融合自注意力机制和深度学习的文本分类方法及系统
文献发布时间:2023-06-19 11:19:16
技术领域
本发明属于文本分类技术领域,特别涉及一种融合自注意力机制和深度学习的文本分类方法及系统。
背景技术
随着人工智能的不断发展,越来越多的研究者关注自然语言处理。越来越多的研究者将机器学习和深度学习的方法应用到文本分类中,逐渐成为文本分类的一种流行趋势。文本分类在机器学习的应用主要体现在以下四个方面:(1)逻辑回归算法,大多数情况下用于判断在其所属类别中的概率;(2)朴素贝叶斯算法,它利用高等数学中的概率数据统计知识中的贝叶斯定理的进行分类;(3)随机森林算法,它以随机的方式选择一些决策树,然后将它们构建到森林中进行分类,从而提高分类的准确性;(4)支持向量机方法,采用监督学习来分离不同类别的数据。该方法是一种广义线性分类器。在深度学习中,为了能够将深度学习中的神经网络算法应用到文本分类当中,首先要做的事就是将文本表示成计算机容易处理的形式。近年来,在自然语言处理的不断发展下,注意力机制受越来越多的研究学者的关注。后来,应用于图像研究领域的注意力机制也开始在自然语言处理领域展现出强大的能力,如机器翻译、情感分析及关系抽取等。由于现存的适用于NLP的网络模型在获取文本长距离关系和提取文本关键特征信息具有一定的不足。
发明内容
为此,本发明提供一种融合自注意力机制和深度学习的文本分类方法及系统,克服现有的技术中存在获取上下文之间的语义关联所存在的不足和文本信息不能够较好的渗透到深度学习神经网络中进而影响文本分类识别效果的情形。
按照本发明所提供的设计方案,一种融合自注意力机制和深度学习的文本分类方法,包含如下内容:
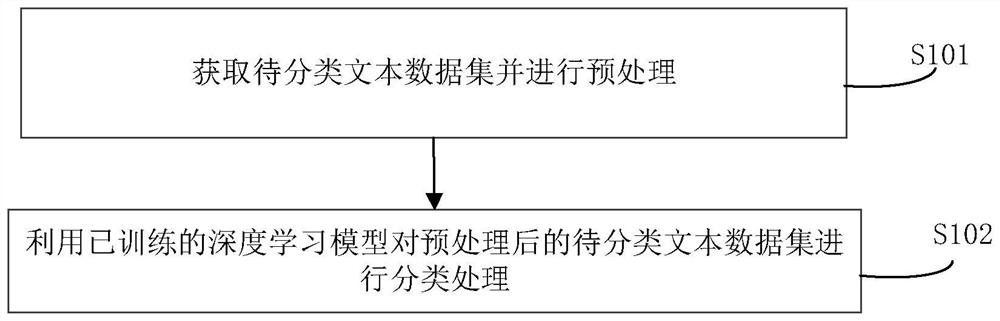
获取待分类文本数据集并进行预处理;
利用已训练的深度学习模型对预处理后的待分类文本数据集进行分类处理,其中,深度学习模型包含:依次连接用于提取待分类文本数据集中句子级词向量表示的ERNIE预训练模块、用于依据句子级词向量表示来提取每个词上下文信息的BiLSTM模块、用于依据句子级词向量表示和每个词上下文信息来深层次提取每个词上下文信息的DPCNN模块、用于依据句子级侧向量表示和每个词上下文信息来提取文本深度信息分配权重的注意力机制模块及用于依据文本深度信息分配权重进行分类输出的Softmax模块。
作为本发明融合自注意力机制和深度学习的文本分类方法,进一步地,数据集预处理包含对文本数据中包含数字、英文和特殊符号数据的清洗处理。
作为本发明融合自注意力机制和深度学习的文本分类方法,进一步地,利用已知类别标签的文本数据样本对深度学习模型进行训练优化,其中,文本数据样本包含:用于模型训练的训练样本集、用于模型校验的校验样本集及用于模型测试的测试样本集。
作为本发明融合自注意力机制和深度学习的文本分类方法,进一步地,ERNIE预训练模块中,将输入的数据集以字为单位进行切分,并通过对文本信息进行编码获取数据集中文本的词向量表示;利用知识整合短语级遮蔽将句子中短语成分遮蔽,得到字和短语层次的知识整合信息;利用知识整合实体级遮蔽将句子中实体信息进行遮蔽,得到实体层次知识整合信息;将字、短语和实体层次的知识整合信息整合到词向量表示中,得到数据集的句子级词向量表示。
作为本发明融合自注意力机制和深度学习的文本分类方法,进一步地,以字为单位进行切分时,在每句切分的句子之前加入标识符,将输入文本数据长度超过预设值的删除,并将长度不够预设值的句子补齐。
作为本发明融合自注意力机制和深度学习的文本分类方法,进一步地,BiLSTM模块包含:前向传播LSTM单元和后向传播LSTM单元,通过遗忘门存储传递信息并在每个时间步输出隐藏状态,获取与文本长度相同的隐序列,其中,遗忘门隐藏状态由前一时刻的隐藏状态和当前输入的存储门记录、输出门控制。
作为本发明融合自注意力机制和深度学习的文本分类方法,进一步地,DPCNN模块中,利用Mish()激活函数处理数据并使用等长卷积且通过增加网络层数捕获存在距离长度的文本依赖关系。
