一种基于聚类和中值收敛的音频切割方法和系统
文献发布时间:2023-06-19 11:06:50
技术领域
本发明涉及音视频处理技术领域,特别涉及一种基于聚类和中值收敛的音频切割方法和系统。
背景技术
在健康监测和风机故障检测领域中,常需用到音频切割。在申请号201911121998.X,专利名《基于信号能量尖峰识别的音频分割方法》中,本申请涉及一种基于信号能量尖峰识别的音频分割方法,包括:将输入的音频信号进行短时傅里叶变换,转换为功率谱矩阵;提取基于功率谱的中频能量特征;对提取的中频能量特征进行尖峰识别;对进行尖峰识别后的信号进行错分修正;输出音频信号的分割点时间坐标。本申请的音频分割方法需从其他系统实时得到的风机叶片转动的额定转速rs为输入条件,与其他系统具有较强耦合性。
发明内容
为此,需要提供一种基于聚类和中值收敛的音频切割方法,用以解决现有音频切割音频输入需依赖其它系统才能得到较好的音频切割效果、耦合性强的技术问题。具体技术方案如下:
一种基于聚类和中值收敛的音频切割方法,包括步骤:
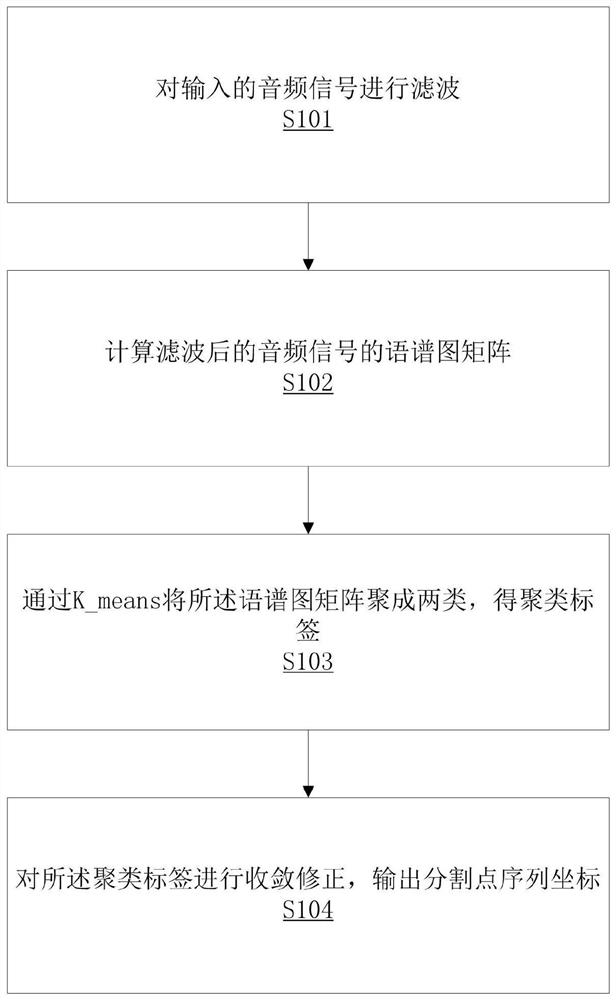
对输入的音频信号进行滤波;
计算滤波后的音频信号的语谱图矩阵;
通过K_means将所述语谱图矩阵聚成两类,得聚类标签;
对所述聚类标签进行收敛修正,输出分割点序列坐标。
进一步的,所述“计算滤波后的音频信号的语谱图矩阵”,具体还包括步骤:
对滤波后的音频信号进行预加重、分帧和加窗处理得第一结果;
对所述第一结果进行快速傅里叶变换得第二结果;
对所述第二结果进行取绝对值或平方值运算得第三结果;
对所述第三结果进行三角带通滤波处理得第四结果;
对所述第四结果进行取对数能量处理得第五结果;
对所述第五结果进行动态特征计算得语谱图矩阵。
进一步的,所述“通过K_means将所述语谱图矩阵聚成两类,得聚类标签”,具体还包括步骤:
对所述语谱图矩阵中的中高维度进行截取,输入降维后的语谱图矩阵至 K_means得标签序列;
对所述标签序列的毛刺和尖峰进行滤除。
进一步的,所述“对所述聚类标签进行收敛修正,输出分割点序列坐标”,具体还包括步骤:
聚类标签的序列坐标标识为V=[v1,v2,…,vn];
步骤1、计算V的一阶差分向量;
步骤2、对所述差分向量进行求中值运算;
步骤3、对所述一阶差分向量从首部进行遍历,判断一阶差分向量是否在预设区间范围内,若在预设区间范围内,则输出分割点序列坐标;
若不在预设区间范围内,则执行预设操作。
进一步的,所述“若不在预设区间范围内,则执行预设操作”,具体还包括步骤:
若不在预设区间范围内,判断所述一阶差分向量是否大于第一预设阈值,若大于第一预设阈值,则在序列坐标中插入新值;
判断所述一阶差分向量是否小于第二预设阈值,若小于第二预设阈值,则删除当前一阶差分向量。
为解决上述技术问题,还提供了一种基于聚类和中值收敛的音频切割系统,具体技术方案如下:
一种基于聚类和中值收敛的音频切割系统,包括:滤波模块、语谱图矩阵生成模块、聚类标签生成模块和序列坐标生成模块;
所述滤波模块用于:对输入的音频信号进行滤波;
所述语谱图矩阵生成模块用于:计算滤波后的音频信号的语谱图矩阵;
所述聚类标签生成模块用于:通过K_means将所述语谱图矩阵聚成两类,得聚类标签;
所述序列坐标生成模块用于:对所述聚类标签进行收敛修正,输出分割点序列坐标。
进一步的,所述语谱图矩阵生成模块还用于:
对滤波后的音频信号进行预加重、分帧和加窗处理得第一结果;
对所述第一结果进行快速傅里叶变换得第二结果;
对所述第二结果进行取绝对值或平方值运算得第三结果;
对所述第三结果进行三角带通滤波处理得第四结果;
