一种文本的情感分类方法
文献发布时间:2023-06-19 11:02:01
技术领域
本发明属于情感分类技术领域,尤其涉及一种文本的情感分类方法。
背景技术
情感分类也称意见挖掘、倾向性分析等,指利用文本挖掘、自然语言处理等技术对评论文本中的主观信息进行识别和提取,获取分析对象对某话题或者某文本的观点态度。
目前,利用深度学习方法和注意力机制技术对评论文本进行情感分类已经成为了新的研究热点。然而,本申请的发明人发现,现有的情感分类方法在训练好一个语言模型之后,每一个词的词向量是固定不变的,后续使用词向量时,无论输入的句子是什么,词向量都没有变化,不能根据上下文进行相应的变动。因此,现有的情感分类方法无法应对评论文本中某个词存在一词多义的问题,分类准确率较差。
发明内容
有鉴于此,本发明实施例提供了一种文本的情感分类方法,以解决现有技术中的情感分类方法无法应对一词多义、分类准确率较差的问题。
本发明实施例的第一方面提供了一种文本的情感分类方法,包括:
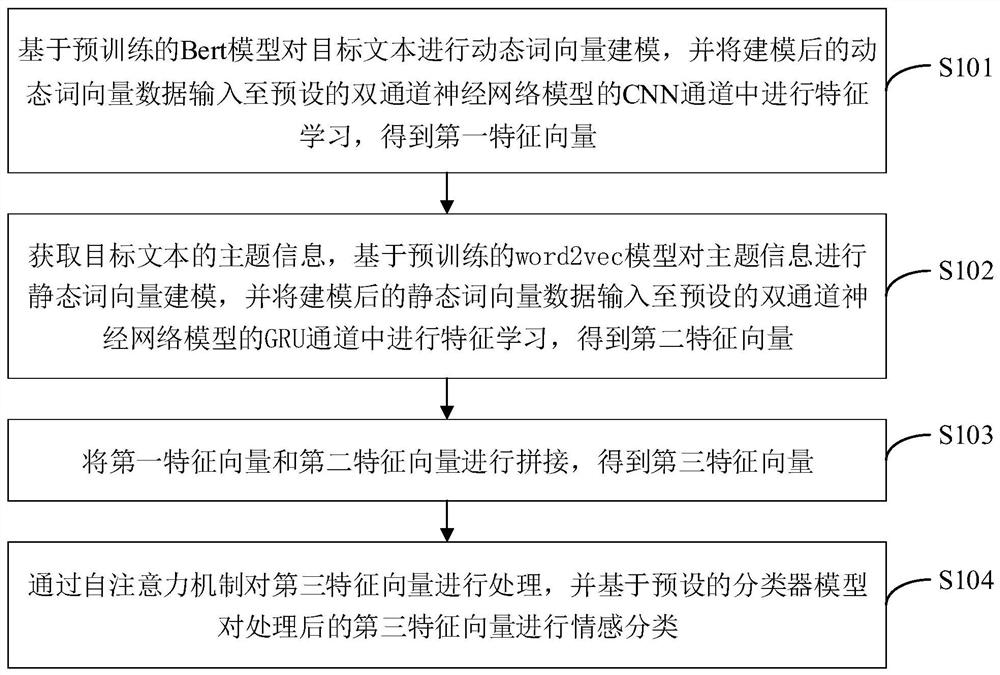
基于预训练的Bert模型对目标文本进行动态词向量建模,并将建模后的动态词向量数据输入至预设的双通道神经网络模型的CNN通道中进行特征学习,得到第一特征向量;
获取目标文本的主题信息,基于预训练的word2vec模型对主题信息进行静态词向量建模,并将建模后的静态词向量数据输入至预设的双通道神经网络模型的GRU通道中进行特征学习,得到第二特征向量;
将第一特征向量和第二特征向量进行拼接,得到第三特征向量;
通过自注意力机制对第三特征向量进行处理,并基于预设的分类器模型对处理后的第三特征向量进行情感分类。
可选的,基于预训练的Bert模型对目标文本进行动态词向量建模,包括:
S=[w
式中,S为n行K列的动态词向量矩阵,n为目标文本中的单词数量,w
可选的,双通道神经网络模型的CNN通道的卷积层设置有至少两个大小不同的卷积核,CNN通道提取第一特征向量的方法包括:
各个卷积核分别对动态词向量数据进行卷积处理,得到各个卷积核对应的动态词向量数据的特征向量矩阵;
基于最大池化法分别从各个特征向量矩阵中提取最大特征向量;
基于注意力机制为各个最大特征向量分配相应的权重,得到第一特征向量。
可选的,基于注意力机制为各个最大特征向量分配相应的权重,得到第一特征向量,包括:
式中,S
可选的,获取目标文本的主题信息,包括:
通过LDA主题模型获取目标文本的多个初始主题信息;
提取各个初始主题信息的前m个单词,得到各个初始主题信息对应的主题信息;其中,各个初始主题信息对应的主题信息的集合形成目标文本的主题信息,m为预设值。
可选的,基于预训练的word2vec模型对主题信息进行静态词向量建模,包括:
T=[t
式中,T为任意一个初始主题信息对应的主题信息的静态词向量矩阵,t
可选的,GRU通道提取第二特征向量的方法,包括:
根据各个单词的静态词向量计算各个单词的特征向量;
基于注意力机制为各个单词的特征向量分配相应的权重,得到第二特征向量。
可选的,基于注意力机制为各个单词的特征向量分配相应的权重,得到第二特征向量,包括:
式中,S
可选的,将第一特征向量和第二特征向量进行拼接,得到第三特征向量,包括:
Y=connact(S
式中,Y为第三特征向量,connact为拼接函数,S
可选的,通过自注意力机制对第三特征向量进行处理,包括:
式中,
本发明实施例与现有技术相比存在的有益效果是:
本发明通过预训练的Bert模型对目标文本进行动态词向量建模,能够很好的应对目标文本当中一词多义的现象;并且,通过提取目标文本的主题信息进行静态词向量建模,能够为分类器提供具有针对意义的主题信息作为参考;进一步,动态词向量数据和静态词向量数据输入至双通道神经网络模型中进行特征提取后,将双通道输出的特征向量进行拼接,并利用自注意力机制对拼接向量进行处理,将处理后的特征向量输入至分类器中,即可得到目标文本的情感类别。本发明能够很好地应对目标文本中的一词多义现象,提高对目标文本情感分类的准确率,优化目标文本的情感分类结果。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的文本的情感分类方法的实现流程示意图;
图2是本发明实施例提供的文本的情感分类方法的整体流程示意图。
具体实施方式
以下描述中,为了说明而不是为了限定,提出了诸如特定系统结构、技术之类的具体细节,以便透彻理解本发明实施例。然而,本领域的技术人员应当清楚,在没有这些具体细节的其它实施例中也可以实现本发明。在其它情况中,省略对众所周知的系统、装置、电路以及方法的详细说明,以免不必要的细节妨碍本发明的描述。
为了说明本发明所述的技术方案,下面通过具体实施例来进行说明。
本发明实施例的第一方面提供了一种文本的情感分类方法,如图1所示,该方法具体包括以下步骤:
步骤S101、基于预训练的Bert模型对目标文本进行动态词向量建模,并将建模后的动态词向量数据输入至预设的双通道神经网络模型的CNN通道中进行特征学习,得到第一特征向量。
可选的,作为本发明实施例提供的文本的情感分类方法的一种具体的实施方式,基于预训练的Bert模型对目标文本进行动态词向量建模,包括:
S=[w
式中,S为n行K列的动态词向量矩阵,n为目标文本中的单词数量,w
在本发明实施例中,目标文本可以为网络上的某个评论文本,在获取一段目标文本后,由于文本数据杂乱,首先要对目标文本进行预处理,提升词向量的质量。具体的,预处理可以包括对文本数据进行分词、去停用词、去除无用的标签、去除特殊符号、将英文的大写转化为小写等操作。
预处理后,将目标文本的长度(包含的单词数量)限值为100,输入到预训练的Bert模型的嵌入层进行词嵌入操作,将每个单词表示为K维的动态词向量,最终嵌入层输出n×K大小的二维矩阵:
可选的,作为本发明实施例提供的文本的情感分类方法的一种具体的实施方式,双通道神经网络模型的CNN通道的卷积层设置有至少两个大小不同的卷积核,CNN通道提取第一特征向量的方法包括:
各个卷积核分别对动态词向量数据进行卷积处理,得到各个卷积核对应的动态词向量数据的特征向量矩阵;
基于最大池化法分别从各个特征向量矩阵中提取最大特征向量;
基于注意力机制为各个最大特征向量分配相应的权重,得到第一特征向量。
可选的,作为本发明实施例提供的文本的情感分类方法的一种具体的实施方式,基于注意力机制为各个最大特征向量分配相应的权重,得到第一特征向量,包括:
式中,S
在本发明实施例中,CNN通道由卷积层、池化层和注意力层构成,CNN通道提取第一特征向量的具体过程如下:
(1)卷积层
卷积层使用三种不同的卷积核(Conv2、Conv3、Conv5)各50个,三种卷积核大小分别为2、3、5,通过设置不同大小的卷积核能够尽可能多的学习到不同类型的特征,卷积结果通过ReLU激活函数进行激活。
具体的,每个卷积核均通过下式提取特征:
Z
式中,Z
对于每种卷积核,当输入{X
(2)池化层
采用最大池化法Max Pooling,对卷积层提取的信息进行降维操作,相当于特征的二次提取,即从各个特征向量矩阵中提取最大特征向量。
(3)注意力层
注意力层对各个最大特征向量的重要性进行评估,对重要性不同的最大特征向量分配不同的权重,用来优化最终的分类结果。
其中,第j个最大特征向量的权重α
E
式中,W
步骤S102、获取目标文本的主题信息,基于预训练的word2vec模型对主题信息进行静态词向量建模,并将建模后的静态词向量数据输入至预设的双通道神经网络模型的GRU通道中进行特征学习,得到第二特征向量。
