一种基于多线程并行的GPU快速目标跟踪方法
文献发布时间:2024-01-17 01:24:51
技术领域
本发明涉及原料混合技术领域,具体为一种基于多线程并行的GPU快速目标跟踪方法。
背景技术
目标跟踪是计算机视觉领域中一个重要同时具有挑战性的研究方向,目标跟踪技术无论在民用还是军事上都有广泛的应用,包括视频监控、人机交互、无人驾驶以及导弹的跟踪拦截等,目标跟踪技术的基本思想是序列图像中根据目标在视频信息的时空上相关性,确定感兴趣的目标在每一帧的位置和姿态,目标跟踪技术经过几十年的发展,已取得了可观的进步,提出了许多性能优异的跟踪算法,但是由于跟踪方法受到许多因素的影响,尤其是光照的变化、遮挡、姿态与视角的变化、相似物体及所处的复杂背景的干扰等,此外,在实际工程应用的过程中,不仅要保证目标跟踪的准确性,还要时刻保证跟踪的实时处理能力,因此在这种情况下,需要在目标跟踪方法中加入多种并行技术和访存优化技术,在保证跟踪准确性不变的情况下,还能有实时高效的处理速度;
但是利用深度网络提取多层次的特征后,在构建滤波器进行预测后,高层的卷积特征构造的滤波器具有更大的权重,低层特征构造的滤波器分配较小的权重,这是因为高层的信息具有更丰富的语义信息,比起低层的特征其发挥的作用更加明显,这是合理的,但是这些权重都是固定的,而在跟踪过程容易受各种因素干扰,固定的权重已经不能胜任目标姿态的变化了,因此,分层特征构建的滤波器融合为最后的预测滤波器,需要探索一种自适应的动态加权方法,以此来动态应对跟踪过程中目标出现的姿态变化、背景变化以及遮挡等干扰;
单核处理器性能已经碰到了瓶颈,想通过单核上的优化去显著提高算力已经是一个非常困难的事情,此外,现有的目标跟踪算法都是同步计算的,各个模块按照顺序进行处理,一般的流程为图像序列读取、特征提取、滤波器定位、模型更新,这样一个流程很多的任务是空闲的,会消耗大量的时间在等待前一个任务完成,其效率并不高,而目标跟踪算法在实际部署过程中,需要进行快速的计算,同时尽可能发挥GPU的处理性能,在保证跟踪准确性不变的情况下,使得跟踪算法具备超实时的处理速度。
发明内容
本发明的目的在于提供一种基于多线程并行的GPU快速目标跟踪方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:一种基于多线程并行的GPU快速目标跟踪方法,包括以下步骤:
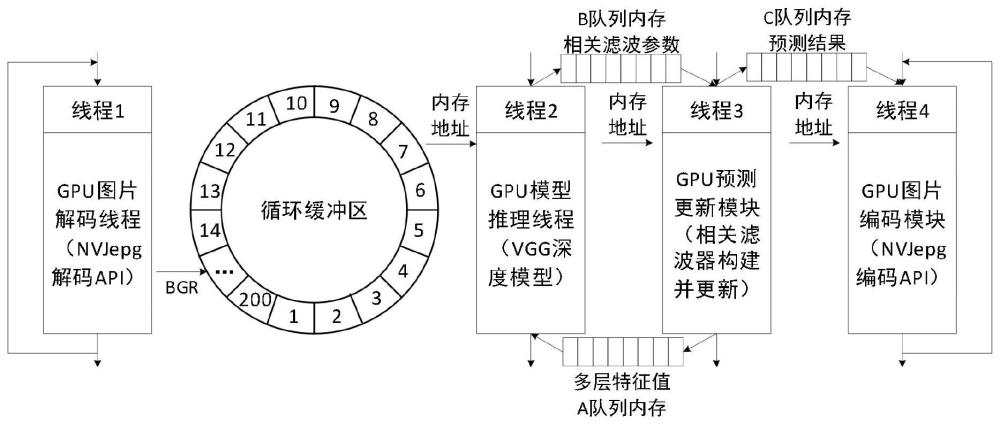
S1、内存开辟及变量预设定,读取视频序列,获得第一帧图像的大小,目标位置(矩形的左上角横纵坐标和宽w及高度h);
S2、图片解码器线程运行,调用nvJPEG库进行图片解码,初始化nvJPEG句柄,指定空闲的GPU芯片用于解码,初始化GPU解码器相关参数;
S3、特征提取线程运行,从循环缓存内存中获取第t帧图像的内存地址,准备进入网络模型进行特征提取;
S4、预测更新线程运行,从A队列内存中取出三层的特征值,并释放该内存;
S5、图片编码器线程运行,调用nvJPEG库进行图片编码,初始化nvJPEG编码句柄,指定同一块GPU芯片用于编码,初始化GPU编码器相关参数。
优选的,所述S1还包括以下步骤:
步骤1:在GPU上开辟循环缓冲内存,大小为200个1024*1024*3字节,用于存储加载进来的解码后的图像;
步骤2:在GPU上开辟3个队列缓冲内存,分别记作A队列、B队列和C队列,大小皆为5*1024字节;
步骤3:计算高斯标签函数标签中的参数σ,其中
步骤4:计算候选区域(目标区域的2.5倍),包含cell_size的长度M和高度N;
