一种融合了序列信息的特征组合推荐算法框架
文献发布时间:2023-06-19 18:53:06
技术领域
本发明涉及互联网推荐系统,特别涉及一种融合了序列信息的特征组合推荐算法框架。
背景技术
互联网推荐系统是指通过算法找到用户可能感兴趣的物品推荐给用户的系统。它已经是电商、广告、音视频等互联网产品中不可或缺的一部分。
推荐系统中的点击率预估指的是根据用户的属性、历史行为、物料的属性等信息判断用户点击商品的可能性。互联网产品将点击概率高的物料展示给用户,以此促进用户转化,提升满意度,为互联网产品实现拉新促活。
本专利针对这一场景,提出了一种融合了序列信息的特征组合推荐算法框架,通过端到端的模型框架,更精准的刻画用户偏好及物品特征,提升了推荐系统点击率预估的准确性。
发明内容
本发明要解决的技术问题是克服现有技术的缺陷,提供一种融合了序列信息的特征组合推荐算法框架。
为了解决上述技术问题,本发明提供了如下的技术方案:
本发明提供一种融合了序列信息的特征组合推荐算法框架,包括以下步骤:
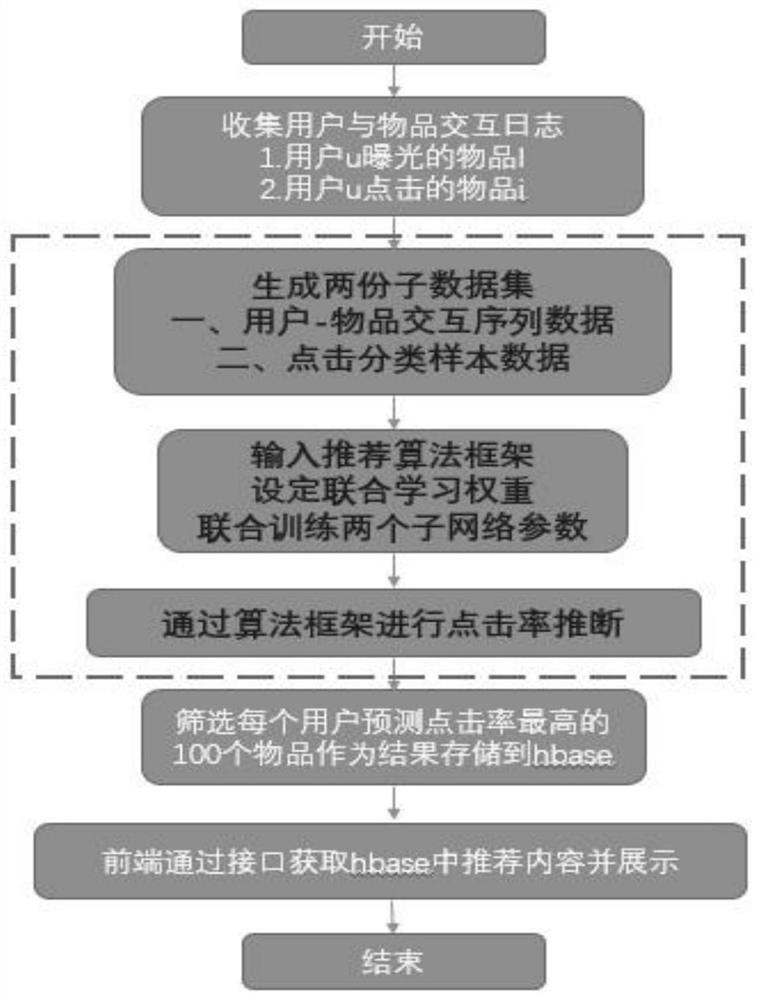
S1、收集用户与物品的交互日志:包括用户U曝光的物品E,点击的物品C(其中C∈E)及每个行为的时间戳;同时保存用户特征信息(如年龄、性别、地域等)、物品特征信息(如类别、品牌、店铺等);
S2、将收集的日志信息整理成结构化数据,其中包括两个部分:
1)用户点击物品序列数据;将每个用户曝光未点击/点击物品按点击时间排序,并以k个点击物品为单位截断生成样本数据;如图二所示;
2)点击分类样本数据;将<用户编号,物品编号>作为样本主键;其中,曝光未点击的样本标记为0,曝光且点击的样本标记为1;同时整理用户特征信息、物品特征信息、用户与物品交互信息作为样本特征;
S3、将上述两部分数据引入本算法框架进行学习,两部分数据分别对应框架中的两个子网络:
1)用户兴趣子网络:使用上述用户点击物品序列数据,输入用户点击序列的物品id以及特征信息,经过embedding层映射成稠密向量;经过sum pooling层表示出用户历史兴趣偏好;同时,用户的特征信息与候选物品经过embedding层映射成稠密向量,与前述用户历史兴趣偏好拼接并压缩,构建出用户信息、用户历史兴趣、目标物品之间的网络关系,再通过全连接层与sigmoid函数,训练网络参数;如图三所示;Loss function为:
其中n为样本总量,y为是否点击的标签,p为输出层的概率值;
2)特征组合子网络:使用上述点击分类样本数据;对于曝光的<用户,物品>样本对,辅以用户的属性信息、物品属性信息、用户与物品的交互信息,以用户是否点击作为标签进行二分类学习;输入的特征信息经过共享embedding层映射为稠密向量,并经过传统的DNN网络实现特征组合交叉,最终经sigmoid函数进行分类学习,如图四所示;Lossfunction为:
其中n为样本总量,y为是否点击的标签,p为输出层的概率值;
S4、将上述两个子网络在本框架中通过共享embedding映射并进行联合学习,如图五;
