一种基于神经网络的设备状态实时监测与异常探测方法
文献发布时间:2023-06-19 09:46:20
技术领域
本发明属于设备监测技术领域,具体涉及一种基于神经网络的设备状态实时监测与异常探测方法。
背景技术
设备状态监测与异常探测的技术方案可以分为两个思路,基于物理模型和基于经验模型的状态监测与异常探测。
基于物理模型的监测预警:如果对于设备或者故障的物理机理有着深入的理解,并建立有刻画设备正常状态的物理模型,那么就可以基于该模型及其相关的输入变量来判定设备是否已经偏离了其正常运行工况。物理模型的优势在于其是可解析的,结果的可解释度高,适用范围广,且应用得当的话结果非常精确;其劣势在于对于大型复杂系统的物理模型往往缺失,建模难度高,模型求解计算量大,由于很多简化及假设的存在,计算结果的偏差往往也会比较大。
基于经验模型的监测预警:该思路不依赖于我们对故障机理模型的深入理解,从设备的历史运行数据和运行经验出发,判定设备是否发生异常。该思路包括两类方法,参数模型法和非参数模型法:参数模型法利用历史数据得到回归拟合模型的参数,以拟合模型作为异常判定的基准,代表方法如线性回归、神经网络法等;非参数模型法通过特定算法将当前运行状态和历史状态存储数据进行比对,进而发现异常情况的出现,代表方法有自相关核回归(AAKR)、多参数状态评估技术(MSET)等。
状态监测预警中待解决的难点体现在四个方面:监测方法的实时性、算法模型的适用性、评估结果的前瞻性、虚警与漏警的平衡。具体而言,一是当前的很多监测手段尚无法做到对运行数据的实时分析处理并及时给出判定结果;二是算法模型有时包含一些个体性很强的参数,导致针对一个设备的算法模型很难迁移到其他类型或个体的设备上;三是监测评估结果目前难以做到在故障初期就给出提醒或者警报,致使预警的意义明显降低,对降低设备故障率的发生也难以起到作用;四是虚警与漏警的平衡,这既需要提高异常探测方法的灵敏度和精度也需要算法能够自适应的调整其对异常状态的判定标准。
发明内容
鉴于以上存在的技术问题,本发明用于提供一种基于神经网络的设备状态实时监测与异常探测方法。
为解决上述技术问题,本发明采用如下的技术方案:
一种基于神经网络的设备状态实时监测与异常探测方法,记部件正常运行状态下重构模型预测残差的分布为r
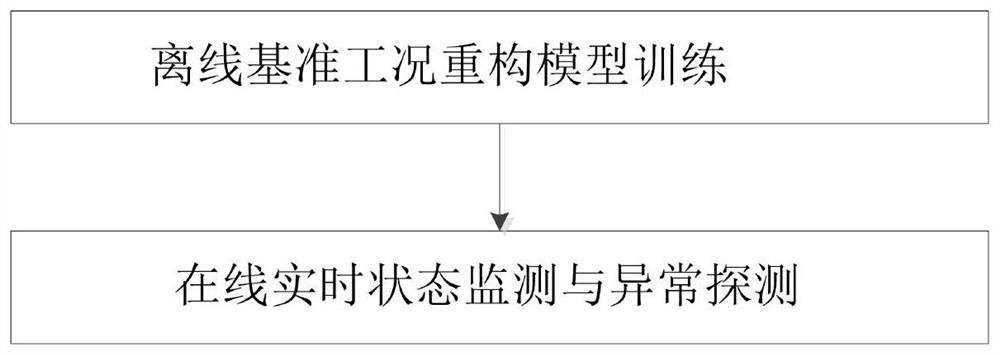
步骤1,离线基准工况重构模型训练,进一步包括:
步骤101,数据收集,选取正常运行阶段的数据作为基准运行工况数据;
步骤102,对收集的原始数据进行加工,主要包括数据清洗、特征提取、特征选择、数据归一化;
步骤103,将处理后的数据分为两个子集:模型训练集与模型测试集,基于训练数据和选定的建模算法建立信号重构模型;
步骤104,将训练得到的重构模型应用于测试集,得到模型预测值与实际工况观测值残差的分布;
步骤105,计算测试集残差分布的均值μ*、方差σ*2、90%分位点δ*统计量,将这些统计量存储下来,作为后续异常识别的参考基准;
步骤2,在线实时状态监测与异常探测,进一步包括:
步骤201,实时计算重构模型预测值和在线观测值的残差;
步骤202,统计异常判定时点前一段固定时长内的预测残差,确保该固定时长内有足够的数据样本,计算预测残差的均值μ、方差σ
步骤203,根据定义计算包括偏离度指标DI、波动度指标VI、显著性指标SI、偏离概率PDI、波动概率PVI、显著概率PSI的指标量,其中,偏离度指标DI用于衡量预测残差分布均值偏离程度的标准分数,其定义公式如(1)所示:
波动度指标用于衡量预测残差分布方差偏离程度的F统计量,其定义如(2)所示:
显著度指标用于衡量预测残差分布中大于某一设定阈值的样本的比例,其定义公式如(3)所示:
SI=P(r≥δ
偏离概率用于反映残差分布的均值偏离基准运行状态的概率,其定义公式如(4)所示:
PDI=2·Φ(DI)-1 (4)
其中Φ(·)是标准正态分布的累计分布函数;
波动概率用于反映残差分布的方差偏离基准运行状态的概率,由于F检验常用于方差检验,波动概率PVI的定义如公式(5)所示,其中F(VI,n,n