对所述第四结果进行取对数能量处理得第五结果;
对所述第五结果进行动态特征计算得语谱图矩阵。
进一步的,所述聚类标签生成模块还用于:
对所述语谱图矩阵中的中高维度进行截取,输入降维后的语谱图矩阵至 K_means得标签序列;
对所述标签序列的毛刺和尖峰进行滤除。
进一步的,所述序列坐标生成模块还用于:
聚类标签的序列坐标标识为V=[v1,v2,…,vn];
步骤1、计算V的一阶差分向量;
步骤2、对所述差分向量进行求中值运算;
步骤3、对所述一阶差分向量从首部进行遍历,判断一阶差分向量是否在预设区间范围内,若在预设区间范围内,则输出分割点序列坐标;
若不在预设区间范围内,则执行预设操作。
进一步的,所述序列坐标生成模块还用于:
若不在预设区间范围内,判断所述一阶差分向量是否大于第一预设阈值,若大于第一预设阈值,则在序列坐标中插入新值;
判断所述一阶差分向量是否小于第二预设阈值,若小于第二预设阈值,则删除当前一阶差分向量。
本发明的有益效果是:通过对输入的音频信号进行滤波;计算滤波后的音频信号的语谱图矩阵;通过K_means将所述语谱图矩阵聚成两类,得聚类标签;对所述聚类标签进行收敛修正,输出分割点序列坐标。整个过程中,不依赖外部系统数据,方法独立,且计算量小,切割点位正确,精确度高,扛干扰能力强,易于工程化,并且能根据音频周期变化,实现动态切割。
附图说明
图1为具体实施方式所述一种基于聚类和中值收敛的音频切割方法的流程图;
图2为具体实施方式所述计算滤波后的音频信号的语谱图矩阵的流程图;
图3为具体实施方式所述一种基于聚类和中值收敛的音频切割系统的模块示意图;
图4为具体实施方式所述时频图示意图;
图5为具体实施方式所述音频语谱图示意图;
图6为具体实施方式所述1标签序列放大后的示意图;
图7为具体实施方式所述聚类标签进行收敛修正前切割线示意图;
图8为具体实施方式所述聚类标签进行收敛修正后切割线示意图;。
附图标记说明:
300、一种基于聚类和中值收敛的音频切割系统,
301、滤波模块,
302、语谱图矩阵生成模块,
303、聚类标签生成模块,
304、序列坐标生成模块。
具体实施方式
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
请参阅图1至图2,在本实施方式中,一种基于聚类和中值收敛的音频切割方法可应用在一种基于聚类和中值收敛的音频切割系统上,所述一种基于聚类和中值收敛的音频切割系统,包括:滤波模块、语谱图矩阵生成模块、聚类标签生成模块和序列坐标生成模块。
请参阅图1,其具体实施方式如下:
步骤S101:对输入的音频信号进行滤波。具体可如下:声音采集器工作在复杂的室外,采集到的音频信号一般包含大量的噪声,如鸟叫,风声,人声,其他风机造成的噪声等。在目前,风机的启动条件一般为平均风速不小于3.5m/s,声音传感器采集到的信号必然包含风噪,因此,相比其他背景噪声,风噪影响较大。由时频图图4看出,风噪的频谱能量集中在350Hz以下的低频区域(图中明亮区域)。需要滤波器将低频的风噪滤除。在本实施方式中采用低频滤波器进行预处理。
步骤S102:计算滤波后的音频信号的语谱图矩阵。声音信号的提取是本申请的核心部分之一,提取到有效,可靠的特征能提高结果的准确性和有效性,降低处理的复杂度。经过研究发现语谱图能很好的表征风机叶片的音频特征。如图5所示为音频语谱图。
语谱图也称时频谱(英语:Spectrogram)也称谱瀑布(spectral waterfall)、声指纹(voiceprint)、声图(voicegram)或声谱图,是一种描述波动的各频率成分如何随时间变化的热图。利用傅里叶变换得到的传统的2维频谱可展示复杂的波动是如何按比例分解为简单波的叠加(分解为频谱),但是无法同时体现它们随时间的变化。能对波动的时间变量与频率分布同时进行分析的常用数学方法是短时距傅里叶变换,但是直接绘成3维图像的话又不便于在纸面上观察和分析。时频谱在借助时频分析方法的基础上,以热图的形式将第3维的数值用颜色的深浅加以呈现。
