临床试验收费单据的识别方法和识别装置
文献发布时间:2023-06-19 09:52:39
技术领域
本发明主要涉及临床医学及试验领域,具体地涉及一种临床试验收费单据的识别方法和识别装置。
背景技术
在临床试验领域,通过对大量的受试者进行数据采集,可以分析特定药物或方法的效果。在传统的临床试验中,受试者可以就临床试验中的一些费用申请报销,或者获得补贴等。随着互联网技术的广泛应用,现代临床试验研究多采用多项目、多中心的临床试验管理方式,可以通过互联网和移动互联网的方式进行信息录入和款项发放等。这样,就需要受试者或者临床研究协调者(CRC,Clinical Research Coordinator)将所要提交的收费单据录入到临床试验管理系统中。然而手工录入的过程繁琐,对于数据量巨大的临床试验研究,手工录入的错误率也较高。此外,来自不同医院的收费单据的收费项目名称不统一,所记录的数据格式也不统一,对于后续的数据管理和分析造成了一定的障碍,降低了临床试验的效率。
发明内容
本发明所要解决的技术问题是提供一种标准化的临床试验收费单据的识别方法和装置。
本发明为解决上述技术问题而采用的技术方案是一种临床试验收费单据的识别方法,其特征在于,包括:接收收费单据图像;采用光学文本识别技术识别所述收费单据图像,从所述收费单据图像中提取多个文字块,所述文字块的信息包括所述文字块的内容和坐标;根据所述多个文字块的坐标计算每个所述文字块与其周围的其他文字块的相对位置关系;比较所述文字块的内容和临床试验随访任务库中的收费项目名称,获得候选收费项目名称文字块;根据所述文字块的相对位置关系确定所述候选收费项目名称文字块右侧的第一文字块组,若所述第一文字块组中包括金额文字块,则判断所述候选收费项目名称文字块为正式收费项目名称文字块;生成第二文字块组,所述第二文字块组包括所述正式收费项目名称文字块和所述金额文字块;以及对所述第二文字块组进行标准化处理,将所述正式收费项目名称文字块的内容转换为标准收费项目名称,并且将所述金额文字块的内容转换为标准金额。
在本发明的一实施例中,根据所述多个文字块的坐标计算每个所述文字块与其周围的其他文字块的相对位置关系的步骤包括:生成文字块集合,所述文字块集合中包括所有文字块的坐标;根据每个文字块的纵坐标排序,得到所有文字块的有序列表;以及在所述有序列表中按照顺序处理每个所述文字块,得到每个文字块的上、下、左、右四个方向的相邻文字块。
在本发明的一实施例中,在所述有序列表中按照顺序处理每个所述文字块的步骤包括:步骤S31:以所述有序列表中的第一个文字块作为第一锚点;步骤S32:在所述有序列表中搜索所述第一锚点右侧的文字块,以所述第一锚点右侧的文字块为第二锚点,并将搜索结果记录在所述第一锚点的数据结构中;步骤S33:在所述文字块集合中搜索与所述第二锚点上下相邻的文字块,并将搜索结果记录在所述第二锚点的数据结构中;步骤S34:在所述有序列表中搜索所述第二锚点右侧的文字块,若有则删除所述第二锚点,并将所述第二锚点右侧的文字块作为新的第二锚点,重复执行步骤S33-S34,直到所述第二锚点右侧没有文字块;步骤S35:在所述有序列表中搜索所述第一锚点左侧的文字块,以所述第一锚点左侧的文字块为第三锚点,并将搜索结果记录在所述第一锚点的数据结构中;步骤S36:在所述文字块集合中搜索与所述第三锚点上下相邻的文字块,并将搜索结果记录在所述第三锚点的数据结构中;步骤S37:在所述有序列表中搜索所述第三锚点左侧的文字块,若有则删除所述第三锚点,并将所述第三锚点左侧的文字块作为新的第三锚点,重复执行步骤S36-S37,直到所述第三锚点左侧没有文字块;步骤S38:在所述有序列表中删除所述第一锚点、第二锚点和第三锚点;以及步骤S39:重复执行步骤S31-38,直到所述有序列表为空。
在本发明的一实施例中,所述文字块的数据结构中包括记录与所述文字块在上、下、左、右四个方向的相邻文字块的字段。
