使用多个碱基检出器模型的碱基检出
文献发布时间:2024-04-18 19:59:31
优先权申请
本申请要求2022年7月28日提交的名称为“Base Calling Using Multiple BaseCaller Models”的美国非临时专利申请号17/876,528(代理人案卷号ILLM 1021-2/IP-1856-US)的优先权,该申请继而要求2021年8月3日提交的名称为“Base Calling UsingMultiple Base Caller Models”的美国临时专利申请号63/228,954(代理人案卷号ILLM1021-1/IP-1856-PRV)的权益。据此优先权申请以引用方式并入以用于所有目的。
技术领域
本发明所公开的技术涉及人工智能类型计算机和数字数据处理系统以及对应数据处理方法和用于仿真智能的产品(即,基于知识的系统、推断系统和知识采集系统);并且包括用于不确定性推断的系统(例如,模糊逻辑系统)、自适应系统、机器学习系统和人工神经网络。具体地,所公开的技术涉及将深度神经网络诸如深度卷积神经网络用于分析数据。
文献并入
以下文献以引用方式并入,即如同在本文完整示出一样:
2020年2月20日提交的名称为“Artificial Intelligence-Based Base Callingof Index Sequences”的美国临时专利申请号62/979,384(代理人案卷号ILLM 1015-1/IP-1857-PRV);
2020年2月20日提交的名称为“Artificial Intelligence-Based Many-to-ManyBase Calling”的美国临时专利申请号62/979,414(代理人案卷号ILLM 1016-1/IP-l 858-PRV);
2020年3月20日提交的名称为“Training Data Generation for ArtificialIntelligence-Based Sequencing”的美国非临时专利申请号16/825,987(代理人案卷号ILLM 1008-16/IP-1693-US);
2020年3月20日提交的名称为“Artificial Intelligence-Based Generation ofSequencing Metadata”的美国非临时专利申请号16/825,991(代理人案卷号ILLM 1008-17/IP-1741-US);
2020年3月20日提交的名称为“Artificial Intelligence-Based Base Calling”的美国非临时专利申请号16/826,126(代理人案卷号ILLM 1008-18/IP-1744-US);
2020年3月20日提交的名称为“Artificial Intelligence-Based QualityScoring”的美国非临时专利申请号16/826,134(代理人案卷号ILLM 1008-19/IP-1747-US);以及
2020年3月21日提交的名称为“Artificial Intelligence-Based Sequencing”的美国非临时专利申请号16/826,168(代理人案卷号ILLM 1008-20/IP-1752-PRV-US)。
背景技术
本部分中讨论的主题不应仅因为在本部分中有提及就被认为是现有技术。类似地,在本部分中提及的或与作为背景技术提供的主题相关联的问题不应被认为先前在现有技术中已被认识到。本部分中的主题仅表示不同的方法,这些方法本身也可对应于受权利要求书保护的技术的具体实施。
近年来,计算能力的快速提高使得深度卷积神经网络(CNN)在许多准确度显著提高的计算机视觉任务上取得了很大的成功。在推理阶段,许多应用需要以严格的功耗要求对一个图像进行低延迟处理,这降低图形处理单元(GPU)和其他通用平台的效率,通过定制专用于深度学习算法推理的数字电路,为特定的加速硬件(例如,现场可编程门阵列(FPGA))带来机会。然而,由于大数据量、密集型计算、变化的算法结构和频繁的存储器访问,在便携式和嵌入式系统上部署CNN仍然具有挑战性。
由于卷积在CNN中贡献了大部分运算,因此卷积加速方案显著影响了硬件CNN加速器的效率和性能。卷积涉及具有沿内核和特征图滑动的四个循环级的乘法和累加(MAC)运算。第一循环级计算内核窗口内的像素的MAC。第二循环级跨不同的输入特征图累加MAC的乘积之和。在完成第一循环级和第二循环级之后,通过添加偏置来获得输出特征图中的最终的输出元素。第三循环级在输入特征图内滑动内核窗口。第四循环级生成不同的输出特征图。
FPGA由于其(1)高度可重构性,(2)与专用集成电路(ASIC)相比开发时间更快,以跟上CNN的快速发展,(3)良好的性能,以及(4)与GPU相比优越的能量效率,获得了越来越多的关注和普及,特别是在加速推理任务方面。FPGA的高性能和高效率可以通过合成针对特定计算定制的电路来实现,以利用定制的存储器系统直接处理数十亿次运算。例如,现代FPGA上的数百至数千个数字信号处理(DSP)块以高并行性支持核心卷积运算,例如乘法和加法。外部片上存储器和片上处理引擎(PE)之间的专用数据缓冲器可被设计成通过在FPGA芯片上配置数十兆字节的片上块随机存取存储器(BRAM)来实现优选的数据流。
需要高效的数据流和CNN加速的硬件架构来最小化数据通信,同时最大化资源利用来实现高性能。因此有机会设计出在具有高性能、高效率和高度灵活性的加速硬件上加速各种CNN算法的推理过程的方法和框架。
附图说明
在附图中,在所有不同视图中,类似的参考符号通常是指类似的部件。另外,附图未必按比例绘制,而是重点说明所公开的技术的原理。在以下描述中,参考以下附图描述了所公开的技术的各种具体实施,其中:
图1示出了可在各种实施方案中使用的生物传感器的横截面。
图2示出了在其区块中包含簇的流通池的一个具体实施。
图3示出了具有八个槽道的示例性流通池,并且还示出了一个区块及其簇和它们的周围背景的放大视图。
图4是用于分析来自测序系统的传感器数据(诸如碱基检出传感器输出)的系统的简化框图。
图5是示出了碱基检出操作的方面的简化图,该方面包括由主机处理器执行的运行时程序的功能。
图6是可配置处理器(诸如,图4的可配置处理器)的配置的简化图。
图6A示出了采用两个或更多个碱基检出器对由生物传感器输出的原始图像进行碱基检出操作的系统。
图7是可使用如本文所述配置的可配置或可重新配置阵列来执行的神经网络架构的图。
图8A是由如图7一样的神经网络架构使用的传感器数据的区块的组织的简化图示。
图8B是由如图7一样的神经网络架构使用的传感器数据的区块的补片的简化图示。
图9示出了可配置或可重构阵列(诸如现场可编程门阵列(FPGA))上的如图7一样的神经网络的配置的一部分。
图10是可使用如本文所述配置的可配置或可重新配置阵列来执行的另一个另选的神经网络架构的图。
图11例示了基于神经网络的碱基检出器的特化架构的一个具体实施,该基于神经网络的碱基检出器用于隔离对不同测序循环的数据的处理。
图12描绘了隔离层的一个具体实施,这些隔离层中的每一个隔离层可包括卷积。
图13A描绘了组合层的一个具体实施,这些组合层中的每一个组合层可包括卷积。
图13B描绘了组合层的另一具体实施,这些组合层中的每一个组合层可包括卷积。
图14示出了包括多个碱基检出器以预测包括碱基序列的未知分析物的碱基检出的碱基检出系统。
图15A、图15B、图15C、图15D和图15E示出了描绘图14的碱基检出系统针对传感器数据的对应集合的各种操作的对应流程图。
图16示出了图14的碱基检出系统的生成传感器数据的示例性集合的上下文信息的上下文信息生成模块。
图17A示出了包括区块的流通池,这些区块基于区块的空间位置来归类。
图17B示出了包括簇的流通池的区块,这些簇基于簇的空间位置来归类。
图17C示出了衰落的示例,其中信号强度随着作为碱基检出操作的测序运行的循环数而降低。
图17D概念性地示出了随着测序循环进展而降低的信噪比。
图18示出了不同示例性碱基检出器配置对于碱基检出均聚物(例如,GGGGG)和近均聚物(例如,GGTGG)的碱基检出准确度(1-碱基检出错误率)。
图19A示出了基于来自图14的碱基检出系统的第一碱基检出器的第一碱基检出分类信息和来自第二碱基检出器的第二碱基检出分类信息的函数来生成传感器数据的集合的最终碱基检出。
图19A1示出了查找表(LUT),该LUT基于时间上下文信息指示要用于最终置信度分数的示例性加权方案。
图19B示出了当被检出碱基包括特殊碱基序列时指示要使用的碱基检出器的LUT。
图19C示出了当被检出碱基包括特殊碱基序列时指示给予各个碱基检出器的置信度分数的权重的LUT。
图19D示出了根据在流通池的簇中检测到一个或多个气泡指示图14的碱基检出组合模块的操作的LUT。
图19D1示出了根据从流通池的簇检测到失焦图像指示图14的碱基检出组合模块的操作的LUT。
图19E示出了基于所使用的试剂组指示给予各个碱基检出器的置信度分数的权重的LUT。
图19F示出了根据区块的空间分类指示图14的碱基检出组合模块的操作的LUT。
图19G示出了根据簇的空间分类指示图14的碱基检出组合模块的操作的LUT。
图20A示出了当(i)检测到特殊碱基序列并且(ii)来自第一碱基检出器的第一被检出碱基与来自第二碱基检出器的第二被检出碱基不匹配时指示图14的碱基检出组合模块的操作的LUT。
图20B示出了当(i)在簇中检测到气泡并且(ii)来自第一碱基检出器的第一被检出碱基与来自第二碱基检出器的第二被检出碱基不匹配时指示图14的碱基检出组合模块的操作的LUT。
图20C示出了当(i)从至少一个簇检测到一个或多个失焦图像并且(ii)来自第一碱基检出器的第一被检出碱基与来自第二碱基检出器的第二被检出碱基不匹配时指示图14的碱基检出组合模块的操作的LUT。
图20D示出了当(i)传感器数据来自边缘簇并且(ii)来自第一碱基检出器的第一被检出碱基与来自第二碱基检出器的第二被检出碱基不匹配时指示图14的碱基检出组合模块的操作的LUT。
图21示出了包括多个碱基检出器以预测包括碱基序列的未知分析物的碱基检出的碱基检出系统,其中基于神经网络的最终碱基检出确定模块基于该多个碱基检出器中的一个或多个碱基检出器的输出来确定最终碱基检出。
图22是根据一个具体实施的碱基检出系统的框图。
图23是可在图22的系统中使用的系统控制器的框图。
图24是可用于实现所公开的技术的计算机系统的简化框图。
具体实施方式
如本文所用,术语“多核苷酸”或“核酸”是指脱氧核糖核酸(DNA),但是,在适当的情况下,技术人员将认识到本文的系统和装置也可应用于核糖核酸(RNA)。应理解,该术语包括作为等同物的由核苷酸类似物形成的DNA或RNA的类似物。如本文所用,术语还涵盖cDNA,即由RNA模板例如通过逆转录酶的作用产生的互补DNA或拷贝DNA。
由本文的系统和设备测序的单链多核苷酸分子可以单链形式,如DNA或RNA,起源,或以双链DNA(dsDNA)形式(例如,基因组DNA片段、PCR及扩增产物等)起源。因此,单链多核苷酸可以是多核苷酸双螺旋的有义链或反义链。使用标准技术制备适用于本公开的方法中的单链多核苷酸分子的方法在本领域中是熟知的。初级多核苷酸分子的精确序列通常对本公开并不重要,并且可以是已知的或未知的。单链多核苷酸分子可表示基因组DNA分子(例如,人类基因组DNA),这些基因组DNA分子包括内含子及外显子序列(编码序列),以及非编码调节序列,诸如启动子及增强子序列。
在某些实施方案中,待通过使用本公开进行测序的核酸被固定在基板(例如,流通池内的基板或基板诸如流通池上的一个或多个小珠等)上。除非另有说明或通过上下文明确指示,否则如本文所用的术语“固定”旨在涵盖直接或间接的、共价或非共价结合。在某些实施方案中,可优选共价附接,但一般来讲全部所需的是分子(例如,核酸)在旨在使用载体的条件下(例如,在需要核酸测序的应用中)保持固定或附接到载体。
如本文所用,术语“固体载体”(或某些用法中的“基底”)是指核酸可附着到其上的任何惰性基底或基质,诸如例如玻璃表面、塑料表面、胶乳、葡聚糖、聚苯乙烯表面、聚丙烯表面、聚丙烯酰胺凝胶、金表面和硅晶片。在许多实施方案中,固体载体为玻璃表面(例如,流通池通道的平坦表面)。在某些实施方案中,固体载体可包括已经例如通过施加中间材料的层或涂层而“官能化”的惰性基底或基质,该中间材料包含容许共价附接到分子诸如多核苷酸的反应性基团。举非限制性示例来说,此类载体可包括负载在惰性基底诸如玻璃上的聚丙烯酰胺水凝胶。在此类实施方案中,分子(多核苷酸)可直接共价附着到中间材料(例如,水凝胶),但该中间材料本身可非共价附着到基板或基质(例如,玻璃基板)。共价附接到固体载体应相应地被解释为涵盖此类型的布置。
如上面所指出,本公开包括用于对核酸进行测序的新型系统和装置。对本领域的技术人员将显而易见的是,根据上下文,本文对特定核酸序列的引用也指包含此类核酸序列的核酸分子。对靶片段的测序意味着建立对碱基的时间顺序的读取。被读取的碱基不需要是连续的,尽管这是优选的,在测序期间也不必对整个片段上的每个碱基进行测序。可使用任何合适的测序技术进行测序,其中核苷酸或寡核苷酸被相继地添加到游离3'羟基基团,导致在5'至3'方向上合成多核苷酸链。优选地在每次核苷酸添加之后确定添加的核苷酸的性质。使用连接测序的测序技术(其中不是每个连续碱基均被测序)以及诸如大规模平行特征测序(MPSS)之类的技术(其中从表面上的链移除而非向其添加碱基)也适于与本公开的系统和装置一起使用。
在某些实施方案中,本公开公开了边合成边测序(SBS)。在SBS中,使用四个带荧光标记的经修饰的核苷酸来对存在于基板(例如,流通池)的表面上的经扩增的DNA的密集簇(可能为数百万个簇)进行测序。可与本文的系统和装置一起使用的关于SBS过程及方法的各种附加方面公开于例如W004018497、W004018493和美国专利号7,057,026(核苷酸)、W005024010和W006120433(聚合酶)、W005065814(表面附接技术)、以及WO 9844151、W006064199及W007010251中,它们中的每一者的内容全文以引用方式并入本文中。
在本文的系统/装置的特定用途中,将含有用于测序的核酸样品的流通池放置在合适的流通池保持器内。用于测序的样本可采取以下形式:单分子、呈簇形式的经扩增的单分子或包含核酸分子的小珠。核酸被制备成使得其包含与未知靶序列相邻的寡核苷酸引物。为了启动第一SBS测序循环,使一种或多种带不同标记的核苷酸和DNA聚合酶等通过流体流动子系统(本文描述了其各种实施方案)流入/流过流通池。可一次添加单个核苷酸,或者可将测序过程中所用的核苷酸特别地设计成具有可逆终止属性,从而使测序反应的每个循环在存在所有四个带标记的核苷酸(A、C、T、G)的情况下同时发生。在将四种核苷酸混合在一起的情况下,聚合酶能够选择要掺入的正确碱基,并且每个序列通过单个碱基延伸。在使用该系统的此类方法时,所有四种另选品之间的自然竞争产生比其中仅一种核苷酸存在于反应混合物中(其中大多数序列因此不暴露于正确的核苷酸)的情况更高的准确度。其中一个接一个地重复特定碱基的序列(例如,均聚物)像任何其他序列一样且以高准确度被寻址。
流体流动子系统还使适当的试剂流动以从每个掺入的碱基去除封闭的3'端(如果适当的话)和荧光团。基底可暴露于四个封闭的核苷酸的第二轮,或者任选地暴露于具有不同单个核苷酸的第二轮。然后重复此类循环,并经多个化学循环读取每个簇的序列。本公开的计算机方面可任选地比对从每个单分子、簇或小珠采集的序列以确定较长聚合物的序列等。另选地,图像处理和比对可在独立计算机上执行。
系统的加热/冷却部件调节流通池通道和试剂储存区域/容器(以及任选地相机、光学器件和/或其他部件)内的反应条件,同时流体流动部件允许基板表面暴露于供掺入的合适试剂(例如,待掺入的适当的带荧光标记的核苷酸),同时冲洗掉未掺入的试剂。流通池放置在其上的任选的可移动台允许流通池进入用于衬底的激光(或其他光)激发的正确取向,并且任选地相对于透镜物镜移动以允许读取基底的不同区域。另外,系统的其他部件(例如,相机、透镜物镜、加热器/冷却器等)也任选地是可移动/可调节的。在激光激发期间,由相机部件捕获从基底上的核酸发射的荧光的图像/位置,从而在计算机部件中记录每个单个分子、簇或小珠的第一碱基的种类。
本文所述的实施方案可用于学术或商业分析的各种生物过程和系统或化学过程和系统。更具体地,本文所述的实施方案可用于期望检测指示所需反应的事件、属性、质量或特征的各种过程和系统中。例如,本文所述的实施方案包括盒、生物传感器和它们的部件,以及与盒和生物传感器一起操作的生物测定系统。在特定实施方案中,盒和生物传感器包括流通池和一个或多个传感器、像素、光检测器或光电二极管,它们在基本上单一结构中耦接在一起。
当结合以下附图阅读时,将更好地理解某些实施方案的以下详细描述。就附图例示了各种实施方案的功能块的图而言,功能块不一定指示硬件电路之间的划分。因此,例如,功能块中的一个或多个功能块(例如,处理器或存储器)可在单片硬件(例如,通用信号处理器或随机存取存储器、硬盘等)中实施。类似地,程序可以是独立式程序,可作为子例程并入操作系统中,可以是所安装的软件包中的功能等。应理解,各种实施方案不限于附图中所示的布置和手段。
如本文所用,以单数形式叙述且前面带有词语“一个”或“一种”的元件或步骤应当理解为不排除多个所述元件或步骤,除非明确地指明此类排除。此外,对“一个实施方案”的引用并非旨在被解释为排除同样并入所叙述特征的附加实施方案的存在。此外,除非有相反的明确说明,否则“包括(comprising)”或“具有”或“包括(including)”具有特定属性的一个或多个元件的实施方案可包括附加元件,无论它们是否具有该属性。
如本文所用,“所需反应”包括感兴趣的分析物的化学属性、电属性、物理属性或光学属性(或质量)中的至少一者的变化。在特定实施方案中,所需反应是阳性结合事件(例如,荧光标记的生物分子与感兴趣的分析物结合)。更一般地,所需反应可以是化学转化、化学变化或化学相互作用。所需反应也可为电属性的变化。例如,所需反应可以是溶液内离子浓度的变化。示例性反应包括但不限于化学反应,诸如还原、氧化、添加、消除、重排、酯化、酰胺化、醚化、环化或取代;第一化学物质与第二种化学物质结合的结合相互作用;两个或更多个化学物质彼此分离的解离反应;荧光;发光;生物发光;化学发光;和生物反应,诸如核酸复制、核酸扩增、核酸杂交、核酸连接、磷酸化、酶催化、受体结合或配体结合。所需反应还可以是质子的添加或消除,例如,可检测为周围溶液或环境的pH变化。附加所需反应可以是检测跨膜(例如,天然或合成双层膜)的离子流,例如,当离子流过膜时,电流被中断,并且该中断可被检测到。
在特定实施方案中,所需反应包括将荧光标记的分子与分析物结合。分析物可为寡核苷酸,并且荧光标记的分子可为核苷酸。当激发光被导向具有标记核苷酸的寡核苷酸,并且荧光团发出可检测的荧光信号时,可检测到所需反应。在另选的实施方案中,检测到的荧光是化学发光或生物发光的结果。所需反应还可例如通过使供体荧光团接近受体荧光团来增加荧光(或Forster)共振能量转移(FRET),通过分离供体荧光团和受体荧光团来降低FRET,通过分离淬灭基团与荧光团来增加荧光,或通过共定位淬灭基团和荧光团来减少荧光。
如本文所用,“反应组分”或“反应物”包括可用于获得所需反应的任何物质。例如,反应组分包括试剂、酶、样品、其他生物分子和缓冲液。可将反应组分通常被递送至溶液中的反应位点和/或固定在反应位点处。反应组分可直接或间接地与另一种物质相互作用,诸如感兴趣的分析物。
如本文所用,术语“反应位点”是可发生所需反应的局部区域。反应位点可包括其上可固定物质的基板的支撑表面。例如,反应位点可包括流通池的通道中的基本上平面的表面,该表面上具有核酸群体。通常,但并不总是如此,群体中的核酸具有相同的序列,例如为单链或双链模板的克隆拷贝。然而,在一些实施方案中,反应位点可仅包含单个核酸分子,例如单链或双链形式。此外,多个反应位点可沿着支撑表面不均匀分布或以预先确定的方式布置(例如,在矩阵中并排布置,诸如在微阵列中)。反应位点还可包括反应室(或孔),其至少部分地限定了被配置为分隔所需反应的空间区域或体积。
本申请可互换地使用术语“反应室”和“孔”。如本文所用,术语“反应室”或“孔”包括与流动通道流体连通的空间区域。反应室可至少部分地与周围环境或其他空间区域隔开。例如,多个反应室可通过共用壁彼此隔开。作为更具体的示例,反应室可包括由孔的内表面限定的腔,并且可具有开口或孔隙,使得该腔可与流动通道流体连通。包括此类反应室的生物传感器在2011年10月20日提交的国际申请号PCT/US2011/057111中有更详细的描述,该专利全文以引用方式并入本文。
在一些实施方案中,反应室的尺寸和形状相对于固体(包括半固体)被设定成使得固体可完全或部分地插入其中。例如,反应室的尺寸和形状可被设定成仅容纳一个捕获小珠。该捕获小珠可在其上具有克隆扩增的DNA或其他物质。另选地,反应室的尺寸和形状可被设定成接纳大约数量的小珠或固体基板。又如,反应室还可填充有多孔凝胶或物质,该多孔凝胶或物质被配置为控制扩散或过滤可流入反应室的流体。
在一些实施方案中,传感器(例如,光检测器、光电二极管)与生物传感器的样品表面的对应像素区域相关联。因此,像素区域是表示一个传感器(或像素)在生物传感器样品表面上的区域的几何构造。当在覆盖相关联的像素区域的反应位置或反应室发生所需反应时,与像素区域相关联的传感器检测从相关联的像素区域收集的光发射。在平坦表面实施方案中,像素区域可重叠。在一些情况下,多个传感器可与单个反应位点或单个反应室相关联。在其他情况下,单个传感器可与一组反应位点或一组反应室相关联。
如本文所用,“生物传感器”包括具有多个反应位点和/或反应室(或孔)的结构。生物传感器可包括固态成像设备(例如,CCD或CMOS成像器件)以及任选地安装到其上的流通池。流通池可包括与反应位点和/或反应室流体连通的至少一个流动通道。作为一个具体示例,生物传感器被配置为流体耦接和电耦接到生物测定系统。生物测定系统可根据预先确定的方案(例如,边合成边测序)将反应物递送至反应位点和/或反应室,并执行多个成像事件。例如,生物测定系统可引导溶液沿着反应位点和/或反应室流动。溶液中的至少一种溶液可包括四种类型的具有相同或不同荧光标记的核苷酸。核苷酸可与位于反应位点和/或反应室的对应寡核苷酸结合。然后,生物测定系统可使用激发光源(例如,固态光源,诸如发光二极管(LED))给反应位点和/或反应室照明。激发光可具有预定的一个或多个波长,包括一个波长范围。所激发的荧光标签提供可被传感器捕获的发射信号。
在另选的实施方案中,生物传感器可包括被配置为检测其他可识别属性的电极或其他类型的传感器。例如,传感器可被配置为检测离子浓度的变化。在另一个示例中,传感器可被配置为检测跨膜的离子电流。
如本文所用,“簇”是相似或相同的分子或核苷酸序列或DNA链的群体。例如,簇可以是扩增的寡核苷酸或具有相同或相似序列的任何其他组的多核苷酸或多肽。在其他实施方案中,簇可为占据样品表面上的物理区域的任何元素或元素组。在实施方案中,在碱基检出循环期间,簇被固定到反应位点和/或反应室。
如本文所用,当关于生物分子或生物或化学物质使用时,术语“固定的”包括在分子水平上基本上将生物分子或生物或化学物质附着到表面。例如,可使用吸附技术将生物分子或生物或化学物质固定到基板材料的表面,这些吸附技术包括非共价相互作用(例如,静电力、范德华力以及疏水界面的脱水)和共价结合技术,其中官能团或接头便于将生物分子附着到表面。将生物分子或生物或化学物质固定到基板材料的表面可基于基板表面的属性、携带生物分子或生物或化学物质的液体介质以及生物分子或生物或化学物质本身的属性。在一些情况下,基板表面可被官能化(例如,化学或物理改性),以便于将生物分子(或生物或化学物质)固定到基板表面。可首先对基板表面进行改性,使官能团结合到表面。然后,官能团可结合到生物分子或生物或化学物质,以将其固定在其上。可经由凝胶将物质固定在表面,例如,如美国专利公布号US2011/0059865 A1,该专利以引用方式并入本文。
在一些实施方案中,核酸可附着到表面,并使用桥式扩增进行扩增。有用的桥式扩增方法描述于,例如,美国专利号5,641,658;WO 2007/010251;美国专利号6,090,592;美国专利公布号2002/0055100A1;美国专利号7,115,400;美国专利公布号2004/0096853A1;美国专利公布号2004/0002090A1;美国专利公布号2007/0128624A1;以及美国专利公布号2008/0009420A1,这些专利中的每一篇均全文并入本文。另一种用于在表面上扩增核酸的有用方法是滚环扩增(RCA),例如,使用下面进一步详细阐述的方法。在一些实施方案中,核酸可附着到表面,并使用一个或多个引物对进行扩增。例如,引物中的一个引物可在溶液中,并且另一个引物可固定在表面上(例如,5’-附着)。通过举例的方式,核酸分子可与表面上的引物中的一个引物杂交,之后延伸固定的引物以产生核酸的第一拷贝。然后溶液中的引物与核酸的第一拷贝杂交,该第一拷贝可用核酸的第一拷贝作为模板进行延伸。任选地,在产生核酸的第一拷贝后,原始核酸分子可与表面上的第二固定引物杂交,并且可在溶液中的引物延伸的同时或之后延伸。在任何实施方案中,使用固定的引物和溶液中的引物重复多轮延伸(例如,扩增)提供了核酸的多个拷贝。
在特定实施方案中,由本文所述的系统和方法执行的测定协议包括使用天然核苷酸以及被配置为与天然核苷酸相互作用的酶。天然核苷酸包括例如,核糖核苷酸(RNA)或脱氧核糖核苷酸(DNA)。天然核苷酸可为单磷酸盐、二磷酸盐或三磷酸盐形式,并且可具有选自腺嘌呤(A)、胸腺嘧啶(T)、尿嘧啶(U)、鸟嘌呤(G)或胞嘧啶(C)的碱基。然而,应当理解,可使用非天然核苷酸、经修饰的核苷酸或前述核苷酸的类似物。关于通过合成方法进行的基于可逆终止子的测序,下面列出了有用的非天然核苷酸的一些示例。
在包括反应室的实施方案中,物品或固体物质(包括半固体物质)可设置在反应室内。当被设置时,物品或固体可通过过盈配合、粘附或截留被物理地保持或固定在反应室内。可设置在反应室内的示例性物品或固体包括聚合物小珠、微丸、琼脂糖凝胶、粉末、量子点或可被压缩和/或保持在反应室内的其他固体。在特定实施方案中,核酸超结构(诸如DNA球)可例如通过附着至反应室的内表面或通过停留在反应室内的液体中而设置在反应室中或反应室处。可进行DNA球或其他核酸超结构,然后将其设置在反应室中或反应室处。另选地,DNA球可在反应室处原位合成。可以通过滚环扩增来合成DNA球,以产生特定核酸序列的多联体,并且可用形成相对紧凑的球的条件来处理多联体。DNA球及其合成方法在例如美国专利公布号2008/0242560 A1或2008/0234136 A1中有所描述,这些专利中的每一篇均全文并入本文。保持或设置在反应室中的物质可以是固态、液态或气态。
如本文所用,“碱基检出”识别核酸序列中的核苷酸碱基。碱基检出是指在具体循环针对每个簇确定碱基检出(A,C,G,T)的过程。作为示例,可利用美国专利申请公布号2013/0079232的合并材料中描述的四通道方法和系统、双通道方法和系统或一通道方法和系统来执行碱基检出。在特定实施方案中,碱基检出循环被称为“采样事件”。在一种染料和双通道测序协议中,采样事件包括时间序列中的两个照明阶段,使得像素信号在每个阶段处生成。第一照明阶段诱导来自指示AT像素信号中核苷酸碱基A和T的给定簇的照明,并且第二照明阶段诱导来自指示CT像素信号中核苷酸碱基C和T的给定簇的照明。
所公开的技术(例如,所公开的碱基检出器)可在处理器如中央处理单元(CPU)、图形处理单元(GPU)、现场可编程门阵列(FPGA)、粗粒度可重构架构(CGRA)、专用集成电路(ASIC)、专用指令集处理器(ASIP)和数字信号处理器(DSP)上实施。
生物传感器
