一种提高地下水位变化量的空间分辨率及精度的方法
文献发布时间:2023-06-19 11:22:42
技术领域
本发明属于卫星重力学、水文学等交叉技术领域,尤其涉及一种提高地下水位变化量的空间分辨率及精度的方法。
背景技术
作为淡水资源的重要来源,地下水在人类生产生活中扮演着重要角色。从全球来看,它不仅为约20亿人提供饮用水,还为约40%配备灌溉设备地区提供灌溉用水。然而,近年来由于气候变化和人类活动,地下水资源正在发生剧烈变化。这将在我们生活的地球上产生一系列环境问题(如海平面上升、陆地沉陷、水文干旱加剧等)。因此,获取并理解地下水动态变化信息变得愈来愈重要。
通过布设监测井获取地下水位变化数据是较为传统的监测方式。然而,这个方式受限于政治因素、观测站和仪器精度,并不适用于大尺度或者偏远地区。2002年,GRACE(Gravity Recovery and Climate Experiment)重力卫星成功发射,为监测陆地水储量变化量提供了新的手段。GRACE重力卫星可以获取月尺度地球时变重力场,进而可以通过球谐系数获取陆地水储量TWSA(Terrestrial Water Storage Anomaly)。此外,GRACE卫星覆盖全球大部分区域且有较少数据缺失,可以为没有水文数据或者质量较差的区域提供连续的高质量数据。然后,通过将各种水文模型数据和GRACE数据相结合可以分离出地下水储量GWSA(Groundwater Storage Anomaly)。研究表明GRACE数据已经应用在许多领域,主要有陆地水储量和地下水储量的确定,以及干旱和洪涝灾害的监测。2003年,Swenson等通过在GRACE实际重力信号中应用平均核来获取北美流域区域尺度陆地水储量,结果表明:对于面积为4×105km
尽管GRACE重力卫星在大尺度陆地水资源监督和分析方面取得了较大成果,但由于其最终产品粗糙的空间分辨率(1°×1°),其贡献仅限于大尺度领域,却很难在精细领域提供更为精确地分析。华北平原是中国的政治、经济和文化中心,长期以来一直遭受着地下水超采的困扰。因此,许多学者已经基于该研究区提出了多种方法来进行了降尺度研究,旨在提供高空间分辨率的水储量估算,并且取得了较好的结果。然而,这些研究的目标变量都是水储量,较少关于地下水位的降尺度研究。
发明内容
本发明的技术解决问题:克服现有技术的不足,提供一种提高地下水位变化量的空间分辨率及精度的方法,可实现地下水位变化量高分辨率和高精度的获取。
为了解决上述技术问题,本发明公开了一种提高地下水位变化量的空间分辨率及精度的方法,包括:
获取待研究区域的气候数据;其中,气候数据,包括:降雨数据P、径流数据R、蒸散发数据ET、土壤水数据SM和雪水当量数据SWE;
通过降尺度模型,对气候数据进行处理,得到修正后的0.25°空间分辨率下的陆地水储量
通过数据融合模型,对气候数据进行处理,得到融合水位数据;
根据得到的
在上述提高地下水位变化量的空间分辨率及精度的方法中,通过降尺度模型,对气候数据进行处理,得到修正后的0.25°空间分辨率下的陆地水储量
确定GRACE-Noah降尺度模型:
其中:
从气候数据中提取得到1°空间分辨率下的土壤水数据和雪水当量数据、以及0.25°空间分辨率下的土壤水数据和雪水当量数据;从GRACE陆地水储量模型中提取得到GRACE卫星反演的1°格网下的规格化陆地水储量
根据1°空间分辨率下的土壤水数据和雪水当量数据的相加结果,得到1°格网下规格化的陆地水储量
根据0.25°空间分辨率下的土壤水数据和雪水当量数据的相加结果,得到0.25°格网下规格化的陆地水储量
确定1°格网的面积A和1°格网包含下的0.25°格网的面积a
将
在上述提高地下水位变化量的空间分辨率及精度的方法中,通过降尺度模型,对气候数据进行处理,得到修正后的0.25°空间分辨率下的陆地水储量
选择MLR降尺度模型或GBR降尺度模型;
从气候数据中提取得到0.25°空间分辨率下的降雨数据、径流数据和蒸散发数据;
将0.25°空间分辨率下的降雨数据、径流数据和蒸散发数据作为MLR降尺度模型或GBR降尺度模型的输入,得到输出结果,即修正后的0.25°空间分辨率下的陆地水储量