在本发明的一实施例中,比较所述文字块的内容和临床试验随访任务库中的收费项目名称的步骤包括:将所述临床试验随访任务库中的收费项目名称拆分成长度相等的第一字段;将所述文字块的内容拆分成与所述第一字段的长度相等的第二字段;以及比较所述第一字段和第二字段。
在本发明的一实施例中,采用2-gram方法对所述临床试验随访任务库中的收费项目名称和所述文字块进行拆分。
在本发明的一实施例中,对所述第二文字块组进行标准化处理的步骤包括:根据下面的公式计算匹配分match_score:match_score=1-(max_len-cross_distance(str1,str2)+Lev_distance(str1,str2))/(max_len*2),其中,str1是所述第二文字块组中的一个文字块的内容,str2是标准术语库中的标准术语,max_len是str1和str2中的长度的最大值,cross_distance(str1,str2)指str1的字符集合和str2的字符集合的交集的元素个数,Lev_distance(str1,str2)指str1和str2的莱文斯坦距离。
在本发明的一实施例中,还包括:比较所述文字块的内容和临床试验随访任务库中的医保类型关键字,判断所述文字块是医保类型文字块;以及将所述医保类型文字块转换为标准医保类型。
在本发明的一实施例中,所述收费项目名称包括费用类型,所述费用类型包括检查费、治疗费、药费中一项或任意项的组合。
本发明为解决上述技术问题还提出一种临床试验收费单据的识别装置,包括:存储器,用于存储可由处理器执行的指令;处理器,用于执行所述指令以实现如上所述的识别方法。
本发明为解决上述技术问题还提出一种存储有计算机程序代码的计算机可读介质,所述计算机程序代码在由处理器执行时实现如上所述的识别方法。
本发明可以从收费单据图像中识别出需要录入临床试验管理系统的收费项目名称文字块、金额文字块等,并根据标准术语库将这些文字块转换为符合标准的标准收费项目名称、标准金额,对从不同数据来源的不同收费单据所提取到的收费信息进行统一标准化,使这些收费信息可以更加方便高效地应用于临床试验研究。
附图说明
为让本发明的上述目的、特征和优点能更明显易懂,以下结合附图对本发明的具体实施方式作详细说明,其中:
图1是本发明一实施例的临床试验收费单据的识别方法的示例性流程图;
图2是本发明一实施例的临床试验收费单据的识别方法中的收费单据图像的示意图;
图3A-3C是本发明一实施例的临床试验收费单据的识别方法中计算文字块的相对位置关系的过程示意图;
图4A和4B是本发明一实施例的临床试验收费单据的识别方法中的搜索相邻文字块的示意图;
图5是本发明一实施例的临床试验收费单据的识别方法中对收费项目名称进行拆分的示意图;
图6是本发明另一实施例的收费单据图像的示意图。
具体实施方式
为让本发明的上述目的、特征和优点能更明显易懂,以下结合附图对本发明的具体实施方式作详细说明。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其它不同于在此描述的其它方式来实施,因此本发明不受下面公开的具体实施例的限制。
如本申请和权利要求书中所示,除非上下文明确提示例外情形,“一”、“一个”、“一种”和/或“该”等词并非特指单数,也可包括复数。一般说来,术语“包括”与“包含”仅提示包括已明确标识的步骤和元素,而这些步骤和元素不构成一个排它性的罗列,方法或者设备也可能包含其他的步骤或元素。
本申请中使用了流程图用来说明根据本申请的实施例的系统所执行的操作。应当理解的是,前面或下面操作不一定按照顺序来精确地执行。相反,可以按照倒序或同时处理各种步骤。同时,或将其他操作添加到这些过程中,或从这些过程移除某一步或数步操作。
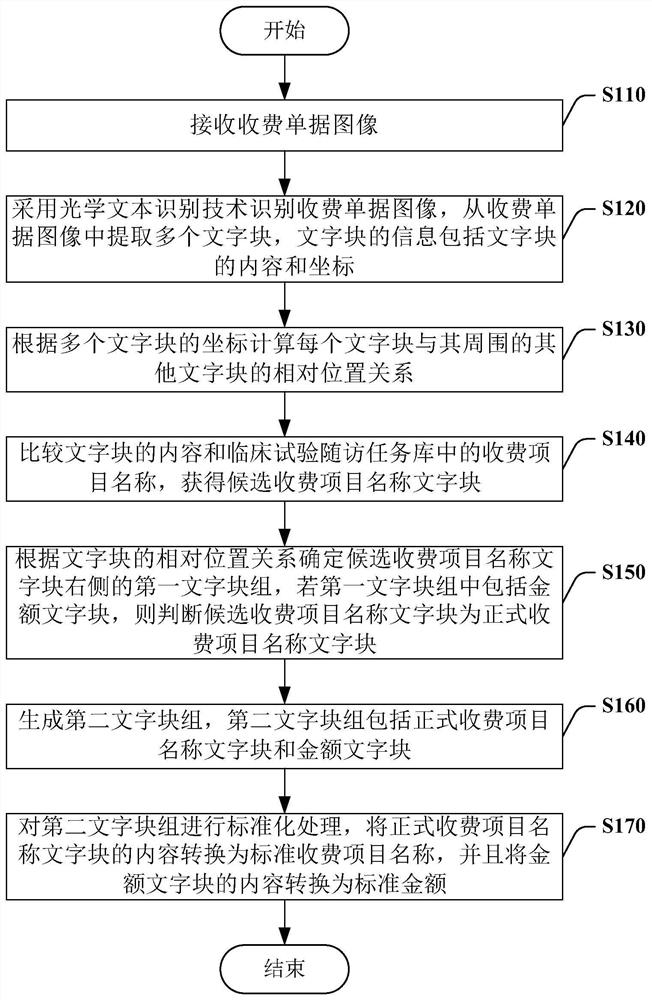
图1是本发明一实施例的临床试验收费单据的识别方法的示例性流程图。参考图1所示,该实施例的收费单据的识别方法包括以下步骤:
步骤S110:接收收费单据图像;
步骤S120:采用光学文本识别技术识别收费单据图像,从收费单据图像中提取多个文字块,文字块的信息包括文字块的内容和坐标;
