一种双光子钙离子图像神经元胞体分割方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明属于计算机视觉、图像处理技术和神经科学领域,涉及一种双光子钙离子图像神经元胞体分割方法。
背景技术
双光子钙离子成像(Two-Photon Calcium Imaging)是一种广泛用于神经科学研究的技术,它允许科学家在活体中以单细胞分辨率观察神经元活动。该技术的优点包括更深的穿透深度和较低的光散射,使得能在较深的脑组织中进行成像。该技术的实现方式主要有高斯光束(Gaussian beam)和Bessel光束(Bessel beam)两种。高斯光束通常提供较高的横向和轴向分辨率,但由于需要逐点扫描感兴趣体积,成像速率更慢,适合需要高分辨率的应用;Bessel光束由于其特殊的形状(在轴线上有一个非常细长的焦点),在轴向上的分辨率较低,但能够提供更好的深度穿透,允许更快的扫描,在短时间内捕获大范围的活动,同时保持横向分辨率不变。
在成像过程后,第一步通常是从采集到的影像数据中识别神经元胞体(soma)的位置。对于这个任务,常用的算法包括基于图像分割的方法,例如阈值分割、水平集(LevelSets)和一些深度学习方法,特别是卷积神经网络(CNN)。这些方法可以有效地从复杂和噪声背景中识别神经元胞体,并为后续的信号提取和分析提供基础。现有的成熟开源软件,包括Suite2p,CaImAn,则主要运用非负矩阵分解(CNMF)方法,实现从钙离子视频为输入,神经元空间形态和发放信号为输出的数据通道,极大地简化了钙离子数据地处理流程。但无论是基于图像分割的方法,还是基于非负矩阵分解的方法,都有其局限性。
首先,基于非负矩阵分解的方法无法兼顾高效和准确性,一般而言,算法的运行时间会随着数据规模(包括神经元的数量和时间点数量)的增加呈多项式规模的增加,这个问题对于大视场、高密度的神经元视频数据尤为明显。其次,算法对于发放程度较低或远离焦平面(针对Bessel光束成像的数据)的神经元敏感性较低,容易遗漏信号强度较低的神经元导致召回率下降。基于图像分割的方法,尤其是基于卷积神经网络的语义分割方法,输入视频帧的平均图像或最大值投影图像,可以更加快速准确的得到该投影图像上的神经元胞体的掩膜,再结合如分水岭算法等阈值分割的后处理方式,可以得到大部分单细胞的实例分割掩膜,但对于重叠程度较高的神经元,仍无可避免的需要利用非负矩阵分解方法实现重叠细胞的分离。即使将双光子视频在时间维度划分为多个帧块,在各帧块的投影图像上分割神经元,最后合并所有“帧块”上的结果,也无法保证单个帧块上分割得到的神经元没有重叠,尤其是对于Bessel光束采集的数据。
发明内容
为了解决现有技术中存在的上述技术问题,本发明基于形态学检测和深度相关聚类,提供了一种双光子钙离子图像神经元胞体分割方法,其具体技术方案如下:
一种双光子钙离子图像神经元胞体分割方法,包括以下步骤:
S1.采用神经元胞体增强网络,去除双光子钙离子视频中的噪声和神经纤维网背景信号,增强胞体的时空信号,得到胞体增强视频;
S2.运用基于anchor的目标检测器,在胞体增强视频的最大投影图像上检测胞体的位置;
S3.通过相关聚类模块在所述目标检测器输出的各anchor中分割出位于中心的胞体的掩膜。
进一步的,所述神经元胞体增强网络为Double Unet模型,基于3D Unet结构的视频增强网络基础上,增加了一个U-former结构信息提取分支,并设有时空注意力TSA模块。
进一步的,所述视频增强网络的3D Block模块中包含两个3D卷积层,每个3D卷积层后依次接有Relu激活层和Group Normal归一化层;在视频增强网络中,对输入的原始3D视频特征依次进行时间维度和空间维度的卷积操作,去除视频中的噪声和神经纤维网背景信号,得到增强后的3D视频特征;