作为本发明融合自注意力机制和深度学习的文本分类方法,进一步地,注意力机制模块采用Bahdanau Attention结构,将编码阶段的隐状态和解码阶段所有位置输出进行线性组合来获取上下文向量并利用Mish()激活函数进行非线性化处理来提取文本特征信息相应权重。
进一步地,本发明还提供一种融合自注意力机制和深度学习的文本分类系统,包含:数据处理模块和数据分类模块,其中,
数据处理模块,用于获取待分类文本数据集并进行预处理;
数据分类模块,用于利用已训练的深度学习模型对预处理后的待分类文本数据集进行分类处理,其中,深度学习模型包含:依次连接用于提取待分类文本数据集中句子级词向量表示的ERNIE预训练模块、用于依据句子级词向量表示来提取每个词上下文信息的BiLSTM模块、用于依据句子级词向量表示和每个词上下文信息来深层次提取每个词上下文信息的DPCNN模块、用于依据句子级侧向量表示和每个词上下文信息来提取文本深度信息分配权重的注意力机制模块及用于依据文本深度信息分配权重进行分类输出的Softmax模块。
本发明的有益效果:
本发明通过使用BERT模型的改进版ERNIE预训练模型提升词向量的表征能力,结合BiLSTM模块和DPCNN模块,使得文本信息学能够更好的渗透到神经网络中去,从而产生更好的准确性与通用性,使得本案方案可以在最大程度获得文本之间的依赖关系信息,并通过融合注意力机制可以增强文本内部的依赖关系,提升模型训练效果和效率,进而提升文本分类识别准确度,具有较好的应用前景。
附图说明:
图1为实施例中文本分类方法流程示意;
图2为实施例中深度学习模型结构示意;
图3为实施例中本案ERNIE预训练模型模块和其他BERT预训练模型结构对比示意;
图4为实施例中Transformer结构示意;
图5为实施例中句编码处理示意;
图6为实施例中BiLSTM编码句子示意;
图7为实施例中DPCNN模型模块结构示意;
图8为实施例中DPCNN模型模块等长卷积结构示意;
图9为实施例中注意力机制流程示意;
图10为实施例中注意力机制模块结构示意。
具体实施方式:
为使本发明的目的、技术方案和优点更加清楚、明白,下面结合附图和技术方案对本发明作进一步详细的说明。
本发明实施例,提供一种融合自注意力机制和深度学习的文本分类方法,参见图1所示,包含如下内容:获取待分类文本数据集并进行预处理;利用已训练的深度学习模型对预处理后的待分类文本数据集进行分类处理,其中,深度学习模型包含:依次连接用于提取待分类文本数据集中句子级词向量表示的ERNIE预训练模块、用于依据句子级词向量表示来提取每个词上下文信息的BiLSTM模块、用于依据句子级词向量表示和每个词上下文信息来深层次提取每个词上下文信息的DPCNN模块、用于依据句子级侧向量表示和每个词上下文信息来提取文本深度信息分配权重的注意力机制模块及用于依据文本深度信息分配权重进行分类输出的Softmax模块。
参见图2所示,通过使用BERT模型的改进版ERNIE预训练模型提升词向量的表征能力,结合BiLSTM模块和DPCNN模块,使得文本信息学能够更好的渗透到神经网络中去,从而产生更好的准确性与通用性,使得本案方案可以在最大程度获得文本之间的依赖关系信息,并通过融合注意力机制可以增强文本内部的依赖关系,提升模型训练效果和效率,进而提升文本分类识别准确度。
作为本发明实施例中融合自注意力机制和深度学习的文本分类方法,进一步地,数据集预处理包含对文本数据中包含数字、英文和特殊符号数据的清洗处理。进一步地,利用已知类别标签的文本数据样本对深度学习模型进行训练优化,其中,文本数据样本包含:用于模型训练的训练样本集、用于模型校验的校验样本集及用于模型测试的测试样本集。