图1示出了可以在各种实施方案中使用的生物传感器100的横截面。生物传感器100具有像素区域106'、108'、110'、112'和114',这些像素区域可各自在碱基检出循环期间保持多于一个簇(例如,每像素区域2个簇)。如图所示,生物传感器100可包括安装到采样设备104上的流通池102。在例示的实施方案中,流通池102直接附连到采样设备104。然而,在另选的实施方案中,流通池102可以可移除地耦接到采样设备104。采样设备104具有可被官能化的样品表面134(例如,以适合进行期望反应的方式进行化学或物理改性)。例如,样品表面134可被官能化并且可包括多个像素区域106'、108'、110'、112'和114',该多个像素区域可各自在碱基检出循环期间保持多于一个簇(例如,每个像素区域具有对应的簇对106A、106B;108A、108B;110A、110B;112A、112B;和114A、114B固定在其上)。每个像素区域与对应的传感器(或像素或光电二极管)106、108、110、112和114相关联,使得由像素区域接收的光由对应的传感器捕获。像素区域106'也可与样品表面134上保持簇对的对应反应位点106”相关联,使得从反应位点106”发射的光由像素区域106'接收并且由对应的传感器106捕获。由于这种感测结构,在以下情况下,该碱基检出循环中的像素信号携带基于该两个或更多个簇中的所有簇的信息:其中在碱基检出循环期间,在特定传感器的像素区域中存在两个或更多个簇(例如,每个像素区域具有对应的簇对)。因此,如本文所述的信号处理用于区分每个簇,其中在特定碱基检出循环的给定采样事件中存在比像素信号更多的簇。
在例示的实施方案中,流通池102包括侧壁138、125和由侧壁138、125支撑的流罩136。侧壁138、125耦接到样品表面134并且在流罩136与侧壁138、125之间延伸。在一些实施方案中,侧壁138、125由可固化粘合剂层形成,该可固化粘合剂层将流罩136粘结到采样设备104。
侧壁138、125的尺寸和形状被设定成使得流动通道144存在于流罩136与采样设备104之间。流罩136可包括对从生物传感器100的外部传播到流动通道144中的激发光101透明的材料。在一个示例中,激发光101以非正交角度接近流罩136。
另外如图所示,流罩136可包括入口端口和出口端口142、146,该入口端口和出口端口被配置为流体地接合其他端口(未示出)。例如,其他端口可来自卡盒或工作站。流动通道144的尺寸和形状被设定成沿样品表面134引导流体。流动通道144的高度H
以举例的方式,流罩136(或流通池102)可包括透明材料,诸如玻璃或塑料。流罩136可构成具有平面外表面和限定流动通道144的平面内表面的基本上矩形的块。该块可安装到侧壁138、125上。另选地,可蚀刻流通池102以限定流罩136和侧壁138、125。例如,可以将凹槽蚀刻到透明材料中。当蚀刻材料安装到采样设备104时,凹槽可变成流动通道144。
采样设备104可类似于例如包括多个堆叠的基板层120至126的集成电路。基板层120至126可包括基底基板120、固态成像器件122(例如,CMOS图像传感器)、滤波器或光控制层124和钝化层126。应当注意,以上仅是说明性的,并且其他实施方案可包括更少层或附加层。此外,基板层120至126中的每一个层可包括多个子层。采样设备104可使用类似于制造集成电路(诸如CMOS图像传感器和CCD)中使用的工艺来制造。例如,基板层120至126或其部分可被生长、沉积、蚀刻等以形成采样设备104。
钝化层126被配置为使滤波器层124屏蔽流动通道144的流体环境。在一些情况下,钝化层126还被配置为提供允许生物分子或其他感兴趣分析物固定在其上的固体表面(即,样品表面134)。例如,反应位点中的每一个反应位点可包括固定到样品表面134的生物分子的簇。因此,钝化层126可以由允许反应位点固定到其上的材料形成。钝化层126还可包括至少对期望荧光透明的材料。以举例的方式,钝化层126可包含氮化硅(Si
滤波器层124可包括影响光的透射的各种特征。在一些实施方案中,滤波器层124可执行多个功能。例如,滤波器层124可被配置为(a)过滤不想要的光信号,诸如来自激发光源的光信号;(b)将来自反应位点的发射信号导向对应的传感器106、108、110、112和114,这些传感器被配置为检测来自反应位点的发射信号;或(c)阻止或防止检测到来自邻近反应位点的不想要的发射信号。因此,滤波器层124也可称为光控制层。在例示的实施方案中,滤波器层124具有约1μm至5μm且更具体地约2μm至4μm的厚度。在另选的实施方案中,滤波器层124可包括微透镜或其他光学元件的阵列。微透镜中的每一个微透镜可被配置为将发射信号从相关联的反应位点引导到传感器。
在一些实施方案中,固态成像器件122和基底基板120可作为先前构造的固态成像设备(例如,CMOS芯片)一起提供。例如,基底基板120可以是硅晶片,并且固态成像器件122可安装在其上。固态成像器件122包括半导体材料(例如,硅)层和传感器106、108、110、112和114。在例示的实施方案中,传感器是被配置为检测光的光电二极管。在其他实施方案中,传感器包括光检测器。固态成像器件122可通过基于CMOS的制造工艺制造为单个芯片。
固态成像器件122可包括传感器106、108、110、112和114的密集阵列,这些传感器被配置为检测指示来自流动通道144内或沿该流动通道的期望反应的活动。在一些实施方案中,每个传感器具有约1平方微米至2平方微米(μm
在一些实施方案中,采样设备104包括微电路布置,诸如美国专利号7,595,882中描述的微电路布置,该美国专利以引用方式整体并入本文。更具体地,采样设备104可包括具有传感器106、108、110、112和114的平面阵列的集成电路。在采样设备104内形成的电路可被配置用于信号放大、数字化、存储和处理中的至少一者。电路可收集和分析检测到的荧光并生成用于将检测数据传送到信号处理器的像素信号(或检测信号)。电路还可以在采样设备104中执行附加的模拟和/或数字信号处理。采样设备104可包括导电通孔130,这些导电通孔执行信号路由(例如,将像素信号传输到信号处理器)。像素信号也可通过采样设备104的电触点132传输。
相对于2020年5月14日提交的名称为“Systems and Devices forCharacterization and Performance Analysis of Pixel-Based Sequencing”的美国非临时专利申请号16/874,599(代理人案卷号ILLM 1011-4/IP-1750-US)进一步详细讨论了采样设备104,该专利申请以引用方式并入本文,如同在本文中完全阐述一样。采样设备104不限于如上所述的上述构造或用途。在另选的实施方案中,采样设备104可采取其他形式。例如,采样设备104可包括CCD设备(诸如CCD相机),其耦接到流通池或移动以与其中具有反应位点的流通池交互。
图2示出了在其区块中包含簇的流通池200的一个具体实施。流通池200对应于图1的流通池102,例如,没有流罩136。此外,流通池200的描绘在性质上是象征性的,并且流通池200象征性地描绘了其内的各种槽道和区块,而未示出其内的各种其他部件。图2示出了流通池200的顶视图。
在一个实施方案中,流通池200被划分或分区为多个槽道,诸如槽道202a、202b、…、202P,即,P个槽道。在图2的示例中,流通池200被示出为包括8个槽道,即,在该示例中,P=8,但是流通池内的槽道的数量是具体实施特定的。
在一个实施方案中,各个槽道202被进一步分区为被称为“区块”212的非重叠区域。例如,图2示出了示例性槽道的区段208的放大视图。区段208被示出为包括多个区块212。
在一个示例中,每个槽道202包括一个或多个区块列。例如,在图2中,每个槽道202包括两个对应的区块列212,如放大区段208内所示。每个槽道内的每个区块列中的区块数量是具体实施特定的,并且在一个示例中,每个槽道内的每个区块列中可存在50个区块、60个区块、100个区块或另一适当数量的区块。
每个区块包括对应的多个簇。在测序过程中,对区块上的簇及其周围背景进行成像。例如,图2示出了示例性区块内的示例性簇216。
图3示出了具有八个槽道的示例性Illumina GA-IIx
相对于2020年3月20日提交的名称为“Training Data Generation ForArtificial Intelligence-Based Sequencing”的美国非临时专利申请号16/825,987(代理人案卷号ILLM 1008-16/IP-1693-US)进一步详细讨论了簇和区块。
图4是用于分析来自测序系统的传感器数据(诸如碱基检出传感器输出(例如,参见图1))的系统的简化框图。在图4的示例中,系统包括测序机器400和可配置处理器450。可配置处理器450可与由主机处理器诸如中央处理单元(CPU)402执行的运行时程序协调地执行基于神经网络的碱基检出器和/或非基于神经网络的碱基检出器(其将在本文中进一步详细讨论)。测序机器400包括碱基检出传感器和流通池401(例如,相对于图1至图3所讨论的)。流通池可包括一个或多个区块,其中遗传物质的簇暴露于分析物流的序列,该分析物流的序列用于引起簇中的反应以识别遗传物质中的碱基,如相对于图1至图3所讨论的。传感器感测流通池的每个区块中该序列的每个循环的反应以提供区块数据。下文更详细地描述了该技术的示例。遗传测序是数据密集型操作,其将碱基检出传感器数据转换为在碱基检出操作期间感测到的遗传物质的每个簇的碱基检出序列。
该示例中的系统包括执行运行时程序以协调碱基检出操作的CPU 402、用于存储区块数据阵列的序列的存储器403、由碱基检出操作产生的碱基检出读段以及碱基检出操作中使用的其他信息。另外,在该图示中,系统包括用于存储一个(或多个)配置文件诸如FPGA位文件的存储器404和用于配置和重新配置可配置处理器450并且执行神经网络的神经网络的模型参数。测序机器400可包括用于配置可配置处理器以及在一些实施方案中的可重构处理器的程序,以执行神经网络。
测序机器400通过总线405耦接到可配置处理器450。总线405可使用高通量技术来实现,诸如在一个示例中,总线技术与当前由PCI-SIG(PCI特别兴趣小组)维护和开发的PCIe标准(快速外围组件互连)兼容。另外,在该示例中,存储器460通过总线461耦接到可配置处理器450。存储器460可以是设置在具有可配置处理器450的电路板上的板上存储器。存储器460用于由可配置处理器450高速访问在碱基检出操作中使用的工作数据。总线461还可使用高通量技术诸如与PCIe标准兼容的总线技术来实现。
可配置处理器,包括现场可编程门阵列(FPGA)、粗粒度可重构阵列(CGRA)以及其他可配置和可重构的设备,可被配置为比使用执行计算机程序的通用处理器可能实现的更有效或更快地实现各种功能。可配置处理器的配置涉及编译功能描述以产生有时称为位流或位文件的配置文件,以及将配置文件分发到处理器上的可配置元件。
该配置文件通过将电路配置为设置数据流模式、分布式存储器和其他片上存储器资源的使用、查找表内容、可配置逻辑块和可配置执行单元(如乘法累加单元、可配置互连和可配置阵列的其他元件)的操作,来定义要由可配置处理器执行的逻辑功能。如果配置文件可在现场通过改变加载的配置文件而改变,则可配置处理器是可重构的。例如,配置文件可存储在易失性SRAM元件中、非易失性读写存储器元件中以及它们的组合中,分布在可配置或可重构处理器上的可配置元件阵列中。多种可商购获得的可配置处理器适用于如本文所述的碱基检出操作。示例包括可商购获得的产品,诸如Xilinx Alveo
本文所述的实施方案使用可配置处理器450实现多循环神经网络。可配置处理器的配置文件可通过使用高级描述语言(HDL)或寄存器传输级(RTL)语言规范指定要执行的逻辑功能来实现。可使用被设计用于所选择的可配置处理器的资源来编译规范以生成配置文件。为了生成可能不是可配置处理器的专用集成电路的设计,可编译相同或相似的规范。
因此,在本文所述的所有实施方案中,可配置处理器的另选方案包括配置的处理器,该配置的处理器包括专用ASIC或专用集成电路或集成电路组,或片上系统(SOC)器件,该配置的处理器被配置为执行如本文所述的基于神经网络的碱基检出操作。
一般来讲,如被配置为执行神经网络的运行的本文所述的可配置处理器和配置的处理器在本文中称为神经网络处理器。在另一个示例中,如被配置为执行非基于神经网络的碱基检出器的运行的本文所述的可配置处理器和配置的处理器在本文中称为非神经网络处理器。一般来讲,可配置处理器和配置的处理器可用于实现基于神经网络的碱基检出器和非基于神经网络的碱基检出器中的一者或两者,如本文稍后将讨论的。
在该示例中,可配置处理器450通过使用由CPU 402或其他源执行的程序加载的配置文件进行配置,该配置文件配置可配置处理器454上的可配置元件的阵列以执行碱基检出功能。在该示例中,该配置包括数据流逻辑451,该数据流逻辑耦接到总线405和总线461,并且执行用于在碱基检出操作中使用的元件之间分发数据和控制参数的功能。
另外,可配置处理器450配置有碱基检出执行逻辑452以执行多循环神经网络。逻辑452包括多个多循环执行簇(例如,453),在该示例中,该多个多循环执行簇包括多循环簇1至多循环簇X。可根据涉及操作的所需通量和可配置处理器上的可用资源的权衡来选择多循环簇的数量。
多循环簇通过使用可配置处理器上的可配置互连和存储器资源实现的数据流路径454耦接到数据流逻辑451。另外,多循环簇通过使用例如可配置处理器上的可配置互连和存储器资源实现的控制路径455耦接到数据流逻辑451,该控制路径提供指示可用簇、准备好向可用簇提供用于执行神经网络的运行的输入单元、准备好提供用于神经网络的经训练参数、准备好提供碱基检出分类数据的输出补片的控制信号,以及用于执行神经网络的其他控制数据。
可配置处理器被配置为使用经训练参数来执行多循环神经网络的运行,以产生碱基流操作的感测循环的分类数据。执行神经网络的运行以产生用于碱基检出操作的受试者感测循环的分类数据。神经网络的运行对序列(包括来自N个感测循环中的相应感测循环的区块数据的数字N个阵列)进行操作,其中N个感测循环在本文所述示例中针对时间序列中每个操作的一个碱基位置提供用于不同碱基检出操作的传感器数据。任选地,如果需要,根据正在执行的特定神经网络模型,N个感测循环中的一些可能会失序。数字N可以是大于一的任何数字。在本文所述的一些示例中,N个感测循环中的感测循环表示时间序列中受试者感测循环之前的至少一个感测循环和受试者循环(subject cycle)之后的至少一个感测循环的一组感测循环。本文描述了其中数字N为等于或大于五的整数的示例。
数据流逻辑451被配置为使用用于给定运行的输入单元(包括N个阵列的空间对准补片的区块数据)将区块数据和模型的至少一些经训练参数从存储器460移动到用于神经网络的运行的可配置处理器。输入单元可通过一个DMA操作中的直接存储器存取操作来移动,或者在可用时隙期间与所部署的神经网络的执行相协调地移动的较小单元中移动。
如本文所述的用于感测循环的区块数据可包括具有一个或多个特征的传感器数据阵列。例如,传感器数据可包括两个图像,对这两个图像进行分析以识别在DNA、RNA或其他遗传物质的遗传序列中的碱基位置处的四种碱基中的一种。区块数据还可包括关于图像和传感器的元数据。例如,在碱基检出操作的实施方案中,区块数据可包括关于图像与簇的对准的信息,诸如距中心距离的信息,该距离指示传感器数据阵列中的每个像素距区块上遗传物质的簇的中心的距离。
在如下所述的多循环神经网络的执行期间,区块数据还可包括在多循环神经网络的执行期间产生的数据,称为中间数据,该数据可在多循环神经网络的运行期间重复使用而不是重新计算。例如,在多循环神经网络的执行期间,数据流逻辑可将中间数据代替用于区块数据阵列的给定补片的传感器数据写入存储器460。下文更详细地描述了类似于此的实施方案。
如图所示,描述了用于分析碱基检出传感器输出的系统,该系统包括可由运行时程序访问的存储器(例如,460),该存储器存储区块数据,该区块数据包括来自碱基检出操作的感测循环的区块的传感器数据。另外,该系统包括神经网络处理器,诸如可访问存储器的可配置处理器450。神经网络处理器被配置为使用经训练参数来执行神经网络的运行,以产生用于感测循环的分类数据。如本文所述,神经网络的运行对来自N个感测循环的相应感测循环(包括受试者循环)的区块数据的N个阵列的序列进行操作,以产生受试者循环的分类数据。提供数据流逻辑451以使用输入单元(包括来自N个感测循环的相应感测循环的N个阵列的空间对准补片的数据)将区块数据和经训练参数从存储器移动到神经网络处理器以用于神经网络的运行。
另外,描述了一种系统,其中神经网络处理器能够访问存储器,并且包括多个执行簇,该多个执行簇中的执行逻辑簇被配置为执行神经网络。数据流逻辑能够访问存储器和多个执行簇中的执行簇,以将区块数据的输入单元提供到该多个执行簇中的可用执行簇,这些输入单元包括来自相应感测循环(包括受试者感测循环)的区块数据阵列的数字N个空间对准补片,并且使执行簇将N个空间对准补片应用于神经网络以产生受试者感测循环的空间对准补片的分类数据的输出补片,其中N大于1。
图5是示出了碱基检出操作的方面的简化图,该方面包括由主机处理器执行的运行时程序的功能。在该图中,来自流通池(诸如图1至图2所示的流通池)的图像传感器的输出在线500上提供到图像处理线程501,该图像处理线程可对图像执行处理,诸如各个区块的传感器数据阵列中的重采样、对准和布置,并且可由为流通池中的每个区块计算区块簇掩膜的过程使用,该过程识别与流通池的对应区块上的遗传物质的簇对应的传感器数据阵列中的像素。为了计算簇掩膜,一个示例性算法是基于用于使用来源于softmax输出的度量来检测在早期测序循环中不可靠的簇的过程,然后丢弃来自那些阱/簇的数据,并且不针对那些簇产生输出数据。例如,过程可在前N1个(例如,25个)碱基检出期间识别具有高可靠性的簇,并且拒绝其他簇。所拒绝的簇可能是多克隆的或强度非常弱的或因基准点模糊。该程序可在主机CPU上执行。在另选的实施方案中,该信息将潜在地用于识别要传回CPU的必要的感兴趣簇,从而限制中间数据所需的存储。
根据碱基检出操作的状态,图像处理线程501的输出在线502上提供到CPU中的调度逻辑510,该调度逻辑将区块数据阵列在高速总线503上路由到数据高速缓存504,或者在高速总线505上路由到硬件520,诸如图4的可配置处理器。硬件520可以是执行基于神经网络的碱基检出器的多簇神经网络处理器,或者可以是执行非基于神经的碱基检出器的硬件,如本文稍后将讨论的。
硬件520将分类数据(例如,由基于神经网络的碱基检出器和/或非基于神经网络的碱基检出器输出)返回到调度逻辑510,该调度逻辑将信息传递到数据高速缓存504,或者在线511上传递到使用分类数据执行碱基检出和质量分数计算的线程502,并且可以标准格式布置用于碱基检出读段的数据。在线512上将执行碱基检出和质量分数计算的线程502的输出提供给线程503,该线程聚合碱基检出读段,执行其他操作诸如数据压缩,并且将所得的碱基检出输出写入指定目的地以供客户利用。
在一些实施方案中,主机可包括执行硬件520的输出的最终处理以支持神经网络的线程(未示出)。例如,硬件520可提供来自多簇神经网络的最终层的分类数据的输出。主机处理器可对分类数据执行输出激活功能诸如softmax功能,以配置供碱基检出和质量评分线程502使用的数据。另外,主机处理器可执行输入操作(未示出),诸如在输入到硬件520之前对区块数据进行重采样、批量归一化或其他调整。
图6是可配置处理器(诸如,图4的可配置处理器)的配置的简化图。在图6中,可配置处理器包括具有多个高速PCIe接口的FPGA。FPGA配置有封装器600,该封装器包括参考图1描述的数据流逻辑。封装器600通过CPU通信链路609来管理与CPU中的运行时程序的接口和协调,并且经由DRAM通信链路610来管理与板载DRAM 602(例如,存储器460)的通信。封装器600中的数据流逻辑将通过遍历板上DRAM 602上的数字N个循环的区块数据阵列而检索到的补片数据提供到簇601,并且从簇601检索过程数据615以递送回板上DRAM 602。封装器600还管理板上DRAM 602和主机存储器之间的数据传输,以用于区块数据的输入阵列和分类数据的输出块两者。封装器将线613上的块数据传输到分配的簇601。封装器在线612上将经训练的参数诸如权重和偏置提供到从板载DRAM 602检索到的簇601。封装器在线611上将配置和控制数据提供到簇601,该簇经由CPU通信链路609从主机上的运行时程序提供或响应于该运行时程序而生成。簇还可在线616上向封装器600提供状态信号,这些状态信号与来自主机的控制信号协作使用,以管理区块数据阵列的遍历,从而提供空间对准的补片数据,并且使用簇601的资源对补片数据执行用于碱基检出的多循环神经网络和/或用于非基于神经网络的碱基检出的操作。
如上所述,在由封装器600管理的单个可配置处理器上可存在多个簇,该多个簇被配置用于在区块数据的多个补片中的对应补片上执行。每个簇可被配置为使用本文所述的多个感测循环的区块数据来提供受试者感测循环中的碱基检出的分类数据。
在系统的示例中,可将模型数据(包括内核数据,如过滤器权重和偏置)从主机CPU发送到可配置处理器,使得模型可根据循环数进行更新。举一个代表性示例,碱基检出操作可包括大约数百个感测循环。在一些实施方案中,碱基检出操作可包括双端读段。例如,模型训练参数可以每20个循环(或其他数量的循环)更新一次,或者根据针对特定系统实现的更新模式来更新。在包括双端读段的一些实施方案中,其中区块上的遗传簇中的给定字符串的序列包括从第一末端沿字符串向下(或向上)延伸的第一部分和从第二末端沿字符串向上(或向下)延伸的第二部分,可在从第一部分到第二部分的过渡中更新经训练参数。
在一些示例中,可将区块的感测数据的多个循环的图像数据从CPU发送到封装器600。封装器600可任选地对感测数据进行一些预处理和变换,并且将信息写入板上DRAM602。每个感测循环的输入区块数据可包括传感器数据阵列,包括每个感测循环每个区块大约4000×3000个像素或更多,其中两个特征表示区块的两个图像的颜色,并且每个特征每个像素一个或两个字节。对于其中数字N为要在多循环神经网络的每个运行中使用的三个感测循环的实施方案,用于多循环神经网络的每个运行的区块数据阵列可消耗每个区块大约数百兆字节。在系统的一些实施方案中,区块数据还包括每个区块存储一次的DFC数据的阵列,或关于传感器数据和区块的其他类型的元数据。
在操作中,当多循环簇可用时,封装器将补片分配给簇。封装器在区块的遍历中获取区块数据的下一个补片,并将其连同适当的控制和配置信息一起发送到所分配的簇。簇可被配置为在可配置处理器上具有足够的存储器,以保存包括来自一些系统中的多个循环的补片且正被就地处理的数据补片,以及当在各种实施方案中使用乒乓缓冲技术或光栅扫描技术完成对当前补片的处理时将被处理的数据补片。
当分配的簇完成其对当前补片的神经网络的运行并产生输出补片时,其将发信号通知封装器。封装器将从分配的簇读取输出补片,或者另选地,分配的簇将数据推送到封装器。然后,封装器将对DRAM 602中的经处理的区块组装输出补片。当整个区块的处理已完成并且数据的输出补片已传输到DRAM时,封装器将区块的经处理输出阵列以指定格式发送回主机/CPU。在一些实施方案中,板上DRAM 602由封装器600中的存储器管理逻辑管理。运行时程序可控制测序操作,以连续流的方式完成运行中所有循环的区块数据的所有阵列的分析,从而提供实时分析。
多个碱基检出器
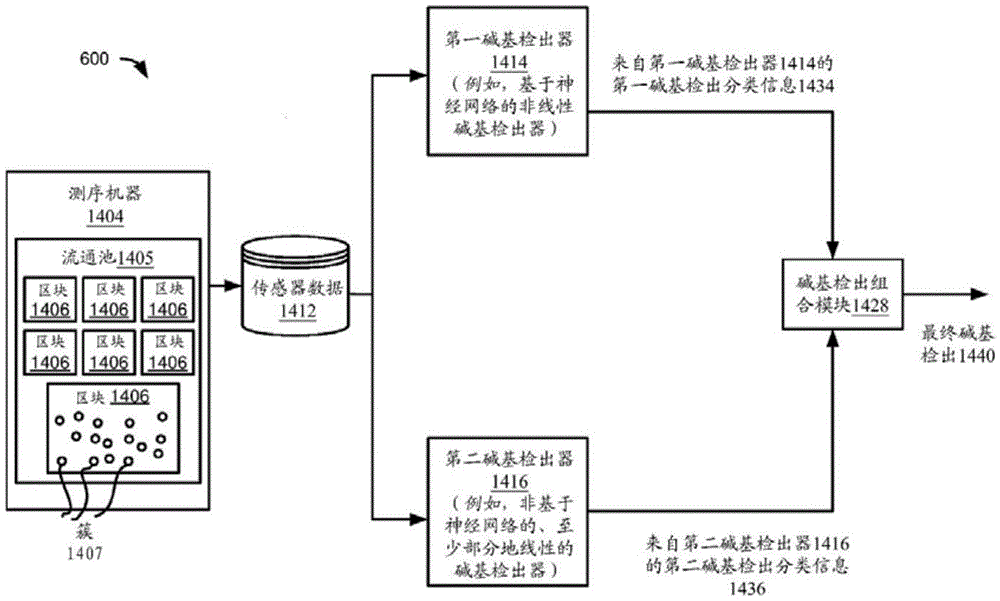
图6A示出了采用两个或更多个碱基检出器对由生物传感器输出的原始图像(即,传感器数据)进行碱基检出操作的系统600。例如,系统600包括测序机器1404,诸如相对于图1所讨论的(并且也在本文中稍后相对于图14所讨论的)测序机器。测序机器1404包括流通池1405,诸如相对于图1至图3所讨论的流通池。流通池1405包括多个区块1406,并且每个区块1406包括多个簇1407(图6A中示出了单个区块的示例性簇),例如如相对于图2和图3所讨论的。如相对于图4至图6所讨论的,包括来自区块1406的原始图像的传感器数据1412由测序机器1404输出。
在一个实施方案中,系统600包括两个或更多个碱基检出器,诸如第一碱基检出器1414和第二碱基检出器1416。尽管图中示出了两个碱基检出器,但是在一个示例中,系统600中可存在多于两个碱基检出器。
图6A的每个碱基检出器输出对应碱基检出分类信息。例如,第一碱基检出器1414输出第一碱基检出分类信息1434,并且第二碱基检出器1416输出第二碱基检出分类信息1436。碱基检出组合模块1428基于第一碱基检出分类信息1434和/或第二碱基检出分类信息1436中的一者或两者来生成最终碱基检出1440。
在一个示例中,第一碱基检出器1414是基于神经网络的碱基检出器。例如,第一碱基检出器1414是采用用于碱基检出的一个或多个神经网络模型的非线性系统,如本文稍后将讨论的。第一碱基检出器1414在本文中也称为DeepRTA(深度实时分析)碱基检出器或深度神经网络碱基检出器。
在一个示例中,第二碱基检出器1416是非基于神经网络的碱基检出器。例如,第二碱基检出器1416至少部分地是用于碱基检出的线性系统。例如,第二碱基检出器1416不采用用于碱基检出的神经网络(或者相比于第一碱基检出器1414所使用的较大神经网络模型,使用较小的用于碱基检出的神经网络模型),如本文稍后将讨论的。第二碱基检出器1416在本文中也称为RTA(实时分析)碱基检出器。
DeepRTA(或深度神经网络)碱基检出器和RTA碱基检出器的示例在2020年3月20日提交的名称为“Artificial Intelligence-Based Base Calling”的美国非临时专利申请16/826,126号(代理人案卷号ILLM 1008-18/IP-1744-US)中有所讨论,该专利申请以引用方式并入以用于所有目的,如同在本文中完全阐述一样。
图6A的系统600的操作的进一步细节以及第一碱基检出器1414和第二碱基检出器1416的进一步示例将在本文中稍后例如相对于图14进一步详细讨论。
非基于神经网络且至少部分线性的碱基检出器(图6A和图14的第二碱基检出器
如相对于图6A所讨论的,第二碱基检出器1416是非基于神经网络且至少部分线性的碱基检出器。也就是说,第二碱基检出器1416不采用用于碱基检出的神经网络(或者相比于第一碱基检出器1414所使用的较大神经网络模型,使用较小的用于碱基检出的神经网络模型)。第二碱基检出器1416的示例是RTA碱基检出器。
RTA是使用线性强度提取器从测序图像提取特征以进行碱基检出的碱基检出器。以下讨论描述了通过RTA进行强度提取和碱基检出的一个具体实施。在该具体实施中,RTA执行模板生成步骤以使用来自叫做模板循环的一定数量的初始测序循环的测序图像来产生模板图像,该模板图像识别区块上的簇的位置。模板图像用作后续的配准和强度提取步骤的参考。模板图像通过检测和合并模板循环的每个测序图像中的亮点来生成,这继而涉及对测序图像进行锐化(例如,使用拉普拉斯卷积)、通过空间隔离的Otsu方法确定“打开”阈值、以及利用子像素位置插值进行的后续五像素局部最大值检测。在另一个示例中,使用基准标记物来识别区块上的簇的位置。生物学标本成像在其上的固体载体可包括此类基准标记物,以便于确定标本或其图像相对于附接到固体载体的探针的取向。示例性基准包括但不限于小珠(具有或不具有荧光部分或诸如带标记的探针可与其结合的核酸之类的部分)、以已知或可确定的特征附接的荧光分子或将形态学形状与荧光部分组合的结构。示例性基准阐述于美国专利公布号2002/0150909中,该美国专利公布以引用方式并入本文。
然后,RTA对着模板图像配准当前测序图像。这通过使用图像相关性来在子区域上将当前测序图像与模板图像对准或者通过使用非线性变换(例如,全六参数线性仿射变换)来实现。
RTA生成颜色矩阵以校正测序图像的颜色通道之间的串扰。RTA实施经验定相校正以补偿测序图像中由相位误差引起的噪声。
在将不同的校正应用于测序图像之后,RTA提取测序图像中每个点位置的信号强度。例如,对于给定的点位置,可通过确定点位置中的像素的强度的加权平均值来提取信号强度。例如,可使用双线性或双三次插值来执行中心像素和相邻像素的加权平均。在一些具体实施中,图像中的每个点位置可包括几个像素(例如,1至5个像素)。
然后,RTA对所提取的信号强度进行空间归一化,以考虑跨采样的图像的照明变化。例如,强度值可被归一化成使得第5百分位和第95百分位分别具有值0和1。图像的归一化信号强度(例如,针对每个通道归一化的强度)可用于计算图像中多个点的均值纯净度。
