一种基于多辐射源基于密度特征聚类及识别的方法
文献发布时间:2023-06-19 11:14:36
技术领域
本发明涉及一种雷达脉冲信号截获技术领域,尤其涉及一种基于多辐射源基于密度特征聚类及识别的方法。
背景技术
随着科学技术的发展,越来越多的高性能雷达投入使用,为了保护己方目标,干扰对方的雷达,雷达干扰、雷达组网、雷达关机等防护手段不断完善,尤其是雷达干扰技术,该技术的应用大大降低了传统雷达的侦查能力。为提高自身雷达的侦查能力,需要不断地发展完善抗干扰技术,通过综合采用多种技术手段,提高雷达的抗干扰能力,但现有抗干扰技术还不能较好地找出有效干扰或雷达目标。
现有技术利用辐射源脉冲的脉冲重复周期这一特征对脉冲进行聚类分选,同时包括对相似脉冲的合并,对跨信道脉冲的合并等。主要聚类方法是直方图法,分选出一些有效辐射源脉冲后,求这些脉冲的到达角均值,以此得出辐射源坐标。这种技术对于脉冲重复间隔变化复杂、环境中目标数较多的情形适应性较差,引入载频、脉宽等多参数聚类会在一定程度上改善此问题。但是较多参数的复杂变化会增大目标增批的概率,使得假辐射源增多,无法正确检测出有效的干扰或雷达目标,且直接利用一个脉冲的平均频率计算脉冲的到达角,会使得计算出的辐射源角度信息误差较大。
为了保护雷达,通常会在雷达附近放置多个干扰源迷惑对方雷达,多个辐射源发出的脉冲信号会形成混叠信号,直接利用此信号较难测出有效的角度信息,难以达到抗干扰的效果。现有技术中,对于脉冲重复间隔变化复杂、环境中目标数较多的情形适应性较差,多参数聚类会使得虚假目标增多,无法正确检测出雷达或目标,且辐射源坐标信息计算不准确。
由此,本发明提供了一种基于多辐射源密度特征聚类及识别的方法,以解决传统方法无法正确检测出雷达或目标,且辐射源坐标信息计算不准确的技术问题。
发明内容
为解决上述问题,本发明的目的在于提供一种基于多辐射源基于密度特征聚类及识别的方法,可在一定程度上得到有效的辐射源到达角信息,解决了脉冲重复间隔变化复杂的问题,使得筛选出的有效数据类的置信度更高、质心坐标更为准确。
为实现上述技术目的,达到上述技术效果,本发明的是通过以下技术方案实现的:
一种多辐射源基于密度特征聚类及识别的方法,包括:
步骤S1,建立聚类分选缓存池网格;以多辐射源大致方位为坐标中心,构建一个二维网格表,其中,横轴为方位角,纵轴为俯仰角,分别以C_Doa_Step1和C_Doa_Step2为步进,以fw_min、fw_max为横轴边界,以fy_min、fy_max为纵轴边界;每个网格均为一个数据缓存池,用于存放辐射源信息,包括脉冲到达角度、脉冲到达时间、角度数据量,缓存池编号从左上至右下依次编号为1,2,3,…,n,其中n为缓存池的总个数;
步骤S2,对脉冲到达角信息进行分选处理;计算每一个脉冲的到达角度,所述到达角度包含方位角fw_angle[i],i=1,2,…,n,俯仰角fy_angle[i],i=1,2,…,n,n为一个脉冲有效的到达角个数;
将脉冲的到达角数据以及脉冲到达时间放入对应的缓存池中,每放入一个角度数据,累计每个缓存池的角度数据量,并计算该缓存池的方位角和及俯仰角和;每个缓存池设置存放数据量上限,超过上限后的缓冲池不再放入数据;累计总的脉冲数量;
