一种实体分类模型训练方法、实体分类方法及相关装置
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及文本分类技术领域,特别是涉及一种实体分类模型训练方法、实体分类方法及相关装置。
背景技术
实体提取是信息提取任务的一个基础任务,是很多其他信息提取任务的上游任务。但是传统的实体提取任务面向粗粒度的类别,比如人物、地点和组织机构等,对实体的刻画不够精确。需要更加细粒的类别来刻画实体,于是,下游应用催生了细粒度实体分类(Fine-grained Entity Typing)这个任务,给定候选实体提及(mention)及其上下文(context),划分为具体的细粒度实体类型。
细粒度实体分类任务的主要困难点是缺少人工标注数据,尤其是在垂直领域,需要具备领域相关知识的人员针对领域文本进行标注,需要耗费大量的人力在数据准备阶段,当无标注情况下,实体分类困难。
发明内容
本发明主要解决的技术问题是提供一种实体分类模型训练方法、实体分类方法及相关装置,能够实现在无标注的情况下进行实体分类模型的训练。
为解决上述技术问题,本发明采用的一个技术方案是:提供一种实体分类模型训练方法,该实体分类模型训练方法包括:从文字样本中提取对应的上位词和下位词;基于上位词确定下位词对应的实体标签;利用下位词和下位词对应的实体标签训练实体分类模型。
其中,基于上位词确定下位词对应的实体标签包括:计算上位词和各个标准标签的相似度,将与上位词相似度最高的标准标签作为下位词对应的实体标签。
其中,计算上位词和各个标准标签的相似度,将与上位词相似度最高的标准标签作为下位词对应的实体标签包括:获取上位词的词向量和各个标准标签的词向量;计算上位词的词向量和各个标准标签的词向量之间的距离,距离越近,相似度越高;将与上位词的词向量距离最近的标准标签作为下位词对应的实体标签。
其中,从文字样本中提取对应的上位词和下位词包括:获取文字样本;利用上下位匹配规则从文字样本中提取存在上下位关系的词,得到上位词和下位词。
其中,实体分类模型包括语义识别层和分类层,利用下位词和下位词对应的实体标签训练实体分类模型包括:对语义识别层进行训练,得到预训练的语义识别层;通过预训练的语义识别层提取到下位词的词向量;通过分类层对下位词的词向量进行处理,得到下位词的实体分类结果;基于下位词的实体分类结果和下位词的实体标签,调整分类层的参数,以得到训练后的实体分类模型。
其中,语义识别层为BERT网络,对语义识别层进行训练包括:利用通用领域文本对BERT网络进行训练;利用垂直领域文本对训练后的BERT网络进行训练。
其中,基于下位词的实体分类结果和下位词的实体标签,调整分类层的参数之后包括:基于训练后的实体分类模型对无标签实体打标签;利用下位词和下位词对应的实体标签、无标签实体和对应的标签对训练后的实体分类模型再次训练。
其中,通过预训练的语义识别层提取到下位词的词向量包括:通过预训练的语义识别层,并基于下位词所属的文字样本的上下文语义信息,提取到下位词的词向量。
为解决上述技术问题,本发明采用的另一个技术方案是:提供一种实体分类方法,该实体分类方法包括:获取待识别文本和待识别文本中的待分类实体;将待识别文本和待分类实体输入实体分类模型中,以通过实体分类模型基于待识别文本对待分类实体进行分类,得到待分类实体的分类结果;其中,实体分类模型是通过上述的实体分类模型训练方法训练得到的。
为解决上述技术问题,本发明采用的另一个技术方案是:提供一种实体分类设备,该实体分类设备包括处理器,处理器用于执行以实现上述的实体分类模型训练方法。
为解决上述技术问题,本发明采用的另一个技术方案是:提供一种计算机可读存储介质,计算机可读存储介质用于存储指令/程序数据,指令/程序数据能够被执行以实现上述的实体分类模型训练方法。
本发明的有益效果是:区别于现有技术的情况,本发明通过在无标注的文字样本中根据上下位关系的词提取出下位词和下位词对应的实体标签,以实现在无标注情况下获取样本语料库,利用获取的样本对,对实体分类模型训练,实现实体分类。