在上述提高地下水位变化量的空间分辨率及精度的方法中,通过如下步骤构建得到MLR降尺度模型或GBR降尺度模型:
获取0.25°空间分辨率下的样本降雨数据、径流样本数据和蒸散发样本数据,将0.25°空间分辨率下的样本降雨数据、径流样本数据和蒸散发样本数据作为自变量;
获取实测的0.25°空间分辨率下的陆地水储量样本数据,将0.25°空间分辨率下的陆地水储量样本数据作为目标变量;
采用MLR算法,训练得到自变量与目标变量之间的MLR降尺度模型;或,采用GBR算法,构建得到自变量与目标变量之间的GBR降尺度模型。
在上述提高地下水位变化量的空间分辨率及精度的方法中,通过数据融合模型,对气候数据进行处理,得到融合水位数据,包括:
从气候数据中提取得到0.25°空间分辨率下的降雨数据、径流数据和蒸散发数据;
将0.25°空间分辨率下的降雨数据、径流数据和蒸散发数据作为数据融合模型的输入,得到输出结果,即融合水位数据。
在上述提高地下水位变化量的空间分辨率及精度的方法中,通过如下步骤构建得到数据融合模型:
获取0.25°空间分辨率下的样本降雨数据、径流样本数据和蒸散发样本数据,将0.25°空间分辨率下的样本降雨数据、径流样本数据和蒸散发样本数据作为自变量;
获取实测的0.25°空间分辨率下的陆地水储量样本数据,将0.25°空间分辨率下的陆地水储量样本数据作为目标变量;
采用GBDT算法,训练得到自变量与目标变量之间的数据融合模型。
在上述提高地下水位变化量的空间分辨率及精度的方法中,根据得到的
从气候数据提取得到0.25°空间分辨率下的土壤水数据和雪水当量数据;
将
在上述提高地下水位变化量的空间分辨率及精度的方法中,通过如下步骤构建得到预测模型:
获取修正后的0.25°空间分辨率下的陆地水储量样本数据、融合水位样本数据、以及0.25°空间分辨率下的土壤水样本数据和雪水当量样本数据,作为预测因子;
获取实测的地下水位变化量样本数据,作为目标变量;
采用GBDT算法,训练得到预测因子与目标变量之间的预测模型。
在上述提高地下水位变化量的空间分辨率及精度的方法中,还包括:
通过均方根误差、平均绝对误差、纳什效率系数和相关系数对降尺度模型、数据融合模型和预测模型进行评估;
根据评估结果,对降尺度模型、数据融合模型和预测模型进行修正。
在上述提高地下水位变化量的空间分辨率及精度的方法中,
通过下式确定均方根误差RMSE:
通过下式确定平均绝对误差MAE:
通过下式确定纳什效率系数NSE:
通过下式确定相关系数CC:
其中,
本发明具有以下优点:
(1)本发明公开了一种提高地下水位变化量的空间分辨率及精度的方法,基于降尺度模型、数据融合模型和预测模型构成了一种新型基于机器学习降尺度预测联合模型,该联合模型在提高GRACE产品空间分辨率及预测高精度GWLA产品方面表现出了巨大的潜力。
(2)本发明公开了一种提高地下水位变化量的空间分辨率及精度的方法,采用新型基于机器学习降尺度预测联合模型对华北平原地下水位变化量进行获取,具有空间分辨率及精度高、计算速度快等优点。
(3)本发明公开了一种提高地下水位变化量的空间分辨率及精度的方法,不仅可以提高GRACE数据的空间分辨率,还可以预测高空间分辨率下高精度的GWLA产品。
附图说明
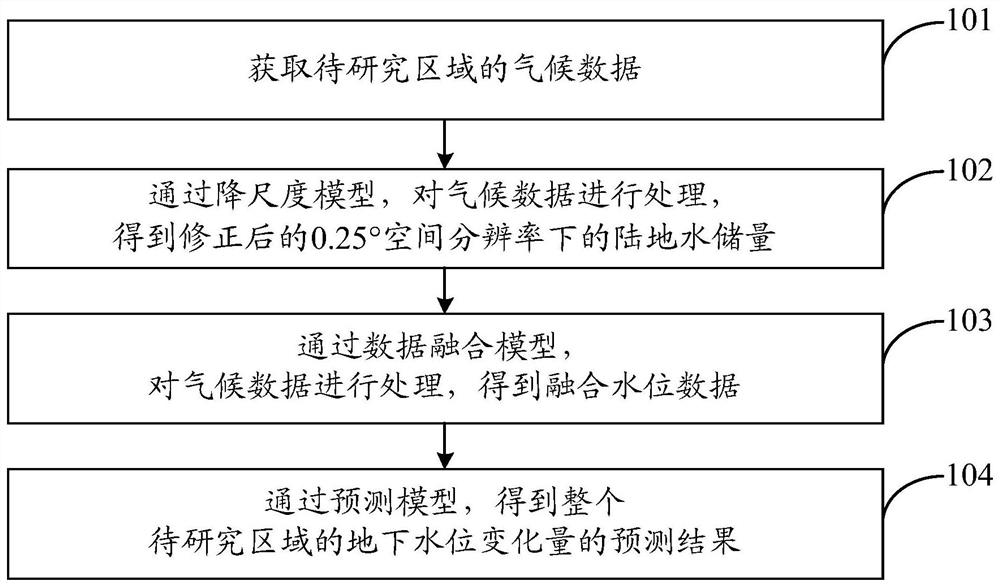
图1是本发明实施例中一种提高地下水位变化量的空间分辨率及精度的方法的步骤流程图;
图2是本发明实施例中一种研究区域的位置及井位分布示意图;
图3是本发明实施例中一种用于构建模型的变量示意图;
图4是本发明实施例中一种水循环示意图;
图5是本发明实施例中一种基于机器学习的降尺度预测联合模型示意图;
图6是本发明实施例中一种陆地水储量异常变化趋势;其中,图6(a)为原始1°分辨率的年变化趋势;图6(b)、图6(c)和图6(d)分别表示GRACE-Noah、GBR和MLR模型的降尺度结果;
图7是本发明实施例中一种地下水储量异常变化趋势;其中,图7(a)为原始1°分辨率的年变化趋势;图7(b)、图7(c)和图7(d)分别表示GRACE-Noah、GBR和MLR模型的降尺度结果;