例如,在对新闻文本进行分类中,可使用清华在NLP提供的THUCNews新闻文本分类数据集的一个子集,共有20万条数据,将18万条数据设置为训练集,1万条设置为校验集,1万条设置为测试集。数据集类别分别为finance,realty,stocks,education,science,society,politics,sports,game,entertainment十个类别。将实验参数Epoch数可设置为5,batch_size可设置为128,序列长度可设置为32,学习率可设置为1e-5,隐藏层数可设置为768,为了防止过拟合将dropout数可设置为0.5。为了保证实验结果的准确性,可设置random_seed为666。
作为本发明实施例中融合自注意力机制和深度学习的文本分类方法,进一步地,ERNIE预训练模块中,将输入的数据集以字为单位进行切分,并通过对文本信息进行编码获取数据集中文本的词向量表示;利用知识整合短语级遮蔽将句子中短语成分遮蔽,得到字和短语层次的知识整合信息;利用知识整合实体级遮蔽将句子中实体信息进行遮蔽,得到实体层次知识整合信息;将字、短语和实体层次的知识整合信息整合到词向量表示中,得到数据集的句子级词向量表示。进一步地,以字为单位进行切分时,在每句切分的句子之前加入标识符,将输入文本数据长度超过预设值的删除,并将长度不够预设值的句子补齐。
对新闻数据集中的数字,英文和特殊符号的数据进行清洗处理。将预处理过的数据集输入ERNIE预训练模型当中。在ERNIE预训练模型当中,用切词器将输入文本以字为单位进行切分,在每句切分的句子之前加入[CLS]标识符,将输入的文本数据长度超过32的地方删去,长度不够32的地方补0。将处理完的数据传入ERNIE预训练模型模块的下一阶段。利用ERNIE预训练模型中的Transformer编码器对文本信息进行编码,得到处理后的数据集数据的词向量表示。利用知识整合的短语级遮蔽将句子中的短语成分进行遮蔽,得到字和短语层次的知识整合信息,利用知识整合的实体级遮蔽将句子中的实体信息进行遮蔽,得到实体的层次的知识整合信息。最后将字,短语和实体之间的层次的知识整合信息整合到经过预处理的对应的词向量表示中,得到数据集的句子级的词向量表示。
ERNIE预训练模型模块是基于BERT的改进模型,参见图3所示,其内部网络也是基于双向注意机制的编码器。共有12层,每层包括自我注意机制、规范化机制、求和和规范归一化机制以及一些前馈神经网络机制。通过这些机制,形成一个相对复杂的神经网络结构。ERNIE的隐码语言模型与BERT不同,它掩盖住的不是一个字而是词或短语、命名实体,使模型通过全局信息推断出隐藏的内容,并学习文本序列中隐藏信息所包含的知识。ERNIE通过学习全局信息使学习一个非常先验的结果成为可能,它可以预先标记这些单词或短语,然后学习它们。它是一个基于现有策略的、基于海量数据训练的好模型。本案中,ERNIE可使用两种机制:顺序学习,一次学习一个任务,参数不断更新。这很容易,但另一方面,会有一个很大的问题,这是很容易陷入遗忘状态。这种学习更适合于任务关系密切的任务,这也是内隐的代码语义模型。第一次学习覆盖词,第二次学习覆盖词,第三次学习覆盖什么样的句子。其实质是完形填空,但内容不同。这样,才能有序地学习。但对于其他任务,你可能需要同时学习。例如,每个迭代都是一个batch。batch和batch之间的任务可以不同,不同的任务可以在同一个batch学习。batch有一个多任务机制,batch有一个多任务机制,它可以在不同的任务之间来回切换,这样它就可以记住学习不同任务的特点,这样就不会陷入之前的遗忘模式。ERNIE预训练模型模块中的Transformer编码器中的self-attention机制的描述公式可表示为:
其中,在计算self-attention时,首先,在每一个Encoder的输入向量上创建三个向量,分别为Q向量,K向量,V向量。且这些向量是通过词嵌入与训练过程中创建的3个训练矩阵而产生的。d
作为本发明实施例中融合自注意力机制和深度学习的文本分类方法,进一步地,BiLSTM模块包含:前向传播LSTM单元和后向传播LSTM单元,通过遗忘门存储传递信息并在每个时间步输出隐藏状态,获取与文本长度相同的隐序列,其中,遗忘门隐藏状态由前一时刻的隐藏状态和当前输入的存储门记录、输出门控制。