步骤S130:根据多个文字块的坐标计算每个文字块与其周围的其他文字块的相对位置关系;
步骤S140:比较文字块的内容和临床试验随访任务库中的收费项目名称,获得候选收费项目名称文字块;
步骤S150:根据文字块的相对位置关系确定候选收费项目名称文字块右侧的第一文字块组,若第一文字块组中包括金额文字块,则判断候选收费项目名称文字块为正式收费项目名称文字块;
步骤S160:生成第二文字块组,第二文字块组包括正式收费项目名称文字块和金额文字块;以及
步骤S170:对第二文字块组进行标准化处理,将正式收费项目名称文字块的内容转换为标准收费项目名称,并且将金额文字块的内容转换为标准金额。
以下对上述步骤逐一进行说明。
本实施例的临床试验收费单据的识别方法在步骤S110中接收收费单据图像。本发明对该收费单据图像的格式、参数等不做限制。收费单据图像可以是照片或任意格式的图片,包括但不限于bmp,jpg,png,tif,gif,pcx,tga,exif,fpx,svg,psd,cdr,pcd,dxf,ufo,eps,ai,raw,WMF,webp等。收费单据图像的参数可以包括分辨率、大小、色度、亮度等。本发明对于收费单据的类型不做限制,该收费单据可以是临床试验研究中所涉及到的任意收费票据、发票、收据、补贴单等。该收费单据中至少需要包括收费项目名称和金额。
本发明的临床试验收费单据的识别方法可以用于临床试验的过程中,从其上游的流程接收收费单据图像,并将经过本发明的识别方法进行电子化和标准化处理的收费单据内容传递到下游的流程中。本发明对于上游流程和下游流程的具体内容不做限制。
图2是本发明一实施例的临床试验收费单据的识别方法中的收费单据图像的示意图。图2示出了某收费单据图像的一部分,而不是全部。可以理解,本发明的识别方法可以用于识别收费单据的部分或全部。
本实施例的识别方法在步骤S120中采用光学文本识别技术(Optical CharacterRecognition,OCR)识别收费单据图像。本发明采用OCR技术从步骤110中所接收到的收费单据图像中提取到的基本单元是文字块。每个文字块的信息包括该文字块的内容和坐标。
参考图2所示,该收费单据图像200包括大标题“收费票据”,“医保类型”,以及具体的收费项目名称、数量、金额等内容。本发明的识别方法在步骤S120可以对该收费单据图像200中的所有文字块进行识别。
为了获取收费项目名称和相应的金额,在步骤S120主要识别该收费单据图像200中包括收费项目名称和金额在内的文字块,例如图中“项目名称”对应文字块211,与该文字块211同列的文字块221、231、241都是收费项目名称文字块;“金额”对应文字块213,与该文字块213同列的文字块223、233、243都是金额文字块。其中,文字块211、212、213属于标题行,其余的文字块则是相应的具体内容行。
图中用实线方框表示所识别到的文字块的边框,该实线方框并不是收费单据图像200中的图像。
需要说明,文字块的内容可以包括文本、数字、符号或特殊字符。文本包括中文、英文等计算机系统可以识别的语言种类。在收费单据中,收费项目名称中通常包括文本;金额通常是数字,也可能包括作为单位的文本,例如“元”,或者特殊字符“€”、“$”等。根据OCR技术,可以将数字与文本区别开来,文本的具体内容则需要进行识别来判断。
参考图2所示,在该收费单据图像200中的标题行还包括“数量”,对应文字块212,与该文字块212同列的文字块222、232、242都是与收费项目相关的数量文字块。步骤S120包括识别这些文字块。
图2所示仅为示例,不用于限制收费单据中的具体内容。
