一种借助服务器前端和后端生成pdf文档的方法及系统
文献发布时间:2023-06-19 11:05:16
技术领域
本发明涉及数据转换技术领域,具体的说是一种借助服务器前端和后端生成pdf文档的方法及系统。
背景技术
pdf是Adobe公司开发的一种电子文件格式,pdf文件是目前世界上公认的最适合于互联网应用的标准传输文件。随着社会现代化及办公无纸化的不断发展,pdf文档因为其具有的不可编辑,可以添加数字水印,在不同平台下显示效果一致等特性,逐渐在一些场景下成为首选。
pdf文档应用的重要性不言而喻,而研究pdf文档构建适合特定情况的方法也显得非常重要。目前的pdf文档有多种生成方式,后端可通过iText库进行生成,前端可通过将html转换成canvas,再将canvas转换成pdf。但是当面对需要生成复杂的pdf文档时,这两种方法都不能完全满足要求。
发明内容
本发明针对目前技术发展的需求和不足之处,提供一种借助服务器前端和后端生成pdf文档的方法及系统,以满足复杂的pdf生成需求。
首先,本发明提供一种借助服务器前端和后端生成pdf文档的方法,解决上述技术问题采用的技术方案如下:
一种借助服务器前端和后端生成pdf文档的方法,其实现过程包括:
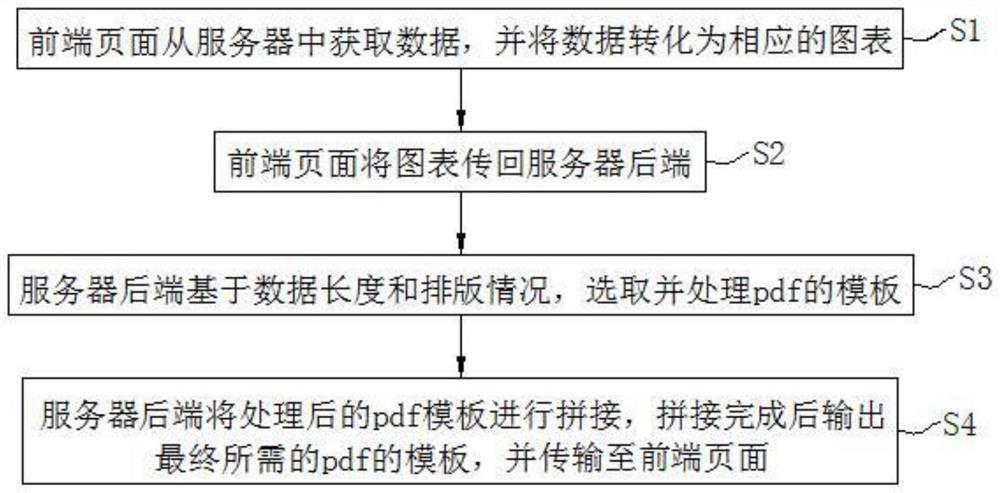
步骤S1、前端页面从服务器中获取数据,并将数据转化为相应的图表;
步骤S2、前端页面将图表传回服务器后端;
步骤S3、服务器后端基于数据长度和排版情况,选取并处理pdf的模板;
步骤S4、服务器后端将处理后的pdf模板进行拼接,拼接完成后输出最终所需的pdf的模板,并传输至前端页面。
执行步骤S1时,前端页面依托可视化工具将数据转化为相应的图表。
执行步骤S2时,前端页面借助html2canvas工具将图表转换为canvas格式,随后再将canvas格式的图表转换为base64,并传回后端。
执行步骤S3时,基于数据长度和排版情况,选取并处理pdf的模板,具体操作为:
对于数据长度不确定并且对排版有影响的页面,准备不同排版情况下的pdf模板;
对于数据长度不固定但排版固定的页面,准备一幅与背景色同色的图片,根据数据长度改变图片大小,实现对空白数据的遮盖。
其次,本发明提供一种借助服务器前端和后端生成pdf文档的系统,解决上述技术问题采用的技术方案如下:
一种借助服务器前端和后端生成pdf文档的系统,其包括服务器的前端页面和后端,还包括部署于前端页面的数据转化模块和部署于后端的数据处理模块;
前端页面从服务器中获取数据,并将数据转化模块转化的图表传送至后端;
数据转化模块将数据转化为相应的图表;
后端接收前端页面传送的图表,并传送至数据处理模块;
数据处理模块首先基于数据长度和排版情况,选取并处理pdf的模板,随后将处理后的pdf模板进行拼接,拼接完成后输出最终所需的pdf的模板,并传输至前端页面。
具体的,所涉及数据转化模块包括可视化工具,可视化工具将数据转化为相应的图表。
具体的,所涉及数据转化模块还包括html2canvas工具,html2canvas工具将图表转换为canvas格式,随后再将canvas格式的图表转换为base64。
具体的,所涉及数据处理模块基于数据长度和排版情况,选取并处理pdf的模板,具体包括:
对于数据长度不确定并且对排版有影响的页面,准备不同排版情况下的pdf模板;
