一种基于模型压缩和服务分发的边缘计算方法及系统
文献发布时间:2023-06-19 11:08:20
技术领域
本发明涉及边缘计算技术领域,尤其一种基于模型压缩和服务分发的边缘计算方法及系统。
背景技术
随着人工智能领域的深度学习技术的快速发展,深度神经网络受到了越来越广泛的应用。这类网络模型通常含有大量的参数和计算量,导致低存储、低算力、低功耗的边缘计算设备难以支撑这类模型的推理运算,限制了边缘智能技术的发展。边缘设备通常具有软硬件环境异构的特点,这为通用型算法的部署带来了阻碍,导致算法服务的部署效率极为低下。
发明内容
鉴于上述的分析,本发明旨在提供一种基于模型压缩和服务分发的边缘计算方法及系统,解决边缘计算中模型体积过大的问题和算法服务部署效率低下问题。
本发明公开了一种基于模型压缩和服务分发的边缘计算方法,包括以下步骤:
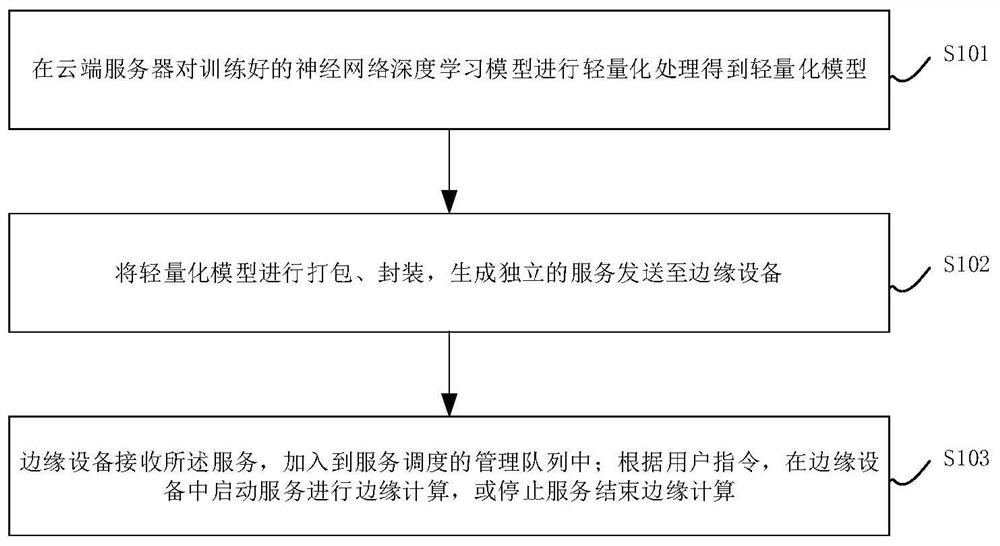
云端服务器对训练好的神经网络深度学习模型进行轻量化处理得到轻量化模型;
将轻量化模型进行打包、封装,生成独立的服务发送至边缘设备;
边缘设备接收所述服务,加入到服务调度的管理队列中;根据用户指令,在边缘设备中启动服务进行边缘计算,或停止服务结束边缘计算。
进一步地,在云端服务器对训练好的神经网络深度学习模型进行轻量化处理包括:
基于稀疏化训练对模型进行自动参数剪枝得到剪枝后的模型;
对剪枝后模型的参数中的浮点型参数逐一进行八比特量化;
基于模型蒸馏对量化后的模型进行自动参数蒸馏得到轻量化模型。
进一步地,基于稀疏化训练对模型进行自动参数剪枝得到剪枝后的模型包括:
1)将剪枝训练集中的图像样本分别输入到模型M1和模型M2中,执行目标检测任务,得到目标检测特征组{F1}和{F2};
以训练好的神经网络深度学习模型为所述模型M1和模型M2的初始模型;
2)将目标检测特征组{F1}或{F2}输入到判别网络D中进行判别,得到用于判别输入特征来自于模型M1或模型M2的判别结果{D};
3)将模型M2的所有卷积层的输出特征图分别点乘权重向量{W};
4)计算模型M2执行目标检测任务的损失函数L_det;计算模型M2的剪枝正则项损失函数L_prn;以及模型M1与模型M2的判别损失函数L_df;
5)冻结模型M1的所有参数,并断开梯度传播;冻结判别结果{D}的参数,计算总损失函数
6)冻结模型M1的所有参数,并断开梯度传播;冻结模型M2的所有参数,计算总损失函数
7)交替进行步骤5)和6)对模型M2、权重向量{W}和判别结果{D}进行训练;直至设定的最大训练轮数后停止训练;
8)对训练后的权重向量{W}中的权重值按数值大小排序,并将排列序号位于(1-θ)*n之后的权重全部置0,其中,n为{W}中权重的总数量,θ为预设的剪枝比例;然后将修改后的权重向量{W}分别与模型M2中对应的卷积核沿着通道相乘,得到的卷积核为权值稀疏的卷积核;
9)分别将模型M2的卷积核中权值为0的通道进行删除,得到的模型即剪枝后的模型M2_prn。
进一步地,所述判别网络D包括结构相同的三组子网络D1、D2和D3;
每个子网络均包括串联的第一特征提取层、第二特征提取层、第三特征提取层和第四特征提取层;
第一特征提取层包括一组3*3的标准卷积层和一个Leaky ReLU激活层;
第二特征提取层包括一组1*1的标准卷积层和一个Leaky ReLU激活层;