本发明根据OCR方法识别到的文字块的信息中包括该文字块中的具体显示内容,也包括该文字块在该收费单据图像200中的坐标位置。参考图2所示,以该图像的左上角为原点O建立直角坐标系,x轴为向右延伸的横轴,y轴为向下延伸的纵轴。以文字块211为例,该文字块211在该收费单据图像200的所有待识别文字块中处于最左上的位置。该文字块211的内容是“项目名称”,其坐标中至少包括包围该文字块211的长方形的左上角和右下角两个点的坐标。文字块211的坐标可以是包围该文字块211的长方形上的每个点的坐标。例如,可以用该长方形的四个顶点坐标代表该文字块211的坐标。在对文字块进行处理时,可以根据实际的计算需求选取需要的坐标。
收费单据图像200中所显示的文字内容不同、大小也不同,相应地所获得的文字块的大小和内容也不同,文字块的大小可以从根据其坐标来反映。例如该文字块的顶边和底边之间的距离为该文字块的高度,左边到右边的距离为该文字块的宽度。
本实施例的收费单据的识别方法在步骤S130根据多个文字块的坐标计算每个文字块与其周围的其他文字块的相对位置关系。根据OCR方法获得了多个文字块的信息,其中包括每个文字块的坐标位置。但是该信息并不能直接表示各个文字块直接的位置关系。本步骤的目的是将所获得的多个文字块采用图数据结构进行重新组织,使得后续可以更加快速的找到与某个文字块相邻的其他文字块,从而确定该某个文字块在所有文字块中的位置。
图3A-3C是本发明一实施例的临床试验收费单据的识别方法中计算文字块的相对位置关系的过程示意图。参考图3A-3C所示,在该实施例中,根据多个文字块的坐标计算每个文字块与其周围的其他文字块的相对位置关系的步骤包括:
步骤S131:生成文字块集合,文字块集合中包括所有文字块的坐标。
本步骤是将经过OCR方法获得的多个文字块的信息中的坐标的集合包含在一个文字块集合中,以备后续步骤使用。
参考图3A所示,其中在虚线框的范围内包括多个矩形框301,每个矩形框301表示采用OCR方法从收费单据图像所获得的一个文字块。显然,图3A所示的多个矩形框301的排列是杂乱无章的,并不能直接从OCR方法的结果得到每个文字块之间的相对位置关系。
步骤S132:根据每个文字块的纵坐标排序,得到所有文字块的有序列表。
图4A和4B是本发明一实施例的临床试验收费单据的识别方法中的搜索相邻文字块的示意图。参考图4A所示,其中示出了文字块411、412。该文字块411的编号为1,文字块412的编号为2。在图4A所示的实施例中,用文字块的边作为该文字块的坐标。文字块411和文字块412的顶边分别记为Top1、Top2,底边分别记为Bottom1、Bottom2,左边分别记位Left1、Left2,右边分别记位Right1、Right2。文字块处于图4A所示的直角坐标系中,x轴为横轴,y轴为纵轴。
在步骤S132中,根据每个文字块的纵坐标y进行排序,可以使纵坐标y相近的文字块相互靠近。在一些实施例中,按照纵坐标y的升序来排序,在该有序列表中的第一个文字块是收费单据图像中处于最左上的文字块。在其他的实施例中,可以按照纵坐标y的降序来排序。
图3B示出了一种经过排序之后的示例。有序列表中可以按照顺序依次排列文字块组310、320、330。
步骤S133:在有序列表中按照顺序处理每个文字块,得到每个文字块的上、下、左、右四个方向的相邻文字块。
在一些实施例中,在有序列表中按照顺序处理每个文字块的步骤包括:
步骤S31:以有序列表中的第一个文字块作为第一锚点;
参考图4A所示,以文字块411为第一锚点。
步骤S32:在有序列表中搜索第一锚点右侧的文字块,以该第一锚点右侧的文字块为第二锚点,并将搜索结果记录在第一锚点的数据结构中。
参考图4A所示,编号为2的文字块412用于代表文字块集合中除第一锚点411之外的其他文字块。文字块412的纵坐标范围与第一锚点411的纵坐标范围重合的条件公式为:
Len(Top1,Bottom1)+Len(Top2,Bottom2)>Max(Len(Top1,Bottom2),Len(Top2,Bottom1))(1)
该条件公式(1)中,Len(Top1,Bottom1)表示顶边Top1到底边Bottom1之间的距离,依此类推;Max(Len(Top1,Bottom2),Len(Top2,Bottom1))指Len(Top1,Bottom2)和Len(Top2,Bottom1)之中的较大者。