如图2所示,所述“计算滤波后的音频信号的语谱图矩阵”,具体还包括步骤:
步骤S201、对滤波后的音频信号进行预加重、分帧和加窗处理得第一结果;
步骤S202、对所述第一结果进行快速傅里叶变换得第二结果;
步骤S203、对所述第二结果进行取绝对值或平方值运算得第三结果;
步骤S204、对所述第三结果进行三角带通滤波处理得第四结果;
步骤S205、对所述第四结果进行取对数能量处理得第五结果;
步骤S206、对所述第五结果进行动态特征计算得语谱图矩阵。具体可如下:
首先,音频输入经过高通滤波器预加重处理:
μ取值0.79。
分帧根据帧长和帧步长把语音信号分成一些短帧来处理。
H(z)=1-uz
加窗将每一帧乘以汉明窗,以增加帧左端和右端的连续性。
快速傅里叶变换:对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。
取绝对值或者平方值:对语音信号的频谱取模平方得到功率谱。
三角带通滤波:将能量谱通过一组Mel尺度的三角滤波器组,定义一个有M个滤波器的滤波器组。经此,对频谱进行了平滑化,并且消除了谐波的作用,突出了共振峰,并且降低了运算量。
取对数能量:计算每个滤波器组的对数能量。
动态特征:计算静态特征的差分谱。
步骤S103:通过K_means将所述语谱图矩阵聚成两类,得聚类标签。具体还包括步骤:
对所述语谱图矩阵中的中高维度进行截取,输入降维后的语谱图矩阵至 K_means得标签序列;在本实施方式中,设定五分之一以上维度为中高维度;
对所述标签序列的毛刺和尖峰进行滤除。具体可如下:
k-means算法中的k代表类簇个数,means代表类簇内数据对象的均值(这种均值是一种对类簇中心的描述),因此,k-means算法又称为k-均值算法。 k-means算法是一种基于划分的聚类算法,以距离作为数据对象间相似性度量的标准,即数据对象间的距离越小,则它们的相似性越高,则它们越有可能在同一个类簇。数据对象间距离的计算有很多种,k-means算法通常采用欧氏距离来计算数据对象间的距离。
先对语谱图的中高维度进行截取。将降维后的矩阵输入K_means两类聚类算法。
得到聚类的0,1标签序列。为了可视化方便,图6为1标签序列进行了放大作用,可见K_means聚类后的效果不错,得到扫风声和安静声的标签序列,能大体划分扫风后周期。
对所述标签序列的毛刺和尖峰进行滤除。
步骤S104:对所述聚类标签进行收敛修正,输出分割点序列坐标。具体还包括步骤:
聚类标签的序列坐标标识为V=[v1,v2,…,vn];
步骤1、计算V的一阶差分向量;
步骤2、对所述差分向量进行求中值运算;
步骤3、对所述一阶差分向量从首部进行遍历,判断一阶差分向量是否在预设区间范围内,若在预设区间范围内,则输出分割点序列坐标;
若不在预设区间范围内,则执行预设操作。
所述“若不在预设区间范围内,则执行预设操作”,具体还包括步骤:
若不在预设区间范围内,判断所述一阶差分向量是否大于第一预设阈值,若大于第一预设阈值,则在序列坐标中插入新值;
判断所述一阶差分向量是否小于第二预设阈值,若小于第二预设阈值,则删除当前一阶差分向量。具体可如下:
根据连续标签0跳跃到连续标签1为坐标点,该序列为坐标的:
V=[v1,v2,…,vn]
其中vi,i∈[1,2,…,N],代表频谱图中在时间轴上第i个波峰。标签是 K_means算法得到,K_means算法对偏离值敏感,需要在此基础上对此修正。
