一种基于语音特征挖掘新词汇的方法及系统
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于NLP和语音相结合的分词技术领域,特别是涉及一种基于语音特征挖掘新词汇的方法及系统。
背景技术
随着网络技术的发展,各个领域一直在不断的涌入新词。新词的发现是NLP领域的基础任务之一,可以提高计算机对文本的理解能力。
现有的新词的发现方法主要有:人工标注、分词等几种方式。对于人工标注的方法,需要耗费大量的人力物力。对于分词方法,往往出现分词错误的情况,导致新词难以被发现。比如:“时空伴随”,利用jieba分词的结果为:”时空伴随”。我们都知道,“时空伴随”这个词是因为疫情而产生的一个新词,如果用传统的分词,则会将这个新词分开,导致难以发现“时空伴随”这个新词。
传统的分词技术,只考虑了文本语义信息,而新词往往很难知晓他的语义信息,因此往往会出现分词效果不佳的现象。
发明内容
发明目的:提出一种基于语音特征挖掘新词汇的方法及系统,以解决现有技术存在的上述问题。通过结合说话方式的连贯性,对收集到的语音文本数据集进行分词,从中发现新词。
技术方案:第一方面,提出了一种基于语音特征挖掘新词汇的方法,该方法具体包括以下步骤:
步骤1、构建包含语音数据和对应文本数据的训练数据集;
步骤2、对训练数据集中的数据进行半标注;
对训练数据集中的数据执行半标注的过程中,采用{B,S,M,E}的模式进行标注,其中B表示一个词的开头,S表示单个字,M表示一个词的中间,E表示一个词的结束。在完成数据标注后,利用至少三种分词技术对文本数据进行分词,并针对分词结果进行判断和修正,获得处理后的语音训练数据TS=[TS
步骤3、读取训练数据集中每一条训练数据,利用语音识别技术,将语音数据和对应的文本数据进行对齐,实现一条语音数据到语音片段的转换;
基于获取到的每个文字对应的语音片段,在经过预处理后,得到语音片段对应的频域特征即向量矩阵TSF
式中,f
步骤4、构建语音文本分词模型,并利用训练数据集进行性能训练;其中,语音文本分词模型包括:输入层、编码层、全连接层、Bert模型、Softmax层和输出层;
在利用语音文本分词对训练数据集进行处理分析时,具体包括以下步骤:
步骤4.1、读取训练数据集中的每个文本数据对应语音片段数据的频域特征矩阵;
步骤4.2、利用编码层对读取到的频域特征矩阵进行编码,输出对应的语音编码向量;
步骤4.3、基于预设的字典,将文本数据转换为文字编码向量;
步骤4.4、将语音编码向量和文字编码向量进行纵向拼接,得到输入向量;
步骤4.5、采用全连接层对输入向量进行维度转换;
步骤4.6、将转换后的向量输入Bert模型进行分析,获得输出矩阵H;
步骤4.7、将输出矩阵中的向量经过一个全连接层后,得到预测向量;
步骤4.8、利用softmax将预测向量映射到对应每个类别的概率向量,并输出对应的类别;
步骤4.9、计算输出值与真实值之间的损失函数,并通过反向传播的方式优化模型参数。
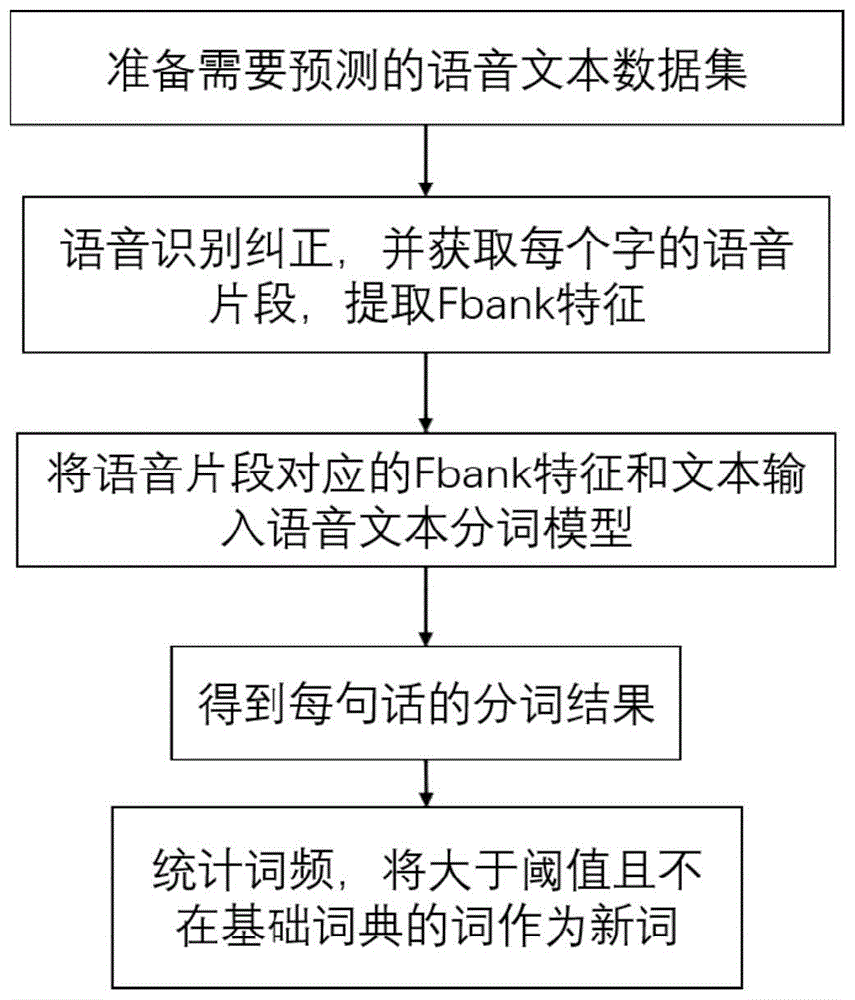
步骤5、利用训练完的语音文本分词模型对待分析语音文本数据进行新词分析,利用语音文本分词模型对待分析语音文本数据进行新词分析的过程具体包括以下步骤:
步骤5.1、获取待分析的语音文本对;所述语音文本对包含语音数据和对应的文本数据;
