一种基于中文字符结构的序列标注方法
文献发布时间:2023-06-19 09:43:16
技术领域
本方法涉及自然语言处理领域,具体涉及一种基于中文字符结构的序列标注方法,为机器翻译、阅读理解、情感感知和知识图谱等自然语言处理应用提供语义和实体特征。
背景技术
随着互联网技术的快速发展,在各类论坛、邮箱或者即时通讯工具中,每天都会产生大量的数据,这些数据由文字、图片、视频或音频等方式构成。在常见的数据类型中,文本数据占了其中很大一部分比例。目前亟需一种能够将文本自动结构化的工具,提取文本中的关键信息,为大数据分析等应用场景提供基础服务。
序列标注就是自然语言处理的常见任务中的一项基础性工作,通常包括了词性标注、命名实体识别、实体链接、关系抽取等任务,还包含了中文分词等针对某种语言的特定任务。通过将文本进行标注的形式,为下游的机器翻译、阅读理解、信息检索、情感分类和知识图谱等任务提供语义特征和语法结构的信息。
近几年硬件技术的发展也推动了自然语言处理任务的研究,显卡对于浮点型数据计算能力的提升减少了很大的神经网络训练所带来的时间支出。
发明内容
本模型的目的在于解决中文序列标注方法中存在的中文特征提取的缺点和不足,提出一种基于中文字符结构的序列标注方法,以实现更有效的提取中文语义信息,提升序列标注准确率的方法。
本发明解决其技术问题所采用的方案是:
一种基于中文字符结构的序列标注方法,包括如下步骤:
步骤1:预处理数据,对无监督训练用语料与监督学习数据集文本进行处理,将字符转化为笔画序列,用空格将每个笔画序列隔开;
步骤2:将步骤1中处理好的语料放入上下文感知的双向LSTM网络中进行无监督训练,得到语言模型;
步骤3:利用迁移学习的方法将将步骤2中训练的语言模型对步骤1中处理好的数据集文本进行特征表示;
步骤4:通过步骤1中的监督学习数据集文本与步骤3中的数据集文本的特征表示对LSTM-CRF序列标注网络进行训练,并保存网络权重参数;
步骤5:利用步骤4所获得的网络权重参数进行序列标注。
本发明有益效果如下:
相比于传统的基于规则和特征的序列标注方法,利用神经网络的序列标注方法能够自动的抽取文本中的语义特征,不需要人工干预,大幅度的减少了人工成本。而目前互联网的迅速发展也缓解了神经网络模型需要大量语料进行模型训练的问题。
本模型将抽取了中文字符中的字形特征和笔画表示特征,通过基于上下文特征的LSTM网络对笔画级别的序列进行语言模型的训练与学习,利用迁移学习的方法将语料中学习到的特征转移至数据集文本中,具有感知上下文的能力,优化了一词多义的能力。通过神经网络能够抽取到更加丰富的上下文笔画信息,也能够解决中文单词的稀疏导致的未收录词的问题。为下游任务提供更加准确的模型向量,提升模型效果。
附图说明
