消费者文本的信息提取结构,标注方法和识别方法
文献发布时间:2023-06-19 11:14:36
技术领域
本发明涉及自然语言处理技术领域,具体涉及一种消费者文本的信息提取结构,标注方法和识别方法。
背景技术
在消费者文本表达的自然语言处理技术领域,常用的信息提取技术包括命名实体识别、方面抽取、文本情感分析。具体的,命名实体识别包括输入一段文本,输出其中提到的命名实体,命名实体通常指人名、地名,品牌名等。方面抽取包括输入一段文本,输出其中提到的方面,方面通常指产品的各方面属性,例如价格、功效、外观等。文本情感分析,包括文档级情感分析,实体级情感分析,方面级情感分析,和实体-方面级情感分析。
上述分析方法互相孤立,没有一种方法能自动提取元素、方面,并自动把实体和方面对应做情感分析。互相孤立的问题是,如果采用生硬地把方法串联,会产生误差传递,即前置任务(如命名实体识别和方面抽取)的错误预测会导致后置任务(情感分析)的结果产生较大偏差。
而且,情感分析技术中,文档级、实体级、方面级情感分析忽视了文档中对不同实体的不同方面可能会表达不同的情感态度,片面地反映了表达者的态度。实体-方面级情感分析虽然较正确反映,但其实体和方面需要依赖其他模型产出,真实场景中的应用有局限性。
此外,现有技术的语义结构化定义不能涵盖主要信息。例如社交媒体上会有大量类似表达:“夏天宝宝容易不消化,吃合生元,很快就会好”。命名实体识别技术可以识别品牌名“合生元”,方面抽取技术可以识别“消化”,实体方面级情感分析可以输出(合生元,消化,正面)。然而这些技术会遗漏不消化发生的场景是夏天,对象是宝宝,不消化是需求,解决方案是合生元,好的快是选择合生元的驱动因素。用现有方法无法识别的信息,包括场景、对象、需求、解决方案、驱动因素、疑问中性因素,对品牌方产品研发、营销话术都有非常大的帮助。
发明内容
本发明的目的是提供一种消费者文本的信息提取结构,标注方法和识别方法,用以识别文消防者文本中的结构化信息及其对应关系。
为了达到上述目的,本发明一方面提供消费者文本的信息提取结构,其特征在于,所述信息提取结构包括:
需求,用以表达消费者的需求;
场景,用以表达所述需求发生的场景;
方案,用以表达所述需求对应的解决方案;
驱动因素,用以表达选择所述解决方案的原因;
阻碍因素,用以表达阻碍选择所述解决方案的原因;
疑问中性因素,用以表达购买决策中的疑问要素。
另一方面,本发明还提供一种消费者文本信息结构的标注方法,其包括以下步骤:
获取待识别的文本;
从待识别的文本中提取信息,根据提取信息建立n个二维数组,每个二维组中包括元素及其维度,所述元素的关联通过维度建立,所述维度包括:需求、场景、方案、驱动因素、阻碍因素和疑问中性因素;
采用BIO结构分别对所述二维数组中的元素进行标注,得到BIO标注结果,标注后每一个元素均包括BIO标注和维度。
另一方面,本发明还提供一种识别方法,包括:
获取经过标注的待检测文本;
根据BIO标注将待检测文本中的元素进行归类,并将归类后的元素输入到相应的信息提取维度的分类,所述维度包括:需求、场景、方案、驱动因素、阻碍因素和疑问中性因素;
根据分类结果,输出待检测文本的经过维度分类的元素。
进一步的,在分类过程中,还包括:
将文本输入BERT编码模型,将文本转化为经过编码后的特征序列,所述特征序列具有结合上下文语义的向量标识。
进一步的,在分类过程中,还包括:
将BERT编码后的特征序列输入LSTM模型,输出具有维度表达的特征序列;
将具有维度表达的特征序列输入Dropout和全连接层,进行泛化处理和分布特征映射。
进一步的,在分类过程中,还包括:
将Dropout和全连接层输出结果输入条件随机场,识别BIO标注中的顺序性关系;
采用分词修正对修正条件随机场的识别结果,完成对信息提取维度的分类;
根据BIO标注和信息提取维度的分类结果,格式化处理输出消费者文本的信息提取结果。
另一方面,本发明还提供一种识别方法,包括:
获取经过标注的待检测文本;
根据BIO标注将待检测文本中的元素进行归类,并将归类后的元素输入到相应的信息提取维度的分类,所述维度包括:需求、场景、方案、驱动因素、阻碍因素和疑问中性因素;
根据分类结果,输出待检测文本的经过维度分类的元素;
识别维度分类的对应关系,所述对应关系包括需求-场景,需求-解决方案,解决方案-驱动因素,解决方案-阻碍因素,解决方案-疑问中性,根据对应关系输出各元素之间的维度分类关系。
进一步的,在分类过程中,还包括:
将文本输入BERT编码模型,将文本转化为经过编码后的特征序列,所述特征序列具有结合上下文语义的向量标识。
进一步的,在分类过程中,还包括:
将BERT编码后的特征序列输入LSTM模型,输出具有维度表达的特征序列;
将具有维度表达的特征序列输入Dropout和全连接层,进行泛化处理和分布特征映射。
进一步的,在分类过程中,还包括:
将Dropout和全连接层输出结果输入条件随机场,识别BIO标注中的顺序性关系;
采用分词修正对修正条件随机场的识别结果,完成对信息提取维度的分类。
进一步的,在识别对应关系的过程中,还包括:
将识别维度分类的对应关系输入BERT识别模型,所述BERT识别模型根据参数调优结果输出识别对象的对应关系。
本发明公开的一种消费者文本的信息提取结构,标注方法和识别方法,其信息提取结构包括需求、场景、方案、驱动因素、阻碍因素、疑问中性因素六个维度,通过多个二维数组和BIO结构对信息提取结构进行标识使其能被模型识别,通过构建识别模型可识别待检测文本中的经过维度分类的元素,并根据维度建立元素之间的对应关系,本发明能串联实体与方面的情感分析,解决现有技术的局限性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例的消费者文本信息结构的标注方法的流程图。
图2是本发明一个实施例的识别方法的流程图。
图3是本发明另一个实施例的识别方法的流程图。
图4是本发明一个实施例的一种电子设备的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在以下的描述中,涉及到“一些实施例”,其描述了所有可能实施例的子集,但是可以理解,“一些实施例”可以是所有可能实施例的相同子集或不同子集,并且可以在不冲突的情况下相互结合。
除非另有定义,本文所使用的所有的技术和科学术语与属于本申请的技术领域的技术人员通常理解的含义相同。本文中所使用的术语只是为了描述本申请实施例的目的,不是旨在限制本申请。
本发明首先定义一种消费者文本的信息提取结构,该结构包括以下六个维度:需求、场景、方案、驱动因素、阻碍因素、疑问中性因素。该维度用以对消者文本中的元素进行定义。
其中,需求为文本中消费者的需求,包括:症状、指标结果、诉求、情绪、生活、疑问等。
例如我今天【心情很糟】,或我今天【拉了很多次肚子】。
场景为需求发生的场景,包括人、时间、空间、伴随事件(包含:需求产生的一些背景信息、检查)、需求诱因。
例如,【我的儿子】总生病,或【因为体质关系】,老受凉。
方案为对于某一需求的解决方案,包括品类、品牌、产品、做法。
例如,只能【喝药】,【擦身体降温】,我想喝【奶茶】。