下面给出收敛修正算法:
1、序列坐标表示为V=[v1,v2,…,vn]。
2、计算V的一阶差分向量Diffv:
Diffv(i)=V(i+1)-V(i),其中i∈1,2,…,N-1。
3、对差分向量进行求中值运算Median(Diffv(i))。
4、对一阶差分向量Diffv从首部进行遍历,如果Diffv(i)>1.3Median (Diffv(i))向量Vi插入新值Vi+Median(Diffv(i))。如果Diffv(i)<0.7 Median(Diffv(i)),删除向量Vi。
5、对新序列进行第一步,直到第四步中0.7Median(Diffv(i)) 在中值收敛迭代中,初始中值有偏差没关系,后续迭代收敛中会逼近真正统计意义上的中值。 现在对坐标序列中值收敛进行举例: 1、V=[0,27,59,89,118,149,178,209,239,269,331,361,391, 421,451,482,511,541,568,602,631,661]。 2、计算V的一阶差分,得到 Diffv(i)=[27.0,32.0,30.0,29.0,31.0,29.0,31.0,30.0,30.0, 62.0,30.0,30.0,30.0,30.0,31.0,29.0,30.0,27.0,34.0,29.0,30.0] 3、对差分向量进行求中值运算Median(Diffv(i))=30 4、对一阶差分向量Diffv从首部进行遍历,如果Diffv(i)>1.3Median (Diffv(i))向量Vi插入新值Vi+Median(Diffv(i))。如果Diffv(i)<0.7 Median(Diffv(i)),删除向量Vi。 其中i为10时候,Diffv(10)>1.3*30。在V10位置插入数值299,后续数值后移。 V=[0,27,59,89,118,149,178,209,239,269,299,331,361, 391,421,451,482,511,541,568,602,631,661] 对应图7到图8切割竖线的变化。 5、对新序列进行第一步,直到第四步中0.7Median(Diffv(i)) 该向量V示例跳出迭代循环。 通过对输入的音频信号进行滤波;计算滤波后的音频信号的语谱图矩阵;通过K_means将所述语谱图矩阵聚成两类,得聚类标签;对所述聚类标签进行收敛修正,输出分割点序列坐标。整个过程中,不依赖外部系统数据,方法独立,且计算量小,切割点位正确,精确度高,扛干扰能力强,易于工程化,并且能根据音频周期变化,实现动态切割。 请参阅图3至图8,在本实施方式中,一种基于聚类和中值收敛的音频切割系统300的具体实施方式如下: 一种基于聚类和中值收敛的音频切割系统300,包括:滤波模块301、语谱图矩阵生成模块302、聚类标签生成模块303和序列坐标生成模块304; 所述滤波模块301用于:对输入的音频信号进行滤波。具体可如下:声音采集器工作在复杂的室外,采集到的音频信号一般包含大量的噪声,如鸟叫,风声,人声,其他风机造成的噪声等。在目前,风机的启动条件一般为平均风速不小于3.5m/s,声音传感器采集到的信号必然包含风噪,因此,相比其他背景噪声,风噪影响较大。由时频图图4看出,风噪的频谱能量集中在 350Hz以下的低频区域(图中明亮区域)。需要滤波器将低频的风噪滤除。在本实施方式中采用低频滤波器进行预处理。 所述语谱图矩阵生成模块302用于:计算滤波后的音频信号的语谱图矩阵。声音信号的提取是本申请的核心部分之一,提取到有效,可靠的特征能提高结果的准确性和有效性,降低处理的复杂度。经过研究发现语谱图能很好的表征风机叶片的音频特征。