第三特征提取层包括一组3*3的标准卷积层和一个Leaky ReLU激活层;
第四特征提取层包括一组1*1的标准卷积层和一个Sigmoid激活层。
进一步地,所述模型M2的剪枝正则项损失函数
进一步地,模型M1与模型M2的判别损失函数L_df:
式中,E为期望函数,log为对数函数:D(F1)为判别器D在输入为{F1}时输出的置信度,D(F2)为判别器D在输入为{F2}时输出的置信度;
进一步地,所述参数蒸馏包括以下步骤:
将模型剪枝前的模型M1的特征层提取出来,记为{FF1};
然后将量化后的模型M2_prn_L的特征层提取出来,记为{FF2};
将{FF1}作为教师网络的知识,并将M1的权重冻结;同时,将{FF2}作为学生网络;
通过知识蒸馏对{FF2}进行训练;计算蒸馏损失L
蒸馏输出所得到的学生网络即为最终的轻量化模型。
进一步地,根据教师网络输出与真值标签的L2距离L
模型M2_prn的总损失函数
进一步地,在云端服务器上,部署了通用的模型打包框架,所述框架对轻量化模型的相关文件的组织框架包括:
文件main.py,用于作为服务的入口;main.py代码以FLASK框架为基础,构建出在不同模型之间完全相同的2个访问服务的接口;
文件夹model;用于放置获得的模型权重文件和模型执行代码文件;文件夹model包括文件夹code和文件夹weight;文件夹code用于放置轻量化模型的定义、执行代码文件;文件夹weight用于放置轻量化模型的权重文件;
文件夹tools,用于放置其它辅助代码文件。
本发明还公开了一种根据如上述的边缘计算方法的边缘计算系统,包括云端服务器和边缘设备;
所述云端服务器,用于对训练好的神经网络深度学习模型进行轻量化处理得到轻量化模型;将轻量化模型进行打包、封装,生成独立的服务发送至边缘设备;
所述边缘设备,用于接收所述服务,加入到服务调度的管理队列中;根据用户指令,在边缘设备中启动服务进行边缘计算,或停止服务结束边缘计算。本发明至少可实现以下有益效果之一:
本发明通过参数剪枝减小模型参数量、计算量和存储空间的需求量;通过模型量化减小模型对存储空间的需求;通过模型蒸馏提高轻量化后的模型的准确率,达到与原重模型相当的性能,从而提高轻量化模型的实用性;并基于FLASK的服务封装方法对模型进行打包和封装,可以实现算法模型的自动打包封装,减少人工参与的工作量,提高模型部署效率;利用服务调度解决终端设备环境异构的问题,统一的接口解决了终端设备软硬件环境异构的问题,从而为通用型自动化模型部署提供了技术基础;基于服务分发的模型自动推送部署技术将轻量化后的模型进行部署,解决了人工手动部署效率低下的问题,实现了全自动的模型推送和模型部署流程,极大地提高了边缘计算设备模型部署的效率。
附图说明
附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
图1为本发明实施例中的边缘计算方法流程图;
图2为本发明实施例中在云端服务器进行轻量化处理流程图;
图3为本发明实施例中自动参数剪枝方法流程图;
图4为本发明实施例中自动参数蒸馏方法流程图;
图5为本发明实施例中边缘计算系统组成连接示意图。
具体实施方式
下面结合附图来具体描述本发明的优选实施例,其中,附图构成本申请一部分,并与本发明的实施例一起用于阐释本发明的原理。
本实施例公开了一种基于模型压缩和服务分发的边缘计算方法,如图1所示,包括以下步骤:
步骤S101、在云端服务器对训练好的神经网络深度学习模型进行轻量化处理得到轻量化模型;
其中,训练好后的神经网络可以是yolo v3或者RetinaNet,用于目标检测任务,由基于汽车目标检测的遥感图像样本训练得到。
步骤S102、将轻量化模型进行打包、封装,生成独立的服务发送至边缘设备;
步骤S103、边缘设备接收所述服务,加入到服务调度的管理队列中;根据用户指令,在边缘设备中启动服务进行边缘计算,或停止服务结束边缘计算。
具体的,如图2所示,所述步骤S101包括以下子步骤:
步骤S201、基于稀疏化训练对神经网络深度学习模型进行自动参数剪枝得到剪枝后的模型;
本实施例中给定已训练的神经网络深度学习模型,为基于yolo v3训练得到的重参数模型,在给定的剪枝比例值θ下,以ResBlock为基本单位对主干网络进行剪枝,剪枝比例可设为0.85%。
步骤S202、对剪枝后模型的参数中的浮点型参数逐一进行八比特量化;
步骤S203、基于模型蒸馏对量化后的模型进行自动参数蒸馏得到轻量化模型。
更具体的,如图3所示,所述步骤S201包括以下子步骤:
步骤S301、将剪枝训练集中的图像样本分别输入到模型M1和模型M2中,执行目标检测任务,得到目标检测特征组{F1}和{F2};
具体的,在神经网络深度学习模型训练时所选取的数据集中随机选择训练集的一半数据,以构建新的训练集,用于模型剪枝的训练。测试集使用原测试集。
以训练好的神经网络深度学习模型为所述模型M1和模型M2的初始模型;即,将yolo v3模型进行复制,即计算机内存中同时存在两个完全相同的yolo v3网络模型,分别称为模型M1、模型M2;其中,模型M1作为剪枝的参考模型;模型M2作为被剪枝的模型。
执行目标检测任务,得到目标检测特征组{F1}或{F2}包括以下过程:
1)将训练集图像缩放至512*512的大小,并输入到yolo v3模型M1中执行目标检测任务;经过模型M1进行特征提取后,得到用于目标检测的三组特征图,记为{F1}。
这三组特征图记为F1a、F1b和F1c,其中F1a来自于M1的第82层,尺寸为64*64*256;F1b来自于M1的第94层,尺寸为32*32*512;F1c来自于M1的第106层,尺寸为16*16*1024。
2)将训练集图像缩放至512*512的大小,并输入到yolo v3模型M2中执行目标检测任务;经过模型M2进行特征提取后,得到用于目标检测的三组特征层,记为{F2}。
这三组特征图记为F2a、F2b和F2c,其中F2a来自于M2的第82层,尺寸为64*64*256;F2b来自于M2的第94层,尺寸为32*32*512;F2c来自于M2的第106层,尺寸为16*16*1024。
步骤S302、将目标检测特征组{F1}或{F2}输入到判别网络D中进行判别,得到用于判别输入特征来自于模型M1或模型M2的判别结果{D};
具体的,所述判别网络D由三组结构相同的子网络D1、D2和D3构成;判别网络D的输入为{F1}或{F2},输出记为{D};{D}中元素均为一个0到1之间的实数,用于区分所输入的特征是来自于模型M1还是来自于模型M2。输出0时,表明所输入的特征为来自于M1的{F1},输出1时,表明所输入的特征为来自于M2的{F2}。
更具体的,每个子网络均包括串联的第一特征提取层、第二特征提取层、第三特征提取层和第四特征提取层;
