基于大数据的地址分级标准方法
文献发布时间:2023-06-19 09:29:07
技术领域
本发明涉及人工智能技术领域,具体来说,涉及一种基于大数据的地址分级标准方法。
背景技术
地址用来描述家庭、公司、门店等建筑物的物理位置,同时也可以描述事情的发生地。在实际使用和书面填报过程中,会出现各种格式的地址,尤其是在描述事发地点时,更由于人们的口语化而呈现出更多的不规范性,这不止带来地址标准化的困难,也带来了从自然语言文本中识别出地址的困难。
地址分级标准指对地址做出基本的规范定义,那么在书面填报地址时需要按照规范填写,反之从文本中识别出的地址必然也属于地址标准分级中的某几级,从而将不规范的地址描述进行规范和标准化。
现有的地址不规范问题有:
1.地址缺失,主要是由于新增地址(道路、建筑物、门牌号等)。
2.地址过时,主要是由于行政区划变更造成的。譬如县改市造成的标准地址与现行申报地址不一致,但其实为同一地址,例如海安县改为海安市,标准地址中仍为海安县。
3.地址写法不统一,例如“狼山镇街道”有时写成“狼山镇”。很多时候也是由于行政区划变更造成,譬如镇升级为街道。
4.地址写法不标准,譬如,标准地址重复或由两段地址拼接。
5.地址存在缩写、简写、约定俗成的省略,譬如如万科花园小区、万科花园指的是同一地址。
6.地址存在错别字,例如“2栋23号”写成“2懂23号”。
为了将不规范地址进行规范化,现有一些从不同角度出发制定的地址分级标准,比如广东省公安厅信息通信处颁发的14级标准地址格式,公安部颁发的警用地理信息标准地址元素组合及编码规则等。
综合分析现有地址分级标准可以发现,这些方法只侧重于从录入地址源头控制地址的标准输入,无论是14级地址标准还是公安部地址编码规则,都致力于对住宅区、兴趣点等拥有门牌的地址做规范化地址制定和使用,没有考虑到前期我们介绍的地址另一种功能,即地址在描述事发地点时,往往是非常口语且随意的,当有从非结构化文本中识别地址的需求时,无法套用现有标准,比如文本中会普遍出现的“金箔路一家广告店内”、“安德门大街和兴业路交界的兴致科技园”等地址无法对应到现有地址分级上。
发明内容
针对相关技术中的上述技术问题,本发明提出一种基于大数据的地址分级标准方法,能够克服现有技术的上述不足。
为实现上述技术目的,本发明的技术方案是这样实现的:
一种基于大数据的地址分级标准方法,该方法包括以下步骤:
S1:建立地址分级标准;
S2:从非结构化数据中识别出地址;
S3:将识别出的地址按照地址分级定义,进行结构化拆分;
S4:建立地址库,其中,建立地址库包括两个方面,一是建立一到十级各个地址分级的地址库,二是建立八级和十级两级兴趣点类地标的地址索引。
进一步的,所述步骤S2进一步的包括以下步骤:
在一段自然语言文字中,按照地址分级标准和文本的语义智能识别出地址文本和非地址文本。
进一步的,所述建立地址库是基于海量地址数据的分级结果。
进一步的,建立地址索引是基于海量数据。
本发明的有益效果:通过该方法,达到了以下效果:
1.提供了更普适的地址分级标准;
2.为地址标准化管理提供了基础依据;
3.为自然语言文本中的不规范地址智能识别提供灵活可用的定义依据;