图8是本发明实施例中一种整个研究区降尺度前后TWSA和GWSA的时间序列变化对比示意图;
图9是本发明实施例中一种GWLA的实测值和模拟值的对比示意图;其中,图9(a)、图9(b)、图9(c)、图9(d)、图9(e)和图9(f)分别表示井位G072、G143、G165、G178、G180和G230;
图10是本发明实施例中一种模型建立前后测试井变化对比图;其中,图10(a)、图10(b)、图10(c)、图10(d)、图10(e)和图10(f)分别表示井位G119、G272、G278、G341、G3890和G510;
图11是本发明实施例中一种模型预测前后相关系数对比图;其中,方块线表示模块#1的结果,圆圈线表示预测模块的结果,直线分别表示对应结果的平均值。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明公开的实施方式作进一步详细描述。
如图1,在本实施例中,该提高地下水位变化量的空间分辨率及精度的方法,包括:
步骤1,获取待研究区域的气候数据。
在本实施例中,气候数据包括:降雨数据、径流数据、蒸散发数据、土壤水数据和雪水当量数据。其中,降雨数据、径流数据、土壤水数据和雪水当量数据可以从Noah(NoahLand Surface Model)水文模型中提取得到,蒸散发数据可以从GLEAM(Global LandEvolution Amsterdam Model)中提取得到。
步骤2,通过降尺度模型,对气候数据进行处理,得到修正后的0.25°空间分辨率下的陆地水储量
在本实施例中,可以采用三种降尺度模型来得到修正后的0.25°空间分辨率下的陆地水储量
优选的,GRACE-Noah降尺度模型的处理流程如下:
21)确定GRACE-Noah降尺度模型:
其中:
22)从气候数据中提取得到1°空间分辨率下的土壤水数据和雪水当量数据、以及0.25°空间分辨率下的土壤水数据和雪水当量数据;从GRACE陆地水储量模型中提取得到GRACE卫星反演的1°格网下的规格化陆地水储量
23)根据1°空间分辨率下的土壤水数据和雪水当量数据的相加结果,得到1°格网下规格化的陆地水储量
24)根据0.25°空间分辨率下的土壤水数据和雪水当量数据的相加结果,得到0.25°格网下规格化的陆地水储量
25)确定1°格网的面积A和1°格网包含下的0.25°格网的面积a
26)将
优选的,MLR降尺度模型的处理流程如下:
从气候数据中提取得到0.25°空间分辨率下的降雨数据、径流数据和蒸散发数据;将0.25°空间分辨率下的降雨数据、径流数据和蒸散发数据作为MLR降尺度模型或GBR降尺度模型的输入,得到输出结果,即修正后的0.25°空间分辨率下的陆地水储量
进一步的,可以通过如下步骤构建得到MLR降尺度模型:获取0.25°空间分辨率下的样本降雨数据、径流样本数据和蒸散发样本数据,将0.25°空间分辨率下的样本降雨数据、径流样本数据和蒸散发样本数据作为自变量;获取实测的0.25°空间分辨率下的陆地水储量样本数据,将0.25°空间分辨率下的陆地水储量样本数据作为目标变量;采用MLR算法,训练得到自变量与目标变量之间的MLR降尺度模型。
优选的,GBR降尺度模型的处理流程如下:
从气候数据中提取得到0.25°空间分辨率下的降雨数据、径流数据和蒸散发数据;将0.25°空间分辨率下的降雨数据、径流数据和蒸散发数据作为MLR降尺度模型或GBR降尺度模型的输入,得到输出结果,即修正后的0.25°空间分辨率下的陆地水储量
进一步的,可以通过如下步骤构建得到GBR降尺度模型:获取0.25°空间分辨率下的样本降雨数据、径流样本数据和蒸散发样本数据,将0.25°空间分辨率下的样本降雨数据、径流样本数据和蒸散发样本数据作为自变量;获取实测的0.25°空间分辨率下的陆地水储量样本数据,将0.25°空间分辨率下的陆地水储量样本数据作为目标变量;采用GBR算法,构建得到自变量与目标变量之间的GBR降尺度模型。
步骤3,通过数据融合模型,对气候数据进行处理,得到融合水位数据。
在本实施例中,从气候数据中提取得到0.25°空间分辨率下的降雨数据、径流数据和蒸散发数据;将0.25°空间分辨率下的降雨数据、径流数据和蒸散发数据作为数据融合模型的输入,得到输出结果,即融合水位数据。