步骤S3,分选有效缓存池;对所有缓存池进行遍历,若缓存池角度数量大于一定门限,则判断该缓存池的角度数量是否大于周围八个缓存池的角度数量,是则将该缓存池视为有效缓存池,并记录所有有效缓存池的编号,计算该缓冲池角度数量与周围八个缓存池角度数量最大值的比值Kp;
步骤S4,合并有效缓存池作为有效数据类;遍历有效缓存池,通过步骤S2累积的缓存池方位角和及俯仰角和,计算有效缓存池及其周围八个缓存池的方位角均值及俯仰角均值作为该缓冲池质心,计算该缓存池标准差σ,然后以有效缓存池质心为圆心,以一定半径R=m*σ画圆,其中,m为合适的正整数,统计该缓存池及其周围八个缓存池中在此圆内的角度数据作为该有效数据类的角度数据,用这些角度数据重新计算有效缓存池的质心;计算各个有效缓存池之间的质心间距,当有效缓冲池的质心间距大于2R时,判定为独立有效数据类,若小于等于2R,则将两个或n个缓存池合并,其中,n最大为有效缓存池个数,缓存池的角度数据亦累积,并求出合并后的独立有效数据类质心;
步骤S5,剔除异常数据点;对独立有效数据类求标准差σ,以当前数据类的质心为圆心,以m*σ为半径,其中,m为合适的正整数,剔除不在该圆内的角度数据,并更新独立有效数据类的质心及标准差;
步骤S6,分选有效数据类;根据所述步骤S5得到独立有效数据类的质心后,分别求出每个独立数据类与其他独立数据类质心间的质心距离的最小值d_min[i],i=1,2,3,…,n,n为分选出的有效数据类个数,每个独立类与其他各个独立数据类的距离和d_sum[i],i=1,2,3,…,n,以及每个独立数据类对应的信号总能量;参照以上参数以及孤立度Kp,计算出所有独立的数据类对应的置信度,以此分选出置信度较高的数据类作为有效目标;若根据这几个参数无法选出合适的数据类,可以剔除超时数据并重新累计新数据进行聚类。
其中,本发明聚类数据来源为:多个辐射源混叠的脉冲信号无法测出准确的到达角,因此选取有效的数据段来进行脉冲到达角的计算,提取适量混叠脉冲中合适的采样点作为聚类分选的数据来源,在不浪费较多资源的情况下得到足够的有用信息。
其中,累积聚类数据的时间处理策略为:每次聚类数据量累积达到一定时间或者数量后启动聚类,累积的时间或数量可以灵活取决于辐射源脉冲的脉冲重复周期,如时间累计到100ms或脉冲数量累计到100个时,开始聚类。若一次聚类无法分选出最孤立的数据类,可以采用滑窗的形式,剔除部分超时脉冲,如最早的5ms脉冲剔除,并继续累积最新5ms的脉冲数据,然后重新进行聚类,这样既可避免数据太老旧导致聚类得到的辐射源坐标结果不准确,也可以避免数据全部丢掉重新积累带来的时间上的浪费。
其中,聚类缓存池网格的处理策略为:简单地对辐射源脉冲进行测向得到多个辐射源的大致方向以及坐标范围,以此确定缓存池网格的步进和横纵坐标边界,尽可能缩小缓存池网格的范围,减少不必要的存储资源浪费,合适的步进会让聚类结果更加准确,尽可能的避免功率较强的辐射源被分割成多个目标,进而在判断最孤立数据类时被错误剔除。
相比于现有技术,本发明具有以下有益效果:
(1)本发明直接使用多辐射源混叠脉冲合适的数据点进行到达角的计算,可以在一定程度上得到有效的辐射源到达角信息,这种测角方法受脉内和脉间的幅度和相位调制影响较小,可能会在一定程度上受到干扰噪声的影响,但是只要前级提取脉冲信号的检测较为准确,这种干扰带来的影响可以忽略,也解决了脉冲重复间隔变化复杂的问题。