如图5所示为音频语谱图。 语谱图也称时频谱(英语:Spectrogram)也称谱瀑布(spectral waterfall)、声指纹(voiceprint)、声图(voicegram)或声谱图,是一种描述波动的各频率成分如何随时间变化的热图。利用傅里叶变换得到的传统的2维频谱可展示复杂的波动是如何按比例分解为简单波的叠加(分解为频谱),但是无法同时体现它们随时间的变化。能对波动的时间变量与频率分布同时进行分析的常用数学方法是短时距傅里叶变换,但是直接绘成3维图像的话又不便于在纸面上观察和分析。时频谱在借助时频分析方法的基础上,以热图的形式将第3维的数值用颜色的深浅加以呈现。 进一步的,所述语谱图矩阵生成模块302还用于: 对滤波后的音频信号进行预加重、分帧和加窗处理得第一结果; 对所述第一结果进行快速傅里叶变换得第二结果; 对所述第二结果进行取绝对值或平方值运算得第三结果; 对所述第三结果进行三角带通滤波处理得第四结果; 对所述第四结果进行取对数能量处理得第五结果; 对所述第五结果进行动态特征计算得语谱图矩阵。具体可如下: 首先,音频输入经过高通滤波器预加重处理: μ取值0.79。 分帧根据帧长和帧步长把语音信号分成一些短帧来处理。 H(z)=1-uz 加窗将每一帧乘以汉明窗,以增加帧左端和右端的连续性。 快速傅里叶变换:对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。 取绝对值或者平方值:对语音信号的频谱取模平方得到功率谱。 三角带通滤波:将能量谱通过一组Mel尺度的三角滤波器组,定义一个有M个滤波器的滤波器组。经此,对频谱进行了平滑化,并且消除了谐波的作用,突出了共振峰,并且降低了运算量。 取对数能量:计算每个滤波器组的对数能量。 动态特征:计算静态特征的差分谱。 所述聚类标签生成模块303用于:通过K_means将所述语谱图矩阵聚成两类,得聚类标签具体还包括步骤: 对所述语谱图矩阵中的中高维度进行截取,输入降维后的语谱图矩阵至 K_means得标签序列;在本实施方式中,设定五分之一以上维度为中高维度; 对所述标签序列的毛刺和尖峰进行滤除。具体可如下: k-means算法中的k代表类簇个数,means代表类簇内数据对象的均值(这种均值是一种对类簇中心的描述),因此,k-means算法又称为k-均值算法。 k-means算法是一种基于划分的聚类算法,以距离作为数据对象间相似性度量的标准,即数据对象间的距离越小,则它们的相似性越高,则它们越有可能在同一个类簇。数据对象间距离的计算有很多种,k-means算法通常采用欧氏距离来计算数据对象间的距离。 先对语谱图的中高维度进行截取。将降维后的矩阵输入K_means两类聚类算法。 得到聚类的0,1标签序列。为了可视化方便,图6为1标签序列进行了放大作用,可见K_means聚类后的效果不错,得到扫风声和安静声的标签序列,能大体划分扫风后周期。 进一步的,所述聚类标签生成模块303还用于: 对所述语谱图矩阵中的中高维度进行截取,输入降维后的语谱图矩阵至 K_means得标签序列;在本实施方式中,设定五分之一以上维度为中高维度; 对所述标签序列的毛刺和尖峰进行滤除。 所述序列坐标生成模块304用于:对所述聚类标签进行收敛修正,输出分割点序列坐标。具体还包括步骤: 聚类标签的序列坐标标识为V=[v1,v2,…,vn]; 步骤1、计算V的一阶差分向量; 步骤2、对所述差分向量进行求中值运算; 步骤3、对所述一阶差分向量从首部进行遍历,判断一阶差分向量是否在预设区间范围内,若在预设区间范围内,则输出分割点序列坐标; 若不在预设区间范围内,则执行预设操作。 