第一特征提取层包括一组3*3的标准卷积层和一个Leaky ReLU激活层;
第二特征提取层包括一组1*1的标准卷积层和一个Leaky ReLU激活层;
第三特征提取层包括一组3*3的标准卷积层和一个Leaky ReLU激活层;
第四特征提取层包括一组1*1的标准卷积层和一个Sigmoid激活层。
具体的,判别网络D中子网络D1具体的判别过程包括:
1)特征F1a或F2a为D1的输入特征,输入尺寸为64*64*256。输入特征首先经过第一特征提取层进行特征提取,所得到的第一特征图,尺寸为64*64*256,即高64,宽64,通道数256;
2)第一特征图经过第二特征提取层进行特征升维,所得到的第二特征图尺寸为64*64*512,即高64,宽64,通道数512;
3)第二特征图经过第三特征提取层进行特征降维,所得到的第三特征图尺寸为64*64*128,即高64,宽64,通道数128;
4)得到第三特征图经过第四特征提取层进行特征提取,所得到的特征图尺寸为64*64*1,即高64,宽64,通道数1。
判别网络D中子网络D2具体的判别过程包括:
1)特征F1b或F2b为D2的输入,输入尺寸为32*32*256。输入特征首先第一特征提取层进行特征提取,所得到的第一特征图尺寸为32*32*256,即高高32,宽32,通道数256;
2)第一特征图经过第二特征提取层进行特征升维,所得到的第二特征图尺寸为32*32*512,即高32,宽32,通道数512;
3)第二特征图经过第二特征提取层进行特征降维,所得到的第三特征图尺寸为32*32*128,即高32,宽32,通道数128;
4)得到第三特征图经过第四特征提取层进行特征提取,所得到的特征图尺寸为32*32*1,即高32,宽32,通道数1。
判别网络D中子网络D3具体的判别过程包括:
1)特征F1c或F2c为D3的输入,输入尺寸为16*16*256。输入特征首先第一特征提取层进行特征提取,所得到的第一特征图尺寸为16*16*256,即高16,宽16,通道数256;
2)第一特征图经过第二特征提取层进行特征升维,所得到的第二特征图尺寸为16*16*512,即高16,宽16,通道数512;
3)第二特征图经过第二特征提取层进行特征降维,所得到的第三特征图尺寸为16*16*128,即高16,宽16,通道数128;
4)得到第三特征图经过第四特征提取层进行特征提取,所得到的特征图尺寸为16*16*1,即高16,宽16,通道数1。
步骤S303、将模型M2的所有卷积层的输出特征图分别点乘权重向量{W};向量W的尺寸为1*1*C,即高1,宽1,通道C与模型M2中W所对应相乘的特征图通道数相同,W的初始值为1.0。
步骤S304、计算模型M2执行目标检测任务的损失函数L_det;计算模型M2的剪枝正则项损失函数L_prn;以及模型M1与模型M2的判别损失函数L_df;
其中,模型M2的目标检测任务的损失函数L_det;与yolo v3的损失函数一致,此处不再赘述。
模型M2的剪枝正则项损失函数L_prn;该损失函数计算公式如下,
其中,w
模型M1与M2的判别损失函数L_df;该损失函数计算公式如下,
式中,E为期望函数,log为对数函数:D(F1)为判别器D在输入为{F1}时输出的置信度,D(F2)为判别器D在输入为{F2}时输出的置信度;
步骤S305、冻结模型M1的所有参数,并断开梯度传播;冻结判别结果{D}的参数,计算总损失函数