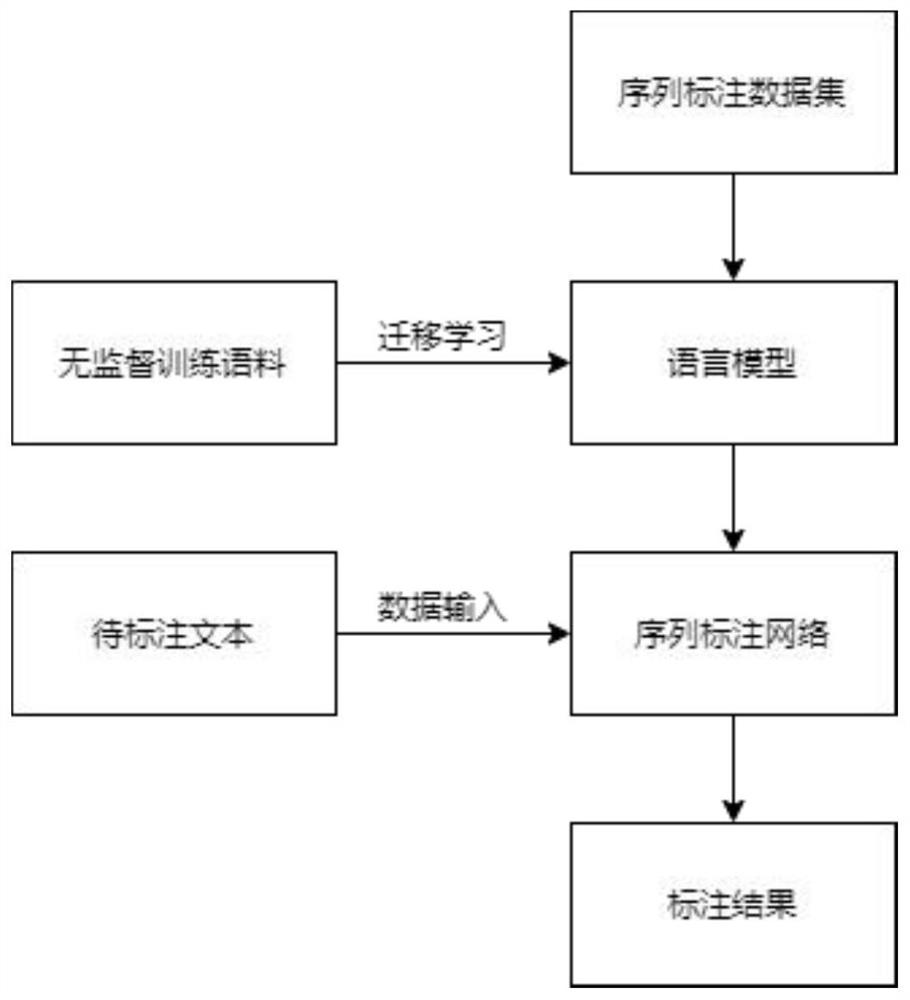
图1为本模型的整体流程图,整体流程分为4个模块,第一模块为序列标注数据集,此模块将预处理好的数据输入到第二个模块语言模型中,利用迁移学习的方式结合大量的无监督训练语料将序列标注数据集中的语义特征抽取出来,此后将提取到的特征传入序列标注网络抽取标签特征,在接受待标注文本后对文本进行标注,得到最终的标注结果。
图2为本模型基于中文字符结构的语言模型模块LSTM网络结构图,首先将数据以传入到字符-笔画映射模块,将得到的笔画序列输入到LSTM网络中,最后根据上下文输出文本对应的特征向量。
具体实施方式
下面结合附图和实施例对本模型作进一步说明。
如图1和2所示,一种基于中文字符结构的序列标注方法,具体实现步骤如下:
步骤1:预处理数据,对无监督训练用语料与监督学习数据集文本进行处理,将字符转化为笔画序列,用空格将每个笔画序列隔开。
1-1.读取字符-笔画映射表;
1-2.使用字符-笔画映射表处理无监督训练用语料;
1-2-1.读取无监督训练用语料,将其拆分为以句子为单元的结构;
1-2-2.通过字符-笔画映射表将每个句子中的字符序列转化为以空格为分隔符的笔画序列;
1-2-3.将处理完的笔画序列保存到指定文件中;
1-3.使用字符-笔画映射表处理监督学习数据集;
1-3-1.读取监督学习数据集,将其拆分为以句子为单元的结构;
1-3-2.验证监督学习数据集中标签的最小单元,若最小单元是单词,将数据集中所有的词切分为字符,进行重新标注,若最小单元是字符,则不进行处理;
1-3-3.将处理好的数据集文本保存到指定文件中;
例如,单词级数据集文本格式如下:
我O;参与O;了O;南B-GPE;都I-GPE;深圳B-GPE;读本O;发起O;的O;投票O;
将单词文本切分后的字符级数据集格式为:
我O;参O;与O;了O;南B-GPE;都I-GPE;深B-GPE;圳I-GPE;读O;本O;发O;起O;的O;投O;票O;
步骤2:将步骤1中处理好的语料放入上下文感知的双向LSTM网络中进行无监督训练,得到语言模型;
2-1.将步骤1中处理后的无监督训练语料以句子为单位依次传入上下文感知的双向LSTM网络中,进行2轮迭代;
2-2.将2轮迭代后的LSTM网络参数保存到语言模型权重文件中;
如图2所示,所述的上下文感知的双向LSTM网络具体结构和实现如下:
该双向LSTM网络由前向LSTM网络与后向LSTM网络拼接而成。将中文字符序列通过字符-笔画映射表转化为对应的笔画序列后,将该序列传入LSTM网络。其中,前向LSTM网络提取笔画序列结束时的向量(如实线所示),后向LSTM网络提取笔画序列前的向量(如虚线所示),将两个单向网络的特征向量进行拼接,拼接后的向量作为该笔画序列对应字符的最终特征。