步骤5:针对每一个cell块,利用参数σ建立高斯函数标签,公式为
步骤6:初始化深度模型网络,本发明采用的是常见的VGGNet-19深度模型。
优选的,所述S2包括以下步骤:
步骤1:传入GPU的循环缓存内存所在的首地址,将解码后的GPU直接写入该循环缓存内存中;
步骤2:写完GPU内存后不需要等待,直接继续获取下一帧视频,继续解码;解码线程独立运行,待循环缓存内存全满时,等待空闲内存。
优选的,所述S3包括以下步骤:
步骤1:在第t帧的图像上裁剪出目标的候选区域,其大小一般为t-1帧目标大小的2.5倍区域;
步骤2:将候选图像区域进行单精度处理,并且利用深度卷积网络进行重采样,归一化后计算出均值,然后图像去均值;
步骤3:利用VGGNet-19预训练的网络模型对候选区域进行特征提取,提取不同卷积层的深度特征。
优选的,所述S3还包括以下步骤:
步骤4:卷积层的每层输出是一组多通道的特征图
步骤5:将t帧候选区域提取到的三层特征图数值(大小分别为56*56*256,28*28*512,14*14*512)和图像的内存地址拷贝至A队列内存中;
步骤6:从B队列内存中取出t帧的目标位置预测信息,若队列中没有值,则阻塞等待,获取成功后则释放该内存,取到值后在t帧图像上再一次提取预测框的三层特征,将这些特征值拷贝到A队列内存中;
步骤7:从循环缓存内存继续提取t+1帧图像进行特征提取。
优选的,所述S4包括以下步骤:
步骤1:构建每一层特征的每个特征通道d(d∈{1,2,....,D})的相关滤波器,构造的公式为
步骤2:记它在第l层中的第d个通道的特征图,表示为
步骤3:获得了三层卷积层的特征响应之后,将响应图记为集合{E
优选的,所述S4还包括以下步骤:
步骤4:计算峰值旁瓣比PSR值来决定动态权重,用于加权融合所有的响应图,最终的相应图为
步骤5:通过找到最大响应值E(m,n)即可以定位当前跟踪目标的中心位置p
步骤6:将t帧的目标中心位置p
步骤7:更新相关滤波器模型,为了获得鲁棒的近似值,更新第t帧的分子
优选的,所述S5包括以下步骤:
步骤1:从C队列中取出图片的内存地址和位置信息,释放该内存,结合目标预测框的宽高信息,在图片上框出目标位置;
步骤2:利用GPU编码器对图片进行编码,编码后直接写入到cpu端,用于结果显示,传入GPU的循环缓存地址,将解码后的GPU直接写入循环缓存内存中;
步骤3:这一帧编码完成后释放循环缓存内存,不需等待后直接继续获取下一帧的结果进行编码。
与现有技术相比,本发明的有益效果是:
本发明不仅具有很高的跟踪准确率和成功率,较好地应对了快速运动、遮挡、光照等干扰因素的影响,还能在部署应用的过程具备了超实时的跟踪效率,将目标跟踪的同步流程改进为多个线程并行流程,大大提高了跟踪的效率,做到了算法落地,响应图的波动状态可以反映跟踪结果的置信度,且利用响应图的PSR值来动态调整权重,从而实现将多级特征响应图有效融合,得到最后的响应图,提升跟踪效果,多种GPU访存优化技术,包括循环缓冲内存和队列内存,通过在初始化开辟GPU内存空间后便不再申请内存,从而能实现在算法执行过程中不打断GPU计算运行,充分挖掘GPU优势,提高了GPU的利用率。
附图说明
图1为本发明实施例提供主体流程图;
图2为本发明实施例提供的VGGNet-19网络结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-2,本发明提供一种技术方案:一种基于多线程并行的GPU快速目标跟踪方法,包括以下步骤:
S1、内存开辟及变量预设定,读取视频序列,获得第一帧图像的大小,目标位置(矩形的左上角横纵坐标和宽w及高度h);