步骤S306、冻结模型M1的所有参数,并断开梯度传播;冻结模型M2的所有参数,计算总损失函数
步骤S307、交替进行步骤S305和步骤S306对模型M2、权重向量{W}和判别结果{D}进行训练;直至设定的最大训练轮数后停止训练;
具体的,最大训练轮数为120epochs。
步骤S308、对训练后的权重向量{W}中的权重值按数值大小排序,并将排列序号位于(1-θ)*n之后的权重全部置0,其中,n为{W}中权重的总数量,θ为预设的剪枝比例;然后将修改后的权重向量{W}分别与模型M2中对应的卷积核沿着通道相乘,得到的卷积核为权值稀疏的卷积核;
步骤S309、分别将模型M2的卷积核中权值为0的通道进行删除,得到的模型即剪枝后的模型M2_prn。
更具体的,如图4所示,所述步骤S203包括以下子步骤:
步骤S401、将模型剪枝前的原模型M1的特征层提取出来,记为{FF1};
步骤S402、然后将量化后的模型M2_prn_L的特征层提取出来,记为{FF2};
量化后的模型M2_prn_L为对剪枝后模型M2_prn的参数中的浮点型参数逐一进行八比特量化的模型;
步骤S403、将{FF1}作为教师网络的“知识”,并将M1的权重冻结;同时,将{FF2}作为学生网络;
步骤S404、利用知识蒸馏的方法对{FF2}进行训练,从而提高学生网络量化后的模型M2_prn_L(即轻量化后的网络模型)的准确率,并计算蒸馏过程中的蒸馏损失,记为L
优选的,量化后的模型M2_prn_L的总损失函数L通过以下方法确定:
利用教师网络输出与真值标签计算L2距离,记为L
L
经过该蒸馏过程所得到的学生网络即为最终输出的轻量化模型。
具体的,步骤S102中将轻量化模型进行打包,并封装为独立的服务,包括:
在云端服务器上,设计部署了一种通用的模型打包框架,该框架对算法模型相关文件的组织方式如下:
文件:main.py,
文件夹:model
文件夹:code(模型代码)
网络模型的定义、执行代码文件
文件夹:weight(权重文件)
M2模型的权重文件
文件夹:tools
其它辅助代码文件
代码main.py为服务的入口,该代码以FLASK框架为基础,构建了2个访问服务的接口,这种接口在不同模型之间是完全相同的,因此具有通用性。
进一步地,2个服务的访问接口为:
启动服务:/start_service;
停止服务:/stop_service;
将最终的轻量化模型的权重文件和模型代码放置到该框架下的对应位置。
将上述框架下的所有文件打包进同一个压缩文件,命名方式为:模型名称.zip。所得压缩包即为模型所对应的服务压缩包。
进一步地,将所述服务压缩包发送至边缘设备;
在所述边缘设备中设计部署一种用于服务压缩包收发、管理、部署功能的通用型服务管理模块。使边缘设备的访问接口固定不变,具有通用性,在不同设备间部署时,可以解决异构设备的接口通用性问题;
服务管理模块采用自定义的标准接口。其中
推送服务:/send_service/
启动服务:/start_service/
停止服务:/stop_service/
云端服务器通过TCP连接,将所述服务压缩包发送至边缘终端设备。
具体的,步骤S103中的边缘终端设备部署服务管理模块。
云端服务器将所述服务压缩包发送至服务管理模块的“推送服务”接口,服务管理模块接收到对应的服务压缩包,并将其保存至指定目录;