进一步的,所述序列坐标生成模块304还用于: 若不在预设区间范围内,判断所述一阶差分向量是否大于第一预设阈值,若大于第一预设阈值,则在序列坐标中插入新值; 判断所述一阶差分向量是否小于第二预设阈值,若小于第二预设阈值,则删除当前一阶差分向量。 具体可如下: 根据连续标签0跳跃到连续标签1为坐标点,该序列为坐标的: V=[v1,v2,…,vn] 其中vi,i∈[1,2,…,N],代表频谱图中在时间轴上第i个波峰。标签是 K_means算法得到,K_means算法对偏离值敏感,需要在此基础上对此修正。 下面给出收敛修正算法: 1、序列坐标表示为V=[v1,v2,…,vn]。 2、计算V的一阶差分向量Diffv: Diffv(i)=V(i+1)-V(i),其中i∈1,2,…,N-1。 3、对差分向量进行求中值运算Median(Diffv(i))。 4、对一阶差分向量Diffv从首部进行遍历,如果Diffv(i)>1.3Median (Diffv(i))向量Vi插入新值Vi+Median(Diffv(i))。如果Diffv(i)<0.7 Median(Diffv(i)),删除向量Vi。 5、对新序列进行第一步,直到第四步中0.7Median(Diffv(i)) 在中值收敛迭代中,初始中值有偏差没关系,后续迭代收敛中会逼近真正统计意义上的中值。 现在对坐标序列中值收敛进行举例: 1、V=[0,27,59,89,118,149,178,209,239,269,331,361,391, 421,451,482,511,541,568,602,631,661]。 2、计算V的一阶差分,得到 Diffv(i)=[27.0,32.0,30.0,29.0,31.0,29.0,31.0,30.0,30.0, 62.0,30.0,30.0,30.0,30.0,31.0,29.0,30.0,27.0,34.0,29.0,30.0] 3、对差分向量进行求中值运算Median(Diffv(i))=30 4、对一阶差分向量Diffv从首部进行遍历,如果Diffv(i)>1.3Median (Diffv(i))向量Vi插入新值Vi+Median(Diffv(i))。如果Diffv(i)<0.7 Median(Diffv(i)),删除向量Vi。 其中i为10时候,Diffv(10)>1.3*30。在V10位置插入数值299,后续数值后移。 V=[0,27,59,89,118,149,178,209,239,269,299,331,361, 391,421,451,482,511,541,568,602,631,661] 对应图7到图8切割竖线的变化。 5、对新序列进行第一步,直到第四步中0.7Median(Diffv(i)) 该向量V示例跳出迭代循环。 通过滤波模块301对输入的音频信号进行滤波;语谱图矩阵生成模块302 计算滤波后的音频信号的语谱图矩阵;聚类标签生成模块303通过K_means 将所述语谱图矩阵聚成两类,得聚类标签;序列坐标生成模块304对所述聚类标签进行收敛修正,输出分割点序列坐标。整个系统,不依赖外部系统数据,方法独立,且计算量小,切割点位正确,精确度高,扛干扰能力强,易于工程化,并且能根据音频周期变化,实现动态切割。 需要说明的是,尽管在本文中已经对上述各实施例进行了描述,但并非因此限制本发明的专利保护范围。因此,基于本发明的创新理念,对本文所述实施例进行的变更和修改,或利用本发明说明书及附图内容所作的等效结构或等效流程变换,直接或间接地将以上技术方案运用在其他相关的技术领域,均包括在本发明的专利保护范围之内。
- 一种基于聚类和中值收敛的音频切割方法和系统
- 一种基于分布-收敛模型的文献聚类方法