每个子网络都学习了推荐场景的一部分信息,其中用户兴趣子网络学习了用户过去的兴趣偏好同时优化了用户特征与物品特征的表征,特征组合子网络通过网络学习了物品、用户之间的高阶交叉特征与点击率之间的关系也同步优化了用户特征与物品特征的表征;
为提升学习效果,本框架将两个子网络进行联合学习;首先两个子网络共享embedding映射层,在embedding层融合了兴趣序列信息与单点预估信息,提升embedding表征准确性;同时,在最终的loss层将两个子网络的loss进行加权求和;
loss=loss
其中α可根据场景的数据特性及学习效果进行调整;
S5、点击率预估与线上服务:
模型训练时将框架中的两个子网络通过联合学习同时训练;在离线推断时,时效性要求较低,可通过整个框架进行精准推断;在线推断时,系统时效性要求高,且用户点击序列表达的兴趣爱好在不断变动中,可单独使用用户兴趣子网络单独推断更新推荐结果,更好的贴近用户短期的兴趣变化,同时实现线上轻量部署;
S6、根据推断得到的用户对物品的点击概率值进行降序排序,将概率值最高的K个物品作为排序结果存储到hbase;
S7、前端在用户登录时,通过接口获取hbase中存储的排序结果,并按顺序进行展示。
与现有技术相比,本发明的有益效果如下:
1.用户历史点击序列融入点击率预估模型,更好的捕捉用户兴趣偏好,有效提升了用户刻画精准度;
2.在算法框架中保留了特征组合模型能力的同时,也结合用户兴趣,通过多类模型共享表征映射层的方式,更精准的学习物品表征,从而提升推荐模型准确性;
3.模型训练时两个子网络融合后联合学习,离线服务使用框架整体进行推断,在线服务仅使用用户兴趣子网络进行推断,在保证推荐准确性的同时实现轻量级部署。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1是本发明的实施流程图;
图2是本发明的用户-物品交互序列数据示意图;
图3是本发明的用户兴趣子网络示意图;
图4是本发明的特征组合子网络示意图;
图5是本发明的推荐框架示意图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例1
本发明如图1-5所示,本发明提供一种融合了序列信息的特征组合推荐算法框架,包括以下步骤:
S1、收集用户与物品的交互日志:包括用户U曝光的物品E,点击的物品C(其中C∈E)及每个行为的时间戳。同时保存用户特征信息(如年龄、性别、地域等)、物品特征信息(如类别、品牌、店铺等);
S2、将收集的日志信息整理成结构化数据,其中包括两个部分:
1)用户点击物品序列数据。将每个用户曝光未点击/点击物品按点击时间排序,并以k个点击物品为单位截断生成样本数据。如图二所示;
2)点击分类样本数据。将<用户编号,物品编号>作为样本主键。其中,曝光未点击的样本标记为0,曝光且点击的样本标记为1。同时整理用户特征信息、物品特征信息、用户与物品交互信息作为样本特征;
S3、将上述两部分数据引入本算法框架进行学习,两部分数据分别对应框架中的两个子网络:
1)用户兴趣子网络:使用上述用户点击物品序列数据,输入用户点击序列的物品id以及特征信息,经过embedding层映射成稠密向量。经过sum pooling层表示出用户历史兴趣偏好。同时,用户的特征信息与候选物品经过embedding层映射成稠密向量,与前述用户历史兴趣偏好拼接并压缩,构建出用户信息、用户历史兴趣、目标物品之间的网络关系,再通过全连接层与sigmoid函数,训练网络参数。如图三所示。Loss function为:
其中n为样本总量,y为是否点击的标签,p为输出层的概率值;
2)特征组合子网络:使用上述点击分类样本数据。对于曝光的<用户,物品>样本对,辅以用户的属性信息、物品属性信息、用户与物品的交互信息,以用户是否点击作为标签进行二分类学习。输入的特征信息经过共享embedding层映射为稠密向量,并经过传统的DNN网络实现特征组合交叉,最终经sigmoid函数进行分类学习,如图四所示。Lossfunction为:
其中n为样本总量,y为是否点击的标签,p为输出层的概率值;
S4、将上述两个子网络在本框架中通过共享embedding映射并进行联合学习,如图五;
每个子网络都学习了推荐场景的一部分信息,其中用户兴趣子网络学习了用户过去的兴趣偏好同时优化了用户特征与物品特征的表征,特征组合子网络通过网络学习了物品、用户之间的高阶交叉特征与点击率之间的关系也同步优化了用户特征与物品特征的表征。
为提升学习效果,本框架将两个子网络进行联合学习。首先两个子网络共享embedding映射层,在embedding层融合了兴趣序列信息与单点预估信息,提升embedding表征准确性。同时,在最终的loss层将两个子网络的loss进行加权求和;
loss=loss
其中α可根据场景的数据特性及学习效果进行调整;
S5、点击率预估与线上服务:
模型训练时将框架中的两个子网络通过联合学习同时训练。在离线推断时,时效性要求较低,可通过整个框架进行精准推断。在线推断时,系统时效性要求高,且用户点击序列表达的兴趣爱好在不断变动中,可单独使用用户兴趣子网络单独推断更新推荐结果,更好的贴近用户短期的兴趣变化,同时实现线上轻量部署;
S6、根据推断得到的用户对物品的点击概率值进行降序排序,将概率值最高的K个物品作为排序结果存储到hbase;
S7、前端在用户登录时,通过接口获取hbase中存储的排序结果,并按顺序进行展示。
具体的,示例过程如下:
1.收集用户与物品的交互记录,包括曝光记录与点击记录,以及用户特征与物品特征。
2.根据交互记录生成两份结构化子数据,包括用户点击物品的序列数据,以及对应的用户特征与物品特征;点击分类样本数据,包括曝光未点击/点击的标签,以及用户特征、物品特征、用户与物品的交互特征。
3.将两份结构化子数据输入本框架的两个子网络,并根据本框架的联合训练方式进行模型学习,设置α为0.2。
4.将3中训练得到的embedding表征及各子网络中的参数保存。
5.在离线服务时,将预测的用户及物品特征输入本框架,输出得到用户对物品的点击率预估值;在线服务时,将预测的用户及物品特征数用户兴趣子网络,输出得到更新的点击率预估值。
6.将点击率最高的TOP100物品降序排序,并作为最终排序结果展示给用户。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于融合特征的文物推荐算法
- 一种融合序列分解和特征选择的组合负荷预测方法