步骤5.2、将语音文本对传输至语音识别模型,获得每个文本对应的语音片段;
步骤5.3、提取语音片段中的频域特征与对应的文字,获得语音文本分词模型的输入数据集;
步骤5.4、利用语音文本分析模型对输入数据集进行分析,得到每个字的标签,获取到每句话的分词结果;
步骤5.5、比对分词词典与语音文本分析模型的分析结果,判断新词;
步骤5.6、将获得的新词更新至分词词典中。
步骤6、将得到的新词结果输出。
在第一方面的一些可实现方式中,为了提高语音文本分词模型的性能,采用交叉熵损失函数判断真实值与预测值的差值,并通过反向传播的方式,更新模型中的参数,实现模型的性能优化;
所述交叉熵损失函数的表达式为:
式中,N表示训练的总样本数;i表示第i条数据;t表示第i条数据第t个文字;c表示第i条数据第t个文字第c类;
第二方面,提出一种基于语音特征挖掘新词汇的系统,用于实现基于语音特征挖掘新词汇的方法,该系统具体包括以下模块:
用于构建训练数据集的数据集构建模块;
用于对训练数据执行半标注的数据标注模块;
用于提取训练数据频域特征的特征提取模块;
用于构建语音文本分析模型的模型构建模块;
用于执行新词分词的数据分析模块;
用于输出新词的新词输出模块。
其中语音文本分词模型包含:输入层、编码层、全连接层、Bert模型、Softmax层和输出层。
第三方面,提出一种智能仓储运输中的障碍物识别规避设备,该设备包括:处理器以及存储有计算机程序指令的存储器。
其中,处理器读取并执行计算机程序指令,以实现基于语音特征挖掘新词汇的方法。
第四方面,提出一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序指令。计算机程序指令被处理器执行时,以实现基于语音特征挖掘新词汇的方法
有益效果:本发明提出了一种基于语音特征挖掘新词汇的方法及系统,通过结合说话方式的连贯性,对收集到的语音文本数据集进行分词,从中发现新词。与现有技术相比,结合了语音特征和文本语义特征对句子进行分词,考虑到了更多的特征,分词效果高于单纯的文本分词;另外,待分析的文本数据来源于实时获得的语音文本数据,可以实时自主的发现新词,且在应用过程中无需重新训练模型或人工标注,节省了人力。除此之外,在模型性能训练的过程中,针对获取的训练集采用三种分词方式对数据进行标注,并只对标注不一致的进行人工检验,达到提高标注数据准确性的同时,不需要从零开始,有效节省了人工成本。
附图说明
图1为本发明的语音数据对应的波形图。
图2为本发明的数据处理流程图。
图3为本发明语音文本分词模型流程图。
图4为本发明基于新的语音文本分词推理流程图。
具体实施方式
在下文的描述中,给出了大量具体的细节以便提供对本发明更为彻底的理解。然而,对于本领域技术人员而言显而易见的是,本发明可以无需一个或多个这些细节而得以实施。在其他的例子中,为了避免与本发明发生混淆,对于本领域公知的一些技术特征未进行描述。
申请人认为随着网络技术的发展,常常会出现新的词汇涌入大众的生活,但是已有的分词技术中并没有实时跟进对新词的划分方法,从而导致对新词错误理解的现象产生。针对新词的挖掘分析,本发明考虑说话并不是单个字往外蹦的特性,结合说话的方式,分析语音波形,提出一种基于语音特征挖掘新词汇的方法及系统,通过结合语音技术和NLP技术,从中发现新词。
实施例一
在一个实施例中,针对现有技术只考虑文本语义信息的特性,结合说话方式的连贯性,提出一种基于语音特征挖掘新词汇的方法,通过对收集到的语音文本数据集进行分词,从中发现新词。