附图说明
图1是本申请实体分类模型训练方法第一实施方式的流程示意图;
图2是本申请实体分类模型训练方法第二实施方式的流程示意图;
图3是本申请实体分类模型训练方法第三实施方式的流程示意图;
图4是本申请实体分类模型训练方法中一具体实施方式的流程示意图;
图5是本申请实体分类模型训练方法第四实施方式的流程示意图;
图6是本申请实施方式中实体分类装置的结构示意图;
图7是本申请实施方式中实体分类设备的结构示意图;
图8是本申请实施方式中计算机可读存储介质的结构示意图。
具体实施方式
为使本发明的目的、技术方案及效果更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。
实体提取是信息提取任务的一个基础任务,如实体提取任务提取出了人物,地址,机构,时间,地址等粗粒度的实体,细粒度实体分类则是根据业务背景,将对应的粗粒度实体分类获取其细粒度实体标签,例如地址可能根据行政区划分为省级地址,市级地址等,人物实体可能根据人物的职业划分为歌手、演员等,具体的细粒度标签划分方法是由实际业务场景而定的。
而细粒度实体分类任务的主要困难点是缺少人工标注数据,尤其是在垂直领域,需要具备领域相关知识的人员针对领域文本进行标注,需要耗费大量的人力在数据准备阶段。一般解决这个任务的一个较通用的方案是远程监督,即通过链接文本中的实体提及与知识库(Knowledge Base,KB)或知识图谱(Knowledge Graph,KG)中的实体,其中,为了方便计算机的处理和理解,三元组是一种形式化、简洁化的表示知识的方式,三元组为实体、实体关系和实体的形式,将实体看作节点,把实体关系看作一条边,包含了大量三元组的知识库就成为了一个庞大的知识图谱。将知识库中的实体类别赋予这个实体,从而得到标注数据,然后使用这份数据集训练分类模型,用于细粒度的实体分类。
尽管如此,该解决方案还是有其限制性。该方法的标签体系严重依赖于知识库,但是实际情况中细粒度实体标签体系可能会随着业务的需要随时变更,因此如果缺少领域知识库,或者知识库的实体标签体系不全或更新速度慢,就无法获取较完整的且质量较高的训练集。因此,本申请提供的实体分类模型训练方法,通过在无标注的文字样本中根据上下位关系的词提取出实体样本和实体样本对应的实体标签,利用实体标签和标准标签的相关性,确定实体样本的标准标签,以实现在无标注情况下获取样本语料库,利用获取的样本对,对实体分类模型训练,实现实体分类。
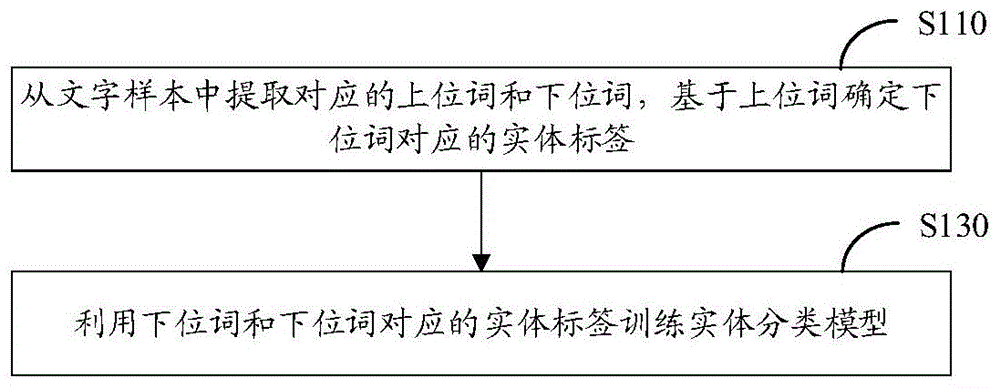
请参阅图1,图1是本申请实体分类模型训练方法第一实施方式的流程示意图。需注意的是,若有实质上相同的结果,本实施例并不以图1所示的流程顺序为限。如图1所示,本实施方式包括:
S110:从文字样本中提取对应的上位词和下位词,基于上位词确定下位词对应的实体标签。
可以从样本数据库中直接获取文字样本,也可以从特定领域的文本中获取文字样本,其中,特定领域的文本如搜索引擎中的搜索文本,公安领域的案件描述文本,法律领域的裁判文书,社交领域的用户生成内容等。从文字样本中提取对应关系的上位词和下位词,基于上位词确定下位词对应的实体标签,具体地,文字样本为包括实体和实体类型的文本,将下位词作为实体样本,将对应的上位词,即实体样本的样本类型作为实体样本对应的实体标签。
S130:利用下位词和下位词对应的实体标签训练实体分类模型。
将下位词和下位词对应的实体标签作为样本组训练实体分类模型。具体地,将实体样本数据实体分类模型中,将输出结果和标准标签对比,反向调整实体分类模型中的参数,使得分类结果更加接近标准标签。训练好的实体分类模型可以对待分类实体进行分类。