若满足上述条件公式(1),则表示文字块2和文字块1在同一行。
在经过条件公式(1)的判断之后,再通过条件公式(2)进行判断:
Left2.x>Right1.x(2)
条件公式(2)表示文字块2的左边的x坐标大于文字块1的右边的x坐标。
若一个文字块同时满足条件公式(1)和(2),则表示该文字块是处于锚点右侧相邻的文字块,将该文字块记录在锚点的数据结构中。
对于一个文字块2来说,当条件公知(1)和(2)都满足时,将该文字块2加入待选集合{Candidate}。
对于包括多个文字块2的情况下,取距离文字块1距离最近的一个文字块2作为第一锚点411右侧的文字块。可以根据下面的公式(3):
Min(Candidate1.Left.x,Candidate2.Left.x,Candidate3.Left.x,...)(3)
即求出左边的x坐标最小的文字块,该文字块是第一锚点411右侧的相邻文字块。
类似地,可以搜索第一锚点左侧的相邻文字块。
步骤S33:在文字块集合中搜索与第二锚点上下相邻的文字块,并将搜索结果记录在第二锚点的数据结构中;本步骤在文字块集合中执行,而不是前面所述的有序列表中。
参考图4B所示,其中示出了第二锚点421和位于其上侧的一个文字块422。根据图4B说明如何寻找第二锚点421上方与其相邻的文字块。文字块422用于代表所有位于第二锚点421上方的文字块。
首先求所有跟第二锚点421的文字块的宽度坐标范围上有重合的文字块,使第二锚点421的编号为1,文字块422的编号为2。则重合条件为条件公式(4):
Len(Left1,Right1)+Len(Left2,Right2)>Max(Len(Left1,Right2),Len(Left2,Right1))(4)
若满足上述条件公式(4),则表示文字块2和文字块1在同一列。
在经过条件公式(4)的判断之后,再通过条件公式(5)进行判断:
Top1.y>Bottom2.y(5)
条件公式(5)表示文字块1的顶边的y坐标大于文字块2的底边的y坐标,表示文字块1在文字块2的下方。
若一个文字块同时满足条件公式(4)和(5),则表示该文字块是处于第二锚点上方相邻的文字块,将该文字块记录在第二锚点的数据结构中。
对于一个文字块2来说,当条件公知(4)和(5)都满足时,将该文字块2加入待选集合{Candidate}。
对于包括多个文字块2的情况下,取距离文字块1距离最近的一个文字块2作为第二锚点421上方的文字块。可以根据下面的公式(6):Max(Candidate1.Bottom.y,Candidate2.Bottom.y,Candidate3.Bottom.y,...)(6)
即求出底边的y坐标最大的文字块,该文字块是第二锚点421上方的相邻文字块。
类似地,可以搜索第二锚点下方的相邻文字块。
步骤S34:在有序列表中搜索第二锚点右侧的文字块,若有则删除第二锚点,并将第二锚点右侧的文字块作为新的第二锚点,重复执行步骤S33-S34,直到第二锚点右侧没有文字块。
根据本步骤可以找到所有位于第一锚点右侧的文字块,并将搜索结果记录在对应的文字块的数据结构中。
步骤S35:在有序列表中搜索第一锚点左侧的文字块,以第一锚点左侧的文字块为第三锚点,并将搜索结果记录在第一锚点的数据结构中;
本步骤可以参考步骤S32,将其中和右侧相关的部分适应性的修改为适于搜索第一锚点左侧的文字块。
步骤S36:在文字块集合中搜索与第三锚点上下相邻的文字块,并将搜索结果记录在第三锚点的数据结构中;
本步骤与步骤S33类似,可参考相关说明。
步骤S37:在有序列表中搜索第三锚点左侧的文字块,若有则删除第三锚点,并将第三锚点左侧的文字块作为新的第三锚点,重复执行步骤S36-S37,直到第三锚点左侧没有文字块;
步骤S38:在有序列表中删除第一锚点、第二锚点和第三锚点;以及
步骤S39:重复执行步骤S31-38,直到有序列表为空。