将ERNIE预训练模型中得到的数据集得到句子级的词向量表示传入到BiLSTM模型中。BiLSTM的基本单元包含着前向传播的LSTM单元和后向传播LSTM单元。LSTM模型的计算过程可以总结为:通过遗忘单元状态中的信息,存储新的信息,为后续的计算传递有用的信息,丢弃无用的信息,并在每个时间步输出隐藏状态h
BiLSTM模型模块是由t时刻的输入词x
f
其中,b
其次,计算存储门并选择要存储的信息。输入前一时刻的隐藏状态h
i
然后,计算当前时刻的单元状态,输入存储门的值i
再然后,计算输出门和当前时刻的隐藏状态,输入前一时刻的隐藏状态h
o
h
最终,我们可以得到与句子长度相同的隐序列{h
作为本发明实施例中融合自注意力机制和深度学习的文本分类方法,进一步地,DPCNN模块中,利用Mish()激活函数处理数据并使用等长卷积且通过增加网络层数捕获存在距离长度的文本依赖关系。进一步地,注意力机制模块采用BahdanauAttention结构,将编码阶段的隐状态和解码阶段所有位置输出进行线性组合来获取上下文向量并利用Mish()激活函数进行非线性化处理来提取文本特征信息相应权重。
将BiLSTM输出的序列输入到DPCNN模型当中,通过深化网络层数来捕获远距离文本的依赖关系。DPCNN模型中使用等长卷积,假设输入序列长度为n,卷积核大小为m,步长为s,输入序列两端各填补p个零,那么该卷积层的输出序列为(n+m+2p)/s+1。可通过采用适当的两层等长卷积来提高文字表达的丰富性嵌入,两层等长卷积后,使用大小3,步长是2对文本序列进行池化,文本序列的长度是压缩为原来的一半,所以能够感知到的文本长度是之前的两倍。将DPCNN模型中输出的序列向量传入到一种具有加性attention机制的BahdanauAttention中,将decoder的隐状态和encoder所有位置输出通过线性组合对齐,得到context向量,用于改善序列到序列的翻译模型。其本质是两层全连接网络,隐藏层的激活函数位Mish(),输出层维度为1。最后,将注意力机制层所输出的不同权重的信息输入到Sofimax函数层进行输出,从而达到最终的新闻文本分类的效果。
传统Seq2seq模型中编码器将输入序列编码成上下文向量,解码器将上下文向量作为初始隐藏状态生成目标序列。随着输入序列长度的增加,编码器对所有输入的信息进行编码成一个上下文向量是困难的,编码信息缺失,难以完成高质量解码。注意机制是计算解码器对输入序列的每个位置的隐藏状态的注意,并基于解码器在当前时刻的隐藏状态、输入或输出信息生成在当前时刻为解码加权的上下文向量。通过与注意力机制相结合,解码器可以在不同时刻注意不同位置的输入信息,提高预测的准确性。
Bahdanau Attention是一种加性Attention机制,将Decoder的隐状态和Encoder所有位置输出进行线性组合,得到上下文向量,用于改进序列到序列的模型。为了使获得的信息更好的深入神经网络,获得更好的准确性和泛化性,本案实施例中,可在注意机制中采用Mish()激活函数。注意机制层用于为提取的文本深度信息分配相应的权重。最后,将不同权重的文本特征信息输入Softmax函数层进行输出。
在Encoder阶段,编码器对于每一个输入向量产生一个隐状态向量:
h
o
在Decoder阶段,第一步,生成该时刻得语义向量:
其中,h
第二步,传递隐藏信息并预测:
s
o
其中,s
进一步地,本案方案可在Attention机制和DPCNN模型中均采用了Mish()激活函数,在DPCNN模型中,在每次卷积操作之前,使用激活函数处理数据,Mish()激活函数中正值可以达到任意高度,不会遇到封顶的饱和的问题。理论上,允许一个稍负的值比硬零边界有更好的梯度流动。最后,平滑激活函数允许更好的信息渗透到神经网络中,从而获得更好的准确性和通用性。其原理公式如下:
y=x*tanh(ln(1+e
进一步地,基于上述的方法,本发明实施例还提供一种融合自注意力机制和深度学习的文本分类系统,包含:数据处理模块和数据分类模块,其中,
数据处理模块,用于获取待分类文本数据集并进行预处理;
数据分类模块,用于利用已训练的深度学习模型对预处理后的待分类文本数据集进行分类处理,其中,深度学习模型包含:依次连接用于提取待分类文本数据集中句子级词向量表示的ERNIE预训练模块、用于依据句子级词向量表示来提取每个词上下文信息的BiLSTM模块、用于依据句子级词向量表示和每个词上下文信息来深层次提取每个词上下文信息的DPCNN模块、用于依据句子级侧向量表示和每个词上下文信息来提取文本深度信息分配权重的注意力机制模块及用于依据文本深度信息分配权重进行分类输出的Softmax模块。
为验证本案方案有效性,下面结合具体实验数据做进一步解释说明:
本案中基于融合自注意力机制的ERNIE-BiLSTM-DPCNN模型可简称EBDA,BERT结合CNN简称为BERTCNN,BERT结合RNN简称为BERTRNN,BERT结合LSTM简称为BERTRCNN,BERT结合DPCNN简称为BERTDPCNN,BERT结合GRU简称为BERTGRU。
实验环境:采用Windows10,GPU为NVIDIA Tesl
实验过程:通过搭建出六种不同的模型,分别为EBDA,BERTCNN,BERTRNN,BERTRCNN,BERTDPCNN,BERTGRU。分别对18万条数据进行训练,1万条数据数据进行测试。通过准确率,精确率,回召率,F1值以及损失率来分别验证六种模型的优缺点。准确率、精确率、回召率、F1值计算公式如下:
其中P代表precision,R代表recall,TP、FP、FN、TN可以理解为:TP:预测为1,实际为1,预测正确,FP:预测为1,实际为0,预测错误,FN:预测为0,实际为1,预测错误,TN:预测为0,实际为0,预测正确。
实验准确率,精确率,回召率,f1值比较:
本案中所采用的损失函数为交叉熵损失函数。交叉熵描述了两个概率分布之间的距离。值越小,两者越接近。但由于神经网络的输出不一定是概率分布。
实验损失率比较:
基于以上实验结果,可得出如下结论:本案提出的EBDA模型通过在THUCNews新闻文本分类数据集上验证,可以看出EBDA模型在准确率,精确率,回召率,f1值相对于其它模型来说取得了较大的提升。在损失函数方面,EBDA模型也取得了较低的损失率。可以看出ERNIE预训练模型可以对语义知识单元分析的更精确,Mish()激活函数可以允许更好的信息深入神经网络,融入注意力机制之后,可以获取有效特征信息所分配的权重大小来进行分类,增强文本内部的词依赖关系以及EBDA模型中的各个模块都发挥出了更好的效果,从而获得了更高的实验效果。
除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对步骤、数字表达式和数值并不限制本发明的范围。
在这里示出和描述的所有示例中,任何具体值应被解释为仅仅是示例性的,而不是作为限制,因此,示例性实施例的其他示例可以具有不同的值。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
最后应说明的是:以上所述实施例,仅为本发明的具体实施方式,用以说明本发明的技术方案,而非对其限制,本发明的保护范围并不局限于此,尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特征进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的精神和范围,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 融合自注意力机制和深度学习的文本分类方法及系统
- 一种基于模型融合的深度学习文本分类方法及系统