优选的,可以通过如下步骤构建得到数据融合模型:获取0.25°空间分辨率下的样本降雨数据、径流样本数据和蒸散发样本数据,将0.25°空间分辨率下的样本降雨数据、径流样本数据和蒸散发样本数据作为自变量;获取实测的0.25°空间分辨率下的陆地水储量样本数据,将0.25°空间分辨率下的陆地水储量样本数据作为目标变量;采用GBDT(Gradient Boosting Decision Tree)算法,训练得到自变量与目标变量之间的数据融合模型。
步骤4,根据得到的
在本实施例中,从气候数据提取得到0.25°空间分辨率下的土壤水数据和雪水当量数据;将
优选的,通过如下步骤构建得到预测模型:获取修正后的0.25°空间分辨率下的陆地水储量样本数据、融合水位样本数据、以及0.25°空间分辨率下的土壤水样本数据和雪水当量样本数据,作为预测因子;获取实测的地下水位变化量样本数据,作为目标变量;采用GBDT算法,训练得到预测因子与目标变量之间的预测模型。
在本实施例中,该提高地下水位变化量的空间分辨率及精度的方法还可以包括:通过均方根误差、平均绝对误差、纳什效率系数和相关系数对降尺度模型、数据融合模型和预测模型进行评估;根据评估结果,对降尺度模型、数据融合模型和预测模型进行修正。
优选的,通过下式确定均方根误差RMSE(Root Mean Square Error):
优选的,通过下式确定平均绝对误差MAE(Mean Absolute Error):
优选的,通过下式确定纳什效率系数NSE(Nash-Sutcliffe efficiencycoefficient):
优选的,通过下式确定相关系数CC(Correlation coefficient):
其中,
综上所述,本发明涉及一种提高地下水位变化量的空间分辨率及精度的方法。GRACE重力卫星为研究水资源提供了新方法并在大尺度区域得到广泛应用,但其粗糙的空间分辨率限制了水资源进一步分析的步伐。为克服这些局限,本发明在基于GRACE重力卫星获取高质量水文产品方面开展了探索性研究。第一,基于一些气候变量及水储量组分(陆地水储量异常、降雨、径流、蒸散发、土壤水储量、雪水当量和实测地下水位),在华北平原构建了新型基于机器学习降尺度预测联合模型,该模型包含三个模块(降尺度模块、数据融合模块和预测模块)。第二,收集了18口实测水井并基于这些水井评估了降尺度模块,结果表明:三种降尺度模型(多元线性回归、梯度提升决策树和GRACE-Noah)在提高陆地水储量异常空间分辨率方面(1°到0.25°)都表现出了较好性能,尤其是GRACE-Noah模型(相关系数为0.24-0.78)。第三,选取了12口井位作为控制井,并基于GBDT(gradient boostingdecision tree)算法构建了预测模型,剩余6口井位用于模型验证。结果表明:6口井位实测数据和仿真结果的平均相关系数达到了0.71,比降尺度结果(0.43)精度提高了65.12%。因此,本发明开发的新型基于机器学习降尺度预测联合模型在提高GRACE产品空间分辨率及预测高精度GWLA产品方面表现出了较大潜力。新型机器学习降尺度预测联合模型的优点为华北平原地下水位变化量的空间分辨率及精度高、计算速度快。
在上述实施例中,下面以对华北平原的研究为例,对本发明进行说明。
一、本实施例的研究区及数据
1.1、研究区域
如图2所示,华北平原是中国东部大平原的重要组成部分,面积为140000km
1.2、数据
如图3和图4所示,为实现各模型的构建,本实施例共收集了四种数据集并进行相应处理:数据集一:从GRACE陆地水储量模型中提取得到的TWSA;数据集二:从Noah水文模型中提取得到的降雨数据P、径流数据R、土壤水数据SM和雪水当量数据SWE;数据集三:从GLEAM中提取得到的蒸散发数据ET(Evapotranspiration);数据集四:通过收集中国实测水井的年鉴资料获得的地下水位数据GWL。其中,数据集一中的数据的空间分辨率为1°,数据集二和数据集三中的数据包括两种空间分辨率(1°和0.25°)。地下水位数据是不规则分布在研究区域的点位数据。本实施例时间跨度为2005~2014(共120个月)。