服务管理模块将所述服务压缩包进行解压,并将解压后的文件移动到服务名称所对应的目录下,以待调用。
所述服务管理模块启动所述服务,并将其加入到服务调度的管理队列;
用户通过TCP连接,向边缘设备所部署的服务管理系统的“启动服务”接口发送请求指令,指令中包含服务名称。
服务管理系统根据用户指令中所包含的服务名称找到对应服务下的主代码main.py文件,该文件即步骤S102所述的main.py文件。服务管理模块通过系统指令将该服务启动,并将该服务加入到服务管理的队列中,该服务将在后台持续运行。
服务管理模块的“停止服务”接口发送请求指令,指令中包含服务名称,服用户通过TCP连接,向边缘设备所部署的服务管理系统会把对应的服务进行关闭。
进一步地,
在所述服务的运行过程中,main.py里的2个服务接口均可被用户通过TCP连接进行访问:“启动服务”和“停止服务”。
其中,“启动服务”接口用于调用最终的模型对输入图像进行处理。当该接口被访问时,请求的数据包含一张输入图像的存储路径以及一个输出文件的路径;
模型根据该图像路径找到对应的图像,并将图像加载到内存,然后输入到最终的模型中;
所述最终的模型调用边缘设备的计算资源进行边缘计算,对所述图像进行处理后,输出对应的结果,并将结果存储到所述的输出文件路径。
其中,“停止服务”接口用于停止所述服务。当该接口被访问时,该服务将自行释放计算机资源,并在后台退出。
综上所述,本实施例的基于模型压缩和服务分发的边缘计算方法,通过参数剪枝减小模型参数量、计算量和存储空间的需求量;通过模型量化减小模型对存储空间的需求;通过模型蒸馏提高轻量化后的模型的准确率,达到与原重模型相当的性能,从而提高轻量化模型的实用性;并基于FLASK的服务封装方法对模型进行打包和封装,可以实现算法模型的自动打包封装,减少人工参与的工作量,提高模型部署效率;利用服务调度解决终端设备环境异构的问题,统一的接口解决了终端设备软硬件环境异构的问题,从而为通用型自动化模型部署提供了技术基础;基于服务分发的模型自动推送部署技术将轻量化后的模型进行部署,解决了人工手动部署效率低下的问题,实现了全自动的模型推送和模型部署流程,极大地提高了边缘计算设备模型部署的效率。
本实施例还公开了一种边缘计算方法的边缘计算系统,如图5所示,包括云端服务器和边缘设备;
所述云端服务器,用于对训练好的神经网络深度学习模型进行轻量化处理得到轻量化模型;将轻量化模型进行打包、封装,生成独立的服务发送至边缘设备;
所述边缘设备,用于接收所述服务,加入到服务调度的管理队列中;根据用户指令,在边缘设备中启动服务进行边缘计算,或停止服务结束边缘计算。
具体的,所述云端服务器包括剪枝模块、量化模块、蒸馏模块和打包封装模块;
所述剪枝模块,用于基于稀疏化训练对神经网络深度学习模型进行自动参数剪枝得到剪枝后的模型;
所述量化模块,用于将剪枝后模型的参数中的浮点型参数逐一进行八比特量化;
所述蒸馏模块,用于基于模型蒸馏对量化后的模型进行自动参数蒸馏得到轻量化模型。
打包封装模块,用于将轻量化模型进行打包、封装,生成独立的服务发送至边缘设备。
本实施例更具体的技术细节和对应的技术效果,与上一实施例中公开的内容相同,在此就不一一赘述了。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
- 一种基于模型压缩和服务分发的边缘计算方法及系统
- 一种分布式内容分发方法、边缘服务器和内容分发网