在一些具体实施中,RTA使用均衡器来最大化所提取的信号强度的信噪比。均衡器可(例如,使用最小二乘估计、自适应均衡算法)被训练为最大化测序图像中的簇强度数据的信噪比。在一些具体实施中,均衡器是包括具有子像素分辨率的多个查找表(LUT)的LUT组,也称为“均衡器滤波器”或“卷积内核”。在一个具体实施中,均衡器中的LUT的数量取决于测序图像的像素可被划分成的子像素的数量。例如,如果像素可被划分成n×n个子像素(例如,5×5个子像素),则均衡器生成n2个LUT(例如,25个LUT)。
在训练均衡器的一个具体实施中,按孔子像素位置对来自测序图像的数据进行分箱。例如,对于5×5LUT,这些孔中的1/25具有在箱(1,1)(例如,传感器像素的左上角)中的中心,这些孔中的1/25在箱(1,2)中,等等。在一个具体实施中,使用对来自对应于相应箱的孔的数据子集的最小二乘估计来确定每个箱的均衡器系数。这样,所得的估计的均衡器系数对于每个箱是不同的。
每个LUT/均衡器滤波器/卷积内核具有从训练中学习的多个系数。在一个具体实施中,LUT中系数的数量对应于用于对簇进行碱基检出的像素的数量。例如,如果用于对簇进行碱基检出的像素的局部网格(图像或像素补片)的大小为p×p(例如,9×9像素补片),则每个LUT具有p2个系数(例如,81个系数)。
在一个具体实施中,训练产生均衡器系数,这些均衡器系数被配置为以最大化信噪比的方式混合/组合像素的强度值,这些像素描绘来自正在碱基检出的目标簇的强度发射和来自一个或多个相邻簇的强度发射。信噪比中被最大化的信号是来自目标簇的强度发射,而信噪比中被最小化的噪声是来自相邻簇的强度发射,即,空间串扰,加上一些随机噪声(例如,以考虑背景强度发射)。均衡器系数用作权重,并且混合/组合包括执行均衡器系数与像素的强度值之间的逐元素乘法,以计算这些像素的强度值的加权和,即,卷积操作。
然后,RTA通过将数学模型拟合到优化的强度数据来执行碱基检出。可使用的合适的数学模型包括例如k均值聚类算法、类k均值聚类算法、期望最大化聚类算法、基于直方图的方法等。可将四个高斯分布拟合到双通道强度数据的集合,使得针对数据集合中表示的四个核苷酸中的每个核苷酸应用一个分布。在一个特定具体实施中,可应用期望最大化(EM)算法。作为EM算法的结果,针对每个X、Y值(分别指两个通道强度中的每个通道强度),可生成表示某个X、Y强度值属于数据所拟合到的四个高斯分布中的一个高斯分布的可能性的值。在四个碱基给出四个单独分布的情况下,每个X、Y强度值也将具有四个相关联的可能值,四个碱基中的每个碱基对应一个可能值。四个可能值中的最大值指示碱基检出。例如,如果簇在两个通道中为“关闭”,则碱基检出为G。如果簇在一个通道中为“关闭”并且在另一通道中为“打开”,则碱基检出为C或T(取决于哪个通道是打开的),并且如果簇在两个通道中为“打开”,则碱基检出为A。
关于RTA的附加细节可见于2018年3月1日提交的名称为“Optical DistortionCorrection For Imaged Samples”的美国非临时专利申请号15/909,437;2014年10月31日提交的名称为“Image Analysis Useful for Patterned Objects”的美国非临时专利申请号14/530,299;2014年12月3日提交的名称为“Methods and Systems for AnalyzingImage Data”的美国非临时专利申请号15/153,953;2011年1月13日提交的名称为“DataProcessing System and Methods”美国非临时专利申请号13/006,206;以及2021年5月4日提交的名称为“Equalization-Based Image Processing and Spatial CrosstalkAttenuator”的美国非临时专利申请号17/308,035(代理人档案号ILLM 1032-2/IP-1991-US)中,所有这些专利申请以引用方式并入本文,如同在本文中完全阐述一样。
基于神经网络且至少部分非线性的碱基检出器(例如,图6A的第一碱基检出器
图7至图13B讨论了图6A的第一碱基检出器1414的各种示例。例如,图7是可使用本文所述的系统执行的多循环神经网络模型的图。多循环神经网络模型是图6A的第一碱基检出器1414的示例,尽管另一基于神经网络的模型也可用于第一碱基检出器1414。
图7所示的示例可称为五循环输入、一循环输出神经网络。然而,需注意,五循环输入、一循环输出神经网络仅是示例,并且神经网络可具有不同数量的输入(诸如六个、七个、九个或另一适当数量)。例如,本文稍后讨论的图10具有9循环输入。再次参考图7,对多循环神经网络模型的输入包括来自给定区块的五个感测循环的区块数据阵列的五个空间对准补片(例如,700)。空间对准补片具有与集合中的其他补片相同的对准行和列尺寸(x,y),使得信息涉及序列循环中的区块上的遗传物质的相同簇。在该示例中,受试者补片是来自循环K的区块数据阵列的补片。一组五个空间对准补片包括来自在受试者补片之前两个循环的循环K-2的补片、来自在受试者补片之前一个循环的循环K-1的补片、来自在来自受试者循环的补片之后一个循环的循环K+1的补片、以及来自在来自受试者循环的补片之后两个循环的循环K+2的补片。
该模型包括输入补片中的每一个输入补片的神经网络的层的隔离叠堆701。因此,叠堆701接收来自循环K+2的补片的区块数据作为输入,并且与叠堆702、703、704和705隔离,使得它们不共享输入数据或中间数据。在一些实施方案中,叠堆710至705中的所有叠堆可具有相同的模型和相同的经训练参数。在其他实施方案中,模型和经训练参数在不同叠堆中可能不同。叠堆702接收来自循环K+1的补片的区块数据作为输入。叠堆703接收来自循环K的补片的区块数据作为输入。叠堆704接收来自循环K-1的补片的区块数据作为输入。叠堆705接收来自循环K-2的补片的区块数据作为输入。隔离叠堆的层各自执行内核的卷积操作,该内核包括层的输入数据上的多个滤波器。如在以上示例中,补片700可包括三个特征。层710的输出可包括更多的特征,诸如10个至20个特征。同样,层711至716中的每一个层的输出可包括适用于特定具体实施的任何数量的特征。滤波器的参数是神经网络的经训练参数,诸如权重和偏置。来自叠堆701-705中的每一个叠堆的输出特征集(中间数据)作为输入被提供到时间组合层的逆层次结构720(其中来自多个循环的中间数据被组合)。在例示的示例中,逆层次结构720包括:第一层,该第一层包括三个组合层721、722、723,每个组合层接收来自隔离叠堆中的三个隔离叠堆的中间数据;以及最终层,该最终层包括一个组合层730,该组合层接收来自三个时间层721、722、723的中间数据。
最终组合层730的输出是位于来自循环K的区块的对应补片中的簇的分类数据的输出补片。可将输出补片组装成循环K的区块的输出阵列分类数据。在一些实施方案中,输出补片可具有不同于输入补片的大小和尺寸。在一些实施方案中,输出补片可包括可经主机滤波以选择簇数据的逐像素数据。
根据特定具体实施,然后可将输出分类数据735应用于任选地由主机或在可配置处理器上执行的softmax函数740(或其他输出激活函数)。可使用不同于softmax的输出函数(例如,根据最大输出产生碱基检出输出参数,然后利用使用上下文/网络输出的经学习非线性映射给出碱基质量)。
最后,可提供softmax函数740的输出作为循环K的碱基检出概率(750)并且将其存储在主机存储器中以在后续处理中使用。其他系统可使用用于输出概率计算的另一函数,例如,另一非线性模型。
可使用具有多个执行簇的可配置处理器来实现神经网络,以便在等于或接近一个感测循环的时间间隔的持续时间内完成一个区块循环的评估,从而有效地实时提供输出数据。数据流逻辑可被配置为将区块数据和经训练参数的输入单元分布到执行簇,并且分布输出补片以用于聚合在存储器中。
参考图8A和图8B描述了用于使用双通道传感器数据的碱基检出操作的如图7一样的五循环输入、一循环输出神经网络的数据的输入单元。例如,对于基因序列中的给定碱基,碱基检出操作可执行两个分析物流和两个反应,该两个反应生成两个信号(诸如图像)通道,这些图像可被处理以识别四种碱基中的哪一种碱基位于遗传物质的每个簇的遗传序列的当前位置处。在其他系统中,可利用不同数量的感测数据的通道。例如,可利用一通道方法和系统来执行碱基检出。美国专利申请公开号2013/0079232的合并材料讨论了使用各种数量的通道(诸如一通道、两通道或四通道)的碱基检出。
图8A示出了针对给定区块(区块M)的五个循环的区块数据阵列,该区块M出于执行五循环输入、一循环输出神经网络的目的使用。在该示例中,五循环输入区块数据可被写入板载DRAM或系统中的可由数据流逻辑访问的其他存储器,并且对于循环K-2包括用于通道1的阵列801和用于通道2的阵列811,对于循环K-1包括用于通道1的阵列802和用于通道2的阵列812,对于循环K包括用于通道1的阵列803和用于通道2的阵列813,对于循环K+1包括用于通道1的阵列804和用于通道2的阵列814,对于循环K+2包括用于通道1的阵列805和用于通道2的阵列815。另外,区块的元数据的阵列820可在存储器中写入一次,在该情况下,包括DFC文件以连同每个循环用作对神经网络的输入。
尽管图8A讨论了两通道碱基检出操作,但是使用两个通道仅仅是示例,并且可使用任何其他适当数量的通道来执行碱基检出。例如,美国专利申请公开号2013/0079232的合并材料讨论了使用各种数量的通道(诸如一通道、两通道、或四通道、或另一适当数量的通道)的碱基检出。
数据流逻辑构成区块数据的输入单元,这些输入单元可参考图8B理解,该区块数据包括每个执行簇的区块数据阵列的空间对准补片,该每个执行簇被配置为对输入补片执行神经网络的运行。用于分配的执行簇的输入单元由数据流逻辑通过以下方式构成:从五个输入循环的区块数据阵列801-805、811、815、820中的每个阵列读取空间对准补片(例如,851、852、861、862、870),并且经由数据路径(示意性地,850)将它们递送至被配置用于由分配的执行簇使用的可配置处理器上的存储器。分配的执行簇执行五循环输入/一循环输出神经网络的运行,并且针对受试者循环K递送受试者循环K中的区块的相同补片的分类数据的输出补片。
图9是如图7(例如,701和720)一样的系统中可使用的神经网络的叠堆的简化表示。在该示例中,神经网络的一些功能(例如,900、902)在主机上执行,并且神经网络的其他部分(例如,901)在可配置处理器上执行。
在一个示例中,第一函数可以为在CPU上形成的批量归一化(层910)。然而,在另一个示例中,作为函数的批量归一化可被融合到一个或多个层中,并且可不存在单独的批量归一化层。
如上文关于可配置处理器所讨论的,多个空间隔离卷积层被执行为神经网络的第一组卷积层。在该示例中,第一组卷积层在空间上应用2D卷积。
如图9所示,针对每个叠堆中的L/2(L是参考图7描述的)个空间隔离的神经网络层,执行第一空间卷积921,之后执行第二空间卷积922,之后执行第三空间卷积923,并依此类推。如923A处所指出,空间层的数量可以是任何实际数字,针对上下文的该实际数字在不同实施方案中可在从几个到多于20个的范围内。
对于SP_CONV_0,内核权重例如存储在(1,6,6,3,L)结构中,因为对于该层存在3个输入通道。
对于其他SP_CONV_层,内核权重存储在(1,6,6L)结构中,因为对于这些层中的每个层,存在K(=L)个输入和输出。
空间层的叠堆的输出被提供到时间层,包括在FPGA上执行的卷积层924、925。层924和925可以是跨循环应用1D卷积的卷积层。如924A处所指出,时间层的数量可以是任何实际数字,针对上下文的该实际数字在不同实施方案中可在从几个到多于20个的范围内。
第一时间层TEMP_CONV_0层924将循环通道的数量从5减少到3,如图7所示。第二时间层(层925)将循环通道的数量从3减少到1,如图7所示,并且针对每个像素将特征映射图的数量减少到四个输出,从而表示每个碱基检出中的置信度。
时间层的输出被累加在输出补片中并且被递送到主机CPU以应用例如softmax函数930或其他函数以归一化碱基检出概率。
图10示出了示出可针对碱基检出操作执行的10输入、六输出神经网络的另选具体实施。在该示例中,来自循环0至9的空间对准输入补片的区块数据被应用于空间层的隔离叠堆,诸如循环9的叠堆1001。将隔离叠堆的输出应用于具有输出1035(2)至1035(7)的时间叠堆1020的逆分层布置,从而提供受试者循环2至7的碱基检出分类数据。
图11示出了基于神经网络的碱基检出器(例如,图7)的专门化架构的一个具体实施,该基于神经网络的碱基检出器用于隔离对不同测序循环的数据的处理。首先描述使用特化的架构的动机。
基于神经网络的碱基检出器处理当前测序循环、一个或多个先前测序循环以及一个或多个后续测序循环的数据。附加测序循环的数据提供序列特异性上下文。在训练期间,基于神经网络的碱基检出器学习使用序列特异性上下文以改进碱基检出准确度。此外,前测序循环和后测序循环的数据为当前测序循环提供了预定相和定相信号的二阶贡献。
空间卷积层使用所谓的“隔离卷积”,该隔离卷积通过经由“专用非共享”卷积序列独立处理多个测序循环中的每一个测序循环的数据来实现隔离。该隔离卷积对仅给定测序循环(即,循环内)的数据和所得特征映射图进行卷积,而不对任何其他测序循环的数据和所得特征映射图进行卷积。
例如,考虑输入数据包括(i)待进行碱基检出的当前(时间t)测序循环的当前数据,(ii)先前(时间t-1)测序循环的先前数据,以及(iii)后续(时间t+1)测序循环的后续数据。然后,专门化架构发起三个单独的数据处理管道(或卷积管道),即当前数据处理管道、先前数据处理管道和后续数据处理管道。当前数据处理管道接收当前(时间t)测序循环的当前数据作为输入,并且通过多个空间卷积层独立地处理该当前数据,以产生所谓的“当前空间卷积表示”作为最终空间卷积层的输出。先前数据处理管道接收先前(时间t-1)测序循环的先前数据作为输入,并且通过多个空间卷积层独立地处理该先前数据以产生所谓的“先前空间卷积表示”作为最终空间卷积层的输出。后续数据处理管道接收后续(时间t+1)测序循环的后续数据作为输入,并且通过多个空间卷积层独立地处理该后续数据以产生所谓的“后续空间卷积表示”作为最终空间卷积层的输出。
在一些具体实施中,当前管道、一个或多个先前管道和一个或多个后续处理管道并行执行。
在一些具体实施中,空间卷积层是专门化架构内的空间卷积网络(或子网络)的一部分。
基于神经网络的碱基检出器还包括混合测序循环之间(即,循环间)的信息的时间卷积层。时间卷积层从空间卷积网络接收其输入,并且对由相应数据处理管道的最终空间卷积层产生的空间卷积表示进行操作。
时间卷积层使用所谓的“组合卷积”,该组合卷积在滑动窗口的基础上逐组地对后续输入中的输入通道进行卷积。在一个具体实施中,这些后续输入是由先前的空间卷积层或先前时间卷积层产生的后续输出。
在一些具体实施中,时间卷积层是专门化架构内的时间卷积网络(或子网络)的一部分。时间卷积网络从空间卷积网络接收其输入。在一个具体实施中,时间卷积网络的第一时间卷积层逐组地组合测序循环之间的空间卷积表示。在另一个具体实施中,时间卷积网络的后续时间卷积层组合先前时间卷积层的后续输出。在一个示例中,压缩逻辑(或压缩网络或压缩子网络或压缩层或挤压层)处理时间和/或空间卷积网络的输出,并且生成输出的压缩表示。在一个具体实施中,压缩网络包括减小由网络生成的特征图的深度维数的压缩卷积层。
最终时间卷积层的输出(例如,有或没有压缩)被馈送到产生输出的输出层。输出用于在一个或多个测序循环处对一个或多个簇进行碱基检出。
在前向传播期间,专门化架构以两个阶段处理来自多个输入的信息。在第一阶段中,使用隔离卷积来防止输入之间的信息混合。在第二阶段中,使用组合卷积来混合
输入之间的信息。将来自第二阶段的结果用于对该多个输入进行单个推断。
这不同于其中卷积层同时处理批量中的多个输入并且对该批量中的每个输入进行对应推断的批处理模式技术。相比之下,专门化架构将该多个输入映射到该单个推断。该单个推断可包括多于一个预测,诸如四种碱基(A、C、T和G)中的每一种碱基的分类得分。
在一个具体实施中,这些输入具有时间顺序,使得每个输入在不同的时间步处生成并且具有多个输入通道。例如,该多个输入可包括以下三个输入:由时间步(t)处的当前测序循环生成的当前输入、由时间步(t-1)处的先前测序循环生成的先前输入以及由时间步(t+1)处的后续测序循环生成的后续输入。在另一个具体实施中,每个输入分别来源于由一个或多个先前卷积层产生的当前输出、先前输出和后续输出,并且包括k个特征映射图。
在一个具体实施中,每个输入可包括以下五个输入通道:红色图像通道(红色)、红色距离通道(黄色)、绿色图像通道(绿色)、绿色距离通道(紫色)和缩放通道(蓝色)。在另一个具体实施中,每个输入可为蓝色及紫罗兰色通道(或者一个或多个其他适当的颜色通道),作为红色及绿色通道的替代或补充。在另一个具体实施中,每个输入可为蓝色及紫罗兰色通道,作为红色、绿色、紫色及/或黄色通道的替代或补充。在另一个具体实施中,每个输入可包括由先前卷积层产生的k个特征映射图,并且每个特征映射图被视为输入通道。在又一个示例中,每个输入可具有仅一个通道、两个通道或另一不同数量的通道。美国专利申请公开号2013/0079232的合并材料讨论了使用各种数量的通道(诸如一通道、两通道或四通道)的碱基检出。
图12描绘了隔离层的一个具体实施,这些隔离层中的每个层可包括卷积。隔离卷积通过将卷积滤波器同步地应用于每个输入一次来处理该多个输入。利用隔离卷积,卷积滤波器组合相同输入中的输入通道,并且不组合不同输入中的输入通道。在一个具体实施中,将相同的卷积滤波器同步地应用于每个输入。在另一个具体实施中,将不同的卷积滤波器同步地应用于每个输入。在一些具体实施中,每个空间卷积层包括一组k个卷积滤波器,其中每个卷积滤波器同步地应用于每个输入。
图13A描绘了组合层的一个具体实施,该组合层中的每一个组合层可包括卷积。图13B描绘了组合层的另一具体实施,该组合层中的每一个组合层可包括卷积。组合卷积通过对不同输入的对应输入通道进行分组并将卷积滤波器应用于每个分组来混合不同输入之间的信息。对这些对应输入通道的分组和卷积滤波器的应用是在滑动窗口的基础上发生的。在该上下文中,窗口跨越两个或更多个后续输入通道,其表示例如两个后续测序循环的输出。由于该窗口是滑动窗口,因此大多数输入通道用于两个或更多个窗口中。
在一些具体实施中,不同输入源于由先前空间卷积层或先前时间卷积层产生的输出序列。在该输出序列中,这些不同输入被布置为后续输出并且因此被后续时间卷积层视为后续输入。然后,在该后续时间卷积层中,这些组合卷积将卷积滤波器应用于这些后续输入中的对应输入通道组。
在一个具体实施中,这些后续输入具有时间顺序,使得当前输入由时间步(t)处的当前测序循环生成,先前输入由时间步(t-1)处的先测序循环生成,并且后续输入由时间步(t+1)处的后续测序循环生成。在另一个具体实施中,每个后续输入分别来源于由一个或多个先前卷积层产生的当前输出、先前输出和后续输出,并且包括k个特征映射图。
在一个具体实施中,每个输入可包括以下五个输入通道:红色图像通道(红色)、红色距离通道(黄色)、绿色图像通道(绿色)、绿色距离通道(紫色)和缩放通道(蓝色)。在另一个具体实施中,附加输入通道可以是紫罗兰色通道。在另一个具体实施中,每个输入可包括由先前卷积层产生的k特征映射图,并且每个特征映射图被视为输入通道。
卷积滤波器的深度B取决于后续输入的数量,这些后续输入的对应输入通道由卷积滤波器在滑动窗口的基础上逐组地进行卷积。换句话讲,深度B等于每个滑动窗口中的后续输入的数量和组大小。
在图13A中,来自两个后续输入的对应输入通道在每个滑动窗口中组合,并且因此B=2。在图13B中,来自三个后续输入的对应输入通道在每个滑动窗口中组合,并且因此B=3。
在一个具体实施中,滑动窗口共享相同的卷积滤波器。在另一个具体实施中,针对每个滑动窗口使用不同的卷积滤波器。在一些具体实施中,每个时间卷积层包括一组k个卷积滤波器,其中每个卷积滤波器在滑动窗口的基础上应用于后续输入。
图4至图10的进一步细节及其变型可见于2021年2月15日提交的名称为“HardwareExecution and Acceleration of Artificial Intelligence-Based Base Caller”的共同未决的美国非临时专利申请号17/176,147(代理人案卷号ILLM 1020-2/IP-1866-US),该专利申请以引用方式并入本文,如同在本文中完全阐述一样。
使用多个碱基检出器的碱基检出
图14示出了包括多个碱基检出器以预测包括碱基序列的未知分析物的碱基检出的碱基检出系统1400。
需注意,先前讨论的图6A仅示出了图14的系统1400的一些部件,而图14示出了图6A中未示出的各种其他部件。
如相对于图6A所讨论的,图14的系统1400包括测序机器1404,诸如相对于图1所讨论的测序机器。测序机器1404包括流通池1405,诸如相对于图1至图3所讨论的流通池。流通池1405包括多个区块1406,并且每个区块1406包括多个簇1407(图6A中示出了单个区块的示例性簇),例如如相对于图2和图3所讨论的。如相对于图4至图6所讨论的,包括来自区块1406的原始图像的传感器数据1412由测序机器1404输出。
在一个实施方案中,系统1400包括两个或更多个碱基检出器,诸如第一碱基检出器1414和第二碱基检出器1416。尽管图中示出了两个碱基检出器,但是在一个示例中,系统1400中可存在多于两个碱基检出器,诸如三个、四个或更高数量的碱基检出器。
在一个示例中,碱基检出器1414和1416在测序机器1404的本地。因此,碱基检出器1414和1416和测序机器1404邻近地定位(例如,在同一壳体内,或在两个邻近地定位的壳体内),并且碱基检出器1414和1416直接从测序机器1404接收传感器数据1412。
在另一个示例中,碱基检出器1414和1416相对于测序机器1404位于远程,这些碱基检出器为所谓的基于云的碱基检出器的示例。因此,碱基检出器1414和1416经由计算机网络(诸如互联网)从测序机器1404接收传感器数据1412。
图14的每个碱基检出器1414和1416输出对应碱基检出分类信息。例如,第一碱基检出器1414输出第一碱基检出分类信息1434,并且第二碱基检出器1416输出第二碱基检出分类信息1436。碱基检出组合模块1428基于第一碱基检出分类信息1434和第二碱基检出分类信息1436中的一者或两者来生成最终碱基检出1440。
在一个示例中,第一碱基检出器1414是基于神经网络的碱基检出器。例如,第一碱基检出器1414是采用用于碱基检出的一个或多个神经网络模型的非线性系统,如本文先前所讨论的(例如,参见图6至图13B)。
在一个示例中,第二碱基检出器1416是非基于神经网络的碱基检出器。例如,第二碱基检出器1416至少部分地是用于碱基检出的线性系统。例如,第二碱基检出器1416不采用用于碱基检出的神经网络(或者相比于第一碱基检出器1414所使用的较大神经网络模型,使用较小的用于碱基检出的神经网络模型),如本文先前所讨论的(例如,参见图6和后续讨论)。
在一个实施方案中,系统1400包括上下文信息生成模块1418。上下文信息生成模块1418生成上下文信息1420。在一个实施方案中,碱基检出组合模块1428基于上下文信息1420进行操作。例如,基于上下文信息1420,碱基检出组合模块1428使用碱基检出分类信息1434和碱基检出分类信息1436中的一者或两者来生成最终碱基检出。上下文信息将在本文中稍后例如相对于图16来讨论。
在一个实施方案中,系统1400还包括切换模块1422。需注意,在图14中,切换模块1422、上下文信息生成模块1418和碱基检出组合模块1428被示出为系统1400的三个单独部件。然而,在一个示例中,这些模块中的一个或多个模块可组合以形成组合模块。
在一个实施方案中,系统1400还包括选择性地接通或断开碱基检出器1414和1416的切换模块1422。例如,取决于上下文信息1420,如果假设碱基检出器1414和1416中的仅一者分析传感器数据1412的特定集合,则对于该传感器数据的集合,仅启用所选择的碱基检出器并且停用另一碱基检出器,如本文稍后将进一步详细讨论的。
针对传感器数据的集合启用或接通碱基检出器意味着该碱基检出器将对传感器数据的特定集合操作或执行。因此,启用或接通碱基检出器不一定意味着打开该碱基检出器—这仅意味着对传感器数据的特定对应集合执行该碱基检出器。针对传感器数据的集合停用或断开碱基检出器意味着该碱基检出器将抑制对传感器数据的特定集合操作或执行。需注意,例如,当针对传感器数据的第一集合停用碱基检出器时,可针对传感器数据的第二集合启用该碱基检出器。在一个示例中,可使用启用信号1424来选择性地启用或停用第一碱基检出器1414,并且可使用启用信号1426来选择性地启用或停用第二碱基检出器1416。因此,启用信号1424和1426是分别选择性地启用(或停用)对应碱基检出器1414或1416的信号。
如本文所讨论的,“传感器数据的集合”是指传感器数据1412的区段或传感器数据1412的数据集。例如,传感器数据的集合可以是来自流通池1405的一个或多个特定簇1407或一个或多个特定区块1406的传感器数据。传感器数据的集合可以是来自一个或多个特定碱基感测循环的传感器数据。因此,传感器数据的集合可与流通池1405的特定空间方面(例如,来自流通池1405的一个或多个特定簇1407)和/或碱基检出循环的特定时间方面(例如,来自一个或多个特定碱基检出循环)相关联。
仅作为一个示例,对于传感器数据1412的第一集合,碱基检出组合模块1428可仅依赖于来自第一碱基检出器1414的碱基检出分类信息1434来生成传感器数据1412的第一集合的最终碱基检出1440。碱基检出组合模块1428例如基于与传感器数据1412的第一集合相关联的上下文信息1420来决定仅依赖于碱基检出分类信息1434(而不依赖于碱基检出分类信息1436)。在一个示例中,当处理传感器数据的第一集合时,切换模块1422仅使用启用信号1424来启用第一碱基检出器1414(例如,第一碱基检出器1414对数据的第一集合执行),并且使用启用信号1426来停用第二碱基检出器1416(例如,第二碱基检出器1416不对数据的第一集合执行),并且来自第一碱基检出器1414的第一碱基检出分类信息1434用于生成最终碱基检出1440。然而,在另一个示例中,尽管使用来自第一碱基检出器1414的第一碱基检出分类信息1434来生成数据的第一集合的最终碱基检出1440,但切换模块1422启用第一碱基检出器1414,并且任选地还启用第二碱基检出器1416,例如出于本文稍后讨论的原因。在这种示例中,碱基检出分类信息1434和1436两者可用于数据的第一集合,并且最终碱基检出1440仅基于第一碱基检出分类信息1434。
仅作为另一个示例,对于传感器数据1412的第二集合,碱基检出组合模块1428可仅依赖于来自第二碱基检出器1416的碱基检出分类信息1436来生成传感器数据1412的第二集合的最终碱基检出1440。碱基检出组合模块1428例如基于与传感器数据1412的第二集合相关联的上下文信息1420来决定仅依赖于碱基检出分类信息1436(而不依赖于碱基检出分类信息1434)。在一个示例中,当处理传感器数据的第二集合时,切换模块1422仅使用启用信号1426来启用第二碱基检出器1416,并且使用启用信号1424来停用第一碱基检出器1414,例如,并且来自第二碱基检出器1416的第二碱基检出分类信息1436用于生成最终碱基检出1440。然而,在另一个示例中,尽管使用来自第二碱基检出器1416的第二碱基检出分类信息1436来生成数据的第二集合的最终碱基检出1440,但切换模块1422启用第二碱基检出器1416,并且任选地还启用第一碱基检出器1414,例如出于本文稍后讨论的原因。在这种示例中,碱基检出分类信息1434和1436两者是可用的,并且最终碱基检出1440仅基于碱基检出分类信息1436。