S2、图片解码器线程运行,调用nvJPEG库进行图片解码,初始化nvJPEG句柄,指定空闲的GPU芯片用于解码,初始化GPU解码器相关参数;
S3、特征提取线程运行,从循环缓存内存中获取第t帧图像的内存地址,准备进入网络模型进行特征提取;
S4、预测更新线程运行,从A队列内存中取出三层的特征值,并释放该内存;
S5、图片编码器线程运行,调用nvJPEG库进行图片编码,初始化nvJPEG编码句柄,指定同一块GPU芯片用于编码,初始化GPU编码器相关参数。
S1还包括以下步骤:
步骤1:在GPU上开辟循环缓冲内存,大小为200个1024*1024*3字节,用于存储加载进来的解码后的图像;
步骤2:在GPU上开辟3个队列缓冲内存,分别记作A队列、B队列和C队列,大小皆为5*1024字节;
步骤3:计算高斯标签函数标签中的参数σ,其中
步骤4:计算候选区域(目标区域的2.5倍),包含cell_size的长度M和高度N;
步骤5:针对每一个cell块,利用参数σ建立高斯函数标签,公式为
步骤6:初始化深度模型网络,本发明采用的是常见的VGGNet-19深度模型。
S2包括以下步骤:
步骤1:传入GPU的循环缓存内存所在的首地址,将解码后的GPU直接写入该循环缓存内存中;
步骤2:写完GPU内存后不需要等待,直接继续获取下一帧视频,继续解码;解码线程独立运行,待循环缓存内存全满时,等待空闲内存;
S3包括以下步骤:
步骤1:在第t帧的图像上裁剪出目标的候选区域,其大小一般为t-1帧目标大小的2.5倍区域;
步骤2:将候选图像区域进行单精度处理,并且利用深度卷积网络进行重采样,归一化后计算出均值,然后图像去均值;
步骤3:利用VGGNet-19预训练的网络模型对候选区域进行特征提取,提取不同卷积层的深度特征;
S3还包括以下步骤:
步骤4:卷积层的每层输出是一组多通道的特征图
步骤5:将t帧候选区域提取到的三层特征图数值(大小分别为56*56*256,28*28*512,14*14*512)和图像的内存地址拷贝至A队列内存中;
步骤6:从B队列内存中取出t帧的目标位置预测信息,若队列中没有值,则阻塞等待,获取成功后则释放该内存,取到值后在t帧图像上再一次提取预测框的三层特征,将这些特征值拷贝到A队列内存中;
步骤7:从循环缓存内存继续提取t+1帧图像进行特征提取;
S4包括以下步骤:
步骤1:构建每一层特征的每个特征通道d(d∈{1,2,....,D})的相关滤波器,构造的公式为
步骤2:记它在第l层中的第d个通道的特征图,表示为
步骤3:获得了三层卷积层的特征响应之后,将响应图记为集合{E
S4还包括以下步骤:
步骤4:计算峰值旁瓣比PSR值来决定动态权重,用于加权融合所有的响应图,最终的相应图为
步骤5:通过找到最大响应值E(m,n)即可以定位当前跟踪目标的中心位置p
步骤6:将t帧的目标中心位置p
步骤7:更新相关滤波器模型,为了获得鲁棒的近似值,更新第t帧的分子
S5包括以下步骤:
步骤1:从C队列中取出图片的内存地址和位置信息,释放该内存,结合目标预测框的宽高信息,在图片上框出目标位置;
步骤2:利用GPU编码器对图片进行编码,编码后直接写入到cpu端,用于结果显示,传入GPU的循环缓存地址,将解码后的GPU直接写入循环缓存内存中;
步骤3:这一帧编码完成后释放循环缓存内存,不需等待后直接继续获取下一帧的结果进行编码。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 一种针对大数据任务处理的基于CPU多线程与GPU多粒度并行及协同优化的方法
- 一种基于GPU并行计算的视频运动目标跟踪方法