(2)本发明的聚类分选有效数据类的策略,对选出的有效数据类进行进一步的比较和合并,对合并后剩余的有效数据类进行进一步的数据剔除及质心计算,可以使得选出的有效数据类的置信度更高,也使得这些有效数据类的质心坐标更为准确。
(3)本发明针对多个辐射源的脉冲信号进行聚类分选处理,选出多个有效数据类后,对这些数据类进行进一步的筛选,通过最小质心距离、最小质心距离和、数据类总能量值及孤立度这四个参数结合,提高分选置信度,选出最有可能是真实目标的数据类。
附图说明
为了使本发明的内容更容易被清楚的理解,下面根据本发明的具体实施例并结合附图,对本发明作进一步详细的说明,其中,
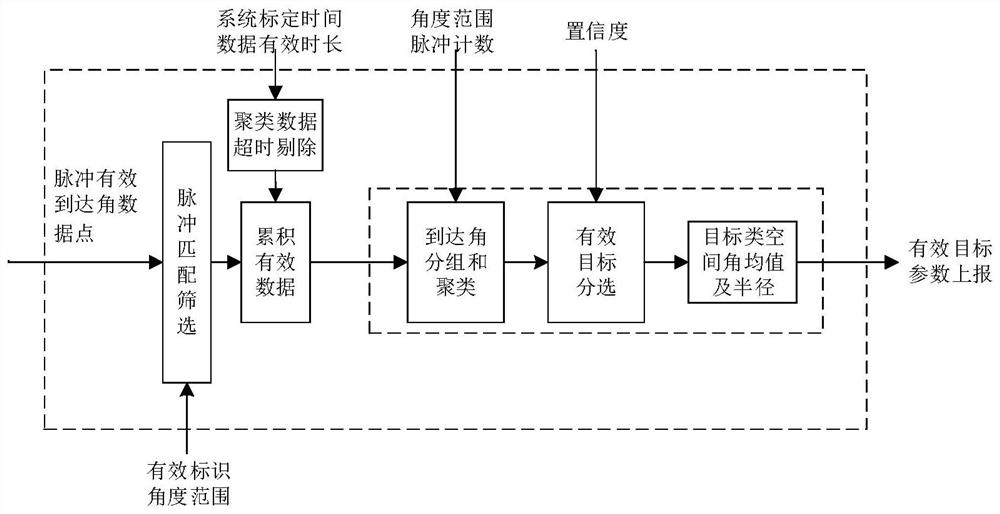
图1为本发明的一种多辐射源基于密度特征聚类及识别工作原理框图。
图2为本发明步骤S1中的聚类分选缓存池网格示意图。
具体实施方式
为使本发明实施的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行更加详细的描述。所描述的实施例是本发明一部分实施例,而不是全部的实施例。对于本领域技术人员根据本发明内容所作的类似改进与调整在没有作出创造性劳动的前提下所获得的其他实施例,均视为本发明保护的范围。
下面结合附图对本发明的实施例进行详细说明。
如图1所示,一种多辐射源基于密度特征聚类及识别的方法,包括:
步骤S1,建立聚类分选缓存池网格;以多辐射源大致方位为坐标中心,构建一个二维网格表,详细网格构建如图2所示,其中,横轴为方位角,纵轴为俯仰角,分别以C_Doa_Step1和C_Doa_Step2为步进,以fw_min、fw_max为横轴边界,以fy_min、fy_max为纵轴边界;每个网格均为一个数据缓存池,用于存放辐射源信息,包括脉冲到达角度、脉冲到达时间、角度数据量,缓存池编号从左上至右下依次编号为1,2,3,…,n,其中n为缓存池的总个数;
步骤S2,对脉冲到达角信息进行分选处理;计算每一个脉冲的到达角度,所述到达角度包含方位角fw_angle[i],i=1,2,…,n,俯仰角fy_angle[i],i=1,2,…,n,n为一个脉冲有效的到达角个数;
将脉冲的到达角数据以及脉冲到达时间放入对应的缓存池中,每放入一个角度数据,累计每个缓存池的角度数据量,并计算该缓存池的方位角和及俯仰角和;每个缓存池设置存放数据量上限,超过上限后的缓冲池不再放入数据;累计总的脉冲数量;
步骤S3,分选有效缓存池;对所有缓存池进行遍历,若缓存池角度数量大于一定门限,则判断该缓存池的角度数量是否大于周围八个缓存池的角度数量,是则将该缓存池视为有效缓存池,并记录所有有效缓存池的编号,计算该缓冲池角度数量与周围八个缓存池角度数量最大值的比值(孤立度)Kp;
步骤S4,合并有效缓存池作为有效数据类;遍历有效缓存池,通过步骤S2累积的缓存池方位角和及俯仰角和,计算有效缓存池及其周围八个缓存池的方位角均值及俯仰角均值作为该缓冲池质心,计算该缓存池标准差σ,然后以有效缓存池质心为圆心,以一定半径R=m*σ画圆,其中,m为合适的正整数,统计该缓存池及其周围八个缓存池中在此圆内的角度数据作为该有效数据类的角度数据,用这些角度数据重新计算有效缓存池的质心;计算各个有效缓存池之间的质心间距,当有效缓冲池的质心间距大于2R时,判定为独立有效数据类,若小于等于2R,则将两个或n个缓存池合并,其中,n最大为有效缓存池个数,缓存池的角度数据亦累积,并求出合并后的独立有效数据类质心;