仅作为又一个示例,对于传感器数据1412的第三集合,碱基检出组合模块1428可依赖于分别来自碱基检出器1414和1416的碱基检出分类信息1434和1436两者来生成传感器数据1412的第三集合的最终碱基检出1440。碱基检出组合模块1428例如基于与传感器数据1412的第三集合相关联的上下文信息1420来决定依赖于碱基检出分类信息1434和1436两者。因此,当处理传感器数据的第三集合时,切换模块1422分别使用启用信号1424和1426来启用碱基检出器1414和1416两者。
因此,对于传感器数据的给定集合,碱基检出组合模块1428基于与传感器数据的对应集合相关联的上下文信息1420来决定依赖于碱基检出分类信息1434和1436中的特定一者或两者。类似地,切换模块1422基于与传感器数据的对应集合相关联的上下文信息1420来决定启用碱基检出器1414和1416中的特定一者或两者。
第一碱基检出器1414和第二碱基检出器1416的示例性操作
图15A、图15B、图15C、图15D和图15E示出了描绘图14的碱基检出系统1400针对传感器数据的对应集合的各种操作的对应流程图。例如,图15A至图15E示出了其中系统1400可操作的各种排列和组合。
第一碱基检出器1414被启用,最终碱基检出1440基于第一碱基检出分类信息1434
图15A示出了系统1400的操作,其中第一碱基检出器1414被启用并生成传感器数据的集合1501a的碱基检出分类信息(例如,同时第二碱基检出器1416不对传感器数据的集合1501a操作),并且最终碱基检出1440基于传感器数据的集合1501a的第一碱基检出分类信息1434。
因此,在图15A中,针对由流通池1405生成的传感器数据的集合1501a示出了系统1400的操作。在1505a处,流通池1405生成传感器数据的集合1501a。如所讨论的,传感器数据的集合1501a可在流通池的特定位置中诸如由特定区块的特定簇或由特定区块生成,并且针对特定碱基序列循环生成(即,集合与流通池1405的特定空间位置和特定时间碱基序列循环相关联)。同样在1505a处,(例如,由切换模块1422和/或碱基检出组合模块1428)访问与传感器数据的集合1501a相关联的上下文信息。如所讨论的,上下文信息可由上下文信息生成模块1418生成。
在图15A的示例中,切换模块1422决定第一碱基检出器1414(而不是第二碱基检出器1416)将处理传感器数据的集合1501a。因此,在1510a处,切换模块1422例如通过打开启用信号1424来启用第一碱基检出器1414。第二碱基检出器1416可保持停用,即,第二碱基检出器1416不对传感器数据的集合1501a操作。
在1515a处,第一碱基检出器1414生成传感器数据的集合1501a的第一碱基检出分类信息1434,而第二碱基检出器1416抑制生成传感器数据的集合1501a的任何第二碱基检出分类信息1436。
在1520a处,碱基检出组合模块1428基于与传感器数据的集合1501a相关联的上下文信息1420使用第一碱基检出分类信息1434来生成传感器数据的集合1501a的最终碱基检出。
第二碱基检出器1416被启用,最终碱基检出1440基于第二碱基检出分类信息1436
图15B示出了系统1400的操作,其中第二碱基检出器1416被启用并生成传感器数据的集合1501b的碱基检出分类信息(例如,同时第一碱基检出器1414不对传感器数据的集合1501b操作),并且最终碱基检出1440基于传感器数据的集合1501b的第二碱基检出分类信息1436。
在1505b处,流通池1405生成传感器数据的集合1501b。如所讨论的,传感器数据的集合1501a可在流通池的特定位置中诸如由特定区块的特定簇或由特定区块生成,并且针对特定碱基序列循环生成(即,集合与流通池1405的特定空间位置和特定时间碱基序列循环相关联)。同样在1505b处,(例如,由切换模块1422和/或碱基检出组合模块1428)访问与传感器数据的集合1501b相关联的上下文信息。如所讨论的,上下文信息可由上下文信息生成模块1418生成。
在图15B的示例中,切换模块1422决定第二碱基检出器1416(而不是第一碱基检出器1414)将处理传感器数据的集合1501b。因此,在1510b处,切换模块1422例如通过使用启用信号1426来启用第二碱基检出器1416。第一碱基检出器1414可保持停用,即,第一碱基检出器1414不对传感器数据的集合1501b操作。
在1515b处,第二碱基检出器1416生成传感器数据的集合1501b的第二碱基检出分类信息1436,而第一碱基检出器1414抑制生成传感器数据的集合1501b的任何第一碱基检出分类信息1434。
在1520b处,碱基检出组合模块1428基于与传感器数据的集合1501b相关联的上下文信息1420使用第二碱基检出分类信息1436来生成传感器数据的集合1501b的最终碱基检出。
第一碱基检出器1414和第二碱基检出器1416被启用,最终碱基检出1440基于(i)
图15C示出了系统1400的操作,其中第一碱基检出器1414和第二碱基检出器1416两者被启用(即,两个碱基检出器对传感器数据的对应集合1501c操作)并生成传感器数据的集合1501c的对应碱基检出分类信息,并且最终碱基检出1440基于(i)第一碱基检出分类信息1434和/或(ii)第二碱基检出分类信息1436中的一者或两者。
在1505c处,流通池1405生成传感器数据的集合1501c。如所讨论的,传感器数据的集合1501c可在流通池的特定位置中诸如由特定区块的特定簇或由特定区块生成,并且针对特定碱基序列循环生成(即,集合与图14中的流通池1405的特定空间位置和特定时间碱基序列循环相关联)。同样在1505c处,(例如,由切换模块1422和/或碱基检出组合模块1428)访问与传感器数据的集合1501c相关联的上下文信息。如本文将进一步详细讨论的,上下文信息可由上下文信息生成模块1418生成。
在图15C的示例中,切换模块1422决定第一碱基检出器1414和第二碱基检出器1416两者将处理传感器数据的集合1501c。因此,在1510c处,切换模块1422(图14)例如使用启用信号1424和1426(图14)来启用第一碱基检出器1414和第二碱基检出器1416两者。例如,第一碱基检出器1414和第二碱基检出器1416两者将处理传感器数据的整个集合1501c。在另一个示例中,第一碱基检出器1414将处理传感器数据的集合1501c的第一子集,并且第二碱基检出器1416将处理传感器数据的集合1501c的第二子集。
在1515c处,第一碱基检出器1414生成传感器数据的集合1501c的第一碱基检出分类信息1434,并且第二碱基检出器1416生成传感器数据的集合1501c的第二碱基检出分类信息1436。
在1520c处,碱基检出组合模块1428基于与传感器数据的集合1501c相关联的上下文信息1420使用第一碱基检出分类信息1434和/或第二碱基检出分类信息1436来生成传感器数据的集合1501c的最终碱基检出。
在仅使用第一碱基检出分类信息1434无法生成最终碱基检出的情况下,启用并使
图15D示出了系统1400的操作,其中在仅使用第一碱基检出分类信息1434无法生成最终碱基检出的情况下,将第二碱基检出分类信息1436用于最终碱基检出1440。
在1505d处,流通池1405生成传感器数据的集合1501d。如所讨论的,传感器数据的集合1501d可在流通池的特定位置中诸如由特定区块的特定簇或由特定区块生成,并且针对特定碱基序列循环生成(即,集合与流通池1405的特定空间位置和特定时间碱基序列循环相关联)。同样在1505d处,(例如,由切换模块1422和/或碱基检出组合模块1428)访问与传感器数据的集合1501d相关联的上下文信息。如所讨论的,上下文信息可由上下文信息生成模块1418生成。
在图15D的示例中,切换模块1422决定第一碱基检出器1414将处理传感器数据的集合1501d。任选地,切换模块1422还可决定第二碱基检出器1416也可处理传感器数据的集合1501d。因此,在1501d处,启用第一碱基检出器1414,并且任选地也启用第二碱基检出器1416。
在1515d处,第一碱基检出器1414生成传感器数据的集合1501d的第一碱基检出分类信息1434。在1510d处的其中启用第二碱基检出器1416的任选操作中,第二碱基检出器1416任选地生成传感器数据的集合1501d的第二碱基检出分类信息1436。
在1520d处,(例如,由切换模块1422和/或碱基检出组合模块1428)确定是否可根据第一碱基检出分类信息1434(例如,在不使用第二碱基检出分类信息1436的情况下)生成最终碱基检出。例如,可确定在例如最终碱基检出1440仅基于第一碱基检出分类信息1434的情况下,最终碱基检出1440中的错误概率可能相对较高。本文稍后将依次讨论这种确定的许多示例。仅作为一个示例,如果第一碱基检出分类信息1434指示均聚物(例如,GGGGG)或近均聚物(例如,GGTGG)序列,则第一碱基检出分类信息1434对于生成最终碱基检出可能是不足或不充分的(例如,必须依赖于第二碱基检出分类信息1436来生成最终碱基检出),例如,如本文稍后相对于图19B和图19C所讨论的。
如果在1520d处为“是”(即,在不使用第二碱基检出分类信息1436的情况下可根据第一碱基检出分类信息1434生成最终碱基检出),则方法1500d前进至1525d,其中使用第一碱基检出分类信息1434来生成传感器数据的集合1501d的最终碱基检出。
如果在1520d处为“否”(即,例如在不使用第二碱基检出分类信息1436的情况下无法仅根据第一碱基检出分类信息1434生成最终碱基检出),则方法1500d前进至1530d,其中启用第二碱基检出器1416,并且接着前进至1535d,其中使用第二碱基检出器1416来生成第二碱基检出分类信息1436。需注意,框1530d和1535d处的操作是任选的,并且因此使用虚线来示出。例如,如果在1510d处任选地启用第二碱基检出器1416,则可跳过操作1530d。类似地,如果在1515d处任选地使用第二碱基检出器1416来生成第二碱基检出分类信息1436,则可跳过操作1535d。
假设其中在1510d处未启用第二碱基检出器1416并且在1530d处启用第二碱基检出器1416的场景。因此,在1530d处,第二碱基检出器1416开始处理传感器数据的集合1510d。可注意到,对于给定的碱基检出循环,第二碱基检出器1416不能立即开始处理对应传感器数据并且生成碱基检出。这是因为,由于本文稍后讨论的定相(例如,参见图17C、图17D),第二碱基检出器1416必须处理一个或多个先前碱基检出循环的传感器数据以令人满意地检出当前循环的碱基。例如,假设要执行碱基检出循环1至1000,并且传感器数据的集合1501d包括来自碱基检出循环100往前的图像。还假设,在1530d处,启用第二碱基检出器1416来处理碱基检出循环100和一个或多个后续碱基检出循环的传感器数据。如所讨论的,第二碱基检出器1416必须处理来自一个或多个先前循环的传感器数据以令人满意地检出循环100和后续循环的碱基。处理来自几个先前循环的传感器数据使得第二碱基检出器1416能够估计循环100处的定相的影响,这提高了循环100处的碱基检出的质量。仅作为一个示例,五个、十个、二十个或另一适当数量的先前循环要由第二碱基检出器1416处理,以便第二碱基检出器1416令人满意地检出循环100的碱基检出。
在第一示例中,假设第二碱基检出器1416必须处理来自N1个先前循环的传感器数据以令人满意地检出循环100的碱基。在第二示例中,假设第二碱基检出器1416必须处理来自N2个先前循环的传感器数据以令人满意地检出循环1000的碱基。现在,如将相对于图17C、图17D讨论的,定相和预定相的影响随着碱基检出循环进展而更加显著。因此,在循环1000中定相和预定相比在循环100中更加显著。因此,为了令人满意地检出循环1000的碱基,第二碱基检出器1416必须处理比要处理的先前循环的数量更高数量的先前循环以令人满意地检出循环100的碱基。因此,N2高于N1。
再次参考图15D,在1535d之后,在1540d处,使用(i)第一碱基检出分类信息1434和/或(ii)第二碱基检出分类信息1436中的一者或两者来生成传感器数据的集合1501d的最终碱基检出。
在仅使用第二碱基检出分类信息1436无法生成最终碱基检出的情况下,启用并使
图15E示出了系统1400的操作,其中在仅使用第二碱基检出分类信息1436无法生成最终碱基检出的情况下,将第一碱基检出分类信息1434用于最终碱基检出1440。
在1505e处,流通池1405生成传感器数据的集合1501e。如所讨论的,传感器数据的集合1501e可在流通池的特定位置中诸如由特定区块的特定簇或由特定区块生成,并且针对特定碱基序列循环生成(即,集合与流通池1405的特定空间位置和特定时间碱基序列循环相关联)。同样在1505e处,(例如,由切换模块1422和/或碱基检出组合模块1428)访问与传感器数据的集合1501e相关联的上下文信息。如所讨论的,上下文信息可由上下文信息生成模块1418生成。
在图15E的示例中,切换模块1422例如基于相关联的上下文信息来决定第二碱基检出器1416将处理传感器数据的集合1501e。任选地,切换模块1422还可决定第一碱基检出器1414也可处理传感器数据的集合1501e。因此,在1510e处,启用第二碱基检出器1416,并且任选地也启用第一碱基检出器1414。
在1515e处,第二碱基检出器1416生成传感器数据的集合1501e的第二碱基检出分类信息1436。在其中也启用第一碱基检出器1414的选项中,第一碱基检出器1414生成传感器数据的集合1501e的第一碱基检出分类信息1434。
在1520e处,(例如,由切换模块1422和/或碱基检出组合模块1428)确定是否可仅根据第二碱基检出分类信息1436(例如,在不使用第一碱基检出分类信息1434的情况下)生成最终碱基检出。例如,可(例如,基于上下文信息)确定在例如最终碱基检出1440仅基于第二碱基检出分类信息1436的情况下,最终碱基检出1440中的错误概率可能相对较高。本文稍后将依次讨论这种确定的许多示例。仅作为一个示例,如果上下文信息指示检测到簇中的气泡,则无法根据第二碱基检出分类信息1436(例如,在不使用第一碱基检出分类信息1434的情况下)生成最终碱基检出,例如,如本文稍后相对于图19D所讨论的。
如果在1520e处为“是”(即,在不使用第一碱基检出分类信息1434的情况下可根据第二碱基检出分类信息1436生成最终碱基检出),则方法1500c前进至1525e,其中使用第二碱基检出分类信息1436来生成传感器数据的集合1501e的最终碱基检出。
如果在1520e处为“否”(即,在不使用第一碱基检出分类信息1434的情况下无法根据第二碱基检出分类信息1436生成最终碱基检出),则方法1500e前进至1530e,其中启用第一碱基检出器1414,并且接着前进至1535e,其中使用第一碱基检出器1414来生成第一碱基检出分类信息1434。需注意,框1530e和1535e处的操作是任选的,并且因此使用虚线来示出。例如,如果在1510e处任选地启用第一碱基检出器1414,则可跳过操作1530e。类似地,如果在1515e任选地使用第一碱基检出器1414来生成第一碱基检出分类信息1434,则可跳过操作1535e。
假设其中在1510e处未启用第一碱基检出器1414并且在1530e处启用第一碱基检出器1414的场景。因此,在1530e处,第一碱基检出器1416开始处理传感器数据的集合1510e。可注意到,对于给定的碱基检出循环,第一碱基检出器1414不能立即开始处理对应传感器数据并且生成碱基检出。例如,假设第一碱基检出器1414要对来自碱基检出循环Na的数据的对应集合操作。为了令人满意地生成来自循环Na的碱基检出,第一碱基检出器1414还必须对来自循环Na之前的至少几个循环的传感器数据操作,例如,因为如相对于图7和图10所讨论的,当前循环的碱基检出也基于来自一个或多个过去循环和一个或多个未来循环的数据。因此,为了生成来自循环Na的第一碱基检出分类信息1434,第一碱基检出器1414还必须处理来自几个先前循环(诸如,在图7的示例中为2个循环,并且在图10的示例中为5个循环)的传感器数据。
随后,在1540e处,使用(i)第一碱基检出分类信息1434和/或(ii)第二碱基检出分类信息1436中的一者或两者来生成传感器数据的集合1501e的最终碱基检出。
上下文信息
图16示出了图14的碱基检出系统1400的生成传感器数据的示例性集合1601的上下文信息1420的上下文信息生成模块1418。例如,上下文信息生成模块1418接收关于传感器数据的集合1601的信息,并且生成传感器数据的集合1601的各种类型的上下文信息,这些上下文信息组合起来称为传感器数据的集合1601的上下文信息。例如,上下文信息生成模块1418生成传感器数据的集合1601的空间上下文信息1604、时间上下文信息1606、碱基序列上下文信息1608和其他上下文信息1610。
空间上下文信息1604
顾名思义,空间上下文信息1604是指与根据其生成传感器数据的集合1601的区块和簇的空间位置相关联的上下文信息。下面的图17A和图17B讨论空间上下文信息1604的示例。
图17A示出了图14的系统1400的流通池1405,其中流通池1405包括区块1406,这些区块基于区块的空间位置来归类。例如,如相对于图2所讨论的,图17A的流通池1405包括多个槽道1702,其中每个槽道内具有对应多个区块1406。图17A示出了流通池1405的顶视图。
各个区块基于区块的位置来归类。例如,与流通池1405的任何边缘相邻的区块被标记为边缘区块1406a(使用灰色框示出),并且其余区块被标记为非边缘区块1406b(使用虚线框示出)。
例如,在流通池1404的竖直边缘(例如,沿Y轴)和/或水平边缘(例如,沿X轴)上的区块被归类为边缘区块1406a,如图14所示。因此,边缘区块1406a与流通池1404的对应边缘相邻(例如,直接相邻),并且非边缘区块不与流通池1404的任何边缘相邻。
针对流通池1404的各个区块中的簇执行碱基检出循环。在一个示例中,与区块的碱基检出操作相关的参数可基于区块的相对位置。例如,相对于图1所讨论的激发光101被导向流通池的区块,并且例如,基于各个区块的位置和/或发射激发光101的一个或多个光源的位置,不同的区块可接收不同量的激发光101。例如,如果发射激发光101的光源垂直位于流通池上方,则非边缘区块1406b可接收与边缘区块1406a不同量的光。在另一个示例中,在流通池1405周围的周边或外部光(例如,来自生物传感器外部的环境光)可影响由流通池1405的各个区块接收的激发光101的量和/或特征。仅作为一个示例,边缘区块1406a可接收激发光101以及来自流通池1405外部的一定量的周边光,而非边缘区块1406b可主要接收激发光101。在又一个示例中,包括在流通池1405中的各个传感器(或像素或光电二极管)(例如,图1中示出的传感器106、108、110、112和114)可基于对应传感器的位置来感测光,对应传感器的位置基于对应区块的位置。例如,与周边光对与非边缘区块1406b相关联的一个或多个其他传感器的感测操作的影响相比,由与边缘区块1406a相关联的一个或多个传感器执行的感测操作可相对更多地受到周边光(以及激发光101)的影响。在又一个示例中,反应物(例如,其包括可用于在碱基检出期间获得期望反应的任何物质,诸如试剂、酶、样品、其他生物分子和缓冲溶液)向各种区块的流动也可能受到区块位置的影响。例如,靠近反应物的源的区块可比离源更远的区块接收到更大量的反应物。
在一个示例中,与传感器数据的集合1601相关联的空间上下文信息1604(参见图16)包括关于传感器数据的集合1601是在边缘区块1406a中还是在非边缘区块1406b中生成的信息。如上所讨论的,对于不同类别的区块,与碱基检出相关联的参数可能略有不同。因此,在一个实施方案中,指示传感器数据的集合1601是从边缘区块还是非边缘区块生成的空间上下文信息1604可影响对用于处理传感器数据的集合1601的碱基检出器的选择。仅作为一个示例且基于具体实施细节,第一碱基检出器1414可更适用于处理来自边缘或非边缘区块中的一者的传感器数据,而第二碱基检出器1416可更适用于处理来自边缘或非边缘区块中的另一者的传感器数据。
图17B示出了图14的系统1400的流通池1405的区块1406,其中区块1406包括簇1407,这些簇基于簇的空间位置来归类。
在一个示例中,基于从区块接收的传感器数据(其可为例如图像数据),可估计该区块内的各种簇的位置。例如,可使用簇的(x,y)坐标来识别各个簇的位置。因此,每个簇1407具有识别该簇相对于该区块的位置的对应(x,y)坐标。在图17B中,示例性区块1406的簇1407被归类为边缘簇1407a或非边缘簇1407b。例如,在距区块的边缘的阈值距离L1内的簇1407被标记为边缘簇1407a,并且在距区块的边缘的阈值距离L1外的簇1407被标记为非边缘簇1407b。因此,边缘簇1407a位于区块1406的周边附近,而非边缘簇1407a位于区块1406的中心区段附近。如所讨论的,使用簇的(x,y)坐标,可(例如,由上下文信息生成模块1418)确定簇相对于区块的边缘的距离,基于该距离,上下文信息生成模块1418将簇分类为边缘簇1407a或非边缘簇1407b。作为简单的示例,图17B中示出假想虚线矩形,该假想虚线矩形在区块1406的周边内并且与区块1406的周边相距距离L1。虚线矩形内的簇被分类为非边缘簇1407b,而虚线矩形的周边和区块1406的周边之间的簇被分类为边缘簇1407a。
如相对于图1所讨论的,流通池1405可包括用于捕获各种簇的图像的透镜(诸如包括微透镜或其他光学部件的阵列的滤波器层124)。在一个示例中,当捕获图像时,例如当图像传感器或相机围绕流通池移动时,对于各种簇的聚焦可能略有差异。例如,当捕获簇的图像时,边缘簇1407a可相对于非边缘簇1407b略微失焦。由于透镜移动引起的加热或机械振动,也可能发生失焦事件。因此,取决于具体实施,第一碱基检出器1414或第二碱基检出器1416中的一者可更适于处理来自边缘簇1407a的传感器数据,而第一碱基检出器1414或第二碱基检出器1416中的另一者可更适于处理来自非边缘簇1407b的传感器数据,如本文稍后将进一步详细讨论的(参见图19G、图20D)。在一个示例中,与传感器数据的集合1601相关联的空间上下文信息1604(参见图16)包括关于传感器数据的集合1601是从一个或多个边缘簇1407a还是一个或多个非边缘簇1407b生成的信息,基于该信息,可由第一碱基检出器1414或第二碱基检出器1416中的特定一者或两者处理传感器数据的集合1601。
因此,总结以上讨论,与传感器数据的集合1601相关联的空间上下文信息1604包括:(i)关于传感器数据的集合1601是从边缘区块1406a还是非边缘区块1406b生成的信息,和/或(ii)关于传感器数据的集合1601是从一个或多个边缘簇1407a还是一个或多个非边缘簇1407b生成的信息。基于本公开的教导,还可设想其他适当空间上下文信息。
时间上下文信息1606
再次参考图16,上下文信息生成模块1418还生成时间上下文信息1606。例如,本文讨论的碱基检出系统可被配置为接收待检出其碱基的样品。这种碱基检出可在多个碱基检出循环内执行。在一个示例中,传感器数据的集合1601的时间上下文信息1606指示针对其生成传感器数据的集合1601的一个或多个碱基检出循环数。例如,假设存在N个碱基检出循环,并且传感器数据的集合1601与总共N个碱基检出循环中的碱基检出循环N1至N2相关联。传感器数据的集合1601的时间上下文信息1606将包括这种信息。如下文所讨论的,使用哪个碱基检出器来处理传感器数据的集合1601的选择也可基于传感器数据的集合1601与之相关联的碱基检出循环数。
图17C示出了衰落的示例,其中信号强度随着碱基检出操作的测序运行的循环数降低。衰落是荧光信号强度随着碱基检出循环数的指数衰减。随着测序运行进展,分析物链被过度洗涤,暴露于产生反应性物质的激光辐射,并且经受恶劣环境条件。所有这些导致每个分析物中片段的逐渐丢失,从而降低了其荧光信号强度。衰落也称为变暗或信号衰减。图17C示出了衰落1700C的一个示例。在图17C中,具有AC微卫星的分析物片段的强度值表现出指数衰减。
图17D概念性地示出了随着测序循环进展而降低的信噪比。例如,随着测序进行,准确的碱基检出变得越来越困难,因为信号强度降低且噪声增加,从而导致信噪比显著降低。在物理上,观察到较晚的合成步骤与较早的合成步骤相比,将标签附着在相对于传感器的不同位置中。当传感器在正在合成的序列下方时,信号衰减是由于在较晚的测序步骤中与在较早步骤中相比将标签附着在离传感器更远的链上。这导致随着测序循环进展,信号衰减。在一些设计中,在传感器位于保持簇的基板上方的情况下,随着测序进行,信号可增强而不是衰减。
在研究的流通池设计中,当信号衰减时,噪声变大。在物理上,随着测序进行,定相和预定相增加噪声。定相是指测序中标签未能沿序列前进的步骤。预定相是指标签在测序循环期间向前跳两个位置而不是一个位置的测序步骤。定相和预定相相对不频繁,在大约500个至1000个循环中发生一次。与预定相相比,定相略微更频繁。定相和预定相影响产生强度数据的簇中的各个链,因此随着测序进行,来自簇的强度噪声分布累积成二项、三项、四项等展开式。
衰落、信号衰减和信噪比降低以及图17C和图17D的进一步细节可见于2020年5月14日提交的名称为“Systems and Devices for Characterization and PerformanceAnalysis of Pixel-Based Sequencing”的美国非临时专利申请16/874,599号(代理人案卷号ILLM 1011-4/IP-1750-US)中,该专利申请以引用方式并入本文,如同在本文中完全阐述一样。
因此,在碱基检出期间,碱基检出的可靠性或质量(例如,检出碱基正确的概率)可基于针对其当前碱基正被检出的碱基检出循环数。因此,对用于处理传感器数据的集合1601的第一碱基检出器1414和/或第二碱基检出器1416的选择还可基于正在针对其执行碱基检出操作的当前循环数,该当前循环数可包括在传感器数据的集合1601的时间上下文信息1606中,如本文稍后将进一步详细讨论的。
碱基序列上下文信息1608
图18示出了碱基检出器的不同示例性配置(例如,DeepRTA、DeepRTA-K0-06、DeepRTA-349-K0-10-160p、DeepRTA-KO-16、DeepRTA-K0-16-Lanczos、DeepRTA-KO-18和DeepRTA-K0-20)对均聚物(例如,GGGGG)和具有近均聚物的序列或具有侧接均聚物的序列(例如,GGTGG)进行碱基检出的碱基检出准确度(1-碱基检出错误率)。在一个示例中,具有侧接均聚物的序列(例如,GGTGG)包括侧接在感兴趣的碱基(例如,T)两侧的均聚物(例如,GG)。类似地,近均聚物包括其中碱基中的几乎全部或大多数碱基相同(例如,5个碱基中的3个、或5个碱基中的4个、或7个碱基中的4个是G)的序列。图18中示出的表示出了各种碱基检出循环诸如循环20、40、60和80的数据(例如,碱基检出概率,或正确检出碱基的概率)。例如,在循环80处,使用DeepRTA碱基检出器正确检出序列GGGGG的中间碱基的概率是96.97%。需注意,假设本公开中讨论的均聚物、近均聚物或具有侧接均聚物的序列的一些示例具有五个碱基。然而,在此类特殊序列中可存在任何不同数量的碱基,诸如三个、五个、六个、七个、九个或另一适当数量。
如上所讨论的,在一些具体实施中,碱基检出器通过处理多个测序循环(包括由右测序循环和左测序循环情境化的当前测序循环)的测序图像窗口来进行当前测序循环的碱基检出。由于碱基“G”在测序图像中由暗或最小信号状态(在本文中也称为关闭状态、难以辨认的信号状态或非活动状态)指示,因此碱基“G”的重复模式可导致错误的碱基检出。在当前测序循环是针对非G碱基(例如,碱基“T”),但右侧和左侧侧接有G时,也会出现此类错误的碱基检出。需注意,非G碱基(即,A、C或T)在测序图像中通过亮起或打开(或活动)状态来指示。