在具体使用场景中,因文字样本比较丰富的表达形式,获取到的实体标签也具有丰富的表达形式,存在属于同一层级但具有不同表达形式的实体标签,但并不是特定领域下的标准类型。因此,本申请预先获取在垂直领域内的标准的细粒度实体标签体系,将各个不标准的实体标签统一为标准标签。即标准标签是预先定义的细粒度实体类别标签,且各个标准标签与各个细粒度实体类别一一对应。具体地,请参阅图2,图2是本申请实体分类模型训练方法第二实施方式的流程示意图。需注意的是,若有实质上相同的结果,本实施例并不以图2所示的流程顺序为限。如图2所示,本实施方式包括:
S210:从文字样本中提取对应的上位词和下位词,基于上位词确定下位词对应的实体标签。
获取文字样本,利用上下位匹配规则从文字样本中提取存在上下位关系的词,得到上位词和下位词。
S230:计算上位词和各个标准标签的相似度,将与上位词相似度最高的标准标签作为下位词对应的实体标签。
因各个文本描述并没有固定的标准,可能存在同一个下位词对应的实体标签相似但用词不同的情况,在后续利用实体样本和对应的实体标签训练实体分类模型时,训练困难。例如公司、企业、合作社之类的实体标签应该属于同一层级的实体标签,即公司,因此需要将这些同义的实体标签名称映射到一个标准的标签体系中。其中,该标准的标签体系来自于业务定义,本申请直接获取一套标准标签体系,计算各个下位词的实体标签和标准标签体系下各个标准标签的相似度,获取与实体标签相似度最高的标准标签,将该实体标签和该标准标签相关联,将下位词对应的标准标签作为对应的实体标签。
S250:利用下位词和下位词对应的实体标签训练实体分类模型。
该实施方式中,通过在无标注的文字样本出提取出下位词和下位词对应的实体标签,利用下位词的实体标签和标准标签的相关性,确定实体样本的标签,以实现在无标注情况下获取样本语料库,利用获取的样本对,对实体分类模型训练,实现实体分类。
在一实施方式中,某些领域的实体是高度领域化的,如果使用来自通用领域的知识库,可能会存在语义偏移的情况,获取得到错误的标注结果,需要人工进行校验与纠错。因此,本申请提出一种针对特定领域下的实体分类模型训练方法。请参阅图3,图3是本申请实体分类模型训练方法第三实施方式的流程示意图。需注意的是,若有实质上相同的结果,本实施例并不以图3所示的流程顺序为限。如图3所示,本实施方式包括:
S310:获取文字样本中的下位词和下位词对应的实体标签。
获取可以进行信息提取的文字样本,该文字样本为已经完成初步的粗粒度实体提取的文本,进一步地,该文字样本可以为特定领域的文字样本,如公安领域的案件描述文本,警情信息,法律领域的裁判文书,社交领域的用户生成内容等。利用启发式规则获取文字样本中的实体样本和实体样本对应的实体标签。具体地,启发式规则为匹配模式,根据自定义的上位词和下位词模式从文字样本中获取对应的上位词和下位词,下位词为实体样本,上位词为实体标签。示例性地,文字样本为“香蕉是一种水果”,提取出上位词“水果”为实体标签,下位词“香蕉”为实体样本。
S330:计算上位词的词向量和各个标准标签的词向量之间的相似度,将与上位词相似度最高的标准标签作为下位词对应的实体标签。
获取下位词的词向量和标准标签的词向量;计算下位词的词向量和标准标签的词向量之间的距离,距离越近,相似度越高;将与上位词的词向量距离最近的标准标签作为下位词对应的实体标签。具体地,利用语义模型获取上位词的词向量和标准标签对应的词向量。其中,上位词为实体标签,下位词为实体样本,语义模型可以为BERT网络,BERT网络输出的基于上下文的动态词向量,其底层词向量则属于静态词向量。本申请基于训练好的BERT网络的底层词向量映射将实体标签的文本映射为实体标签的词向量,将标准标签的文本映射为标准标签的词向量。并计算实体标签的词向量和标准标签的词向量之间的距离,具体地,对于每一个实体标签的词向量,在标准标签的词向量中寻找距离最近的一个标准标签,距离越近,代表实体标签和标准标签的相似度越高,将与上位词的词向量距离最近的标准标签作为下位词对应的实体标签。因此,获取的实体样本和对应的标准标签,利用标准标签更新实体样本对应的实体标签。