步骤S5,剔除异常数据点;对独立有效数据类求标准差σ,以当前数据类的质心为圆心,以m*σ为半径,其中,m为合适的正整数,剔除不在该圆内的角度数据,并更新独立有效数据类的质心及标准差;
步骤S6,分选有效数据类;根据所述步骤S5得到独立有效数据类的质心后,分别求出每个独立数据类与其他独立数据类质心间的质心距离的最小值d_min[i],i=1,2,3,…,n,n为分选出的有效数据类个数,每个独立类与其他各个独立数据类的距离和d_sum[i],i=1,2,3,…,n,以及每个独立数据类对应的信号总能量;参照以上参数以及孤立度Kp,计算出所有独立的数据类对应的置信度,以此分选出置信度较高的数据类作为有效目标;若根据这几个参数无法选出合适的数据类,可以剔除超时数据并重新累计新数据进行聚类。
一种如实施例1所述的一种多辐射源基于密度特征聚类及识别的方法,聚类数据来源为:多个辐射源混叠的脉冲信号无法测出准确的到达角,因此选取有效的数据段来进行脉冲到达角的计算,提取适量混叠脉冲中合适的采样点作为聚类分选的数据来源,在不浪费较多资源的情况下得到足够的有用信息。
一种如实施例1所述的一种多辐射源基于密度特征聚类及识别的方法,累积聚类数据的时间处理策略为:每次聚类数据量累积达到一定时间或者数量后启动聚类,累积的时间或数量可以灵活取决于辐射源脉冲的脉冲重复周期,如时间累计到100ms或脉冲数量累计到100个时,开始聚类。若一次聚类无法分选出最孤立的数据类,可以采用滑窗的形式,剔除部分超时脉冲,如最早的5ms脉冲剔除,并继续累积最新5ms的脉冲数据,然后重新进行聚类,这样既可避免数据太老旧导致聚类得到的辐射源坐标结果不准确,也可以避免数据全部丢掉重新积累带来的时间上的浪费。
一种如实施例1所述的一种多辐射源基于密度特征聚类及识别的方法,聚类缓存池网格的处理策略为:简单地对辐射源脉冲进行测向得到多个辐射源的大致方向以及坐标范围,以此确定缓存池网格的步进和横纵坐标边界,尽可能缩小缓存池网格的范围,减少不必要的存储资源浪费,合适的步进会让聚类结果更加准确,尽可能的避免功率较强的辐射源被分割成多个目标,进而在判断最孤立数据类时被错误剔除。
综上所述,在对到达角信息进行聚类时,本发明是一种根据数据密度来进行有效类筛选的方法,即通过比较缓存池与周围缓存池的数据量来提取有效缓存池,并将质心距离小于一定范围的缓存池合并,这使得本发明提取出的缓存池更突出,且在进行最小质心距离计算时,不会造成目标由于数据量较多被分散在多个缓存池中,从而使得有效目标被剔除,再结合有效目标的判断策略,综合各项参数求出各个独立有效类的置信度,使得提取出的有效目标更真实可靠。
本发明使用有效缓存池及其周围八个缓存池的角度数据进行处理,并求出一定半径内九个缓存池数据的质心及标准差,以求出的质心为圆心,m倍标准差为半径画一个新的聚类圆(m为合适的正整数),剔除圆外的角度数据点,然后使用剩余的角度数据点求出新的质心和标准差,该过程对有效缓存池的质心进行了更准确的收敛,每个独立有效类的角度数据更加集中,使得最终得到的脉冲角度数据更为准确。
- 一种基于多辐射源基于密度特征聚类及识别的方法
- 一种基于功率谱密度的通信辐射源个体识别方法