驱动因素为选择某一解决方案的原因,直接驱动选择这个产品/采取这个方法的原因。包括满足诉求、产品特性(成分、材料、颜色等)、产地、包装、质量安全、品牌形象、性价比、情感体验。
例如,迪巧儿童钙【口味好】,【嚼着吃简单方便】。
阻碍因素为选择某一解决方案的原因,包括:副作用、未满足诉求、包装、质量安全、品牌形象、性价比、情感体验。
例如,现在君乐宝的奶粉【容易上火】。
疑问中性因素为消费者对产品购买决策中的疑问点,或中性观点。
例如,如:【口感】好不好,【德国】产的。
本发明的实施例提供一种消费者文本信息结构的标注方法,标注数据的目的是让自然语言处理模型学习人类的思维方式和认知结果。通过记录文本和其中的需求、场景、方案、驱动因素、阻碍因素、疑问中性因素,并且记录其中各维度之间的对应关系。
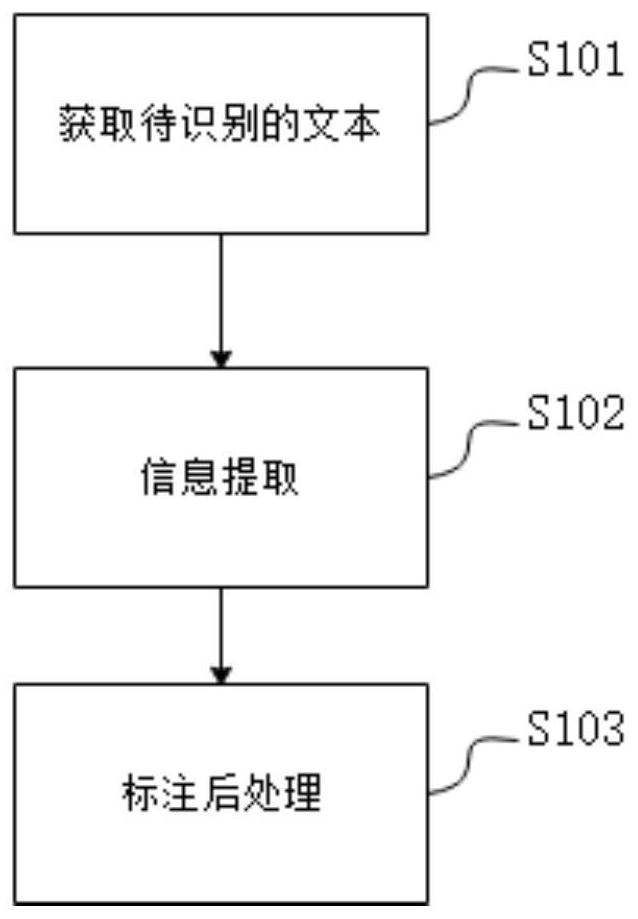
图1本发明实施例的消费者文本信息结构的标注方法的流程图。如图1所示,本发明的消费者文本信息结构的标注方法包括以下步骤:
S101,获取待识别的文本。
其中待识别文本可以来自于消费者文本也可来自于供应链厂家发布的营销语料。
例如,消费者文本可来自消费者评价,消费者投诉,消费者留言等C端数据源,也可来自产品设计说明,营销内容等B端数据源。
待识别语句可以是系统将用户通过语音采集装置采集到的语音数据转换而成的文本数据,也可以是用户直接通过输入装置输入的文本数据,本申请实施例对于该待识别语句的来源不做固定限制,具体可以根据实际的应用场景确定。
S102,信息提取。
信息提取的目的是将元素提取后与相应的维度相关联,元素的维度包括需求、场景、方案、驱动因素、阻碍因素、疑问中性因素。因此,当一句话存在多个元素和维度时,就需要考虑元素和元素,维度和维度,元素与维度的关系。
在一个实施例中,本发明从待识别的文本中提取信息,根据提取信息建立n个二维数组,每个二维组中包括元素及其维度,所述元素的关联通过维度建立,所述维度包括:需求、场景、方案、驱动因素、阻碍因素和疑问中性因素。具体如下表所示:
S103,标注后处理
采用BIO结构分别对所述二维数组中的元素进行标注,得到BIO标注结果,标注后每一个元素均包括BIO标注和维度。BIO标注是序列标注任务中常用的一种标注模式,其中,B-begin标记实体的起始字,I-inside标记实体中的字(除了起始字),O-outside标记实体以外的字;则上述B标签指的则是实体起始字,I标签指的则是实体中除了起始字之外的其他字。
经过标注处理后的元素如下表所示:
图2是本发明一个实施例的识别方法的流程图。如图2所示,本发明实施例的识别方法包括以下步骤:
S201,获取经过标注的待检测文本。
具体的,在步骤S201中,待检测文本记为T={w1,w2,w3,…wn},其中wi是文本中的第i个字符。
S202,根据BIO标注将待检测文本中的元素进行归类,并将归类后的元素输入到相应的信息提取维度的分类,所述维度包括:需求、场景、方案、驱动因素、阻碍因素和疑问中性因素。
在一个实施例中,首先把待检测文本输入BERT编码模型,输出获得文字结合上下文语义的向量表示,每个字被表示成768维的向量表示。BERT编码层的输出是V={v1,v2,v3,…vn},其中vi是文本中的第i个字符经过编码后的向量表示。
然后,将BERT编码后的特征序列输入LSTM模型,输出具有维度表达的特征序列,记为H={h1,h2,h3,…hn}。
可以理解的是,LSTM模型目的是解决上下文信息长期依赖和短期依赖的问题。它既可以编码出上下文全局信息,对理解整句语义有帮助;又可以编码出局部信息。LSTM模型识别需求、场景、解决方案、驱动因素、阻碍因素、疑问中性因素具有很高效率。