4.为不同警务场景提供不同粒度的地址定义。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
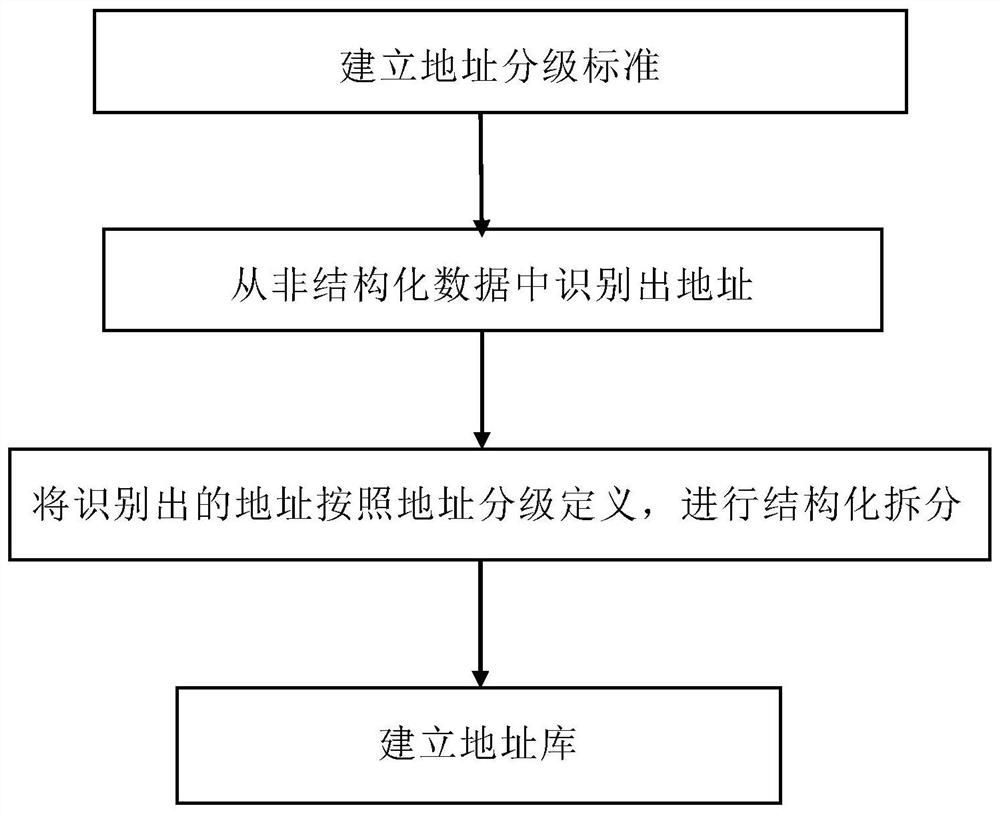
图1是根据本发明实施例所述的基于大数据的地址分级标准方法的流程框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,根据本发明实施例所述的基于大数据的地址分级标准方法,包括以下步骤:
S1:建立地址分级标准;
S2:从非结构化数据中识别出地址;
S3:将识别出的地址按照地址分级定义,进行结构化拆分;
S4:建立地址库,其中,建立地址库包括两个方面,一是建立一到十级各个地址分级的地址库,二是建立八级和十级两级兴趣点类地标的地址索引。
在本发明的一个具体实施例中,所述步骤S2进一步的包括以下步骤:
在一段自然语言文字中,按照地址分级标准和文本的语义智能识别出地址文本和非地址文本。
在本发明的一个具体实施例中,所述建立地址库是基于海量地址数据的分级结果。
在本发明的一个具体实施例中,建立地址索引是基于海量数据。
为了方便理解本发明的上述技术方案,以下对本发明的上述技术方案进行详细说明。
制定合理可用的地址标准不止在警务地址信息的标准化管理中有重要意义,也对从复杂的非结构文本中精确识别出地址意义重大。地址标准是进一步进行地址标准化、地址智能识别的基石。正向制定一套地址标准用来约束地名规范、地址填报等工作是现有地址标准普遍侧重关注的问题,然而如何使这些标准普适于自然语言文本中的地址描述,是本发明兼容考虑的问题。
根据现有的地址规范,我们可以很容易将“北京市海淀区颐和园路5号北京大学”按照14级或者9级的标准分级进行对号入座,做出“北京市”(市级)“海淀区”(区县级)“颐和园路5号”(路街巷级)“北京大学”(标志物级)等类似的划分。但是,当面对自然语言文本中常出现的“金箔路一家广告店内”,明显与“金箔路阿迪专卖店”表达的信息明确度不一样,然而在现行标准中对这些警务场景中使用度不同的地址描述是一视同仁的。并且自然语言文本中地址的描述词常常比较随意,“**家中”“**门口”等也常常是很重要的事发地点,却很难包含到现有的地址分级标准中。
本专利不仅调研了现有地址标准的普适度,更在长期的警务场景业务处理中积攒了大量的自然语言文本地址描述,在综合分析了大量像“北京市海淀区颐和园路5号北京大学”这样的较为规范的地址和“金箔路一家广告店内”这样的自然语言文本地址的信息和规律之后,从业务角度出发,制定了一套适用于地址标准化管理以及地址智能识别的地址分级标准。
本专利旨在兼顾正向地址规范制定和反向普适于已广泛存在于自然语言文本中的地址描述,经过大数据分析和调研、经过多种警务场景分析和落地,制定能同时服务于地址标准化管理和地址智能识别的地址分级标准。地址分级概览:
地址分级细节:
①省
省、直辖市、自治区、特别行政区,指行政区划中直属中央政府管辖行政区,包括23个省、5个自治区、4个直辖市、2个特别行政区,合计34个省级行政区。
②市
