使用单一测定分析多种分析物
文献发布时间:2023-06-19 11:06:50
技术领域
本文提供的系统、方法和组合物涉及用于同时分析单个样本中的多种分析物的测定。具体地讲,本文所公开的方面涉及在单一测定中分析来自单个样本的DNA和RNA的方法。
背景技术
生物样本中存在的特定核酸序列的检测已被用作例如鉴定和分类微生物、诊断传染病、检测和表征遗传异常、鉴定与癌症相关联的遗传变化、研究对疾病的遗传易感性,以及测量对各种类型的治疗的反应的方法。用于检测生物样本中的特定核酸序列的常用技术是核酸测序。
组织样本的全基因组测序、基因分型、靶向重测序、基因表达、单细胞基因组学、表观基因组学和蛋白质表达分析对于鉴定疾病生物标志物、准确诊断和预测疾病,以及为患者选择适当的治疗可能是非常重要的。通常,这需要多种测定来分别分析感兴趣的特定分析物,诸如DNA、RNA或蛋白质。已建立不同的测定来分别并单独分析这些分析物。然而,对多种分析物的全面分析既耗时又繁琐。
发明内容
本公开涉及用于使用单一测定同时分析样本中的多种分析物的系统、方法和组合物。
本文提供的一些实施方案涉及核酸文库。在一些实施方案中,文库包括互补DNA(cDNA)文库和基因组DNA(gDNA)文库。在一些实施方案中,cDNA文库来源于mRNA分子并且包含具有第一标签的核酸,该第一标签包含第一条形码。在一些实施方案中,gDNA文库来源于基因组DNA并且包含具有第二标签的核酸,该第二标签包含第二条形码。在一些实施方案中,第一条形码和第二条形码是相同或不同的,并且第一条形码和第二条形码识别cDNA文库和gDNA文库的共同来源。在一些实施方案中,cDNA文库和gDNA文库被共隔室化并在相同环境中制备。在一些实施方案中,用于DNA的标签和用于RNA的标签是相同的。
本文提供的一些实施方案涉及流通池装置。在一些实施方案中,流通池装置包括用于捕获RNA的第一探针和用于捕获DNA的第二探针,其中第一探针包含第一条形码和第一底物识别序列,其中第二探针包含第二条形码和第二底物识别序列。在一些实施方案中,第一条形码和第二条形码是相同或不同的,并且第一条形码和第二条形码识别RNA和DNA的共同来源。在一些实施方案中,第一探针和第二探针被配置为在单个隔室中同时分析来自样本的RNA和DNA。根据权利要求19所述的方法,其中所述第一捕获探针和所述第二捕获探针固定在固体载体上。
本文提供的一些实施方案涉及在单个隔室中同时分析样本中的DNA和RNA的方法。在一些实施方案中,该方法包括:提供包含DNA和RNA的样本,其中RNA包含第一标签;用第二标签将DNA差异加标签;使样本在单个隔室中与用于捕获RNA的第一捕获探针和用于捕获带标签的DNA的第二捕获探针接触;使第一捕获探针与RNA杂交并且使第二捕获探针与DNA杂交,从而捕获RNA和DNA;以及分析DNA和RNA。在一些实施方案中,第一捕获探针包含第一条形码,并且第二捕获探针包含第二条形码,并且第一条形码和第二条形码识别RNA和DNA的共同来源。
本文提供的一些实施方案涉及在单个隔室中同时产生包含gDNA和cDNA的核酸文库的方法。在一些实施方案中,该方法包括:提供包含DNA和RNA的样本,其中RNA包含第一标签;用第二标签将DNA差异加标签,在单个隔室中使样本与用于捕获RNA的第一探针和用于捕获带标签的DNA的第二探针接触;使RNA和DNA分别与第一探针和第二探针杂交,并且由杂交的RNA和DNA同时产生cDNA文库和gDNA文库。在一些实施方案中,第一探针包含第一条形码,并且第二探针包含第二条形码,并且第一条形码和第二条形码识别RNA和DNA的共同来源。
本文提供的一些实施方案涉及用于在单个隔室中同时分析样本中的DNA和RNA的试剂盒。在一些实施方案中,试剂盒包括转座试剂和与第一标签互补的第一探针以及与第二标签互补的第二探针,其中第一探针和第二探针固定在固体载体上,其中第一探针包含第一条形码并且第二探针包含第二条形码,并且其中第一条形码和第二条形码识别DNA和RNA的共同来源。
本文提供的一些实施方案涉及执行单细胞ATAC-seq分析的方法。在一些实施方案中,该方法包括:提供包含细胞群或细胞核群的样本;在靶核酸上执行保留邻近性转座;将细胞群或细胞核群分配成各个小滴,其中单个细胞或细胞核被分配成单个小滴;对靶核酸进行索引;以及分析索引的核酸。
本文提供的一些实施方案涉及组合索引(CPT-seq)的方法。在一些实施方案中,该方法包括:提供包含细胞群或细胞核群的样本;在靶核酸上执行单独索引保留邻近性转座;将细胞群或细胞核群分配成各个小滴,其中多个细胞或细胞核被分配成单个小滴,并且其中单个小滴内的多个细胞或细胞核具有独特的索引;对靶核酸进行索引;以及分析索引的核酸。
在本文概述的实施方案中的任何实施方案中,分析物获自细胞群、单个细胞、细胞核群或细胞核。在本文概述的实施方案中的任何实施方案中,根据分析物为何物,使用不同的分析技术来分析分析物。例如,分析技术可包括DNA分析、RNA分析、蛋白质分析、片段标签化、核酸扩增、核酸测序、核酸文库制备、染色质转座酶可及性测序测定(ATAC-seq)、保留邻近性转座(CPT-seq)、单细胞组合索引测序(SCI-seq)、或单细胞基因组扩增、或它们的任何组合。
附图说明
图1A是示出用于分析样本中的多种感兴趣分析物的传统方法的示意图,其中每种感兴趣分析物在两次不同的观察中分别进行分析。图1B是用于在同一隔室内同时测量不同的感兴趣分析物的过程的实施方案的示意图。
图2是描绘使用不同标签用于结合DNA和RNA的共测定的实施方案的示意图。不同的标签被示出为被引入具有RNA或DNA的单个细胞或细胞核中。单个细胞或细胞核包封在小滴内或在板的孔上分离。条形码固定在表面上或以溶液状态加入,并且经由标签捕获DNA和RNA。
图3是描绘使用相同标签用于结合DNA和RNA的共测定的实施方案的示意图。DNA首先被转座体片段化以包含polyA尾。使用具有固定在表面上或处于溶液中的条形码的polyT寡核苷酸对DNA片段和mRNA两者进行索引。在DNA上进行的转座反应使得DNA能够借助于内部转座子特异性序列而与RNA区别开。
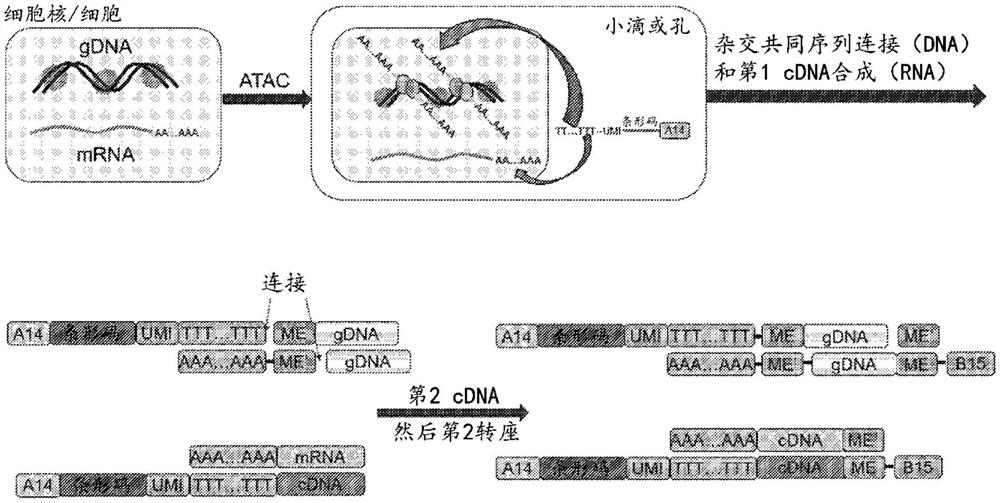
图4是描绘用于通过转座将polyA转座子引入基因组DNA中的过程的实施方案的示意图。细胞核/细胞用具有polyT尾的索引寡核苷酸包封。将索引的寡核苷酸杂交并连接至转座的gDNA片段,然后与mRNA杂交以产生第一cDNA。在第二cDNA合成之后,再次转座双链cDNA和gDNA以在另一端添加PCR衔接子。然后通过PCR来扩增片段。
图5A至图5B示意性地描绘了染色质转座酶可及性测序测定(ATAC-seq)。图5A示意性地示出了ATAC-seq的一般原理,并且图5B概述了用于执行单细胞ATAC-seq的步骤。
图6A至图6B示出了描绘批量共测定的实施方案的示意图。如图6A所示,分离细胞核,并用polyA尾将DNA片段标签化。用探针捕获片段标签化的DNA和mRNA并将其纯化以供进一步分析。图6B示出了在图6A的过程中使用的DNA片段的附加细节。
图7A至图7B示出了描绘小珠上共测定的实施方案的示意图。如图7A所示,分离细胞核,并用polyA尾将DNA片段标签化。使用生物素捕获法来捕获片段标签化的DNA和mRNA。图7B示出了在图7A的过程中使用的DNA片段的附加细节。
图8描绘了来自图6A至图6B的批量共测定测序的数据。ATAC文库的片段具有特征ME序列,在图8中突出显示。
图9的分图A和B描绘了来自图6A至图6B的批量共测定测序的数据。对所产生的文库进行测序。ATAC片段显示围绕启动子区域的典型富集(分图A),用于3'计数的RNA片段显示围绕基因末端的读段累积(分图B)。
图10是示出使用组合索引执行的共测定(诸如SCI-seq)的实施方案的示意图。
图11是示出使用组合测序执行共测定的方法的实施方案的示意图。
图12描绘了测序工作流程的示例性实施方案,示出了其中插入有条形码的小珠池,并描绘了示例性引物。
图13示出了描绘每个细胞的读段数量的曲线图,示出了增加转座酶导致每个细胞的读段数量增多。
图14示出了使用ATAC-seq,指示单细胞对混合细胞类型的敏感性的曲线图。
具体实施方式
在以下具体实施方式中,参考了附图,附图形成具体实施方式的一部分。在附图中,除非上下文另有规定,否则类似的符号通常标识类似的组分。具体实施方式、附图和权利要求书中所述的示例性实施方案并非旨在为限制性的。在不脱离本文所提出的主题的精神或范围的情况下,可利用其他实施方案,并且可作出其他改变。将容易理解的是,如本文大体所述并且如附图所示,本公开的各方面可被布置、替代、组合、分离和设计成多种不同的构型,所有这些构型均明确涵盖于本文中。
本文提供的系统、方法和组合物的实施方案涉及同时分析单个样本中的多种分析物。在一些实施方案中,多种分析物包括DNA和RNA。
传统的分析来自单个样本的多种分析物的方法需要单独的测定,并且涉及使用单独的试剂和步骤用于分离每种感兴趣分析物,然后分析每种感兴趣分析物,如例如图1A所示。因此,可利用时间和/或空间,例如在不同时刻或在不同隔室中分别分析多种分析物。例如,可能希望分析来自单个样本的DNA和RNA两者。传统方法分别使用一种测定分析DNA,并使用另一种测定分析RNA,从而增加时间、成本和资源消耗。此外,同一样本还可包含另外的感兴趣分析物,诸如蛋白质,并且蛋白质的分析也需要单独的测定。
核酸文库可用于确定基因产物或用于全基因组测序。可产生不同类型的文库,例如互补DNA(cDNA)文库,其由逆转录的RNA或基因组DNA(gDNA)文库产生,包括诸如通过染色质转座酶可及性测序测定(ATAC-seq,一种整合表观基因组分析的快速且灵敏的方法)用于表观基因组学中。传统上,这些文库是单独且独立产生的。cDNA文库可用于多种应用,这些应用包括例如发现新基因、用于研究基因功能、用于确定mRNA表达、或用于确定选择性剪接。gDNA文库可用于多种单独的应用,这些应用包括例如确定生物体的完整基因组、研究调控序列的功能、或研究基因突变。本文所述的方法、组合物和系统使得能够同时产生cDNA文库和gDNA文库两者。
本发明的一个实施方案是使用单一测定分析单个样本中的多种分析物的系统和方法,其中在单个隔室中同时分析每种感兴趣分析物,例如如图1B所示。虽然图1B描绘了样本中的两种分析物,但应当理解,可存在多于两种感兴趣分析物,并且可同时分析每种感兴趣分析物。本文所述的系统、方法和组合物涉及同时分析单个样本中的多种分析物。该系统、方法和组合物的实施方案通过降低测定复杂性、成本和缩短时间来提高分析的效率。
本文提供的一些实施方案涉及核酸文库。在一些实施方案中,核酸文库包括cDNA文库和gDNA文库,cDNA文库来源于mRNA分子并包含具有条形码序列和被配置为结合底物的第一标签的核酸,gDNA文库来源于基因组DNA并包含具有被配置为结合底物并不同于第一标签的第二标签的核酸。在一些实施方案中,核酸文库由细胞群、单个细胞、细胞核群或细胞核产生。在一些实施方案中,第一标签是polyA标签。在一些实施方案中,第二标签包含转座酶特异性元件。
