一种基于bert的字音混合纠错模型
文献发布时间:2023-06-19 09:35:27
技术领域
本发明涉及一种基于bert的字音混合纠错模型。
背景技术
随着信息化建设的不断推进,各级业务部门产生了大量电子公文文档,公文作为企业生产经营的信息资源,公文的文风和质量,反映着企业的工作作风和管理水平。但是在公文写作过程中,由于写作者习惯于连拼输入或者手写输入法易出错等原因,导致错误串在输入文本中占比高达10%-15%。目前,依靠人工纠错文本不但费时费力,还可能导致二次错误。因此,提供实时的无处不在纠错功能,可以最大限度的从源头上切实加强公文内容的质量管理。
BERT作为自然语言表示模型被应用到许多语言理解任务,业界把BERT类的模型迁移到了文本纠错中,并取得了新的最优效果。在公文短文本中,任何汉字的句法和语义解释都高度依赖上下文,而BERT模型拥有很强语言理解的能力。但是由于Bert采用掩码语言模型进行预训练,并且在掩码的时候不再考虑掩码位置的信息,而在实际中文输入过程中,主要拼写错误都是音同或者音似错误,错误位置的拼音信息是非常重要的,因此目前的BERT模型对于纠错任务的效果较差,难以实现工业界可用的标准。
发明内容
为解决上述技术问题,本发明提供了一种基于bert的字音混合纠错模型,该基于bert的字音混合纠错模型能够有效对字符所组成语句中的错别字进行纠正,且便于用于工业界的语法纠错、词性标注等任务中,准确率高、通用性强。
本发明通过以下技术方案得以实现。
本发明提供的一种基于bert的字音混合纠错模型,包括检测网络;检测网络后级有纠错网络,纠错网络采用BERT模型;检测网络指出可能存在错误的字符,纠错网络对可能存在错误的字符进行校正。
所述纠错网络为序列多标注模型。
所述纠错网络还接受原始输入作为输入,且该原始输入和检测网络的输出一一对应。
所述检测网络采用双向循环神经网络模型BiLSTM。
所述检测网络的输入字符数和纠错网络的输出字符数一致。
所述纠错网络后接一前馈网络。
所述检测网络的输出为每个字符存在错误的概率值。
所述纠错网络由十二个相同的块堆叠组成,每个块包含多头及注意力机制。
本发明的有益效果在于:能够有效对字符所组成语句中的错别字进行纠正,且便于用于工业界的语法纠错、词性标注等任务中,准确率高、通用性强。
附图说明
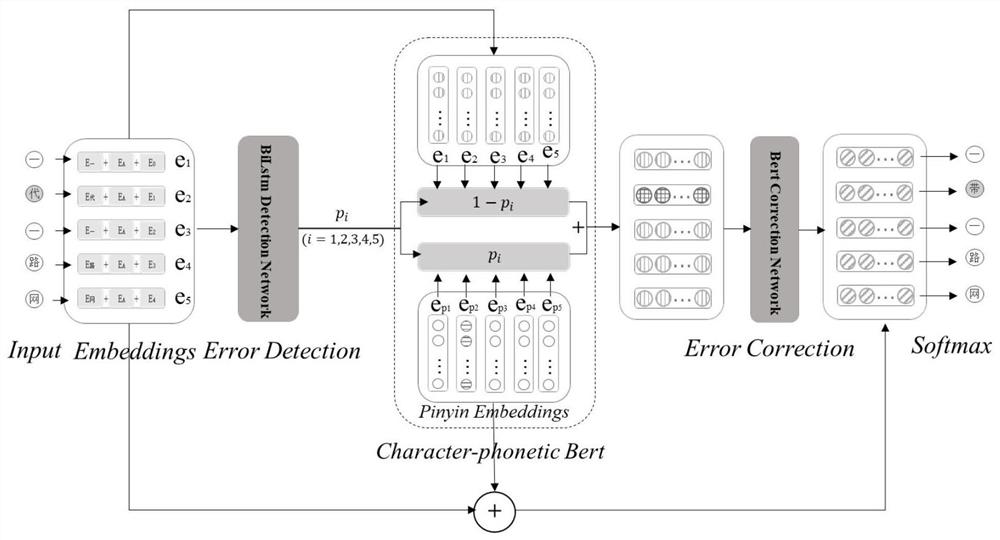
图1是本发明的模型示意图。
具体实施方式
下面进一步描述本发明的技术方案,但要求保护的范围并不局限于所述。
如图1所示的一种基于bert的字音混合纠错模型,包括检测网络;检测网络后级有纠错网络,纠错网络采用BERT模型;检测网络指出可能存在错误的字符,纠错网络对可能存在错误的字符进行校正。
纠错网络为序列多标注模型。
纠错网络还接受原始输入作为输入,且该原始输入和检测网络的输出一一对应。
检测网络采用双向循环神经网络模型BiLSTM。
检测网络的输入字符数和纠错网络的输出字符数一致。
纠错网络后接一前馈网络。
检测网络的输出为每个字符存在错误的概率值。
纠错网络由十二个相同的块堆叠组成,每个块包含多头及注意力机制。
由此,本发明实质上由错误检测网络、错误校正网络组成。
具体而言,检测网络是一个序列的多分类模型,输入是序列嵌入E=(e
e
e
纠错网络是基于BERT的序列多标注模型,输入是Character-phonetic序列嵌入E'=(e
MultiHead(Q;K;V)=Concat(head
head
FFN(X)=max(0;XW
其中,Q、K和V是表示输入序列或前一个块的输出的相同矩阵,MultiHead、Attention以及FFN分别代表多头自注意力、自注意力、前馈网络,W
P
P
实验例1
为了构建错误文本,建立一个混淆字符表:每一个字符其对应的音似混淆集和形近混淆集。下表显示了部分汉字及其相应的混淆集。