步骤3:利用迁移学习的方法将将步骤2中训练的语言模型对步骤1中处理好的数据集进行特征表示;
3-1.加载步骤2中训练完成的语言模型权重文件;
3-2.加载步骤1中处理完成的监督学习数据集;
3-2-1.分别加载数据集中的文本数据部分与标注标签部分;
3-2-2.将加载的文本数据利用语言模型将文本数据转化为包含语义信息的特征向量;
3-2-3.将获得的特征向量与对应的标注标签进行关联,获得数据集特征表示;
3-2-4.将所有获得数据集特征表示按8:1:1的比例进行切分,分成训练集、验证集和测试集;
步骤4:通过步骤1中的监督学习数据集与步骤3中的数据集特征表示对LSTM-CRF序列标注网络进行训练,并保存网络权重参数;
4-1.将步骤3中分割的训练集中关联后的特征向量和标注标签以句子为单位传入LSTM-CRF网络中进行标签特征提取;
4-2.利用步骤3中分割的验证集进行损失计算与性能验证;
损失计算选择了交叉熵损失,F1值作为性能验证评价指标。
其中,交叉熵损失和性能验证评价指标均是现有成熟技术。
4-3.迭代操作步骤4-1与4-2,直至步骤4-2中计算的损失连续5次迭代不下降;
4-4.终止迭代,保存LSTM-CRF网络模型权重参数;
步骤5:利用步骤4所获得的网络权重参数进行序列标注;
5-1.加载步骤4中保存的LSTM-CRF模型权重参数;
5-2.利用字符-笔画映射表处理待标注新文本;
5-2-1.将待标注新文本切分成字符序列,每个字符之间用空格分隔;
5-2-2.将分隔之后的待标注新文本通过字符-笔画映射表转化为以空格为分隔符的笔画序列;
5-3.将分隔完的笔画序列输入步骤3保存的语言模型中获得特征向量;
5-4.将该特征向量利用步骤4中保存的LSTM-CRF网络模型权重参数进行序列标注,得到预测结果;
进一步的,步骤1中的字符-笔画映射表如下:
确定25个细粒度笔画,包括:
一(横);(提);丨(竖);(竖勾);(竖撇);丿(撇);丶(点);(捺);(斜勾);(横折);(横撇);(竖提);(横折弯);(撇折);(竖弯钩);(横折折折勾);(横折勾);(竖折弯勾);(竖折);ㄣ(竖折折);(横折弯);(撇折);(横折提);(横折折撇);(横折折折);
进一步的,步骤2具体实现如下:
语言模型训练的目标函数:
语言模型的双向LSTM网络表示:
实验中,网络结构设置的超参数如下:选用随机梯度下降优化器,学习率设为0.001;batch_size设为16;语言模型LSTM网络层数1层,隐藏层节点数2048;。
本发明所提出的结构加入了中文字符结构的特征,并通过LSTM网络迁移学习的方式利用特征信息,提高了序列标注的准确率和F1值。
- 一种基于中文字符结构的序列标注方法
- 基于图像处理与序列标注的学术文献语义再结构化方法