经过上述步骤,有序列表中的文字块被逐个按顺序删除,直到最后为空,最终可以获得文字块集合中的每一个文字块的相对位置。
图3C示出了根据上述方法所得到的结果,其中用箭头表示每一个文字块都确定与其相邻的其他文字块。
在一些实施例中,每个文字块的数据结构中包括记录与该文字块在上、下、左、右四个方向的相邻文字块的字段。
可以理解,并不是每个文字块都完全包括四个相邻文字块。例如图3C中的文字块311,其仅包括一个右侧相邻文字块312和一个下侧相邻文字块331。
可以理解,如果该文字块在某个方向上没有相邻的文字块,例如最左上的文字块只有右侧和下侧的相邻文字块,则其左侧和上侧的相邻文字块记录为空。
本实施例的收费单据的识别方法在步骤S140中比较文字块的内容和临床试验随访任务库中的收费项目名称,获得候选收费项目名称文字块。
临床试验随访任务库可以是包括临床试验过程中所涉及到的所有术语的数据库,其中包括各种医学术语、医学检验术语、检查项目名称术语、药物名称术语、疾病名称术语等。该临床试验随访任务库可以是针对该临床试验所特别建立的一个数据库,其中仅包括与该临床试验相关联的一些术语。
对于特定的受试者来说,其在参加临床试验之外,可能同时接受其他的检查、药物等。那么将受试者所提交的收费单据与该临床试验随访任务库进行比较,可以仅将与该临床试验相关联的收费项目名称识别出来,以便于将该部分收费项目及其金额等信息录入到临床试验受试者的管理系统中,可以避免与非临床试验相关的费用产生混淆。
步骤S140的目的在于判断文字块的内容是否是临床试验随访任务库中的收费项目名称。
在一些实施例中,步骤S140进一步地包括以下步骤:
步骤S141:将临床试验随访任务库中的收费项目名称拆分成长度相等的第一字段;
步骤S142:将该文字块的内容拆分成与第一字段的长度相等的第二字段。
步骤S143:比较第一字段和第二字段。
本发明对于第一字段和第二字段的长度不做限制,可以是2或3个字符等。
在一些实施例中,采用2-gram方法执行步骤S141和S142中的拆分步骤。
图5是本发明一实施例的临床试验收费单据的识别方法中对收费项目名称进行拆分的示意图。参考图5所示,左边是临床试验随访任务库中的完整的收费项目名称510,例如“静脉采血”、“常规心电图检查”等。本发明所接收到的收费单据图像中所包括的收费项目名称有可能与临床试验随访任务库中的收费项目名称不相符,如果将完整的收费项目名称与收费单据图像中的文字内容进行比较,有可能出现漏误。由于收费项目名称的长度不统一,有长有短,如果不统一长度,在将标准收费项目名称与文字块的内容进行比较时耗费的时间也较长。
参考图5所示,将完整的收费项目名称510拆分成长度相等的收费项目名称数据,在该实施例中,采用2-gram方法对收费项目名称进行拆分,获得了长度为2的多个收费项目名称数据。如图5中的拆分后的收费项目名称数据集合520中包括从“静脉采血”获得的“静脉”、“脉采”、“采血”,从“常规心电图检查”获得的“常规”、“规心”、“心电”等收费项目名称数据。
同理,对所接收到的收费单据图像中的文字块的内容进行拆分。举例说明:以图2中的文字块221为例,该文字块221的内容是“静脉采血”,采用2-gram方法对文字块221的内容进行拆分,得到拆分后的第二字段的集合C:
C={静脉,脉采,采血}
参考图5所示,经过拆分的收费项目名称数据集合520为第一字段的集合DC。
统计集合C中的第二字段和集合DC中的第一字段的匹配个数,记为match(C,DC)。
计算第一字段和第二字段的置信度confidence:
confidence=match(C,DC)/count(C)
其中,count(C)指集合C中包含第二字段的数目。