所述U-former结构信息提取分支采用CBAM模块对输入的2D结构特征筛选重组得到2D空间特征;
所述时空注意力TSA模块将2D空间特征经过张量广播机制Broadcast处理后与增强后的3D视频特征进行相乘融合,将相乘结果经过深度可分的三维卷积,得到胞体增强视频。
进一步的,所述U-former结构信息提取分支以Ground Truth视频的平均图像作为单独的监督信号,与视频增强网络同时训练优化,表达式如下:
V
V
Double Unet模型优化目标为:最小化L1、L2损失以及时序一阶差分损失Temporal,公式表达为:
L1
L2
其中,V
总体损失函数为:
进一步的,所述的基于anchor的目标检测器采用Matrix NMS算法,由YOLOv7目标检测器改进得到。
进一步的,所述的YOLOv7目标检测器的改进,具体为:只保留YOLOv7网络的下采样率为8的最大输出层,去掉下采样倍率为16和32的输出层,同时,采用CIou Loss损失函数约束网络。
进一步的,所述S3的具体内容为:首先取出与所述的目标检测器输出的胞体位置对应的视频块,然后将视频块中的每个像素与其余所有像素计算皮尔逊相关系数,得到一个二维的相关矩阵,最后将该相关矩阵输入Resnet18网络,后输出一个一维向量代表各像素属于中心胞体的概率,设置阈值,获得anchor中心细胞的掩膜。
进一步的,对于目标检测器检测匹配得到的每个神经元胞体真实框L∈R
B
进一步的,对于视频块Bi中的每个像素p,计算它和其他所有像素之间的皮尔逊相关系数γ(p,q),得到一个400维的相关向量,其中,q是除p以外的其他像素:
γ(p,q)=Pearson(B
对所有400个像素做同样的操作,并拼接所有向量,得到一个400×400的相关矩阵P
P
进一步的,将每个相关矩阵P
选择Dice Loss作为Resnet18网络的损失函数:
其中,i是预测和目标张量中的元素索引,smooth设定为常数1,用于平滑梯度和维持数值稳定性;
在推理阶段,将
R
将R
本发明的有益效果:本发明的方法基于有监督的深度学习方法,涉及图像增强、目标检测和聚类,以及信号去混叠方法,兼顾方法驱动和数据驱动的优点,相比传统算法,极大提高了处理数据的效率,对于具有高细胞重叠特点的Bessel成像数据,极大提高了重叠细胞分割的精准程度。
附图说明
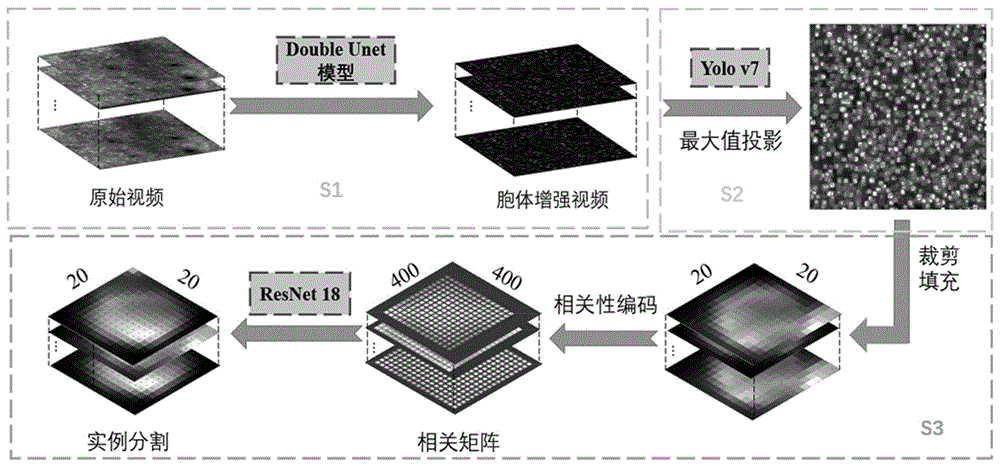
图1是本发明的基于形态学检测和深度相关聚类的双光子神经元胞体分割方法流程示意图。
具体实施方式
为了使本发明的目的、技术方案和技术效果更加清楚明白,以下结合说明书附图和实施例,对本发明作进一步详细说明。
如图1所示,本发明提供的一种基于形态学检测和深度相关聚类的双光子钙离子图像神经元胞体分割方法,具体过程如下:
S1.胞体视频增强:采用神经元胞体增强网络,去除双光子钙离子视频图像中的噪声和神经纤维网背景信号,增强胞体的时空信号,提高后续胞体检测的性能指标。
所述神经元胞体增强网络为Double Unet模型,由两个Unet分支组成,其中的主分支是3D Unet结构,输入原始3D视频数据,输出去噪、去背景的增强视频。主分支中3D Block模块中包含两个3D卷积层,每个3D卷积层后依次接Relu激活层和Group Normal归一化层。由于钙离子视频中细胞的位置不会改变(在配准过后),换言之,视频中神经元的结构信息几乎不随时间变化,并且,尽管单帧图像上的噪声非常大,多帧视频的平均图像却异常清晰,因此,平均图像可为视频增强提供更多的结构先验信息,避免生成结果中出现过多伪影和信号漂移。
所以,本发明在基于3D Unet的视频增强网络基础上,增加一个U-former结构信息提取分支,并设计了时空注意力TSA模块将各尺度上提取到的结构特征图与视频增强主分支融合。首先对原始3D视频特征图依次进行时间维度(一维)和空间维度(二维)的简单卷积,然后在时空注意力TSA模块中,将经卷积后的3D视频特征与U-former结构信息提取分支得到的2D空间特征相乘,将相乘结果经过深度可分的三维卷积并与原始的3D视频特征相加,使训练过程更加稳定,该时空注意力模块功能描述为:
F
=DSConv3d(GN(Relu(conv2d(conv1d(F
其中,F
另外,结构信息提取分支以Ground Truth视频的平均图像作为单独的监督信号,与增强主分支同时训练,使网络在增强胞体特征能力与结构信息提取能力上共同迭代优化。整体网络功能描述为:
V
网络优化目标为最小化L1、L2损失以及时序一阶差分损失,公式表达为:
L1
L2
其中,V
总体损失函数为:
S2.胞体位置检测计数:运用胞体检测器即基于anchor的目标检测器,在增强视频的最大投影图像上检测胞体的位置。
所述的基于anchor的目标检测器由YOLOv7目标检测器改进得到。针对图像中目标尺寸小,尺度单一且高密度的特点,本发明只保留YOLOv7网络的下采样率为8的最大输出层,去掉其余两个下采样倍率为16和32的输出层,提高网络的计算效率。同时,采用CIouLoss损失函数约束网络预测框回归的准确性。由于目标重叠程度高,为了在推理阶段提高非极大值抑制(NMS)的准确性和效率,本发明采用Matrix NMS算法,该算法由Soft NMS目标检测算法改进而来,在保留更多潜在目标的同时提高了算法执行的效率。
S3.胞体实例聚类分割:通过相关聚类模块在胞体检测器输出的各anchor中分割出位于中心的胞体的掩膜。具体而言,取出与胞体检测器输出的位置对应的视频块,将视频中的每个像素与其余所有像素计算皮尔逊相关系数,得到一个相关性矩阵,为二维矩阵,将该二维矩阵输入Resnet18网络,后输出一个一维向量代表各像素属于中心胞体的概率,设置阈值,获得anchor中心细胞的掩膜。
在训练阶段,基于已知的原始的3D视频和视频中神经元胞体的位置标签,在每个神经元胞体的真实框内训练网络。具体来说,对于每个神经元胞体真实框L∈R
B
然后,对于每个像素p,计算它和其他所有像素之间的皮尔逊(Pearson)相关系数γ(p,q),得到一个400维的相关向量,其中,q是除p以外的其他像素:
γ(p,q)=Pearson(B
对所有400个像素做同样的操作,并拼接所有向量,得到一个400×400的相关矩阵P
P
最后,训练了一个小型但高效的ResNet18模型,将每个相关矩阵P
选择Dice Loss作为网络的损失函数:
其中,i是预测和目标张量(已经展平到一维)中的元素索引,smooth设定为常数1,用于平滑梯度和维持数值稳定性。
在推理阶段,将
R
将R
对网络的训练和测试数据做如下说明:在本发明中,用于网络训练和测试的数据均由NAOMi双光子仿真软件生成。一共生成100组尺寸为490*490*1000(x-y-t)的视频数据,每组包括原始带噪视频和对应的去噪、去背景(只仿真神经元,去除所有神经纤维和血管)视频。其中50组视频用于训练神经元胞体增强网络,所有100个去背景视频可生成的1000张最大值投影图像用于训练胞体检测器,用1个原始带噪视频和对应的所有胞体anchor标签训练相关性聚类网络。
发现,即使目标框中存在多个神经元与中心目标重叠,网络依然能够很好地将目标像素聚类出来。网络能够很容易地学习到本发明的设计意图,将属于目标框周围神经元的像素与位于目标框中心的神经元的像素区分开来。实验表明,即使在信噪比较低的数据中,本发明方法依然能够有效地分割出位于荧光显微镜轴向PSF半高宽以内的低信号强度神经元。
以上所述,仅为本发明的优选实施案例,并非对本发明做任何形式上的限制。虽然前文对本发明的实施过程进行了详细说明,对于熟悉本领域的人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行同等替换。凡在本发明精神和原则之内所做修改、同等替换等,均应包含在本发明的保护范围之内。