在一个示例中,存在其碱基检出中的错误概率相对高的一些特定碱基检出序列模式。图18中示出了GGGGG和GGTGG的两个这样的示例。可能存在其碱基检出中的错误概率也相对高的其他特定碱基检出序列模式,诸如GGTCG。在一个示例中,此类特定碱基检出序列模式具有多个G,诸如至少在序列的开始和结束处的G,并且可能在5碱基序列中的两个端部G之间具有第三个G。此类特定碱基检出序列的其他示例包括GGXGG、GXGGG、GGGXG、GXXGG和GGXXG,其中X可为A、C、T或G中的任一者。
在一个示例中,传感器数据的集合1601的碱基序列上下文信息1608还提供关于传感器数据的集合1601是否与任何这样的特殊碱基序列模式相关联的指示。例如,如果传感器数据的集合1601用于检出序列GGGGG(或GGTGG)的中间碱基,则这可能需要特殊操作来生成最终碱基检出,如将在本文所讨论的(例如,参见图19B、图19C、图20A)。
其他上下文信息1610
再次参考图16,上下文信息生成模块1418进一步生成其他上下文信息1610。其他上下文信息1610可涵盖空间、时间和碱基序列上下文信息未涵盖的任何类型的上下文信息。
其他上下文信息1610的许多示例是可能的,其中一些示例在下文中讨论。
有时,在一个或多个碱基检出操作序列期间,在一个或多个簇上形成气泡。这种气泡可以是簇中存在的任何液体中的气体(诸如空气)的珠粒(诸如用于碱基检出的试剂内的气泡)。气泡的存在可基于分析从受影响的簇捕获的图像来检测。例如,簇内气泡的存在可通过在簇的所捕获图像中检测唯一强度信号特征来估计。在一个示例中,其他上下文信息1610可指示来自簇的传感器数据的集合1601是否与这种气泡相关联。换句话讲,如果来自簇的传感器数据的集合1601内的图像指示簇中存在气泡,则其他上下文信息1610提供簇中的这种气泡的指示。气泡的检测在2021年4月2日提交的名称为“Machine-Learning Modelfor Detecting a Bubble Within aNucleotide-Sample Slide for Sequencing”的共同未决的美国专利申请号63/170,072中有进一步详细的讨论,该专利申请以引用方式并入本文。关于在检测到气泡的情况下生成最终碱基检出的进一步细节在本文中稍后依次讨论。
在一个示例中,流通池中使用的试剂在如何进行碱基检出中起主要作用。例如,如果使用第一类型的试剂,则第一碱基检出器1414可能是合适的,而如果使用第二类型的试剂,则第二碱基检出器1416可能是合适的。在一个示例中,其他上下文信息1610提供了流通池中使用的试剂的指示。关于基于试剂的选择生成最终碱基检出的进一步细节在本文中稍后依次讨论。
第一碱基检出器1414和第二碱基检出器1416的选择性使用:最终碱基检出是来自
图19A示出了基于来自图14的系统1400的第一碱基检出器1414的第一碱基检出分类信息1434和来自第二碱基检出器1416的第二碱基检出分类信息1436的函数来生成传感器数据的集合的最终碱基检出。
在一个实施方案中,每个碱基检出器1414、1416输出待检出碱基是A、C、G或T的对应概率。例如,考虑来自第一碱基检出器1414的第一碱基检出分类信息1434。对于给定待检出碱基,第一碱基检出分类信息1434呈概率或置信度分数p1(A)、p1(C)、p1(G)、p1(T)的形式。在本文中,p1(A)表示待检出碱基是A的概率;p1(C)表示待检出碱基是C的概率;p1(G)表示待检出碱基是G的概率;p1(T)表示待检出碱基是T的概率。仅作为一个示例,如果p1(A)、p1(C)、p1(G)、p1(T)分别为0.6、0.2、0.15、0.05,则第一碱基检出器1414指示待检出碱基是A的为0.6的高概率。
在一个示例中,p1(A)、p1(C)、p1(G)、p1(T)的总和为1。因此,在一个示例中,第一碱基检出器例如使用softmax函数输出每个碱基的归一化概率。在另一个示例中,可使用其他技术(例如,除softmax之外)。例如,碱基检出器具有不使用softmax的输出层。例如,可使用基于回归的运算,该运算可使用例如到云中心的欧几里得或马哈拉诺比斯距离来导出每个碱基的概率量度。
类似地,对于给定待检出碱基,第二碱基检出分类信息1436呈概率或置信度分数p2(A)、p2(C)、p2(G)、p2(T)的形式,其中p2(A)、p2(C)、p2(G)、p2(T)的总和为1。
在一个实施方案中,除上文所讨论的概率之外,碱基检出器还可输出对应被检出碱基。例如,第一碱基检出器1414输出第一被检出碱基,而第二碱基检出器1416输出第二被检出碱基。
用于碱基检出的简单规则如下。例如,假设对于给定待检出碱基,第一碱基检出器1414输出的第一碱基检出分类信息1434为p1(A)、p1(C)、p1(G)、p1(T),其中p1(C)大于p1(A)、p1(G)和p1(T)中的每一者。然后,第一碱基检出器1414可将碱基检出为C。在另一个示例中,仅在对应概率p1(C)高于阈值概率的情况下,第一碱基检出器1414才可将碱基检出为C。在又一个示例中,假设p1(C)>p1(A)>p1(T)且>p1(G)。也就是说,p1(C)具有最高概率,接着是概率p1(A)。然后,如果p1(C)比p1(A)高出至少阈值(即,如果两个碱基的概率之间的差值是至少阈值量),则第一基检出器1414可将碱基检出为C。基于本公开的教导,可设想用于碱基检出的任何其他适当规则。第二碱基检出器1416也可相应地检出碱基。
再次参考图19A,碱基检出组合模块1428接收第一碱基检出分类信息1434和第二碱基检出分类信息1436以及上下文信息1420。假设基于上下文信息1420,碱基检出组合模块1428决定组合第一碱基检出分类信息和第二碱基检出分类信息,例如,如相对于图15C的方法1500c所讨论的。因此,在该示例中,碱基检出器1414和1416两者正在处理传感器数据的集合,并且最终置信度分数pf(A)、pf(C)、pf(G)、pf(T)和最终被检出碱基是基于碱基检出器1414和1416两者的输出。
当来自两个碱基检出器的分类信息相一致或匹配时,使用来自两个碱基检出器的
仍参考图19A,假设其中来自第一碱基检出器1414的第一碱基检出分类信息1434和来自第二碱基检出器1416的第二碱基检出分类信息1436相匹配的场景。例如,第一碱基检出器1414输出包括p1(A)、p1(C)、p1(G)、p1(T)的置信度分数的第一碱基检出分类信息1434,并且将碱基检出为C,仅作为一个示例。另外,例如,第二碱基检出器1416输出包括p2(A)、p2(C)、p2(G)、p2(T)的置信度分数的第二碱基检出分类信息1436,并且也将碱基检出为C,仅作为一个示例。因此,在该示例中,来自两个碱基检出器的碱基检出相匹配并且是C。
在其中来自碱基检出器1414和1416两者的碱基检出相匹配的这种场景中,最终碱基检出1440包括与由碱基检出器1414和1416做出的碱基检出相匹配的最终被检出碱基检出。
在一个实施方案中,最终置信度分数pf(A)、pf(C)、pf(G)、pf(T)是由第一碱基检出器1414输出的置信度分数p1(A)、p1(C)、p1(G)、p1(T)和由第二碱基检出器1416输出的置信度分数p2(A)、p2(C)、p2(G)、p2(T)的适当函数。
例如,最终置信度分数pf(A)、pf(C)、pf(G)、pf(T)中的每一者可以是由第一碱基检出器1414输出的置信度分数p1(A)、p1(C)、p1(G)、p1(T)中的对应置信度分数和由第二碱基检出器1416输出的置信度分数p2(A)、p2(C)、p2(G)、p2(T)中的对应置信度分数的平均值或算术均值。因此,如果碱基检出器1414和1416两者都将所考虑的碱基检出为C,则碱基检出组合模块1428将最终被检出碱基输出为C,并且将最终置信度分数输出为:
pf(A)=(p1(A)和p2(A))的平均值,
pf(C)=(p1(C)和p2(C))的平均值,
pf(G)=(p1(G)和p2(G))的平均值,并且
pf(T)=(p1(T)和p2(T))的平均值。公式1
在另一个示例中,代替平均值或算术均值,可使用另一数学函数(诸如几何均值)。例如,如果使用几何均值,则公式1可被重写为:
并且
在另一个示例中,如果碱基检出系统1400想要报告保守分数,则最终置信度分数pf(A)、pf(C)、pf(G)、pf(T)中的每一者可以是由第一碱基检出器1414输出的置信度分数p1(A)、p1(C)、p1(G)、p1(T)中的对应置信度分数和由第二碱基检出器1416输出的置信度分数p2(A)、p2(C)、p2(G)、p2(T)中的对应置信度分数中的最小值(例如,假设两个碱基检出器的碱基检出相匹配)。因此,如果碱基检出器1414和1416两者都将所考虑的碱基检出为C,则碱基检出组合模块1428将最终被检出碱基输出为C,并且将最终置信度分数输出为:
pf(A)=(p1(A)和p2(A))的最小值,
pf(C)=(p1(C)和p2(C))的最小值,
pf(G)=(p1(G)和p2(G))的最小值,并且
pf(T)=(p1(T)和p2(T))的最小值。 公式2
在又一个示例中,如果碱基检出系统1400想要报告高置信度分数,则最终置信度分数pf(A)、pf(C)、pf(G)、pf(T)中的每一者可以是由第一碱基检出器1414输出的置信度分数p1(A)、p1(C)、p1(G)、p1(T)中的对应置信度分数和由第二碱基检出器1416输出的置信度分数p2(A)、p2(C)、p2(G)、p2(T)中的对应置信度分数中的最大值(例如,假设两个碱基检出器的碱基检出相匹配)。因此,如果碱基检出器1414和1416两者都将所考虑的碱基检出为C,则碱基检出组合模块1428将最终被检出碱基输出为C,并且将最终置信度分数输出为:
pf(A)=(p1(A)和p2(A))的最大值,
pf(C)=(p1(C)和p2(C))的最大值,
pf(G)=(p1(G)和p2(G))的最大值,并且
pf(T)=(p1(T)和p2(T))的最大值。公式3
在另一个示例中,如果碱基检出系统1400想要报告加权置信度分数,则最终置信度分数pf(A)、pf(C)、pf(G)、pf(T)中的每一者可以是由第一碱基检出器1414输出的置信度分数p1(A)、p1(C)、p1(G)、p1(T)中的对应置信度分数和由第二碱基检出器1416输出的置信度分数p2(A)、p2(C)、p2(G)、p2(T)中的对应置信度分数中的归一化加权和(例如,假设两个碱基检出器的碱基检出相匹配)。因此,如果碱基检出器1414和1416两者都将所考虑的碱基检出为C,则碱基检出组合模块1428将最终被检出碱基输出为C,并且将最终置信度分数输出为:
pf(A)=A1 x p1(A)+A2×p2(A),
pf(C)=A1 x p1(C)+A2×p2(C),
pf(G)=A1 x p1(G)+A2×p2(G),并且
pf(T)=A1 x p1(T)+A2×p2(T)。公式4
在一个示例中,公式4中的权重A1和A2是固定的、预先指定的权重,使得A1+A2=1。在一个示例中,权重A1和A2在训练过程期间例如基于训练数据来调整或更新。
基于与传感器数据相关联的时间上下文(例如,碱基检出循环数)的来自两个碱基
在一个示例中,碱基检出系统1400将最终置信度分数pf(A)、pf(C)、pf(G)、pf(T)中的每一者生成为由第一碱基检出器1414输出的置信度分数p1(A)、p1(C)、p1(G)、p1(T)中的每一者和由第二碱基检出器1416输出的置信度分数p2(A)、p2(C)、p2(G)、p2(T)中的对应置信度分数的加权平均值(例如,假设两个碱基检出器的碱基检出相匹配),其中权重是基于上下文信息1420。也就是说,上下文信息1420规定要给予来自两个碱基检出器的置信度分数中的各个置信度分数的权重。
图19A1示出了查找表(LUT)1901,该LUT基于时间上下文信息1606(参见图16)指示要用于最终置信度分数的示例性加权方案。LUT 1910中包括的实际权重仅仅是示例而非限制性的。
由于相对于图17C和图17D讨论的定相、预定相和衰落,已经观察到,在初始碱基检出循环期间,碱基检出器1414和1416两者的性能是可比较的(例如,参见图17D,该图示出了在初始碱基检出循环期间相对更好的信号质量和更少的噪声)。在稍后碱基检出循环期间,第一碱基检出器1414的表现优于第二碱基检出器1416,因为第一碱基检出器1414可被更好地装备以处理稍后碱基检出循环期间的信号衰退。然而,相比于第二碱基检出器1416的操作,第一碱基检出器1414操作起来可能是计算上密集的。
因此,在一个示例中并且如图19A1所示,在初始阈值数量个碱基检出循环期间,来自第二碱基检出器1416的置信度分数比来自第一碱基检出器1414的置信度分数更受重视。随着并且当碱基检出循环进展时,更加重视来自第一碱基检出器1414的置信度分数(例如,因为在稍后循环期间第一碱基检出器1414的表现优于第二碱基检出器1414)。
具体地,参考LUT 1901的第一行,假设存在N个碱基检出循环。对于碱基检出循环1-N1(即,初始N1个碱基检出循环),将高(例如,90-100%)权重给予来自第二碱基检出器1416的置信度分数,并且将低(例如,0-10%)权重给予来自第一碱基检出器1414的置信度分数。因此,在碱基检出循环1-N1期间,第一碱基检出器1414可被停用或不操作。由于第一碱基检出器1414操作起来是计算上密集的(例如,相比于第二碱基检出器1416的操作),这提高了计算效率。如所讨论的,在前N1个循环期间,两个碱基检出器具有可比较的性能,并且因此没有观察到碱基检出质量的衰退。
这里,N1是在1和N2(稍后讨论)之间的适当的碱基检出循环数。仅作为一个示例,N1可以是100、150、200、250或另一适当的碱基检出循环数。N1可被确定为初始碱基检出循环数,对于这些初始碱基检出循环,两个碱基检出器提供合理地可比较的碱基检出质量。
因此,例如,对于循环1和N1之间的碱基检出循环,最终碱基检出pf由下式给出(例如,假设将100%权重给予第二碱基检出器):
对于循环1至N1:pf(A)=p2(A);pf(C)=p2(C);pf(T)=p2(T);并且
pf(G)=p2(G)。 公式5
如所讨论的,对于至少初始N1个循环,第一碱基检出器1414可被停用(即,不对至少初始N1个循环的数据的对应集合操作)。需注意,第一碱基检出器1414将对从循环(N1+1)往前的数据的对应集合操作(参见LUT 1901的第二行)。为了令人满意地生成循环(N1+1)和后续循环的碱基检出,第一碱基检出器1414还必须在循环(N1+1)之前操作至少几个循环,例如,因为如相对于图7和图10所讨论的,当前循环的碱基检出也基于来自一个或多个过去循环和一个或多个未来循环的数据(还参见相对于图15E的讨论以供进一步解释)。因此,第一碱基检出器1414可不对循环1和循环(N1-T)之间的数据的对应集合操作,并且从循环(N1-T+1)开始操作。这里,T是从循环(N1+1)开始的需要对来自其的数据进行碱基检出的循环的阈值数量。
现在参考LUT 1901的第二行,在一个示例中,对于碱基检出循环(N1+1)至N2,将第一权重给予来自第二碱基检出器1416的置信度分数,并且将第二权重给予来自第一碱基检出器1414的置信度分数。在图19A1的示例中,第一权重和第二权重两者都是中等权重,诸如约50%,仅作为一个示例。因此,在这些循环期间,碱基检出器1414和1416两者都进行操作。因此,例如,对于循环N1+1和N2之间的碱基检出循环,最终分数pf由下式给出:
对于循环(N1+1)至N2:
pf(A)=0.5×p1(A)+0.5×p2(A);
pf(C)=0.5×p1(C)+0.5×p2(C);
pf(G)=0.5×p1(G)+0.5×p2(G);以及
pf(T)=0.5×p1(T)+0.5×p2(T)。公式6
现在参考LUT 1901的第三行,在一个示例中,对于碱基检出循环(N2+1)至N,将低(例如,0%)权重给予来自第二碱基检出器1416的置信度分数,并且将高(例如,100%)权重给予来自第一碱基检出器1414的置信度分数。这是因为,如本文所讨论的,在稍后碱基检出循环期间,第一碱基检出器1414的表现优于第二碱基检出器1416,因为第一碱基检出器1414可被更好地装备以处理稍后碱基检出循环期间的信号衰退(参见图17C、图17D)。
因此,例如,对于循环(N2+1)和N之间的碱基检出循环,最终分数pf由下式给出:
对于循环(N2+1)至N:
pf(A)=p2(A);
pf(C)=p2(C);
pf(T)=p2(T);以及
pf(G)=p2(G)。公式7
在一个示例中,LUT 1901(或本文所讨论的任何其他LUT)可保存在系统1400的存储器中(图14中未示出该存储器)。切换模块1422和/或碱基检出组合模块1428从存储器访问LUT 1901,并且接收指示当前碱基检出循环数的上下文信息1420(例如,时间上下文信息)。基于时间上下文信息,切换模块1422和/或碱基检出组合模块1428选择LUT 1901的适当行,并且根据在所选择的行中指定的权重进行操作。
基于指示特殊碱基序列的碱基序列上下文信息的置信度分数校正(其中来自两个
假设以下场景,其中来自两个碱基检出器的碱基检出相匹配,并且碱基序列上下文信息指示来自碱基检出器中的任一碱基检出器的被检出碱基包括特殊碱基序列,诸如均聚物(例如,GGGGG)、具有侧接均聚物的序列(例如,GGTGG)、近均聚物或另一特殊碱基序列。在一个示例中,由碱基检出组合模块1428(或碱基检出器1414、1416中的任一者)作出五个连贯最终碱基检出,并且这五个连贯最终碱基检出结果是包括特殊碱基序列。如本文先前所讨论的(参见图18),此类特殊碱基序列的错误概率可能更高。因此,系统1400可采取特殊措施来可能地修改与此类碱基序列的碱基相关联的置信度分数。同样需注意,本公开中讨论的特殊碱基序列的一些示例(诸如均聚物、近均聚物或具有侧接均聚物的序列)具有五个碱基。然而,在此类特殊碱基序列中可存在任何不同数量的碱基,诸如三个、五个、六个、七个、九个或另一适当数量。
图19B示出了指示当被检出碱基包括特殊碱基序列时要使用的碱基检出器的LUT1905。在LUT 1905中,字母“X”指示任何碱基,诸如A、C、T或G。因此,对于LUT 1905中包括的任何碱基序列(诸如GGXGG、GXGGG、GGGXG、GXXGG、GGXXG),将使用例如来自第二碱基检出器1416的置信度分数来确定最终置信度分数。这是因为通过发明人的实验已经确定,当遇到在LUT 1905中指示的任何特殊碱基序列时,第二碱基检出器1416的表现优于第一碱基检出器1414。
因此,如果由碱基检出组合模块1428作出的五个连贯最终碱基检出是LUT 1905的特殊碱基序列中的任一者,则碱基检出组合模块1428修改与五个碱基中的每一者(或至少一些,诸如中间碱基)相关联的置信度分数,以对应于由第二碱基检出器1416针对五个碱基输出的置信度分数。
在一个示例中,LUT 1905(或本文所讨论的任何其他LUT)可保存在系统1400的存储器中(图14中未示出该存储器)。切换模块1422和/或碱基检出组合模块1428从存储器访问LUT,并且接收上下文信息1420。基于上下文信息,切换模块1422和/或碱基检出组合模块1428选择LUT的适当行,并且根据所选择的行中指定的碱基检出操作进行操作。除非另外说明,否则这适用于本公开中讨论的所有LUT。
图19C示出了当被检出碱基包括特殊碱基序列时指示给予各个碱基检出器的置信度分数的权重的LUT 1910。需注意,LUT 1910中包括的实际权重仅仅是示例并且不限制本公开的范围。例如,参考LUT 1910的第一行,如果遇到特殊序列GGXGG,则可将60%权重给予来自第二碱基检出器1416的置信度分数,并且可将40%权重给予来自第一碱基检出器1414的置信度分数。例如,假设由“X”指示的序列的中间(即,第三)碱基是T,且第一碱基检出器1414指示置信度分数p1(T)并且第二碱基检出器1414指示置信度分数p2(T)。在这种示例中,最终被检出碱基是T,并且序列的中间(即,第三)碱基的最终置信度分数是:
pf(A)=0.6×p1(A)+0.4×p2(A),
pf(C)=0.6×p1(C)+0.4×p2(C),
pf(G)=0.6×p1(G)+0.4×p2(G),并且
pf(T)=0.6×p1(T)+0.4×p2(T)。公式8
在一个示例中,LUT 1910中的权重可通过测试和校准凭经验确定。
LUT 1910的其他行也可具有基于检测到的碱基序列的权重。这些权重可以是预先指定的,并且这些权重的最佳值可经由测试和校准来确定。
需注意,在LUT 1910中指定的所有示例性权重中,第二碱基检出器1416的权重高于第一碱基检出器1414的权重。这是因为,如上文所讨论的,在一些示例中,当遇到LUT中指示的特殊碱基序列中的任一者时,第二碱基检出器1416的表现可优于第一碱基检出器1414。
基于簇中气泡的检测生成最终分类信息
如本文先前所讨论的,在一个或多个碱基检出操作序列期间,在一个或多个簇上形成气泡。这种气泡可以是簇中存在的任何液体中的气体(诸如空气)的珠粒(诸如用于碱基检出的试剂内的气泡)。气泡的存在可基于分析从受影响的簇捕获的图像来检测。例如,簇内气泡的存在可通过在簇的所捕获图像中检测A唯一强度信号特征来估计。在一个示例中,其他上下文信息1610可指示来自簇的传感器数据的集合1601是否与这种气泡相关联。
图19D示出了根据在流通池的簇中检测到一个或多个气泡而指示图14的碱基检出组合模块1428的操作的LUT 1915。例如,参考LUT 1915的第一行,如果在流通池中未检测到气泡,则例如根据本文在本公开中讨论的任何适当的操作方案,由碱基检出组合模块1428正常地执行最终碱基检出。
参考LUT 1915的第二行,讨论了其中在流通池的簇中检测到一个或多个气泡的场景。一般地,第一碱基检出器1414被更好地装备以处理包括此类气泡的簇的碱基检出。因此,在一个实施方案中,响应于其他上下文信息1610(参见图16)指示簇中存在气泡,碱基检出组合模块1428将相对较高的权重(例如,90-100%权重)置于来自第一碱基检出器1414的置信度分数,并且将相对较低的权重(例如,0-10%权重)置于来自第二碱基检出器1416的置信度分数。
需注意,流通池的区块包括多个簇,并且例如在区块的单个簇中检测到气泡。因此,来自单个簇的传感器数据根据LUT 1915的第二行主要由第一碱基检出器1414来处理,而来自区块的其他簇的传感器数据根据LUT 1915的第一行由第一碱基检出器1414和/或第二碱基检出器1416来处理。
假设对于碱基检出循环1至Na,在簇中没有检测到气泡,并且在循环(Na+1)处,检测到簇包括气泡。因此,从碱基检出循环(Na+1)往前,根据LUT 1915的第二行,第一碱基检出器1414将处理来自簇的传感器数据。然而,假设在循环(Na+1)之前(即,从循环1至Na),第一碱基检出器1414不对来自簇的传感器数据操作,而第二碱基检出器1416对来自该簇的传感器数据操作。但为了使第一碱基检出器1414从簇(Na+1)开始检出碱基,第一碱基检出器1414也必须处理过去几个循环(例如,因为如相对于图7和图10所讨论的,当前循环的碱基检出也基于来自一个或多个过去循环和一个或多个未来循环的数据;还参见相对于图15E进行的讨论)。因此,响应于上下文信息指示在循环(Na+1)处存在气泡,第一碱基检出器处理在循环(Na+1)之前发生的几个循环的传感器数据(例如,处理循环Na、循环(Na-1)、循环(Na-2)、…、(Na-T)的传感器数据),并且基于处理此类过去循环,现在准备对(Na+1)处的循环进行处理和碱基检出。T是第一碱基检出器必须处理以正确地处理当前碱基检出循环的传感器数据的过去碱基检出循环的阈值数量。
基于簇中的失焦事件检测生成最终分类信息
如本文先前所讨论的,流通池1405可包括用于捕获各种簇的图像的透镜(诸如包括微透镜或其他光学部件的阵列的滤波器层124)。在一个示例中,当捕获图像时,例如当图像传感器或相机围绕流通池移动时,对于各种簇的聚焦可能略有差异。例如,当捕获簇的图像时,边缘簇1407a可相对于非边缘簇1407b略微失焦。由于透镜移动引起的加热或机械振动,也可能发生失焦事件。
图19D1示出了根据从流通池的簇检测到失焦图像而指示图14的碱基检出组合模块1428的操作的LUT 1917。例如,参考LUT 1917的第一行,如果针对流通池未检测到失焦图像,则例如根据本文在本公开中讨论的任何适当的操作方案,由碱基检出组合模块1428正常地执行最终碱基检出。
参考LUT 1917的第二行,讨论了其中从流通池的一个或多个簇检测到失焦图像的场景。一般地,第一碱基检出器1414被更好地装备以处理生成此类失焦图像的簇的碱基检出。因此,在一个实施方案中,响应于其他上下文信息1610(参见图16)指示来自簇的失焦图像的存在,碱基检出组合模块1428将相对较高的权重(例如,90-100%权重)置于来自第一碱基检出器1414的置信度分数,并且将相对较低的权重(例如,0-10%权重)置于来自第二碱基检出器1416的置信度分数。
需注意,流通池的区块包括多个簇,并且可在例如区块的单个簇或几个簇(但不是全部或甚至大多数簇)中检测到失焦图像。因此,来自具有失焦图像的一个或多个簇的传感器数据根据LUT 1915的第二行主要由第一碱基检出器1414来处理,而来自区块的其他簇的传感器数据根据LUT 1915的第一行由第一碱基检出器1414和/或第二碱基检出器1416来处理。
基于所使用的试剂的来自两个碱基检出器的置信度分数的归一化比率
试剂在碱基检出中起主要作用,如上文所讨论的。仅作为一个示例,当使用第一组试剂时,第一碱基检出器1414可比第二碱基检出器1416更适合,而当使用第二组试剂时,第一碱基检出器1414可比第二碱基检出器1416更不适合。在一个实施方案中,上下文信息1601指示所使用的试剂的类型,并且上下文信息生成模块1418可为来自两个碱基检出器的置信度分数指定归一化权重以用于确定最终置信度分数。
图19E示出了基于所使用的试剂组指示给予各个碱基检出器的置信度分数的权重的LUT 1920。例如,参考LUT 1920的第一行,当使用示例性试剂组A时,将A1%权重给予来自第一碱基检出器1414的置信度分数,并且将A2%权重给予来自第二碱基检出器1416的置信度分数,其中A1+A2=100。类似地,参考LUT 1920的第二行,当使用示例性试剂组B时,将B1%权重给予来自第一碱基检出器1414的置信度分数,并且将B2%权重给予来自第二碱基检出器1416的置信度分数,其中B1+B2=100。
在对数概率域中的来自两个碱基检出器的置信度分数的归一化比率
上文的各种示例和实施方案就概率而言讨论了置信度分数。然而,在一个实施方案中,可使用对数标度来表达置信度分数,并且可在使用对数标度表达置信度分数的情况下执行本文(例如,相对于公式1至8)所讨论的数学运算。例如,Phred质量分数是通过自动化DNA测序生成的核碱基的识别质量的量度。Phred质量分数Q被定义为如下与碱基检出概率P对数相关的属性:
Q=-10×log
因此,90%的碱基检出准确度(例如,p1(c)具有0.9的值)转化为10的对应Phred分数,99%的碱基检出准确度(例如,p1(c)具有0.99的值)转化为20的对应Phred分数,等等。这里,P是碱基检出概率,该碱基检出概率如下与错误概率E相关:P=(1-E)。因此,Phred质量分数Q如下与错误概率E相关:Q=-10*log
在一个实施方案中,本文(例如,相对于公式1至8)讨论的数学运算可使用Phred分数而不是置信度分数来执行。因此,在其中数学运算使用Phred或质量分数的一些示例中,对要使用的碱基检出器的选择可基于Phred或质量分数(例如,如相对于公式1至8所讨论的)。
基于与传感器数据相关联的空间上下文,例如边缘区块,生成来自两个碱基检出
如先前相对于图17A所讨论的,可基于区块的空间位置将一些区块分类为边缘区块。例如,在图17A中,与流通池1405的任何边缘相邻的区块被标记为边缘区块1406a,并且其余区块被标记为非边缘区块1406b。例如,在流通池1404的竖直边缘(例如,沿Y轴)和/或水平边缘(例如,沿X轴)上的区块被归类为边缘区块1406,如图14所示。因此,边缘区块1406与流通池1404的对应边缘紧邻。