1.2.1、TWSA数据
美德合作研制的GRACE重力卫星于2002年升空,并于2017年圆满完成任务。GRACE重力卫星采用双星编队和低低卫星跟踪卫星模式,在轨运行期间获取了大量的高精度卫星跟踪数据,并经由美国喷气推进实验室JPL(Jet Propulsion Laboratory)、德克萨斯州立大学空间研究中心CSR(Center for Space Research)和德国波兹坦地球科学研究中心GFZ(Geo Forschungs Zentrum Potsdam)三大机构进行处理。本实施例采用的数据为经三大机构对GRACE数据进行滤波、高斯平滑和去平均处理后的RL05产品,数据时间跨度为2003~2016年共156个月、空间分辨率为1°×1°、时间分辨率为月尺度的陆地水储量变化格网数据,TWSA的单位为cm。由于三大机构的数据并不完全一致,且某些月份存在空缺值,故在使用时需对三大机构的产品进行插值得到完整时间序列数据,并乘上对应的尺度因子以矫正数据信息。
1.2.2、降雨数据P
热带雨林测量任务TRMM(Tropical Rainfall Measuring Mission)是NASA和日本航空航天局JAXA(Japan Aerospace Exploration Agency)共同合作项目,主要为了研究降雨数据对天气和气候的影响。本发明采用的数据集是时间跨度为2003~2015、纬度范围为113°~120°E、经度范围为35°~41°N、空间分辨率为0.25°×0.25°、时间分辨率为月尺度的3B43数据。该数据集可从戈达德地球科学数据和信息服务中心GES DISC(Goddard EarthSciences Data and Information Services Center)。由于降尺度的需要,还需对0.25°降雨数据进行重采样处理得到1°降雨产品。
1.2.3、径流数据R、土壤水数据SM和雪水当量数据SWE
全球陆地数据同化系统GLDAS(Global Land Data Assimilation System)是NASA与JAXA的联合项目,主要目的是使用先进的地面建模和数据同化技术提取卫星和地面数据并整合为最佳模型。目前,GLDAS系统共有四种陆面模型(Land Surface Model,LSM):Mosaic、CLM2、Noah和VIC。本实施例主要采用的陆面模型为Noah水文模型,主要包含径流数据R、土壤水数据SM和雪水当量数据SWE,其中径流数据包含地表径流和地下径流,土壤水数据为四层土壤水数据总和。径流数据R、土壤水数据SM和雪水当量数据SWE的时间分辨率为月尺度,空间分辨率包含1°和0.25°两种,覆盖范围同降雨数据。
1.2.4、蒸散发数据ET
本实施例采用的蒸散发数据ET来源于GLEAM。GLEAM是一种通过结合卫星观测数据并利用Priestley和Taylor方程估算全球规模下的蒸散发算法。自2011年来,GLEAM一直在不断修订和更新,到2017年已经发布了该模型的第三个版本。采用的数据包含两种空间分辨率分别为1°和0.25°,这两种数据都是月尺度,范围覆盖华北平原。
1.2.5、地下水位数据GWL
地下水位数据可验证降尺度后的陆地水储量数据是否在研究区域能够较好拟合。月尺度地下水位数据主要通过收集海河流域地下水位年鉴资料获取。虽然收集了华北平原区域内多口水井的水位数据,但有较大部分数据出现大时间跨度的缺失以及少部分数据具有明显的误差现象。因此,在使用数据前需要对收集的数据进行预处理:(1)剔除缺失月份较多的数据及误差明显的数据;(2)针对0.25°网格内存在多口井的情况取平均值作为该格网值;(3)选取的井位数据需进行去平均化得到地下水位变化量。最终经过对水井数据的处理,一共有18口井被选择用于本发明,再依据水井位置分布,选取12口水井用于模型训练和6口水井用于模型测试。
二、本实施例使用的算法和模型
2.1、梯度提升回归树算法