将置信度confidence和经验阈值threshold做比较,若confidence>threshold判定为疑似收费项目,若confidence 若通过上述判断之后,文字块中的内容为疑似收费项目,则将该文字块作为候选收费项目名称文字块。上述的匹配方法属于一种模糊匹配方法。 在从收费单据图像中所提取的文字块中,除了包括收费项目名称的候选收费项目名称文字块之外,还包括以数字形式呈现的金额文字块。 本实施例的收费单据的识别方法在步骤S150根据文字块的相对位置关系确定候选收费项目名称文字块右侧的第一文字块组,若第一文字块组中包括金额文字块,则判断候选收费项目名称文字块为正式收费项目名称文字块。 在步骤S150中利用在步骤S130所获得的每个文字块的相对位置关系,可以找到候选收费项目名称文字块右侧的第一文字块组,该第一文字块组指位于候选收费项目名称文字块右侧的所有文字块。参考图2所示,在文字块221右侧的第一文字块组包括文字块222、223。其中,文字块223是金额文字块。 在本发明的实施例中,若候选收费项目名称文字块右侧包括金额文字块,则可以确认该候选收费项目名称文字块是收费项目名称,可以成为正式收费项目名称文字块。参考图2所示,由于文字块221右侧的文字块223是金额文字块,因此文字块221在步骤S150中成为正式收费项目名称文字块。 参考图2所示,其中包括三个收费项目名称文字块221、231、241,三个数量文字块222、232、242和三个金额文字块223、233、243。对于文字块221来说,其第一文字块组包括数量文字块222和金额文字块223。 本实施例的收费单据的识别方法在步骤S160生成第二文字块组,该第二文字块组包括正式收费项目名称文字块和金额文字块。参考图2所示,对于文字块221来说,第二文字块组包括正式收费项目名称文字块221和金额文字块223。 可以理解,对于一个收费项目来说,第一文字块组和第二文字块组相关,第二文字块组比第一文件块组多一个正式收费项目名称文字块。 本实施例的收费单据的识别方法在步骤S170对第二文字块组进行标准化处理。对于一项临床研究来说,可能在不同的医院招募受试者,受试者所提供的收费单据各式各样。其中的收费项目名称、金额的格式等都不统一。本发明针对该技术问题,对从收费单据图像中所获得的第二文字块组进行标准化处理。具体地,本发明建立了一个标准术语库,将第二文字块组中的所有文字块与该标准术语库中的每个标准术语进行匹配度计算,得到匹配分。 在一实施例中,采用如下地匹配方法: 步骤S171:算法入口函数记为Lev_distance(str1,str2),该算法入口函数根据莱文斯坦距离(Levenshtein)算法计算str1和str2之间的距离。其中,str1表示第二文字块组中的一个文字块,str2是标准术语库中的标准术语。 步骤S172:定义字符串字符交集函数,记为交集函数cross_distance(str1,str2),该交集函数返回构成str1的字符集合和构成str2的字符集合的交集的元素个数,例如 cross_distance(‘abc’,‘bcd’) len({‘a’,‘b’,‘c’}∩{‘b’,‘c’,‘d’})=len({‘b’,‘c’})=2 步骤S173:取str1和str2的长度的最大值,max_len=max(len(str1),len(str2)); 步骤S174:计算str1和str2的匹配分match_score: match_score=1-(max_len-cross_distance(str1,str2)+Lev_distance(str1,str2))/(max_len*2) 将标准术语库中的标准术语都作为str2和str1进行比较,取匹配分match_score最大的str2为与str1匹配的标准术语。如果匹配分为1,表示完全匹配,则该匹配结果为确定结果;如果匹配分小于1,表示部分匹配,则该匹配结果为非确定结果。无论匹配结果确定与否,都可以传递给下游流程,由下游流程根据自身的设置来使用。 在上述的匹配方法中,str1指文字块中的整个字符或字符串。 通过步骤S170,可以将本发明所识别到的第二文字块组中的收费项目名称文字块的内容转换为标准收费项目名称,将金额文字块的内容转换为标准金额。 对于金额文字块来说,来自不同来源的收费单据上的金额的格式可能是不同的,例如所保留的小数点后面的位数。