同样如相对于图17A所讨论的,在一个示例中,与区块的碱基检出操作相关的参数可基于区块的相对位置。例如,相对于图1所讨论的激发光101被导向流通池的区块,并且例如,基于各个区块的位置和/或发射激发光101的一个或多个光源的位置,不同的区块可接收不同量的激发光101。例如,如果发射激发光101的光源垂直位于流通池上方,则非边缘区块1406b可接收与边缘区块1406a不同量的光。在另一个示例中,在流通池1405周围的周边或外部光(例如,来自生物传感器外部的环境光)可影响由流通池1405的各个区块接收的激发光101的量和/或特征。仅作为一个示例,边缘区块1406a可接收激发光101以及来自流通池1405外部的一定量的周边光,而非边缘区块1406b可主要接收激发光101。在又一个示例中,包括在流通池1405中的各个传感器(或像素或光电二极管)(例如,图1中示出的传感器106、108、110、112和114)可基于对应传感器的位置来感测光,对应传感器的位置基于对应区块的位置。例如,与周边光对与非边缘区块1406b相关联的一个或多个其他传感器的感测操作的影响相比,由与边缘区块1406a相关联的一个或多个传感器执行的感测操作可相对更多地受到周边光(以及激发光101)的影响。在又一个示例中,反应物(例如,其包括可用于在碱基检出期间获得期望反应的任何物质,诸如试剂、酶、样品、其他生物分子和缓冲溶液)向各种区块的流动也可能受到区块位置的影响。例如,靠近反应物的源的区块可比离源更远的区块接收更大量的反应物。
在一个示例中,与传感器数据的集合1601相关联空间上下文信息1604(参见图16)包括关于传感器数据的集合1601是在边缘区块1406a中还是在非边缘区块1406b中生成的信息。
图19F示出了根据区块的空间分类指示图14的碱基检出组合模块1428的操作的LUT 1925。例如,参考LUT 1925的第一行,对于非边缘区块,例如根据本文在本公开中讨论的任何适当的操作方案,由碱基检出组合模块1428正常地执行最终碱基检出。
参考LUT 1925的第二行,讨论了针对边缘区块的最终碱基检出的场景。一般地,如本文所讨论的,第一碱基检出器1414被更好地装备以处理边缘区块的碱基检出。因此,在一个实施方案中,对于边缘区块,碱基检出组合模块1428将E1权重置于来自第一碱基检出器1414的置信度分数,并且将E2权重置于来自第二碱基检出器1416的置信度分数,其中在一个示例中,E1高于E2,并且E1和E2的和是100%(即,权重被归一化)。
基于与传感器数据相关联的空间上下文,例如边缘簇,生成来自两个碱基检出器
如先前相对于图17B所讨论的,示例性区块1406的簇1407被归类为边缘簇1407a或非边缘簇1407b。同样如本文先前所讨论的,流通池1405可包括用于捕获各种簇的图像的透镜(诸如包括微透镜或其他光学部件的阵列的滤波器层124),并且当捕获簇的图像时,边缘簇1407a相对于非边缘簇1407b可略微失焦。因此,取决于具体实施,第一碱基检出器1414或第二碱基检出器1416中的一者可更适于处理来自边缘簇1407a的传感器数据,而第一碱基检出器1414或第二碱基检出器1416中的另一者可更适于处理来自非边缘簇1407b的传感器数据。在一个示例中,与传感器数据的集合1601相关联的空间上下文信息1604(参见图16)包括关于传感器数据的集合1601是从一个或多个边缘簇1407a还是一个或多个非边缘簇1407b生成的信息,基于该信息,可由第一碱基检出器1414或第二碱基检出器1416中的特定一者或两者处理传感器数据的集合1601。
图19G示出了根据簇的空间分类指示图14的碱基检出组合模块1428的操作的LUT1930。例如,参考LUT 1930的第一行,对于非边缘簇,例如根据本文在本公开中讨论的任何适当的操作方案,由碱基检出组合模块1428正常地执行最终碱基检出。
参考LUT 1930的第二行,讨论了针对边缘簇的最终碱基检出的场景。一般地,如本文所讨论的,第一碱基检出器1414可被更好地装备以处理边缘区块的碱基检出。因此,在一个实施方案中,对于边缘簇,碱基检出组合模块1428将C1权重置于来自第一碱基检出器1414的置信度分数,并且将C2权重置于来自第二碱基检出器1416的置信度分数,其中在一个示例中,C1高于C2,并且C1和C2的和是100%(即,权重被归一化)。在一个示例中,权重C1可高达100%,在这种情况下,来自第一碱基检出器1414的分类信息唯一地用于对边缘簇进行碱基检出。
当来自两个碱基检出器的分类信息不一致或不匹配时,降低最终置信度分数
如相对于图19A所讨论的,第一碱基检出器1414输出第一被检出碱基和第一置信度分数p1(A)、p1(C)、p1(G)、p1(T);并且第二碱基检出器1416输出第二被检出碱基和第二置信度分数p2(A)、p2(C)、p2(G)、p2(T)。在一个示例中,对于给定碱基,来自第一基检出器1414的第一被检出碱基可能与来自第二基检出器1416的第二被检出碱基不匹配。
例如,假设第一碱基检出器1414以置信度分数p1(A)检出碱基为A,并且第二碱基检出器1416以置信度分数p2(C)检出碱基为C。在这种场景中,由碱基检出组合模块1428输出的最终被检出碱基为:
如果p1(A)高于p2(C),则最终被检出碱基=A;或者
如果p1(A)低于p2(C),则最终被检出碱基=C。公式10
需注意,因为来自两个碱基检出器的两个碱基检出不一致,所以存在高错误概率。因此,可降低最终置信度分数。例如,假设p1(A)高于p2(C)(即,p1(A)>p2(C)),并且最终被检出碱基是A。则对应于A的最终置信度分数pf(A)为:
pf(A)=(p1(A)和p2(A))的下限。公式11
因此,由于两个碱基检出器对被检出碱基的不一致而人为地降低最终置信度分数。
在另一个示例中,如下降低最终置信度分数pf(A):
pf(A)=W1×p1(A),其中权重W1小于1。公式12
因此,由于两个碱基检出器对被检出碱基的不一致而使用小于1的适当权重W1来降低最终置信度分数。
当来自两个碱基检出器的分类信息不一致或不匹配时,连同特定上下文信息(诸
如上文所讨论的,第一碱基检出器1414输出第一被检出碱基和第一置信度分数p1(A)、p1(C)、p1(G)、p1(T);并且第二碱基检出器1416输出第二被检出碱基和第二置信度分数p2(A)、p2(C)、p2(G)、p2(T)。在一个示例中,对于给定碱基,来自第一基检出器1414的第一被检出碱基可能与来自第二基检出器1416的第二被检出碱基不匹配。
在一个实施方案中,如果来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基不匹配,并且这种不匹配还伴随有一个或多个特定上下文信息,则可针对最终被检出碱基将上下文信息考虑在内。
图20A示出了当(i)检测到特殊碱基序列并且(ii)来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基不匹配时指示图14的碱基检出组合模块1428的操作的LUT 2000。例如,参考LUT 2000的第一行,讨论了其中来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基相匹配并且检测到特殊碱基序列的场景,该特殊碱基序列诸如均聚物(例如,GGGGG)、具有侧接均聚物的序列、或近均聚物(诸如GGXGG)。此类特殊序列的进一步示例相对于图19B进行了讨论。因为来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基相匹配,最终被检出碱基将与来自第一碱基检出器和第二碱基检出器的被检出碱基相匹配,并且置信度分数可根据图19B和/或根据本文所讨论的任何适当操作方案来计算。如先前所述,本公开中讨论的特殊碱基序列的一些示例(诸如均聚物、近均聚物或具有侧接均聚物的序列)具有五个碱基。然而,在此类特殊碱基序列中可存在任何不同数量的碱基,诸如三个、五个、六个、七个、九个或另一适当数量。
现在参考LUT 2000的第二行,讨论了其中来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基不匹配并且检测到特殊碱基序列的场景,该特殊碱基序列诸如均聚物(例如,GGGGG)、具有侧接均聚物的序列、或近均聚物(诸如GGXGG)。此类特殊序列的进一步示例相对于图19B进行了讨论。因为来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基不匹配,最终被检出碱基基于来自第二碱基检出器1416的第二被检出碱基(例如,由于相对于图19B和图19C所讨论的原因,第二碱基检出器1416在这种特殊碱基序列的情况下更可靠)。最终被检出碱基的置信度分数例如可以是来自两个碱基检出器的对应置信度分数的最小值或平均值(或另一适当函数)。
当来自两个碱基检出器的分类信息不一致或不匹配时,连同特定上下文信息(诸
图20B示出了当(i)在簇中检测到气泡并且(ii)来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基不匹配时指示图14的碱基检出组合模块1428的操作的LUT 2005。
例如,参考LUT 2005的第一行,讨论了其中来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基相匹配并且在任何簇中未检测到气泡的场景。因此,根据本文所讨论的任何适当操作方案来执行最终碱基检出。
现在参考LUT 2005的第二行,讨论了其中(i)来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基不匹配并且(ii)在簇中检测到气泡的场景。因为来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基不匹配,最终被检出碱基基于来自第一碱基检出器1414的第一被检出碱基(例如,由于相对于图19D所讨论的原因,第一碱基检出器1414在气泡检测的情况下更可靠)。最终被检出碱基的置信度分数例如可以是来自两个碱基检出器的对应置信度分数的最小值或平均值(或另一适当函数)。
当来自两个碱基检出器的分类信息不一致或不匹配时,连同特定上下文信息(诸
图20C示出了当(i)从至少一个簇检测到一个或多个失焦图像并且(ii)来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基不匹配时指示图14的碱基检出组合模块1428的操作的LUT 2010。
例如,参考LUT 2010的第一行,讨论了其中来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基相匹配并且在任何簇中未检测到失焦图像的场景。因此,根据本文所讨论的任何适当操作方案来执行最终碱基检出。
现在参考LUT 2010的第二行,讨论了其中(i)来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基不匹配并且(ii)从至少一个簇检测到一个或多个失焦图像的场景。因为来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基不匹配,最终被检出碱基基于来自第一碱基检出器1414的第一被检出碱基(例如,由于相对于图19D1所讨论的原因,第一碱基检出器1414在失焦图像检测的情况下更可靠)。最终被检出碱基的置信度分数例如可以是来自两个碱基检出器的对应置信度分数的最小值或平均值(或另一适当函数)。
当来自两个碱基检出器的分类信息不一致或不匹配时,连同特定上下文信息(诸
图20D示出了当(i)传感器数据来自边缘簇并且(ii)来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基不匹配时指示图14的碱基检出组合模块1428的操作的LUT 2015。
例如,参考LUT 2015的第一行,讨论了其中来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基相匹配并且传感器数据的集合来自边缘簇的场景。因此,根据本文所讨论的任何适当操作方案(诸如相对于图19G所讨论的方案)来执行最终碱基检出。
现在参考LUT 2015的第二行,讨论了其中(i)来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基不匹配并且(ii)传感器数据来自边缘簇的场景。因为来自第一碱基检出器1414的第一被检出碱基与来自第二碱基检出器1416的第二被检出碱基不匹配,最终被检出碱基基于来自第一碱基检出器1414的第一被检出碱基(例如,由于相对于图19G所讨论的原因,第一碱基检出器1414在边缘簇的情况下更可靠)。最终被检出碱基的置信度分数例如可以是来自两个碱基检出器的对应置信度分数的最小值或平均值(或另一适当函数)。
潜在的不可靠置信度分数的检测,以及基于这种检测在碱基检出器之间进行的选
如本文相对于图19B和图19C所讨论的,对于一些特定的所检测的碱基序列,第一碱基检出器1414的表现可能不令人满意地(例如,相对于第二碱基检出器),例如,当检出均聚物(例如,GGGGG)、具有侧接均聚物的序列、或近均聚物(例如,GGTGG)时。在一个实施方案中,对于一些这样的序列,第一碱基检出器1414可针对其被检出碱基生成高置信度分数,尽管此类高置信度分数可能高于被检出碱基的真实置信度。因此,例如,当第一碱基检出器1414针对均聚物、或具有侧接均聚物的序列、或近均聚物检出此类相对高的置信度分数(例如,高于阈值)时,此类高置信度分数可能是不可靠的。在一些这样的场景中,可使用来自第二碱基检出器1416的置信度分数。
在一个示例中,对于均聚物、具有侧接均聚物的序列或近均聚物,可改变与序列的中间或第三被检出碱基相关联的置信度分数p1(A)、p1(C)、p1(G)、p1(T)。例如,假设对于具有侧接均聚物的序列(例如,GGTGG),第一碱基检出器1414以某些置信度分数检出第三碱基,其中第三碱基为T的置信度分数是相对高的(例如,高于阈值)。因此,来自第二碱基检出器1416的置信度分数p2(A)、p2(C)、p2(G)、p2(T)可用于具有侧接均聚物的5碱基序列或近均聚物的第三碱基,并且可用于确定最终置信度分数。
当来自两个碱基检出器的分类信息不一致或不匹配时,最终碱基检出包括不确定
在一个示例中,当来自两个碱基检出器的分类信息不一致或不匹配时,最终碱基检出1440可包括不确定的碱基检出和对应的置信度分数。例如,可使用本文所讨论的任何方法来生成各种碱基的最终置信度分数,诸如最小值、平均值、最大值或归一化加权置信度分数,并且最终碱基检出可被指示为不确定的。
例如,假设对于给定待检出碱基,第一碱基检出分类信息1434包括置信度分数p1(A)、p1(C)、p1(G)、p1(T)和第一被检出碱基A(例如,因为p1(A)高于p1(C)、p1(G)、p1(T)中的每一者)。还假设对于给定待检出碱基,第二碱基检出分类信息1436包括置信度分数p2(A)、p2(C)、p2(G)、p2(T)和第二被检出碱基C(例如,因为p2(C)高于p2(A)、p2(G)、p2(T)中的每一者)。由于两个碱基检出不匹配,最终碱基检出是“N”,其中在一个示例中,“N”表示不确定的碱基检出。在另一个示例中并且针对本文所讨论的特定用例,“N”可表示碱基A或C中的任一者(即,由两个碱基检出器输出的第一碱基检出和第二碱基检出)。最终碱基检出N可附带有最终置信度分数,这些最终置信度分数可使用本文早先讨论的公式1至8中的任一公式来计算。
基于神经网络的最终碱基检出确定模块
图21示出了包括多个碱基检出器以预测包括碱基序列的未知分析物的碱基检出的碱基检出系统2100,其中基于神经网络的最终碱基检出确定模块2128基于该多个碱基检出器中的一个或多个碱基检出器的输出来确定最终碱基检出1440。在一个示例中,最终碱基检出确定模块2128考虑上下文信息和其他变量(例如,如相对于图19A所讨论的)来确定如何组合第一碱基检出分类信息1434和第二碱基检出分类信息1436以生成最终碱基检出1440。系统2100至少部分地类似于图14的系统1400。然而,在图21的系统2100中,图14的上下文信息生成模块1418和碱基检出组合模块1428被替换成最终碱基检出确定模块2128。
在一个示例中,最终碱基检出确定模块2128是已经使用来自两个碱基检出器1414和1416的输出训练的基于神经网络的模块。经训练最终基检出确定模块2128随后用于碱基检出。最终碱基检出确定模块2128的训练可基于本文所讨论的一个或多个最终碱基检出确定操作。图21的系统2100的操作将基于相对于图14进行的讨论以及本文呈现的关于最终碱基检出确定的进一步讨论而显而易见。在其他示例中,最终碱基检出确定模块2128可以是另一适当机器学习模型,诸如逻辑回归模型、梯度提升树模型、随机森林模型、朴素贝叶斯模型等。在一个示例中,最终碱基检出确定模块2128可以是可组合两个分类分数以生成最终碱基检出1440的任何适当机器学习模型。
权重估计
本文已经在整个公开中讨论了各种权重,其中这些权重用于在生成最终分类信息时对第一分类信息1434和第二分类信息1436进行加权。可采用各种技术来生成权重。
在一个示例中,图21的最终碱基检出确定模块2128的经训练神经网络模型可用于微调权重。在另一个示例中,还可使用试误法或另一适当方法凭经验确定权重。在又一个示例中,可凭经验估计置信度分数的预测协方差矩阵并且用其估计权重。
碱基检出系统架构
图22是根据一个具体实施的碱基检出系统2200的框图。碱基检出系统2200可操作以获得与生物物质或化学物质中的至少一者相关的任何信息或数据。在一些具体实施中,碱基检出系统2200是可类似于台式设备或台式计算机的工作站。例如,用于进行所需反应的大多数(或全部)系统和部件可位于共同的外壳2216内。
在特定具体实施中,碱基检出系统2200是被配置用于各种应用的核酸测序系统(或测序仪),各种应用包括但不限于从头测序、全基因组或靶基因组区域的重测序以及宏基因组学。测序仪也可用于DNA或RNA分析。在一些具体实施中,碱基检出系统2200还可被配置为在生物传感器中生成反应位点。例如,碱基检出系统2200可被配置为接收样品并且生成来源于样品的克隆扩增核酸的表面附着簇。每个簇可构成生物传感器中的反应位点或作为其一部分。示例性碱基检出系统2200可包括被配置为与生物传感器2202相互作用以在生物传感器2202内执行所需反应的系统插座或接口2212。在以下相对于图22的描述中,将生物传感器2202加载到系统插座2212中。然而,应当理解,可将包括生物传感器2202的卡盒插入到系统插座2212中,并且在一些状态下,可暂时或永久地移除卡盒。如上所述,除了别的以外,卡盒还可包括流体控制部件和流体储存部件。
在特定具体实施中,碱基检出系统2200被配置为在生物传感器2202内执行大量平行反应。生物传感器2202包括可发生所需反应的一个或多个反应位点。反应位点可例如固定至生物传感器的固体表面或固定至位于生物传感器的对应反应室内的小珠(或其他可移动基板)。反应位点可包括,例如,克隆扩增核酸的簇。生物传感器2202可包括固态成像设备(例如,CCD或CMOS成像器件)和安装到其上的流通池。流通池可包括一个或多个流动通道,该一个或多个流动通道从碱基检出系统2200接收溶液并且将溶液引向反应位点。任选地,生物传感器2202可被配置为接合热元件,以用于将热能传递到流动通道中或从流动通道传递出去。
碱基检出系统2200可包括彼此相互作用以执行用于生物或化学分析的预先确定的方法或测定协议的各种部件、组件和系统(或子系统)。例如,碱基检出系统2200包括系统控制器2204,该系统控制器可与碱基检出系统2200的各种部件、组件和子系统以及生物传感器2202通信。例如,除系统插座2212之外,碱基检出系统2200还可包括:流体控制系统2206,该流体控制系统用于控制流体在碱基检出系统2200和生物传感器2202的整个流体网络中的流动;流体储存系统2208,该流体储存系统被配置为保持生物测定系统可使用的所有流体(例如,气体或液体);温度控制系统2210,该温度控制系统可调节流体网络、流体储存系统2208和/或生物传感器2202中的流体的温度;和照明系统2209,该照射系统被配置为给生物传感器2202照明。如上所述,如果将具有生物传感器2202的卡盒装载到系统插座2212中,则该卡盒还可包括流体控制部件和流体储存部件。
同样如图所示,碱基检出系统2200可包括与用户交互的用户界面2214。例如,用户界面2214可包括用于显示或请求来自用户的信息的显示器2213和用于接收用户输入的用户输入设备2215。在一些具体实施中,显示器2213和用户输入设备2215为同一设备。例如,用户界面2214可包括触敏显示器,该触敏显示器被配置为检测个体触摸的存在并且还识别触摸在显示器上的位置。然而,可使用其他用户输入设备2215,诸如鼠标、触摸板、键盘、小键盘、手持扫描仪、语音辨识系统、运动辨识系统等。如将在下文更详细地讨论,碱基检出系统2200可与包括生物传感器2202(例如,呈卡盒的形式)的各种部件通信,以执行所需反应。碱基检出系统2200还可被配置为分析从生物传感器获得的数据以向用户提供所需信息。
系统控制器2204可包括任何基于处理器或基于微处理器的系统,包括使用微控制器、精简指令集计算机(RISC)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)、逻辑电路以及能够执行本文所述功能的任何其他电路或处理器。上述示例仅是示例性的,因此不旨在以任何方式限制术语系统控制器的定义和/或含义。在示例性具体实施中,系统控制器2204执行存储在一个或多个存储元件、存储器或模块中的指令集,以便进行获得检测数据和分析检测数据中的至少一者。检测数据可包括多个像素信号序列,使得可在许多碱基检出循环内检测来自数百万个传感器(或像素)中的每一个传感器(或像素)的像素信号序列。存储元件可呈碱基检出系统2200内的信息源或物理存储器元件的形式。
指令集可包括指示碱基检出系统2200或生物传感器2202执行特定操作(诸如本文所述的各种具体实施的方法和过程)的各种命令。指令集可为软件程序的形式,该软件程序可形成有形的一个或多个非暂态计算机可读介质的一部分。如本文所用,术语“软件”和“固件”是可互换的,并且包括存储在存储器中以供计算机执行的任何计算机程序,包括RAM存储器、ROM存储器、EPROM存储器、EEPROM存储器和非易失性RAM(NVRAM)存储器。上述存储器类型仅是示例性的,因此不限制可用于存储计算机程序的存储器类型。
软件可为各种形式,诸如系统软件或应用软件。此外,软件可以是独立程序的集合的形式,或者是较大程序内的程序模块或程序模块的一部分的形式。软件还可包括面向对象编程形式的模块化编程。在获得检测数据之后,检测数据可由碱基检出系统2200自动处理,响应于用户输入而处理,或者响应于另一个处理机器提出的请求(例如,通过通信链路的远程请求)而处理。在例示的具体实施中,系统控制器2204包括分析模块2338(在图23中示出)。在其他具体实施中,系统控制器2204不包括分析模块2338,而是可访问分析模块2338(例如,分析模块2338可单独地托管在云上)。
系统控制器2204可经由通信链路连接到生物传感器2202和碱基检出系统2200的其他部件。系统控制器2204还可通信地连接到非现场系统或服务器。通信链路可以是硬连线的、有线的或无线的。系统控制器2204可从用户界面2214和用户输入设备2215接收用户输入或命令。
流体控制系统2206包括流体网络,并且被配置为引导和调节一种或多种流体通过流体网络的流动。流体网络可与生物传感器2202和流体储存系统2208流体连通。例如,选定的流体可从流体储存系统2208抽吸并且以受控方式引导至生物传感器2202,或者流体可从生物传感器2202抽吸并且朝向例如流体储存系统2208中的废物贮存器引导。尽管未示出,但流体控制系统2206可包括检测流体网络内的流体的流速或压力的流量传感器。传感器可与系统控制器2204通信。
温度控制系统2210被配置为调节流体网络、流体储存系统2208和/或生物传感器2202的不同区域处流体的温度。例如,温度控制系统2210可包括热循环仪,该热循环仪与生物传感器2202对接并且控制沿着生物传感器2202中的反应位点流动的流体的温度。温度控制系统2210还可调节碱基检出系统2200或生物传感器2202的固体元件或部件的温度。尽管未示出,但温度控制系统2210可包括用于检测流体或其他部件的温度的传感器。传感器可与系统控制器2204通信。
流体储存系统2208与生物传感器2202流体连通,并且可储存用于在其中进行所需反应的各种反应组分或反应物。流体储存系统2208还可储存用于洗涤或清洁流体网络和生物传感器2202以及用于稀释反应物的流体。例如,流体储存系统2208可包括各种贮存器,以储存样品、试剂、酶、其他生物分子、缓冲溶液、水性溶液和非极性溶液等。此外,流体储存系统2208还可包括用于接收来自生物传感器2202的废物的废物贮存器。在包括卡盒的具体实施中,卡盒可包括流体储存系统、流体控制系统或温度控制系统中的一者或多者。因此,本文所述的与那些系统有关的一个或多个部件可容纳在卡盒外壳内。例如,卡盒可具有各种贮存器,以储存样品、试剂、酶、其他生物分子、缓冲溶液、水性溶液和非极性溶液、废物等。因此,流体储存系统、流体控制系统或温度控制系统中的一者或多者可经由卡盒或其他生物传感器与生物测定系统可移除地接合。
照明系统2209可包括光源(例如,一个或多个LED)和用于给生物传感器照明的多个光学部件。光源的示例可包括激光器、弧光灯、LED或激光二极管。光学部件可以是例如反射器、二向色镜、分束器、准直器、透镜、滤光器、楔镜、棱镜、反射镜、检测器等。在使用照明系统的具体实施中,照明系统2209可被配置为将激发光引导至反应位点。作为一个示例,荧光团可由绿色波长的光激发,因此激发光的波长可为大约532nm。在一个具体实施中,照明系统2209被配置为产生平行于生物传感器2202的表面的表面法线的照明。在另一具体实施中,照明系统2209被配置为产生相对于生物传感器2202的表面的表面法线成偏角的照明。在又一具体实施中,照明系统2209被配置为产生具有多个角度的照明,包括一些平行照明和一些偏角照明。系统插座或接口2212被配置为以机械、电气和流体方式中的至少一种方式接合生物传感器2202。系统插座2212可将生物传感器2202保持在所需取向,以有利于流体流过生物传感器2202。系统插座2212还可包括电触点,这些电触点被配置为接合生物传感器2202,使得碱基检出系统2200可与生物传感器2202通信和/或向生物传感器2202提供功率。此外,系统插座2212可包括被配置为接合生物传感器2202的流体端口(例如,喷嘴)。在一些具体实施中,生物传感器2202以机械方式、电气方式以及流体方式可移除地耦接到系统插座2212。
此外,碱基检出系统2200可与其他系统或网络或与其他生物测定系统2200远程通信。由生物测定系统2200获得的检测数据可存储在远程数据库中。
图23是可在图22的系统中使用的系统控制器2204的框图。在一个具体实施中,系统控制器2204包括可彼此通信的一个或多个处理器或模块。这些处理器或模块中的每一者可包括用于执行特定过程的算法(例如,存储在有形和/或非暂态计算机可读存储介质上的指令)或子算法。系统控制器2204在概念上被示出为模块的集合,但可利用专用硬件板、DSP、处理器等的任何组合来实现。另选地,系统控制器2204可利用具有单个处理器或多个处理器的现成PC来实现,其中功能操作分布在处理器之间。作为进一步的选择,下文所述的模块可利用混合配置来实现,其中某些模块化功能利用专用硬件来执行,而其余模块化功能利用现成PC等来执行。模块还可被实现为处理单元内的软件模块。
在操作期间,通信端口2320可向生物传感器2202(图22)和/或子系统2206、2208、2210(图22)传输信息(例如,命令)或从其接收信息(例如,数据)。在具体实施中,通信端口2320可输出多个像素信号序列。通信端口2320可从用户界面2214(图22)接收用户输入并且将数据或信息传输到用户界面2214。来自生物传感器2202或子系统2206、2208、2210的数据可在生物测定会话期间由系统控制器2204实时处理。除此之外或另选地,数据可在生物测定会话期间临时存储在系统存储器中,并且以比实时或脱机操作更慢的速度进行处理。