在一些实施方案中,该方法包括用标签将样本中的每种感兴趣分析物加标签以对每种感兴趣分析物进行索引。在一些实施方案中,该方法还包括用与标签互补的探针捕集每种感兴趣分析物。在一些实施方案中,该方法还包括分析每种感兴趣分析物。
在一些实施方案中,该方法包括同时分析样本中的DNA和RNA。在一些实施方案中,该方法包括提供包含DNA和RNA的样本。在一些实施方案中,RNA包含第一标签。在一些实施方案中,该方法包括用第二标签将DNA差异加标签。在一些实施方案中,该方法包括使固体载体与样本接触,其中固体载体包含用于捕获RNA的第一固定化探针和用于捕获带标签的DNA的第二固定化探针。在一些实施方案中,该方法包括在固体载体上同时捕获DNA和RNA。在一些实施方案中,该方法包括分析DNA和RNA。
如本文所用,样本包括具有感兴趣分析物的任何样本。样本可以是生物样本,诸如具有感兴趣分析物的生物样本,包括例如全血、血清、间质液、淋巴液、脑脊液、痰液、尿液、粪便、乳、汗液、泪液、脐带、外周血、骨髓、细胞或实体组织。在一些实施方案中,样本是细胞群、细胞、细胞核群或细胞核。样本可从受试者获得,其中希望分析来自受试者的一种或多种感兴趣分析物。如本文所用,“受试者”是指作为治疗、观察或实验对象的动物。“动物”包括冷血和温血脊椎动物和无脊椎动物,诸如鱼、贝类、爬行动物和(特别是)哺乳动物。“哺乳动物”包括但不限于小鼠、大鼠、兔子、豚鼠、狗、猫、绵羊、山羊、牛、马、灵长类动物(诸如猴、黑猩猩和猿)以及(特别是)人。
本文提供的一些实施方案涉及一种同时分析样本中的多种感兴趣分析物的方法,其中感兴趣分析物是核酸或氨基酸中的一者或多者,诸如DNA、RNA、蛋白质、或任何其他细胞生物分子、或其他感兴趣靶分子。
样本可为得自环境来源的流体或标本。例如,从环境源获得的流体或标本可获自或来源于食物产品、食物作物、家禽、肉类、鱼类、饮料、乳制品、水(包括废水)、池塘、河流、水库、游泳池、土壤、食物加工和/或包装工厂、农业场所、水生养殖场(包括水培食物农场)、制药工厂、动物群设施、或它们的任何组合。在一些实施方案中,样本是收集或来源于细胞培养物或微生物菌落的流体或标本。
如本文所用,“分析物”、“靶标分析物”、“感兴趣分析物”可互换使用,并且是指在本文所公开的方法和体系中测量的分析物。在一些实施方案中,分析物可为生物分子。生物分子的非限制性示例包括大分子诸如多核苷酸(例如DNA或RNA)、蛋白质、脂质和碳水化合物。在某些情况下,分析物可为激素、抗体、生长因子、细胞因子、酶、受体(例如神经、激素、营养物质和细胞表面受体)或它们的配体、癌症标志物(例如PSA、TNF-α)、心肌梗塞标志物(例如肌钙蛋白、肌酸激酶等)、毒素、药物(例如成瘾药物)、代谢药剂(例如包括维生素)等。蛋白质分析物的非限制性实施方案包括肽、多肽、蛋白质片段、蛋白质复合物、融合蛋白、重组蛋白、磷蛋白、糖蛋白、脂蛋白、带寡核苷酸标签的蛋白质等。靶分析物可为核酸。
靶核酸可包括这样的样本:其中该样本中核酸的平均尺寸小于、大于或等于约2kb、1kb、500bp、400bp、200bp、100bp、50bp或介于前述尺寸中的任何两个尺寸之间的范围。在一些实施方案中,样本中核酸的平均尺寸小于、大于或等于约2000个核苷酸、1000个核苷酸、500个核苷酸、400个核苷酸、200个核苷酸、100个核苷酸、50个核苷酸或介于前述尺寸中的任何两个尺寸之间的范围。
如本文所用,“多核苷酸”和“核酸”可互换使用,并且可指任何长度的核苷酸的聚合形式,即核糖核苷酸或脱氧核糖核苷酸。因此,这些术语包括单链、双链或多链DNA或RNA。多核苷酸的示例包括基因或基因片段、全基因组DNA、基因组DNA、表观基因组DNA片段、基因组DNA片段、外显子、内含子、信使RNA(mRNA)、调控RNA、转移RNA、核糖体RNA、非编码RNA(ncRNA)诸如PIWI相互作用RNA(piRNA)、小干扰RNA(siRNA)和长非编码RNA(lncRNA)、小发夹(shRNA)、小核RNA(snRNA)、微RNA(miRNA)、小核仁RNA(snoRNA)和病毒RNA、核酶、cDNA、重组多核苷酸、支链多核苷酸、质粒、载体、任何序列的分离DNA、任何序列的分离RNA、核酸探针、引物、或前述任一项的扩增拷贝。多核苷酸可包含经修饰的核苷酸,诸如甲基化的核苷酸和核苷酸类似物,包括具有非天然碱基的核苷酸、具有经修饰的天然碱基诸如氮杂或去氮杂嘌呤的核苷酸。多核苷酸可由以下四个核苷酸碱基的特定序列构成:腺嘌呤(A)、胞嘧啶(C)、鸟嘌呤(G)和胸腺嘧啶(T)。当多核苷酸是RNA时,尿嘧啶(U)也可例如作为胸腺嘧啶的天然替代物存在。尿嘧啶也可用于DNA。术语“核酸序列”可以指多核苷酸或任何核酸分子(包括天然和非天然碱基)的字母表示。
核酸可含有磷酸二酯键,并且可包括其他类型的主链,包括例如磷酰胺、硫代磷酸酯、二硫代磷酸酯、O-甲基亚磷酰胺、以及肽核酸主链和键。核酸可含有脱氧核糖核苷酸和核糖核苷酸的任何组合;以及碱基的任何组合,这些碱基包括尿嘧啶、腺嘌呤、胸腺嘧啶、胞嘧啶、鸟嘌呤、肌苷、黄原胶、次黄嘌呤、异胞嘧啶、异鸟嘌呤;以及碱基类似物,诸如硝基吡咯(包括3-硝基吡咯)和硝基吲哚(包括5-硝基吲哚)。在一些实施方案中,核酸可包含至少一种混杂碱基(promiscuous base)。混杂碱基可与不止一种不同类型的碱基进行碱基配对,并且例如,当包含在用于在复杂核酸样本(诸如基因组DNA样本)中随机杂交的寡核苷酸引物或插入物中时,可以使用该混杂碱基。混杂碱基的示例包括可与腺嘌呤、胸腺嘧啶或胞嘧啶配对的肌苷。其他示例包括次黄嘌呤、5-硝基吲哚、非环状5-硝基吲哚、4-硝基吡唑、4-硝基咪唑和3-硝基吡咯。可使用可与至少两种、三种、四种或更多种类型的碱基进行碱基配对的混杂碱基。
如本文所用,术语“同时”是指动作同时或基本上同时发生。因此,同时分析多种分析物是指在单一测定中同时或基本上同时分析多种分析物。类似地,同时收集或得到可测序元件是指同时或基本上同时收集或得到可测序元件。
如本文所用,术语“标签”是指对一种或多种感兴趣分析物的修饰,使得稍后可分离、识别、跟踪或分析感兴趣分析物。因此,标签可识别样本中的感兴趣分析物。标签可包括例如聚腺苷酸化(polyA)标签。在一些实施方案中,标签可包括长度为至少1个核苷酸、至少2个核苷酸、至少3个核苷酸、至少4个核苷酸、至少5个核苷酸、至少10个核苷酸、至少15个核苷酸、至少20个核苷酸、至少25个核苷酸、至少30个核苷酸、至少35个核苷酸、至少40个核苷酸、至少45个核苷酸、至少50个核苷酸或50个核苷酸或更大,或在前述长度中的任何两个长度范围内的核苷酸序列。在一些实施方案中,通过片段标签化来执行加标签。如本文所用,“片段标签化”可指将转座子插入到靶核酸中,使得转座子切割靶核酸,并且将衔接子序列添加到所切割的靶核酸的末端。片段标签化的示例性方法公开于美国专利第9,115,396号、第9,080,211号、第9,040,256号、以及美国专利申请公布2014/0194324,这些专利中的每一篇专利均全文以引用方式并入本文。在一些实施方案中,标签对于每种感兴趣分析物而言是相同或不同的。例如,每种感兴趣分析物可用相同的标签加标签,或可用不同的标签加标签。差异加标签(例如)是指以使得将一种感兴趣分析物(诸如DNA)加标签不同于或有别于将另一种感兴趣分析物(诸如RNA)加标签的方式来加标签。在一些实施方案中,标签对于每种分析物而言是不同的,但标签的关系事先是已知的。
基于转座子的技术可用于使DNA片段化,例如如用于NEXTERA
转座反应是其中一个或多个转座子在随机位点或几乎随机位点处插入到靶标核酸中的反应。转座反应中的组分包括转座酶(或能够片段化并将如本文所述的核酸加标签的其他酶,诸如整合酶)和转座子元件,该转座子元件包括结合转座酶(或如本文所述的其他酶)的双链转座子末端序列,以及附接到两个转座子末端序列中的一个转座子末端序列上的衔接子序列。双链转座子末端序列的一条链被转移到靶核酸的一条链上,而互补转座子末端序列链未转移到靶核酸链上(未转移的转座子序列)。根据需要或期望,衔接子序列可包括一种或多种功能序列或组分(例如,引物序列、锚定序列、通用序列、间隔区或索引标签序列)。
“转座体复合物”由至少一种转座酶(或如本文所述的其他酶)和转座子识别序列构成。在一些此类体系中,转座酶结合转座子识别序列以形成能够催化转座反应的功能性复合物。在某些方面,转座子识别序列为双链转座子末端序列。转座酶结合靶标核酸中的转座酶识别位点并将转座子识别序列插入到靶标核酸中。在一些此类插入事件中,转座子识别序列(或末端序列)的一条链被转移到靶标核酸中,导致切割事件。可容易地适于与本公开的转座酶一起使用的示例性转座程序和体系在例如PCT公布第WO10/048605号、美国专利公布第2012/0301925号、美国专利公布第2012/13470087号或美国专利公布第2013/0143774号中有描述,这些专利中的每一篇均全文以引用方式并入本文。
可与本文提供的某些实施方案一起使用的示例性转座酶包括以下转座酶或由以下转座酶编码:Tn5转座酶(参见Reznikoff等人,Biochem.Biophys.Res.Commun.1999年,第266卷,第729-734页)、Sleeping Beauty(SB)转座酶、哈氏弧菌(Vibrio harveyi)(转座酶,通过Agilent来表征并用于SureSelect QXT产物)、MuA转座酶和包含R1和R2末端序列的Mu转座酶识别位点(Mizuuchi,K.,Cell,第35卷,第785页,1983年;Savilahti,H等人,EMBOJ.,第14卷:第4893页,1995年)、金黄色葡萄球菌(Staphylococcus aureus)Tn552(Colegio,O.等人,J.Bacteriol.,第183卷:第2384-2388页,2001年;Kirby,C.等人,Mol.Microbiol.,第43卷:第173-186页,2002年)、Ty1(Devine&Boeke,Nucleic AcidsRes.,第22卷:第3765-3772页,1994年和PCT公布第WO95/23875号)、Transposon Tn7(Craig,N.L.,Science,第271卷:第1512页,1996年;Craig,N.L.,Curr.Top.Microbiol.Immunol.,第204卷:第27-48页,1996年)、Tn/O和IS10(Kleckner N.等人,Curr.Top.Microbiol.Immunol.,第204卷:第49-82页,1996年)、Mariner转座酶(Lampe,D.J.等人,EMBO J.,第15卷:第5470-5479页,1996年)、Tc1(Plasterk,R.H.,Curr.Top.Microbiol.Immunol.,第204卷:第125-143页,1996年)、P Element(Gloor,G.B.,Methods Mol.Biol.,第260卷:第97-114页,2004年)、Tn3(Ichikawa和Ohtsubo,J.Biol.Chem.,第265卷:第18829-18832页,1990年)、细菌插入序列(Ohtsubo和Sekine,Curr.Top.Microbiol.Immunol.第204卷:第1-26页,1996年)、逆转录病毒(Brown等人,Proc.Natl.Acad.Sci.USA,第86卷:第2525-2529页,1989年)和酵母反转录转座子(Boeke和Corces,Ann.Rev.Microbiol.第43卷:第403-434页,1989年)。更多的示例包括IS5、Tn10、Tn903、IS911以及转座酶家族酶的工程化形式(Zhang等人,(2009)PLoS Genet.第5卷:第e1000689页Epub,10月16日;Wilson C.等人,(2007)J.Microbiol.Methods,第71卷:第332-335页),本文相对于转座酶引用的参考文献中的每一篇全文以引用方式并入本文。本文所述的方法还可包括转座酶的组合,而不仅仅是单一转座酶。