省会城市、地级城市、自治州、盟等,指行政区划中直属一级行政区管辖行政区,包括293个地级市、7个地区、30个自治州、3个盟,合计333个地级区划。
③区县
县、县级市、市辖区、自治县、旗、林区、工农区、特区等,指行政区划中直属二级行政区管辖行政区,965个市辖区、387个县级市、1323个县、117个自治县、49个旗、3个自治旗、1个特区、1个林区,合计2846个县级区划。
④乡、镇、街道
乡、镇、民族乡、街道办等,指行政区划中直属三级行政区管辖行政区,包括8516个街道、20975个镇、8122个乡、966个民族乡、153个苏木、1个民族苏木、1个县辖区,合计38734个乡级区划。
⑤村、居、社区
乡政府管理的村、社区级行政单位【村/庄、社区、村委会、居委会】。
⑥路、街、巷、桥、门等名称【最早使用的街、巷、里、弄、坊、胡同,现在常用的路、街、大街,以及近年来出现的“大道”】。
⑦门牌
权威部门确定的描述门牌的数值标识符,【门牌类型有号、号院】。
⑧小区、大院、学校、厂区、大厦、公司等,具有市政路、街、巷门牌号的的建筑物群/地标名称。
⑨楼牌号/单元/楼层/房号
楼牌号码:【栋、楼、号楼、楼斋、堂、公寓、宅、房等、村组】。
层:
单元:【门、单元、座等】。
房号:【室、房、间等】。
⑩建筑物名字/门店/公司等,指在八级地址之内的点地标建筑。不独自拥有一个路街巷门牌。
细化分级细节:
在自定义的十级地址分级基础上,本专利结合大量警务非结构化文本,分析自然语言中出现的地址描述,进一步定义了8级地址-具体、8级地址-统称;10级地址-具体、10级地址统称、10级地址-附属;完整地址等更贴近自然使用场景的地址细化分级。
8级地址-具体:拥有对应**路**号的小区名、学校名、公司名、大厦等(需要判断一下文中怎么说,不管地址中是否显示体现)。
8级地址-统称:特殊的,地址中出现中介公司、麻辣烫店、理发店、体育彩票店、门面房、公司、银行、医院、中医院、火车站、工商局、菜场这种不带具体名字的,为8级统称地址。
9级地址:**号楼**单元**层的任意几部分。
10级地址-具体:在8级地址之内的小区名、学校名、公司名、大厦等。
10级地址-统称:特殊的,地址中出现中介公司、麻辣烫店、理发店、体育彩票店、门面房、公司、银行、医院、中医院、火车站、工商局、菜场这种不带具体名字的,为10级统称地址。
10级地址-附属:地址的一部分,不能算是一个独立的地标建筑/公司等,比如医务处、住院部、6号出口等。
完整地址:完整地址的边界,指整个地址,不止包含上述标准地址分级,也包括地址中出现的**家中,**门口,**店内,**附近,**旁边等描述词。
细化地址分级举例,注意,以下标黄部分要整体为完整地址:
综上所述,借助于本发明的上述技术方案,通过该方法,达到了以下效果:提供了更普适的地址分级标准;为地址标准化管理提供了基础依据;为自然语言文本中的不规范地址智能识别提供灵活可用的定义依据;为不同警务场景提供不同粒度的地址定义。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 基于大数据的地址分级标准方法
- 基于居住地址分级的产品推荐方法、装置及存储介质