入数据的一个固定形状窗口(又称池化窗口)中的元素计算平均输出;
2D模型全连接模块:用于输出最后的特征向量,其公式表达如下:
Y
式中,X
所述视觉唇语识别模块,利用唇部区域特征训练视觉唇语识别模型,并通过其指导超声波唇语识别模块进行训练;
所述视觉唇语识别模块使用resnet3d_18网络作为模型的架构,包含3D模型深度卷积模块,3D模型残差模块,3D模型池化模块,3D模型全连接模块:其中,
3D模型深度卷积模块:采用一个深度3d卷积G
y
式中,x
3D模型残差模块:采用一个深度3d卷积G
y
式中,x
3D模型池化模块:使用3d平均池化进行计算,即每次对输入数据的一个固定形状窗口(又称池化窗口)中的元素计算平均输出。
3D模型全连接模块:用于输出最后的特征向量,其公式表达如下:
Y
式中,X
所述知识蒸馏模块,用于将视觉唇语识别模块训练得到的视觉唇语识别模型的参数信息蒸馏到超声波唇语识别模型中,以指导超声波唇语识别模型的训练。
参照图2所示,所述知识蒸馏模块是将一系列2D模型残差模块最后输出的一维向量x
L=g(f(x
式中,f表示一种线性映射,g表示均方误差函数,L表示计算的均方误差,使用反向传播的方式仅更新超声波唇语识别模块的参数。
参照图3所示,本发明的一种基于超声波感知和知识蒸馏的唇语识别方法,包括步骤如下:
1)在模型训练阶段,采集用户无声说话时唇部反射的超声波信号,及人脸正面的视频数据;
所述步骤1)具体步骤如下:
11)使用智能移动设备的扬声器发出20kHz的超声波,智能移动设备的麦克风接收用户无声说话时唇部反射的超声波信号;
12)使用其他智能移动设备的前置摄像头收集人脸正面的视频数据。
2)对采集到的超声波信号进行滤波,时频变换,并通过后一帧减前一帧的方式以及归一化计算信号梯度特征;
所述步骤2)具体步骤如下:
21)对采集到的超声波信号使用巴特沃斯带通滤波器过滤得到频率范围在[20000-20,20000+40]Hz区间的信号;
22)对过滤后的信号进行短时傅里叶变换操作,得到时频矩阵;
23)对时频矩阵采用后一帧减前一帧的方式得到原始的信号梯度特征;
24)得到原始的信号梯度特征后,计算信号梯度特征中的最大值和最小值,以最大值最小值为界限,将信号梯度特征归一化,得到最终的信号梯度特征。
3)对采集到的视频数据逐帧进行人脸检测,在检测到人脸的基础上切割出唇部区域,并对得到的每一帧唇部数据进行归一化,得到唇部区域特征;
所述步骤3)具体步骤如下:
31)使用现有的人脸识别库(dlib)从采集到的视频数据中逐帧检测人脸对应的68个特征点,取最后20个特征点所包含的区域即为嘴唇区域;
32)通过对提取到的唇部区域图片的像素值除以255将所有数据归一化到0-1,得到唇部区域特征。
4)将唇部区域特征输入到视觉唇语识别模型中,对视觉唇语识别模型进行预训练;
所述步骤4)具体步骤如下:
41)将唇部区域特征输入到视觉唇语识别模型中,得到预测的输出;
42)使用交叉熵的方式计算真实标签和预测输出之间的损失,再通过反向传播的方式更新视觉唇语识别模型的参数。
5)在使用信号梯度特征训练超声波唇语识别模型的同时,还需将唇部区域特征输入到视觉唇语识别模型中,在此过程中将视觉唇语识别模型预训练得到的模型信息蒸馏到超声波唇语识别模型中;即一系列3D模型残差模块最后输出的一维向量xv在特征空间中的分布信息,蒸馏到超声波唇语识别模块中;
所述步骤5)具体步骤如下:
51)将信号梯度特征输入到超声波唇语识别模型中,得到一系列2D模型残差模块最后输出的一维向量,及最终的预测输出;
52)将唇部区域特征输入到视觉唇语识别模型中,得到一系列3D模型残差模块最后输出的一维向量;
53)使用交叉熵的方式计算真实标签和预测输出之间的损失,再通过反向传播的方式更新超声波唇语识别模型的参数;
54)在知识蒸馏模块中将超声波唇语识别模型和视觉唇语识别模型中间输出的一维向量先映射到同一个向量空间中,再计算两者的均方误差损失,利用反向传播的方式更新超声波唇语识别模型的参数。
6)在唇语识别阶段,采集唇部的超声波数据并进行数据预处理得到信号梯度特征;
所述步骤6)中超声波数据采集的方式与步骤1)的方式相同,信号梯度特征的计算方式与步2)的方式相同。
7)将得到的信号梯度特征输入到超声波唇语识别模块中进行识别,输出结果。
本发明具体应用途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进,这些改进也应视为本发明的保护范围。
- 基于超声波感知与知识蒸馏的唇语识别系统及方法
- 一种基于知识蒸馏的不良图片识别系统、方法、计算机及存储介质