其中,BERT网络主要用于两阶段预训练机制中,一共包括两个步骤:预训练和微调。在预训练中,模型基于无标签数据,在不同的预训练任务上进行训练,因此BERT网络包含有大量常识性知识。在微调中,模型首先基于预训练得到的参数初始化,然后使用来自下游具体任务的标签数据对所有参数进行微调。BERT网络预训练过程使用了基于掩盖的语言模型MLM(Masked Language Modeling),并且还加入了下句预测NSP(Next SentencePrediction),其中MLM主要是通过随机对输入序列中的某些位置进行遮蔽,然后通过模型来对其进行预测;其中NSP任务是同时输入两句话到模型中,然后预测第二句话是不是第一句话的下一句话。首先,获取通用领域文本,利用通用领域文本对BERT网络进行预训练,使得BERT网络实现基本文本的识别;然后,获取垂直领域文本,即确定具体任务,利用垂直领域文本对训练后的BERT网络进一步训练,使得BERT网络实现特定文本的识别。在特定领域中存在通用领域中的非常见词或特定含义的词,因此,本申请进行二次训练,能够提高语言识别层对垂直领域文本的识别能力。
S350:利用下位词和下位词对应的实体标签训练实体分类模型。
其中,实体分类模型包括语义识别层和分类层,语义识别层用于对实体样本进行语义识别,分类层用于对语义识别结果进行分类。请参阅图4,图4是本申请实体分类模型训练方法中一具体实施方式的流程示意图。需注意的是,若有实质上相同的结果,本实施例并不以图4所示的流程顺序为限。如图4所示,本实施方式包括:
S410:对语义识别层进行训练。
语义识别层可以为BERT网络,利用步骤S330中的训练方法,在通用文本训练BERT网络的基础上,再利用特定的垂直领域的文本进行训练,二次训练,能够用于识别垂直领域的待识别实体,得到预训练的语义识别层。具体训练方法在此不再赘述。
S430:利用实体样本和实体样本对应的实体标签对包含预训练语义识别层的实体分类模型进行训练。
将训练完成的语义识别层和分类层结合,得到实体分类模型,将实体样本输入实体分类模型中,通过预训练的语义识别层提取到下位词的词向量;通过分类层对下位词的词向量进行处理,得到下位词的实体分类结果;基于下位词的实体分类结果和下位词的实体标签,调整分类层的参数,以得到训练后的实体分类模型。其中,分类层为CRF(Conditional Random Field,条件随机场)分类层,CRF是一种有向图模型,用于建模一个序列的分类问题,给定词的标记序列,寻找序列的标记最可能的组合。
在本申请中,利用半监督的方法对分类层进行训练,如self-training、co-training等半监督方法。其中,本申请利用self-training的方式训练分类层,用未标记的数据集来扩充已标记的数据集。通过用已有的有标签的数据,对还未标记的数据打标签,然后将扩充的有标签数据更新模型,直到满足收敛条件。具体地,在利用上述下位词和下位词对应的实体标签训练分类层的基础对无标签实体打标签上,具体为获取无标签实体的样本,将无标签实体输入训练后的实体分类模型中,得到置信度最高的分类结果作为无标签实体的分类结果,将分类结果作为无标签实体的标签。由此,获取了新的一组样本数据,即无标签实体和无标签的实体的新的标签,扩充了样本数据库。利用下位词和下位词对应的实体标签、无标签实体和对应的标签对训练后的实体分类模型进行再次训练。
该实施方式中,通过提出一种基于无标注的领域文本的细粒度分类方法,从无标注领域文本中提取包含大量的实体样本和实体标签对的语料,进一步借助预训练模型中蕴含的大量语义信息,常识信息等完成实体标签与标准标签之间的映射关系,从而获得垂直领域的标注数据,训练获得分类模型,实现细粒度实体分类任务,能够解决训练数据依赖标注信息的问题,同时解决标注信息存在语义偏差,数据集质量差等问题,能够实现无标注的细粒度分类,提高模型训练效率和模型分类准确性。
对于特定的垂直领域,可能存在数据样本较少,模型训练困难等问题,因此,本申请提出一种实体分类模型训练方法,在具有垂直领域内的细粒度实体标签体系和完成初步的粗粒度实体提取的领域特定文本的基础上,从无标签数据中构建细粒度分类的标注数据,从而利用这些标注数据训练获得分类模型。具体地,请参阅图5,图5是本申请实体分类模型训练方法第四实施方式的流程示意图。需注意的是,若有实质上相同的结果,本实施例并不以图5所示的流程顺序为限。如图5所示,本实施方式包括:
S510:获取实体样本和实体标签的映射词典。
基于一些启发式的规则在提供的领域特定文本中提取下位词(实体样本)和上位词(实体标签)之间的映射字典。当领域特定文本的文本格式为:<名词1>例如<名词2>,<名词3>等,提取得到对应的映射词典为:(<名词2>,<名词1>),(<名词3>,<名词1>)。示例性地:一些海外的互联网公司,例如谷歌、脸书等,提取得到对应的映射词典为:(谷歌,互联网公司),(脸书,互联网公司),其中,“谷歌”为实体样本,“互联网公司”为对应的实体标签。当领域特定文本的文本格式为:<名词1>是一种/类<名词2>,提取得到对应的映射词典为:(<名词1>,<名词2>)。示例性地:竹子是一种多年生草本植物,提取得到对应的映射词典为:(竹子,草本植物),其中“竹子”为实体样本,“草本植物”为对应的实体标签。当领域特定文本的文本格式为:<名词1>属于<名词2>的一种,提取得到对应的映射词典为:(<名词1>,<名词2>)。示例性地:大米是主粮的一种,提取得到对应的映射词典为:(大米,主粮),其中,“大米”为实体样本,“主粮”为对应的实体标签。诸如此类,利用上述方法过滤文本数据,收集由诸如“苹果是一种水果”、“苹果是一个手机品牌”、“苹果是一家高科技公司。”之类的句子组成的大规模文本语料库,与此同时,还收集了大量的(实体样本,实体标签)对,例如(苹果,水果),(苹果,公司)和(微软,公司)等。
S530:训练领域语言模型。
首先,获取通用领域文本,利用通用领域文本对BERT网络进行预训练,使得BERT网络实现基本文本的识别;然后,获取垂直领域的大量无结构文本,即确定具体任务,利用垂直领域文本对训练后的BERT网络进一步训练,使得BERT网络实现特定文本的识别。
S550:实体标签名称映射。
对于获取的大量的(实体样本,实体标签)对,实体标签有相对较丰富的表达形式,甚至存在矛盾的(实体样本,实体标签)对,因此需要将这些同义的实体标签名称映射到一个标准的标签体系中。利用上述步骤的BERT网络的底层词向量映射获取(实体样本,实体标签)对中实体标签的词向量,得到一个实体标签的词向量矩阵,记为S;同样可以获得标准标签的词向量矩阵,记为T。对于任意的实体标签词向量s∈实体标签的词向量矩阵S,在标准标签的词向量矩阵T中寻找距离实体标签词向量s最近的标准标签词向量t,将对应的实体标签和标准标签对应,将实体样本赋予实体标签对应的标准标签,得到实体样本和标准标签的映射。示例性地,利用上述方法获取的(实体样本,实体标签)对有(谷歌,互联网公司),而“互联网公司”对应的标准标签为“公司”,则得到的“谷歌”对应的标准标签为“公司”,得到新的(实体样本,标准)对为(谷歌,公司)。
S570:训练实体分类模型。
实体分类模型包括语义识别层和分类层,具体地,在利用上述方法训练得到的语言模型的基础上,添加CRF分类层得到实体分类模型。使用self-training的本监督方式训练实体分类模型。对于样本数据中没有标签或者标签不明确的实体样本,在训练模型时采用半监督方法迭代更新标签。如,当实体样本为“苹果”时,其标签在实际场景中可能应该分类为水果、公司、电子产品、商标等,模型根据上下文语义学习,确定当前语境下的实体类别。因此,在利用实体样本和实体样本对应的标准标签训练分类层的基础上,将上述没有标签或者标签不明确的实体样本输入实体分类模型中,选择置信度最高的分类结果作为无标签的实体样本的分类结果,由此,获取了新的一组样本数据,即无标签的实体样本和无标签的实体样本的分类结果,扩充了样本数据库。利用分类实体和实体样本对应的标准标签、无标签的实体样本和无标签的实体样本的分类结果对训练后的实体分类模型进行训练。利用该迭代更新标签的方法,消除噪声数据对分类记过的影响。
S590:利用实体分类模型进行分类预测。