在构建含错字文本时,将每个正确文本序列中20%的字符替换为错误字符,由于在实际情况中,人们使用拼写输入法进行文本输入的概率高达97%,错误文本中80%的错误都是拼写错误的同音字,所以错误字符80%来自音似混淆集中,20%的错误字符来自形近混淆集,以此构造出包含错误字符x
(1)首先,对模型的错误检测效果进行评估,在这部分实验中,将上述BiLSTM错误检测网络与统计语言模型Kenlm、神经网络语言模型NNLM的错误检测进行对比,并且在不同大小的训练数据集上观察上述三个方法的性能。实验结果如表1所示:
表1在不同大小数据集上训练后,模型的错误检测效果对比
如表1数据所示在错误检测模块,随着训练数据量的加大各个模型的效果都越好。当训练数据量达到150万篇公文时,本文Character-phonetic BERT模型的精确率为64.3%,相比于Kenlm模型提升了3.1%,相比于RNNLM模型提升了2%;召回率为63.2%,高出Kenlm模型3%左右,高出RNNLM模型2%左右;最终F1值为63.7%,比另外两个模型高出2-3%。
(2)对模型的错误纠正效果进行评估,在这部分实验中将上述Character-phonetic BERT模型与Bret-Finetune进行对比。同样,我们也在不同大小的数据集上进行了实验。实验结果如表2所示:
表2在不同大小的训练集上模型的错误纠正效果对比
由表2中的数据可以看出,同错误检测模块一样,随着训练数据量的增加,模型效果越来越好,最终本文Character-phonetic BERT模型在错误纠正模块精确率P值达到54.9%,高出Bert-Finetune模型1.8%,召回率R值为53.6%,高出Bert-Finetune 3%,最终F1值为54.2%,高出Bert-Finetune模型3%左右。
(3)将上述Character-phonetic BERT模型与Bert-Fintune模型,以及语言模型RNNLM和Kenlm模型进行对比,对模型的整体效果进行测试。实验结果如下表3所示:
表3三种不同方法在同一测试集上的效果对比
由表3数据可以看出,模型的检错纠错整体效果优于其他三个模型。Kenlm模型的本质是统计语言模型模型,受限于上下文窗口大小和以及字符没有出现在统计数据集中的不可预测性(OOV),其最终F1值只达到了47.9%。而BiLM模型解决了传统Kenlm模型OOV的问题,但是由于RNN在学习时存在长距离依赖问题,其最终F1值为50.1%,优于Kenlm 2%左右。而Bert-Fintune引入了attention机制和Multi-head的多角度理解,拥有更强语言理解能力,因此其最终F1值为53.5%,相比于RNNLM模型提升了2%。但是由于bert在掩码时没有考虑当前错误位置本身的信息,但是在实际的错误输入中出现的错误都是音似或形似字错误,错字的原始信息对于错字纠正是非常有用的。由此对错误位置的字音信息进行分析的Character-phonetic BERT模型相比于Bert-Fintune模型性能提升了2%左右,最终F1值达到了54.2%。
由此,本发明的技术方案提供了改进的中文拼写纠错网络结构,具体地应用到中文拼写纠错任务中,模型可称为Character-Phonetic BERT,由检测网络和基于bert的纠错网络构成,检测网络指出一句话中可能存在错误的字符,以及错误字符的Character-Phonetic。纠错网络将Character-Phonetic作为输入,并对其进行纠错,Character-Phonetic是一个比较通用的利用当前位置信息的技术,并具在纠错任务中有潜在的应用价值,实验结果表明,Character-Phonetic Bert明显优于单独使用工业界迄今效果最好的bert。
- 一种基于bert的字音混合纠错模型
- 一种基于纠错策略的CNN-SVM混合模型手势识别方法