一种实现跨领域的中文文本纠错方法和系统
文献发布时间:2023-06-19 11:44:10
技术领域
本发明涉及文本纠错领域,特别是指一种实现跨领域的中文文本纠错方法和系统。
背景技术
在日常生活中,我们在用微信、微博等社交工具中,在浏览网页、看公众号文章的时候经常会出现错字,导致文本意义出现歧义的情况。中文文本纠错技术就是通过自然语言处理的算法对中文语句进行自动检查,自动纠错的一项重要技术,其目的是提高语言的正确性,提升文本交互的效率和价值。现有的主流文本纠错的技术主要分为两种:一种是通过序列学习的方式来找到文本错误位置,再通过排序纠正文本的错误信息的pipline的方式。另外一种是端到端基于NMT(神经网络翻译)的模型从输入的错误文本到输出正确的文本内容的方式。
但是前者对于排序召回纠正错误文本的算法存在效率比较低,而且给出的正确文本由于候选集是有限集导致适用范围有限,可能还会导致歧义的出现。后者端到端的方式需要大量的有监督的训练集,并且模型复杂度很高性能无法作为基础模块嵌入很多下游应用中,过于低效。
发明内容
本发明的主要目的在于克服现有技术中的上述缺陷,提出一种实现跨领域的中文文本纠错方法,即一套错误检测→候选召回→纠错排序的模型,能够更通用地处理跨领域文本的纠错问题,通过深度学习训练的语言模型来召回文本,能够提升召回文本的困惑度,并且模型相互解耦合,提升了效率。
本发明采用如下技术方案:
一种实现跨领域的中文文本纠错方法,包括如下步骤:
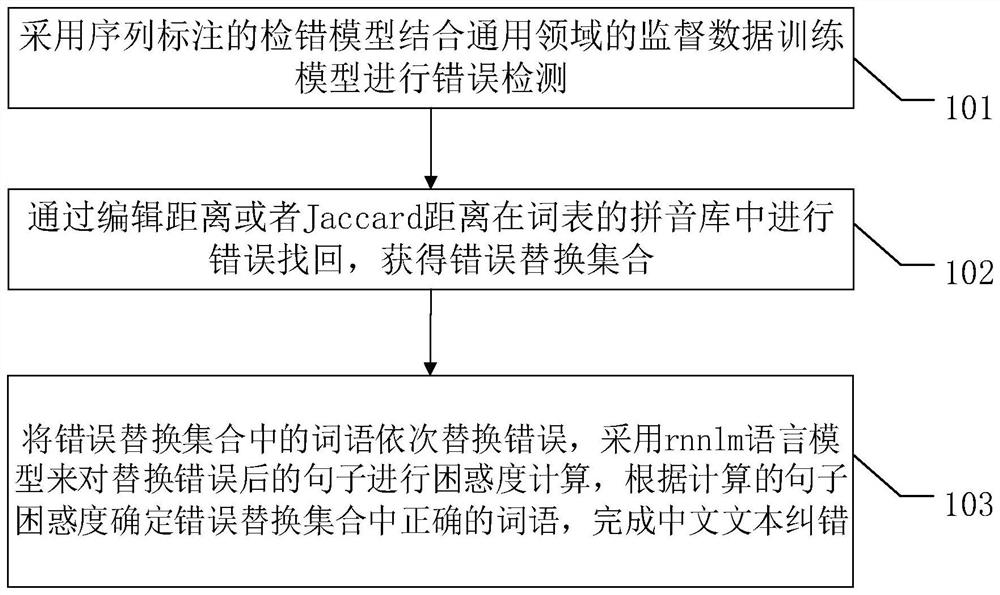
采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测;
通过编辑距离或者Jaccard距离在词表的拼音库中进行错误找回,获得错误替换集合;
将错误替换集合中的词语依次替换错误,采用rnnlm语言模型来对替换错误后的句子进行困惑度计算,根据计算的句子困惑度确定错误替换集合中正确的词语,完成中文文本纠错。
具体地,采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测,所述序列标注的检错模型结合通用领域的监督数据训练模型,具体为:
文本表示层,通过bert预训练模型进行文本表示,文本表示为n*k的矩阵,其中n为句子的最大长度,k为词向量维度;
Bi-LSTM层,通过长短期记忆网络实现句子中每个字的输出,并通过数学结构保持长距离的字的信息,Bi-LSTM层的输出矩阵为n*2*h,其中h为文本表示层的维度;
CRF层,结合Bi-LSTM层的输出,通过初始化转移矩阵来计算每个句子出现的实体标签的最佳路径。
具体地,采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测,所述序列标注的检错模型结合通用领域的监督数据训练模型,具体为:
文本表示层,通过skip-gram或者cbow的方式嵌入文本,文本表示为n*k的矩阵,其中n为句子的最大长度,k为词向量维度;
Bi-LSTM层,通过长短期记忆网络实现句子中每个字的输出,并通过数学结构保持长距离的字的信息,Bi-LSTM层的输出矩阵为n*2*h,其中h为文本表示层的维度;
CRF层,结合Bi-LSTM层的输出,通过初始化转移矩阵来计算每个句子出现的实体标签的最佳路径。
具体地,在采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测之前,还包括:
对文本进行特殊字符和表情符号的过滤,并构成字表,将每个句子中的字进行数字化;
将字符和实体标注对应的数据以batch的方式读取,并tokenize每个句子,将[CLS]和[SEP]加在句子的首尾。
具体地,对文本进行特殊字符和表情符号的过滤,并构成字表,将每个句子中的字进行数字化,还包括:
将字符与标注的实体标签处理为一一对应的形式,采用分词处理拼音词典。具体地,将错误替换集合中的词语依次替换错误,采用rnnlm语言模型来对替换错误后的句子进行困惑度计算,其中所述rnnlm语言模型具体为:
表示层,将字+词合起来表征句子,并用word2vec进行向量化;
RNN层,包括循环神经网络,将文本进行序列建模,每一个隐藏层输出都取决于当前的输入和前一时刻的输出,学习到句子的表述顺序;
输出层,接入线性变化的一个激活函数,得到每个句子的损失值。
具体地,所述困惑度的计算具体为:
其中,S表示为句子,w表示字,i表示句子中字的序号,i=1,2....N,N表示句子中字的个数。
本发明实施例一方面还提供一种实现跨领域的中文文本纠错系统,包括:
错误检测模块:采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测;
错误召回模块:通过编辑距离或者Jaccard距离在词表的拼音库中进行错误召回,获得错误替换集合;
纠错排序模块:将错误替换集合中的词语依次替换错误,采用rnnlm语言模型来对替换错误后的句子进行困惑度计算,根据计算的句子困惑度确定错误替换集合中正确的词语,完成中文文本纠错。
本发明实施例另一方面还提供一种设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述一种实现跨领域的中文文本纠错方法的步骤。
本发明实施例再一方面还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述一种实现跨领域的中文文本纠错方法的步骤。
由上述对本发明的描述可知,与现有技术相比,本发明具有如下有益效果:
(1)本发明提供了一种实现跨领域的中文文本纠错方法,采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测;通过编辑距离或者Jaccard距离在词表的拼音库中进行错误找回,获得错误替换集合;将错误替换集合中的词语依次替换错误,采用rnnlm语言模型来对替换错误后的句子进行困惑度计算,根据计算的句子困惑度确定错误替换集合中正确的词语,完成中文文本纠错;本发明通过提出一套错误检测→候选召回→纠错排序的模型,能够更通用地处理跨领域文本的纠错问题,通过深度学习训练的语言模型来召回文本,能够提升召回文本的困惑度,并且模型相互解耦合,提升了效率。
(2)本发明通过采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测,能够在不同领域下对错误文本进行纠正,从而实现跨领域的文本纠错。
附图说明
图1为本发明实施例提供的实现跨领域的中文文本纠错方法流程图;
图2为本发明实施例提供的实现跨领域的中文文本纠错方法架构图;
图3为本发明实施例提供的实现跨领域的中文文本纠错系统的结构图
图4为本发明实施例提供的一种电子设备的实施例示意图;
图5为本发明实施例提供的一种计算机可读存储介质的实施例示意图。
以下结合附图和具体实施例对本发明作进一步详述。
具体实施方式
本发明实施例提出一种实现跨领域的中文文本纠错方法,即一套错误检测→候选召回→纠错排序的模型,能够更通用地处理跨领域文本的纠错问题,通过深度学习训练的语言模型来召回文本,能够提升召回文本的困惑度,并且模型相互解耦合,提升了效率。
如图1,为本发明实施例提供的一种实现跨领域的中文文本纠错方法的具体流程图,包括如下步骤:
S101:采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测;
具体地,采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测,所述序列标注的检错模型结合通用领域的监督数据训练模型,具体为:
文本表示层,通过bert预训练模型进行文本表示,文本表示为n*k的矩阵,其中n为句子的最大长度,k为词向量维度;
Bi-LSTM层,通过长短期记忆网络实现句子中每个字的输出,并通过数学结构保持长距离的字的信息,Bi-LSTM层的输出矩阵为n*2*h,其中h为文本表示层的维度;
CRF层,结合Bi-LSTM层的输出,通过初始化转移矩阵来计算每个句子出现的实体标签的最佳路径。
其中hidden为隐藏层。