在一些实施方案中,转座酶是Tn5、MuA或哈氏弧菌转座酶、或其活性突变体。在其他实施方案中,转座酶是Tn5转座酶或其活性突变体。在一些实施方案中,Tn5转座酶是超高活性Tn5转座酶(参见例如Reznikoff等人,PCT公布第WO2001/009363号,美国专利第5,925,545号、第5,965,443号、第7,083,980号和第7,608,434号;以及Goryshin和Reznikoff,J.Biol.Chem.第273卷:第7367页,1998年),或其活性突变体。在一些方面,Tn5转座酶是如PCT公布第WO2015/160895号中所述的Tn5转座酶,该专利以引用方式并入本文。在一些实施方案中,Tn5转座酶是融合蛋白质。在一些实施方案中,Tn5转座酶融合蛋白质包含融合的延长因子Ts(Tsf)标签。在一些实施方案中,Tn5转座酶是相对于野生型序列在氨基酸54、56和372处包含突变的超高活性Tn5转座酶。在一些实施方案中,超高活性Tn5转座酶是融合蛋白质,任选地,其中融合蛋白质是延长因子Ts(Tsf)。在一些实施方案中,识别位点是Tn5型转座酶识别位点(Goryshin和Reznikoff,J.Biol.Chem.,第273卷:第7367页,1998年)。在一个实施方案中,使用与超高活性Tn5转座酶形成复合物的转座酶识别位点(例如EZ-Tn5
在本文所述的方法、组合物或体系的实施方案中的任何实施方案中,转座子包括转座子末端序列。在一些实施方案中,转座子末端序列为嵌合端(ME)序列。在一些实施方案中,使用片段标签化将DNA加标签,其中DNA用标签加标签,并且转座子特异性序列(诸如ME序列)包括在标签中。因此,基于转座子特异性序列,DNA与样本中的RNA区分开。
在本文所述的方法、组合物或体系的实施方案中的任何实施方案中,转座子包括衔接子序列。衔接子序列可包括一种或多种功能序列或组分,这些功能序列或组分选自引物序列、锚定序列、通用序列、间隔区、索引序列、捕获序列、条形码序列、切割序列、测序相关序列以及它们的组合。在一些实施方案中,衔接子序列包括引物序列。在其他实施方案中,衔接子序列包括引物序列和索引或条形码序列。引物序列也可以是通用序列。本公开不限于可以使用的衔接子序列的类型,并且技术人员将认识到可用于文库制备和下一代测序的另外的序列。通用序列是两个或更多个核酸片段共有的核苷酸序列区域。任选地,该两个或更多个核酸片段还具有序列差异区域。可存在于多个核酸片段的不同成员中的通用序列可允许使用与通用序列互补的单个通用引物来复制或扩增多个不同序列。
衔接子包括核酸,例如单链核酸。衔接子可包括长度小于、大于或等于约5个核苷酸、10个核苷酸、20个核苷酸、30个核苷酸、40个核苷酸、50个核苷酸、60个核苷酸、70个核苷酸、80个核苷酸、90个核苷酸、100个核苷酸或在前述尺寸中任何两个尺寸之间的范围内的短核酸。
在实施方案中的任何实施方案中,如下提供了衔接子序列或转座子末端序列,包括A14-ME、ME、B15-ME、ME'、A14、B15和ME:
A14-ME:5'-TCGTCGGCAGCGTCAGATGTGTATAAGAGACAG-3'(SEQ ID NO:1)
B15-ME:5'-GTCTCGTGGGCTCGGAGATGTGTATAAGAGACAG-3'(SEQ ID NO:2)
ME':5'-phos-CTGTCTCTTATACACATCT-3'(SEQ ID NO:3)
A14:5'-TCGTCGGCAGCGTC-3'(SEQ ID NO:4)
B15:5'-GTCTCGTGGGCTCGG-3'(SEQ ID NO:5)
ME:AGATGTGTATAAGAGACAG(SEQ ID NO:6)
在一些实施方案中,包括引物序列以制备用于测序的文库。在一些实施方案中,引物序列为P5引物序列或P7引物序列。P5和P7引物在由Illumina,Inc.销售的商业流通池的表面上使用,用于在各种Illumina平台上测序。引物序列在美国专利公布第2011/0059865A1号中有所描述,该专利公布全文以引用方式并入本文。P5和P7引物(其可以是在5'末端封端的炔烃)的示例包括如下引物:
P5:AATGATACGGCGACCACCGAGAUCTACAC(SEQ ID NO:7)
P7:CAAGCAGAAGACGGCATACGAG*AT(SEQ ID NO:8)
以及它们的衍生物或类似物。在一些示例中,P7序列包括在G*位置处的经修饰的鸟嘌呤,例如8-氧代-鸟嘌呤。在其他示例中,*表示G*与相邻的3'A之间的键为硫代磷酸酯键。在一些示例中,P5和/或P7引物包括非天然接头。任选地,P5和P7引物中的一者或两者可包括poly T尾。poly T尾通常位于上文所示序列的5'末端处,例如介于5'碱基和末端炔烃单元之间,但在一些情况下可位于3'末端处。poly T序列可包含任何数量(例如2个至20个)的T核苷酸。虽然P5和P7引物作为示例提供,但应当理解,任何合适的引物都可用于本文提出的示例中。具有引物序列(包括P5和P7引物序列)的索引序列用来添加P5和P7以激活用于测序的文库。
如本文所用,术语“探针”是指具有足够的结合特性以特异性结合靶分析物(例如结合靶分析物上的标签)的捕获分子。例如,探针可包括具有足够的互补性以特异性杂交至靶核酸的多核苷酸。例如,探针可包含用于特异性结合polyA标签的polyT序列。在另一个示例中,探针包含抗体或蛋白质标签。捕获探针可用作用于将靶核酸与混合物中的其他核酸和/或组分分离的亲和结合分子。靶核酸也可通过介入分子(诸如接头、衔接子和具有足够互补性以特异性杂交至靶序列和捕获探针两者的其他桥接核酸)由捕获探针特异性结合。
在一些实施方案中,探针还包含条形码。条形码将靶标识别为来自某个样本。例如,条形码用于将一种或多种分析物识别为来自共同来源。识别一种分析物的条形码可以与识别不同分析物的条形码相同或不同。只要条形码之间的关系是已知的,条形码就可用于将分析物识别为来自共同来源。
在一些实施方案中,条形码可包括可用于识别阵列内的多核苷酸的核酸序列。该条形码可包括与其他条形码可区分的独特核苷酸序列。该条形码还可通过条形码的序列,也可通过条形码在多核苷酸内的位置,例如通过引物结合位点的5'位置,与多核苷酸和靶核酸中的其他核苷酸序列区分开来。例如,在一些实施方案中,条形码的序列可在多个核酸中存在不止一次;然而,位于引物结合位点5'处的条形码可被检测到。条形码可具有足以成为群体中的多个条形码内和/或被分析或询问的多个多核苷酸和靶核酸内的独特核苷酸序列的任何期望序列长度。在一些实施方案中,条形码是在约1-30个核苷酸或更大范围内的多核苷酸内的核酸或区域。例如,条形码可具有1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、或30个核苷酸或更长的长度。在一些实施方案中,条形码可为35、40、45或50个核苷酸或更长。在一些实施方案中,条形码可将阵列中的一个多核苷酸与另一个多核苷酸区分开来,使得每个条形码不同于另一个条形码。在一些实施方案中,条形码可将阵列中多核苷酸的一个群体与多核苷酸的另一个群体区分开来,使得一组条形码不同于另一组条形码。
在一些实施方案中,使用转座直接插入条形码。在此类实施方案中,不需要与固体载体的结合事件。因此,在本文提供的实施方案中的任一实施方案中,在存在或不存在固体载体的情况下同时分析感兴趣分析物。
在一些实施方案中,探针可固定在固体载体上。固体载体可包括例如蚀刻的表面、孔、覆盖的孔、阵列、流通池装置、微流体通道、小珠、磁性小珠、柱、小滴或微粒。在此类实施方案中,感兴趣分析物由固定化探针结合至固体载体,其中感兴趣分析物在固体载体上经受进一步的处理或分析。在一些实施方案中,固定化探针和固体载体用于溶液中。例如,固定化载体可以是小珠,而附接于小珠的探针可溶于溶液中,以捕获溶液中的感兴趣分析物(诸如DNA和RNA)。在此类实施方案中,带标签的感兴趣分析物在溶液中结合至探针,并且在溶液中给带标签的感兴趣分析物编条形码。有条形码的感兴趣分析物可在溶液中经受进一步处理或分析,或者可使用沉降测定(包括通过使用磁性小珠)沉降。
如本文所用,术语“流通池”是指包括固体表面的室,一种或多种流体试剂可流过该固体表面。可容易地用于本公开的方法中的流通池以及相关流体系统和检测平台的示例包括例如,微流体装置、微结构、微孔、微量滴定板等,并描述于例如以下文献中:Bentley等人,Nature,第456卷:第53-59卷(2008年);WO 04/018497;美国专利第7,057,026号;WO91/06678;WO 07/123744;美国专利7,329,492;美国专利第7,211,414号;美国专利第7,315,019号;美国专利第7,405,281号和US 2008/0108082,这些文献中的每一篇文献均以引用方式并入本文。
如本文所用,“阵列”可指不同微特征的群体,诸如包含多核苷酸的微特征,该微特征与表面相关联或附接,使得不同的微特征可根据相对位置彼此区分。阵列的单个特征可包括微特征的单个拷贝,或者该微特征的多个拷贝可作为阵列的单个特征处的微特征的群体而存在。每个特征处的微特征的群体通常是同质的,具有单个种类的微特征。因此,单个核酸序列的多个拷贝可存在于一个特征处,例如,存在于具有相同序列的多个核酸分子上。