PVI=F(VI,n,n
显著概率用于反映残差分布中有较多大残差值出现时部件发生异常的概率,选取双曲正切函数tanh(·)作为显著度指标SI的激活函数,显著概率PSI的定义如公式(6)所示。
显著概率PSI定义中的比例因子α可以由用户自己设定,其作用是抑制虚警率,虚警抑制因子α的数值越大,PSI的值越小,发生虚警的概率越低,通常情况下,为了平衡PSI对异常探测的灵敏度和对虚警的抑制,建议将α设为0.1(当δ*为90%分位点)或0.05(当δ*为95%分位点);
步骤204,进行信息融合,得到单一部件实时运行状态的健康度指标HI,健康度指标的定义如公式(7)所示:
HI=PDI*PVI*PSI (7)。
优选地,数据清洗中采用切比雪夫不等式方法剔除样本中异常点。
优选地,采用缩放法进行数据归一化。
优选地,进一步包括,通过上述方法得到设备N个部件的健康度指标HI,进而估计设备的整体健康度指标integral-HI,其定义公式如下:
其中HI
采用本发明具有如下的有益效果:
(1)相比于设定固定判定阈值的YES/NO式的异常判断方法,定义的健康度指标均为刻画异常发生可能性的概率量,能够为运维人员提供异常状态发生的可能性和时间演变信息,而不仅仅告诉运维人员当前是否发生异常,运维人员有一定的自主权来根据自身使用经验判定;
(2)对于某一特定故障,不同维度的诊断指标能提供更多的异常判定依据,提出的概率化指标体系能够很容易的将各维度的诊断信息进行融合,同时兼顾虚警和漏警问题;
(3)概率化的指标体系让不同部件间的比较更加直观,包括故障概率和时间先后,这在多个部件的报警信号同时出现时的优势更加明显,能够帮助运维人员快速定位故障点及故障顺序,及时找出根原因并给出故障诊断结果;
(4)概率化的部件健康度指标能进一步融合成表征系统或设备整体健康状态的指标量,让系统的健康状态表征更加直观;
(5)所提指标是通过判定是否偏离基准状态来识别异常,而不仅仅是当异常发展到一定程度时才触发报警,识别精度较高,使得对早期异常和细微异常的发现成为可能;
(6)给出的异常判定指标中基本不需要设置或调整参数,对运行经验和专家知识的依赖程度很低,结果的可解释性更高。
附图说明
图1为本发明实施例的基于神经网络的设备状态实时监测与异常探测方法的步骤流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
参照图1,所示为本发明实施例的基于神经网络的设备状态实时监测与异常探测方法的步骤流程图,记部件正常运行状态下重构模型预测残差的分布为r
步骤1,离线基准工况重构模型训练,进一步包括:
步骤101,数据收集,选取正常运行阶段的数据作为基准运行工况数据;
步骤102,对收集的原始数据进行加工,主要包括数据清洗、特征提取、特征选择、数据归一化;
步骤103,将处理后的数据分为两个子集:模型训练集与模型测试集,基于训练数据和选定的建模算法建立信号重构模型;
步骤104,将训练得到的重构模型应用于测试集,得到模型预测值与实际工况观测值残差的分布;
步骤105,计算测试集残差分布的均值μ*、方差σ*2、90%分位点δ*统计量,将这些统计量存储下来,作为后续异常识别的参考基准;
步骤2,在线实时状态监测与异常探测,进一步包括:
步骤201,实时计算重构模型预测值和在线观测值的残差;
步骤202,统计异常判定时点前一段固定时长内的预测残差,确保该固定时长内有足够的数据样本,计算预测残差的均值μ、方差σ
步骤203,根据定义计算包括偏离度指标DI、波动度指标VI、显著性指标SI、偏离概率PDI、波动概率PVI、显著概率PSI的指标量,其中,偏离度指标DI用于衡量预测残差分布均值偏离程度的标准分数,其定义公式如(1)所示:
波动度指标用于衡量预测残差分布方差偏离程度的F统计量,其定义如(2)所示:
显著度指标用于衡量预测残差分布中大于某一设定阈值的样本的比例,其定义公式如(3)所示:
SI=P(r≥δ
偏离概率用于反映残差分布的均值偏离基准运行状态的概率,其定义公式如(4)所示:
PDI=2·Φ(DI)-1 (4)
其中Φ(·)是标准正态分布的累计分布函数;
波动概率用于反映残差分布的方差偏离基准运行状态的概率,由于F检验常用于方差检验,波动概率PVI的定义如公式(5)所示,其中F(VI,n,n
PVI=F(VI,n,n
显著概率用于反映残差分布中有较多大残差值出现时部件发生异常的概率,选取双曲正切函数tanh(·)作为显著度指标SI的激活函数,显著概率PSI的定义如公式(6)所示。
显著概率PSI定义中的比例因子α可以由用户自己设定,其作用是抑制虚警率,虚警抑制因子α的数值越大,PSI的值越小,发生虚警的概率越低,通常情况下,为了平衡PSI对异常探测的灵敏度和对虚警的抑制,建议将α设为0.1(当δ*为90%分位点)或0.05(当δ*为95%分位点);
步骤204,进行信息融合,得到单一部件实时运行状态的健康度指标HI,健康度指标的定义如公式(7)所示:
HI=PDI*PVI*PSI (7)
为了使本领域技术人员更好的理解本发明实施例的实施过程和有益效果,以下进一步结合具体应用场景进行说明。
为了提高重构模型法中异常判定在早期故障的识别、虚/漏警平衡上的不足,本发明实施例创新性的构建了一组可以高精度识别信号异常状态的指标体系。构建这些指标的基本假设在于认为部件正常运行状态下重构模型预测残差分布较为稳定,异常运行状态下重构模型预测残差的分布将和其正常运行状态下的残差分布不同,通过衡量重构模型预测残差分布的偏离程度来判定部件是否处于异常状态及其可能性或严重程度。
将以上设置的技术方案应用于基于某电力集团风力发电机组轴承等旋转部件超温预警的实际应用场景案例进行验证。
风力发电机组是将风的机械能转换为电能的设备,一个风力发电机组的系统通常包括的部件依次是:叶片、主轴、齿轮箱高速转轴轴承、发电机驱动端轴承、风速仪、机舱、电力输出线、发电机非驱动端轴承、发电机、齿轮箱。此外,风力发电机组还包括偏航系统、液压系统、冷却系统等重要部件。
风力发电机组通常都安装有数据采集和监视控制(Supervisory Control andDataAcquisition,SCADA)系统以实现对机组状态的掌握,SCADA能给出风电机组各监测参数的实时数据,并根据设定的报警阈值给出报警信号。在本案例所用机组的SCADA数据库中,存储有200多个观测信号过去数年的运行数据,这些信号的采样频率为每5分钟一次。SCADA系统为重构模型的建立提供了充足的样本数据,同时其给出的系统报警也为模型验证提供了比较基准。
发电机驱动端轴承温度超温停机(generator drive end bearing temperaturehigh stop,DETHS)故障是系统中常见的故障类型。故应用中从SCADA数据库众多的监测信号中挑选了与超温故障相关的信号,以期利用这些信号来建立正常状态的重构模型,这些信号既包括直接的温度信号,也包括与温度信号可能有关的功率、转速、偏航角度等信号,具体包括:发电机驱动端轴承温度、非驱动端轴承温度、齿轮箱高速轴承温度、齿轮箱油过滤器压力、主轴轴承温度、机舱温度、室外温度、输出功率、主轴转速和叶片偏转角度。
SCADA系统实际采集的信号中存在一定的噪声和异常点,在正式利用这些数据进行重构模型建模前需要对这些原始信号进行一定的处理,包括数据清洗、数据归一化、特征选择等,以提高数据利用的效率和模型计算速度、减少信息冗余。
(1)数据清洗
数据清洗(data cleansing)的目的是修正或剔除样本数据中不精确或不相关的记录,本发明实施例中选取切比雪夫不等式(Chebyshev inequality)方法作为剔除样本中异常点的技术手段。根据切比雪夫不等式,在任一个均值为μ、方差为σ
切比雪夫不等式进行数据异常点去除的前提是确定信号的均值和方差,针对实时测量信号均值和方差不恒定的问题,本发明实施例采用自适应的信号均值和方差确定方式,即用当前时刻点前一段时间(如1周、1天、1小时)内的信号片段的均值和方差作为切比雪夫不等式的对应参数。