梯度提升回归树算法简称GBDT或者GBRT(Gradient Boosting RegressionTree),是将多个弱学习器组合成强学习器的算法。GBRT既可以用作回归模型又可以用作分类模型,但是模型的每一棵决策树都是回归树。与其他传统回归方法不同,GBDT通过遵循梯度负方向来实现算法的全局收敛。GBRT的计算核心就是通过不断传递前面所有棵树的结论和残差进行学习和预测,最终能够使得所有树的预测值之和与输入目标的残差和达到最小。
2.2、GRACE-Noah模型
通过GRACE数据可以得到陆地水储量变化量,研究区域内陆地水储量变化量包含地下水储量、土壤水和雪水当量变化量。GLDAS提供的Noah水文模型可以提供研究区内土壤水储量和雪水当量变化量,故利用GRACE得到的陆地水储量数据来修正GLDAS-Noah模型得到的陆地水储量数据,可以得到更为准确的陆地水储量产品。GRACE-Noah模型推导如下:
2.3、多元线性回归MLR
多元线性回归MLR是多自变量对应多因变量的回归建模方法,其参数最主要的估计方法为最小二乘法。最小二乘法主要通过最小化误差的平方和寻找最佳函数。同一元回归模型相比,多元线性回归模型更切合实际,更能准确模拟自变量与因变量的关系达到预测和估计的目的。本实施例采用的MLR方法可以用如下公式表达:
y=a
其中,y表示独立目标变量(TWSA),x
2.4、提高地下水位变化量的空间分辨率及精度的方法
为获得高空间分辨率和高精度的地下水位变化量,如图5所示,本实施例在华北平原建立了由降尺度模型构成的模块#1、由数据融合模型构成的模块#2和由预测模型构成的模块#3。模块#1通过使用不同的算法(MLR、GBDT和GRACE-Noah)将GRACE衍生的TWSA从1°缩减到0.25°。模块#2用于基于GBDT算法将气候变量与原位水平合并。模块#3,接受来自模块#1的缩减后的TWSA和来自模块#2的融合GWLA。然后,将这些变量集成到一个大模型中,以获得整个研究区域的GWLA。
2.4.1、降尺度模型
可以采用GBR降尺度模型、MLR降尺度模型和GRACE-Noah降尺度模型中的任意一种对TWSA进行降尺度。其中,GBR降尺度模型和MLR降尺度模型应用了机器学习算法,GRACE-Noah降尺度模型是基于GRACE衍生的TWSA和水文数据的融合。
第一步:准备数据。获取NCP范围内0.25°和1°空间分辨率的P、R、ET、SM、SWE数据产品和1°空间分辨率下的TWS数据。
第二步:训练模型。针对每一个1°网格,分别采用GBR和MLR两种算法得到对应格网自变量P、R、ET和目标变量TWS的对应模型,研究区共计42个网格的模型,其中共计25个网格与NCP最为贴合。通过纳什效率系数来评价模型的性能。
第三步:模型传递。将第二步得到的42个1°空间分辨率的模型传递到0.25°空间分辨率下,每一个1°格网模型对应其0.25°空间分辨率下的16个格网数据,得到0.25°TWS产品。
第四步:水井验证。利用降尺度的TWS产品去除GLDAS模型下的SM和SWE得到0.25°下的GWS,和实测的水井数据进行比较分析,检验降尺度数据的适用性。
2.4.2、数据融合模型
数据融合模型的构建主要是为了实现气候数据和地下水位变化量的融合。这些融合的井位数据主要是为了在模块#3中实现控制井的作用。本实施例基于海河流域水资源公报收集了18口实测井位数据,选取了12口井位作为控制井。基于GBDT算法,本实施例为每口控制井构建了数据融合模型,并选取70%的数据进行训练,剩下的30%用于验证模型的性能。
2.4.3、预测模型
为了得到研究区所有格网的GWLA数据,本实施例基于前两个模块和其他气候数据构建了预测模型:12口实测井位被选择用作训练井,剩余的6口井位被用作评估预测模型的性能。为构建预测模型,本实施例选择了15个和水储量相关的特征作为预测因子。针对每一口训练井,本实施例构建一个子数据集,每个数据集包含12口固定变量(数据融合模型的结果)和3个水变量。然后,本实施例将12个子数据集堆叠起来构建一个维度为1440×15的矩阵。通过不断的训练和调试,一个理想的预测模型在华北平原被构建起来。假设这个模型适用于整个研究区,本实施例可获取整个研究区的地下水位变化量通过应用每个网格的子数据集到此模型中。