在一些实施方案中,微特征的异质群体可存在于一个特征处。在一些实施方案中,特征可仅包括单一微观特征物类。在一些实施方案中,特征可包括多个不同的微观特征物类,诸如具有不同序列的核酸的混合物。阵列的相邻特征可彼此分散。特征可彼此邻近或由缺口隔开。在特征间隔开的实施方案中,相邻位点可分开例如小于100μm、50μm、10μm、5μm、1μm、0.5μm、100nm、50nm、10nm、5nm、1nm、0.5nm的距离或在前述距离中的任何两个距离范围内的任何距离。阵列上特征的布局也可根据相邻特征之间的中心至中心距离来理解。可用于本发明的阵列可具有中心至中心间距小于约100μm、50μm、10μm、5μm、1μm、0.5μm、100nm、50nm、10nm、5nm、1nm、0.5nm或在前述距离中的任何两个距离范围内的任何距离的相邻特征。在一些实施方案中,本文所述的距离值可表示阵列的相邻特征之间的平均距离。因此,除非有相反的明确说明,例如通过距离构成阵列的所有相邻特征之间的阈值距离的明确说明,否则并非所有相邻特征都需要落入指定范围内。实施方案可包括具有多种密度的特征的阵列。某些实施方案的密度的示例性范围包括约10,000,000个特征/cm
如本文所用,“表面”可指可与试剂、小珠或分析物接触的基板或支撑结构的一部分。表面可为基本上平坦的或平面的。另选地,表面可为圆形的或轮廓状的。可包括在表面上的示例性轮廓为孔、凹陷、柱、脊、通道等。可用作基板或支撑结构的示例性材料包括:玻璃,诸如改性的或官能化的玻璃;塑料,诸如丙烯酸、聚苯乙烯或苯乙烯与另一种材料的共聚物、聚丙烯、聚乙烯、聚丁烯、聚氨酯或特氟隆;多糖或交联多糖,诸如琼脂糖或琼脂糖凝胶;尼龙;硝化纤维;树脂;二氧化硅或基于二氧化硅的材料,包括硅和改性硅;碳纤维;金属;无机玻璃;光纤束,或多种其他聚合物。单一材料或几种不同材料的混合物可形成可用于本发明的表面。在一些实施方案中,表面包括孔。
如本文所用,“小珠”可指由刚性或半刚性材料制成的小主体。主体可具有例如以球形、椭圆形、微球形或其他公认的颗粒形状为特征的形状,无论是具有规则的尺寸还是不规则的尺寸。可用于小珠的示例性材料包括:玻璃,诸如改性的或官能化的玻璃;塑料,诸如丙烯酸、聚苯乙烯或苯乙烯与另一种材料的共聚物、聚丙烯、聚乙烯、聚丁烯、聚氨酯或特氟隆;多糖或交联多糖,诸如琼脂糖或琼脂糖凝胶;尼龙;硝化纤维;树脂;二氧化硅或基于二氧化硅的材料,包括硅和改性硅;碳纤维;金属;无机玻璃;光纤束,或多种其他聚合物。示例性小珠包括可控孔玻璃小珠、顺磁性小珠、氧化钍溶胶、琼脂糖小珠、纳米晶体和本领域已知的其他小珠。小珠可由生物或非生物材料制成。由于易于使用磁体来操纵磁性小珠,因此磁性小珠特别有用。用于某些实施方案中的小珠可具有0.1μm至100μm的直径、宽度或长度。可将小珠尺寸选择成具有减小的尺寸,从而具有增大的密度,同时保持足够强的信号以分析特征。
如本文所用,“杂交”、“使…杂交”或其语法等同形式可指其中一种或多种多核苷酸反应形成复合物的反应,该复合物至少部分地经由核苷酸残基的碱基之间的氢键形成。氢键可通过Watson-Crick碱基配对、Hoogstein结合或以任何其他序列特异性方式出现。复合物可具有形成双链体结构的两条链、形成多链复合物的三条或更多条链、单条自杂交链或它们的任何组合。除了氢键之外,这些链还可通过力交联或以其他方式接合。
如本文所用,“使…延伸”、“延伸”或其任何语法等同形式可指通过延伸酶诸如聚合酶向引物、多核苷酸或其他核酸分子添加dNTP。例如,在本文所公开的一些实施方案中,所得的延伸引物包括核酸的序列信息。虽然一些实施方案被论述为使用聚合酶诸如DNA聚合酶或逆转录酶进行延伸,但延伸也可以本领域熟知的任何其他方式进行。例如,延伸可通过将寡核苷酸(诸如已杂交至感兴趣链的寡核苷酸)连接在一起来执行。
如本文所用,“连接”、“将…连接”或其其他语法等同形式可指通过磷酸二酯键接合两条核苷酸链。连接可包括化学连接。此类反应可由连接酶催化。连接酶是指通过ATP或类似的三磷酸酯的水解来催化该反应的一类酶。
本文提供的一些实施方案涉及使用单一测定同时分析样本中的多种分析物,其中多种分析物包括DNA和RNA。在一些实施方案中,通过加标签来修饰靶DNA和靶RNA。因此,在一些实施方案中,该方法包括用第一标签修饰样本中的DNA,以及用第二标签修饰样本中的RNA。在一些实施方案中,该方法包括用与第一标签互补的第一探针捕获经修饰的DNA,以及用与第二标签互补的第二探针捕获经修饰的RNA。在一些实施方案中,该方法包括分析所捕获的DNA和RNA。如本文所用,术语“第一标签”和“第二标签”不是指加标签事件的任何特定时序或顺序。相反,这些术语仅用于描述第一分析物包含一个标签(称为例如第一标签),并且第二分析物包含另一个标签(称为例如第二标签)。在本文所述的实施方案中的任何实施方案中,第一标签和第二标签可以是相同或不同的。条形码将分析物识别为来自共同来源,而标签将分析物识别为某种类型,例如DNA或RNA。
在一些实施方案中,除了分析DNA和RNA之外,该方法还包括同时分析另外的感兴趣分析物,例如分析蛋白质。在此类实施方案中,另外的感兴趣分析物(诸如蛋白质)用另外的标签修饰。
在一些实施方案中,第一标签和第二标签(或相关的附加标签)是不同的。在一些实施方案中,第一标签和第二标签(或相关的附加标签)是相同的。在一些实施方案中,第一标签和第二标签还包含底物识别序列。底物识别序列是识别底物并与其结合,从而固定标签的序列。在一些实施方案中,第一标签的底物识别序列与第二标签的底物识别序列是相同的。
在一些实施方案中,经由片段标签化过程将DNA加标签,如图2所示。在图2的实施方案中,示出了具有分离的单个细胞或细胞核15的孔板10。细胞核15包括细胞核15内的DNA20和mRNA 25。单个细胞或细胞核15可包封在小滴中或在单个孔中分离以供分析。DNA 20被示出为带有TAG1标签,其可通过片段标签化或其他加标签过程(诸如逆转录、连接、或其他用于将DNA加标签的方式)得到。在图2的实施方案中,mRNA 25带有TAG2标签。图2还描绘了固定在固体载体40上的探针30、35,该固体载体可以是小珠或其他表面。对DNA 20具有特异性的探针30包括TAG1捕获元件,该捕获元件是特异性结合DNA 20上的TAG1的捕获元件。对mRNA 25具有特异性的探针35包括TAG2捕获元件,该捕获元件是特异性结合mRNA 25上的TAG2的捕获元件。每个探针还包括条形码,从而允许对感兴趣分析物(在这种情况下为DNA和mRNA)进行索引。
在一些实施方案中,未将包含polyA尾的mRNA加标签。例如,在图3所示的实施方案中,孔板200具有细胞核205,该细胞核包含具有polyA尾215,但不以其他方式加标签的mRNA210。在图3的实施方案中,gDNA220用polyA尾215加标签。在将gDNA 220加标签后,gDNA 220和mRNA210均包含polyA尾215。可使用例如片段标签化用polyA尾215将gDNA220加标签。如图3所示,具有polyA尾215的gDNA 220和也具有polyA尾215的mRNA 210可用含有polyT捕获元件230的相同探针225捕获。探针225固定在固体载体240上。因此,同时处理gDNA 220和mRNA 210并为其分配相同的条形码235。可基于在片段标签化过程中掺入的转座子特异性序列,将gDNA 220与mRNA 210区分开。该概念将参考图4作进一步详述。
图4描绘了同时分析单个样本中的gDNA和mRNA两者的示例性方法。在该实施方案中,通过转座将polyA转座子引入基因组DNA中。细胞核/细胞用具有polyT尾的索引探针包封。将索引探针杂交,然后连接至转座的gDNA片段,并与mRNA杂交。这产生第一cDNA。转座后,gDNA包含ME序列、片段标签化特异性序列。在第二cDNA合成之后,再次转座双链cDNA和gDNA以掺入PCR衔接子。然后制备片段以用于PCR扩增。
如本文所用,术语“试剂”描述可用于与样本反应、与样本相互作用、稀释样本或加入样本的试剂或者两种或更多种试剂的混合物,并且可包括用于本文所述的测定中的试剂,包括用于裂解、核酸分析、核酸扩增反应、蛋白质分析、片段标签化反应、ATAC-seq、CPT-seq或SCI-seq反应或其他测定的试剂。因此,试剂可包括例如缓冲液、化学品、酶、聚合酶、尺寸小于50个碱基对的引物、模板核酸、核苷酸、标记物、染料或核酸酶。在一些实施方案中,试剂包括溶菌酶、蛋白酶K、随机六聚体、聚合酶(例如Φ29DNA聚合酶、Taq聚合酶、Bsu聚合酶)、转座酶(例如Tn5)、引物(例如P5和P7衔接子序列)、连接酶、催化酶、三磷酸脱氧核苷酸、缓冲液或二价阳离子。
在一些实施方案中,样本包含单个细胞,并且单个细胞是固定的。在一些实施方案中,细胞可用固定剂固定。如本文所用,固定剂通常是指可固定细胞的试剂。例如,固定的细胞可稳定细胞中的蛋白质复合物、核酸复合物或蛋白质-核酸复合物。合适的固定剂和交联剂可包括基于醇或醛的固定剂;甲醛;戊二醛;基于乙醇的固定剂;基于甲醇的固定剂;丙酮;乙酸;四氧化锇;重铬酸钾;铬酸;高锰酸钾;汞剂;苦味酸盐;福尔马林;多聚甲醛;胺反应性NHS-酯交联剂,诸如双[磺基琥珀酰亚胺基]辛二酸酯(BS3)、3,3'-二硫代双[磺基琥珀酰亚胺基丙酸酯](DTSSP)、乙二醇双[磺基琥珀酰亚胺基琥珀酸酯](磺基-EGS)、双琥珀酰亚胺戊二酸酯(DSG)、二硫代双[琥珀酰亚胺基丙酸酯](DSP)、双琥珀酰亚胺基辛二酸酯(DSS)、乙二醇双[琥珀酰亚胺基琥珀酸酯](EGS);NHS-酯/双吖丙啶交联剂,诸如NHS-双吖丙啶、NHS-LC-双吖丙啶、NHS-SS-双吖丙啶、磺基-NHS-双吖丙啶、磺基-NHS-LC-双吖丙啶和磺基-NHS-SS-双吖丙啶。在一些实施方案中,固定细胞保留细胞的内部状态,从而防止细胞在后续分析期间或在执行测定期间被修饰。