如图1所示为一段新闻语音数据对应的波形图,从划分的波形图中可以看出一个词的波形会密切结合,不同词之间的波形则会存在间隔,例如图1中可以将“关于密接次密接和高风险人群的隔离管控措施”分词为“关于密接次密接和高风险人群的隔离管控措施”。其中,密接和次密接这两个词是2020年疫情以后出现的新词汇,如果利用以前训练好的分词模型,在不增加额外知识或者训练集的前提下,难以将其分好的。因此,本实施例针对语音文本连贯的特殊性,构建语音文本分词模型,并利用提出的新词汇挖掘方法对收集到的语音文本数据集进行分词,该方法具体包括以下步骤:
步骤1、构建具备语音数据和文本数据的训练数据集;
具体的,为了提高新词被挖掘到的准确性,在语音文本分词模型执行新词汇挖掘之前,首先对其进行性能训练。训练过程中为了便于训练数据集的获取,优选实施例中采用开源的中文语音数据集,例如THCHS30、AISHELL等。为满足对训练数据集的需求,这些语料均具有语音数据集和对应的文本数据集。
步骤2、对训练数据集中的数据进行半标注;
具体的,采用{B,S,M,E}的模式进行标注,其中B表示一个词的开头,S表示单个字,M表示一个词的中间,E表示一个词的结束。例如“我出生地在中国”对应的分词结果为“我出生地在中国”,对应的标注数据为“SBMMESBE”。
随后,针对读取到的训练集数据,利用现有技术中的分词模型jieba分词、HanLP分词和词典三种分词技术,对上述语料涉及到的文本进行分词。
在进一步的实施例中,对文本的分词结果进行比对,当不同分词技术的分词结果一致时,则不对分词结果做进一步的检查处理;反之,则进行人工检查,修正分词结果;从而获得最终的语音训练数据TS=[TS
本实施例利用三种不同的开源分词技术对同一句话进行分词,不需要人工对每条分词结果进行检查,只需要对分词结果不一致的进行检查,大量节省了人工检查的成本。
步骤3、读取训练数据集中每一条训练数据,并提取频域特征;
具体的,读取训练数据集中的每一条语音训练数据TS
在进一步的实施例中,利用开源的语音识别技术可以达到语音对齐的目的,即输入一段语音TS
随后,提取每个语音片段的FBank特征,即以帧率为f,经过预加重、分帧、加窗、快速傅里叶变换、复数取模、Mel滤波等步骤。最终,对于每个语音片段Ts
式中,f
步骤4、构建语音文本分词模型,并利用训练数据集进行性能训练;
具体的训练过程如图2所示,如图3所示语音文本分词模型包含输入层、编码层、全连接层、Bert模型、Softmax层和输出层。在性能训练的过程中,TSF1,TSF2,……TSFt为一条训练数据集中每个文字对应语音片段的FBank声学特征矩阵;Conformer为一个声学encoder模型,每个Conformer共享参数,结构完全一致;语音特征1,语音特征2……语音特征t为Conformer输出的Encoder向量,维度为512*1。将语音特征1,语音特征2……语音特征t标记为变量Con_E
Con_E
文字向量1,文字向量2……文字向量t为每个文字的编码,基于事先准备的字典,将每个字对应的编码向量随机初始化为768*1维的向量;并将文字向量1,文字向量2……文字向量t标记记为T_E
随后,将语音特征和文字特征进行纵向拼接,得到维度为1280*1的Input
将得到的数据BInput