可选的,作为本发明实施例提供的文本的情感分类方法的一种具体的实施方式,获取目标文本的主题信息,包括:
通过LDA主题模型获取目标文本的多个初始主题信息;
提取各个初始主题信息的前m个单词,得到各个初始主题信息对应的主题信息;其中,各个初始主题信息对应的主题信息的集合形成目标文本的主题信息,m为预设值。
可选的,作为本发明实施例提供的文本的情感分类方法的一种具体的实施方式,基于预训练的word2vec模型对主题信息进行静态词向量建模,包括:
T=[t
式中,T为任意一个初始主题信息对应的主题信息的静态词向量矩阵,t
在本发明实施例中,首先利用LDA主题模型获取目标文本的多个初始主题信息,并提取各个主题下的前m个单词来表示各个主题,然后采用word2vec模型对各个单词进行词嵌入操作。
可选的,作为本发明实施例提供的文本的情感分类方法的一种具体的实施方式,GRU通道提取第二特征向量的方法,包括:
根据各个单词的静态词向量计算各个单词的特征向量;
基于注意力机制为各个单词的特征向量分配相应的权重,得到第二特征向量。
可选的,作为本发明实施例提供的文本的情感分类方法的一种具体的实施方式,基于注意力机制为各个单词的特征向量分配相应的权重,得到第二特征向量,包括:
式中,S
在本发明实施例中,GRU通道计算各个单词的特征向量的过程为:
r
z
式中,t
步骤S103、将第一特征向量和第二特征向量进行拼接,得到第三特征向量。
可选的,作为本发明实施例提供的文本的情感分类方法的一种具体的实施方式,将第一特征向量和第二特征向量进行拼接,得到第三特征向量,包括:
Y=connact(S
式中,Y为第三特征向量,connact为拼接函数,S
步骤S104、通过自注意力机制对第三特征向量进行处理,并基于预设的分类器模型对处理后的第三特征向量进行情感分类。
可选的,作为本发明实施例提供的文本的情感分类方法的一种具体的实施方式,通过自注意力机制对第三特征向量进行处理,包括:
式中,
在本发明实施例中,采用自注意力机制Self-Attention处理拼接的特征向量,仅通过关注自身信息更新训练参数,不需要添加额外的信息。
处理后的特征向量输入至分类器模型中进行文本的情感分类,该模型包含一个全连接层的前馈神经网络,隐藏层的大小为Nlabel,并在全连接层前加入Dropout方法防止过拟合,最后用softmax函数进行分类,如下所示:
式中,A
为了便于对本方案的理解,图2示出了本发明实施例提供的文本的情感分类方法的整体流程框架,其对应于上述实施例中的各个实现步骤,本申请在此不再进行阐述。
由以上内容可知,本发明采用预训练的Bert模型对目标文本进行动态词向量建模,能够很好的应对目标文本当中一词多义的现象;并且,通过提取目标文本的主题信息进行静态词向量建模,能够为分类器提供具有针对意义的主题信息作为参考;并且,通过在CNN通道和GRU通道中加入注意力机制,对重要的信息投入更大的权重,可以在提取局部信息的同时,增强对重点信息的关注度,使分类器获得更有针对性的输入信息,提高文本情感分类的效果。本发明能够很好地应对目标文本中的一词多义现象,提高对目标文本情感分类的准确率,优化目标文本的情感分类结果。
应理解,上述实施例中各步骤的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本发明实施例的实施过程构成任何限定。
以上所述实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围,均应包含在本发明的保护范围之内。
- 一种基于Tree-LSTM和情感信息的短文本情感分类方法
- 一种基于情感词典与微博文本数据的七情感分类方法