在一些实施方案中,样本包括核酸源,诸如单个细胞、单个细胞核、或细胞群、或细胞核群,并且单个细胞、单个细胞核、细胞群或细胞核群包封在小滴内。在一些实施方案中,在包封之前固定细胞。如本文所用,小滴可包括水凝胶小珠,该水凝胶小珠是用于包封单个细胞并且由水凝胶组合物构成的小珠。在一些实施方案中,小滴是水凝胶材料的均质小滴或者是具有聚合物水凝胶外壳的中空小滴。无论是均质的还是中空的,小滴均能够包封单个细胞。如本文所用,术语“水凝胶”是指当有机聚合物(天然的或合成的)通过共价键、离子键或氢键交联以产生夹带水分子以形成凝胶的三维开放晶格结构时所形成的物质。在一些实施方案中,水凝胶可为生物相容性水凝胶。如本文所用,术语“生物相容性水凝胶”是指形成凝胶的聚合物对活细胞无毒并且允许氧和营养物质充分扩散到包埋的细胞以保持活力。在一些实施方案中,水凝胶材料包括藻酸盐、丙烯酰胺或聚乙二醇(PEG)、PEG-丙烯酸酯、PEG-胺、PEG-羧酸酯、PEG-二硫醇、PEG-环氧化物、PEG-异氰酸酯、PEG-马来酰亚胺、聚丙烯酸(PAA)、聚(甲基丙烯酸甲酯)(PMMA)、聚苯乙烯(PS)、聚苯乙烯磺酸酯(PSS)、聚乙烯吡咯烷酮(PVPON)、N,N'-双(丙烯酰基)胱胺、聚环氧丙烷(PPO)、聚(甲基丙烯酸羟乙酯)(PHEMA)、聚(N-异丙基丙烯酰胺)(PNIPAAm)、聚(乳酸)(PLA)、聚(乳酸-共-乙醇酸)(PLGA)、聚已酸内酯(PCL)、聚(乙烯基磺酸)(PVSA)、聚(L-天冬氨酸)、聚(L-谷氨酸)、聚赖氨酸、琼脂、琼脂糖、肝素、藻酸硫酸酯、葡聚糖硫酸酯、透明质酸、果胶、角叉菜胶、明胶、脱乙酰壳多糖、纤维素、胶原、双丙烯酰胺、二丙烯酸酯、二烯丙基胺、三烯丙基胺、二乙烯基砜、二乙二醇二烯丙基醚、乙二醇二丙烯酸酯、聚亚甲基二醇二丙烯酸酯、聚乙二醇二丙烯酸酯、三羟甲基丙烷三甲基丙烯酸酯、乙氧基化三羟甲基三丙烯酸酯、或乙氧基化季戊四醇四丙烯酸酯、或它们的组合或混合物。在一些实施方案中,水凝胶为藻酸盐、丙烯酰胺或基于PEG的材料。在一些实施方案中,水凝胶是具有丙烯酸酯-二硫醇、环氧化物-胺反应化学性质的基于PEG的材料。在一些实施方案中,水凝胶形成包含PEG-马来酰亚胺/二硫醇油、PEG-环氧化物/胺油、PEG-环氧化物/PEG-胺、或PEG-二硫醇/PEG-丙烯酸酯的聚合物外壳。在一些实施方案中,将水凝胶材料选择成避免产生能够损害细胞内生物分子的自由基。在一些实施方案中,水凝胶聚合物包含60%-90%的流体(诸如水)和10-30%的聚合物。在某些实施方案中,水凝胶的水含量为约70-80%。如本文所用,当修饰数值时,术语“约”或“大约”是指可在数值中发生的变化。例如,变化可通过特定底物或组分的制造差异而发生。在一个实施方案中,术语“约”意指在所述数值的1%、5%、或至多10%内。
水凝胶可通过使亲水性生物聚合物或合成聚合物交联来制备。因此,在一些实施方案中,水凝胶可包含交联剂。如本文所用,术语“交联剂”是指当与适当的碱单体反应时可形成三维网络的分子。可包含一种或多种交联剂的水凝胶聚合物的示例包括但不限于透明质酸、脱乙酰壳多糖、琼脂、肝素、硫酸酯、纤维素、藻酸盐(包括藻酸硫酸酯)、胶原、葡聚糖(包括葡聚糖硫酸酯)、果胶、角叉菜胶、聚赖氨酸、明胶(包括明胶A型)、琼脂糖、(甲基)丙烯酸酯-低聚乳酸-PEO-低聚乳酸-(甲基)丙烯酸酯、PEO-PPO-PEO共聚物(Pluronics)、聚(磷腈)、聚(甲基丙烯酸酯)、聚(N-乙烯基吡咯烷酮)、PL(G)A-PEO-PL(G)A共聚物、聚(乙烯亚胺)、聚乙二醇(PEG)-硫醇、PEG-丙烯酸酯、丙烯酰胺、N,N'-双(丙烯酰基)胱胺、PEG、聚环氧丙烷(PPO)、聚丙烯酸、聚(甲基丙烯酸羟乙酯)(PHEMA)、聚(甲基丙烯酸甲酯)(PMMA)、聚(N-异丙基丙烯酰胺)(PNIPAAm)、聚(乳酸)(PLA)、聚(乳酸-共-乙醇酸)(PLGA)、聚己酸内酯(PCL)、聚(乙烯基磺酸)(PVSA)、聚(L-天冬氨酸)、聚(L-谷氨酸)、双丙烯酰胺、二丙烯酸酯、二烯丙基胺、三烯丙基胺、二乙烯基砜、二乙二醇二烯丙基醚、乙二醇二丙烯酸酯、聚亚甲基二醇二丙烯酸酯、聚乙二醇二丙烯酸酯、三羟甲基丙烷三甲基丙烯酸酯、乙氧基化三羟甲基三丙烯酸酯、或乙氧基化季戊四醇四丙烯酸酯、或它们的组合。因此,例如,组合可包括聚合物和交联剂,例如聚乙二醇(PEG)-硫醇/PEG-丙烯酸酯、丙烯酰胺/N,N'-双(丙烯酰基)胱胺(BACy)、或PEG/聚环氧丙烷(PPO)。在一些实施方案中,聚合物外壳包含四臂聚乙二醇(PEG)。在一些实施方案中,四臂聚乙二醇(PEG)选自PEG-丙烯酸酯、PEG-胺、PEG-羧酸酯、PEG-二硫醇、PEG-环氧化物、PEG-异氰酸酯和PEG-马来酰亚胺。
在一些实施方案中,交联剂为瞬时交联剂或缓慢交联剂。瞬时交联剂是使水凝胶聚合物瞬时交联的交联剂,并且在本文中被称为点击化学。瞬时交联剂可包括二硫醇油+PEG-马来酰亚胺或PEG环氧化物+胺油。缓慢交联剂是使水凝胶聚合物缓慢交联的交联剂,并且可包括PEG-环氧化物+PEG-胺、或PEG-二硫醇+PEG-丙烯酸酯。缓慢交联剂可能需要超过若干小时来交联,例如超过2、3、4、5、6、7、8、9、10、11或12小时来交联。在本文提供的一些实施方案中,小滴由瞬时交联剂配制,从而与缓慢交联剂相比更好地保持细胞状态。不希望受理论的束缚,细胞可能在较长的交联时间内通过细胞内信号转导机制发生生理变化。
在一些实施方案中,交联剂在水凝胶聚合物中形成二硫键,从而连接水凝胶聚合物。在一些实施方案中,水凝胶聚合物形成具有孔的水凝胶基质(例如,多孔水凝胶基质)。这些孔能够将足够大的颗粒(诸如单个细胞或从其中提取的核酸)保留在小滴内,但允许其他材料(诸如试剂)穿过孔,从而进入并离开小滴。在一些实施方案中,通过改变聚合物浓度与交联剂浓度的比率来微调小滴的孔尺寸。在一些实施方案中,聚合物与交联剂的比率为30:1、25:1、20:1、19:1、18:1、17:1、16:1、15:1、14:1、13:1、12:1、11:1、10:1、9:1、8:1、7:1、6:1、5:1、4:1、3:1、2:1、1:1、1:2、1:3、1:4、1:5、1:6、1:7、1:8、1:9、1:10、1:15、1:20或1:30,或者由前述比率中的任两个比率限定的范围内的比率。在一些实施方案中,可将另外的功能诸如DNA引物或带电化学基团接枝到聚合物基质以满足不同应用的要求。
如本文所用,术语“孔隙度”是指由开放空间(例如,孔或其他开口)构成的水凝胶的体积分数(无量纲)。因此,孔隙度测量材料中的空隙空间,并且是空隙在总体积中的体积分数,为介于0%和100%之间(或介于0和1之间)的百分比。水凝胶的孔隙度可在0.5至0.99、约0.75至约0.99、或约0.8至约0.95的范围内。
在一些实施方案中,小滴可具有允许试剂充分扩散同时附带地保留从其中提取的单个细胞或核酸的任何孔尺寸。如本文所用,术语“孔尺寸”是指孔的横截面的直径或有效直径。术语“孔径”也可指基于多个孔的测量结果的孔的横截面的平均直径或平均有效直径。非圆形横截面的有效直径等于具有与非圆形横截面相同的横截面积的圆形横截面的直径。在一些实施方案中,当水凝胶水合时,水凝胶可溶胀。然后,孔尺寸的尺寸可根据水凝胶中的水含量而变化。在一些实施方案中,水凝胶的孔可具有尺寸足以将包封的细胞保留在水凝胶内但允许试剂穿过的孔。在一些实施方案中,小滴的内部为水性环境。在一些实施方案中,设置在小滴内的单个细胞不与小滴的聚合物外壳相互作用并且/或者不与聚合物外壳接触。在一些实施方案中,聚合物外壳围绕细胞形成,并且由于聚合物外壳因被动吸附或以靶向方式(诸如通过附接于抗体或其他特异性结合分子)而被带到细胞表面,细胞与聚合物外壳接触。
在一些实施方案中,小滴具有足以包封单个细胞的尺寸。在一些实施方案中,小滴具有约20μm至约200μm,诸如20μm、30μm、40μm、50μm、60μm、70μm、80μm、90μm、100μm、110μm、120μm、130μm、140μm、150μm、160μm、170μm、180μm、190μm或200μm的直径,或由前述值中的任何两个值限定的范围内的直径。小滴的尺寸可因环境因素而改变。在一些实施方案中,当小滴与连续油相分离并浸入水相中时,小滴膨胀。在一些实施方案中,小滴的膨胀提高了对包封的细胞内部的遗传物质执行测定的效率。在一些实施方案中,小滴的膨胀为待在PCR期间扩增的索引插入片段形成更大的环境,否则该环境在当前基于细胞的测定中可能受限。
在一些实施方案中,小滴通过动态方式制备,诸如通过涡旋辅助的乳液、微流体小滴生成或基于阀的微流体制备。在一些实施方案中,小滴以均匀的尺寸分布配制。在一些实施方案中,通过调节微流体装置的尺寸、一条或多条通道的尺寸、或通过微流体通道的流速来微调小滴的尺寸。在一些实施方案中,所得小滴具有在20μm至200μm范围内的直径,例如20μm、25μm、30μm、35μm、40μm、45μm、50μm、55μm、60μm、65μm、70μm、75μm、80μm、85μm、90μm、95μm、100μm、110μm、120μm、130μm、140μm、150μm、160μm、170μm、180μm、190μm或200μm,或由前述值中任两个值限定的范围内的直径。
在一些实施方案中,分析一种或多种分析物可包括多种分析技术,这取决于分析物为何物。例如,分析可包括DNA分析、RNA分析、蛋白质分析、片段标签化、核酸扩增、核酸测序、核酸文库制备、染色质转座酶可及性测序测定(ATAC-seq)、保留邻近性转座(CPT-seq)、单细胞组合索引测序(SCI-seq)、或单细胞基因组扩增、或它们的任何组合。
DNA分析是指用于扩增、测序或以其他方式分析DNA的任何技术。DNA扩增可使用PCR技术或焦磷酸测序完成。DNA分析还可包括基于非靶向、非PCR的DNA测序(例如宏基因组学)技术。作为非限制性示例,DNA分析可包括对16S rDNA(核糖体DNA)的高变区进行测序,并使用该测序通过DNA进行物类鉴定。
RNA分析是指用于扩增、测序或以其他方式分析RNA的任何技术。用于分析DNA的相同技术可用于扩增RNA并对其进行测序。不如DNA稳定的RNA是DNA响应于刺激的翻译。因此,RNA分析可提供对群体的代谢活性成员的更准确描述,并且可用于提供关于样本中生物体的群体功能的信息。此外,DNA和RNA两者的同时分析可有益于有效确定DNA和RNA两者相关询问。核酸测序是指使用测序来确定核酸分子(诸如DNA或RNA)序列中核苷酸的顺序。
如本文所用,术语“测序”是指通过其获得多核苷酸的至少10个连续核苷酸的同一性(例如,至少20个、至少50个、至少100个或至少200个或更多个连续核苷酸的同一性)的方法。
术语“下一代测序”或“高通量测序”或“NGS”通常是指高通量测序技术,包括但不限于大规模平行测序、高通量测序、连接测序(例如SOLiD测序)、质子离子半导体测序、DNA纳米球测序、单分子测序和纳米孔测序,并且可以指Illumina、Life Technologies或Roche等目前采用的平行测序合成平台或测序连接平台。下一代测序方法还可包括纳米孔测序方法或基于电子检测的方法,诸如由Life Technologies商业化的Ion Torrent技术或由Pacific Biosciences商业化的基于单分子荧光的方法。
蛋白质分析是指蛋白质的研究,并且可包括蛋白质组学分析、感兴趣的蛋白质的翻译后修饰的测定、蛋白质表达水平的测定、或蛋白质与其他分子(包括与其他蛋白质或与核酸)的相互作用的测定。
如本文所用,术语“片段标签化”是指通过转座体复合物修饰DNA,该转座体复合物包含与包含转座子末端序列的衔接子复合的转座酶。片段标签化导致DNA的片段化和衔接子与双重片段的两条链的5'末端的连接同时发生。在移除转座酶的纯化步骤后,可例如通过PCR、连接或本领域技术人员已知的任何其他合适的方法将另外的序列添加到经修改片段的末端。