在训练好实体分类模型的基础上,本申请提出一种实体分类方法,具体地,获取待识别文本和待识别文本中的待分类实体;将待识别文本和待识别文本中的待分类实体输入训练好的实体分类模型中,以通过实体分类模型基于待识别文本对待分类实体进行分类,得到待分类实体的分类结果。示例性地,输入待识别文本为“谷歌公司在2017年发表论文《xxx》”,待分类实体为“谷歌”,将待识别文本和待分类实体输入训练后的实体分类模型中,对“谷歌”进行分类。
在该实施方式中,利用大量的无标注的领域文本,使用大量的匹配模式,获得与领域高度相关的实体和实体标签名称对的语料库,实现初步的冷启动。同时,借助预训练模型中蕴含的大量语义信息,常识信息等,并在领域文本上进行第一步预训练任务,最后在预训练模型获得的静态词向量空间上,完成实体类别与标准标签体系的映射关系,解决领域差异导致的文本识别错误问题,同时,使用半监督的方式训练分类模型,进一步地扩充了标注数据,便于利用无标注文本中可能存在的有效匹配对,提升分类模型的泛化能力,因此,本申请基于领域内的无标注文本,实现无需人工标注的情况下,开发特定领域的细粒度实体分类模型。
请参阅图6,图6是本申请实施方式中实体分类装置的结构示意图。该实施方式中,实体分类装置包括获取模块61和训练模块62。
其中,获取模块61用于从文字样本中提取对应的上位词和下位词,基于上位词确定下位词对应的实体标签;训练模块62用于利用下位词和下位词对应的实体标签训练实体分类模型。该实体分类装置用于通过在无标注的文字样本出提取出下位词和下位词对应的实体标签,利用实体标签和标准标签的相关性,确定下位词,即实体样本的标签,以实现在无标注情况下获取样本语料库,利用获取的样本对,对实体分类模型训练,实现实体分类。
请参阅图7,图7是本申请实施方式中实体分类设备的结构示意图。该实施方式中,实体分类设备71包括处理器72。
处理器72还可以称为CPU(Central Processing Unit,中央处理单元)。处理器72可能是一种集成电路芯片,具有信号的处理能力。处理器72还可以是通用处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。通用处理器可以是微处理器或者该处理器72也可以是任何常规的处理器等。
实体分类设备71可以进一步包括存储器(图中未示出),用于存储处理器72运行所需的指令和数据。
处理器72用于执行指令以实现上述本申请实体分类模型训练方法和实体分类方法任一实施例及任意不冲突的组合所提供的方法。
请参阅图8,图8是本申请实施方式中计算机可读存储介质的结构示意图。本申请实施例的计算机可读存储介质81存储有指令/程序数据82,该指令/程序数据82被执行时实现本申请实体分类模型训练方法和实体分类方法任一实施例以及任意不冲突的组合所提供的方法。其中,该指令/程序数据82可以形成程序文件以软件产品的形式存储在上述存储介质81中,以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本申请各个实施方式方法的全部或部分步骤。而前述的存储介质81包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,RandomAccess Memory)、磁碟或者光盘等各种可以存储程序代码的介质,或者是计算机、服务器、手机、平板等终端设备。
在本申请所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
以上所述仅为本发明的实施方式,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 命名实体识别模型训练方法、命名实体识别方法及装置
- 二分类模型训练方法、数据分类方法及对应装置
- 一种分类模型的训练方法和装置
- 票据自动分类训练方法、装置及自动分类方法、装置
- 实体关系分类模型训练方法、实体关系分类方法及装置
- 实体分类模型的训练方法、实体分类方法及装置