BERT模型是一种基于双向Transformer构建的语言模型;在之前的预训练模型(包括word2vec,ELMo等)都会生成词向量,这种类别的预训练模型属于领域迁移,而bert模型属于模型迁移。
BERT模型是将预训练模型和下游任务模型结合在一起的,也就是说在做下游任务时仍然是用BERT模型,而且天然支持文本分类任务,在做文本分类任务时不需要对模型做修改,提升效率。
另一实施例,采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测,所述序列标注的检错模型结合通用领域的监督数据训练模型,具体为:
文本表示层,通过skip-gram或者cbow的方式嵌入文本,文本表示为n*k的矩阵,其中n为句子的最大长度,k为词向量维度;
Bi-LSTM层,通过长短期记忆网络实现句子中每个字的输出,并通过数学结构保持长距离的字的信息,Bi-LSTM层的输出矩阵为n*2*h,其中h为文本表示层的维度;
CRF层,结合Bi-LSTM层的输出,通过初始化转移矩阵来计算每个句子出现的实体标签的最佳路径。
skip-gram模型和cbow模型为word2vec中涉及到的两个模型,cbow是已知当前词的上下文,来预测当前词,而Skip-gram则相反,是在已知当前词的情况下,预测其上下文;
skip-gram和cbow模型均包括三层,分别是输入层、投影层和输出层,且都是以Huffman树作为基础的,而Huffman树中非叶节点存储的中间向量的初始化值是零向量,而叶节点对应的单词的词向量是随机初始化的。
具体地,在采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测之前,还包括:
对文本进行特殊字符和表情符号的过滤,并构成字表,将每个句子中的字进行数字化;
将字符和实体标注对应的数据以batch的方式读取,并tokenize每个句子,将[CLS]和[SEP]加在句子的首尾。
具体地,对文本进行特殊字符和表情符号的过滤,并构成字表,将每个句子中的字进行数字化,还包括:
将字符与标注的实体标签处理为一一对应的形式,采用分词处理拼音词典。
本发明实施例通过采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测,能够在不同领域下对错误文本进行纠正,从而实现跨领域的文本纠错。
S102:通过编辑距离或者Jaccard距离在词表的拼音库中进行错误找回,获得错误替换集合;
编辑距离,又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符;
例如将kitten一字转成sitting:sitten(k→s);sittin(e→i);sitting(→g);
找出字符串的编辑距离,即把一个字符串s1最少经过多少步操作变成编程字符串s2,操作有三种,添加一个字符,删除一个字符,修改一个字符;
Jaccard距离,即杰卡德距离,距离用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度;与杰卡德相似系数相反的概念是杰卡德距离(Jaccard Distance),可以用如下公式来表示:
其中,两个集合A和B交集元素的个数在A、B并集中所占的比例,称为这两个集合的杰卡德系数,用符号J(A,B)表示。杰卡德相似系数是衡量两个集合相似度的一种指标(余弦距离也可以用来衡量两个集合的相似度)。
S103:将错误替换集合中的词语依次替换错误,采用rnnlm语言模型来对替换错误后的句子进行困惑度计算,根据计算的句子困惑度确定错误替换集合中正确的词语,完成中文文本纠错。
具体地,将错误替换集合中的词语依次替换错误,采用rnnlm语言模型来对替换错误后的句子进行困惑度计算,其中所述rnnlm语言模型具体为:
表示层,将字+词合起来表征句子,并用word2vec进行向量化;
RNN层,包括循环神经网络,将文本进行序列建模,每一个隐藏层输出都取决于当前的输入和前一时刻的输出,学习到句子的表述顺序;
输出层,接入线性变化的一个激活函数,得到每个句子的损失值。
具体地,所述困惑度的计算具体为:
其中,S表示为句子,w表示字,i表示句子中字的序号,i=1,2....N,N表示句子中字的个数。
困惑度是用在自然语言处理领域(NLP)中,衡量语言模型好坏的指标。它主要是根据每个词来估计一句话出现的概率,困惑度越小,句子出现概率越大,说明句子困惑度越高。
对于句子S,句子出现的概率为:
P(S)=P(W
=p(W
就是每个字出现概率相乘的联合概率;
句子S困惑度为:
则:
上式两边取对数,然后再解出PP(S)就可以得到每个字连乘取负log再做指数的形式:
指数的部分其实就是交叉熵损失的形式,满足句子出现的概率越高,则困惑度越小,句子出现的概率其实就可以表征句子的困惑度,因此用这个来度量句子的困惑度。
如图2为本发明实施例提供的一种实现跨领域的中文文本纠错方法的架构图。
如图3,本发明实施例一方面还提供一种实现跨领域的中文文本纠错系统,包括:
错误检测模块301:采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测;
在错误检测模块301中,采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测,所述序列标注的检错模型结合通用领域的监督数据训练模型,具体为:
文本表示层,通过bert预训练模型进行文本表示,文本表示为n*k的矩阵,其中n为句子的最大长度,k为词向量维度;
Bi-LSTM层,通过长短期记忆网络实现句子中每个字的输出,并通过数学结构保持长距离的字的信息,Bi-LSTM层的输出矩阵为n*2*h,其中h为文本表示层的维度;
CRF层,结合Bi-LSTM层的输出,通过初始化转移矩阵来计算每个句子出现的实体标签的最佳路径。
BERT模型是一种基于双向Transformer构建的语言模型;在之前的预训练模型(包括word2vec,ELMo等)都会生成词向量,这种类别的预训练模型属于领域迁移,而bert模型属于模型迁移。
BERT模型是将预训练模型和下游任务模型结合在一起的,也就是说在做下游任务时仍然是用BERT模型,而且天然支持文本分类任务,在做文本分类任务时不需要对模型做修改,提升效率。
另一实施例,采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测,所述序列标注的检错模型结合通用领域的监督数据训练模型,具体为:
文本表示层,通过skip-gram或者cbow的方式嵌入文本,文本表示为n*k的矩阵,其中n为句子的最大长度,k为词向量维度;
Bi-LSTM层,通过长短期记忆网络实现句子中每个字的输出,并通过数学结构保持长距离的字的信息,Bi-LSTM层的输出矩阵为n*2*h,其中h为文本表示层的维度;
CRF层,结合Bi-LSTM层的输出,通过初始化转移矩阵来计算每个句子出现的实体标签的最佳路径。
skip-gram模型和cbow模型为word2vec中涉及到的两个模型,cbow是已知当前词的上下文,来预测当前词,而Skip-gram则相反,是在已知当前词的情况下,预测其上下文;
skip-gram和cbow模型均包括三层,分别是输入层、投影层和输出层,且都是以Huffman树作为基础的,而Huffman树中非叶节点存储的中间向量的初始化值是零向量,而叶节点对应的单词的词向量是随机初始化的。
具体地,在采用序列标注的检错模型结合通用领域的监督数据训练模型进行错误检测之前,还包括:
对文本进行特殊字符和表情符号的过滤,并构成字表,将每个句子中的字进行数字化;
将字符和实体标注对应的数据以batch的方式读取,并tokenize每个句子,将[CLS]和[SEP]加在句子的首尾。
具体地,对文本进行特殊字符和表情符号的过滤,并构成字表,将每个句子中的字进行数字化,还包括:
将字符与标注的实体标签处理为一一对应的形式,采用分词处理拼音词典
错误召回模块302:通过编辑距离或者Jaccard距离在词表的拼音库中进行错误召回,获得错误替换集合;
在错误召回模块中,编辑距离,又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符;