染色质转座酶可及性测序测定(ATAC-seq)是指一种综合表观基因组分析的快速且灵敏的方法。ATAC-seq捕获开放染色质位点并揭示开放染色质的基因组位置、DNA结合蛋白质、单独核小体和具有核苷酸分辨率的调控区处的更高级压缩结构之间的相互作用。已发现严格避免、可耐受或趋于与核小体重叠的DNA结合因子类别。使用ATAC-seq,测量静息人T细胞的系列每日表观基因组并通过标准抽血程序从先证者评估该系列每日表观基因组,从而表明在用于监测健康和疾病的临床时间尺度中读取个人表观基因组的可行性。更具体地讲,ATAC-seq可通过用插入酶复合物处理来自单个细胞的染色质以产生基因组DNA的带标签片段来执行。在该步骤中,使用插入酶诸如Tn5或MuA将染色质片段标签化(例如,在同一反应中进行片段化和加标签),该步骤在染色质的开放区域中切割基因组DNA并将衔接子添加到片段的两端。ATAC-seq允许仅在开放染色质状态中转座,如图5A所概述,并且通常描述于Buenrostro等人(Nature Methods,2013,10,1213-1218),该文献全文以引用方式并入本文。
在本文所述的方法、组合物或系统的实施方案中的任一个实施方案中,ATAC-seq可在单个细胞上或批量执行。单细胞ATAC-seq允许单细胞表观遗传学分析,并且例如通过将单个细胞或单个细胞核包封在小滴或小珠内,可在隔室中执行。如本文所用,术语“隔室”是指其中可发生反应的有限空间的物理或虚拟名称。例如,隔室可为小珠、小滴、孔或限定其中可保留组分的区域的其他物理参数,例如,其中单个细胞可经受实验和分析。术语“共隔室化”是指位于单一隔室内。例如,当两种分析物据称被共隔室化时,两种分析物均位于同一隔室内。共隔室化的反应产物是指置于同一隔室内或在同一隔室中制备的产物(例如,在相同反应条件下在单一环境中制备)。
单个细胞或单个细胞核在小珠或小滴内的包封可通过将单个细胞或细胞核分配在小珠内来执行。在包封时,使单个细胞经受ATAC-seq,如图5B所概述。在单细胞ATAC-seq中,可将细胞(或细胞核)单独隔室化、加标签和分析。这允许保留邻近性转座(CPT-seq),因为它确保来自单个细胞的所有DNA或文库被包封在单个小滴中。通常转座插入衔接子并在移除转座酶后将DNA片段化。片段化从而将来自多个细胞的读数扰乱成小滴,使得无法获得单个细胞分辨率。相比之下,本文提供的方法使得转座酶能够将所有单独的DNA/文库片段保持在一起,从而允许来自单个细胞的所有材料移动到单个小滴中。然后可使用有条形码的引物(来自装载到小滴中的小珠)通过PCR对来自单个小滴中的细胞的所有片段进行索引。CPT-seq通常描述于Amini等人(Nat Genet,2014,46,1343-1349),该文献全文以引用方式并入本文。此外,在一些实施方案中,单细胞ATAC-seq可用于组合索引。组合索引或分拆/合并索引可用于在同一孔或小滴中装载多个细胞,同时保持单个细胞/单个细胞核分辨率。在一些实施方案中,索引可用于样本识别、实验条件或用于相同的细胞。组合索引可用于增加小滴利用率和细胞通量,并且可与单个细胞或细胞核一起使用。
在一些情况下,可调整条件以在染色质中获得期望的插入水平(例如,在开放区域中平均每50个至200个碱基对发生一次插入)。用于该方法中的染色质可由任何合适的方法制得。在一些实施方案中,可将细胞核分离、裂解,并且可例如从核被膜进一步纯化染色质。在其他实施方案中,可通过使分离的细胞核与反应缓冲液接触来分离染色质。在这些实施方案中,分离的细胞核在与反应缓冲液(其包含插入酶复合物和其他必需的试剂)接触时可裂解,这允许插入酶复合物进入染色质。在这些实施方案中,该方法可包括从细胞群中分离细胞核;以及将所分离的细胞核与转座酶和衔接子组合,其中组合导致细胞核裂解以释放所述染色质并产生基因组DNA的带衔接子标签片段。染色质不需要像在其他方法(例如ChIP-SEQ方法)中那样的交联。
在染色质已被片段化并加标签以产生基因组DNA的带标签片段后,对带衔接子标签片段中的至少一些片段进行测序以产生多个序列读段。可使用任何合适的方法对片段进行测序。例如,可使用Illumina的可逆终止子方法、Roche的焦磷酸测序方法(454)、LifeTechnologies的连接测序(SOLiD平台)或Life Technologies的Ion Torrent平台对片段进行测序。此类方法的示例在以下参考文献中有所描述:Margulies等人,(Nature 2005437:376-80);Ronaghi等人,(Analytical Biochemistry 1996 242:84-9);Shendure等人,(Science 2005 309:1728-32);Imelfort等人,(Brief Bioinform.2009 10:609-18);Fox等人,(Methods Mol Biol.2009;553:79-108);Appleby等人,(Methods Mol Biol.2009;513:19-39)和Morozova等人,(Genomics.2008 92:255-64),这些文献以引用方式并入本文以了解方法和方法的特定步骤的一般描述,包括步骤中的每个步骤的所有起始产物、文库制备方法、试剂和最终产物。显而易见的是,可在扩增步骤期间将与选定下一代测序平台兼容的正向和反向测序引物位点添加至片段的末端。在某些实施方案中,可使用与已添加至片段的标签杂交的PCR引物来扩增片段,其中用于PCR的引物具有与特定测序平台兼容的5'尾。执行ATAC-seq的方法在PCT申请第PCT/US2014/038825号中示出,该申请全文以引用方式并入本文。
如本文所用,术语“染色质”是指如存在于真核细胞的细胞核中的包括蛋白质和多核苷酸(例如DNA、RNA)的分子的复合物。染色质部分地由组蛋白构成,形成核小体、基因组DNA和通常与基因组DNA结合的其他DNA结合蛋白质(例如转录因子)。
保留邻近性转座测序(CPT-seq)是指一种在通过使用转座酶保持靶标核酸中邻近的模板核酸片段的关联性来保持邻近性信息的同时进行测序的方法。例如,CPT可在核酸诸如DNA或RNA上进行。CPT-核酸可通过具有独特索引或条形码的互补寡核苷酸的杂交捕获并固定在固体载体上。在一些实施方案中,除了条形码之外,固定在固体载体上的寡核苷酸还可包含引物结合位点、独特的分子指数。有利地,此类使用转座体来保持片段化核酸的物理邻近性增加了来自相同初始分子(例如染色体)的片段化核酸从固定在固体载体上的寡核苷酸接收相同独特条形码和索引信息的可能性。这将产生具有独特条形码的连续链接测序文库。可对连续链接测序文库进行测序以获得连续的序列信息。
如本文所用,术语“邻近性信息”是指基于共享信息的两个或更多个DNA片段之间的空间关系。信息的共享方面可以是相对于相邻空间关系、隔室空间关系和距离空间关系。关于TUM中的这些关系的信息有利于来源于DNA片段的序列读段的层次组装或映射。这种邻近性信息提高了此类组装或映射的效率和准确性,因为与常规鸟枪测序相关联使用的传统组装或映射方法不考虑各个序列读段的相对基因组起源或坐标,因为它们与各个序列读段所源自的两个或更多个DNA片段之间的空间关系相关。
因此,根据本文所述的实施方案,捕获邻近性信息的方法可通过确定相邻空间关系的短程邻近性方法、确定隔室空间关系的中程邻近性方法或确定距离空间关系的长程邻近性方法来实现。这些方法有利于DNA序列组装或映射的准确性和质量,并且可与任何测序方法(诸如本文所述的那些)一起使用。
邻近性信息包括各个序列读段的相对基因组起源或坐标,因为它们与各个序列读段所源自的两个或更多个DNA片段之间的空间关系相关。在一些实施方案中,邻近性信息包括来自非重叠序列读段的序列信息。
在一些实施方案中,靶标核酸序列的邻近性信息指示单倍型信息。在一些实施方案中,靶标核酸序列的邻近性信息指示基因组变体。
单细胞组合索引测序(SCI-seq)是用于同时生成数千个低通单细胞文库以检测体细胞拷贝数变体的测序技术。本文提供的一些实施方案涉及使用组合索引方法(诸如通过SCI-seq)同时分析样本中的多种分析物的方法、组合物和系统。例如,如图10所示,可使用SCI-seq同时对DNA和RNA进行索引。在引入针对DNA和RNA的特异性标签后,将细胞/细胞核物理上分成多个组。对于每一组,DNA用第一条形码(图10中的条形码I)标记,RNA用第二条形码(图10中的条形码J)标记。DNA和RNA的标记可同时或相继发生。然后将这些组合并在一起并随机分成多个组,这些组可进一步用第三条形码(图10中的条形码K)标记。可将合并/分拆过程重复多轮以增加索引能力。索引冲突率(不同细胞/细胞核具有相同条形码)可通过每轮条形码的数量和每组中细胞/细胞核的数量来控制。条形码可通过逆转录酶、通过连接、通过片段标签化或通过其他用于引入条形码的方式引入。在一些实施方案中,本文所述的组合测序技术不需要从细胞分离或隔离细胞核。
图11还示出了组合测序(诸如通过SCI-seq)的细节,其中边索引边连接和延伸。通过转座将具有TAG1的转座子插入基因组DNA中。通过TAG1杂交将具有条形码I和TAG2的寡核苷酸连接至gDNA。第一cDNA合成由具有条形码J和TAG2的polyT寡核苷酸引发,随后是第二cDNA合成。在合并和拆分过程后,将具有条形码K的寡核苷酸与TAG2区域上的gDNA和cDNA两者杂交并通过缺口填充连接来连接。TAG3可用作拆分和合并之后下一轮索引的锚定件。在组合索引后,可通过第二转座添加另一端上的PCR/文库衔接子。
如本文所用,除非另外指明,否则本文所用的术语“分离”、“纯化”及其语法等同形式是指从分离出材料的样本或来源(例如细胞)中减少至少一种污染物(诸如蛋白质和/或核酸序列)的量。因此,纯化导致“富集”,例如样本中期望蛋白质和/或核酸序列的量有所增加。
在核酸的裂解和分离之后,可执行扩增,诸如多重置换扩增(MDA),这是用于扩增(尤其来自单个细胞的)少量DNA的广泛使用的技术。在一些实施方案中,核酸被扩增、测序或用于制备核酸文库。如本文所用,如关于核酸或核酸反应所用的术语“扩增”是指例如通过本发明的实施方案制备特定核酸(诸如靶核酸)的拷贝的体外方法。多种扩增核酸的方法是本领域已知的,并且扩增反应包括聚合酶链反应、连接酶链反应、链置换扩增反应、滚环扩增反应、基于多次退火和成环的扩增循环(MALBAC)、转录介导的扩增方法诸如NASBA、环介导的扩增方法(例如使用环形成序列的“LAMP”扩增)。扩增的核酸可以是包含DNA或RNA或DNA和RNA的混合物、由它们组成、或来源于它们的DNA,(包括经修饰的DNA和/或RNA)。无论起始核酸是DNA、RNA还是这两者,由一个或多个核酸分子的扩增得到的产物(例如,“扩增产物”)可以是DNA或RNA,或DNA和RNA核苷或核苷酸的混合物,或者它们可包括经修饰的DNA或RNA核苷或核苷酸。“拷贝”不一定意指与靶序列的完全序列互补性或同一性。例如,拷贝可包含核苷酸类似物,诸如脱氧肌苷或脱氧尿苷、有意的序列改变(诸如通过引物引入的序列改变和/或在扩增期间发生的序列错误,该引物包含可与靶序列杂交但不互补的序列)。