在一个实施例中,将具有维度表达的特征序列输入Dropout和全连接层,进行泛化处理和分布特征映射。
优选的,Dropout层的Dropout rate=0.5,让该层随机选取50%的节点,数值置为0。可在只保留了一部分信息时,依然能做出比较好的预测。
在一个实施例中,本发明将Dropout和全连接层输出结果输入条件随机场,识别BIO标注中的顺序性关系。
可以理解的,条件随机场可被看作是最大熵马尔可夫模型在标注问题上的推广。它的主要价值是学会BIO标注结构中标签的顺序性关系,例如I的前面只能是B或I。
在一个实施例中,本发明采用分词修正对修正条件随机场的识别结果,完成对信息提取维度的分类。
具体的,为了解决某些词汇边界识别不准确的问题。分词修正步骤的计算方法如下:
输入:条件随机场的预测输出{pi},其中i={1,…,n};原句分词结果。
计算步骤:
for i from 1to n:
如果第i个位置的预测结果不是标签O即pi!=O:
分词后第i个字符所在的词,对于该词中所有字符:
如果预测结果的类别标签是O:
保证该词的所有字符的类别标签都和pi的类别标签一致;
该词的首字符的结构标签设置为B,其余字符设置为O。
例如品牌名“帮宝适”只识别出“宝适”是方案,而忽略了“帮”字。我们采用分词技术来修正条件随机场的输出,修正的方式是,分词后的词,只要其中有一个字被识别成需求、场景、解决方案、驱动因素、阻碍因素、疑问中性因素之一,就把这个词的所有字都识别成那个类别。如果一个词中有多个字符分别被识别成多个类别,则不进行修正,这种情况通常发生的概率非常小,每1000个词中出现这种情况的平均不到1次,且通常是由于分词本身的问题导致的。
S203,根据分类结果,输出待检测文本的经过维度分类的元素。
在一个实施例中,按照BIO结构进行分类预测后,通过后处理步骤将预测结果转化成结构化的5列,即通过B和I作为开头的类别,抽取出对应的文字输出到对应的类别中,输出形式如下表所示:
图3是本发明另一个实施例的识别方法的流程图。如图3所示,本实施例的识别方法包括以下步骤:
S301,获取经过标注的待检测文本。
具体的,在步骤S201中,待检测文本记为T={w1,w2,w3,…wn},其中wi是文本中的第i个字符。
S302,根据BIO标注将待检测文本中的元素进行归类,并将归类后的元素输入到相应的信息提取维度的分类,所述维度包括:需求、场景、方案、驱动因素、阻碍因素和疑问中性因素。
在一个实施例中,首先把待检测文本输入BERT编码模型,输出获得文字结合上下文语义的向量表示,每个字被表示成768维的向量表示。BERT编码层的输出是V={v1,v2,v3,…vn},其中vi是文本中的第i个字符经过编码后的向量表示。
然后,将BERT编码后的特征序列输入LSTM模型,输出具有维度表达的特征序列,记为H={h1,h2,h3,…hn}。
在一个实施例中,将具有维度表达的特征序列输入Dropout和全连接层,进行泛化处理和分布特征映射。
优选的,Dropout层的Dropout rate=0.5,让该层随机选取50%的节点,数值置为0。可在只保留了一部分信息时,依然能做出比较好的预测。
在一个实施例中,本发明将Dropout和全连接层输出结果输入条件随机场,识别BIO标注中的顺序性关系。
在一个实施例中,本发明采用分词修正对修正条件随机场的识别结果,完成对信息提取维度的分类。
具体的,为了解决某些词汇边界识别不准确的问题。分词修正步骤的计算方法如下:
输入:条件随机场的预测输出{pi},其中i={1,…,n};原句分词结果。
计算步骤:
for i from 1to n:
如果第i个位置的预测结果不是标签O即pi!=O:
分词后第i个字符所在的词,对于该词中所有字符:
如果预测结果的类别标签是O:
保证该词的所有字符的类别标签都和pi的类别标签一致;
该词的首字符的结构标签设置为B,其余字符设置为O。
S303,根据分类结果,输出待检测文本的经过维度分类的元素。
在一个实施例中,按照BIO结构进行分类预测后,通过后处理步骤将预测结果转化成结构化的5列,即通过B和I作为开头的类别,抽取出对应的文字输出到对应的类别中,输出形式如下表所示:
S304,识别维度分类的对应关系。对应关系包括需求-场景,需求-解决方案,解决方案-驱动因素,解决方案-阻碍因素,解决方案-疑问中性,根据对应关系输出各元素之间的维度分类关系。
其中,对于每一条文本的识别结果,如果同时包含某一种或几种关系的前项和后项,则把他们排列组合组装成一个2元的关系对,形如关系前项-关系后项。例如:
将原文和对应关系输入BERT模型,输出有无对应关系。该BERT模型与BERT编码模型不同,在学习的过程中,BERT模型的内部参数会持续调优。此处的设计相当于是让预训练的语言模型在该任务上进行微调,学得针对该任务的模型参数。
最后,模型输出有对应关系的元素和维度。
另一方面,本发明还提供一种计算机设备,其特征在于,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行上述方法的步骤。
另一方面,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被处理器执行时使所述处理器执行执行上述方法的步骤。
图4是本发明一个实施例的一种电子设备的结构示意图。如图4所示,本发明一个实施例的一种电子设备包括一个或多个输入设备1000、一个或多个输出设备1000、一个或多个处理器3000和存储器4000。
在本发明一个实施例中,处理器1000、输入设备2000、输出设备3000和存储器4000可以通过总线或其它方式连接。输入设备2000、输出设备3000可以是标准的有线或无线通信接口。
处理器1000可以是中央处理模块(Central Processing Unit,CPU),该处理器还可以是其他通用处理器、数字信号处理器(Digital Signal Processor,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现成可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
存储器4000可以是高速RAM存储器,也可为非不稳定的存储器,例如磁盘存储器。存储器4000用于存储一组计算机程序,输入设备2000、输出设备3000和处理器1000可以调用存储器4000中存储的程序代码。
存储器4000存储的计算机程序包括程序指令,所述程序指令当被处理器执行时使所述处理器执行如上述实施例中所述专利价值评估方法的步骤。
本发明的一个实施例还提供一种计算机可读存储介质。该计算机可读存储介质可以是高速RAM存储器,也可为非不稳定的存储器,例如磁盘存储器。该计算机可读存储介质可通过外部计算设备或网络进行连接,以读取该计算机可读存储介质所存储的一组计算机程序。该计算机可读存储介质存储的计算机程序包括程序指令,所述程序指令当被处理器执行时使所述处理器执行如上述实施例中上述方法的步骤。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 消费者文本的信息提取结构,标注方法和识别方法
- 利用二次语义标注的文本信息提取方法