对于数据长度不固定但排版固定的页面,准备一幅与背景色同色的图片,根据数据长度改变图片大小,实现对空白数据的遮盖。
本发明的一种借助服务器前端和后端生成pdf文档的方法及系统,与现有技术相比具有的有益效果是:
本发明借助前端页面将数据转化为图表,借助后端选取pdf模板并进行选取和拼接,以生成并输出满足需求的pdf模板。
附图说明
附图1是本发明实施例一的方法流程图;
附图2是本发明实施例二的连接框图。
附图中各标号信息表示:
1、前端页面,2、后端,3、数据转化模块,4、数据处理模块。
具体实施方式
为使本发明的技术方案、解决的技术问题和技术效果更加清楚明白,以下结合具体实施例,对本发明的技术方案进行清楚、完整的描述。
实施例一:
结合附图1,本实施例提出一种借助服务器前端和后端生成pdf文档的方法,其实现过程包括:
步骤S1、前端页面1从服务器中获取数据,并依托可视化工具将数据转化为相应的图表。
步骤S2、前端页面1借助html2canvas工具将图表转换为canvas格式,随后再将canvas格式的图表转换为base64,并传回服务器后端2。
步骤S3、服务器后端2基于数据长度和排版情况,选取并处理pdf的模板,具体操作为:
对于数据长度不确定并且对排版有影响的页面,准备不同排版情况下的pdf模板;
对于数据长度不固定但排版固定的页面,准备一幅与背景色同色的图片,根据数据长度改变图片大小,实现对空白数据的遮盖。
步骤S4、服务器后端2将处理后的pdf模板进行拼接,拼接完成后输出最终所需的pdf的模板,并传输至前端页面1。
实施例二:
结合附图2,本实施例提出一种借助服务器前端和后端生成pdf文档的系统,其包括服务器的前端页面1和后端2,还包括部署于前端页面1的数据转化模块3和部署于后端2的数据处理模块4。
前端页面1从服务器中获取数据,并将数据转化模块3转化的图表传送至后端2。
数据转化模块3包括可视化工具和html2canvas工具,可视化工具将数据转化为相应的图表,html2canvas工具将图表转换为canvas格式,随后再将canvas格式的图表转换为base64。
后端2接收前端页面1传送的图表,并传送至数据处理模块4。
数据处理模块4首先基于数据长度和排版情况,选取并处理pdf的模板,随后将处理后的pdf模板进行拼接,拼接完成后输出最终所需的pdf的模板,并传输至前端页面1。
本实施例中,数据处理模块4基于数据长度和排版情况,选取并处理pdf的模板,具体包括:
对于数据长度不确定并且对排版有影响的页面,准备不同排版情况下的pdf模板;
对于数据长度不固定但排版固定的页面,准备一幅与背景色同色的图片,根据数据长度改变图片大小,实现对空白数据的遮盖。
综上可知,采用本发明的一种借助服务器前端和后端生成pdf文档的方法及系统,可以借助前端页面1,实现pdf文档在服务器后端2的生成,解决了现有方法不能生成复杂pdf文档的问题。
以上应用具体个例对本发明的原理及实施方式进行了详细阐述,这些实施例只是用于帮助理解本发明的核心技术内容。基于本发明的上述具体实施例,本技术领域的技术人员在不脱离本发明原理的前提下,对本发明所作出的任何改进和修饰,皆应落入本发明的专利保护范围。
- 一种借助服务器前端和后端生成pdf文档的方法及系统
- 识别商品伪造的方法、前端装置、后端识别服务器和系统