所捕获的核酸可根据本领域已知的任何合适的扩增方法来扩增。应当理解,本文所述的或本领域通常已知的扩增方法中的任一种方法可与通用引物或靶标特异性引物一起用于扩增核酸。合适的扩增方法包括但不限于聚合酶链反应(PCR)、链置换扩增(SDA)、转录介导的扩增(TMA)和基于核酸序列的扩增(NASBA),如美国专利第8,003,354号中所述,该专利全文以引用方式并入本文。上述扩增方法可用于扩增一种或多种感兴趣核酸。例如,可利用PCR(包括多重PCR)、SDA、TMA、NASBA等扩增核酸。在一些实施方案中,在扩增反应中包括特异性针对感兴趣核酸的引物。
其他合适的核酸扩增方法可包括寡核苷酸延伸和连接、滚环扩增(RCA)(Lizardi等人,Nat.Genet.第19卷:第225-232页(1998年),其以引用方式并入本文)和寡核苷酸连接测定(OLA)技术(通常参见美国专利第7,582,420号、第5,185,243号、第5,679,524号和第5,573,907号;EP 0 320 308B1;EP 0 336 731B1;EP 0 439 182B1;WO 90/01069;WO89/12696;和WO 89/09835,所有这些专利均以引用方式并入)。应当理解,这些扩增方法可被设计成用于扩增核酸。例如,在一些实施方案中,扩增方法可包括连接探针扩增或含有特异性针对感兴趣核酸的引物的寡核苷酸连接测定(OLA)反应。在一些实施方案中,扩增方法可包括引物延伸-连接反应,该引物延伸-连接反应含有特异性针对感兴趣核酸并能够穿过水凝胶孔的引物。作为可被特别设计用于扩增感兴趣核酸的引物延伸和连接引物的非限制性示例,扩增可包括用于GoldenGate测定(Illumina,Inc.,San Diego,Calif.)的引物,如美国专利第7,582,420号和第7,611,869号所示例,这两篇专利中的每一篇专利全文均以引用方式并入本文。
在一些实施方案中,使用如美国专利第7,985,565号和第7,115,400号的公开内容所示例的簇扩增方法扩增核酸,这两篇专利中的每一篇专利的内容均全文以引用方式并入本文。美国专利第7,985,565号和第7,115,400号的所并入材料描述了核酸扩增方法,该方法允许扩增产物固定在固体载体上以形成由固定化核酸分子的簇或“群体”构成的阵列。此类阵列上的每个簇或群体由多个相同的固定化多核苷酸链和多个相同的固定化互补多核苷酸链形成。如此形成的阵列在本文中通常被称为“簇阵列”。固相扩增反应的产物(例如美国专利第7,985,565号和第7,115,400号中描述的那些)是所谓的“桥联”结构,该结构通过成对的固定化多核苷酸链和固定化互补链的退火形成,两条链优选地通过共价附接而在5'末端处固定在固体载体上。簇扩增方法是其中使用固定化核酸模板产生固定化扩增子的方法的示例。也可使用其他合适的方法由根据本文提供的方法产生的固定化DNA片段产生固定化扩增子。例如,无论每对扩增引物中的一个或两个引物是否被固定,都可通过固相PCR形成一个或多个簇或群体。
另外的扩增方法包括等温扩增。可以使用的示例性等温扩增方法包括但不限于由例如Dean等人,Proc.Natl.Acad.Sci.USA 99:5261-66(2002)所示例的多重置换扩增(MDA),或由例如美国专利第6,214,587号所示例的等温链置换核酸扩增,这两篇文献中的每篇文献全文以引用方式并入本文。可用于本公开的其他非基于PCR的方法包括:例如链置换扩增(SDA),其描述于例如Walker等人,Molecular Methods for Virus Detection,Academic Press,Inc.,1995年,美国专利第5,455,166号和第5,130,238号,以及Walker等人,Nucl.Acids Res.第20卷:第1691-1696页(1992年);或超支化链置换扩增,其描述于例如Lage等人,Genome Research,第13卷,第294-307页(2003年)中,这些文献中的每篇文献均全文以引用方式并入本文。等温扩增方法可与链置换Phi 29聚合酶或Bst DNA聚合酶大片段5'->3'exo-一起用于基因组DNA的随机引物扩增。这些聚合酶的使用利用了它们的高持续合成能力和链置换活性。高持续合成能力允许聚合酶产生长度为10kb-20kb的片段。如上所述,可使用具有低持续合成能力和链置换活性的聚合酶(诸如Klenow聚合酶)在等温条件下产生较小的片段。对扩增反应、条件和组分的附加描述在美国专利第7,670,810号的公开内容中有详细阐述,该专利全文以引用方式并入本文。在一些实施方案中,使无规六聚体与变性的DNA退火,然后在恒定温度下,在催化酶Phi 29的存在下进行链置换合成。这导致DNA扩增,如通过MDA后荧光强度(用SYTOX染色的DNA)增加所证实的那样。独立地,也可执行裂解和纯化后基于
可用于本公开的另一种核酸扩增方法是带标签的PCR,其使用具有恒定5'区,接着是随机3'区的二结构域引物的群体,如例如Grothues等人,Nucleic Acids Res.第21卷第5期:第1321-1322页(1993年)中所述,该专利全文以引用方式并入本文。基于来自随机合成的3'区的单独杂交,进行第一轮扩增以允许大量启动热变性的DNA。由于3'区的性质,设想启动位点在整个基因组中是随机的。然后,可移除未结合的引物,并且可使用与恒定5'区互补的引物进行进一步的复制。
在一些实施方案中,对核酸进行全部或部分测序。可根据任何合适的测序方法对核酸进行测序,这些测序方法诸如直接测序,包括边合成边测序、边连接边测序、杂交测序、纳米孔测序等。
一种测序方法是通过边合成边测序(SBS)。在SBS中,监测核酸引物沿核酸模板(例如,靶核酸或其扩增子)的延伸,以确定模板中核苷酸的序列。基础化学过程可以是聚合(例如,由聚合酶催化)。在特定的基于聚合酶的SBS实施方案中,以依赖于模板的方式将荧光标记的核苷酸添加至引物(从而使引物延伸),使得对添加至引物的核苷酸的顺序和类型的检测可用于确定模板的序列。
可对一个或多个扩增的核酸进行SBS或涉及在循环中重复递送试剂的其他检测技术。例如,为了启动第一SBS循环,可使一个或多个标记的核苷酸、DNA聚合酶等流入/流过容纳有一个或多个扩增核酸分子的小滴。可检测其中引物延伸导致标记的核苷酸掺入的那些位点。任选地,核苷酸可进一步包括可逆终止属性,一旦将核苷酸添加至引物,该可逆终止属性终止进一步的引物延伸。例如,可将具有可逆终止子部分的核苷酸类似物添加至引物,使得随后的延伸直到递送解封闭剂以除去该部分才发生。因此,对于使用可逆终止的实施方案,可(在检测发生之前或之后)将解封闭试剂递送到流通池。洗涤可在各个递送步骤之间进行。然后可将循环重复n次以使引物延伸n个核苷酸,从而检测长度为n的序列。可容易地适于与通过本公开的方法产生的扩增子一起使用的示例性SBS程序、流体系统和检测平台描述于例如以下文献中:Bentley等人,Nature,第456卷:第53-59页(2008年);WO 04/018497;美国专利第7,057,026号;WO 91/06678;WO 07/123744;美国专利7,329,492;美国专利第7,211,414号;美国专利第7,315,019号;美国专利第7,405,281号和US 2008/0108082,这些文献中的每一篇文献均以引用方式并入本文。
可使用利用循环反应的其他测序程序,诸如焦磷酸测序。焦磷酸测序检测当特定的核苷酸掺入新生核酸链中时无机焦磷酸盐(PPi)的释放(Ronaghi等人,AnalyticalBiochemistry,第242卷第1期,第84-89页(1996年);Ronaghi,Genome Res.第11卷第1期,第3-11页(2001年);Ronaghi等人,Science,第281卷第5375期,第363页(1998年);美国专利第6,210,891号;美国专利第6,258,568号和美国专利第6,274,320号,这些文献中的每一篇文献均以引用方式并入本文)。在焦磷酸测序中,所释放的PPi可通过ATP硫酸化酶立即转化成三磷酸腺苷(ATP)来检测,并且所产生ATP的水平可经由荧光素酶产生的光子来检测。因此,可经由发光检测系统来监测测序反应。用于基于荧光的检测系统的激发辐射源不是焦磷酸测序程序所必需的。可适于对根据本公开产生的扩增子应用焦磷酸测序的可用流体系统、检测器和程序在例如WIPO专利申请序列号PCT/US11/57111、US 2005/0191698 A1、美国专利第7,595,883号和美国专利第7,244,559号中有所描述,这些专利中的每一篇专利均以引用方式并入本文。
一些实施方案可利用涉及DNA聚合酶活性的实时监测的方法。例如,核苷酸掺入可通过带有荧光团的聚合酶与γ-磷酸标记的核苷酸之间的荧光共振能量转移(FRET)相互作用来检测,或者用零模式波导(ZMW)来检测。用于基于FRET的测序的技术和试剂在例如Levene等人,Science,第299卷,第682-686页(2003年);Lundquist等人,Opt.Lett.第33卷,第1026-1028页(2008年);Korlach等人,过程Natl.Acad.Sci.USA,第105卷,第1176-1181页(2008年)中有所描述,这些文献的公开内容以引用方式并入本文。
一些SBS实施方案包括检测在将核苷酸掺入延伸产物时释放的质子。例如,基于对释放的质子的检测的测序可使用电检测器和可商购获得的相关技术。此类测序系统的示例是焦磷酸测序(例如,可从Roche的454Life Sciences子公司商购获得的平台),使用γ-磷酸标记的核苷酸测序(例如,可从Pacific Biosciences商购获得的平台),并且使用质子检测测序(例如,可从Life Technologies的Ion Torrent子公司商购获得的平台)或US2009/0026082A1;US 2009/0127589 A1;US 2010/0137143 A1;或US2010/0282617A1中所述的测序方法和系统,这些专利中的每一篇专利均以引用方式并入本文。本文所述的使用动力学排除来扩增靶核酸的方法可容易地应用于用于检测质子的底物。更具体地讲,本文所述的方法可用于产生用于检测质子的扩增子的克隆群体。