例如将kitten一字转成sitting:sitten(k→s);sittin(e→i);sitting(→g);
找出字符串的编辑距离,即把一个字符串s1最少经过多少步操作变成编程字符串s2,操作有三种,添加一个字符,删除一个字符,修改一个字符;
Jaccard距离,即杰卡德距离,距离用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度;与杰卡德相似系数相反的概念是杰卡德距离(Jaccard Distance),可以用如下公式来表示:
其中,两个集合A和B交集元素的个数在A、B并集中所占的比例,称为这两个集合的杰卡德系数,用符号J(A,B)表示。杰卡德相似系数是衡量两个集合相似度的一种指标(余弦距离也可以用来衡量两个集合的相似度)。
纠错排序模块303:将错误替换集合中的词语依次替换错误,采用rnnlm语言模型来对替换错误后的句子进行困惑度计算,根据计算的句子困惑度确定错误替换集合中正确的词语,完成中文文本纠错。
在纠错排序模块中,具体地,将错误替换集合中的词语依次替换错误,采用rnnlm语言模型来对替换错误后的句子进行困惑度计算,其中所述rnnlm语言模型具体为:
表示层,将字+词合起来表征句子,并用word2vec进行向量化;
RNN层,包括循环神经网络,将文本进行序列建模,每一个隐藏层输出都取决于当前的输入和前一时刻的输出,学习到句子的表述顺序;
输出层,接入线性变化的一个激活函数,得到每个句子的损失值。
具体地,所述困惑度的计算具体为:
其中,S表示为句子,w表示字,i表示句子中字的序号,i=1,2....N,N表示句子中字的个数。
困惑度是用在自然语言处理领域(NLP)中,衡量语言模型好坏的指标。它主要是根据每个词来估计一句话出现的概率,困惑度越小,句子出现概率越大,说明句子困惑度越高。
对于句子S,句子出现的概率为:
P(S)=P(W
=p(W
就是每个字出现概率相乘的联合概率;
句子S困惑度为:
则:
上式两边取对数,然后再解出PP(S)就可以得到每个字连乘取负log再做指数的形式:
指数的部分其实就是交叉熵损失的形式,满足句子出现的概率越高,则困惑度越小,句子出现的概率其实就可以表征句子的困惑度,因此用这个来度量句子的困惑度。
如图4,本发明实施例另一方面还提供一种设备,包括存储器410、处理器420及存储在存储器上并可在处理器上运行的计算机程序411,所述处理器420执行所述计算机程序411时实现上述一种实现跨领域的中文文本纠错方法的步骤。
在具体实施过程中,处理器420执行计算机程序411时,可以实现图1对应的实施例中任一实施方式。
由于本实施例所介绍的电子设备为实施本发明实施例中一种数据处理装置所采用的设备,故而基于本发明实施例中所介绍的方法,本领域所属技术人员能够了解本实施例的电子设备的具体实施方式以及其各种变化形式,所以在此对于该电子设备如何实现本发明实施例中的方法不再详细介绍,只要本领域所属技术人员实施本发明实施例中的方法所采用的设备,都属于本发明所欲保护的范围。
如图5所示,本发明实施例再一方面还提供一种计算机可读存储介质500,所述计算机可读存储介质上存储有计算机程序511,所述计算机程序被处理器执行时实现上述一种实现跨领域的中文文本纠错方法的步骤。
在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(digitalsubscriber line,DSL))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存储的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,DVD)、或者半导体介质(例如固态硬盘(solid state disk,SSD))等。
上述仅为本发明的具体实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均应属于侵犯本发明保护范围的行为。
- 一种实现跨领域的中文文本纠错方法和系统
- 一种实现纠错的方法及系统以及一种实现纠错的接入设备