三、结果
3.1、降尺度模型评估
本实施例从空间分辨率和时间分辨率两个角度分别评估了三个降尺度模型的性能。
3.1.1、空间分辨率
三种模型降尺度结果以每个格网的年变化趋势表示,如图6所示。图6(a)显示了空间分辨率为1°时TWSA的年度变化特征,图6(b)、图6(c)和图6(d)分别显示了GRACE-Noah、GBR和MLR模型的降尺度结果。通过对比发现:在降尺度前后,整个华北平原的TWSA年变化趋势的空间分布特征基本一致。但是,GRACE-Noah模型的结果与其他模型结果略有不同,主要体现在环渤海地区,出现这种现象可能由模型算法本身导致。
此外,GWSA产品是依据GLDAS-Noah模型模拟的水文变量(SM和SWE)从降尺度后的TWSA中分离出来,空间分布如图7所示。与TWSA类似,GWSA变化趋势的分布特征在降尺度前后基本相同。而且图8(b)的结果也在环渤海地区与其它模型结果不同。尽管TWSA和GWSA在数值上有所不同,但是它们的空间分布基本一致,并且在整个研究区域中都呈现出下降的趋势。
3.1.2、时间分辨率
为了更直观地评估缩小后的结果,图8中绘制了TWSA和GWSA的时间序列。从2005~2015年,TWSA和GWSA可以观察到类似的下降趋势,其趋势为-9.89mm/yr和-8.45mm/yr。对于GWSA,下降趋势从开始的-5.94mm/yr逐渐增加到-10.21mm/yr。基于GLDAS-Noah模型的降尺度地下水储量估算值与原始分辨率下的结果具有较好相关性,相关性高达0.99,RMSE值为1.49mm。MLR模型在降尺度过程中表现较差,可能的原因是在降尺度过程中缺少某些信息。基于以上讨论,选择GRACE-Noah的降尺度结果作为代表值,从而在以下讨论中使用。
3.2、数据融合结果
为了构建预测模型,本实施例在数据融合模块中依据井位的空间分布及数据质量选择了12口井位作为控制井。基于GBR算法,本实施例共构建了12个机器学习模型将12口控制井的P、R和ET信息融入到每口井的GWLA中,时间序列变化结果如图9所示。无论是从性能指标还是时间变化来看,12个机器学习模型都表现出了较优性能,平均NSE和CC分别为0.91和0.97。然后融合后的地下水位变化量被选做控制井并作为预测模型的输入变量。
3.3、预测性能分析
研究区域内所有网格的GWLA数据通过预测模块获得。在这个模块中,6口井用于测试模型的性能,预测得到的GWLA和实测水井的GWLA以及模块#1得到的GWSA的对比结果如图10所示。结果表明:前5口井位的预测结果和实测数据的时间序列对比结果表现较好,而最后一口井位的数据相对较差。这主要归因于P6井位处于比较靠近渤海湾区域导致数据质量较差。总体而言,所有井的预测值与原位值之间会有一定的偏差,但总体趋势基本相同。
3.4、实测井验证
为进一步探索基于机器学习的融合模型的适用性,本实施例共收集18口井位以评估仿真结果,相关系数的比较结果如图11所示。验证包括两部分,即验证缩减结果并验证预测结果。针对降尺度结果,全部18口井位均用于评估模型的性能,三个降尺度模型均可获得较合理结果,平均CC值为0.36(MLR)、0.49(GBDT)和0.56(GRACE-Noah)。尽管MLR和GRR模型在某些井(例如P2、P4和P6井)中可能显示出更好的性能,但其值接近于GRACE-Noah模型。此外,其他井在GRACE-Noah模型中表现出明显更好的性能,特别是在T10井中,CC值为-0.46(MLR)、0.30(GBDT)和0.41(GRACE-Noah)。因此,在本发明中,GRACE-Noah模型被认为是最佳的降尺度模型,其次是GBDT模型。因此,基于GRACE-Noah模型的地下水估算值可与预测产品进行比较。
针对预测结果,本实施例比较了预测前后的结果的相关系数(如图11所示)。左侧的浅蓝色区域代表12个训练井的结果,而深蓝色区域代表6个预测井的结果。可以看出:GRACE衍生的GWSA(GRACE-Noah)与实测得到的GWLA之间的平均相关系数为0.43,而预测结果相对于降尺度结果增加到0.71。此外,在预测结果和原位GWLA之间的所有CC值均优于降尺度的结果,尤其是在P6井中,其性能高于预期结果,相关系数为0.67(图10(f)和图11)。总体而言,预测模型在模拟变化趋势方面表现出较为出色的性能,但在数值预测中可能有所不足。