另一种测序技术是纳米孔测序(参见例如Deamer等人,Trends Biotechnol.第18卷,第147-151页(2000年);Deamer等人,Acc.Chem.Res.第35卷,第817-825页(2002年);Li等人,Nat.Mater.第2卷,第611-615页(2003年),这些文献的公开内容以引用方式并入本文)。在一些纳米孔的实施方案中,靶核酸或从靶核酸移除的单独核苷酸穿过纳米孔。当核酸或核苷酸穿过纳米孔时,可通过测量孔的电导率的波动来识别每种核苷酸类型。(美国专利第7,001,792号;Soni等人,Clin.Chem.第53卷,第1996-2001页(2007年);Healy,Nanomed.第2卷,第459-481页(2007年);Cockroft等人,J.Am.Chem.Soc.第130卷,第818-820页(2008年),这些文献的公开内容以引用方式并入本文)。
可应用于根据本公开的检测的基于阵列的表达和基因分型分析的示例性方法描述于美国专利第7,582,420号;第6,890,741号;第6,913,884号或第6,355,431号或美国专利公布第2005/0053980A1号;第2009/0186349A1号或US 2005/0181440 A1中,这些专利中的每一篇专利均以引用方式并入本文。
如本文所述的分离核酸、扩增和测序的方法中,多种试剂可用于核酸分离和制备。此类试剂可包括例如溶菌酶、蛋白酶K、随机六聚体、聚合酶(例如Φ29DNA聚合酶、Taq聚合酶、Bsu聚合酶)、转座酶(例如Tn5)、引物(例如P5和P7衔接子序列)、连接酶、催化酶、三磷酸脱氧核苷酸、缓冲液或二价阳离子。
衔接子可包括测序引物位点、扩增引物位点和索引。如本文所用,“索引”可包括用作分子标识符和/或条形码的核苷酸的序列以将核酸加标签和/或识别核酸的来源。在一些实施方案中,索引可用于识别单个核酸或核酸亚群。在一些实施方案中,单个细胞可用于组合索引,例如,使用保留邻近性转座(CPT-seq)方法。
索引可用于识别核酸分子的来源。在一些实施方案中,衔接子可例如通过添加阻止衔接子在一端或两端延伸的封闭基团而防止多联体形成。3'封闭基团的示例包括3'-间隔部分C3、双脱氧核苷酸和与底物的附接部分。5'封闭基团的示例包括去磷酸化的5'核苷酸,以及与底物的附接基。
示例性方法包括使靶核酸的5'端去磷酸化以防止在后续连接步骤中形成多联体;使用连接酶将第一衔接子连接至去磷酸化靶标的3'端,其中第一衔接子的3'端被封闭;将所连接的靶标的5'端再磷酸化;使用单链连接酶将第二衔接子连接到去磷酸化靶标的5'端,其中第二衔接子的5'端是非磷酸化的。
另一个示例包括用5'核酸外切酶部分消化核酸以形成具有单链3'悬垂的双链核酸。含有3'封闭基团的衔接子可连接至具有3'悬垂的双链核酸的3'端。可使具有3'悬垂和所连接的衔接子的双链核酸去杂交以形成单链核酸。含有非磷酸化5'端的衔接子可连接至单链核酸的5'端。
使核酸(诸如核酸的5'核苷酸)去磷酸化的方法包括使核酸与磷酸酶接触。磷酸酶的示例包括小牛肠磷酸酶、虾碱性磷酸酶、Antarctic磷酸酶和APEX碱性磷酸酶(Epicentre)。
连接核酸的方法包括使核酸与连接酶接触。连接酶的示例包括T4 RNA连接酶1、T4RNA连接酶2、RtcB连接酶、甲烷杆菌属RNA连接酶和TS2126 RNA连接酶(CIRCLIGASE)。
使核酸(诸如核酸的5'核苷酸)磷酸化的方法包括使核酸与激酶接触。激酶的示例包括T4多核苷酸激酶。
本文提供的体系和方法的实施方案包括试剂盒,该试剂盒含有转座试剂和与第一标签互补的第一探针以及与第二标签互补的第二探针,其中第一探针和第二探针固定在固体载体上。在一些实施方案中,第一探针和第二探针包括条形码。在一些实施方案中,第一探针和第二探针为polyT探针。在一些实施方案中,固体载体是蚀刻的表面、孔、阵列、流通池装置、微流体通道、小珠、磁性小珠、柱、小滴或微粒。
以下实施例展示了同时分析批量细胞的样本中的DNA和RNA的实施方案。
获得细胞并将其裂解以分离细胞核,如图6A所示。使用具有polyA转座子的转座体将全基因组DNA(gDNA)片段标签化。转座体进入细胞核并将开放染色质片段标签化(gDNA未被组蛋白结合)。
片段标签化后,gDNA和RNA均包含3'polyA尾。使用polyT捕获探针捕获gDNA和RNA两者,该捕获探针与gDNA和RNA的3'polyA尾杂交。捕获探针包含用于样本、细胞的下游扩增和分子索引或用于分子解复用的第一共同序列(CS1)。为了将RNA转化为DNA,捕获探针用作用于通过逆转录酶合成cDNA的引物。
使用柱纯化(ZYMO)从细胞核中纯化gDNA和所产生的cDNA,如图6B所示。染色质可及性测序(ATAC)文库制备利用延伸/连接反应完成,并且RNA文库制备利用cDNA的第二链合成完成。第二轮片段标签化用于掺入第二共同序列(CS2)和分子索引。执行样本纯化以移除Tn5,并使用与CS1和CS2互补的引物通过PCR产生最终测序文库。
也使用类似的方法同时分析小珠上的DNA和RNA。如图7A和图7B所示,可执行分析以改善样本处理和/或启用全长RNA文库。如图7A和图7B的示意图所示,获得细胞并将其裂解以分离细胞核。用包含polyA转座子和共同序列(CS2)的两个转座体将gDNA片段标签化。转座体进入细胞核并将开放染色质片段标签化(gDNA未被组蛋白结合)。将具有polyT尾并包含共同序列(CS1)的捕获探针与DNA文库和RNA文库两者的polyA尾杂交。为了完成RNA文库制备,杂交探针用于引发cDNA合成。使用逆转录酶的模板切换活性和允许制造全长RNA的模板切换寡核苷酸(TSO),将第二共同序列(CS2)添加至RNA文库。为了改善样本处理,使用生物素酰化捕获探针将RNA和DNA文库结合至磁性链霉亲和素小珠。在小珠结合分子上容易执行洗涤、缓冲液交换和处理。
图8描绘了ATAC和RNA文库制备的结果。ATAC文库的片段具有在图8中带边框的特征ME序列、转座子特异性序列。如图9所示,ATAC片段显示围绕启动子区域的典型富集(分图A),用于3'计数的RNA片段显示围绕基因末端的读段累积(分图B)。表1和表2汇总了用于同时进行DNA和RNA分析的ATAC-seq和RNA指标的结果。
以下实施例展示了在隔室中执行单细胞ATAC-seq的实施方案。
转座到染色质中如图5B所概述执行。转座后,将单个细胞或单个细胞核分配到隔室中,在这种情况下,分配成小滴。转座酶将所有单独的DNA/文库片段保持在一起,从而使得来自单个细胞的所有材料能够被包封在单个小滴内。来自单个小滴中的细胞的所有片段使用有条形码的引物通过PCR进行索引。
为了确保将单个细胞适当地分配成单个小滴,使混合的人类细胞和小鼠细胞经受该过程。样本包括500,000个人类细胞和500,000个小鼠细胞。每次测定包括34,000个细胞核,这些细胞核被合并以产生一个包含约300,000个小滴的小滴PCR芯片。该测定包括140,000个小珠(每条通道11μL的3200个小珠)。执行四次小滴PCR循环,然后执行十次批量循环。测序工作流程的示例概述于图12中,该图提供了其中插入有条形码的序列。据观察,增加Tn5转座酶提高了产率、敏感性和转录起始位点(TSS)的百分比,如图13所示。
读取将序列读段识别为来自小鼠或来自人类的条形码,并且如图14所概述,结果指示读段与小鼠或与人类对准,从而指示单个细胞被包封在单个小滴内,从而实现单个细胞的分配,这使得能够进行单个细胞的分析。可以预知,ATAC读段输出分布在转录起始位点周围。
如本文所用,术语“包含”与“包括”、“含有”或“特征在于”同义,并且是包括性的或开放式的,并且不排除另外的未列举的要素或方法步骤。
以上描述公开了本发明的几种方法和材料。本发明易于在方法和材料上进行修改,以及在制造方法和装置上进行改变。考虑到本公开或本文公开的本发明的实践,这种修改对于本领域技术人员来说将变得显而易见。因此,并非意图将本发明限制于本文所公开的具体实施方案,而是其涵盖了落入本发明的真实范围和精神内的所有修改形式和替代形式。
本文引用的所有参考文献,包括但不限于公开和未公开的申请、专利和参考文献,均全文以引用方式并入本文,并且据此成为本说明书的一部分。就以引用方式并入的出版物和专利或专利申请与说明书中包含的公开内容相矛盾的程度而言,本说明书旨在取代和/或优先于任何此类矛盾的材料。
序列表
<110> ILLUMINA公司
<120> 使用单一测定分析多种分析物
<130> ILLINC.444WO
<150> 62/773,862
<151> 2018-11-30
<160> 8
<170> PatentIn 3.5版
<210> 1
<211> 33
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成寡核苷酸
<400> 1
tcgtcggcag cgtcagatgt gtataagaga cag 33
<210> 2
<211> 34
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成寡核苷酸
<400> 2
gtctcgtggg ctcggagatg tgtataagag acag 34
<210> 3
<211> 19
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221>
<222>
<223> 合成寡核苷酸
<400> 3
ctgtctctta tacacatct 19
<210> 4
<211> 14
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221>
<222>
<223> 合成寡核苷酸
<400> 4
tcgtcggcag cgtc 14
<210> 5
<211> 15
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221>
<222>
<223> 合成寡核苷酸
<400> 5
gtctcgtggg ctcgg 15
<210> 6
<211> 19
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221>
<222>
<223> 合成寡核苷酸
<400> 6
agatgtgtat aagagacag 19
<210> 7
<211> 29
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221>
<222>
<223> 合成寡核苷酸
<400> 7
aatgatacgg cgaccaccga gauctacac 29
<210> 8
<211> 24
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<221>
<222>
<223> 合成寡核苷酸
<400> 8
caagcagaag acggcatacg agat 24
- 使用单一测定分析多种分析物
- 使用与多孔膜偶联的分析物传感分子测定分析物浓度的方法