H=Bert(BInput)
式中,BInput=(BInput
对于每个隐藏层向量h
式中,
最后,计算预测值
式中,N表示训练的总样本数;i表示第i条数据;t表示第i条数据第t个文字;c表示第i条数据第t个文字第c类;
上述整个过程完成模型的讲解,最后根据该交叉熵进行反向传播,更新Bert模型参数、汉字字典参数,全连接层参数和Conformer模型参数,完成性能训练。
步骤5、利用训练完的语音文本分词模型对待分析语音文本数据进行新词分析;
具体的,如图4所示,对新词进行挖掘分析的过程包括以下步骤:首先,获取包含语音数据和文本数据的语音文本对;其次,将获取到的语音文本对输入语音识别模型中,获取每个文字对应的语音片段,并对每个语音片段进行预处理,得到对应的FBank特征,构成输入数据集;再次,将得到的输入数据集输入语音文本分词模型中,得到每个字的标签,进而获得每句话的分析结果;从次,通过比对的方式,判断新词;最后,将获得的新词更新至分词词典中。
在进一步的实施例中,在语音文本分词模型训练完成后,根据需求对待分析的语音文本数据进行预测分析,获得新词。预测分析的过程中,仍需要准备语音文本对,具体的语音文本对可根据实际需求采集。例如新闻领域,可以收集新闻联播的语音数据集,在可以直接从网上获取到对应的文本数据时,采用爬虫直接进行获取;若不存在可以直接获取的情况,则使用OCR的方式对新闻的字幕进行识别,获取其对应的文本。针对文学作品的应用场景,例如在喜马拉雅APP上有专门的人去朗读小说,可以在上面下载对应的语音数据和对应的文本。
针对获取到的语音文本对,将其中的语音数据输入至语音识别模型中,获得每个文字对应的语音片段,并对每个语音片段进行预处理,得到相应的FBank特征,进而获得输入数据集。随后,将输入数据集输入至语音文本分词模型中,得到每个字的标签,进而获得每句话的分词结果。
最后,基于现有的基础分词词典WD,通过比对的方式对获取到的分词结果进行判断分析。具体的,在语音文本分词模型分析处理后,可得到一系列的词语Nowd
步骤6、将得到的新词结果输出。
实施例二
在一个实施例中,提出一种基于语音特征挖掘新词汇的系统,用于实现一种基于语音特征挖掘新词汇的方法,该系统具体包括以下模块:数据集构建模块、数据标注模块、特征提取模块、模型构建模块、数据分析模块、新词输出模块。
具体的,数据集构建模块用于构建训练数据集;数据标注模块用于对训练数据集中的数据进行半标注;特征提取模块用于读取训练数据集中每一条训练数据,并提取频域特征;模型构建模块用于构建语音文本分词模型,并利用训练数据集进行性能训练;数据分析模块用于利用训练完的语音文本分词模型对待分析文本进行新词分析;新词输出模块用于将得到的新词结果输出。
其中语音文本分词模型包含:输入层、编码层、全连接层、Bert模型、Softmax层和输出层。在执行数据分析的过程中,输入层首先接收用于分析的数据,随后利用编码层对数据进行编码;针对编码后的数据利用全连接层进行维度转换,并将转换后的数据输入Bert模型中,获得输出矩阵H;将输出矩阵中的向量经过一个全连接层后,得到预测向量;最后,利用softmax将预测向量映射到对应每个类别的概率向量,并输出对应的类别。
如上所述,尽管参照特定的优选实施例已经表示和表述了本发明,但其不得解释为对本发明自身的限制。在不脱离所附权利要求定义的本发明的精神和范围前提下,可对其在形式上和细节上做出各种变化。