4讨论
4.1、适用性分析
新型机器学习降尺度预测联合模型的变量数据选择主要基于水平衡原理,目的为提高GRACE数据的空间分辨率并获取高精度GWLA数据。通过对模型性能的评估以及结果的验证可以证明模型在本研究区域具有较好的适用性。在降尺度模块中选用机器学习算法(GBR和MLR)和经验模型(GRACE-Noah)进行了对比,尽管这三种模型都能达到较好的效果,但GRACE-Noah模型最优(如图10所示)。通过分析其模型的原理推测,可能是GRACE-Noah模型在构建时既保证了水文信息完整性,又通过权重分配法加入了尽可能多的GRACE信息。数据融合模块主要是将变量P、R和ET的信息融入12口控制井的GWLA数据中。在数据融合模块中,本发明主要基于GBR机器学习算法以格网为单位为每个控制井构建了机器学习模型,并且每个模型都表现出较好性能。降尺度模块和数据融合模块的结果都是为预测模块能得到高精度GWLA做准备。预测模块的构建依旧基于GBR算法模型,预测模块能够较好地实现预测功能,且相比降尺度模块的结果能大幅提高数据精度。
4.2、数据的局限性分析
新型机器学习降尺度预测联合模型可以预测较高质量的GWLA,但其预测结果的空间分辨率受限于构建模型所需水文变量的空间分辨率。空间分辨率的局限性主要体现在降尺度模块中,因为用于构建该模型需要用到水文变量(P、R和ET),而部分数据源的官方发布产品的空间分辨率最高为0.25°,导致该降尺度模块产品的空间分辨率被限制到0.25°。数据融合模块和预测模块都需要用到降尺度后的TWSA产品,并且其他变量(SM和SWE)的空间分辨率也为0.25°,因此本实施例只能在0.25°的空间分辨率下构建这两个模块的模型。当然,可以通过重采样获得具有较高空间分辨率的水文变量,但是这样操作将丢失部分水文信息,导致得到的结果和实测数据不符。因此,本发明希望可以得到空间分辨率更高的官方产品,并将其用于新型机器学习降尺度预测联合模型中,从而获得更高空间分辨率和精度的GWLA产品,以便对华北平原的地下水位信息进行解译。
4.3、不确定性分析
本实施例涉及到许多不确定性源,主要包括数据来源、变量选择和模型误差三个方面。尽管TWSA是取三大机构官方产品的平均值,但无论哪个机构在处理数据时都会涉及测量误差和信号泄漏误差。此外,水文模型得到的变量数据并不总是完全准确,并且来自实测井的GWLA数据可能存在仪器误差和人为错误。变量的选择对降尺度模型和预测模型的构建都具有较大影响。为了使新型机器学习降尺度预测联合模型具有物理意义,本实施例基于水平衡原理构造了降尺度模型。以P、R和ET三个数据集作为模型的输入变量,TWSA作为输出变量,进而提高GRACE-TWSA数据空间分辨率。当然,也有学者选择其他变量(温度、地表植被覆盖指数等),并且取得了较好成果。针对预测模块,本发明选择与GWLA数据直接相关的变量(TWSA、SM、SWE和GWLA_P)来构建模型。尽管模块变量的选择都使得降尺度模型和预测模型更具物理意义,但它们依旧不能表达出完整的水文信息。对于新型机器学习降尺度预测联合模型,无论模型的设计采用了哪种算法,都不能完全表达由算法本身确定的输入变量和输出变量之间的完整关系,都会存在误差。因此,这项研究可以做的是选择可能的最佳变量并训练更近似的模型,以达到提高GWLA的空间分辨率和精度的目的。
本发明虽然已以较佳实施例公开如上,但其并不是用来限定本发明,任何本领域技术人员在不脱离本发明的精神和范围内,都可以利用上述揭示的方法和技术内容对本发明技术方案做出可能的变动和修改,因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化及修饰,均属于本发明技术方案的保护范围。
本发明说明书中未作详细描述的内容属于本领域专业技术人员的公知技术。
- 一种提高地下水位变化量的空间分辨率及精度的方法
- 一种提高分布式光纤传感系统空间分辨率和定位精度的光纤传感器及其制作方法