对于参考信号片段时长以及参数λ的选择,本发明实施例中基于正常运行工况下驱动端轴承温度信号的实际测量数据对比了几种不同参数组合下的数据异常点去除效果。λ越大、参考信号片段选取时长越短,异常点的判断标准较松,数据异常点剔除的比例越低,但这存在异常点仍未被全部清除的风险;λ越小、参考信号片段选取时长越长,异常点的判断标准越严格,数据异常点剔除的比例提升,但存在丢失部分正常数据的风险。实际的参数选择必须在这两种风险中取得一定的平衡,且要考虑到信号片段中有一定数量的样本保证参数的前后一致性。在发明实施例中选择了一组较为严格的参数组合用来数据异常点剔除,即设定参考信号片段时长为1周、设定λ=3。
(2)数据归一化
原始数据中各信号的类型和数值差异很大,甚至存在数个量级上的差异,直接采用这些数据进行建模时,量级小的信号存在被忽略的可能。数据归一化(datanormalization)的主要作用是将原始数据中各维度的信号都归一到统一的数值区间,方便数据间的横向比较。数据归一化的方式有很多种,缩放(rescaling)、均值归一化(meannormalization)、标准差归一化(standardization)等线性归一化和非线性归一化方法都可以采用,本发明实施例采用的数据归一化方法是缩放法,将所有的信号都缩放到[01]区间,具体的计算如公式(9),其中S表示单一信号的整个数据集,s表示原始数据,s
(3)特征选择
为了减少模型复杂度、提高重构模型的建模效率,本发明实施例中还进一步采取了特征选择(feature selection)手段对上述初步挑选出来了的信号数据进行二次选择,从中选取一部分信号作为建模输入。采用了相关分析方法计算了驱动端轴承温度信号和其他信号间的相关关系,表3.3列出了驱动端轴承温度信号和其他信号之间的相关系数,并从高到低进行了排序,本发明实施例选取了相关度较高的7个信号作为建模的输入,分别是非驱动段轴承温度、主轴轴承温度、机舱温度、齿轮箱高速转轴轴承温度、齿轮箱油过滤器压力、叶片转速、输出功率、偏航角度等。
考虑到部件当前时刻的温度和其自身的历史温度也有一定的自相关性,在建模中需要将过往温度信息考虑进去。本发明实施例中采用了滑动时间窗的技术来将信号的历史信息考虑进去,来提高模型预测的精度。时间窗长度的选择可以通过对信号的自相关分析来确定。本发明实施例中选取的时间窗口长度为120分钟,一是因为超过120分钟后相关系数的变化逐渐平缓,二是更长的时间窗口将带来更多的模型输入维度,模型复杂度以及建模需要的计算时间和计算资源都会更大。
实施例2
实施例1通过对设备单一部件的基于数据重构的设备异常状态检测方法进行了详细的说明。但对于一个设备或者系统,其往往包含多个部件,对于大多数的时间设备或系统都运行在正常状态,在工程实际应用中,首先最需要显示的是设备或系统整体的健康状态,而不需要同时对多个部件的实时状态进行显示。
对设备或系统整体的健康状态进行评估并得出其健康度指标有诸多的好处:一是方便同时对多个设备或包含多个设备的系统的监测跟踪,;二是部分单一监测信号的异常可能对设备的安全运行影响不大,但如果设备的多个监测信号出现异常则需要引起重视,监测系统需要具备融合分析多个信号的能力;三是某一故障的出现可能会同时触发多个报警信号,短时间内多个报警信号的出现可能会运维人员的决策判断造成干扰,需要对这些单一信号进行合理的组织以避免信息干扰。
在实施例1单一部件健康状态监测的基础上,实施例2提出一种适用于设备或系统整体健康状态监测的方法。该方法的核心是构建基于单一部件健康度指标的设备整体健康度指标(integral Health Index,integral-HI),部件健康度指标HI的计算可以直接参考实施例1的方法,整体健康度指标integral-HI的计算如公式(10)所示,其中HI
应当理解,本文所述的示例性实施例是说明性的而非限制性的。尽管结合附图描述了本发明的一个或多个实施例,本领域普通技术人员应当理解,在不脱离通过所附权利要求所限定的本发明的精神和范围的情况下,可以做出各种形式和细节的改变。
- 一种基于神经网络的设备状态实时监测与异常探测方法
- 一种基于北斗的车辆异常状态实时监测装置