如图23所示,系统控制器2204可包括与主控制模块2330通信的多个模块2331-2339。主控制模块2330可与用户界面2214(图22)通信。尽管模块2331-2339被示出为与主控制模块2330直接通信,但模块2331-2339也可彼此直接通信,与用户界面2214和生物传感器2202直接通信。另外,模块2331-2339可通过其他模块与主控制模块2330通信。
多个模块2331-2339包括分别与子系统2206、2208、2210和2209通信的系统模块2331-2333、2339。流体控制模块2331可与流体控制系统2206通信,以控制流体网络的阀和流量传感器,从而控制一种或多种流体通过流体网络的流动。流体储存模块2332可在流体量低时或在废物贮存器处于或接近容量时通知用户。流体储存模块2332还可与温度控制模块2333通信,使得流体可储存在所需温度下。照明模块2339可与照明系统2209通信,以在协议期间的指定时间给反应位点照明,诸如在已发生所需反应(例如,结合事件)之后。在一些具体实施中,照明模块2339可与照明系统2209通信,从而以指定角度给反应位点照明。
多个模块2331-2339还可包括与生物传感器2202通信的设备模块2334和确定与生物传感器2202相关的识别信息的识别模块2335。设备模块2334可例如与系统插座2212通信以确认生物传感器已与碱基检出系统2200建立电气连接和流体连接。识别模块2335可接收识别生物传感器2202的信号。识别模块2335可使用生物传感器2202的身份来向用户提供其他信息。例如,识别模块2335可确定并随后显示批号、制造日期或建议与生物传感器2202一起运行的协议。
多个模块2331-2339还包括接收和分析来自生物传感器2202的信号数据(例如,图像数据)的分析模块2338(也称为信号处理模块或信号处理器)。分析模块2338包括用于存储检测数据的存储器(例如,RAM或闪存)。检测数据可包括多个像素信号序列,使得可在许多碱基检出循环内检测来自数百万个传感器(或像素)中的每一个传感器(或像素)的像素信号序列。信号数据可被存储用于后续分析,或者可被传输到用户界面2214以向用户显示所需信息。在一些具体实施中,信号数据可在分析模块2338接收信号数据之前由固态成像器件(例如,CMOS图像传感器)处理。
分析模块2338被配置为在多个测序循环的每个测序循环处从光检测器获得图像数据。图像数据来源于由光检测器检测到的发射信号,并且通过神经网络(例如,基于神经网络的模板生成器2348、基于神经网络的碱基检出器2358(例如,参见图7、图9和图10)和/或基于神经网络的质量评分器2368)处理该多个测序循环中的每个测序循环的图像数据,并且在该多个测序循环中的每个测序循环处针对分析物中的至少一些产生碱基检出。
协议模块2336和协议模块2337与主控制模块2330通信,以在进行预先确定的测定协议时控制子系统2206、2208和2210的操作。协议模块2336和2337可包括用于指示碱基检出系统2200根据预先确定的协议执行特定操作的指令集。如图所示,协议模块可以是边合成边测序(SBS)模块2336,该模块被配置为发出
用于执行边合成边测序过程的各种命令。在SBS中,监测核酸引物沿核酸模板的延伸,以确定模板中核苷酸的序列。基础化学过程可以是聚合(例如,由聚合酶催化)或连接(例如,由连接酶催化)。在特定的基于聚合酶的SBS具体实施中,以依赖于模板的方式将荧光标记的核苷酸添加至引物(从而使引物延伸),使得对添加至引物的核苷酸的顺序和类型的检测可用于确定模板的序列。例如,为了启动第一SBS循环,可发出命令以将一个或多个标记的核苷酸、DNA聚合酶等递送至/通过容纳有核酸模板阵列的流通池。核酸模板可位于对应的反应位点。其中引物延伸导致标记的核苷酸掺入的那些反应位点可通过成像事件来检测。在成像事件期间,照明系统2209可向反应位点提供激发光。任选地,核苷酸还可以包括一旦将核苷酸添加到引物就终止进一步的引物延伸的可逆终止属性。例如,可将具有可逆终止子部分的核苷酸类似物添加到引物,使得在递送去封闭剂以除去该部分之前不会发生后续延伸。因此,对于使用可逆终止的具体实施,可给出将去封闭试剂递送至流通池的命令(在检测发生之前或之后)。可发出一个或多个命令以实现各个递送步骤之间的洗涤。然后可重复该循环n次,以将引物延伸n个核苷酸,从而检测长度为n的序列。示例性测序技术描述于:例如Bentley等人,Nature 456:53-59(2008)、WO 04/018497、US 7,057,026、WO91/06678、WO 07/123744、US 7,329,492、US 7,211,414、US 7,315,019和US 7,405,281中,这些文献中的每一篇以引用方式并入本文。
对于SBS循环的核苷酸递送步骤,可一次递送单一类型的核苷酸,或者可递送多种不同的核苷酸类型(例如,A、C、T和G一起)。对于一次仅存在单一类型的核苷酸的核苷酸递送构型,不同的核苷酸不需要具有不同的标记,因为它们可基于个体化递送中固有的时间间隔来区分。因此,测序方法或装置可使用单色检测。例如,激发源仅需要提供单个波长或单个波长范围内的激发。对于其中递送导致多种不同核苷酸同时存在于流通池中的核苷酸递送构型,可基于附着到混合物中相应核苷酸类型的不同荧光标记来区分掺入不同核苷酸类型的位点。例如,可使用四种不同的核苷酸,每种核苷酸具有四种不同荧光团中的一种。在一个具体实施中,可使用在光谱的四个不同区域中的激发来区分四种不同的荧光团。例如,可使用四种不同的激发辐射源。另选地,可使用少于四种不同的激发源,但来自单个源的激发辐射的光学过滤可用于在流通池处产生不同范围的激发辐射。
在一些具体实施中,可在具有四种不同核苷酸的混合物中检测到少于四种不同颜色。例如,核苷酸对可在相同波长下检测,但基于对中的一个成员相对于另一个成员的强度差异,或基于对中的一个成员的导致与检测到的该对的另一个成员的信号相比明显的信号出现或消失的变化(例如,经由化学改性、光化学改性或物理改性)来区分。用于使用少于四种颜色的检测来区分四个不同核苷酸的示例性装置和方法描述于例如美国专利申请序列号61/538,294和61/619,878,这些专利申请全文以引用方式并入本文。2012年9月21日提交的美国申请号13/624,200也全文以引用方式并入。
多个协议模块还可包括样品制备(或生成)模块2337,该模块被配置为向流体控制系统2206和温度控制系统2210发出命令,以扩增生物传感器2202内的产物。例如,生物传感器2202可接合至碱基检出系统2200。扩增模块2337可向流体控制系统2206发出指令,以将必要的扩增组分递送至生物传感器2202内的反应室。在其他具体实施中,反应位点可能已包含一些用于扩增的组分,诸如模板DNA和/或引物。在将扩增组分递送至反应室之后,扩增模块2337可指示温度控制系统2210根据已知的扩增协议循环通过不同的温度阶段。在一些具体实施中,扩增和/或核苷酸掺入等温进行。
SBS模块2336可发出命令以执行桥式PCR,其中克隆扩增子的簇形成于流通池的通道内的局部区域上。通过桥式PCR产生扩增子后,可将扩增子“线性化”以制备单链模板DNA或sstDNA,并且可将测序引物杂交至侧接感兴趣的区域的通用序列。例如,可如上所述或如下使用基于可逆终止子的边合成边测序方法。
每个碱基检出或测序循环可通过单个碱基延伸sstDNA,这可例如通过使用经修饰的DNA聚合酶和四种类型的核苷酸的混合物来完成。不同类型的核苷酸可具有独特的荧光标记,并且每个核苷酸还可具有可逆终止子,该可逆终止子仅允许在每个循环中发生单碱基掺入。在将单个碱基添加到sstDNA之后,激发光可入射到反应位点上并且可检测荧光发射。在检测后,可从sstDNA化学切割荧光标记和终止子。接下来可为另一个类似的碱基检出或测序循环。在这种测序协议中,SBS模块2336可指示流体控制系统2206引导试剂和酶溶液流过生物传感器2202。可与本文所阐述的装置和方法一起使用的基于可逆终止子的示例性SBS方法描述于美国专利申请公布号2007/0166705A1、美国专利申请公布号2006/0188901A1、美国专利号7,057,026、美国专利申请公布号2006/0240439A1、美国专利申请公布号2006/02814714709A1、PCT公布号WO 05/065814、PCT公布号WO 06/064199,这些专利中的每一篇均全文以引用方式并入本文。US 7,541,444;US 7,057,026;US 7,427,673;US 7,566,537;以及US 7,592,435中描述了基于可逆终止子的SBS的示例性试剂,这些专利中的每一篇均全文以引用方式并入本文。
在一些具体实施中,扩增模块和SBS模块可在单个测定协议中操作,其中例如扩增模板核酸并随后将其在同一盒内测序。
碱基检出系统2200还可允许用户重新配置测定协议。例如,碱基检出系统2200可通过用户界面2214向用户提供用于修改所确定的协议的选项。例如,如果确定生物传感器2202将用于扩增,则碱基检出系统2200可请求退火循环的温度。
此外,如果用户已提供对于所选择的测定协议通常不可接受的用户输入,则碱基检出系统2200可向用户发出警告。
在具体实施中,生物传感器2202包括数百万个传感器(或像素),每个传感器(或像素)在后续碱基检出循环内生成多个像素信号序列。分析模块2338根据传感器阵列上传感器的逐行和/或逐列位置来检测多个像素信号序列并将它们归属于对应的传感器(或像素)。
传感器阵列中的每个传感器可产生流通池的区块的传感器数据,其中区块位于流通池上的在碱基检出操作期间设置遗传物质的簇的区域中。传感器数据可包括像素阵列中的图像数据。对于给定循环,传感器数据可包括多于一个图像,从而产生多特征每像素作为区块数据。
图24是可用于实现所公开的技术的计算机系统2400的简化框图。计算机系统2400包括经由总线子系统2455与多个外围设备通信的至少一个中央处理单元(CPU)2472。这些外围设备可包括存储子系统2410(包括例如存储器设备和文件存储子系统2436)、用户界面输入设备2438、用户界面输出设备2476和网络接口子系统2474。输入设备和输出设备允许用户与计算机系统2400进行交互。网络接口子系统2474提供通向外部网络的接口,该接口包括通向其他计算机系统中的对应接口设备的接口。
用户界面输入设备2438可包括:键盘;指向设备,诸如鼠标、轨迹球、触摸板或图形输入板;扫描仪;结合到显示器中的触摸屏;音频输入设备,诸如语音辨识系统和麦克风;以及其他类型的输入设备。一般来讲,使用术语“输入设备”旨在包括将信息输入到计算机系统2400中的所有可能类型的设备和方式。
用户界面输出设备2476可包括显示子系统、打印机、传真机或非视觉显示器(诸如音频输出设备)。显示子系统可包括LED显示器、阴极射线管(CRT)、平板设备诸如液晶显示器(LCD)、投影设备或用于产生可见图像的一些其他机构。显示子系统还可提供非视觉显示器,诸如音频输出设备。一般来讲,使用术语“输出设备”旨在包括将信息从计算机系统2400输出到用户或者输出到另一机器或计算机系统的所有可能类型的设备和方式。
存储子系统2410存储提供本文所述的一些或全部模块和方法的功能的编程结构和数据结构。这些软件模块通常由深度学习处理器2478执行。
在一个具体实施中,神经网络使用深度学习处理器2478来实现,这些深度学习处理器可以是可配置和可重新配置处理器、现场可编程门阵列(FPGA)、专用集成电路(ASIC)和/或粗粒度可重构架构(CGRA)和图形处理单元(GPU)、其他配置的设备。深度学习处理器2478可由深度学习云平台诸如Google Cloud Platform
在存储子系统2410中使用的存储器子系统2422可包括多个存储器,包括用于在程序执行期间存储指令和数据的主随机存取存储器(RAM)2434和其中存储固定指令的只读存储器(ROM)2432。文件存储子系统2436可为程序文件和数据文件提供持久性存储,并且可包括硬盘驱动器、软盘驱动器以及相关联的可移动介质、CD-ROM驱动器、光盘驱动器或可移动介质磁盘盒。实现某些具体实施的功能的模块可由文件存储子系统2436存储在存储子系统2410中,或者存储在处理器可访问的其他机器中。
总线子系统2455提供用于使计算机系统2400的各种部件和子系统按照预期彼此通信的机构。尽管总线子系统2455被示意性地示出为单条总线,但是该总线子系统的替代性具体实施可使用多条总线。
计算机系统2400本身可具有不同类型,包括个人计算机、便携式计算机、工作站、计算机终端、网络计算机、电视机、主机、服务器群、一组广泛分布的松散联网的计算机,或者任何其他数据处理系统或用户设备。由于计算机和网络的不断变化的性质,对图23中描绘的计算机系统2400的描述仅旨在作为用于示出本发明的优选具体实施的具体示例。计算机系统2400的许多其他配置是可能的,其具有比图23中描绘的计算机系统更多或更少的部件。
条款
条款集1(根据两个碱基检出器的分类信息生成最终分类)
1.一种用于使用至少两个碱基检出器进行碱基检出的计算机实现的方法,该方法包括:
对针对一系列感测循环中的感测循环生成的传感器数据执行至少第一碱基检出器和第二碱基检出器;
基于对该传感器数据执行该第一碱基检出器,由该第一碱基检出器生成与该传感器数据相关联的第一分类信息;
基于对该传感器数据执行该第二碱基检出器,由该第二碱基检出器生成与该传感器数据相关联的第二分类信息;以及
基于该第一分类信息和该第二分类信息,生成最终分类信息,该最终分类信息包括该传感器数据的一个或多个碱基检出。
2.根据条款要求1所述的方法,其中该第一碱基检出器和该第二碱基检出器中的至少一者实现非线性函数,并且其中该第一碱基检出器和该第二碱基检出器中的至少另一者至少部分地是线性的。
3.根据条款1所述的方法,其中该第一碱基检出器和该第二碱基检出器中的至少一者实现神经网络模型,而该第一碱基检出器和该第二碱基检出器中的至少另一者不包括神经网络模型。
4.根据条款1所述的方法,其中:
对于每个碱基检出循环,由该第一碱基检出器生成的该第一分类信息包括:(i)第一多个分数,该第一多个分数中的每个分数指示待检出碱基为A、C、T或G中的一者的概率,以及(ii)第一被检出碱基;以及
对于每个碱基检出循环,由该第二碱基检出器生成的该第二分类信息包括:(i)第二多个分数,该第二多个分数中的每个分数指示该待检出碱基为A、C、T或G中的一者的概率,以及(ii)第二被检出碱基。
5.根据条款4所述的方法,其中:
对于每个碱基检出循环,该最终分类信息包括:(i)第三多个分数,该第三多个分数中的每个分数指示该待检出碱基为A、C、T或G中的一者的概率,以及(ii)最终被检出碱基。
6.根据条款4所述的方法,其中该第一碱基检出器和该第二碱基检出器中的至少一者使用softmax函数来生成对应多个分数。
7.根据条款1所述的方法,其中生成该最终分类信息包括:通过基于与该传感器数据相关联的上下文信息选择性地组合该第一分类信息和该第二分类信息来生成该最终分类信息。
8.根据条款7所述的方法,其中与该传感器数据相关联的该上下文信息包括时间上下文信息、空间上下文信息、碱基序列上下文信息和其他上下文信息。
9.根据条款7所述的方法,其中与该传感器数据相关联的该上下文信息包括时间上下文信息,该时间上下文信息指示与该传感器数据相关联的一个或多个碱基检出循环数。
10.根据条款7所述的方法,其中与该传感器数据相关联的该上下文信息包括空间上下文信息,该空间上下文信息指示流通池内生成该传感器数据的一个或多个区块的位置。
11.根据条款7所述的方法,其中与该传感器数据相关联的该上下文信息包括空间上下文信息,该空间上下文信息指示该流通池的区块内生成该传感器数据的一个或多个簇的位置。
11A.根据条款11所述的方法,其中该空间上下文信息指示该流通池的该区块内生成该传感器数据的该一个或多个簇是边缘簇还是非边缘簇。
11B.根据条款11A所述的方法,其中如果簇被估计为位于距该区块的边缘的阈值距离内,则该簇被分类为边缘簇。
11C.根据条款11A所述的方法,其中如果簇被估计为位于距该区块的任何边缘大于阈值距离处,则该簇被分类为非边缘簇。
12.根据条款7所述的方法,其中与该传感器数据相关联的该上下文信息包括碱基序列上下文信息,该碱基序列上下文信息指示针对该传感器数据检出的碱基序列。
13.根据条款1所述的方法,其中:
对于特定待检出碱基,该第一分类信息包括分别指示该待检出碱基为A、C、T和G的概率的第一分数、第二分数、第三分数和第四分数;
对于该特定待检出碱基,该第二分类信息包括分别指示该待检出碱基为A、C、T和G的概率的第五分数、第六分数、第七分数和第八分数;以及
生成该最终分类信息包括:
针对该特定待检出碱基,基于该第一分数、该第二分数、该第三分数、该第四分数、该第五分数、该第六分数、该第七分数和该第八分数,生成该最终分类信息。
14.根据条款13所述的方法,其中:
该最终分数包括为该第一分数和该第五分数的函数的第一最终分数,该第一最终分数指示该待检出碱基为A的概率;
该最终分数包括为该第二分数和该第六分数的函数的第二最终分数,该第二最终分数指示该待检出碱基为C的概率;
该最终分数包括为该第三分数和该第七分数的函数的第三最终分数,该第三最终分数指示该待检出碱基为T的概率;以及
该最终分数包括为该第四分数和该第八分数的函数的第四最终分数,该第四最终分数指示该待检出碱基为G的概率。
15.根据条款14所述的方法,其中:
该第一最终分数是该第一分数和该第五分数的平均值、归一化加权平均值、最小值或最大值;
该第二最终分数是该第二分数和该第六分数的平均值、归一化加权平均值、最小值或最大值;
该第三最终分数是该第三分数和该第七分数的平均值、归一化加权平均值、最小值或最大值;以及
该第四最终分数是该第四分数和该第八分数的平均值、归一化加权平均值、最小值或最大值。
16.根据条款14所述的方法,其中:
对于特定待检出碱基,该第一分类信息包括为A、C、T和G中的一者的第一被检出碱基,该第一被检出碱基具有为该第一分数、该第二分数、该第三分数和该第四分数中的最高分数的对应分数;以及
对于该特定待检出碱基,该第二分类信息包括为A、C、T和G中的一者的第二被检出碱基,该第二被检出碱基具有为该第五分数、该第六分数、该第七分数和该第八分数中的最高分数的对应分数。
17.根据条款1所述的方法,其中:
对于特定待检出碱基,该第一分类信息包括为A、C、T和G中的一者的第一被检出碱基;
对于该特定待检出碱基,该第二分类信息包括与该第一被检出碱基相同的第二被检出碱基;以及
生成该最终分类信息包括:
针对该特定待检出碱基,生成该最终分类信息,使得该最终分类信息包括与该第一被检出碱基和该第二被检出碱基相匹配的最终被检出碱基。
18.根据条款1所述的方法,其中:
对于特定待检出碱基,该第一分类信息包括为A、C、T和G中的一者的第一被检出碱基;
对于该特定待检出碱基,该第二分类信息包括为A、C、T和G中的另一者的第二被检出碱基,使得该第二被检出碱基与该第一被检出碱基不匹配;以及
生成该最终分类信息包括:
针对该特定待检出碱基,生成该最终分类信息,使得该最终分类信息包括为以下中的一者的最终被检出碱基:(i)该第一被检出碱基,(ii)该第二被检出碱基,或(iii)被标记为不确定的。
19.根据条款1所述的方法,其中:
该第一分类信息、该第二分类信息或该最终分类信息中的至少一者指示被检出碱基序列具有特定碱基序列模式;以及
响应于该被检出碱基序列具有该特定碱基序列模式的该指示,通过将第一权重置于该第一分类信息并且将第二权重置于该第二分类信息来生成该最终分类信息,其中该第一权重和该第二权重是不同的。
20.根据条款19所述的方法,其中:
该特定碱基序列模式包括均聚物模式或近均聚物模式。
20a.根据条款19所述的方法,其中:
该特定碱基序列模式包括均聚物模式或具有侧接均聚物的模式。
21.根据条款19所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基为G。
21a.根据条款19所述的方法,其中:
该特定碱基序列模式包括至少五个碱基,其中至少第一碱基和最后一个碱基为G。
22.根据条款19所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中该特定碱基序列模式的该多个碱基中的大多数碱基为G。
22a.根据条款19所述的方法,其中:
特定碱基序列模式包括至少五个碱基,其中特定碱基序列模式的至少三个碱基为G。
22A.根据条款19所述的方法,其中:
特定碱基序列模式包括GGXGG、GXGGG、GGGXG、GXXGG、GGXXG中的任一者,其中X为A、C、T或G中的任一者。
22B.根据条款19所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基中的每一者与非活动碱基检出相关联。
22B1.根据条款19所述的方法,其中:
该特定碱基序列模式包括至少五个碱基,其中至少第一碱基和最后一个碱基中的每一者与非活动碱基检出相关联。
22C.根据条款19所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基中的每一者的碱基检出与暗循环相关联。
22D.根据条款19所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中该特定碱基序列模式的这些碱基中的至少大多数碱基中的每一者与非活动碱基检出相关联。
22E.根据条款19所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中该特定碱基序列模式的这些碱基中的至少大多数碱基中的每一者与暗循环相关联。
23.根据条款19所述的方法,其中:
该第一权重低于该第二权重,使得在生成该最终分类信息时该第一分类信息的权重小于该第二分类信息的权重。
24.根据条款23所述的方法,其中:
该第一碱基检出器实现神经网络模型,而该第二碱基检出器不包括神经网络模型。
25.根据条款19所述的方法,其中:
该第一权重高于90%,而该第二权重低于10%。
26.根据条款1所述的方法,其中:
该传感器数据包括:(i)第一一个或多个感测循环的第一传感器数据,以及(ii)在该第一一个或多个感测循环之后发生的第二一个或多个感测循环的第二传感器数据;
该最终分类信息包括:
(i)通过以下方式生成的该第一一个或多个感测循环的第一最终分类信息:(a)将第一权重置于与该第一一个或多个感测循环相关联的该第一分类信息,以及(b)将第二权重置于与该第一一个或多个感测循环相关联的该第二分类信息;以及
(i)通过以下方式生成的该第二一个或多个感测循环的第二最终分类信息:(a)将第三权重置于与该第二一个或多个感测循环相关联的该第一分类信息,以及(b)将第四权重置于与该第二一个或多个感测循环相关联的该第二分类信息;以及
该第一权重、该第二权重、该第三权重和该第四权重是不同的。
27.根据条款26所述的方法,其中:
该第一碱基检出器实现神经网络模型,而该第二碱基检出器不包括神经网络模型;
该第一权重低于该第二权重,使得对于该第一一个或多个感测循环,来自该第二碱基检出器的该第二分类信息比来自该第一碱基检出器的该第一分类信息更受重视;以及
该第三权重高于该第四权重,使得对于该第二一个或多个感测循环,来自该第一碱基检出器的该第一分类信息比来自该第二碱基检出器的该第二分类信息更受重视。
28.根据条款1所述的方法,其中:
该传感器数据包括:(i)来自流通池的区块的第一一个或多个簇的第一传感器数据,以及
(ii)来自该流通池的该区块的第二一个或多个簇的第二传感器数据;该最终分类信息包括:
(i)来自该第一一个或多个簇的该第一传感器数据的第一最终分类信息,该第一最终分类信息通过以下方式生成:(a)将第一权重置于来自该第一一个或多个簇的该第一分类信息,以及
(b)将第二权重置于来自该第一一个或多个簇的该第二分类信息;以及
(i)来自该第二一个或多个簇的该第二传感器数据的第二最终分类信息,该第二最终分类信息通过以下方式生成:(a)将第三权重置于来自该第二一个或多个簇的该第一分类信息,以及
(b)将第四权重置于来自该第二一个或多个簇的该第二分类信息;以及
该第一权重、该第二权重、该第三权重和该第四权重是不同的。
29.根据条款28所述的方法,其中:
该第一一个或多个簇是设置在距该流通池的该区块的一个或多个边缘的阈值距离内的边缘簇;以及
该第二一个或多个簇是设置在超过距该流通池的该区块的一个或多个边缘的该阈值距离处的非边缘簇。
30.根据条款29所述的方法,其中:
该第一碱基检出器实现神经网络模型,而该第二碱基检出器不包括神经网络模型;以及
该第一权重高于该第二权重,使得对于该第一一个或多个边缘簇,来自该第一碱基检出器的该第一分类信息比来自该第二碱基检出器的该第二分类信息更受重视。
31.根据条款30所述的方法,其中:
该第三权重低于或等于该第四权重,使得对于该第二一个或多个非边缘簇,来自该第一碱基检出器的该第一分类信息与来自该第二碱基检出器的该第二分类信息相比更少或同样受重视。
32.根据条款1所述的方法,该方法还包括:
根据该传感器数据检测流通池的区块的至少一个簇中的一个或多个气泡的存在,
其中生成该最终分类信息包括:
响应于该一个或多个气泡的该检测,通过将第一权重置于该第一分类信息并且将第二权重置于该第二分类信息来生成该最终分类信息,其中该第一权重和该第二权重是不同的。
33.根据条款32所述的方法,其中:
该第一碱基检出器实现神经网络模型,而该第二碱基检出器不包括神经网络模型;以及
该第一权重高于该第二权重,使得响应于该一个或多个气泡的该检测,来自该第一碱基检出器的该第一分类信息比来自该第二碱基检出器的该第二分类信息更受重视。
34.根据条款1所述的方法,其中该传感器数据包括至少一个图像,并且其中该方法还包括:
检测该至少一个图像是失焦图像,
其中生成该最终分类信息包括:
响应于该失焦图像的该检测,通过将第一权重置于该第一分类信息并且将第二权重置于该第二分类信息来生成该最终分类信息,其中该第一权重和该第二权重是不同的。
35.根据条款32所述的方法,其中:
该第一碱基检出器实现神经网络模型,而该第二碱基检出器不包括神经网络模型;以及
该第一权重高于该第二权重,使得响应于该失焦图像的该检测,来自该第一碱基检出器的该第一分类信息比来自该第二碱基检出器的该第二分类信息更受重视。
36.根据条款1所述的方法,其中:
该传感器数据与多个测序循环相关联;
该第一分类信息包括与该多个测序循环相对应的第一被检出碱基序列,并且该第二分类信息包括与该多个测序循环相对应的第二被检出碱基序列;
该第一被检出碱基序列和该第二被检出碱基序列不匹配,并且该第一被检出碱基序列或该第二被检出碱基序列中的至少一者具有特定碱基序列模式;
该第一碱基检出器实现神经网络模型,而该第二碱基检出器不包括神经网络模型;以及
生成该最终分类信息包括:
响应于(i)该第一被检出碱基序列或该第二被检出碱基序列中的至少一者具有该特定碱基序列模式,并且(ii)该第二碱基检出器不包括该神经网络模型,生成该最终分类信息,使得该最终分类信息的最终被检出碱基序列与该第二被检出碱基序列相匹配,而与该第一被检出碱基序列不匹配。
37.根据条款36所述的方法,其中:
该特定碱基序列模式包括均聚物模式或近均聚物模式。
38.根据条款36所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基为G。
39.根据条款36所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中该特定碱基序列模式的这些碱基中的至少大多数碱基为G。
39a.根据条款36所述的方法,其中:
特定碱基序列模式包括至少五个碱基,其中特定碱基序列模式的至少三个碱基为G。
39A.根据条款36所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基中的每一者与非活动碱基检出相关联。