经过步骤S170可以统一该数字的格式,以便于后续的自动化处理。 在一些实施例中,本发明的识别方法还包括:比较文字块的内容和临床试验随访任务库中的医保类型关键字,判断文字块是医保类型文字块;以及将医保类型文字块转换为标准医保类型。 具体地,参考图2所示,在该收费单据图像200中包括了内容是“医保类型:医保”的文字块250,在步骤S120可以获得该文字块250。在这些实施例中,将所获得文字块与医保类型关键字进行比较,判断该文字块是医保类型文字块,则将该医保类型文字块的内熔转换为标准医保类型,以便于后续的应用。 在一些实施例中,本发明的收费项目名称包括费用类型,该费用类型包括检查费、治疗费、药费中一项或任意项的组合。 图6是本发明另一实施例的收费单据图像的示意图。该收费单据图像600不同于图2所示的收费单据图像200。参考图6所示,该收费单据图像600的标题为“受试者费用支付明细表”,其中具体示出了筛选号、随机号等受试者相关信息,还以表格的形式列出了费用类型、具体明细和金额三列内容。 参考图6所示,根据本发明的识别方法可以对该收费单据图像600中的所有文字信息进行提取,获得多个文字块。 在图6所示的实施例中,本发明的收费项目名称是费用类型,相应的收费项目名称文字块就是费用类型文字块。可以在步骤S140中比较从收费单据图像600中所获得的文字块和临床试验随访任务库中的费用类型,获得候选费用类型文字块,例如文字块621。若该候选费用类型文字块621右侧的第一文字块组中包括金额文字块,例如金额文字块623,则该候选费用类型文字块621为正式费用类型文字块621。生成第二文字块组,其中包括该正式费用类型文字块621和金额文字块623,再对该第二文字块组进行标准化处理。 图6仅示出了一种费用类型,即“检查费”。在其他的实施例中,费用类型可以包括检查费、治疗费、药费中一项或任意项的组合。 根据本发明的收费单据的识别方法,可以对收费单据图像中需要录入临床试验管理系统的文字块进行自动识别,并将文字块的内容转换为标准格式,统一了来自不同数据来源的不同收费单据的内容和格式,使临床试验中所获得的收费单据相关数据可以更加方便高效地应用于临床试验研究。 本发明还包括一种临床试验受试者收费单据的识别装置,包括存储器和处理器。该存储器用于存储可由处理器执行的指令;该处理器用于执行该指令以实现如前文所述的收费单据的识别方法。 本发明还包括一种存储有计算机程序代码的计算机可读介质,该计算机程序代码在由处理器执行时实现如如前文所述的收费单据的识别方法。 收费单据的识别方法实施为计算机程序时,也可以存储在计算机可读存储介质中作为制品。例如,计算机可读存储介质可以包括但不限于磁存储设备(例如,硬盘、软盘、磁条)、光盘(例如,压缩盘(CD)、数字多功能盘(DVD))、智能卡和闪存设备(例如,电可擦除可编程只读存储器(EPROM)、卡、棒、键驱动)。此外,本文描述的各种存储介质能代表用于存储信息的一个或多个设备和/或其它机器可读介质。术语“机器可读介质”可以包括但不限于能存储、包含和/或承载代码和/或指令和/或数据的无线信道和各种其它介质(和/或存储介质)。 应该理解,上文所描述的实施例仅是示意。本文描述的实施例可在硬件、软件、固件、中间件、微码或者其任意组合中实现。对于硬件实现,处理单元可以在一个或者多个特定用途集成电路(ASIC)、数字信号处理器(DSP)、数字信号处理设备(DSPD)、可编程逻辑器件(PLD)、现场可编程门阵列(FPGA)、处理器、控制器、微控制器、微处理器和/或设计为执行本文所述功能的其它电子单元或者其结合内实现。 虽然本发明已参照当前的具体实施例来描述,但是本技术领域中的普通技术人员应当认识到,以上的实施例仅是用来说明本发明,在没有脱离本发明精神的情况下还可作出各种等效的变化或替换,因此,只要在本发明的实质精神范围内对上述实施例的变化、变型都将落在本申请的权利要求书的范围内。
- 临床试验收费单据的识别方法和识别装置
- 临床试验不良反应的识别方法、装置、介质及电子设备