39B.根据条款36所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基中的每一者的碱基检出与暗循环相关联。
39C.根据条款36所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中该特定碱基序列模式的这些碱基中的至少大多数碱基中的每一者与非活动碱基检出相关联。
39D.根据条款36所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中该特定碱基序列模式的这些碱基中的至少大多数碱基中的每一者与暗循环相关联。
40.根据条款1所述的方法,其中生成该最终分类信息包括:由机器学习模型从该第一碱基检出器接收与该传感器数据相关联的该第一分类信息;
由该机器学习模型从该第二碱基检出器接收与该传感器数据相关联的该第二分类信息;以及
由该机器学习模型基于该第一分类信息和该第二分类信息生成该最终分类信息。
40a.根据条款40所述的方法,其中该机器学习模型是逻辑回归模型、梯度提升树模型、随机森林模型、朴素贝叶斯模型或神经网络模型中的任一者。
40b.根据条款1所述的方法,其中生成该最终分类信息包括:由神经网络模型从该第一碱基检出器接收与该传感器数据相关联的该第一分类信息;
由该神经网络模型从该第二碱基检出器接收与该传感器数据相关联的该第二分类信息;以及
由该神经网络模型基于该第一分类信息和该第二分类信息生成该最终分类信息。
41.一种计算机实现的方法,该方法包括:
针对该一系列感测循环中的感测循环生成传感器数据;以及对该传感器数据的至少对应部分执行至少第一碱基检出器和第二碱基检出器,并且基于与该传感器数据相关联的上下文信息选择性地切换该第一碱基检出器和该第二碱基检出器的执行,其中该第一碱基检出器不同于该第二碱基检出器;
分别由该第一碱基检出器和该第二碱基检出器生成第一分类信息和第二分类信息,
基于该第一分类信息和该第二分类信息中的一者或两者生成碱基检出。
42.一种印有渐进地训练碱基检出器的计算机程序指令的非暂态计算机可读存储介质,所述指令在处理器上执行时实现包括以下各项的方法:
对针对一系列感测循环中的感测循环生成的传感器数据执行至少第一碱基检出器和第二碱基检出器;
基于对该传感器数据执行该第一碱基检出器,由该第一碱基检出器生成与该传感器数据相关联的第一分类信息;
基于对该传感器数据执行该第二碱基检出器,由该第二碱基检出器生成与该传感器数据相关联的第二分类信息;以及
基于该第一分类信息和该第二分类信息,生成最终分类信息,该最终分类信息包括该传感器数据的一个或多个碱基检出。
43.根据条款42所述的非暂态计算机可读存储介质,其中该第一碱基检出器和该第二碱基检出器中的至少一者实现非线性函数,并且其中该第一碱基检出器和该第二碱基检出器中的至少另一者至少部分地是线性的。
44.根据条款42所述的非暂态计算机可读存储介质,其中该第一检出器和该第二碱基检出器中的至少一者实现神经网络模型,而该第一碱基检出器和该第二碱基检出器中的至少另一者不包括神经网络模型。
45.根据条款42所述的非暂态计算机可读存储介质,其中:
对于每个碱基检出循环,由该第一碱基检出器生成的该第一分类信息包括:(i)第一多个分数,该第一多个分数中的每个分数指示待检出碱基为A、C、T或G中的一者的概率,以及(ii)第一被检出碱基;以及
对于每个碱基检出循环,由该第二碱基检出器生成的该第二分类信息包括:(i)第二多个分数,该第二多个分数中的每个分数指示该待检出碱基为A、C、T或G中的一者的概率,以及(ii)第二被检出碱基。
46.根据条款45所述的非暂态计算机可读存储介质,其中:
对于每个碱基检出循环,该最终分类信息包括:(i)第三多个分数,该第三多个分数中的每个分数指示该待检出碱基为A、C、T或G中的一者的概率,以及(ii)最终被检出碱基。
47.根据条款45所述的非暂态计算机可读存储介质,其中该第一碱基检出器和该第二碱基检出器中的至少一者使用softmax函数来生成对应多个分数。
48.根据条款42所述的非暂态计算机可读存储介质,其中生成该最终分类信息包括:
通过基于与该传感器数据相关联的上下文信息选择性地组合该第一分类信息和该第二分类信息来生成该最终分类信息。
49.根据条款48所述的非暂态计算机可读存储介质,其中与该传感器数据相关联的该上下文信息包括时间上下文信息、空间上下文信息、碱基序列上下文信息和其他上下文信息。
50.根据条款48所述的非暂态计算机可读存储介质,其中与该传感器数据相关联的该上下文信息包括时间上下文信息,该时间上下文信息指示与该传感器数据相关联的一个或多个碱基检出循环数。
51.根据条款48所述的非暂态计算机可读存储介质,其中与该传感器数据相关联的该上下文信息包括空间上下文信息,该空间上下文信息指示流通池内生成该传感器数据的一个或多个区块的位置。
52.根据条款48所述的非暂态计算机可读存储介质,其中与该传感器数据相关联的该上下文信息包括空间上下文信息,该空间上下文信息指示该流通池的区块内生成该传感器数据的一个或多个簇的位置。
52A.根据条款52所述的非暂态计算机可读存储介质,其中该空间上下文信息指示该流通池的该区块内生成该传感器数据的该一个或多个簇是边缘簇还是非边缘簇。
52B.根据条款52A所述的非暂态计算机可读存储介质,其中如果簇被估计为位于距该区块的边缘的阈值距离内,则该簇被分类为边缘簇。
52C.根据条款52A所述的非暂态计算机可读存储介质,其中如果簇被估计为位于距该区块的任何边缘大于阈值距离处,则该簇被分类为非边缘簇。
53.根据条款48所述的非暂态计算机可读存储介质,其中与该传感器数据相关联的该上下文信息包括碱基序列上下文信息,该碱基序列上下文信息指示针对该传感器数据检出的碱基序列。
54.根据条款42所述的非暂态计算机可读存储介质,其中:
对于特定待检出碱基,该第一分类信息包括分别指示该待检出碱基为A、C、T和G的概率的第一分数、第二分数、第三分数和第四分数;
对于该特定待检出碱基,该第二分类信息包括分别指示该待检出碱基为A、C、T和G的概率的第五分数、第六分数、第七分数和第八分数;以及
生成该最终分类信息包括:
针对该特定待检出碱基,基于该第一分数、该第二分数、该第三分数、该第四分数、该第五分数、该第六分数、该第七分数和该第八分数,生成该最终分类信息。
55.根据条款54所述的非暂态计算机可读存储介质,其中:
该最终分数包括为该第一分数和该第五分数的函数的第一最终分数,该第一最终分数指示该待检出碱基为A的概率;
该最终分数包括为该第二分数和该第六分数的函数的第二最终分数,该第二最终分数指示该待检出碱基为C的概率;
该最终分数包括为该第三分数和该第七分数的函数的第三最终分数,该第三最终分数指示该待检出碱基为T的概率;以及
该最终分数包括为该第四分数和该第八分数的函数的第四最终分数,该第四最终分数指示该待检出碱基为G的概率。
56.根据条款55所述的非暂态计算机可读存储介质,其中:
该第一最终分数是该第一分数和该第五分数的平均值、归一化加权平均值、最小值或最大值;
该第二最终分数是该第二分数和该第六分数的平均值、归一化加权平均值、最小值或最大值;
该第三最终分数是该第三分数和该第七分数的平均值、归一化加权平均值、最小值或最大值;以及
该第四最终分数是该第四分数和该第八分数的平均值、归一化加权平均值、最小值或最大值。
57.根据条款55所述的非暂态计算机可读存储介质,其中:
对于特定待检出碱基,该第一分类信息包括为A、C、T和G中的一者的第一被检出碱基,该第一被检出碱基具有为该第一分数、该第二分数、该第三分数和该第四分数中的最高分数的对应分数;以及
对于该特定待检出碱基,该第二分类信息包括为A、C、T和G中的一者的第二被检出碱基,该第二被检出碱基具有为该第五分数、该第六分数、该第七分数和该第八分数中的最高分数的对应分数。
58.根据条款42所述的非暂态计算机可读存储介质,其中:
对于特定待检出碱基,该第一分类信息包括为A、C、T和G中的一者的第一被检出碱基;
对于该特定待检出碱基,该第二分类信息包括与该第一被检出碱基相同的第二被检出碱基;以及
生成该最终分类信息包括:
针对该特定待检出碱基,生成该最终分类信息,使得该最终分类信息包括与该第一被检出碱基和该第二被检出碱基相匹配的最终被检出碱基。
59.根据条款42所述的非暂态计算机可读存储介质,其中:
对于特定待检出碱基,该第一分类信息包括为A、C、T和G中的一者的第一被检出碱基;
对于该特定待检出碱基,该第二分类信息包括为A、C、T和G中的另一者的第二被检出碱基,使得该第二被检出碱基与该第一被检出碱基不匹配;以及
生成该最终分类信息包括:
针对该特定待检出碱基,生成该最终分类信息,使得该最终分类信息包括为以下中的一者的最终被检出碱基:(i)该第一被检出碱基,(ii)该第二被检出碱基,或(iii)被标记为不确定的。
60.根据条款42所述的非暂态计算机可读存储介质,其中:
该第一分类信息、该第二分类信息或该最终分类信息中的至少一者指示被检出碱基序列具有特定碱基序列模式;以及响应于该被检出碱基序列具有该特定碱基序列模式的该指示,通过将第一权重置于该第一分类信息并且将第二权重置于该第二分类信息来生成该最终分类信息,其中该第一权重和该第二权重是不同的。
61.根据条款60所述的非暂态计算机可读存储介质,其中:
该特定碱基序列模式包括均聚物模式或近均聚物模式。
62.根据条款60所述的非暂态计算机可读存储介质,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基为G。
63.根据条款60所述的非暂态计算机可读存储介质,其中:
该特定碱基序列模式包括多个碱基,其中该特定碱基序列模式的这些碱基中的大多数碱基为G。
63A.根据条款60所述的非暂态计算机可读存储介质,其中:
特定碱基序列模式包括GGXGG、GXGGG、GGGXG、GXXGG、GGXXG中的任一者,其中X为A、C、T或G中的任一者。
63B.根据条款60所述的非暂态计算机可读存储介质,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基中的每一者与非活动碱基检出相关联。
63C.根据条款60所述的非暂态计算机可读存储介质,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基中的每一者的碱基检出与暗循环相关联。
63D.根据条款60所述的非暂态计算机可读存储介质,其中:
该特定碱基序列模式包括多个碱基,其中该特定碱基序列模式的这些碱基中的大多数碱基与非活动碱基检出相关联。
63E.根据条款60所述的非暂态计算机可读存储介质,其中:
该特定碱基序列模式包括至少五个碱基,其中该特定碱基序列模式的至少三个碱基中的每一者与暗循环相关联。
64.根据条款60所述的非暂态计算机可读存储介质,其中:
该第一权重低于该第二权重,使得在生成该最终分类信息时该第一分类信息的权重小于该第二分类信息的权重。
65.根据条款64所述的非暂态计算机可读存储介质,其中:
该第一碱基检出器实现神经网络模型,而该第二碱基检出器不包括神经网络模型。
66.根据条款60所述的非暂态计算机可读存储介质,其中:
该第一权重高于90%,而该第二权重低于10%。
67.根据条款42所述的非暂态计算机可读存储介质,其中:
该传感器数据包括:(i)第一一个或多个感测循环的第一传感器数据,以及(ii)在该第一一个或多个感测循环之后发生的第二一个或多个感测循环的第二传感器数据;
该最终分类信息包括:
(i)通过以下方式生成的该第一一个或多个感测循环的第一最终分类信息:(a)将第一权重置于与该第一一个或多个感测循环相关联的该第一分类信息,以及(b)将第二权重置于与该第一一个或多个感测循环相关联的该第二分类信息;以及
(i)通过以下方式生成的该第二一个或多个感测循环的第二最终分类信息:(a)将第三权重置于与该第二一个或多个感测循环相关联的该第一分类信息,以及(b)将第四权重置于与该第二一个或多个感测循环相关联的该第二分类信息;以及
该第一权重、该第二权重、该第三权重和该第四权重是不同的。
68.根据条款67所述的非暂态计算机可读存储介质,其中:
该第一碱基检出器实现神经网络模型,而该第二碱基检出器不包括神经网络模型;
该第一权重低于该第二权重,使得对于该第一一个或多个感测循环,来自该第二碱基检出器的该第二分类信息比来自该第一碱基检出器的该第一分类信息更受重视;以及
该第三权重高于该第四权重,使得对于该第二一个或多个感测循环,来自该第一碱基检出器的该第一分类信息比来自该第二碱基检出器的该第二分类信息更受重视。
69.根据条款42所述的非暂态计算机可读存储介质,其中:
该传感器数据包括:(i)来自流通池的区块的第一一个或多个簇的第一传感器数据,以及
(ii)来自该流通池的该区块的第二一个或多个簇的第二传感器数据;该最终分类信息包括:
(i)来自该第一一个或多个簇的该第一传感器数据的第一最终分类信息,该第一最终分类信息通过以下方式生成:(a)将第一权重置于来自该第一一个或多个簇的该第一分类信息,以及(b)将第二权重置于来自该第一一个或多个簇的该第二分类信息;以及
(i)来自该第二一个或多个簇的该第二传感器数据的第二最终分类信息,该第二最终分类信息通过以下方式生成:(a)将第三权重置于来自该第二一个或多个簇的该第一分类信息,以及
(b)将第四权重置于来自该第二一个或多个簇的该第二分类信息;以及
该第一权重、该第二权重、该第三权重和该第四权重是不同的。
70.根据条款69所述的非暂态计算机可读存储介质,其中:
该第一一个或多个簇是设置在距该流通池的该区块的一个或多个边缘的阈值距离内的边缘簇;以及
该第二一个或多个簇是设置在超过距该流通池的该区块的一个或多个边缘的该阈值距离处的非边缘簇。
71.根据条款70所述的非暂态计算机可读存储介质,其中:
该第一碱基检出器实现神经网络模型,而该第二碱基检出器不包括神经网络模型;以及
该第一权重高于该第二权重,使得对于该第一一个或多个边缘簇,来自该第一碱基检出器的该第一分类信息比来自该第二碱基检出器的该第二分类信息更受重视。
72.根据条款71所述的非暂态计算机可读存储介质,其中:
该第三权重低于或等于该第四权重,使得对于该第二一个或多个非边缘簇,来自该第一碱基检出器的该第一分类信息与来自该第二碱基检出器的该第二分类信息相比更少或同样受重视。
73.根据条款42所述的非暂态计算机可读存储介质,该非暂态计算机可读存储介质还包括:根据该传感器数据检测流通池的区块的至少一个簇中的一个或多个气泡的存在,
其中生成该最终分类信息包括:
响应于该一个或多个气泡的该检测,通过将第一权重置于该第一分类信息并且将第二权重置于该第二分类信息来生成该最终分类信息,其中该第一权重和该第二权重是不同的。
74.根据条款73所述的非暂态计算机可读存储介质,其中:
该第一碱基检出器实现神经网络模型,而该第二碱基检出器不包括神经网络模型;以及
该第一权重高于该第二权重,使得响应于该一个或多个气泡的该检测,来自该第一碱基检出器的该第一分类信息比来自该第二碱基检出器的该第二分类信息更受重视。
75.根据条款73所述的非暂态计算机可读存储介质,其中该传感器数据包括至少一个图像,并且其中该方法还包括:
检测该至少一个图像是失焦图像,
其中生成该最终分类信息包括:
响应于该失焦图像的该检测,通过将第一权重置于该第一分类信息并且将第二权重置于该第二分类信息来生成该最终分类信息,其中该第一权重和该第二权重是不同的。
76.根据条款73所述的非暂态计算机可读存储介质,其中:
该第一碱基检出器实现神经网络模型,而该第二碱基检出器不包括神经网络模型;以及
该第一权重高于该第二权重,使得响应于该失焦图像的该检测,来自该第一碱基检出器的该第一分类信息比来自该第二碱基检出器的该第二分类信息更受重视。
77.根据条款42所述的非暂态计算机可读存储介质,其中:
该传感器数据与多个测序循环相关联;
该第一分类信息包括与该多个测序循环相对应的第一被检出碱基序列,并且该第二分类信息包括与该多个测序循环相对应的第二被检出碱基序列;
该第一被检出碱基序列和该第二被检出碱基序列不匹配,并且该第一被检出碱基序列或该第二被检出碱基序列中的至少一者具有特定碱基序列模式;
该第一碱基检出器实现神经网络模型,而该第二碱基检出器不包括神经网络模型;以及
生成该最终分类信息包括:
响应于(i)该第一被检出碱基序列或该第二被检出碱基序列中的至少一者具有该特定碱基序列模式,并且(ii)该第二碱基检出器不包括该神经网络模型,生成该最终分类信息,使得该最终分类信息的最终被检出碱基序列与该第二被检出碱基序列相匹配,而与该第一被检出碱基序列不匹配。
78.根据条款77所述的非暂态计算机可读存储介质,其中:
该特定碱基序列模式包括均聚物模式或近均聚物模式。
79.根据条款77所述的非暂态计算机可读存储介质,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基为G。
80.根据条款77所述的非暂态计算机可读存储介质,其中:
该特定碱基序列模式包括多个碱基,其中该特定碱基序列模式的这些碱基中的大多数碱基为G。
80A.根据条款77所述的非暂态计算机可读存储介质,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基中的每一者与非活动碱基检出相关联。
80B.根据条款77所述的非暂态计算机可读存储介质,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基中的每一者的碱基检出与暗循环相关联。
80C.根据条款77所述的非暂态计算机可读存储介质,其中:
该特定碱基序列模式包括多个碱基,其中该特定碱基序列模式的该多个碱基中的大多数碱基与非活动碱基检出相关联。
80D.根据条款60所述的非暂态计算机可读存储介质,其中:
该特定碱基序列模式包括至少五个碱基,其中该特定碱基序列模式的至少三个碱基中的每一者与暗循环相关联。
81.根据条款42所述的非暂态计算机可读存储介质,其中生成该最终分类信息包括:
由神经网络模型从该第一碱基检出器接收与该传感器数据相关联的该第一分类信息;
由该神经网络模型从该第二碱基检出器接收与该传感器数据相关联的该第二分类信息;以及
由该神经网络模型基于该第一分类信息和该第二分类信息生成该最终分类信息。
条款集2(切换/选择性地启用两个碱基检出器)
1.一种用于使用至少两个碱基检出器进行碱基检出的计算机实现的方法,该方法包括:
对针对一系列感测循环中的感测循环生成的传感器数据执行第一碱基检出器;基于对该传感器数据所述执行该第一碱基检出器,由该第一碱基检出器生成与该传感器数据相关联的第一分类信息;
确定该第一分类信息对于生成该传感器数据的最终分类信息是不充分的;
响应于确定该第一分类信息的该不充分,对该传感器数据执行第二碱基检出器,该第二碱基检出器不同于该第一碱基检出器;
基于对该传感器数据所述执行该第二碱基检出器,由该第二碱基检出器生成与该传感器数据相关联的第二分类信息;以及
基于该第一分类信息和该第二分类信息,生成该最终分类信息,该最终分类信息包括该传感器数据的一个或多个碱基检出。
2.根据条款1所述的方法,其中该第一分类信息包括第一被检出碱基序列,并且其中确定该第一分类信息不充分包括:确定该第一被检出碱基序列与特定碱基序列模式相匹配;以及
基于该第一被检出碱基序列与该特定碱基序列模式相匹配,确定该第一分类信息对于生成该最终分类信息是不充分的。
3.根据条款2所述的方法,其中:
该特定碱基序列模式包括均聚物模式或近均聚物模式。
4.根据条款2所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中该多个碱基中的至少第一碱基和最后一个碱基为G。
4A.根据条款2所述的方法,其中:
该特定碱基序列模式包括至少五个碱基,其中至少第一碱基和最后一个碱基为G。
5.根据条款2所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中该多个碱基中的至少三个碱基为G。
5A.根据条款2所述的方法,其中:
特定碱基序列模式包括至少五个碱基,其中特定碱基序列模式的至少三个碱基为G。
6.根据条款2所述的方法,其中:
特定碱基序列模式包括GGXGG、GXGGG、GGGXG、GXXGG、GGXXG中的任一者,其中X为A、C、T或G中的任一者。
6A.根据条款2所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基中的每一者与非活动碱基检出相关联。
6B.根据条款2所述的方法,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基中的每一者的碱基检出与暗循环相关联。
6C.根据条款2所述的方法,其中:
该特定碱基序列模式包括至少五个碱基,其中该特定碱基序列模式的至少三个碱基中的每一者与非活动碱基检出相关联。
6D.根据条款2所述的方法,其中:
该特定碱基序列模式包括至少五个碱基,其中该特定碱基序列模式的至少三个碱基中的每一者与暗循环相关联。
7.根据条款2所述的方法,其中生成该最终分类信息包括:响应于该第一被检出碱基序列与该特定碱基序列模式相匹配,通过将第一权重置于该第一分类信息并且将第二权重置于该第二分类信息
来生成该最终分类信息,其中该第一权重和该第二权重是不同的。
8.根据条款7所述的方法,其中:
该第一碱基检出器实现神经网络模型,而该第二碱基检出器不包括神经网络模型;以及
该第一权重小于该第二权重,使得在生成该最终分类信息时,该第一分类信息的权重小于该第二分类信息的权重。
9.根据条款2所述的方法,其中:
该第一碱基检出器实现神经网络模型,而该第二碱基检出器不包括神经网络模型;
该第二分类信息包括第二被检出碱基序列;
该第一被检出碱基序列与该第二被检出碱基序列不匹配;以及
响应于(i)该第一被检出碱基序列与该特定碱基序列模式相匹配,并且(ii)该第二碱基检出器不包括该神经网络模型,生成该最终分类信息,使得该最终分类信息的最终被检出碱基序列与该第二被检出碱基序列相匹配,而与该第一被检出碱基序列不匹配。
10.根据条款1所述的方法,其中确定该第一分类信息不充分包括:
检测从其生成该传感器数据的簇中的气泡的存在;以及
基于该气泡的该检测,确定该第一分类信息对于生成该最终分类信息是不充分的。
11.根据条款10所述的方法,其中该第二碱基检出器实现神经网络模型,而该第一碱基检出器不包括神经网络模型,并且生成该最终分类信息包括:
通过将第一权重置于该第一分类信息并且将第二权重置于该第二分类信息来生成该最终分类信息,其中该第二权重大于该第一权重。
12.根据条款1所述的方法,其中:
该传感器数据为当前传感器数据;
该当前传感器数据是针对感测循环N1和一个或多个后续感测循环的,其中N1是大于1的正整数;并且
对该当前传感器数据执行该第二碱基检出器包括:
首先,对与在该感测循环N1之前发生的至少T个感测循环相关联的过去传感器数据执行该第二碱基检出器,以估计与该至少T个感测循环相关联的定相数据,并且
随后,使用所估计的定相数据对与该感测循环N1和该一个或多个后续感测循环相关联的该当前传感器数据执行该第二碱基检出器。
13.根据条款1所述的方法,其中该传感器数据是从流通池的区块的第一一个或多个簇生成的第一传感器数据,并且其中该方法还包括:
针对该一系列感测循环中的感测循环从该流通池的该区块的第二一个或多个簇生成第二传感器数据;以及
对该第二传感器数据执行该第一碱基检出器;
基于对该第二传感器数据执行该第一碱基检出器,由该第一碱基检出器生成与该第二传感器数据相关联的第三分类信息;
确定该第三分类信息对于生成该第二一个或多个簇的最终分类信息是充分的;
其中对该第一传感器数据执行该第二碱基检出器包括:
对该第一传感器数据执行该第二碱基检出器,而不对该第二传感器数据执行该第二碱基检出器,使得(i)该第一一个或多个簇的该最终分类基于该第一碱基检出器和该第二碱基检出器的输出,并且(ii)该第二一个或多个簇的该最终分类基于该第一碱基检出器而非该第二碱基检出器的输出。
14.根据条款1所述的方法,其中确定该第一分类信息不充分包括:
接收与该传感器数据相关联的上下文信息;
基于该上下文数据确定该第一分类信息包括高于阈值概率的错误概率;以及
基于确定该第一分类信息包括高于该阈值概率的该错误概率,确定该第一分类信息对于生成该传感器数据的最终分类信息是不充分的。
15.一种用于碱基检出的系统,所述系统包括:
存储器,该存储器存储描绘一组分析物的强度发射的图像,这些强度发射是在测序运行的测序循环期间由该一组分析物中的分析物生成的,其中该存储器进一步存储第一碱基检出器和第二碱基检出器的拓扑;
上下文信息生成模块,该上下文信息生成模块被配置为生成与这些图像相关联的上下文信息;
一个或多个处理器,该一个或多个处理器被配置为对这些图像执行该第一碱基检出器,从而生成与这些图像相关联的第一分类信息;以及
最终碱基检出确定模块,该最终碱基检出确定模块被配置为确定该第一分类信息在生成与这些图像相关联的最终分类信息中的不足,
其中响应于该第一分类信息的该不足的确定,该一个或多个处理器被配置为对这些图像执行该第二碱基检出器,从而生成与这些图像相关联的第二分类信息,并且
其中该最终碱基检出确定模块被进一步配置为至少部分地基于该第二分类信息生成包括该测序运行的一个或多个最终碱基检出的该最终分类信息。
16.根据条款15所述的系统,其中该最终分类信息进一步至少部分地基于该第一分类信息来生成。
17.根据条款15所述的系统,其中该最终分类信息基于该第一分类信息和该第二分类信息的加权和来生成。
18.根据条款15所述的系统,其中该第一分类信息包括第一被检出碱基序列,并且其中为了确定该第一分类信息的该不足,该最终碱基检出确定模块将:
确定该第一被检出碱基序列与特定基序列模式相匹配;以及基于该第一被检出碱基序列与该特定碱基序列模式相匹配,确定该第一分类信息对于生成最终分类信息是不充分的。
19.根据条款18所述的系统,其中:
该特定碱基序列模式包括均聚物模式或近均聚物模式。
20.根据条款18所述的系统,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基为G。
21.根据条款18所述的系统,其中:
特定碱基序列模式包括至少五个碱基,其中特定碱基序列模式的至少三个碱基为G。
22.根据条款18所述的系统,其中:
特定碱基序列模式包括GGXGG、GXGGG、GGGXG、GXXGG、GGXXG中的任一者,其中X为A、C、T或G中的任一者。
23A.根据条款18所述的系统,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基中的每一者与非活动碱基检出相关联。
23B.根据条款18所述的系统,其中:
该特定碱基序列模式包括多个碱基,其中至少第一碱基和最后一个碱基中的每一者的碱基检出与暗循环相关联。
23C.根据条款18所述的系统,其中:
该特定碱基序列模式包括至少五个碱基,其中该特定碱基序列模式的至少三个碱基中的每一者与非活动碱基检出相关联。
23D.根据条款18所述的系统,其中:
该特定碱基序列模式包括至少五个碱基,其中该特定碱基序列模式的至少三个碱基中的每一者与暗循环相关联。
23.根据条款15所述的系统,其中为了确定该第一分类信息的该不足,该最终碱基检出确定模块将:
检测从其生成这些图像的簇中的气泡的存在;以及
基于该气泡的该检测,确定该第一分类信息对于生成该最终分类信息是不足的。
24.根据条款15所述的系统,其中为了确定该第一分类信息的该不足,该最终碱基检出确定模块将:
检测这些图像内失焦图像的存在;以及
基于该失焦图像的该检测,确定该第一分类信息对于生成该最终分类信息是不足的。
25.一种印有渐进地训练碱基检出器的计算机程序指令的非暂态计算机可读存储介质,这些指令在处理器上执行时实现包括以下各项的方法:
对针对一系列感测循环中的感测循环生成的传感器数据执行第一碱基检出器,以生成与该传感器数据相关联的第一分类信息;
处理(i)与该传感器数据相关联的上下文信息和(ii)该第一分类信息;
基于处理该上下文信息和该第一分类信息,对该传感器数据执行第二碱基检出器,以生成与该传感器数据相关联的第二分类信息;以及
基于该第一分类信息和该第二分类信息,生成该最终分类信息,该最终分类信息包括该传感器数据的一个或多个碱基检出。